进程生命周期揭秘:从启动到替换的完整过程
- 一. 进程创建
- 1.1 基本概念
- 1.2 创建新进程的方法
- 1.2.1 初识fork函数
- 1.2.2 fork函数返回值
- 1.2.3 写时拷⻉
- 1.2.4 fork调用失败原因
- 二. 进程终止
- 2.1 基本概念
- 2.2 进程退出场景
- 2.3 进程常见退出方法
- 2.3.1 退出码
- 2.3.2 _exit函数和exit函数区别
- 三. 进程等待
- 3.1 基本概念
- 3.2 为什么有进程等待
- 3.3 进程等待方法
- 3.3.1 wait系统调用
- 3.3.2 waitpid
- 3.3.3 获取子进程status
- 四. 进程程序替换
- 4.1 基本概念
- 4.2 替换原理
- 4.3 替换函数
- 4.3.1 execl()
- 4.3.2. execlp()
- 4.3.4. execv()
- 4.3.5. execvp()
- 4.3.6. execve()
- 4.3.7 总结:
- 5. 最后
本文将介绍进程的创建、终止、等待和程序替换四个关键过程,帮助读者深入理解操作系统如何管理进程生命周期。进程创建涉及操作系统如何为新进程分配资源并初始化环境,进程终止则描述了操作系统如何清理资源并回收内存。等待过程讲解了父子进程之间的同步机制,以及如何通过进程调度实现资源共享和任务协调。程序替换则涉及操作系统如何在内存不足时通过交换技术,确保多个进程得以高效运行。这些过程共同作用,保证了多任务环境中的进程安全与高效运行,为操作系统的核心功能提供了支持。
💬 欢迎讨论:如果你在学习过程中有任何问题或想法,欢迎在评论区留言,我们一起交流学习。你的支持是我继续创作的动力!
👍 点赞、收藏与分享:觉得这篇文章对你有帮助吗?别忘了点赞、收藏并分享给更多的小伙伴哦!你们的支持是我不断进步的动力!
