代码随想录算法训练营第60天:动态and
72. 编辑距离
力扣题目链接(opens new window)
给你两个单词 word1 和 word2,请你计算出将 word1 转换成 word2 所使用的最少操作数 。
你可以对一个单词进行如下三种操作:
- 插入一个字符
- 删除一个字符
- 替换一个字符
- 示例 1:
- 输入:word1 = “horse”, word2 = “ros”
- 输出:3
- 解释: horse -> rorse (将 ‘h’ 替换为 ‘r’) rorse -> rose (删除 ‘r’) rose -> ros (删除 ‘e’)
- 示例 2:
- 输入:word1 = “intention”, word2 = “execution”
- 输出:5
- 解释: intention -> inention (删除 ‘t’) inention -> enention (将 ‘i’ 替换为 ‘e’) enention -> exention (将 ‘n’ 替换为 ‘x’) exention -> exection (将 ‘n’ 替换为 ‘c’) exection -> execution (插入 ‘u’)
提示:
- 0 <= word1.length, word2.length <= 500
- word1 和 word2 由小写英文字母组成
#算法公开课
《代码随想录》算法视频公开课 ****(opens new window)**** :动态规划终极绝杀! LeetCode:72.编辑距离 ****(opens new window)**** ,相信结合视频再看本篇题解,更有助于大家对本题的理解。
#思路
编辑距离终于来了,这道题目如果大家没有了解动态规划的话,会感觉超级复杂。
编辑距离是用动规来解决的经典题目,这道题目看上去好像很复杂,但用动规可以很巧妙的算出最少编辑距离。
接下来我依然使用动规五部曲,对本题做一个详细的分析:
#1. 确定dp数组(dp table)以及下标的含义
dp[i][j] 表示以下标i-1为结尾的字符串word1,和以下标j-1为结尾的字符串word2,最近编辑距离为dp[i][j] 。
有同学问了,为啥要表示下标i-1为结尾的字符串呢,为啥不表示下标i为结尾的字符串呢?
为什么这么定义我在 718. 最长重复子数组 **(opens new window)** 中做了详细的讲解。
其实用i来表示也可以! 用i-1就是为了方便后面dp数组初始化的。
#2. 确定递推公式
在确定递推公式的时候,首先要考虑清楚编辑的几种操作,整理如下:
if (word1[i - 1] == word2[j - 1])
不操作
if (word1[i - 1] != word2[j - 1])
增
删
换
也就是如上4种情况。
if (word1[i - 1] == word2[j - 1]) 那么说明不用任何编辑,dp[i][j] 就应该是 dp[i - 1][j - 1],即dp[i][j] = dp[i - 1][j - 1];
此时可能有同学有点不明白,为啥要即dp[i][j] = dp[i - 1][j - 1]呢?
那么就在回顾上面讲过的dp[i][j]的定义,word1[i - 1] 与 word2[j - 1]相等了,那么就不用编辑了,以下标i-2为结尾的字符串word1和以下标j-2为结尾的字符串word2的最近编辑距离dp[i - 1][j - 1]就是 dp[i][j]了。
在下面的讲解中,如果哪里看不懂,就回想一下dp[i][j]的定义,就明白了。
在整个动规的过程中,最为关键就是正确理解dp[i][j] 的定义!
if (word1[i - 1] != word2[j - 1]),此时就需要编辑了,如何编辑呢?
