论文:Self-Refine: Iterative Refinement with Self-Feedback
⭐⭐⭐⭐
CMU, NeurIPS 2023, arXiv:2303.17651
Code: https://selfrefine.info/
论文速读
本文提出了 Self-Refine 的 prompt 策略,可以在无需额外训练的情况下,在下游任务上产生更好的效果。
该方法的直观 insight:我们在写一封 email 时,往往写出一个 draft,然后再修改其中措辞不当的地方,修改为更好的版本。
其思路如下图:
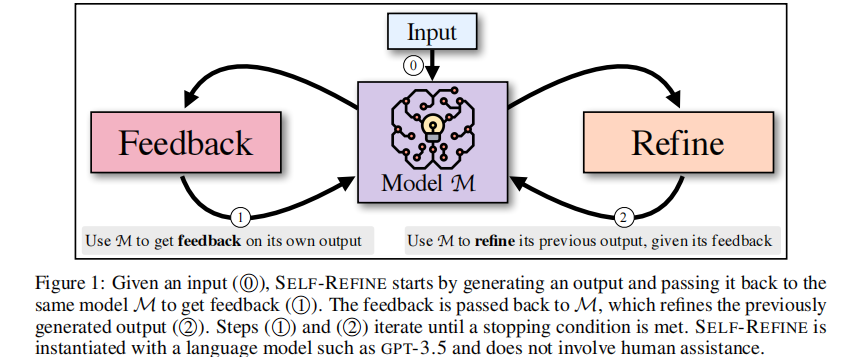
- 首先,给定一个 input x x x,在 prompt p g e n p_{gen} pgen 下让 LLM 先生成一个初始 output y 0 y_0 y0
- 进行迭代,每一轮 t t t 中:
- Feedback:将 input x x x、上一轮 output y t y_t yt 和 prompt p f b p_{fb} pfb 给 LLM,得到这一轮的 feedback f b t fb_t fbt
- Refine:将 input x x x、历史的所有 feedback 和 output、prompt p r e f i n e p_{refine} prefine 给 LLM,得到这一轮的 output t t + 1 t_{t+1} tt+1
如此迭代,直到 feedback 中被检查出有 stop 标识符,或者达到了最大迭代次数。
下面是一个使用 Self-Refine 来进行 code optimization 的示例:

总结
论文提出了 Self-Refine,核心就是反复迭代 Feedback 和 Refine 操作,从而让 LLM 在具体任务上有更好的表现。
论文在多个任务上进行了实验,发现 Self-Refine 可以有效地在各种任务上提升 LLM 的表现,当在较弱的小模型上则表现不佳(会重复输出)。