🚀 分享给更多人:如果你觉得这篇文章对你有帮助,欢迎分享给更多对Linux OS感兴趣的朋友,让我们一起进步!
一. 进程创建
1.1 基本概念
进程创建是操作系统中启动一个新进程的过程。通常,进程创建由现有进程发起,称为父进程。创建新进程时,操作系统会分配资源(如内存、文件句柄等),并初始化进程控制块(PCB)。父进程通过调用系统调用(如UNIX中的fork()或Windows中的CreateProcess())来创建子进程。子进程通常会继承父进程的一些资源和属性,但也可以根据需要进行修改。进程创建后,子进程会与父进程并行执行,可能有自己的执行路径,也可能通过exec()等系统调用加载新程序。
1.2 创建新进程的方法
1.2.1 初识fork函数
fork()函数用于创建一个新的子进程,子进程是父进程的副本,拥有独立的进程ID。返回值区分父进程(返回子进程ID)和子进程(返回0)。
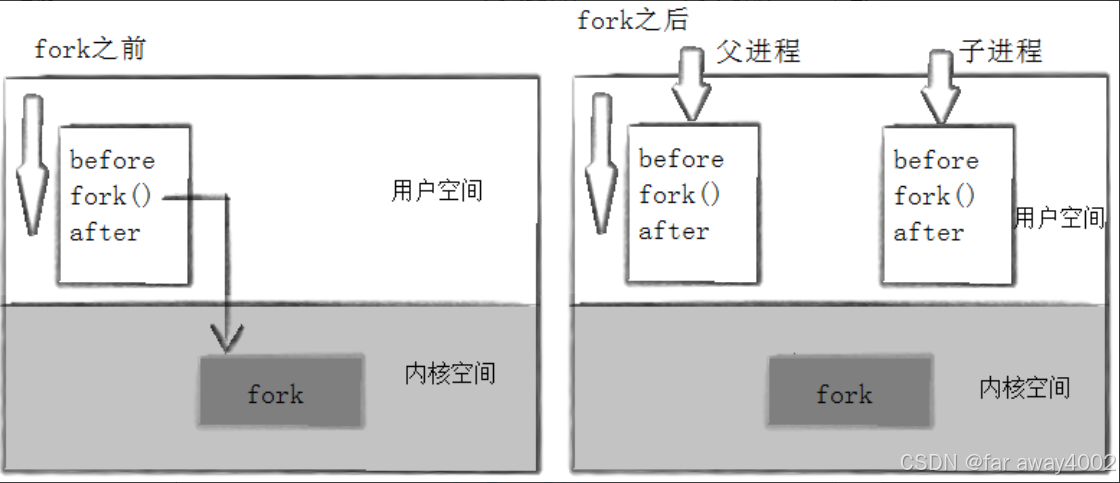
进程调用fork后,当控制转移到内核中的fork代码后,内核做:
- 分配新的内存块和内核数据结构给⼦进程
- 将⽗进程部分数据结构内容拷⻉⾄⼦进程
- 添加⼦进程到系统进程列表当中
- fork返回,开始调度器调度
fork之前⽗进程独⽴执⾏,fork之后,⽗⼦两个执⾏流分别执⾏。注意,fork之后,谁先执⾏完全由调度器决定。
1.2.2 fork函数返回值
- ⼦进程返回0
- ⽗进程返回的是⼦进程的pid。
1.2.3 写时拷⻉
通常,⽗⼦代码共享,⽗⼦再不写⼊时,数据也是共享的,当任意⼀⽅试图写⼊,便以写时拷⻉的⽅式各⾃⼀份副本(让权限出错,不一致)。具体⻅下图:
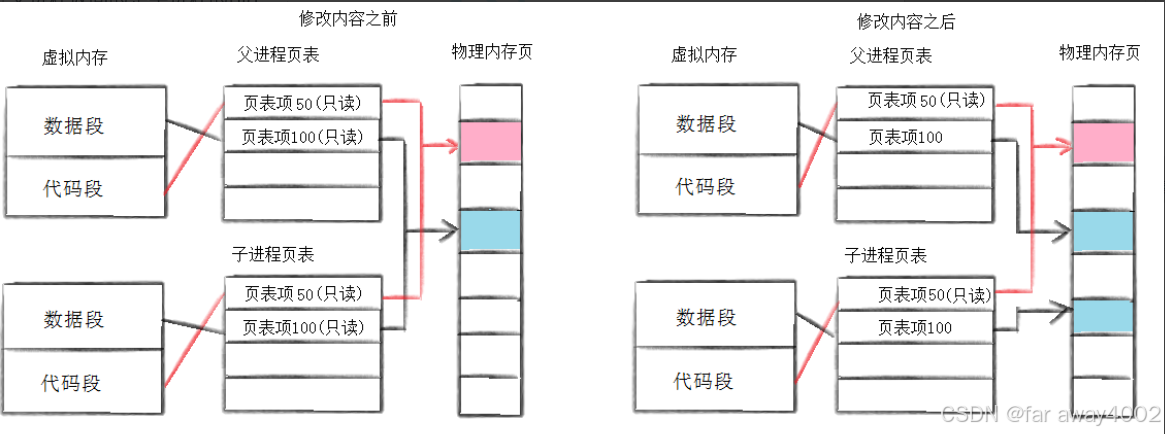
- 因为有写时拷⻉技术的存在,所以⽗⼦进程得以彻底分离离!完成了进程独⽴性的技术保证!