- 操作一:word1删除一个元素,那么就是以下标i - 2为结尾的word1 与 j-1为结尾的word2的最近编辑距离 再加上一个操作。
即 dp[i][j] = dp[i - 1][j] + 1;
- 操作二:word2删除一个元素,那么就是以下标i - 1为结尾的word1 与 j-2为结尾的word2的最近编辑距离 再加上一个操作。
即 dp[i][j] = dp[i][j - 1] + 1;
这里有同学发现了,怎么都是删除元素,添加元素去哪了。
word2添加一个元素,相当于word1删除一个元素,例如 word1 = "ad" ,word2 = "a",word1删除元素'd' 和 word2添加一个元素'd',变成word1="a", word2="ad", 最终的操作数是一样! dp数组如下图所示意的:
a a d
+-----+-----+ +-----+-----+-----+
| 0 | 1 | | 0 | 1 | 2 |
+-----+-----+ ===> +-----+-----+-----+
a | 1 | 0 | a | 1 | 0 | 1 |
+-----+-----+ +-----+-----+-----+
d | 2 | 1 |
+-----+-----+
操作三:替换元素,word1替换word1[i - 1],使其与word2[j - 1]相同,此时不用增删加元素。
可以回顾一下,if (word1[i - 1] == word2[j - 1])的时候我们的操作 是 dp[i][j] = dp[i - 1][j - 1] 对吧。
那么只需要一次替换的操作,就可以让 word1[i - 1] 和 word2[j - 1] 相同。
所以 dp[i][j] = dp[i - 1][j - 1] + 1;
综上,当 if (word1[i - 1] != word2[j - 1]) 时取最小的,即:dp[i][j] = min({dp[i - 1][j - 1], dp[i - 1][j], dp[i][j - 1]}) + 1;
递归公式代码如下:
if (word1[i - 1] == word2[j - 1]) {
dp[i][j] = dp[i - 1][j - 1];
}
else {
dp[i][j] = min({dp[i - 1][j - 1], dp[i - 1][j], dp[i][j - 1]}) + 1;
}
#3. dp数组如何初始化
再回顾一下dp[i][j]的定义:
dp[i][j] 表示以下标i-1为结尾的字符串word1,和以下标j-1为结尾的字符串word2,最近编辑距离为dp[i][j] 。
那么dp[i][0] 和 dp[0][j] 表示什么呢?
dp[i][0] :以下标i-1为结尾的字符串word1,和空字符串word2,最近编辑距离为dp[i][0]。
那么dp[i][0]就应该是i,对word1里的元素全部做删除操作,即:dp[i][0] = i;
同理dp[0][j] = j;
所以C++代码如下:
for (int i = 0; i <= word1.size(); i++) dp[i][0] = i;
for (int j = 0; j <= word2.size(); j++) dp[0][j] = j;
#4. 确定遍历顺序
从如下四个递推公式:
-
dp[i][j] = dp[i - 1][j - 1] -
dp[i][j] = dp[i - 1][j - 1] + 1 -
dp[i][j] = dp[i][j - 1] + 1 -
dp[i][j] = dp[i - 1][j] + 1
可以看出dp[i][j]是依赖左方,上方和左上方元素的,如图:

所以在dp矩阵中一定是从左到右从上到下去遍历。
代码如下:
for (int i = 1; i <= word1.size(); i++) {
for (int j = 1; j <= word2.size(); j++) {
if (word1[i - 1] == word2[j - 1]) {
dp[i][j] = dp[i - 1][j - 1];
}
else {
dp[i][j] = min({dp[i - 1][j - 1], dp[i - 1][j], dp[i][j - 1]}) + 1;
}
}
}
#5. 举例推导dp数组
以示例1为例,输入:word1 = "horse", word2 = "ros"为例,dp矩阵状态图如下:
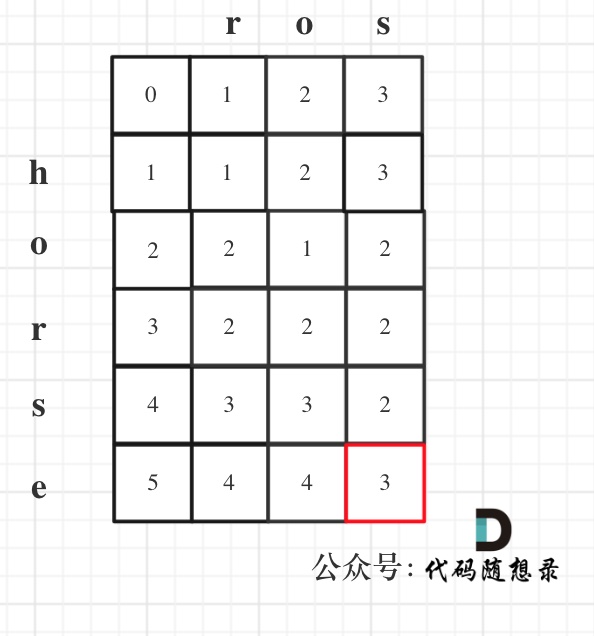
以上动规五部分析完毕,C++代码如下:
class Solution {
public:
int minDistance(string word1, string word2) {
vector<vector<int>> dp(word1.size() + 1, vector<int>(word2.size() + 1, 0));
for (int i = 0; i <= word1.size(); i++) dp[i][0] = i;
for (int j = 0; j <= word2.size(); j++) dp[0][j] = j;
for (int i = 1; i <= word1.size(); i++) {
for (int j = 1; j <= word2.size(); j++) {
if (word1[i - 1] == word2[j - 1]) {
dp[i][j] = dp[i - 1][j - 1];
}
else {
dp[i][j] = min({dp[i - 1][j - 1], dp[i - 1][j], dp[i][j - 1]}) + 1;
}
}
}
return dp[word1.size()][word2.size()];
}
};
- 时间复杂度: O(n * m)
- 空间复杂度: O(n * m)
-
动态规划之编辑距离总结篇
本周我们讲了动态规划之终极绝杀:编辑距离,为什么叫做终极绝杀呢?
