文件编码检测与转换:从自定义实现到 ICU 应用
本文摘要:
在实际工程开发中,不同来源的文件可能采用了不同的字符编码格式,导致读取、解析或展示时出现乱码或异常。本篇文章围绕文件编码检测与统一处理展开,介绍了自定义编码检测的实现思路,评测了主流字符集检测库,并最终基于 ICU(International Components for Unicode)提供了稳定的跨平台编码检测与转换方案。同时,详细记录了在使用过程中遇到的问题与解决方案,并针对不同系统环境(Windows/Linux/macOS)给出了完整的配置与应用指南。文章还扩展了如何根据系统默认编码动态适配文件内容,适合有实际工程需求的开发者参考。
一、为什么要做文件编码检测和统一?
在开发中,我们经常需要处理来源不同的文件,如:
- 下载自网络、复制自其他设备
- 不同系统(Windows/Linux/macOS)上生成的文件
- 迁移过网络、U盘,导致编码不一致
如果不统一编码,就有可能造成:
- 读取文件时出现乱码
- 程序崩溃(特别是UTF-16/非UTF-8文件)
- 分析错误,传递数据异常
实际例子:
如下图所示,在Visual Studio调试过程中,加载了一些外来CSV文件,进入splitCSVLine分割时,发现std::string里有大量\0\0\0等不可见字符,导致分割失败:
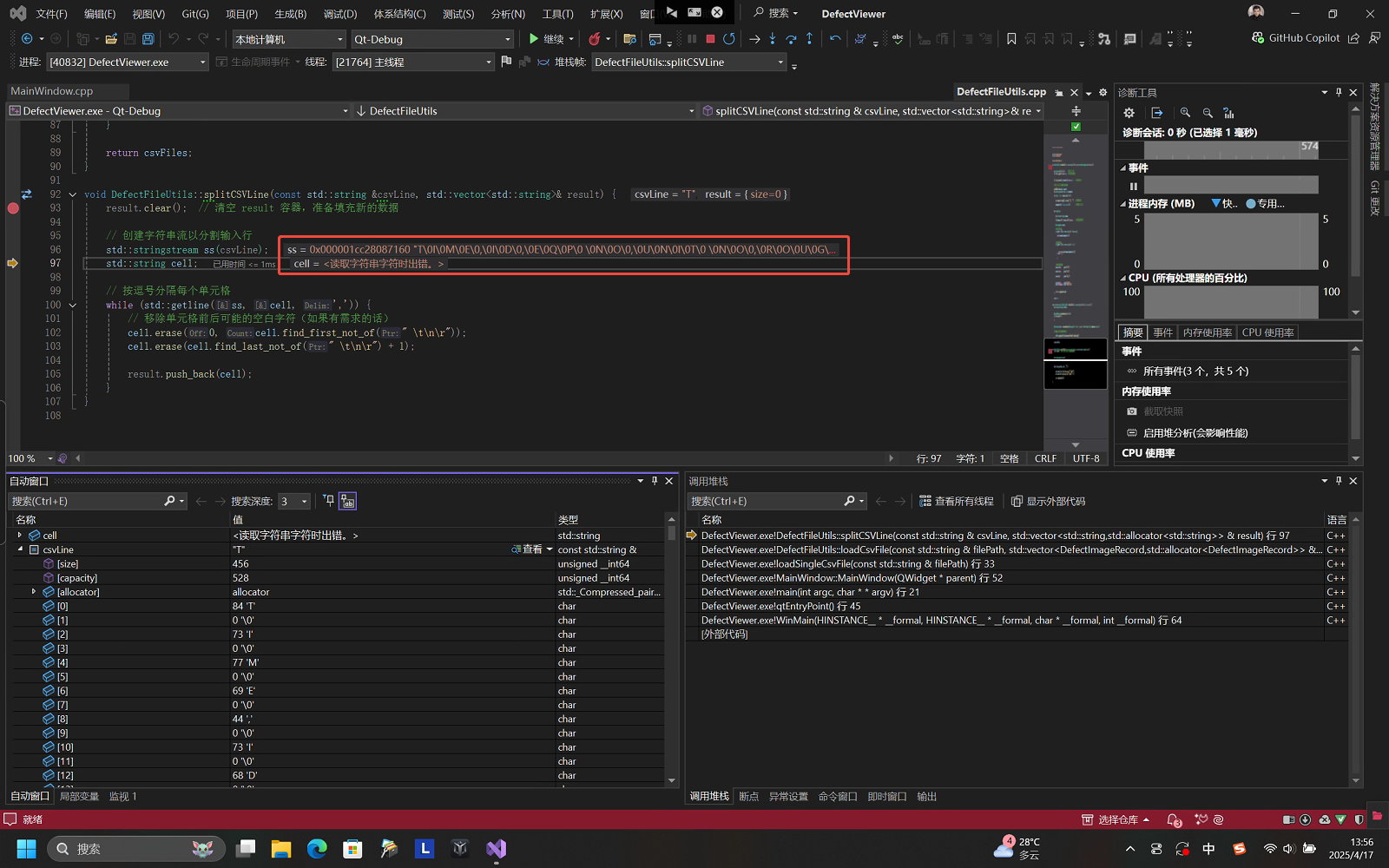
因此,在处理文件时,第一步就是 检测编码类型,并统一为UTF-8。
二、自定义实现 detectFileEncoding(const std::string& filePath)
最初,我使用了一个简单的自定义算法,基于 BOM标识符 和 内容特征 判断:
enum class FileEncoding {Unknown,UTF8_BOM,UTF16_LE,UTF16_BE,ANSI
};
FileEncoding DefectFileUtils::detectFileEncoding(const std::string& filePath) {std::ifstream file(filePath, std::ios::binary);if (!file.is_open()) return FileEncoding::Unknown;unsigned char bom[3] = { 0 };file.read(reinterpret_cast<char*>(bom), sizeof(bom));if (bom[0] == 0xEF && bom[1] == 0xBB && bom[2] == 0xBF) return FileEncoding::UTF8_BOM;if (bom[0] == 0xFF && bom[1] == 0xFE) return FileEncoding::UTF16_LE;if (bom[0] == 0xFE && bom[1] == 0xFF) return FileEncoding::UTF16_BE;// 没有BOM,根据内容大致判断file.seekg(0, std::ios::beg);unsigned char buffer[512] = { 0 };file.read(reinterpret_cast<char*>(buffer), sizeof(buffer));int nullByteCount = 0;for (int i = 0; i + 1 < file.gcount(); i += 2) {if (buffer[i+1] == 0x00) ++nullByteCount;}double ratio = static_cast<double>(nullByteCount) / (file.gcount() / 2);if (ratio > 0.8) return FileEncoding::UTF16_LE;return FileEncoding::ANSI;
}
这个函数有一些限制:
- 只能检测BOM或特征明显的UTF16
- 无法区分GBK,Big5,Shift-JIS等类似编码
- 短文件/小文件检测精度低
因此,如果需要完整应对各种编码,必须使用更强大的库!
使用自定义函数检测字符集:
bool DefectFileUtils::loadCsvFile(const std::string &filePath, std::vector<DefectImageRecord> &outRecords) {outRecords.clear();// 检测编码FileEncoding encoding = detectFileEncoding(filePath);// 打开文件QFile file(QString::fromStdString(filePath));if (!file.open(QIODevice::ReadOnly)) {return false;}// 先把整个文件读到 QByteArrayQByteArray fileData = file.readAll();file.close();QString content;// 根据编码手动转换成 