2022.DKE.Anomaly explanation: A review
- paper
- explanation by feature importance[most used]
- main idea
- Non-weighted feature importance(methods do not quantify the importance of each feature)
- weighted feature importance
- explanation by feature values
- main idea
- explanation by data points comparison
- main idea
- explanation by structure analysis
- main idea
paper
explanation by feature importance[most used]
main idea
to explain that anomaly to the user, we can just say that attribute f1 contributed to the abnormality of the square data point.

The output of these techniques can be a list of features (ordered or not)possibly with a weight indicating the importance of the feature, a pair of features or a list of feature pairs, or a plot displaying how the outlier is separated from the others in a features subspace.
Non-weighted feature importance(methods do not quantify the importance of each feature)
1999.VLDB.Finding intensional knowledge of distance-based outliers
- define the outlier categories C = {“trivial outlier,” “weak outlier,” “strongest outlier”} to help gain better insights about the nature of outliers.
2013.ICDM.Explaining outliers by subspace separability
- explain a given anomaly by identifying the subspace of features that best separates that outlier from the rest of the dataset.
2009.PAKDD.Outlier detection in axis-parallel subspaces of high dimensional data(SOD)
- identify outliers in subspaces of the original feature space
2012.ICDM.Outlier detection in arbitrarily oriented subspaces(COP)
- identify outliers in subspaces of a transformation of the original feature space
2019.ECML PKDD.Beyond outlier detection: lookout for pictorial explanation[pdf,code]
- use a set of focus-plots, each of which “blames” or “explains away” a subset of the input outliers.(for all the outliers)
2020.ICDM.LP-Explain: Local Pictorial Explanation for Outliers[pdf]
- identify the set of best Local Pictorial explanations (defined as the scatter plots in the 2-D space of the feature pairs) that can Explain the behavior for cluster of outliers.(different from lookout in for clusters of outliers)
2018.WACV.Anomaly explanation using metadata[pdf]
- use tags help to explain what causes the identified anomalies, and also to identify the truly unusual examples that defy such simple categorization
2019.TKDD.Sequential feature explanations for anomaly detection[pdf]
- use a sequence of features, which are presented to the analyst one at a time (in order) until the information contained in the highlighted features is enough for the analyst to make a confident judgement about the anomaly.
weighted feature importance
2013.ECML PKDD.Local Outlier Detection with Interpretation[pdf]
- explores the quadratic entropy to adaptively select a set of neighboring instances, and seek an optimal subspace in which an outlier is maximally separated from its neighbors.
2014.ICDE.Discriminative features for identifying and interpreting outliers[pdf]
- uncovers outliers in subspaces of reduced dimensionality in which they are well discriminated from regular objects while at the same time retaining the natural local structure of the original data to ensure the quality of outlier explanation.
2019.arxiv.Explaining anomalies detected by autoencoders using SHAP[pdf]
- uses kernel SHAP to explain anomalies detected by an autoencoder. aims to provide a comprehensive explanation to the experts by focusing on the connection between the features with high reconstruction error and the features that are most important in affecting the reconstruction error.
2019.CIKM.Additive explanations for anomalies detected from multivariate temporal data[pdf]
- produce similar explanations to time series anomalies using an extension of Kernel SHAP, the anomalies having been identified by a GRU-AutoEncoder.
2019.idcmw.Shapley values of reconstruction errors of pca for explaining anomaly detection[pdf]
- uses SHAP to explain anomalies detected by an PCA
2004.arxiv.On anomaly interpretation via shapley values
- uses SHAP to explain anomalies detected by any semi-supervised anomaly detector.
2007.arxiv.Interpretable anomaly detection with diffi: Depth-based feature importance for the isolation forest [local&global, model-specific]
- DIFFI processes each tree separately to assign feature importance scores to each feature for a specific tree and then aggregates the scores to compute the feature importance scores for the whole forest. also provides local feature importance scores which help identify the features that contributed the most to detecting a specific anomaly.
