目录
- 基本概念
- State, Action, State transition
- Policy, Reward, Trajectory, Discount Return
- Episode
- Markov decision process
- 贝尔曼公式
- 推导确定形式的贝尔曼公式
- 推导一般形式的贝尔曼公式
- State Value
- Action Value
- 一些例子
- 贝尔曼公式的 Matric-vector form
- 贝尔曼公式的解析解
- 一些理论可得的结论
- 贝尔曼公式的迭代解
基本概念
State, Action, State transition
-
State: 用于描述agent目前所处的状态,以grid-world为例,即location: s 1 , s 2 , . . . s_1, s_2, ... s1,s2,...
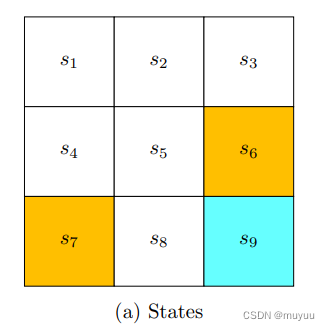
-
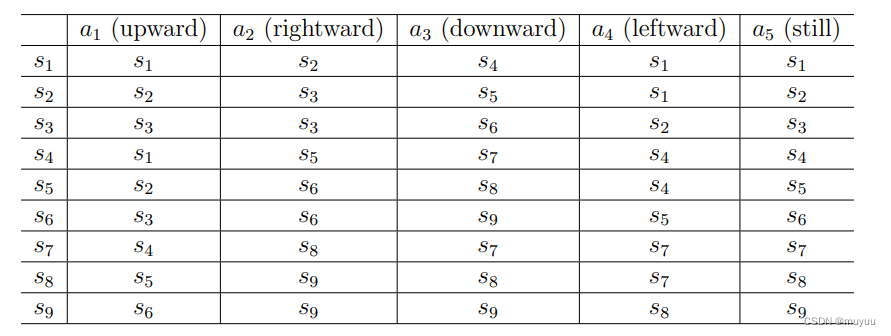
Action: 在某个State时,可以做的动作的集合,以grid-world为例,即:

-
State transition:State转移矩阵(确定情形)or State转移分布(概率情形),以grid-world为例,eg:
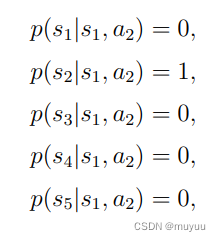
Policy, Reward, Trajectory, Discount Return
- Policy:即策略,告诉agent在每个State时,应该做什么Action,也有(确定形式)和(概率形式):
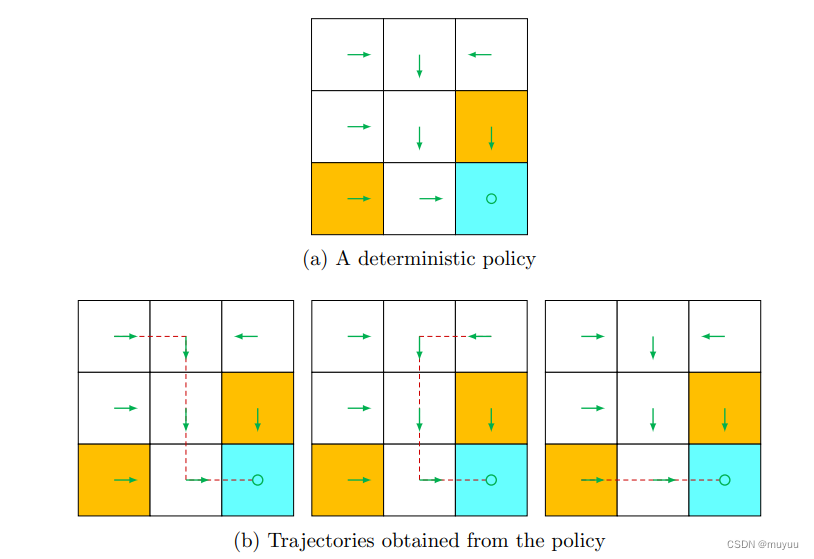
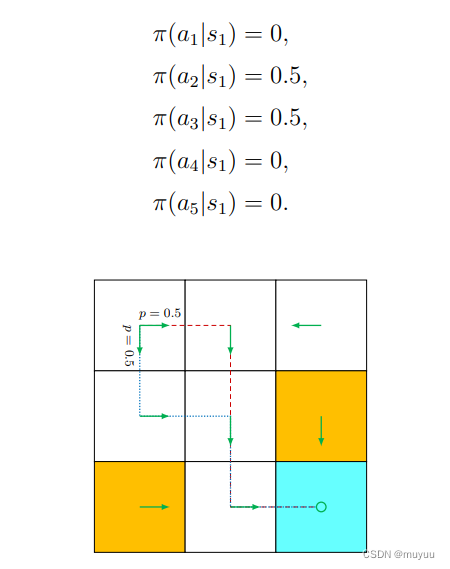
Policy在实际使用时,一般是存为表格(数组)形式,eg:

-
Reward:一个实值(标量),eg:正数用于reward,负数用于punishment,数学表达,eg :
{ P ( r = 1 ∣ 当前 s t a t e ,当前选择的 a i ) = 0.8 P ( r = 0 ∣ 当前 s t a t e ,当前选择的 a i ) = 0.2 \begin{cases} P(r=1|当前state,当前选择的a_i) = 0.8\\ \\ P(r=0|当前state,当前选择的a_i) = 0.2 \end{cases} ⎩ ⎨ ⎧P(r=1∣当前state,当前选择的ai)=0.8P(r=0∣当前state,当前选择的ai)=0.2 -
Trajectory:即 state-action-reward 链,eg:
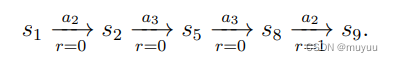
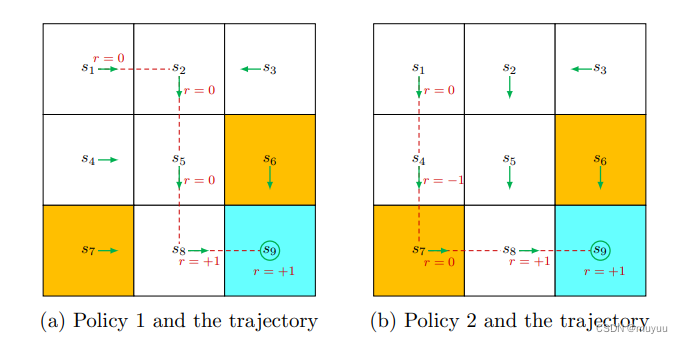
-
Return:即一个Trajectory上所有reward之和,eg:上图中第一个return是2,第二个return是1,所以第一个policy更好(没有进到forbidden block)
