基本介绍
随着人工智能大模型技术的迅速发展,一种创新的计费模式正在逐渐普及,即以“令牌”(Token)作为衡量使用成本的单位。那么,究竟什么是Token呢?
Token 是一种将自然语言文本转化为计算机可以理解的形式——词向量的手段。这个转化过程涉及对文本进行分词处理,将每个单词、汉字或字符转换为唯一的词向量表示。通过计算这些词向量在模型中的使用次数,服务提供商就能够量化用户所消耗的计算资源,并据此收取费用。
需要注意的是,不同的厂商可能采用不同的方式来定义和计算 Token。一般来说,一个 Token 可能代表一个汉字、一个英文单词,或者一个字符。
在大模型领域,通常情况下,服务商倾向于以千 Tokens(1K Tokens)为单位进行计费。用户可以通过购买一定数量的 Token 来支付模型训练和推理过程中产生的费用。
注意:Token的数量与使用模型的服务次数或数据处理量有关。一般是有梯度的,用得越多可以拿到越便宜的价格,和买东西的道理一样,零售一个价,批发一个价。
如何计算 Tokens 数量?
=======================
具体要怎么计算 Tokens 数量,这个需要官方提供计算方式,或提供接口,或提供源码。
这里以 openAI 的 GPT 为例,介绍 Tokens 的计算方式。
openAI 官方提供了两种计算方式:网页计算、接口计算。
网页计算
网页计算顾名思义,就是打开网页输入文字,然后直接计算结果,网页的链接是:https://platform.openai.com/tokenizer。
曾经看到一个粗略的说法:1 个 Token 大约相当于 4 个英文字符或 0.75 个英文单词;而一个汉字则大约需要 1.5 个 Token 来表示。真实性未知,但从个人经验,一个汉字似乎没有达到 1.5 个 Token 这么多。
随意举三个例子:
【例子1】以下十个汉字计算得到的 Token 数是 14 个。
一二三四五六七八九十
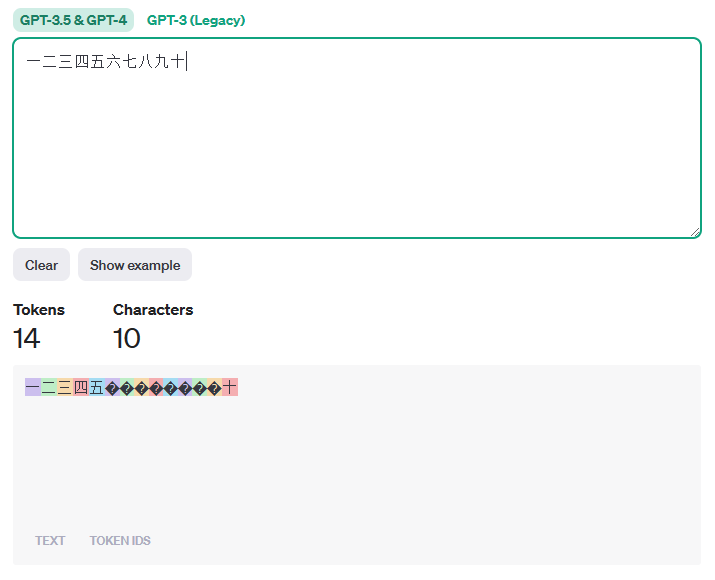
【例子2】以下 11 个汉字加2个标点计算得到的 Token 数是 13 个。
今天是十二月一日,星期五。
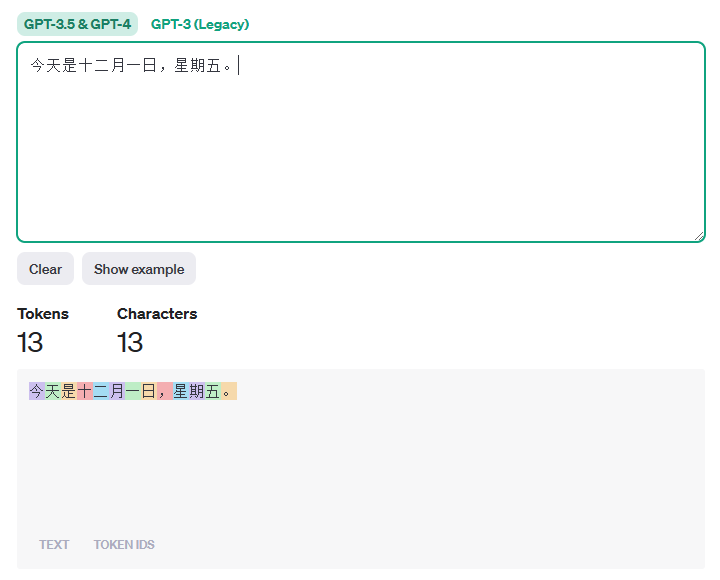
【例子3】以下 这段话计算得到的 Token 数是 236 个。
人工智能是智能学科重要的组成部分,它企图了解智能的实质,并生产出一种新的能以人类智能相似的方式做出反应的智能机器,该领域的研究包括机器人、语言识别、图像识别、自然语言处理和专家系统等。人工智能从诞生以来,理论和技术日益成熟,应用领域也不断扩大,可以设想,未来人工智能带来的科技产品,将会是人类智慧的“容器”。人工智能可以对人的意识、思维的信息过程的模拟。人工智能不是人的智能,但能像人那样思考、也可能超过人的智能。
接口计算
接下来看看怎么使用 Python 接口实现 Token 计算。
相关链接:https://github.com/openai/openai-cookbook/blob/main/examples/How_to_count_tokens_with_tiktoken.ipynb
从 Note 中可以了解到,要计算 Tokens 需要安装两个第三方包:tiktoken和openai。第一个包不需要 GPT 的 API Key 和 API Secret 便可使用,第二个需要有 GPT 的 API Key 和 API Secret 才能使用,由于某些限制,还需要海外代理。
不过,好消息是openai可以不用,使用tiktoken来计算即可。
先安装tiktoken包:
pip install tiktoken 注:我使用的是 Python 3.9,默认安装的tiktoken版本是 0.5.1。
安装好tiktoken之后,直接看最后两个 cell(In[14] 和 In[15])。
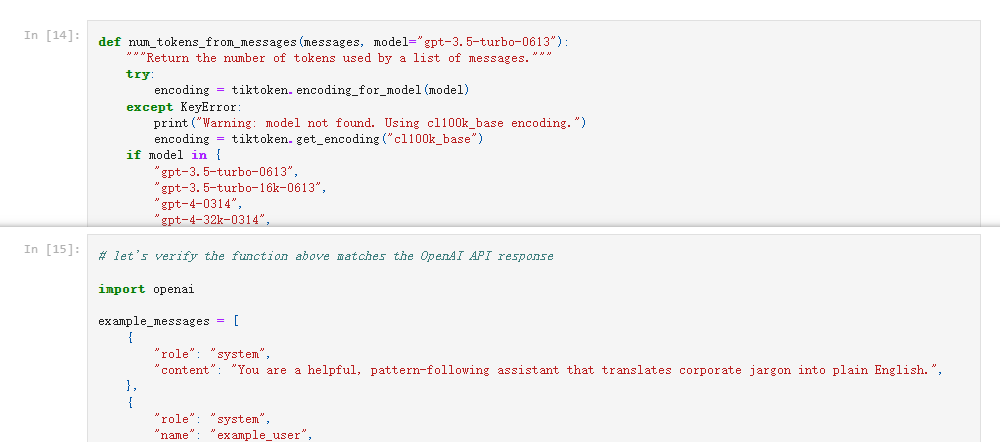
完整代码如下:
def num_tokens_from_messages(messages, model="gpt-3.5-turbo-0613"): """Return the number of tokens used by a list of messages.""" try: encoding = tiktoken.encoding_for_model(model) except KeyError: print("Warning: model not found. Using cl100k_base encoding.") encoding = tiktoken.get_encoding("cl100k_base") if model in { "gpt-3.5-turbo-0613", "gpt-3.5-turbo-16k-0613", "gpt-4-0314", "gpt-4-32k-0314", "gpt-4-0613", "gpt-4-32k-0613", }: tokens_per_message = 3 tokens_per_name = 1 elif model == "gpt-3.5-turbo-0301": tokens_per_message = 4 # every message follows <|start|>{role/name}\n{content}<|end|>\n tokens_per_name = -1 # if there's a name, the role is omitted elif "gpt-3.5-turbo" in model: print("Warning: gpt-3.5-turbo may update over time. Returning num tokens assuming gpt-3.5-turbo-0613.") return num_tokens_from_messages(messages, model="gpt-3.5-turbo-0613") elif "gpt-4" in model: print("Warning: gpt-4 may update over time. Returning num tokens