QStringswitch (encoding) {case FileEncoding::UTF8_BOM:case FileEncoding::ANSI:content = QString::fromUtf8(fileData);break;case FileEncoding::UTF16_LE:content = QString::fromUtf16(reinterpret_cast<const char16_t*>(fileData.constData()), fileData.size() / 2);break;case FileEncoding::UTF16_BE:qWarning("暂不直接支持UTF-16 BE,需要额外处理!");return false;default:content = QString::fromUtf8(fileData); // fallbackbreak;}// 切成行static const QRegularExpression reNewline("[\r\n]+");QStringList lines = content.split(reNewline, Qt::SkipEmptyParts);if (lines.isEmpty()) {return false;}// 解析表头// ......return true;
}
三、可选库列表
在实际工程中,有这些选择:
| 库 | 简介 |
|---|---|
| uchardet | Firefox源码分支,支持检测GBK/Big5/Shift-JIS等,小而精 |
| ICU (International Components for Unicode) | 工业级,全面支持Unicode、编码检测和转换,系统等级使用 |
| enca | Linux环境中常用,支持部分编码,但功能较粗糙 |
| chardet (Python) | Python社区常用,可以C++调用小挂件等,实际应用有较大限制 |
| libcharsetdetect | 简单较小,支持基础检测,功能有限 |
最终,我选择了 ICU,因为:
- vcpkg/跨平台支持好
- Windows/Linux/macOS 都有供应
- API完善,支持检测+编码转换
四、实际工程:使用 ICU
ICU检测编码流程:
ucsdet_open创建检测器ucsdet_setText设置文件内容ucsdet_detect扫描最优编码ucsdet_getName返回编码名称ucsdet_close释放资源