由于在到达target s 9 s_9 s9之后, s 9 s_9 s9的action会维持在 s 9 s_9 s9,即action一直是 a 5 a_5 a5(维持不动),因此reward会一直+1(那为什么不设置到达target之后停止/退出?),引入 discount rate γ ∈ ( 0 , 1 ) \gamma \in (0,1) γ∈(0,1):
discount return = 0 + 0 γ + 0 γ 2 + 1 γ 3 + 1 γ 4 + 1 γ 5 + . . . = γ 3 ( 1 + γ + γ 2 + . . . ) = γ 3 1 1 − γ \begin{aligned} \text{discount return} &= 0 + 0\gamma + 0\gamma^2 + 1\gamma^3 + 1\gamma^4 + 1\gamma^5 + ... \\ &= \gamma^3 (1 + \gamma + \gamma^2 + ...) = \gamma^3 \frac{1}{1-\gamma} \end{aligned} discount return=0+0γ+0γ2+1γ3+1γ4+1γ5+...=γ3(1+γ+γ2+...)=γ31−γ1
作用是:当 γ \gamma γ更趋于0时,return更受早期的action影响,而当 γ \gamma γ更趋于1时,return更受后期的action的影响
Episode
- Episode:当有terminal state时,即到这个state就停止,称为 episodic task(有限步);反之称为 continuing task(无限步,现实不存在,但当步数非常多时,近似认为是continuing task)。可以通过以下两种方法将 episodic task 看作特殊的 continuing task,这样后面就只需要对continuing task做理解:
- 将terminal state看作特殊的absorbing state(即进到这个stage再也不会离开),且需要将这个state的action的reward都设为0
- 将terminal state看作普通的state,可以离开,且每次进入该state时 r = + 1 r = +1 r=+1 (后面采用该种,因为更一般化)
Markov decision process
需要以上几个分布:
- π ( a ∣ s ) \pi(a|s) π(a∣s),在当前状态s,所做的action的分布 (即Policy)
- P ( s ′ ∣ s , a ) P(s' | s,a) P(s′∣s,a),在当前状态s,选定了动作a之后,下一个可能到的状态的分布(eg:往下时,即可能往下一格,也可能往下两格)
- P ( r ∣ s , a ) P(r | s,a) P(r∣s,a),在当前状态s,选定了动作a之后,可能的reward ( 跟 P ( s ′ ∣ s , a ) P(s' | s,a) P(s′∣s,a)属同一分布,即 s ′ s' s′ 定了reward 就定了;还是说即使 s ′ s' s′ 定了,reward也仍然不是确定值?)