- 写时拷⻉,是⼀种延时申请技术,可以提⾼整机内存的使⽤率
1.2.4 fork调用失败原因
- 系统资源不足:系统可能没有足够的内存或进程表项来创建新的进程。每个进程都需要一定的内存和操作系统资源。如果系统资源有限,fork()会失败。
- 进程数限制:操作系统对每个用户或系统中可创建的最大进程数有一个限制。如果达到该限制,fork()会返回失败。
- 权限不足:如果调用进程没有足够的权限(例如,普通用户没有权限创建新进程),fork()可能会失败。
地址空间限制:在某些系统中,fork()会复制父进程的内存空间(例如,使用写时复制机制),如果内存地址空间过大或不允许复制,fork()可能会失败。
- 内核限制:操作系统的内核可能有某些限制,特别是对于系统进程和守护进程。内核可能会限制某些类型进程的创建。
- 文件描述符限制:每个进程可以打开的文件描述符是有限的。如果打开的文件描述符数超过了限制,fork()可能会失败。
- 调用参数错误:fork()函数本身没有太多参数错误的情况,但调用环境不正确或程序存在其他逻辑错误也可能导致fork()失败。
二. 进程终止
2.1 基本概念
进程终止是指一个进程的执行结束,操作系统回收该进程所占用的资源并从进程表中移除。进程终止通常有两种方式:正常终止和异常终止。正常终止发生在进程完成其预定任务后,通常通过调用exit()系统调用或返回main()函数完成。异常终止则发生在进程出现错误时,如访问非法内存、除零错误等,通常由操作系统或运行时环境通过发送信号来处理,如SIGSEGV信号(段错误)。进程在终止时,会将退出状态码返回给父进程,父进程可以通过wait()或waitpid()等系统调用获取子进程的退出状态,并处理相关的清理工作。进程的终止不仅意味着其自身的消失,还会触发资源的释放,包括文件句柄、内存、CPU时间等,保证操作系统的资源得到有效管理。进程终止后,系统会在进程表中留下一个“僵尸”状态,等待父进程回收。
2.2 进程退出场景
- 代码运⾏完毕,结果正确
- 代码运⾏完毕,结果不正确
- 代码异常终⽌
2.3 进程常见退出方法
正常终⽌(可以通过 echo $? 查看进程退出码):打印最近一次程序的退出状态。
- 正常退出:进程通过调用exit()函数来正常退出,操作系统会回收该进程的资源并从进程表中移除。exit()可以传递一个退出状态码,供父进程通过wait()获取。
- 返回main()函数:对于从main()函数启动的进程,执行完main()函数后会自动退出,操作系统会回收资源。
- 调用_exit():_exit()是一个系统调用,类似于exit(),但它不会调用标准库的清理工作(如文件流的刷新)。通常用于在子进程中调用,以避免父进程的标准库清理操作影响。
- 父进程终止:如果父进程调用exit()或发生崩溃,子进程会被标记为孤儿进程,由系统的init进程收养并终止。
异常退出:退出码无意义
- 异常退出:进程在执行过程中遇到未捕获的错误(如段错误、除零错误等)时会异常终止,操作系统会发出信号(如SIGSEGV),导致进程退出。
- 调用abort():abort()函数用于立即终止进程,且不进行任何清理工作,进程的退出状态通常是异常终止。
- 接收到终止信号:操作系统通过发送特定信号(如SIGTERM或SIGKILL)请求进程退出,进程收到信号后执行相应的退出操作。
2.3.1 退出码
退出码(Exit Code),也称为返回值或退出状态码,是一个整数值,用于表示进程的执行结果。操作系统通过退出码来判断进程是否成功执行以及执行过程中的错误类型。
常见的退出码定义如下:

- 0:表示进程正常退出,即没有发生任何错误。成功执行是进程退出时常用的退出码。