ICU 实现全整流程代码
以下是完整使用 ICU 实现的检测+转换,并自动处理ASCII检测与统计:
#include <unicode/ucsdet.h>
#include <unicode/ucnv.h>#include <filesystem>
#include <fstream>
#include <vector>
#include <string>
#include <iostream>#ifdef _WIN32
#include <windows.h> // 为了SetConsoleOutputCP
#endifnamespace fs = std::filesystem;// 检测文件编码
std::string detectEncodingICU(const std::string& filePath) {std::ifstream file(filePath, std::ios::binary);if (!file.is_open()) {return "Unknown";}std::vector<char> buffer(4096);file.read(buffer.data(), buffer.size());std::streamsize bytesRead = file.gcount();if (bytesRead <= 0) {return "Empty";}UErrorCode status = U_ZERO_ERROR;UCharsetDetector* csd = ucsdet_open(&status);ucsdet_setText(csd, buffer.data(), static_cast<int32_t>(bytesRead), &status);const UCharsetMatch* match = ucsdet_detect(csd, &status);std::string result = "Unknown";if (match != nullptr && U_SUCCESS(status)) {const char* name = ucsdet_getName(match, &status);if (name) {result = name;}}ucsdet_close(csd);return result;
}// 判断是否纯ASCII
bool isPureAscii(const std::vector<char>& data) {for (char c : data) {if (static_cast<unsigned char>(c) > 0x7F) {return false;}}return true;