2019.CNS.A gradient-based explainable variational autoencoder for network anomaly detection [local, model-specific]
- extract the gradients of the features from a trained Variational AutoEncoder to explain why a data point is anomalous
2020.PR.Towards explaining anomalies:a deep taylor decomposition of one-class models[ local, model-specific]
- rewrite One-Class SVMs models to be used for anomaly detection. a Layer-wise Relevance Propagation (LRP) with a Deep Taylor Decomposition is used to obtain the most important features for identifying the outliers
2018.HSI.Toward explainable deep neural network based anomaly detection
2018.MLCS.Recurrent neural network attention mechanisms for interpretable system log anomaly detection
- attention mechanism is used with LSTM to detect anomalies in system logs. An analysis of the attention weights is performed afterwards in order to identify the most important features for anomaly detection globally.
2019.IEEE International Conference on Big Data.Ace–an anomaly contribution explainer for cyber-security applications
- explains the prediction of an anomaly detection algorithm by feature importance. To compute the contribution of each feature to the anomaly score of an instance, ACE builds a local linear model around the instance using its neighbors and their anomaly scores as computed by the anomaly detection algorithm.close to LIME.
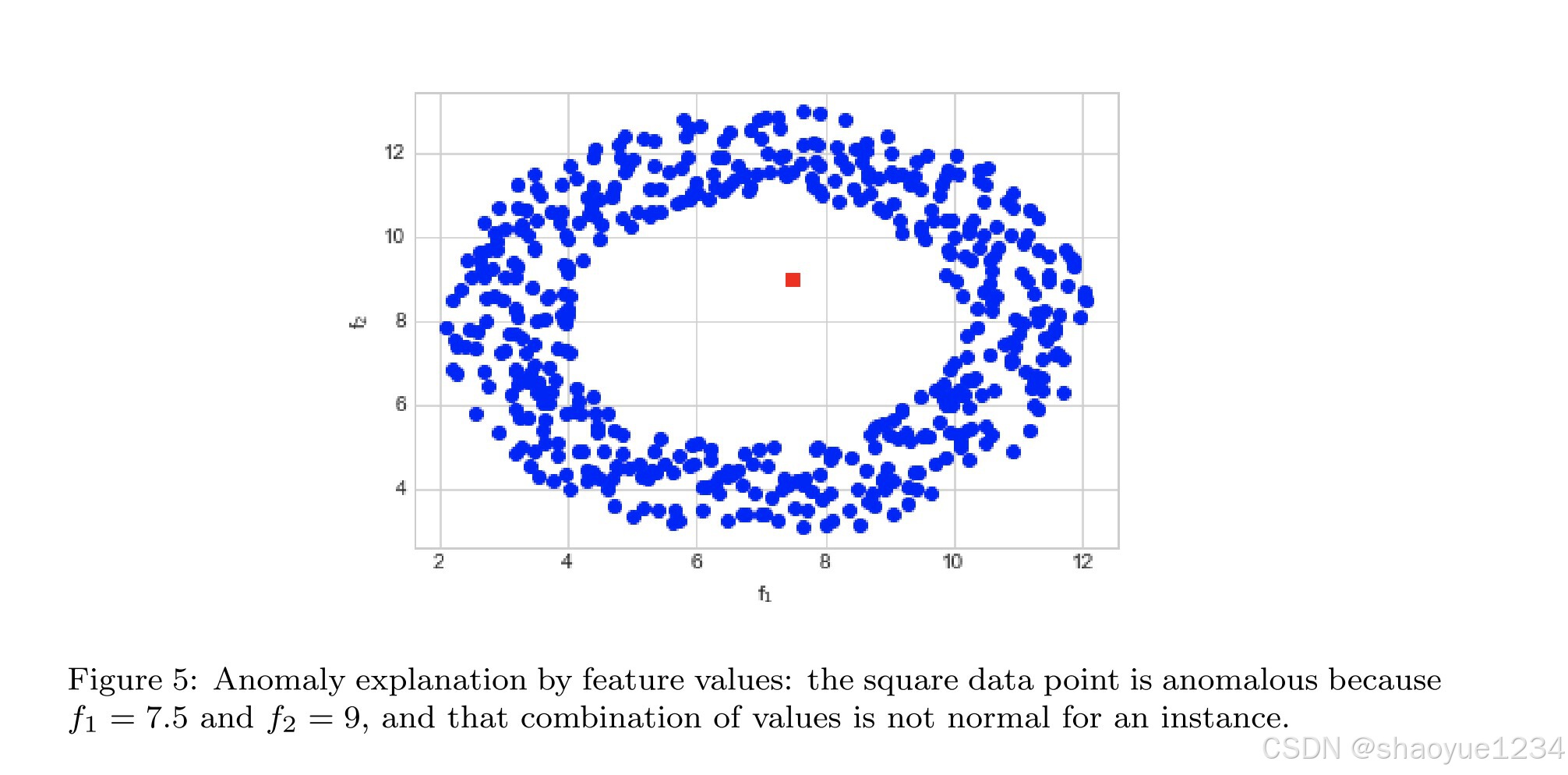
explanation by feature values
main idea
output of this kind of explanations is typically a set of rules
2016.SIGKDD.Interpretable anomaly detection for monitoring of high performance computing systems
- use a random forest to identify anomalies in HPC systems.The algorithm identifies the trees which classified the data point as anomalous; then going from the leaves to the root of each tree, it finds the conditions which helped to flag the data point as anomalous. The conditions regarding the same feature are consolidated afterwards, in order to have the fewest possible number of predicates. Those conditions are then displayed to a human analyst who identifies the most relevant ones and can throw out the least interesting in order to prune the decision trees, so that only relevant anomalies could be identified later.
2022.arxiv.Rule extraction in unsupervised anomaly detection for model explainability [model-agnostic]