- 非零值:表示进程异常退出,具体值用于指示不同的错误类型。常见的非零退出码有:
1:一般性错误,表示发生了某些问题,但未明确具体类型。
2:命令行使用错误或错误的参数传递。
127:命令未找到,通常在尝试执行一个不存在的命令时返回。
128:无效的命令退出,通常是由信号引起的异常退出。
130:通常由Ctrl+C(SIGINT信号)终止的进程。
137:表示进程由于接收到SIGKILL信号被强制终止。
- 信号退出码:如果进程是由于接收到信号终止的,退出码会以128加上信号编号的方式表示。例如,进程因SIGSEGV(段错误)退出时,退出码可能是139(128+ 11,11是SIGSEGV信号的编号)。
- 自定义退出码:用户可以根据程序的实际需求定义不同的退出码,用来表示具体的错误或状态,特别是在脚本和应用程序中。
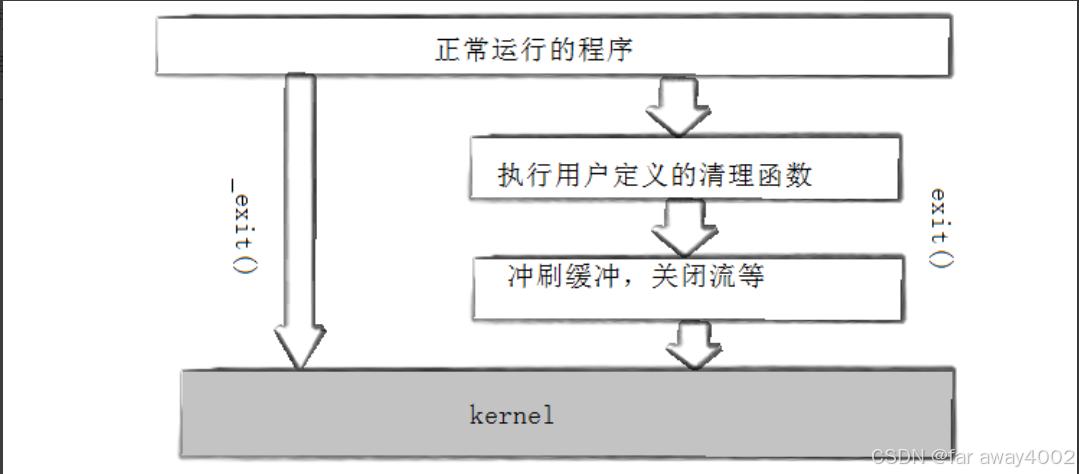
2.3.2 _exit函数和exit函数区别
void exit(int status); void _exit(int status);
- exit():exit()是标准库函数,会做一些清理工作。
在调用exit()时,标准库会执行以下操作:
- 调用所有注册的atexit()函数(如果有的话)。
- 刷新所有打开的输出流(如标准输出、文件流等),确保未写入的数据被保存。
- 关闭所有打开的文件描述符。
- 执行其他标准库的清理任务。
- exit()通常用于正常退出进程,并执行进程的资源清理。
_exit():_exit()是一个系统调用,它不会执行标准库的清理工作。
- 当调用_exit()时,它直接终止进程,立即回收资源并退出,不会刷新输出缓冲区,也不会调用atexit()函数。
- _exit()通常用于子进程的退出,特别是在fork()后,因为在子进程中执行exit()可能会影响父进程的资源清理工作。
总结:
- exit()用于正常退出进程,进行标准库清理操作。
- _exit()用于立即退出进程,不执行任何标准库的清理,适用于子进程或者需要立即退出的情况。
示例代码:
int main()
{
printf("hello");
exit(0);
}
运⾏结果:
[root@localhost linux]# ./a.out
hello[root@localhost linux]#
int main()
{
printf("hello");
_exit(0);
}
运⾏结果:
[root@localhost linux]# ./a.out
[root@localhost linux]#
三. 进程等待
3.1 基本概念
进程等待是指一个进程在执行过程中暂停,等待另一个进程完成某些任务或条件。通常,父进程会等待子进程的终止,以回收子进程的资源。进程等待是进程间同步的一部分,确保进程的协调和资源的有效管理。在操作系统中,父进程通过调用wait()或waitpid()等系统调用,阻塞自己,直到子进程终止,并获取子进程的退出状态。进程等待有助于防止“僵尸进程”的产生,因为父进程会获取子进程的退出信息并回收资源。如果父进程不调用wait(),子进程会处于“僵尸”状态,操作系统仍会为其保留资源,直到父进程处理它。进程等待也常用于处理同步问题,例如多个进程需要按顺序完成任务。
3.2 为什么有进程等待
进程等待的主要原因是确保进程间的协调和资源管理。当一个进程创建子进程后,父进程需要等待子进程完成任务,以回收子进程的资源,避免产生僵尸进程。如果父进程不等待,子进程的退出信息无法被回收,导致系统资源浪费。此外,进程等待用于进程间同步,确保任务按照特定顺序执行,避免数据竞争或不一致。例如,一个进程可能需要等待另一个进程的结果或某些条件满足才能继续执行。进程等待还能避免多进程环境中因过度并发而导致的资源冲突,提高系统稳定性和效率。