assuming gpt-4-0613.") return num_tokens_from_messages(messages, model="gpt-4-0613") else: raise NotImplementedError( f"""num_tokens_from_messages() is not implemented for model {model}. See https://github.com/openai/openai-python/blob/main/chatml.md for information on how messages are converted to tokens.""" ) num_tokens = 0 for message in messages: num_tokens += tokens_per_message for key, value in message.items(): num_tokens += len(encoding.encode(value)) if key == "name": num_tokens += tokens_per_name num_tokens += 3 # every reply is primed with <|start|>assistant<|message|> return num_tokens
# let's verify the function above matches the OpenAI API response import openai example_messages = [ { "role": "system", "content": "You are a helpful, pattern-following assistant that translates corporate jargon into plain English.", }, { "role": "system", "name": "example_user", "content": "New synergies will help drive top-line growth.", }, { "role": "system", "name": "example_assistant", "content": "Things working well together will increase revenue.", }, { "role": "system", "name": "example_user", "content": "Let's circle back when we have more bandwidth to touch base on opportunities for increased leverage.", }, { "role": "system", "name": "example_assistant", "content": "Let's talk later when we're less busy about how to do better.", }, { "role": "user", "content": "This late pivot means we don't have time to boil the ocean for the client deliverable.", },
] for model in [ "gpt-3.5-turbo-0301", "gpt-3.5-turbo-0613", "gpt-3.5-turbo", "gpt-4-0314", "gpt-4-0613", "gpt-4", ]: print(model) # example token count from the function defined above print(f"{num_tokens_from_messages(example_messages, model)} prompt tokens counted by num_tokens_from_messages().") # example token count from the OpenAI API response = openai.ChatCompletion.create( model=model, messages=example_messages, temperature=0, max_tokens=1, # we're only counting input tokens here, so let's not waste tokens on the output ) print(f'{response["usage"]["prompt_tokens"]} prompt tokens counted by the OpenAI API.') print() 接下来处理一下以上代码,把 In[15] 中,和openai包相关的内容可以直接注释掉,然后执行代码。处理之后,可直接执行代码如下:
import tiktoken
def num_tokens_from_messages(messages, model="gpt-3.5-turbo-0613"): """Return the number of tokens used by a list of messages.""" try: encoding = tiktoken.encoding_for_model(model) except KeyError: print("Warning: model not found. Using cl100k_base encoding.") encoding = tiktoken.get_encoding("cl100k_base") if model in { "gpt-3.5-turbo-0613", "gpt-3.5-turbo-16k-0613", "gpt-4-0314", "gpt-4-32k-0314", "gpt-4-0613", "gpt-4-32k-0613", }: tokens_per_message = 3 tokens_per_name = 