- using One-Class SVMs to detect outliers, the space containing the inliers is divided into hyper-cubes recursively using a clustering algorithm(k-means++ in this case) until there is no outlier in any hyper-cube; then rules are extracted from the boundaries of each hyper-cube. Example:

2018.ICDMW.Exad: A system for explainable anomaly detection on big data traces
- perform anomaly detection using a LSTM neural network. They then approximate the neural network by a decision tree in order to retrieve the explanations.
2020.ESWA.Anomaly explanation with random forests[model-agnostic]
- each outlier is explained by exploiting a random forest composed of decision trees built using that outlier and a subset of regular instances. The authors propose two explanation methods: minimal explanation in which only one tree is used to extract the rules and maximal explanation in which a set of trees is used. Each decision tree aims at separating the outlier from the regular instances. Decision rules are extracted from each tree of the forest to explain the abnormality of the data point in the form of a conjunction of predicates. For the maximal explanation,the rules for all the trees concerning the outlier are aggregated to obtain one compact DNF. To provide global explanations, the detected anomalies are clustered, then the trees for all the anomalies of a specific cluster are aggregated into one forest and explanations are extracted.
2021.8th ACM IKDD CODS and 26th COMAD.Reliable counterfactual explanations for autoencoder based anomalies
- generate counterfactuals with an autoencoder-based anomaly detection.
2019.ICANN.Tsxplain: Demystification of dnn decisions for time-series using natural language and statistical features
- authors identify anomalies in time series data using a neural network: anomaly detection is performed in a supervised manner and, when a time series is classified as anomalous, the parts of the time series that contributed to the anomaly are identified; then, these parts are checked against some predefined rules. Those parts are finally compared to some statistics about the time series and textual explanations are generated with the information retrieved (statistical features comparison + rules checking).
explanation by data points comparison
main idea
what is the difference between anomalies and regular data points.
outputs of anomaly explanation by data points comparisons methods are the closest or the set of closest instances (irregular or not) of an anomaly, possibly with the differences (visual or not) between the instances.