- 以及Markov假设:
P ( s t + 1 ∣ a t + 1 , s t , . . . , a 1 , s 0 ) = P ( s t + 1 ∣ a t + 1 , s t ) P ( r t + 1 ∣ a t + 1 , s t , . . . , a 1 , s 0 ) = P ( r t + 1 ∣ a t + 1 , s t ) \begin{aligned} P(s_{t+1}|a_{t+1},s_t, ..., a_1,s_0) &= P(s_{t+1}|a_{t+1},s_t) \\ P(r_{t+1}|a_{t+1},s_t, ..., a_1,s_0) &= P(r_{t+1}|a_{t+1},s_t) \end{aligned} P(st+1∣at+1,st,...,a1,s0)P(rt+1∣at+1,st,...,a1,s0)=P(st+1∣at+1,st)=P(rt+1∣at+1,st)
贝尔曼公式
推导确定形式的贝尔曼公式
定义 v i v_i vi 为从 s i s_i si 出发的Trajectory的return, eg:
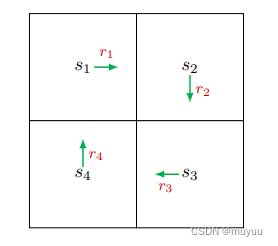
则有 Bootstrapping 推导式:
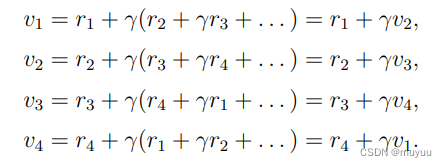
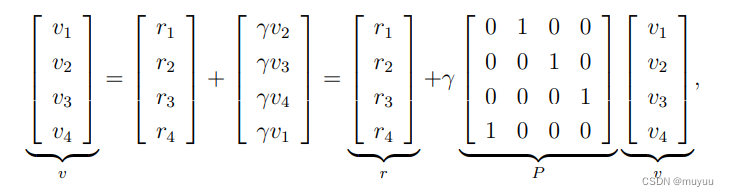
⇒ v = r + γ P v \Rightarrow v = r + \gamma P v ⇒v=r+γPv
⇒ \Rightarrow ⇒ 解析解 : v = ( I − γ P ) − 1 r v=(I-\gamma P)^{-1} r v=(I−γP)−1r
推导一般形式的贝尔曼公式
State Value
首先给出 State Value 的定义,对于一个multi-step trajectory,其步骤可以表示为:
S t → A t S t + 1 , R t + 1 → A t + 1 S t + 2 , R t + 2 → A t + 2 S t + 3 , R t + 3 , . . . S_t \overset{A_t} \rightarrow S_{t+1}, R_{t+1} \overset{A_{t+1}} \rightarrow S_{t+2}, R_{t+2} \overset{A_{t+2}} \rightarrow S_{t+3}, R_{t+3},... St→AtSt+1,Rt+1→At+1St+2,Rt+2→At+2St+3,Rt+3,...
该条从 S t S_t St 出发的 trajectory 的 discounted return 则为:
G t = R t + 1 + γ R t + 2 + γ 2 R t + 3 + . . . G_t = R_{t+1} + \gamma R_{t+2} + \gamma^2R_{t+3} + ... Gt=Rt+1+γRt+2+γ2Rt+3+...