3.3 进程等待方法
3.3.1 wait系统调用
pid_t wait(int* status);
返回值:
- 成功返回被等待进程pid,失败返回-1。
参数:
- 输出型参数,获取⼦进程退出状态,不关⼼则可以设置成为NULL
3.3.2 waitpid
pid_ t waitpid(pid_t pid, int *status, int options);
waitpid 是一种系统调用,主要用于在父进程中等待子进程的状态改变。在 Unix/Linux 系统中,当一个子进程结束时,父进程需要知道它的终止状态,以便可以进行相应的处理(比如回收资源)。waitpid 提供了一种机制,允许父进程等待一个特定的子进程,或者等待任意一个子进程的退出,并返回该子进程的状态信息。
参数说明:
pid:指定要等待的子进程的进程ID。具体值的意义如下:
- pid > 0:等待进程ID为 pid 的子进程。
- pid == 0:等待与当前进程属于同一个进程组的任意子进程。
- pid == -1:等待任意子进程的状态变化。
- pid < -1:等待进程ID为进程组ID的子进程。
status:用于保存子进程的退出状态。如果传入 NULL,则不获取状态信息。
- 退出状态包含的信息可以通过宏WIFEXITED(status)(判断进程是否正常退出)、WEXITSTATUS(status)(获取进程的退出状态码)等来解析。
options:控制 waitpid 行为的选项。常用选项有:
- WNOHANG:如果没有子进程退出,waitpid 不会阻塞,直接返回。
- WUNTRACED:当子进程暂停(例如由于接收到信号)时,waitpid 也会返回。
返回值:
- 如果成功,返回退出的子进程的进程ID。
- 如果没有子进程可等待,返回 0。
- 如果出现错误,返回 -1,并设置 errno 以指示错误。
3.3.3 获取子进程status
说明:该参数是一个输出型参数,由操作系统填充。如果传递NULL,表⽰不关⼼⼦进程的退出状态信息;否则,操作系统会根据该参数,将⼦进程的退出信息反馈给⽗进程。
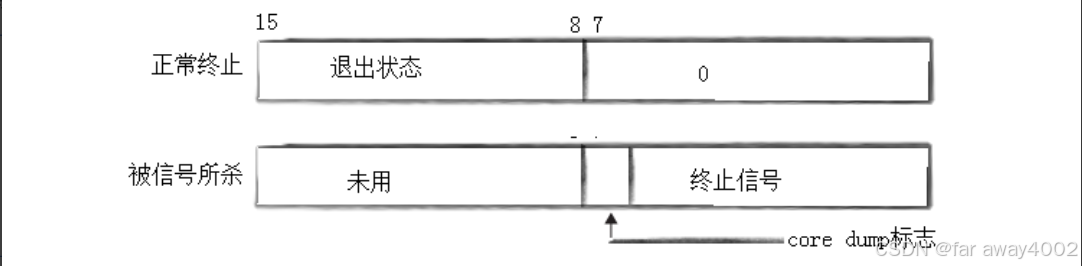
- 正常退出时,低七个比特位被设置为0。如exit(1),表明程序正常退出,要获取退出码要status>>8&&0xFF。
- 异常退出时,退出码无意义,一般是接受的信号了。
补充:非阻塞调用可以让自己在等待的同时,做其他的事情,二阻塞等调用必须等到阻塞成功完成。
示例代码(非阻塞式调用):
#include <stdio.h>
#include <stdlib.h>
#include <sys/wait.h>
#include <unistd.h>
#include <vector>
typedef void (*handler_t)(); // 函数指针类型
std::vector<handler_t> handlers; // 函数指针数组
void fun_one() {
printf("这是⼀个临时任务1\n");
}
void fun_two() {
printf("这是⼀个临时任务2\n");
}
void Load() {
handlers.push_back(fun_one);
handlers.push_back(fun_two);}
void handler() {
if (handlers.empty())
Load();
for (auto iter : handlers)
iter();
}
int main() {
pid_t pid;
pid = fork();
if (pid < 0) {
printf("%s fork error\n", __FUNCTION__);