细心的录友应该知道,我们在前三篇动态规划的文章就一直为 编辑距离 这道题目做铺垫。
#判断子序列
动态规划:392.判断子序列 **(opens new window)** 给定字符串 s 和 t ,判断 s 是否为 t 的子序列。
这道题目 其实是可以用双指针或者贪心的的,但是我在开篇的时候就说了这是编辑距离的入门题目,因为从题意中我们也可以发现,只需要计算删除的情况,不用考虑增加和替换的情况。
-
if (s[i - 1] == t[j - 1])
- t中找到了一个字符在s中也出现了
-
if (s[i - 1] != t[j - 1])
- 相当于t要删除元素,继续匹配
状态转移方程:
if (s[i - 1] == t[j - 1]) dp[i][j] = dp[i - 1][j - 1] + 1;
else dp[i][j] = dp[i][j - 1];
#不同的子序列
动态规划:115.不同的子序列 **(opens new window)** 给定一个字符串 s 和一个字符串 t ,计算在 s 的子序列中 t 出现的个数。
本题虽然也只有删除操作,不用考虑替换增加之类的,但相对于动态规划:392.判断子序列 **(opens new window)** 就有难度了,这道题目双指针法可就做不了。
当s[i - 1] 与 t[j - 1]相等时,dp[i][j]可以有两部分组成。
一部分是用s[i - 1]来匹配,那么个数为dp[i - 1][j - 1]。
一部分是不用s[i - 1]来匹配,个数为dp[i - 1][j]。
这里可能有同学不明白了,为什么还要考虑 不用s[i - 1]来匹配,都相同了指定要匹配啊。
例如: s:bagg 和 t:bag ,s[3] 和 t[2]是相同的,但是字符串s也可以不用s[3]来匹配,即用s[0]s[1]s[2]组成的bag。
当然也可以用s[3]来匹配,即:s[0]s[1]s[3]组成的bag。
所以当s[i - 1] 与 t[j - 1]相等时,dp[i][j] = dp[i - 1][j - 1] + dp[i - 1][j];
当s[i - 1] 与 t[j - 1]不相等时,dp[i][j]只有一部分组成,不用s[i - 1]来匹配,即:dp[i - 1][j]
所以递推公式为:dp[i][j] = dp[i - 1][j];
状态转移方程:
if (s[i - 1] == t[j - 1]) {
dp[i][j] = dp[i - 1][j - 1] + dp[i - 1][j];
} else {
dp[i][j] = dp[i - 1][j];
}
#两个字符串的删除操作
动态规划:583.两个字符串的删除操作 **(opens new window)** 给定两个单词 word1 和 word2,找到使得 word1 和 word2 相同所需的最少步数,每步可以删除任意一个字符串中的一个字符。
本题和动态规划:115.不同的子序列 **(opens new window)** 相比,其实就是两个字符串可以都可以删除了,情况虽说复杂一些,但整体思路是不变的。
- 当word1[i - 1] 与 word2[j - 1]相同的时候
- 当word1[i - 1] 与 word2[j - 1]不相同的时候
当word1[i - 1] 与 word2[j - 1]相同的时候,dp[i][j] = dp[i - 1][j - 1];
当word1[i - 1] 与 word2[j - 1]不相同的时候,有三种情况:
情况一:删word1[i - 1],最少操作次数为dp[i - 1][j] + 1
情况二:删word2[j - 1],最少操作次数为dp[i][j - 1] + 1
情况三:同时删word1[i - 1]和word2[j - 1],操作的最少次数为dp[i - 1][j - 1] + 2
那最后当然是取最小值,所以当word1[i - 1] 与 word2[j - 1]不相同的时候,递推公式:dp[i][j] = min({dp[i - 1][j - 1] + 2, dp[i - 1][j] + 1, dp[i][j - 1] + 1});
状态转移方程:
if (word1[i - 1] == word2[j - 1]) {