1 elif model == "gpt-3.5-turbo-0301": tokens_per_message = 4 # every message follows <|start|>{role/name}\n{content}<|end|>\n tokens_per_name = -1 # if there's a name, the role is omitted elif "gpt-3.5-turbo" in model: print("Warning: gpt-3.5-turbo may update over time. Returning num tokens assuming gpt-3.5-turbo-0613.") return num_tokens_from_messages(messages, model="gpt-3.5-turbo-0613") elif "gpt-4" in model: print("Warning: gpt-4 may update over time. Returning num tokens assuming gpt-4-0613.") return num_tokens_from_messages(messages, model="gpt-4-0613") else: raise NotImplementedError( f"""num_tokens_from_messages() is not implemented for model {model}. See https://github.com/openai/openai-python/blob/main/chatml.md for information on how messages are converted to tokens.""" ) num_tokens = 0 for message in messages: num_tokens += tokens_per_message for key, value in message.items(): num_tokens += len(encoding.encode(value)) if key == "name": num_tokens += tokens_per_name num_tokens += 3 # every reply is primed with <|start|>assistant<|message|> return num_tokens
# let's verify the function above matches the OpenAI API response example_messages = [ { "role": "system", "content": "You are a helpful, pattern-following assistant that translates corporate jargon into plain English.", }, { "role": "system", "name": "example_user", "content": "New synergies will help drive top-line growth.", }, { "role": "system", "name": "example_assistant", "content": "Things working well together will increase revenue.", }, { "role": "system", "name": "example_user", "content": "Let's circle back when we have more bandwidth to touch base on opportunities for increased leverage.", }, { "role": "system", "name": "example_assistant", "content": "Let's talk later when we're less busy about how to do better.", }, { "role": "user", "content": "This late pivot means we don't have time to boil the ocean for the client deliverable.", },
] for model in [ "gpt-3.5-turbo-0301", "gpt-3.5-turbo-0613", "gpt-3.5-turbo", "gpt-4-0314", "gpt-4-0613", "gpt-4", ]: print(model) # example token count from the function defined above print(f"{num_tokens_from_messages(example_messages, model)} prompt tokens counted by num_tokens_from_messages().") print() 运行结果如下图:
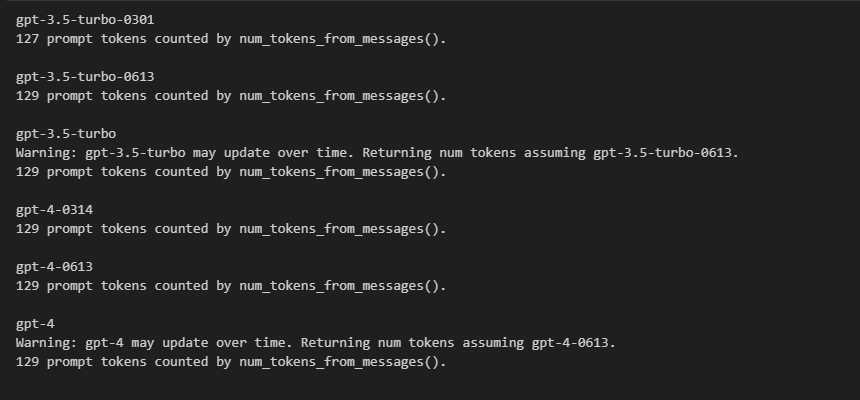
小解析:
-
example_messages变量是一个列表,列表的元素是字典,这个是 GPT 的数据结构,在这个示例代码中,整个列表作为 GPT 的 prompt 输入,所以计算的是整个的 Token 数。 -
不同的模型,对于 prompt 的计算规则有一点点不同,重点在于数据结构多出的字符。
问题1:实际生产中的数据,可能不是这样的,更多时候是存一个字符串,又该怎么处理?
demo 是从列表解析出键content的值,这个比较简单,如果是要从字符串中去解析相关的数据,则需要多加一步转化,使用json包将字符串转化为列表,然后其他的处理方式保持一致即可。
参考如下:
import tiktoken,json