由于 R t + 1 , R t + 2 , . . . R_{t+1}, R_{t+2}, ... Rt+1,Rt+2,... 均为随机变量,因此 G t G_t Gt 也是随机变量。
- State Value:即当前状态为 s 时,discounted return G t G_t Gt 的期望值:
v π ( s ) = E [ G t ∣ S t = s ] v_{\pi}(s) = E[G_t|S_t=s] vπ(s)=E[Gt∣St=s]
更具象的理解是 :
- 给定Policy π \pi π ,当从状态 s 出发时,discounted return的期望值(从一个state出发,可能有多条路径到达terminal/或称多条trajectory,对所有可能的trajectory的discounted return求期望)
- 某个状态的 v π ( s ) v_{\pi}(s) vπ(s) 越高,说明它越有价值/越值得去(见以下例子)
Action Value
State Value 是指从一个 state 出发的 average return,而 Action Value 是指从一个 state 出发,并且 take 某个 action 的 average return。
q π ( s , a ) = E [ G t ∣ S t = s , A t = a ] q_{\pi}(s,a) = E[G_t|S_t=s, A_t =a ] qπ(s,a)=E[Gt∣St=s,At=a]
state value 用于选择哪个 Policy 更好,而 action value 用于选择哪个 action 更好
Action Value 和 State value 的关系:
E [ G t ∣ S t = s ] = ∑ a E [ G t ∣ S t = s , A t = a ] π ( a ∣ s ) E[G_t|S_t=s] = \sum_a E[G_t|S_t=s, A_t =a ] \pi(a|s) E[Gt∣St=s]=a∑E[Gt∣St=s,At=a]π(a∣s)
即: v π ( s ) = ∑ a π ( a ∣ s ) q π ( s , a ) v_{\pi}(s) = \sum_a \pi(a|s) q_{\pi}(s,a) vπ(s)=a∑π(a∣s)qπ(s,a)
⇒ \Rightarrow ⇒ State Value 实际是所有 Action Value 的 “平均”
下面开始推导贝尔曼公式:
由于
G t = R t + 1 + γ R t + 2 + γ 2 R t + 3 + . . . = R t + 1 + γ ( R t + 2 + γ R t + 3 + . . . ) = R t + 1 + γ G t + 1 \begin{aligned} G_t &= R_{t+1} + \gamma R_{t+2} + \gamma^2 R_{t+3} + ...\\ &= R_{t+1} + \gamma (R_{t+2} + \gamma R_{t+3} + ...) \\ & = R_{t+1} + \gamma G_{t+1} \end{aligned} Gt=Rt+1+γRt+2+γ2Rt+3+...=Rt+1+γ(Rt+2+γRt+3+...)=Rt+1+γGt+1
⇒ v π ( s ) = E [ G t ∣ S t = s ] = E [ R t + 1 + γ G t + 1 ∣ S t = s ] = E [ R t + 1 ∣ S t = s ] + γ E [ G t + 1 ∣ S t = s ] \begin{aligned} \Rightarrow v_{\pi}(s) &= E[G_t|S_t=s]\\ &= E[R_{t+1} + \gamma G_{t+1}|S_t=s] \\ &= E[R_{t+1}|S_t=s] + \gamma E[G_{t+1}|S_t=s] \end{aligned} ⇒vπ(s)=E[Gt∣St=s]=E[Rt+1+γGt+1∣St=s]=E[Rt+1∣St=s]+γE[Gt+1∣St=s]
其中第一项为 下一步的reward的期望,可以分解为:
E [ R t + 1 ∣ S t = s ] = ∑ a E [ R t + 1 ∣ S t = s , A t = a ] π ( a ∣ s ) = ∑ a π ( a ∣ s ) ∑ r P ( r ∣ s , a ) r \begin{aligned} E[R_{t+1}|S_t=s] &= \sum_{a} E[R_{t+1}|S_t=s, A_t=a] \pi(a|s)\\ &= \sum_{a} \pi(a|s) \sum_{r} P(r|s,a)r \end{aligned} E[Rt+1∣St=s]=a∑E[Rt+1∣St=s,At=a]π(a∣s)=a∑π(a∣s)r∑P(r∣s,a)r
第二项为 从下一时刻的状态为起点的 trajectory 的 discounted return,可以分解为:
E [ G t + 1 ∣ S t = s ] = ∑ s ′ E [ G t + 1 ∣ S t = s , S t + 1 = s ′ ] P ( s ′ ∣ s ) = ∑ s ′ E [ G t + 1 ∣ S t + 1 = s ′ ] P ( s ′ ∣ s ) = ∑ s ′ v π ( s ′ ) P ( s ′ ∣ s ) = ∑ s ′ v π ( s ′ ) ∑ a P ( s ′ ∣ s , a ) π ( a ∣ s ) \begin{aligned} E[G_{t+1}|S_t=s] &= \sum_{s'} E[G_{t+1}|S_t=s, S_{t+1}=s'] P(s'|s)\\ &= \sum_{s'} E[G_{t+1}|S_{t+1}=s'] P(s'|s)\\ &= \sum_{s'} v_{\pi}(s') P(s'|s)\\ &= \sum_{s'} v_{\pi}(s') \sum_{a} P(s'|s,a) \pi(a|s) \end{aligned} E[Gt+1∣St=s]=s′∑E[Gt+1∣St=s,St+1=s′]P(s′∣s)=s′∑E[Gt+1∣St+1=s′]P(s′∣s)=s′∑vπ(s′)P(s′∣s)=s′∑vπ(s′)a∑P(s′∣s,a)π(a∣s)
由上得贝尔曼公式一般形式:
v π ( s ) = ∑ a π ( a ∣ s ) [ ∑ r P ( r ∣ s , a ) r + γ ∑ s ′ P ( s ′ ∣ s , a ) v π ( s ′ ) ] , ∀ s \begin{aligned} v_{\pi}(s) = \sum_{a} \pi(a|s) [\sum_{r} P(r|s,a)r + \gamma \sum_{s'} P(s'|s,a) v_{\pi}(s')], \quad \forall s \end{aligned} vπ(s)=a∑π(a∣s)[r∑P(r∣s,a)r+γs′∑P(s′∣s,a)vπ(s′)],∀s
贝尔曼公式描述了 两个 state value v π ( s ) v_{\pi}(s) vπ(s) 和 v π ( s ′ ) v_{\pi}(s') vπ(s′) 的关系
同时由 state value 和 action value 的关系: v π ( s ) = ∑ a π ( a ∣ s ) q π ( s , a ) v_{\pi}(s) = \sum_a \pi(a|s) q_{\pi}(s,a) vπ(s)=a∑π(a∣s)qπ(s,a)
可得 q π ( s , a ) = ∑ r P ( r ∣ s , a ) r + γ ∑ s ′ P ( s ′ ∣ s , a ) v π ( s ′ ) q_{\pi}(s,a) = \sum_{r} P(r|s,a)r + \gamma \sum_{s'} P(s'|s,a) v_{\pi}(s') qπ(s,a)=r∑P(r∣s,a)r+γs′∑P(s′∣s,a)vπ(s′)
即如果知道所有的State Value,反过来也可以求 Action Value
一些例子
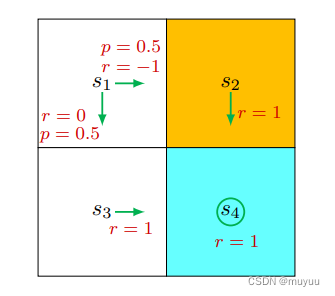
- 对于policy:
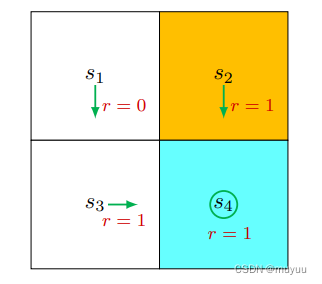
由于
