下篇地址:机器学习各个算法的优缺点!(下篇) 建议收藏。-CSDN博客
纯干货!!
-
回归
-
正则化算法
-
集成算法
-
决策树算法
-
支持向量机
-
降维算法
-
聚类算法
-
贝叶斯算法
-
人工神经网络
-
深度学习
感兴趣的朋友可以点赞、转发起来,让更多的朋友看到。
目录
1.回归
2.正则化算法
3集成算法
4决策树算法
5.支持向量机
未完待续..
1.回归
回归算法是一类用于预测连续数值输出的监督学习算法。
根据输入特征预测一个或多个目标变量。回归算法有多个分支和变种,每个分支都有其独特的优缺点。
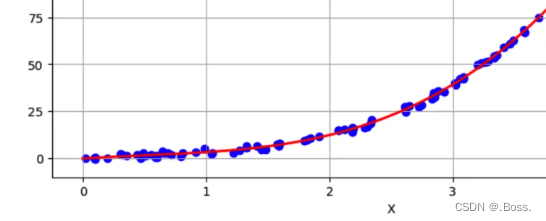
1、线性回归(Linear Regression)
-
优点:
-
简单且易于解释。
-
计算效率高,适用于大规模数据集。
-
在特征与目标之间存在线性关系时效果良好。
-
-
缺点:
-
无法处理非线性关系。
-
对异常值敏感。
-
需要满足线性回归假设(如线性关系、残差正态分布等)。
-
2、多项式回归(Polynomial Regression)
-
优点:
-
可以捕捉特征和目标之间的非线性关系。
-
相对简单实现。
-
-
缺点:
-
可能会过度拟合数据,特别是高阶多项式。
-
需要选择适当的多项式阶数。
-
3、岭回归(Ridge Regression)
-
优点:
-
可以解决多重共线性问题。
-
对异常值不敏感。
-
-
缺点:
-
不适用于特征选择,所有特征都会被考虑。
-
参数需要调整。
-
4、Lasso回归(Lasso Regression)
-
优点:
-
可以用于特征选择,趋向于将不重要的特征的系数推到零。
-
可以解决多重共线性问题。
-
-
缺点:
-
对于高维数据,可能会选择较少的特征。
-
需要调整正则化参数。
-
5、弹性网络回归(Elastic Net Regression)
-
优点:
-
综合了岭回归和Lasso回归的优点。
-
可以应对多重共线性和特征选择。
-
-
缺点:
-
需要调整两个正则化参数。
-
6、逻辑斯蒂回归(Logistic Regression):
-
优点:
-
用于二分类问题,广泛应用于分类任务。
-
输出结果可以解释为概率。
-
-
缺点:
-
仅适用于二分类问题。
-
对于复杂的非线性问题效果可能不佳。
-
7、决策树回归(Decision Tree Regression)
-
优点:
-
能够处理非线性关系。
-
不需要对数据进行特征缩放。
-
结果易于可视化和解释。
-
-
缺点:
-
容易过拟合。
-
对数据中的噪声敏感。
-
不稳定,小的数据变化可能导致不同的树结构。
-
8、随机森林回归(Random Forest Regression)
-
优点:
-
降低了决策树回归的过拟合风险。
-
能够处理高维数据。
-
-
缺点:
-
失去了部分可解释性。
-
难以调整模型参数。
-
在选择回归算法时,需要根据数据的性质以及问题的要求来决定哪种算法最适合。通常,需要进行实验和模型调优来确定最佳的回归模型。