return 1;
} else if (pid == 0) { // child
printf("child is run, pid is : %d\n", getpid());
sleep(5);
exit(1);
} else {
int status = 0;
pid_t ret = 0;
do {
ret = waitpid(-1, &status, WNOHANG); // ⾮阻塞式等待
if (ret == 0) {
printf("child is running\n");
}
handler();
} while (ret == 0);
if (WIFEXITED(status) && ret == pid) {
printf("wait child 5s success, child return code is :%d.\n",
WEXITSTATUS(status));
} else {
printf("wait child failed, return.\n");
return 1;
}
}
return 0;
}
四. 进程程序替换
4.1 基本概念
进程程序替换(Process Image Replacement)是指在一个进程中用新的程序替换当前正在运行的程序的过程。也就是说,当前进程会通过某种方式加载和执行一个新的程序,这个过程不需要创建新的进程,而是直接替换当前进程的执行内容。
4.2 替换原理
进程替换原理是指在操作系统中,当前进程的程序被替换成另一个程序的过程。这个过程并不需要创建新的进程,而是直接将当前进程的执行映像(包括内存、堆栈、代码段等)替换为新的程序。这样,当前进程的标识符(PID)保持不变,但程序的执行内容完全被新的程序替换。
注意:不会创建新进程,只是将页表中的映射的数据与代码段进行替换。
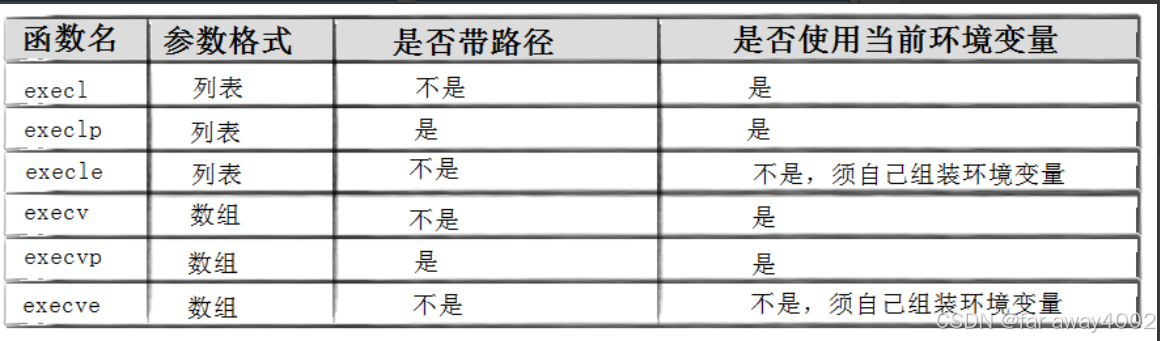
4.3 替换函数
#include <unistd.h>
int execl(const char *path, const char *arg, …);
int execlp(const char *file, const char *arg, …);
int execle(const char *path, const char *arg, …,char *const envp[]);
int execv(const char *path, char *const argv[]);
int execvp(const char *file, char *const argv[]);
int execve(const char *path, char *const argv[], char *const envp[]);
上述函数特点:
- 如果 exec() 调用成功,当前进程会 立即开始执行新程序,并且从新程序的入口点开始执行。
- 如果 exec() 调用失败(例如路径错误、权限问题或文件不存在),会返回 -1,并设置 errno 来指示错误原因(如
ENOENT、EACCES 等),没有成功的返回值。
示例代码:
#include <unistd.h>
int main()
{
char *const argv[] = {"ps", "-ef", NULL};
char *const envp[] = {"PATH=/bin:/usr/bin", "TERM=console", NULL};
execl("/bin/ps", "ps", "-ef", NULL);
// 带p的,可以使⽤环境变量PATH,⽆需写全路径
execlp("ps", "ps", "-ef", NULL);