π ( a = a 3 ∣ s 1 ) = 1 , π ( a ≠ a 3 ∣ s 1 ) = 0 P ( s ′ = s 3 ∣ s 1 , a 3 ) = 1 , P ( s ′ ≠ s 3 ∣ s 1 , a 3 ) = 0 P ( r = 0 ∣ s 1 , a 3 ) = 1 , P ( r ≠ 0 ∣ s 1 , a 3 ) = 0 \begin{aligned} &\pi(a = a_3|s_1) = 1, \pi(a \neq a_3|s_1) = 0 \\ &P(s'=s_3|s_1, a_3) =1, P(s'\neq s_3|s_1, a_3) =0 \\ &P(r=0|s_1, a_3) = 1, P(r \neq 0|s_1, a_3) = 0 \end{aligned} π(a=a3∣s1)=1,π(a=a3∣s1)=0P(s′=s3∣s1,a3)=1,P(s′=s3∣s1,a3)=0P(r=0∣s1,a3)=1,P(r=0∣s1,a3)=0
⇒ v π ( s 1 ) = ∑ a π ( a ∣ s 1 ) [ ∑ r P ( r ∣ s 1 , a ) r + γ ∑ s ′ P ( s ′ ∣ s 1 , a ) v π ( s ′ ) ] = 1 ∗ [ ∑ r P ( r ∣ s 1 , a 3 ) r + γ ∑ s ′ P ( s ′ ∣ s 1 , a 3 ) v π ( s ′ ) ] = 1 ∗ [ 1 ∗ 0 + 0 + γ ∗ 1 ∗ v π ( s 3 ) ] = 0 + γ v π ( s 3 ) \begin{aligned} \Rightarrow v_{\pi}(s_1) &= \sum_{a} \pi(a|s_1) [\sum_{r} P(r|s_1,a)r + \gamma \sum_{s'} P(s'|s_1,a) v_{\pi}(s')]\\ &= 1* [\sum_{r} P(r|s_1,a_3)r + \gamma \sum_{s'} P(s'|s_1,a_3) v_{\pi}(s')] \\ &= 1* [1*0 + 0 + \gamma * 1*v_{\pi}(s_3)]\\ &= 0 + \gamma v_{\pi}(s_3) \end{aligned} ⇒vπ(s1)=a∑π(a∣s1)[r∑P(r∣s1,a)r+γs′∑P(s′∣s1,a)vπ(s′)]=1∗[r∑P(r∣s1,a3)r+γs′∑P(s′∣s1,a3)vπ(s′)]=1∗[1∗0+0+γ∗1∗vπ(s3)]=0+γvπ(s3)
同理有:
v π ( s 2 ) = 1 + γ v π ( s 4 ) v π ( s 3 ) = 1 + γ v π ( s 4 ) v π ( s 4 ) = 1 + γ v π ( s 4 ) \begin{aligned} v_{\pi}(s_2) &= 1 + \gamma v_{\pi}(s_4) \\ v_{\pi}(s_3) &= 1 + \gamma v_{\pi}(s_4) \\ v_{\pi}(s_4) &= 1 + \gamma v_{\pi}(s_4) \end{aligned} vπ(s2)vπ(s3)vπ(s4)=1+γvπ(s4)=1+γvπ(s4)=1+γvπ(s4)
解得:
v π ( s 1 ) = γ 1 − γ v π ( s 2 ) = 1 1 − γ v π ( s 3 ) = 1 1 − γ v π ( s 4 ) = 1 1 − γ \begin{aligned} v_{\pi}(s_1) &= \frac{\gamma}{1-\gamma}\\ v_{\pi}(s_2) &= \frac{1}{1-\gamma}\\ v_{\pi}(s_3) &= \frac{1}{1-\gamma}\\ v_{\pi}(s_4) &= \frac{1}{1-\gamma} \end{aligned} vπ(s1)vπ(s2)vπ(s3)vπ(s4)=1−γγ=1−γ1=1−γ1=1−γ1
⇒ v π ( s 1 ) < v π ( s 2 ) = v π ( s 3 ) = v π ( s 4 ) \Rightarrow v_{\pi}(s_1) < v_{\pi}(s_2) = v_{\pi}(s_3) =v_{\pi}(s_4) ⇒vπ(s1)<vπ(s2)=vπ(s3)=vπ(s4)