def num_tokens_from_messages(messages, model="gpt-3.5-turbo-0613"): """Return the number of tokens used by a list of messages.""" try: encoding = tiktoken.encoding_for_model(model) except KeyError: print("Warning: model not found. Using cl100k_base encoding.") encoding = tiktoken.get_encoding("cl100k_base") if model in { "gpt-3.5-turbo-0613", "gpt-3.5-turbo-16k-0613", "gpt-4-0314", "gpt-4-32k-0314", "gpt-4-0613", "gpt-4-32k-0613", }: tokens_per_message = 3 tokens_per_name = 1 elif model == "gpt-3.5-turbo-0301": tokens_per_message = 4 # every message follows <|start|>{role/name}\n{content}<|end|>\n tokens_per_name = -1 # if there's a name, the role is omitted elif "gpt-3.5-turbo" in model: print("Warning: gpt-3.5-turbo may update over time. Returning num tokens assuming gpt-3.5-turbo-0613.") return num_tokens_from_messages(messages, model="gpt-3.5-turbo-0613") elif "gpt-4" in model: print("Warning: gpt-4 may update over time. Returning num tokens assuming gpt-4-0613.") return num_tokens_from_messages(messages, model="gpt-4-0613") else: raise NotImplementedError( f"""num_tokens_from_messages() is not implemented for model {model}. See https://github.com/openai/openai-python/blob/main/chatml.md for information on how messages are converted to tokens.""" ) # 结构转化,结构不完整则返回0 try: messages = json.loads(messages) num_tokens = 0 for message in messages: num_tokens += tokens_per_message for key, value in message.items(): num_tokens += len(encoding.encode(value)) if key == "name": num_tokens += tokens_per_name num_tokens += 3 # every reply is primed with <|start|>assistant<|message|> except json.JSONDecodeError: num_tokens = 0 return num_tokens
# let's verify the function above matches the OpenAI API response example_messages = [ { "role": "system", "content": "You are a helpful, pattern-following assistant that translates corporate jargon into plain English.", }, { "role": "system", "name": "example_user", "content": "New synergies will help drive top-line growth.", }, { "role": "system", "name": "example_assistant", "content": "Things working well together will increase revenue.", }, { "role": "system", "name": "example_user", "content": "Let's circle back when we have more bandwidth to touch base on opportunities for increased leverage.", }, { "role": "system", "name": "example_assistant", "content": "Let's talk later when we're less busy about how to do better.", }, { "role": "user", "content": "This late pivot means we don't have time to boil the ocean for the client deliverable.", },
]
example_messages = json.dumps(example_messages) # 假设使用的是 "gpt-4-0613" 模型
model = "gpt-4-0613"
print(f"{num_tokens_from_messages(example_messages, model)} prompt tokens counted by num_tokens_from_messages().")