// 带e的,需要⾃⼰组装环境变量
execle("ps", "ps", "-ef", NULL, envp);
execv("/bin/ps", argv);
// 带p的,可以使⽤环境变量PATH,⽆需写全路径
execvp("ps", argv);
// 带e的,需要⾃⼰组装环境变量
execve("/bin/ps", argv, envp);
exit(0);
}
总结:
带p的,不需要指明路径。因为它会自动在环境变量PATH中查找指定的命令。
带v的,需要提供命令行参数表,其实本质是一个指针数组。
带envp的,如果传了,则从父进程继承的环境变量会被覆盖,不传则使用默认的。
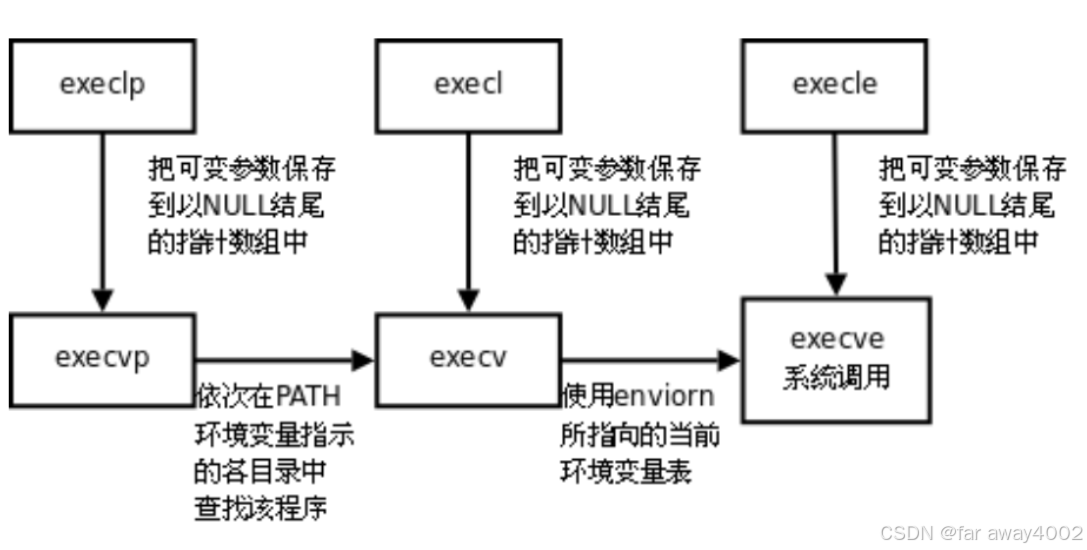
注意:其它的exce都封装了execve函数,所以execev系统调用通过 man 2 execve查看使用信息,其它的使用man 3 [函数];
下面具体介绍函数功能。
4.3.1 execl()
int execl(const char *path, const char *arg, …);
功能:execl() 用于执行指定路径的程序,并传递给新程序一系列命令行参数(以空指针 NULL 作为参数的结尾标识)。
参数:
- path:要执行的程序的路径。
- arg:传递给新程序的第一个参数(通常是程序名称),后续参数依次传递给新程序。
- 后续参数(…):一系列参数,直到 NULL 为止,用于传递给新程序的命令行参数。
示例:
execl(“/bin/ls”, “ls”, “-l”, NULL);
上面的例子执行 /bin/ls 命令,传递了 “ls” 作为程序名,“-l” 作为命令行参数。
4.3.2. execlp()
int execlp(const char *file, const char *arg, …);
功能:execlp() 与 execl() 的不同之处在于,execlp() 会使用环境变量 PATH 来查找指定的程序。也就是说,它不需要给出程序的完整路径,只需给出程序名。
参数:
- file:要执行的程序名,可以是相对路径或文件名,execlp() 会通过 PATH 环境变量来查找该程序。
- arg:传递给新程序的第一个参数,通常是程序名称。
- 后续参数(…):一系列参数,直到 NULL 为止。
示例:
execlp(“ls”, “ls”, “-l”, NULL);
上面的例子执行 ls 命令,execlp 会自动通过 PATH 查找 ls 命令的路径。
- execle()
int execle(const char *path, const char *arg, …, char *const
envp[]);
功能:execle() 与 execl() 类似,不同之处在于它允许你传递一个自定义的环境变量数组 envp[],用来替换当前进程的环境变量。
参数:
- path:要执行的程序的路径。
- arg:传递给新程序的第一个参数,通常是程序名。
- 后续参数(…):一系列参数,直到 NULL 为止。
- envp[]:一个指向环境变量数组的指针,替代当前进程的环境变量。如果不需要更改环境变量,可以传递 NULL。
示例:
char *new_env[] = { “USER=guest”, “PATH=/usr/bin”, NULL };
execle(“/bin/ls”, “ls”, “-l”, NULL, new_env);
上面的例子执行 /bin/ls 命令,传递了 “ls” 和 “-l” 作为命令行参数,并且替换了当前进程的环境变量。
4.3.4. execv()
int execv(const char *path, char *const argv[]);