解释: s 1 s_1 s1 距离 target state 比其他 state 都要远,因此其 价值 低于其他的 state,(直观上也可以看到 s 1 s_1 s1 距离 target state,比其他的 state 都要远)
- 更复杂的例子
两种好的 Policy,及其各个 state 的 state value:
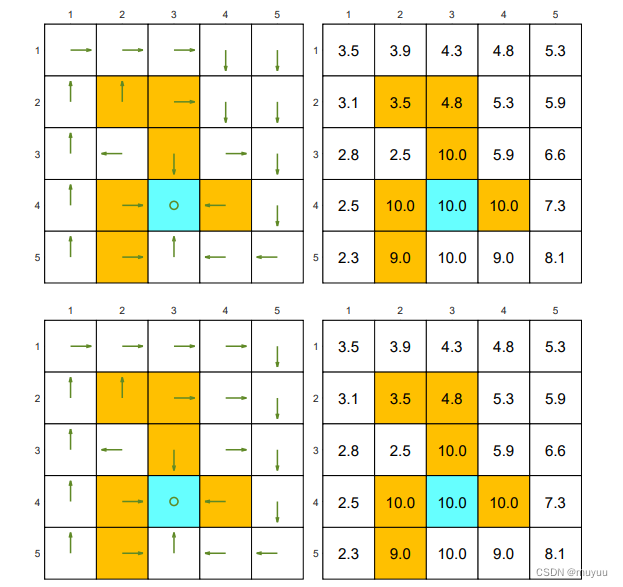
两种不好的 Policy:一个全向右的 Policy 和 一个随机生成的 Policy:
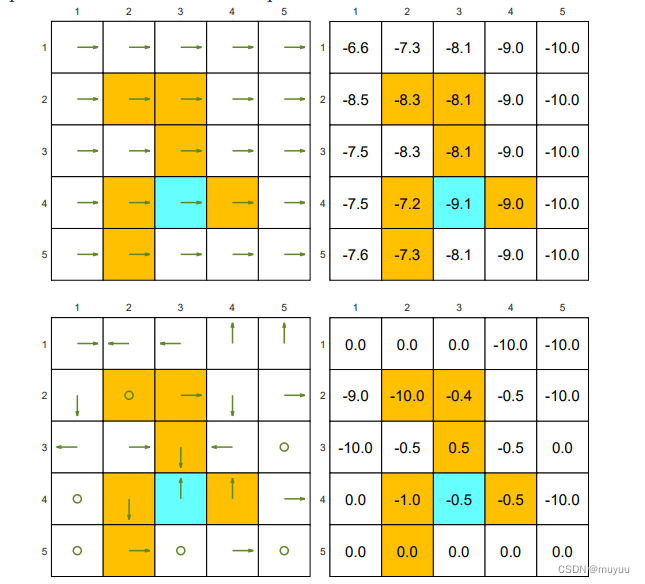
可以看到
- 好的 Policy 的 state value,基本都为正;而不好的 Policy 的 state value 中,会有很多负数
- 两个不完全相同的 Policy,也可能有完全一样的 state value (因为在其出现 diff 的部分路径上,reward总和相同)
贝尔曼公式的 Matric-vector form
记
r π ( s i ) = ∑ a π ( a ∣ s i ) ∑ r P ( r ∣ s i , a ) r = E [ R t + 1 ∣ S t = s i ] \begin{aligned} r_{\pi}(s_i) &= \sum_{a} \pi(a|s_i) \sum_{r} P(r|s_i,a)r = E[R_{t+1}|S_t=s_i] \end{aligned} rπ(si)=a∑π(a∣si)r∑P(r∣si,a)r=E[Rt+1∣St=si]
又有: P π ( s j ∣ s i ) = ∑ a P ( s j ∣ s i , a ) π ( a ∣ s i ) P_{\pi}(s_j|s_i) = \sum_{a} P(s_j|s_i,a) \pi(a|s_i) Pπ(sj∣si)=a∑P(sj∣si,a)π(a∣si)
因此 v π ( s i ) = r π ( s i ) + γ ∑ s j P π ( s j ∣ s i ) v π ( s j ) v_{\pi}(s_i) = r_{\pi}(s_i) + \gamma \sum_{s_j} P_{\pi}(s_j|s_i) v_{\pi}(s_j) vπ(si)=rπ(si)+γsj∑Pπ(sj∣si)vπ(sj)
Matric-vector form: v π = r π + γ P π v π v_{\pi} = r_{\pi} + \gamma P_{\pi} v_{\pi} vπ=rπ+γPπvπ
例如:
上式可展开为:

贝尔曼公式的解析解
贝尔曼公式: v π = r π + γ P π v π v_{\pi} = r_{\pi} + \gamma P_{\pi} v_{\pi} vπ=rπ+γPπvπ
⇒ 解析解: v π = ( I − γ P π ) − 1 r π \Rightarrow 解析解:v_{\pi} = (I - \gamma P_{\pi})^{-1} r_{\pi} ⇒解析解:vπ=(I−γPπ)−1rπ
一些理论可得的结论
- ( I − γ P π ) (I - \gamma P_{\pi}) (I−γPπ) 是可逆的
Gershgorin 圆盘定理
设 A A A 是一个 n × n n \times n n×n 复矩阵,矩阵的元素为 a i j a_{ij} aij。对于每个 i i i,定义 Gershgorin 圆盘 D i D_i Di 为以 a i i a_{ii} aii 为中心,半径为矩阵第 i i i 行上非对角元素绝对值之和的圆盘。即:
D i = { z ∈ C : ∣ z − a i i ∣ ≤ R i } D_i = \{ z \in \mathbb{C} : |z - a_{ii}| \leq R_i \} Di={z∈C:∣z−aii∣≤Ri}
其中 R i = ∑ j ≠ i ∣ a i j ∣ R_i = \sum_{j \neq i} |a_{ij}| Ri=∑j=i∣aij∣