2.正则化算法
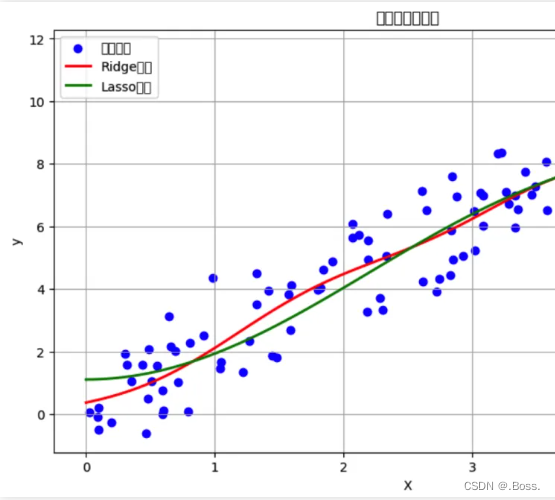
通过在模型的损失函数中引入额外的惩罚项来限制模型参数的大小。正则化有多个分支和变种,以下是一些常见的正则化算法分支以及它们的优缺点:
1、L1 正则化(Lasso 正则化)
-
优点:
-
可以用于特征选择,将不重要的特征的系数推到零。
-
可以解决多重共线性问题。
-
-
缺点:
-
对于高维数据,可能会选择较少的特征。
-
需要调整正则化参数。
-
2、L2 正则化(岭正则化)
-
优点:
-
可以解决多重共线性问题。
-
对异常值不敏感。
-
-
缺点:
-
不适用于特征选择,所有特征都会被考虑。
-
参数需要调整。
-
3、弹性网络正则化(Elastic Net 正则化)
-
优点:
-
综合了 L1 和 L2 正则化的优点,可以应对多重共线性和特征选择。
-
可以调整两个正则化参数来平衡 L1 和 L2 正则化的影响。
-
-
缺点:
-
需要调整两个正则化参数。
-
4、Dropout 正则化(用于神经网络)
-
优点:
-
通过在训练过程中随机禁用神经元,可以减少神经网络的过拟合。
-
不需要额外的参数调整。
-
-
缺点:
-
在推断时,需要考虑丢失的神经元,增加了计算成本。
-
可能需要更多的训练迭代。
-
5、贝叶斯Ridge和Lasso回归
-
优点:
-
引入了贝叶斯思想,可以提供参数的不确定性估计。
-
可以自动确定正则化参数。
-
-
缺点:
-
计算成本较高,尤其是对于大型数据集。
-
不适用于所有类型的问题。
-
6、早停法(Early Stopping)
-
优点:
-
可以通过监测验证集上的性能来减少神经网络的过拟合。
-
简单易用,不需要额外的参数调整。
-
-
缺点:
-
需要精心选择停止训练的时机,过早停止可能导致欠拟合。
-
7、数据增强
-
优点:
-
通过增加训练数据的多样性,可以降低模型的过拟合风险。
-
适用于图像分类等领域。
-
-
缺点:
-
增加了训练数据的生成和管理成本。
-
选择哪种正则化方法通常取决于数据的性质、问题的要求以及算法的复杂性。在实际应用中,通常需要通过实验和调参来确定最合适的正则化策略。
3集成算法
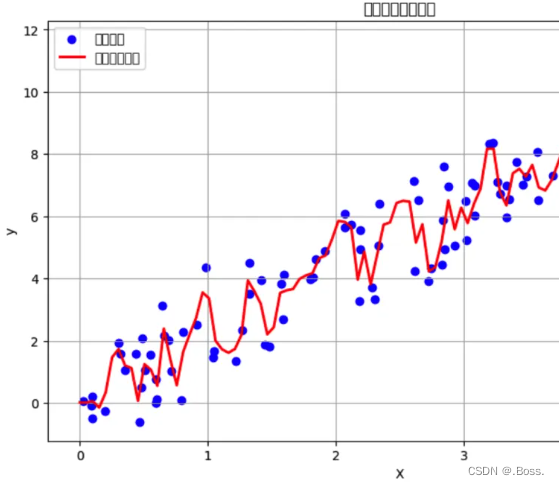
通过结合多个模型的预测,集成算法可以提高模型的性能和鲁棒性。
1、Bagging(Bootstrap Aggregating)
-
优点:
-
降低了模型的方差,减少了过拟合风险。
-
并行化处理,适用于大规模数据。
-
-
缺点:
-
不适用于处理高度偏斜的类别分布。
-
难以解释组合模型的预测结果。
-
2、随机森林(Random Forest)
-
优点:
-
基于 Bagging,降低了方差。
-
能够处理高维数据和大规模特征。
-
提供特征重要性评估。
-
-
缺点:
-
难以调整大量的超参数。
-
对噪声和异常值敏感。
-
3、Boosting
-
优点:
-
增强了模型的准确性。
-