2008.SIGKDD.Angle-based outlier detection in high-dimensional data
- To give explanations on why an instance is outlying, ABOD finds its closest instance in the nearest cluster, then computes and returns the difference vector between the two data points. Figure 9 below provides an example.

2009.EC2ND.Visualization and explanation of payload-based anomaly detection
- anomalies in network payloads (data contained in a packet, request or connection) are explained by computing the difference between the vector representing the anomaly and a vector which is the average of the regular instances. The difference vector is then plotted for each feature in order to identifying the anomaly features having a value really far from the average regular data points.
2010.CERMA.Outlier detection with innovative explanation facility over a very large financial database
- clustering is used to detect anomalies: after the clustering, the most smallest cluster in terms of cardinality is considered anomalous. Then, the anomalous cluster is compared to the other clusters in terms of features. This comparison is reported to the final user as a text enumerating the features (along with the percentages) on which the clusters are different. A global difference percentage between pairs of clusters is also given. The pairs of clusters which are the most different can also be returned with the features differences percentages
2018.Credit card fraud detection via kernel-based supervised hashing
- constructs a group of hash functions which will map the original data points to lower dimensional expressions in a hash code space To build the hash functions, KSH uses a labelled training set. Data points having the same label will be similar/neighbors in the hashing space. To find out if a given data point is anomalous or not, KSH will search for its (10) nearest neighbors in the hash code space after hashing the data point. The class (anomalous or not) of the instance will be the majority class among its neighbors, and these neighbors are returned as an explanation of the abnormality.
2019.VLDB.Cape: explaining outliers by counterbalancing
- Cape explains outliers in aggregation queries through related outliers in the opposite direction that provide counterbalance.The foundation of our approach are aggregate regression patterns (ARPs) that describe coarse-grained trends in the data. An abnormally high number of publications by an author during a year can be explained by the fact that he had an abnormally low number of publications the year before due to rejection, and the publications that were previously rejected were accepted the following year.
2019.IUI workshop.Towards an explainable threat detection tool
- anomaly detection is performed in a semi-supervised way using GANomaly. . To provide explanations on why an instance is anomalous, two methods are proposed: display the normal instance closest to the anomaly, or generate a synthetic normal instance that is similar to the anomaly but without the features that make the anomaly outlying. The authors also propose a feature importance anomaly explanation method by inspecting the hidden layers of the GAN to find the most relevant attributes.
explanation by structure analysis
main idea
x1 and x2 are anomalies for the cluster of round instances and why it is the case, that y is an anomaly for the the triangles and why, and finally that z is an anomaly for the squares and why.

the output can ideally be a text in natural language giving as much details as possible on the anomalies, or even a set of rules.
2012.Credit-card fraud profiling using a hybrid incremental clustering methodology
- use a variant of the linearised fuzzy c-medoids algorithm to cluster the anomalies after detecting them using another anomaly detection algorithm. They were able to obtain distinct fraud profiles, but they did not reach the explanation step.
2018.DMKD.Explaining anomalies in groups with characterizing subspace rules
- a subspace clustering is first performed on the dataset containing anomalies and normal data points. After that step, hyper-rectangles containing the maximum number of anomalous data points and the minimum number of regular instances are obtained. Then each hyper-rectangles is refined into a hyper-ellipsoid in order to enclose as many outliers as possible and as few regular instances as possible. Finally, rules on every feature of the ellipsoid are generated and constitute the explanations for the set of anomalies contained in the ellipsoid. The explanations are computed after the anomalies identification which can be made using any algorithm; it is therefore a model-agnostic method.
2020.fuzzy IEEE.Explaining data regularities and anomalies
- authors derive a similarity measure from an Isolation Forest; a clustering (or more precisely an Agglomerative Hierarchical Clustering) of the regularities and the irregularities is then performed based on the similarity measure defined. After that, each cluster of anomalies is compared to each cluster of regular points based on their distinctive properties and, linguistic summaries, describing not only the properties of each cluster but also the differences between clusters, are generated.