dp[i][j] = dp[i - 1][j - 1];
} else {
dp[i][j] = min({dp[i - 1][j - 1] + 2, dp[i - 1][j] + 1, dp[i][j - 1] + 1});
}
#编辑距离
动态规划:72.编辑距离 **(opens new window)** 给你两个单词 word1 和 word2,请你计算出将 word1 转换成 word2 所使用的最少操作数 。
编辑距离终于来了,有了前面三道题目的铺垫,应该有思路了,本题是两个字符串可以增删改,比 动态规划:判断子序列 **(opens new window)** ,动态规划:不同的子序列 **(opens new window)** ,动态规划:两个字符串的删除操作 **(opens new window)** 都要复杂的多。
在确定递推公式的时候,首先要考虑清楚编辑的几种操作,整理如下:
-
if (word1[i - 1] == word2[j - 1])
- 不操作
-
if (word1[i - 1] != word2[j - 1])
- 增
- 删
- 换
也就是如上四种情况。
if (word1[i - 1] == word2[j - 1]) 那么说明不用任何编辑,dp[i][j] 就应该是 dp[i - 1][j - 1],即dp[i][j] = dp[i - 1][j - 1];
此时可能有同学有点不明白,为啥要即dp[i][j] = dp[i - 1][j - 1]呢?
那么就在回顾上面讲过的dp[i][j]的定义,word1[i - 1] 与 word2[j - 1]相等了,那么就不用编辑了,以下标i-2为结尾的字符串word1和以下标j-2为结尾的字符串word2的最近编辑距离dp[i - 1][j - 1] 就是 dp[i][j]了。
在下面的讲解中,如果哪里看不懂,就回想一下dp[i][j]的定义,就明白了。
在整个动规的过程中,最为关键就是正确理解dp[i][j]的定义!
if (word1[i - 1] != word2[j - 1]),此时就需要编辑了,如何编辑呢?
操作一:word1增加一个元素,使其word1[i - 1]与word2[j - 1]相同,那么就是以下标i-2为结尾的word1 与 i-1为结尾的word2的最近编辑距离 加上一个增加元素的操作。
即 dp[i][j] = dp[i - 1][j] + 1;
操作二:word2添加一个元素,使其word1[i - 1]与word2[j - 1]相同,那么就是以下标i-1为结尾的word1 与 j-2为结尾的word2的最近编辑距离 加上一个增加元素的操作。
即 dp[i][j] = dp[i][j - 1] + 1;
这里有同学发现了,怎么都是添加元素,删除元素去哪了。
word2添加一个元素,相当于word1删除一个元素,例如 word1 = “ad” ,word2 = “a”,word2添加一个元素d,也就是相当于word1删除一个元素d,操作数是一样!
操作三:替换元素,word1替换word1[i - 1],使其与word2[j - 1]相同,此时不用增加元素,那么以下标i-2为结尾的word1 与 j-2为结尾的word2的最近编辑距离 加上一个替换元素的操作。
即 dp[i][j] = dp[i - 1][j - 1] + 1;
综上,当 if (word1[i - 1] != word2[j - 1]) 时取最小的,即:dp[i][j] = min({dp[i - 1][j - 1], dp[i - 1][j], dp[i][j - 1]}) + 1;
递归公式代码如下:
if (word1[i - 1] == word2[j - 1]) {
dp[i][j] = dp[i - 1][j - 1];
}
else {
dp[i][j] = min({dp[i - 1][j - 1], dp[i - 1][j], dp[i][j - 1]}) + 1;
}
#总结
心思的录友应该会发现我用了三道题做铺垫,才最后引出了动态规划:72.编辑距离 **(opens new window)** ,Carl的良苦用心呀,你们体会到了嘛!