\quad
Gershgorin 圆盘定理的结论是:矩阵 A A A 的所有特征值都位于至少一个 Gershgorin 圆盘内
Proof:
那么根据Gershgorin 圆盘定理, ( I − γ P π ) (I - \gamma P_{\pi}) (I−γPπ) 的每个特征值都至少在一个
圆心为 : [ ( I − γ P π ) ] i i = 1 − γ P π ( s i ∣ s i ) 半径为 : ∑ j ≠ i ∣ [ I − γ P π ] i j ∣ = ∑ j ≠ i γ P π ( s j ∣ s i ) (因为 j ≠ i 时, I i j = 0 ) \begin{aligned} 圆心为&: [(I - \gamma P_{\pi})]_{ii} = 1-\gamma P_{\pi}(s_i | s_i)\\ 半径为&:\sum_{j \neq i} |[I-\gamma P_{\pi}]_{ij}| = \sum_{j \neq i} \gamma P_{\pi}(s_j|s_i) (因为 j \neq i 时,I_{ij} =0) \end{aligned} 圆心为半径为:[(I−γPπ)]ii=1−γPπ(si∣si):j=i∑∣[I−γPπ]ij∣=j=i∑γPπ(sj∣si)(因为j=i时,Iij=0)
的圆当中,又有:
∑ j ≠ i γ P π ( s j ∣ s i ) + γ P π ( s i ∣ s i ) = γ < 1 \sum_{j \neq i} \gamma P_{\pi}(s_j|s_i) + \gamma P_{\pi}(s_i | s_i) = \gamma < 1 j=i∑γPπ(sj∣si)+γPπ(si∣si)=γ<1
因此:
∑ j ≠ i γ P π ( s j ∣ s i ) < 1 − γ P π ( s i ∣ s i ) \sum_{j \neq i} \gamma P_{\pi}(s_j|s_i) < 1 - \gamma P_{\pi}(s_i | s_i) j=i∑γPπ(sj∣si)<1−γPπ(si∣si)
即 半径 < |圆心|,说明 ( I − γ P π ) (I - \gamma P_{\pi}) (I−γPπ) 的 Gershgorin 圆盘都不包含原点,因此其特征值都不为零。
- ( I − γ P π ) − 1 > I (I - \gamma P_{\pi})^{-1} > I (I−γPπ)−1>I
由泰勒级数展开: 1 1 − x = 1 + x + x 2 + x 3 + . . . \frac{1}{1-x} = 1 + x + x^2 + x^3 + ... 1−x1=1+x+x2+x3+...
⇒ ( I − γ P π ) − 1 = I + γ P π + γ 2 P π 2 + . . . ≥ I , ( γ > 0 ,而 P π 的值是概率,也总大于 0 ) \Rightarrow (I - \gamma P_{\pi})^{-1} = I + \gamma P_{\pi} + \gamma^2 P_{\pi}^2 + ... \geq I , (\gamma > 0, 而 P_{\pi} 的值是概率,也总大于0) ⇒(I−γPπ)−1=I+γPπ+γ2Pπ2+...≥I,(γ>0,而Pπ的值是概率,也总大于0)
贝尔曼公式的迭代解
不过实际中, ( I − γ P π ) (I - \gamma P_{\pi}) (I−γPπ) 是一个很大的矩阵,求逆计算量太大,因此实际一般使用迭代式:
v k + 1 = r π + γ P π v k v_{k+1} = r_{\pi} + \gamma P_{\pi} v_{k} vk+1=rπ+γPπvk
以上迭代式成立的原因是:
v k → v π = ( I − γ P π ) − 1 r π , as k → ∞ . v_k \to v_\pi = (I - \gamma P_\pi)^{-1} r_\pi, \text{ as } k \to \infty. vk→vπ=(I−γPπ)−1rπ, as k→∞.
证明如下:

Reference:
1.强化学习的数学原理