一 Bagging
Bagging是并行式集成学习方法的最典型代表,算法名称来源于Bootstrap aggregating的简写,又称装袋算法,这种算法直接采用自助采样法获得 T T T个各不相同的数据集,分别使用这 T T T个数据集进行训练可获得 T T T个个体学习器,再将这些学习器组合起来共同完成分类或者回归任务。当完成分类任务时,采用简单投票法对 T T T个体学习器结果进行组合后输出;当染成回归任务时,采用简单平均法对 T T T个个体学习器学习结果进行组合输出。

Bagging算法的流程如下所示:

可以看出Bagging主要通过样本的扰动来增加基学习器之间的多样性,因此Bagging的基学习器应为那些对训练集十分敏感的不稳定学习算法,例如:神经网络与决策树等。从偏差-方差分解来看,Bagging算法主要关注于降低方差,即通过多次重复训练提高稳定性。不同于AdaBoost的是,Bagging可以十分简单地移植到多分类、回归等问题。总的说起来则是:AdaBoost关注于降低偏差,而Bagging关注于降低方差。
1.1 自助采样法
Bagging法直接采用自助采样法获得 T T T个各不相同的数据集。
自助采样法(Bootstrap sampling是一种从给定原始数据集中有放回的均匀抽样,也就是说,每当选中一个样本,它等可能地被再次选中并被再次添加到训练集中。对于给定包含 m m m个样本的原始数据集 D D D,进行自助采样获得 D ′ D' D′,具体操作方式:每次采样时,从几何 D D D中随机抽取一个样本拷贝一份到集合 D ′ D' D′中,然后将样本放回集合 D D D中,该样本在后续采样中仍有可能被采集到;重复这一步骤 m m m次后,就可以获得同样包含 m m m个样本的集合 D ′ D' D′,集合 D ′ D' D′就是自助采样的最终结果。可以想象,集合 D D D中的样本有一部分会在集合 D ′ D' D′中出现重复出现,而有些样本却一次都不出现。在 m m m次抽样中,某个样本从未被抽到的概率为 ( 1 − 1 m ) m {(1 - \frac{1}{m})^m} (1−m1)m,当集合 D D D样本足够多时有:
lim m → ∞ ( 1 − 1 m ) m = 1 e ≈ 0.368 \mathop {\lim }\limits_{m \to \infty } {(1 - \frac{1}{m})^m} = \frac{1}{e} \approx 0.368 m→∞lim(1−m1)m=e1≈0.368
也就是说,原始集合 D D D中有36.8%的样本不包含在通过自助采样法获得的集合 D ′ D' D′中。在Bagging中,未被采集到的36.8%的样本可以用作测试集对个体学习器性能进行评估,当个体学习器使用决策树算法构建时,这部分用本可以用来辅助树剪枝;使用神经网络构建个体学习器时,可以用来防止过拟合。
1.2 结合策略
结合策略指的是在训练好基学习器后,如何将这些基学习器的输出结合起来产生集成模型的最终输出,假设共有 T T T个个体学习器,以${ {h_1},{h_2}, \cdots ,{h_T}} 表示,其中样本 表示,其中样本 表示,其中样本x 经 经 经h_i 后的输出值为 后的输出值为 后的输出值为h_i(x) 。对于结合 。对于结合 。对于结合T$个个体学习器输出值,主要有一下几种策略。
1.2.1 平均法(回归问题)
平均法常用于回归类任务的数值型输出,包括简单平均法、加权平均法等。
- 简单平均法
H ( x ) = 1 T ∑ i = 1 T h i ( x ) H(x) = \frac{1}{T}\sum\limits_{i = 1}^T {{h_i}(x)} H(x)=T1i=1∑Thi(x) - 加权平均法
H ( x ) = ∑ i = 1 T w i h i ( x ) H(x) = \sum\limits_{i = 1}^T {{w_i}{h_i}(x)} H(x)=i=1∑Twihi(x)
式中, w i w_i wi是个体学习器 h i h_i hi的权重,通常要求 w i ⩾ 0 {w_i} \geqslant 0 wi⩾0且 ∑ i = 1 T w i = 1 \sum\limits_{i = 1}^T {{w_i}} = 1 i=1∑Twi=1。至于 w i w_i wi的具体值,可以根据 h i h_i hi的具体表现来确定, h i h_i hi准确率越高, w i w_i wi越大。
对于两种平均法的选择上,当个体学习器性能相差较大时,选用加权平均法;当各个体学习器性能相近时,使用简单加权平均法。
1.2.2 投票法(分类问题)
投票法更多用于作为分类任务的集成学习的结合策略。
- 相对多数投票法