647. 回文子串
力扣题目链接(opens new window)
给定一个字符串,你的任务是计算这个字符串中有多少个回文子串。
具有不同开始位置或结束位置的子串,即使是由相同的字符组成,也会被视作不同的子串。
示例 1:
- 输入:“abc”
- 输出:3
- 解释:三个回文子串: “a”, “b”, “c”
示例 2:
- 输入:“aaa”
- 输出:6
- 解释:6个回文子串: “a”, “a”, “a”, “aa”, “aa”, “aaa”
提示:输入的字符串长度不会超过 1000 。
#算法公开课
《代码随想录》算法视频公开课 ****(opens new window)**** :动态规划,字符串性质决定了DP数组的定义 | LeetCode:647.回文子串 ****(opens new window)**** ,相信结合视频在看本篇题解,更有助于大家对本题的理解。
#思路
#暴力解法
两层for循环,遍历区间起始位置和终止位置,然后还需要一层遍历判断这个区间是不是回文。所以时间复杂度:O(n^3)
#动态规划
动规五部曲:
- 确定dp数组(dp table)以及下标的含义
如果大家做了很多这种子序列相关的题目,在定义dp数组的时候 很自然就会想题目求什么,我们就如何定义dp数组。
绝大多数题目确实是这样,不过本题如果我们定义,dp[i] 为 下标i结尾的字符串有 dp[i]个回文串的话,我们会发现很难找到递归关系。
dp[i] 和 dp[i-1] ,dp[i + 1] 看上去都没啥关系。
所以我们要看回文串的性质。 如图:

我们在判断字符串S是否是回文,那么如果我们知道 s[1],s[2],s[3] 这个子串是回文的,那么只需要比较 s[0]和s[4]这两个元素是否相同,如果相同的话,这个字符串s 就是回文串。
那么此时我们是不是能找到一种递归关系,也就是判断一个子字符串(字符串的下表范围[i,j])是否回文,依赖于,子字符串(下表范围[i + 1, j - 1])) 是否是回文。
所以为了明确这种递归关系,我们的dp数组是要定义成一位二维dp数组。
布尔类型的dp[i][j]:表示区间范围[i,j] (注意是左闭右闭)的子串是否是回文子串,如果是dp[i][j]为true,否则为false。
- 确定递推公式
在确定递推公式时,就要分析如下几种情况。
整体上是两种,就是s[i]与s[j]相等,s[i]与s[j]不相等这两种。
当s[i]与s[j]不相等,那没啥好说的了,dp[i][j]一定是false。
当s[i]与s[j]相等时,这就复杂一些了,有如下三种情况
- 情况一:下标i 与 j相同,同一个字符例如a,当然是回文子串
- 情况二:下标i 与 j相差为1,例如aa,也是回文子串
- 情况三:下标:i 与 j相差大于1的时候,例如cabac,此时s[i]与s[j]已经相同了,我们看i到j区间是不是回文子串就看aba是不是回文就可以了,那么aba的区间就是 i+1 与 j-1区间,这个区间是不是回文就看dp[i + 1][j - 1]是否为true。
以上三种情况分析完了,那么递归公式如下:
if (s[i] == s[j]) {
if (j - i <= 1) { // 情况一 和 情况二
result++;
dp[i][j] = true;
} else if (dp[i + 1][j - 1]) { // 情况三
result++;
dp[i][j] = true;
}
}
result就是统计回文子串的数量。
注意这里我没有列出当s[i]与s[j]不相等的时候,因为在下面dp[i][j]初始化的时候,就初始为false。
- dp数组如何初始化
dp[i][j]可以初始化为true么? 当然不行,怎能刚开始就全都匹配上了。
所以dp[i][j]初始化为false。
- 确定遍历顺序
遍历顺序可有有点讲究了。
首先从递推公式中可以看出,情况三是根据dp[i + 1][j - 1]是否为true,在对dp[i][j]进行赋值true的。
dp[i + 1][j - 1] 在 dp[i][j]的左下角,如图:

如果这矩阵是从上到下,从左到右遍历,那么会用到没有计算过的dp[i + 1][j - 1],也就是根据不确定是不是回文的区间[i+1,j-1],来判断了[i,j]是不是回文,那结果一定是不对的。
所以一定要从下到上,从左到右遍历,这样保证dp[i + 1][j - 1]都是经过计算的。
有的代码实现是优先遍历列,然后遍历行,其实也是一个道理,都是为了保证dp[i + 1][j - 1]都是经过计算的。
代码如下:
for (int i = s.size() - 1; i >= 0; i--) { // 注意遍历顺序