能够自动调整弱学习器的权重。
-
适用于不平衡类别分布。
-
-
缺点:
-
对噪声数据敏感。
-
训练时间可能较长。
-
-
AdaBoost(自适应Boosting):
-
优点:能够处理高维数据和大规模特征,对异常值敏感性较低。
-
缺点:对噪声和异常值敏感。
-
-
Gradient Boosting(梯度提升):
-
优点:提供了很高的预测性能,对噪声和异常值相对较稳定。
-
缺点:需要调整多个超参数。
-
-
XGBoost(极端梯度提升)和LightGBM(轻量级梯度提升机):都是梯度提升算法的变种,具有高效性和可扩展性。
4、Stacking
-
优点:
-
可以组合多个不同类型的模型。
-
提供更高的预测性能。
-
-
缺点:
-
需要更多的计算资源和数据。
-
复杂性较高,超参数的调整较困难。
-
5、Voting(投票)
-
优点:
-
简单易用,易于实现。
-
能够组合多个不同类型的模型。
-
-
缺点:
-
对于弱学习器的性能要求较高。
-
不考虑各个模型的权重。
-
6、深度学习集成
-
优点:
-
可以利用神经网络模型的强大表示能力。
-
提供了各种集成方法,如投票、堆叠等。
-
-
缺点:
-
训练时间长,需要大量的计算资源。
-
超参数调整更加复杂。
-
选择合适的集成算法通常取决于数据的性质、问题的要求以及计算资源的可用性。在实际应用中,通常需要进行实验和模型调优,以确定最适合特定问题的集成方法。
4决策树算法
决策树算法是一种基于树状结构的监督学习算法,用于分类和回归任务。

它通过一系列的分割来建立一个树形结构,每个内部节点表示一个特征测试,每个叶节点表示一个类别或数值输出。
1、ID3 (Iterative Dichotomiser 3)
-
优点:
-
简单易懂,生成的树易于解释。
-
能够处理分类任务。
-
-
缺点:
-
对数值属性和缺失值的处理有限。
-
容易过拟合,生成的树可能很深。
-
2、C4.5
-
优点:
-
可以处理分类和回归任务。
-
能够处理数值属性和缺失值。
-
在生成树时使用信息增益进行特征选择,更健壮。
-
-
缺点:
-
对噪声和异常值敏感。
-
生成的树可能过于复杂,需要剪枝来降低过拟合风险。
-
3、CART (Classification and Regression Trees)
-
优点:
-
可以处理分类和回归任务。
-
对数值属性和缺失值有很好的支持。
-
使用基尼不纯度或均方误差进行特征选择,更灵活。
-
-
缺点:
-
生成的树可能较深,需要剪枝来避免过拟合。
-
4、随机森林(Random Forest)
-
优点:
-
基于决策树,降低了决策树的过拟合风险。
-
能够处理高维数据和大规模特征。
-
提供特征重要性评估。
-
-
缺点:
-
难以调整大量的超参数。
-
对噪声和异常值敏感。
-
5、梯度提升树(Gradient Boosting Trees)
-
优点:
-
提供了很高的预测性能,对噪声和异常值相对较稳定。
-
适用于回归和分类任务。
-
可以使用不同的损失函数。
-
-