也可以认为是多数决策法,即预测结果中票数最高的分类类别。如果不止一个类别获得最高票,则随机选择一个作为最终类别。
-
绝对多数投票法

不光要求获得票数最高,而且要求票数过半,否则拒绝输出。
-
加权投票法
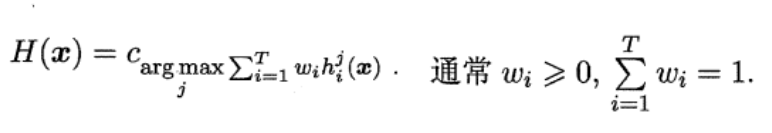
与加权平均法类似,每个个体学习器的分类票数要乘以一个权重,最终将各个类别的加权票数求和,最大的值对应的类别为最终类别。
绝对多数投票法(majority voting)提供了拒绝选项,这在可靠性要求很高的学习任务中是一个很好的机制。同时,对于分类任务,各个基学习器的输出值有两种类型,分别为类标记和类概率。

一些在产生类别标记的同时也生成置信度的学习器,置信度可转化为类概率使用,一般基于类概率进行结合往往比基于类标记进行结合的效果更好,需要注意的是对于异质集成,其类概率不能直接进行比较,此时需要将类概率转化为类标记输出,然后再投票。
1.2.3 学习法
学习法是一种更高级的结合策略,即学习出一种“投票”的学习器,Stacking是学习法的典型代表。Stacking的基本思想是:首先训练出T个基学习器,对于一个样本它们会产生T个输出,将这T个基学习器的输出与该样本的真实标记作为新的样本,m个样本就会产生一个m*T的样本集,来训练一个新的“投票”学习器。投票学习器的输入属性与学习算法对Stacking集成的泛化性能有很大的影响,书中已经提到:投票学习器采用类概率作为输入属性,选用多响应线性回归(MLR)一般会产生较好的效果。

1.3 多样性
在集成学习中,基学习器之间的多样性是影响集成器泛化性能的重要因素。因此增加多样性对于集成学习研究十分重要,一般的思路是在学习过程中引入随机性,常见的做法主要是对数据样本、输入属性、输出表示、算法参数进行扰动。
数据样本扰动,即利用具有差异的数据集来训练不同的基学习器。例如:有放回自助采样法,但此类做法只对那些不稳定学习算法十分有效,例如:决策树和神经网络等,训练集的稍微改变能导致学习器的显著变动。
输入属性扰动,即随机选取原空间的一个子空间来训练基学习器。例如:随机森林,从初始属性集中抽取子集,再基于每个子集来训练基学习器。但若训练集只包含少量属性,则不宜使用属性扰动。
输出表示扰动,此类做法可对训练样本的类标稍作变动,或对基学习器的输出进行转化。
算法参数扰动,通过随机设置不同的参数,例如:神经网络中,随机初始化权重与随机设置隐含层节点数。
二 随机森林

2.1 介绍
随机森林(Random Forest)是Bagging的一个拓展体,它的基学习器固定为决策树,多棵树也就组成了森林,而“随机”则在于选择划分属性的随机,随机森林在训练基学习器时,也采用有放回采样的方式添加样本扰动,同时它还引入了一种属性扰动,即在基决策树的训练过程中,在选择划分属性时,RF先从候选属性集中随机挑选出一个包含K个属性的子集,再从这个子集中选择最优划分属性,一般推荐K=log2(d)。
这样随机森林中基学习器的多样性不仅来自样本扰动,还来自属性扰动,从而进一步提升了基学习器之间的差异度。相比决策树的Bagging集成,随机森林的起始性能较差(由于属性扰动,基决策树的准确度有所下降),但随着基学习器数目的增多,随机森林往往会收敛到更低的泛化误差。同时不同于Bagging中决策树从所有属性集中选择最优划分属性,随机森林只在属性集的一个子集中选择划分属性,因此训练效率更高。