for (int j = i; j < s.size(); j++) {
if (s[i] == s[j]) {
if (j - i <= 1) { // 情况一 和 情况二
result++;
dp[i][j] = true;
} else if (dp[i + 1][j - 1]) { // 情况三
result++;
dp[i][j] = true;
}
}
}
}
- 举例推导dp数组
举例,输入:“aaa”,dp[i][j]状态如下:

图中有6个true,所以就是有6个回文子串。
注意因为dp[i][j]的定义,所以j一定是大于等于i的,那么在填充dp[i][j]的时候一定是只填充右上半部分。
以上分析完毕,C++代码如下:
class Solution {
public:
int countSubstrings(string s) {
vector<vector<bool>> dp(s.size(), vector<bool>(s.size(), false));
int result = 0;
for (int i = s.size() - 1; i >= 0; i--) { // 注意遍历顺序
for (int j = i; j < s.size(); j++) {
if (s[i] == s[j]) {
if (j - i <= 1) { // 情况一 和 情况二
result++;
dp[i][j] = true;
} else if (dp[i + 1][j - 1]) { // 情况三
result++;
dp[i][j] = true;
}
}
}
}
return result;
}
};
以上代码是为了凸显情况一二三,当然是可以简洁一下的,如下:
class Solution {
public:
int countSubstrings(string s) {
vector<vector<bool>> dp(s.size(), vector<bool>(s.size(), false));
int result = 0;
for (int i = s.size() - 1; i >= 0; i--) {
for (int j = i; j < s.size(); j++) {
if (s[i] == s[j] && (j - i <= 1 || dp[i + 1][j - 1])) {
result++;
dp[i][j] = true;
}
}
}
return result;
}
};
- 时间复杂度:O(n^2)
- 空间复杂度:O(n^2)
#双指针法
动态规划的空间复杂度是偏高的,我们再看一下双指针法。
首先确定回文串,就是找中心然后向两边扩散看是不是对称的就可以了。
在遍历中心点的时候,要注意中心点有两种情况。
一个元素可以作为中心点,两个元素也可以作为中心点。
那么有人同学问了,三个元素还可以做中心点呢。其实三个元素就可以由一个元素左右添加元素得到,四个元素则可以由两个元素左右添加元素得到。
所以我们在计算的时候,要注意一个元素为中心点和两个元素为中心点的情况。
这两种情况可以放在一起计算,但分别计算思路更清晰,我倾向于分别计算,代码如下:
class Solution {
public:
int countSubstrings(string s) {
int result = 0;
for (int i = 0; i < s.size(); i++) {
result += extend(s, i, i, s.size()); // 以i为中心
result += extend(s, i, i + 1, s.size()); // 以i和i+1为中心
}
return result;
}
int extend(const string& s, int i, int j, int n) {
int res = 0;
while (i >= 0 && j < n && s[i] == s[j]) {
i--;
j++;
res++;
}
return res;
}
};
- 时间复杂度:O(n^2)
- 空间复杂度:O(1)
516.最长回文子序列
力扣题目链接(opens new window)
给定一个字符串 s ,找到其中最长的回文子序列,并返回该序列的长度。可以假设 s 的最大长度为 1000 。
示例 1: 输入: “bbbab” 输出: 4 一个可能的最长回文子序列为 “bbbb”。
示例 2: 输入:“cbbd” 输出: 2 一个可能的最长回文子序列为 “bb”。
提示:
- 1 <= s.length <= 1000
- s 只包含小写英文字母
#算法公开课