问题2:在网页计算小节中使用的字符串跑出来的数据是否和tiktoken一样呢?
实现这个验证很简单,把上面的代码再做简化,直接计算字符串即可。参考逻辑如下:
import tiktoken def num_tokens_from_messages(messages, model="gpt-3.5-turbo-0613"): """Return the number of tokens used by a list of messages.""" try: encoding = tiktoken.encoding_for_model(model) except KeyError: print("Warning: model not found. Using cl100k_base encoding.") encoding = tiktoken.get_encoding("cl100k_base") num_tokens = len(encoding.encode(messages)) return num_tokens str1 = num_tokens_from_messages('一二三四五六七八九十')
str2 = num_tokens_from_messages('今天是十二月一日,星期五。')
str3 = num_tokens_from_messages('人工智能是智能学科重要的组成部分,它企图了解智能的实质,并生产出一种新的能以人类智能相似的方式做出反应的智能机器,该领域的研究包括机器人、语言识别、图像识别、自然语言处理和专家系统等。人工智能从诞生以来,理论和技术日益成熟,应用领域也不断扩大,可以设想,未来人工智能带来的科技产品,将会是人类智慧的“容器”。人工智能可以对人的意识、思维的信息过程的模拟。人工智能不是人的智能,但能像人那样思考、也可能超过人的智能。') print(f'字符串1长度{str1},字符串2长度{str2},字符串3长度{str3}。') 返回结果如下:
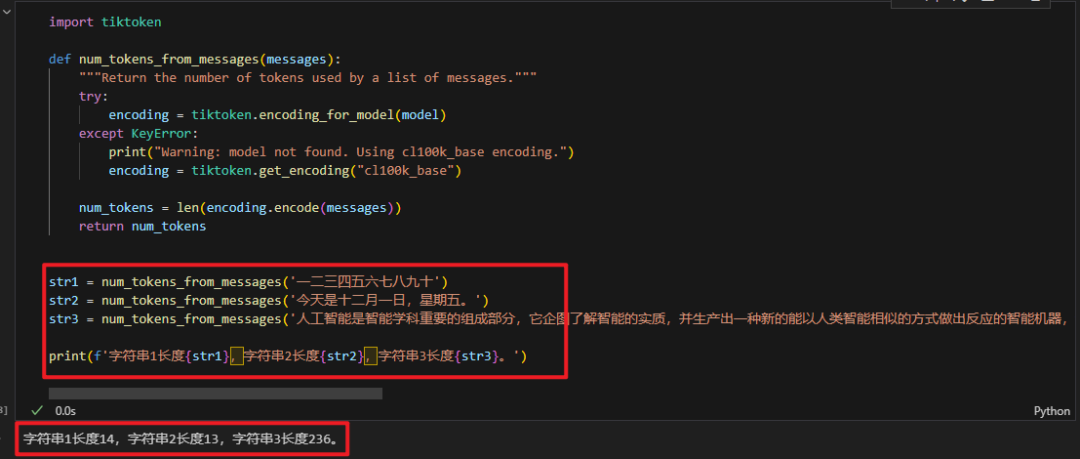
返回结果和网页计算的结果完全一致!
其实这个有点像是 GPT 给我们返回的文本数据,可以直接计算其长度,不需要像上面那么复杂,如果数据结构也是像上面一样,那就需要多加一步解析。
import tiktoken,json def num_tokens_from_messages(messages): """Return the number of tokens used by a list of messages.""" try: encoding = tiktoken.encoding_for_model(model) except KeyError: print("Warning: model not found. Using cl100k_base encoding.") encoding = tiktoken.get_encoding("cl100k_base") try: messages = json.loads(messages)[0]['content'] num_tokens = len(encoding.encode(messages)) except json.JSONDecodeError: num_tokens = 0 return num_tokens example_messages = '''[ { "role": "system", "content": "一二三四五六七八九十" }
]'''
print(num_tokens_from_messages(example_messages)) 小结
=========
本文主要介绍了 GPT 如何计算 Tokens 的方法,官方提供了两种方式:网页计算和接口计算。
网页计算不需要技术,只需要魔法即可体验,而接口计算,事实上接口计算包含了两种方法,一种使用tiktoken,则需要点 Python 基础,而openai还需要点网络基础和货币基础,需要代理和 plus 账号(20刀/月)等。
参考链接:
网页计算链接:https://platform.openai.com/tokenizer 接口使用链接:https://github.com/openai/openai-cookbook/blob/main/examples/How_to_count_tokens_with_tiktoken.ipynb
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。