功能:execv() 用于执行指定路径的程序,并通过 argv[] 数组传递命令行参数。
参数:
- path:要执行的程序的路径。
- argv[]:一个指向参数数组的指针,数组的第一个元素是程序的名称,后续元素是传递给新程序的命令行参数。数组必须以 NULL 结尾。
示例:
char *args[] = { “ls”, “-l”, NULL }; execv(“/bin/ls”, args);
上面的例子执行 /bin/ls 命令,传递了 “ls” 和 “-l” 作为命令行参数。
4.3.5. execvp()
int execvp(const char *file, char *const argv[]);
功能:execvp() 与 execv() 类似,不同之处在于,execvp() 会通过环境变量 PATH 查找程序的位置,因此不需要提供完整的路径。
参数:
- file:要执行的程序名,可以是相对路径或文件名,execvp() 会通过 PATH 环境变量查找该程序。
- argv[]:一个指向参数数组的指针,数组的第一个元素是程序的名称,后续元素是传递给新程序的命令行参数,数组必须以 NULL 结尾。
示例:
- char *args[] = { “ls”, “-l”, NULL }; execvp(“ls”, args);
上面的例子执行 ls 命令,execvp() 会自动通过 PATH 查找 ls 命令的路径。
4.3.6. execve()
int execve(const char *path, char *const argv[], char *const envp[]);
功能:execve() 是 execv() 系列的底层版本,允许指定程序的路径、参数和环境变量。它是最强大的 exec() 系列函数,execve() 允许完全控制新的程序执行时的环境。
参数:
- path:要执行的程序的路径。
- argv[]:一个指向参数数组的指针,数组的第一个元素是程序的名称,后续元素是传递给新程序的命令行参数,数组必须以 NULL 结尾。
- envp[]:一个指向环境变量数组的指针,替代当前进程的环境变量。如果不需要更改环境变量,可以传递 NULL。
示例:
char *args[] = { “ls”, “-l”, NULL }; char *env[] = { “PATH=/bin”,
“USER=guest”, NULL }; execve(“/bin/ls”, args, env);
上面的例子执行 /bin/ls 命令,传递了 “ls” 和 “-l” 作为命令行参数,并且替换了当前进程的环境变量。
4.3.7 总结:
这些 exec() 系列函数都用于替换当前进程的程序,具体的区别在于:
- execl、execlp:通过一个个的参数传递给新程序,参数列表以 NULL 结尾。
- execle:类似于 execl,但允许传递自定义的环境变量。
- execv、execvp:通过参数数组(argv[])传递给新程序,适用于参数较多或动态生成的场景。
- execve:最底层的 exec 调用,允许完全控制程序路径、参数和环境变量。
5. 最后
进程生命周期总结:
进程的创建、终止、等待以及程序替换是操作系统多任务管理的基础。通过合理的进程调度和资源管理,操作系统确保多个进程能够并发执行并高效地共享资源。了解这些过程有助于掌握操作系统内部机制,从而优化程序设计和性能。希望这篇文章帮助你更好地理解进程生命周期的每个阶段。如果有其他相关问题,欢迎随时讨论!
路虽远,行则将至;事虽难,做则必成
亲爱的读者们,下一篇文章再会!!! \color{Red}亲爱的读者们,下一篇文章再会!!! 亲爱的读者们,下一篇文章再会!!!