《代码随想录》算法视频公开课 ****(opens new window)**** :动态规划再显神通,LeetCode:516.最长回文子序列 ****(opens new window)**** ,相信结合视频再看本篇题解,更有助于大家对本题的理解。
#思路
我们刚刚做过了 动态规划:回文子串 **(opens new window)** ,求的是回文子串,而本题要求的是回文子序列, 要搞清楚这两者之间的区别。
回文子串是要连续的,回文子序列可不是连续的! 回文子串,回文子序列都是动态规划经典题目。
回文子串,可以做这两题:
- 647.回文子串
- 5.最长回文子串
思路其实是差不多的,但本题要比求回文子串简单一点,因为情况少了一点。
动规五部曲分析如下:
- 确定dp数组(dp table)以及下标的含义
dp[i][j]:字符串s在[i, j]范围内最长的回文子序列的长度为dp[i][j] 。
- 确定递推公式
在判断回文子串的题目中,关键逻辑就是看s[i]与s[j]是否相同。
如果s[i]与s[j]相同,那么dp[i][j] = dp[i + 1][j - 1] + 2;
如图: 
(如果这里看不懂,回忆一下dp[i][j]的定义)
如果s[i]与s[j]不相同,说明s[i]和s[j]的同时加入 并不能增加[i,j]区间回文子序列的长度,那么分别加入s[i]、s[j]看看哪一个可以组成最长的回文子序列。
加入s[j]的回文子序列长度为dp[i + 1][j]。
加入s[i]的回文子序列长度为dp[i][j - 1]。
那么dp[i][j]一定是取最大的,即:dp[i][j] = max(dp[i + 1][j], dp[i][j - 1]);

代码如下:
if (s[i] == s[j]) {
dp[i][j] = dp[i + 1][j - 1] + 2;
} else {
dp[i][j] = max(dp[i + 1][j], dp[i][j - 1]);
}
- dp数组如何初始化
首先要考虑当i 和j 相同的情况,从递推公式:dp[i][j] = dp[i + 1][j - 1] + 2; 可以看出 递推公式是计算不到 i 和j相同时候的情况。
所以需要手动初始化一下,当i与j相同,那么dp[i][j]一定是等于1的,即:一个字符的回文子序列长度就是1。
其他情况dp[i][j]初始为0就行,这样递推公式:dp[i][j] = max(dp[i + 1][j], dp[i][j - 1]); 中dp[i][j]才不会被初始值覆盖。
vector<vector<int>> dp(s.size(), vector<int>(s.size(), 0));
for (int i = 0; i < s.size(); i++) dp[i][i] = 1;
- 确定遍历顺序
从递归公式中,可以看出,dp[i][j] 依赖于 dp[i + 1][j - 1] ,dp[i + 1][j] 和 dp[i][j - 1],如图:

所以遍历i的时候一定要从下到上遍历,这样才能保证下一行的数据是经过计算的。
j的话,可以正常从左向右遍历。
代码如下:
for (int i = s.size() - 1; i >= 0; i--) {
for (int j = i + 1; j < s.size(); j++) {
if (s[i] == s[j]) {
dp[i][j] = dp[i + 1][j - 1] + 2;
} else {
dp[i][j] = max(dp[i + 1][j], dp[i][j - 1]);
}
}
}
- 举例推导dp数组
输入s:“cbbd” 为例,dp数组状态如图:

红色框即:dp[0][s.size() - 1]; 为最终结果。
以上分析完毕,C++代码如下:
class Solution {
public:
int longestPalindromeSubseq(string s) {
vector<vector<int>> dp(s.size(), vector<int>(s.size(), 0));
for (int i = 0; i < s.size(); i++) dp[i][i] = 1;
for (int i = s.size() - 1; i >= 0; i--) {
for (int j = i + 1; j < s.size(); j++) {
if (s[i] == s[j]) {
dp[i][j] = dp[i + 1][j - 1] + 2;
} else {
dp[i][j] = max(dp[i + 1][j], dp[i][j - 1]);
}
}
}
return dp[0][s.size() - 1];
}
};
- 时间复杂度: O(n^2)
- 空间复杂度: O(n^2)