缺点:
-
需要调整多个超参数。
-
训练时间可能较长。
-
6、XGBoost(极端梯度提升)和LightGBM(轻量级梯度提升机)
-
这些是梯度提升树的高效实现,具有高度可扩展性和性能。
7、多输出树(Multi-output Trees)
-
优点:
-
能够处理多输出(多目标)问题。
-
可以预测多个相关的目标变量。
-
-
缺点:
-
需要大量的数据来训练有效的多输出树。
-
选择合适的决策树算法通常取决于数据的性质、问题的要求以及模型的复杂性。在实际应用中,通常需要通过实验和模型调优来确定最合适的决策树算法。决策树算法的优点之一是它们产生的模型易于可视化和解释。
5.支持向量机
支持向量机(Support Vector Machine,SVM)是一种强大的监督学习算法,用于分类和回归任务。
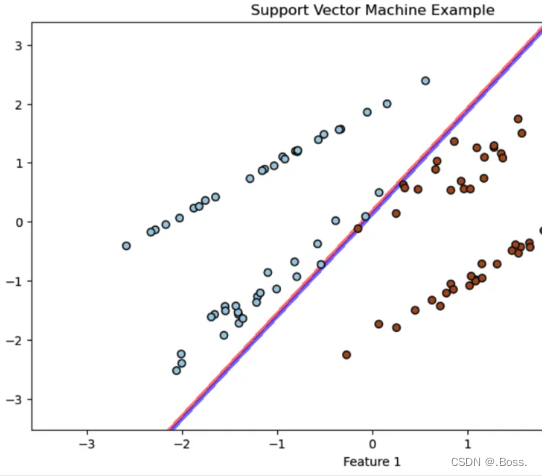
通过找到最佳的超平面来将数据分隔成不同的类别或拟合回归函数。
1、线性支持向量机
-
优点:
-
在高维空间中有效,适用于高维数据。
-
可以通过选择不同的核函数扩展到非线性问题。
-
具有较强的泛化能力。
-
-
缺点:
-
对大规模数据集和特征数目敏感。
-
对噪声和异常值敏感。
-
2、非线性支持向量机
-
优点:
-
可以处理非线性问题。
-
通过选择合适的核函数,可以适应不同类型的数据。
-
-
缺点:
-
对于复杂的非线性关系,可能需要选择合适的核函数和参数。
-
计算复杂性较高,特别是对于大型数据集。
-
3、多类别支持向量机
-
优点:
-
可以处理多类别分类问题。
-
常用的方法包括一对一(One-vs-One)和一对多(One-vs-Rest)策略。
-
-
缺点:
-
在一对一策略中,需要构建多个分类器。
-
在一对多策略中,类别不平衡问题可能出现。
-
4、核函数支持向量机
-
优点:
-
能够处理非线性问题。
-
通常使用径向基函数(RBF)作为核函数。
-
适用于复杂数据分布。
-
-
缺点:
-
需要选择适当的核函数和相关参数。
-
对于高维数据,可能存在过拟合风险。
-
5、稀疏支持向量机
-
优点:
-
引入了稀疏性,只有少数支持向量对模型有贡献。
-
可以提高模型的训练和推断速度。
-
-
缺点:
-
不适用于所有类型的数据,对于某些数据分布效果可能不佳。
-
6、核贝叶斯支持向量机
-
优点:
-
结合了核方法和贝叶斯方法,具有概率推断能力。
-
适用于小样本和高维数据。
-
-
缺点:
-
计算复杂性较高,对于大规模数据集可能不适用。
-
7、不平衡类别支持向量机
-
优点:
-
专门设计用于处理类别不平衡问题。
-
通过调整类别权重来平衡不同类别的影响。
-
-
缺点:
-
需要调整权重参数。
-
对于极不平衡的数据集,可能需要其他方法来处理。
-
选择适当的支持向量机算法通常取决于数据的性质、问题的要求以及计算资源的可用性。SVM通常在小到中等规模的数据集上表现出色,但在大规模数据集上可能需要更多的计算资源。此外,需要注意调整超参数以获得最佳性能。