}// 转成 UTF-8
bool convertFileToUTF8(const std::string& inputPath, const std::string& outputPath, const std::string& srcEncoding) {UErrorCode status = U_ZERO_ERROR;UConverter* srcConv = ucnv_open(srcEncoding.c_str(), &status);UConverter* dstConv = ucnv_open("UTF-8", &status);if (U_FAILURE(status)) {if (srcConv) ucnv_close(srcConv);if (dstConv) ucnv_close(dstConv);return false;}std::ifstream inFile(inputPath, std::ios::binary);std::vector<char> inputBuffer((std::istreambuf_iterator<char>(inFile)), std::istreambuf_iterator<char>());std::vector<char> outputBuffer(inputBuffer.size() * 4);const char* src = inputBuffer.data();const char* srcLimit = src + inputBuffer.size();char* dst = outputBuffer.data();char* dstLimit = dst + outputBuffer.size();ucnv_convertEx(dstConv, srcConv,&dst, dstLimit,&src, srcLimit,nullptr, nullptr,nullptr, nullptr,true, true,&status);if (U_FAILURE(status)) {ucnv_close(srcConv);ucnv_close(dstConv);return false;}std::ofstream outFile(outputPath, std::ios::binary);outFile.write(outputBuffer.data(), dst - outputBuffer.data());ucnv_close(srcConv);ucnv_close(dstConv);return true;