随机森林中的每棵树是怎么生成的呢?
每棵树的按照如下规则生成:
- 如果训练集大小为N,对于每棵树而言,随机且有放回地从训练集中的抽取N个训练样本(这种采样方式称为bootstrap sample方法),作为该树的训练集;
从这里我们可以知道:每棵树的训练集都是不同的,而且里面包含重复的训练样本(理解这点很重要)。
为什么要随机抽样训练集?
如果不进行随机抽样,每棵树的训练集都一样,那么最终训练出的树分类结果也是完全一样的,这样的话完全没有bagging的必要;
为什么要有放回地抽样?
我理解的是这样的:如果不是有放回的抽样,那么每棵树的训练样本都是不同的,都是没有交集的,这样每棵树都是"有偏的",都是绝对"片面的"(当然这样说可能不对),也就是说每棵树训练出来都是有很大的差异的;而随机森林最后分类取决于多棵树(弱分类器)的投票表决,这种表决应该是"求同",因此使用完全不同的训练集来训练每棵树这样对最终分类结果是没有帮助的,这样无异于是"盲人摸象"。
- 如果每个样本的特征维度为M,指定一个常数m<<M,随机地从M个特征中选取m个特征子集,每次树进行分裂时,从这m个特征中选择最优的;
- 每棵树都尽最大程度的生长,并且没有剪枝过程。
一开始我们提到的随机森林中的“随机”就是指的这里的两个随机性。两个随机性的引入对随机森林的分类性能至关重要。由于它们的引入,使得随机森林不容易陷入过拟合,并且具有很好得抗噪能力(比如:对缺省值不敏感)。
随机森林分类效果(错误率)与两个因素有关:
- 森林中任意两棵树的相关性:相关性越大,错误率越大;
- 森林中每棵树的分类能力:每棵树的分类能力越强,整个森林的错误率越低。
减小特征选择个数m,树的相关性和分类能力也会相应的降低;增大m,两者也会随之增大。所以关键问题是如何选择最优的m(或者是范围),这也是随机森林唯一的一个参数。
2.2 优缺点
随机森林不仅在每个个体学习器训练样本选择上,延用了Bagging算法中的自助采样法,保证了每个个体学习器训练集的差异性,同时也通过特征属性的选择,进一步进行扰动,保证了个体信息器的多样性,这也是随机森林在众多集成算法中表现突出的原因。 最后总结一下随机森林的优缺点:
优点:
(1) 每棵树都选择部分样本及部分特征,一定程度避免过拟合;
(2) 每棵树随机选择样本并随机选择特征,使得具有很好的抗噪能力,性能稳定;
(3) 能处理很高维度的数据,并且不用做特征选择;
(4) 适合并行计算;
(5) 实现比较简单;
缺点:
(1)当随机森林中的决策树个数很多时,训练时需要的空间和时间会较大;
(2)随机森林模型还有许多不好解释的地方,有点算个黑盒模型。
2.3 袋外错误率(oob error)
上面我们提到,构建随机森林的关键问题就是如何选择最优的m,要解决这个问题主要依据计算袋外错误率oob error(out-of-bag error)。
随机森林有一个重要的优点就是,没有必要对它进行交叉验证或者用一个独立的测试集来获得误差的一个无偏估计。它可以在内部进行评估,也就是说在生成的过程中就可以对误差建立一个无偏估计。
我们知道,在构建每棵树时,我们对训练集使用了不同的bootstrap sample(随机且有放回地抽取)。所以对于每棵树而言(假设对于第k棵树),大约有1/3的训练实例没有参与第k棵树的生成,它们称为第k棵树的oob样本。
而这样的采样特点就允许我们进行oob估计,它的计算方式如下:
- 对每个样本,计算它作为oob样本的树对它的分类情况(约1/3的树);
- 然后以简单多数投票作为该样本的分类结果;
- 最后用误分个数占样本总数的比率作为随机森林的oob误分率。