}// 遍历处理文件夹
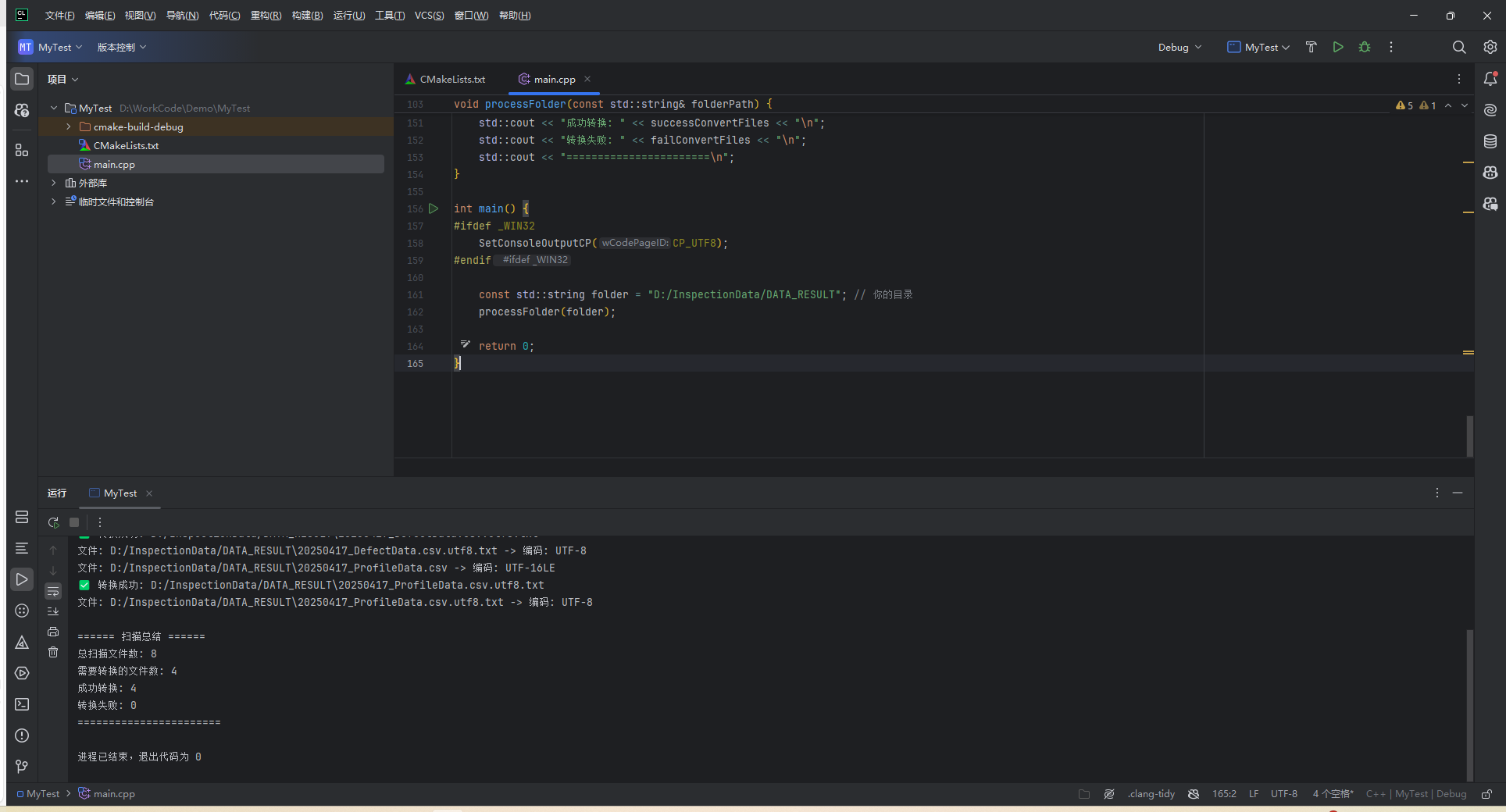
void processFolder(const std::string& folderPath) {int totalFiles = 0;int needConvertFiles = 0;int successConvertFiles = 0;int failConvertFiles = 0;for (const auto& entry : fs::recursive_directory_iterator(folderPath)) {if (entry.is_regular_file()) {totalFiles++;std::string filePath = entry.path().string();// 读一段内容std::ifstream file(filePath, std::ios::binary);std::vector<char> buffer(4096);file.read(buffer.data(), buffer.size());std::streamsize bytesRead = file.gcount();std::string encoding = detectEncodingICU(filePath);// 修正 ISO-8859-1 的检测误判(如果内容是ASCII,强制归为UTF-8)if (encoding == "ISO-8859-1" || encoding == "windows-1252") {if (isPureAscii(buffer)) {encoding = "UTF-8";}}std::cout << "文件: " << filePath << " -> 编码: " << encoding << std::endl;if (encoding != "UTF-8" && encoding != "ASCII") {needConvertFiles++;std::string outputPath = filePath + ".utf8.txt";if (convertFileToUTF8(filePath, outputPath, encoding)) {successConvertFiles++;std::cout << "✅ 转换成功: " << outputPath << std::endl;} else {failConvertFiles++;std::cout << "❌ 转换失败: " << filePath << std::endl;}}}}// 输出总结std::cout << "\n====== 扫描总结 ======\n";std::cout << "总扫描文件数: " << totalFiles << "\n";std::cout << "需要转换的文件数: " << needConvertFiles << "\n";std::cout << "成功转换: " << successConvertFiles << "\n";std::cout << "转换失败: " << failConvertFiles << "\n";std::cout << "=======================\n";
}int main() {
#ifdef _WIN32SetConsoleOutputCP(CP_UTF8);
#endifconst std::string folder = "D:/InspectionData/DATA_RESULT"; // 你的目录processFolder(folder);return 0;
}
这些函数满足:
- 检测编码(detectEncodingICU)
- 判断ASCII(isPureAscii)
- 编码转换(convertFileToUTF8)
- 手动扫描文件夹(processFolder)
- 统计结果输出
解决 CMake ICU 引入问题
在 Windows/macOS/Linux 项目中,需要确保 CMake 正确引入 ICU:
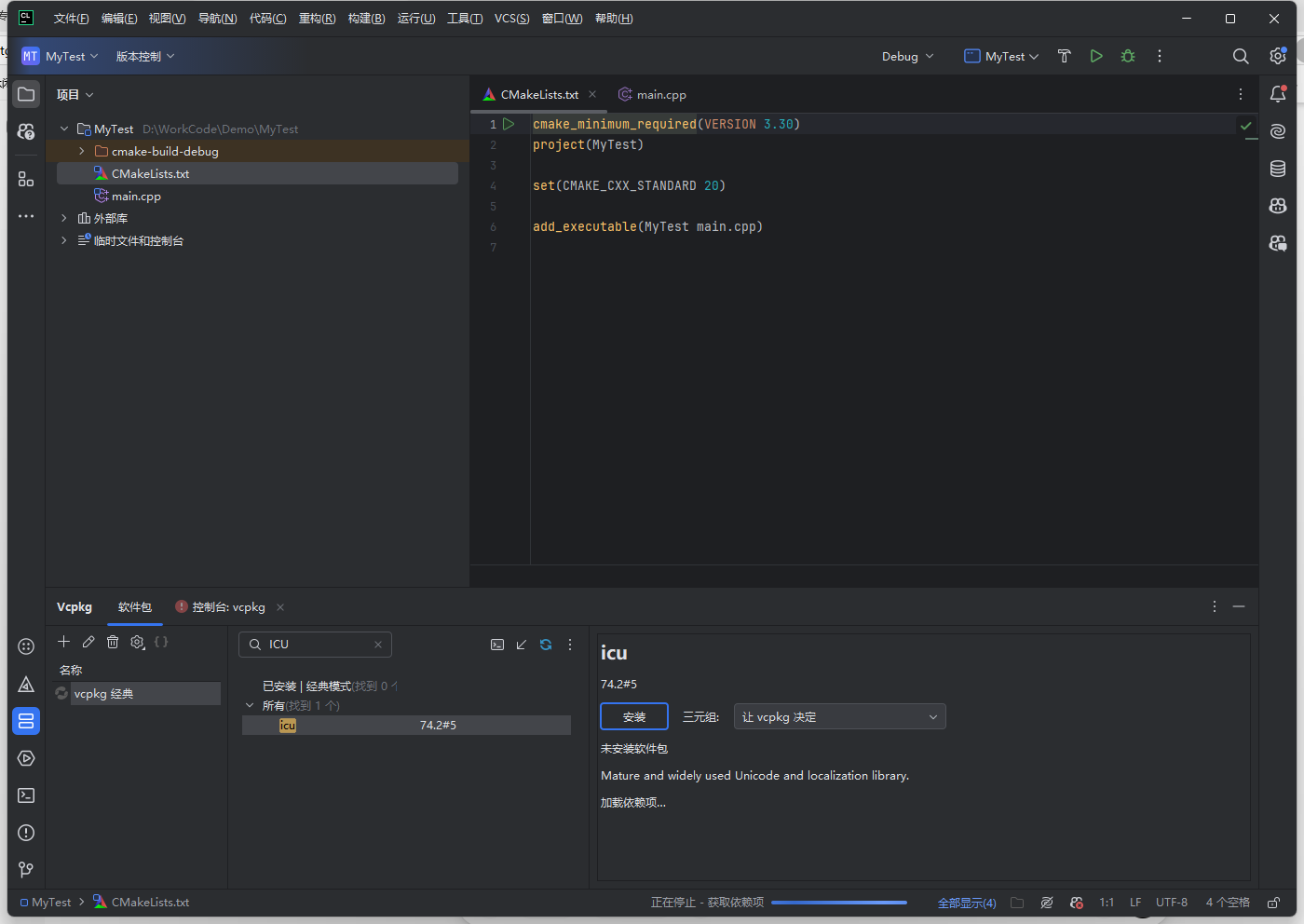
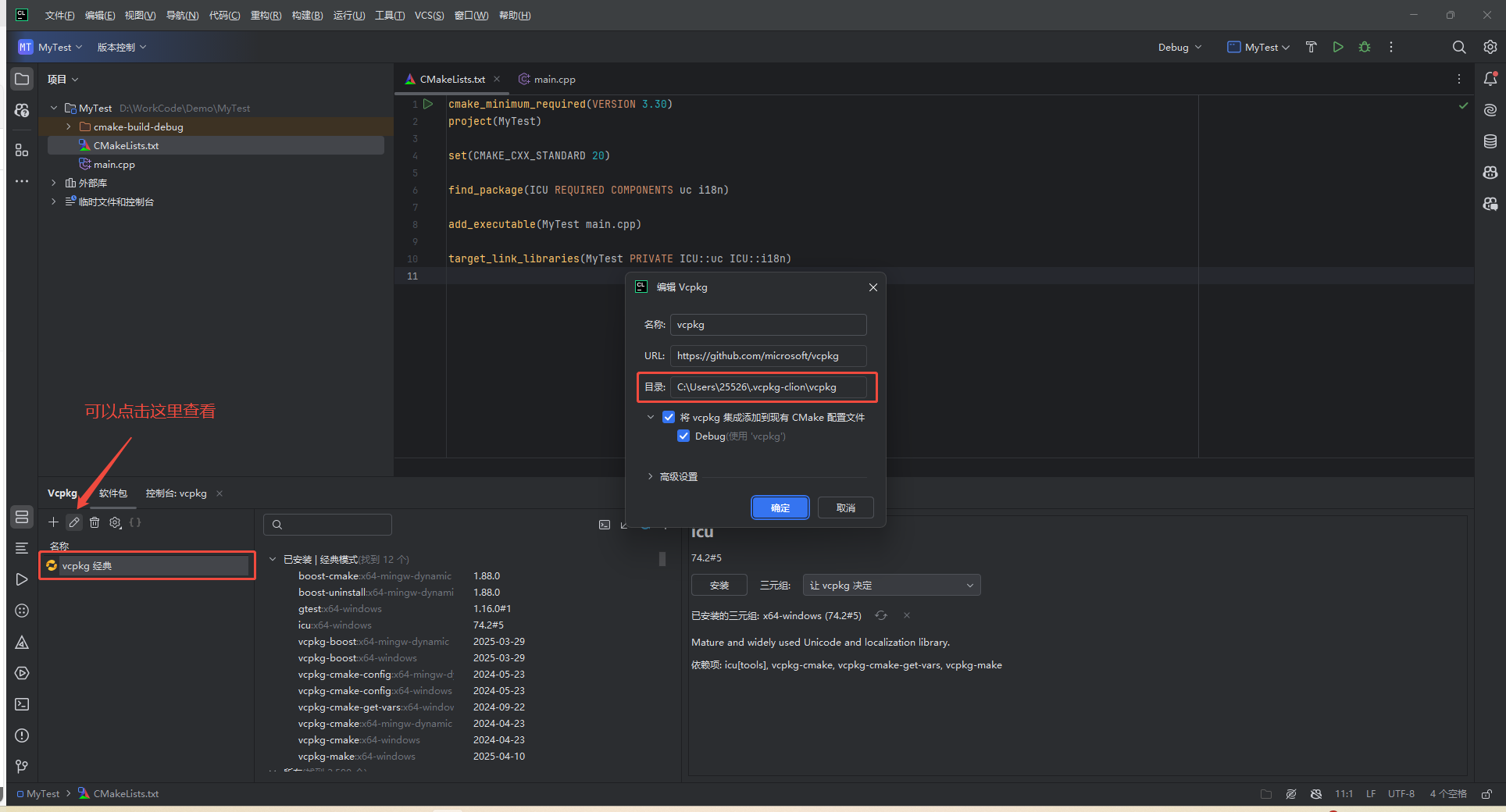
1.通过 vcpkg 安装 ICU(这里使用的是经典模式,并不是清单模式)
vcpkg install icu
2.如果是 macOS,可直接使用 Homebrew 安装:
brew install icu4c
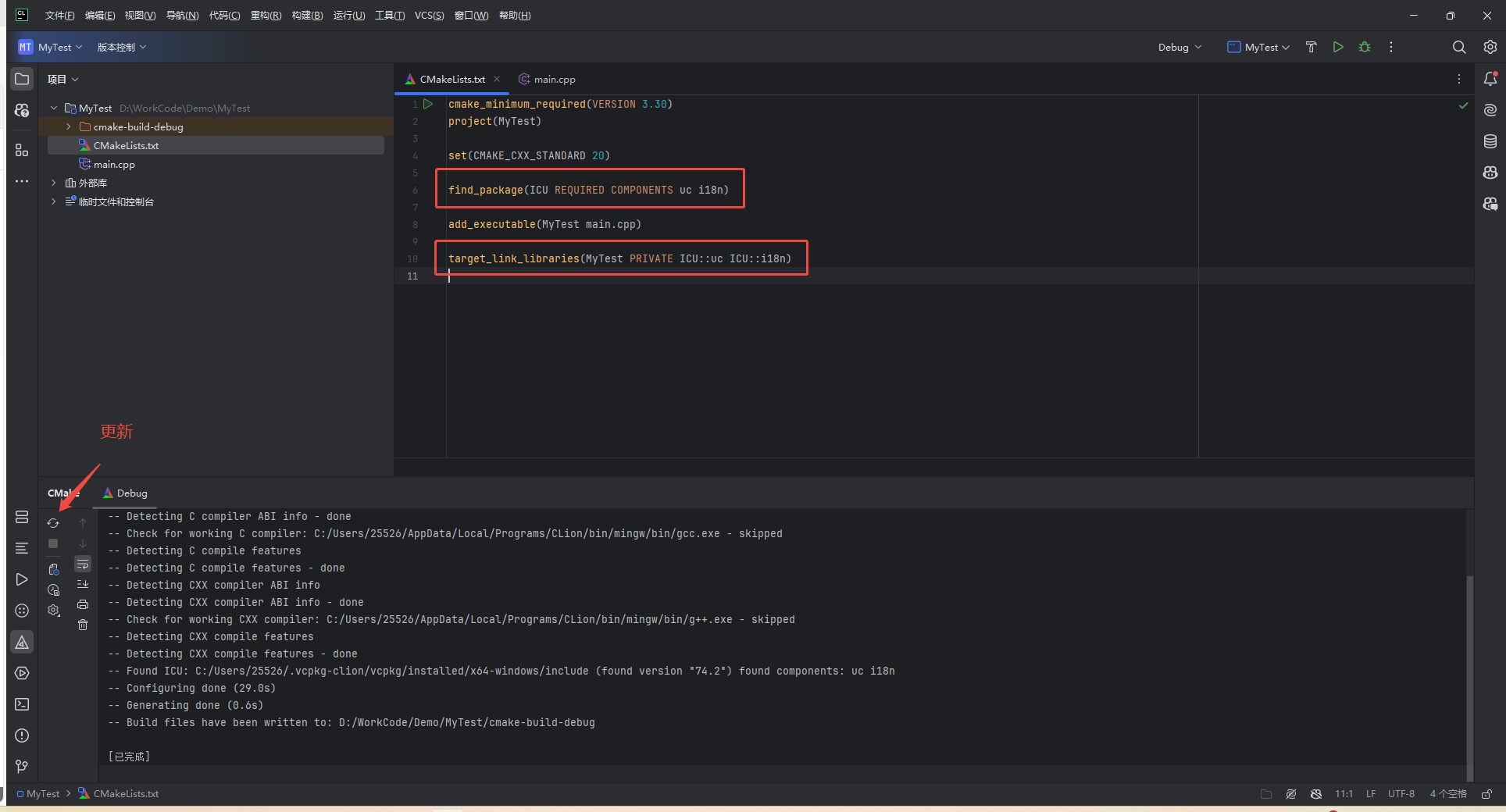
3.在 CMakeLists.txt 中添加(如果报错请查看下面的解决办法):
find_package(ICU REQUIRED COMPONENTS uc i18n)add_executable(MyTest main.cpp)target_link_libraries(MyTest PRIVATE ICU::uc ICU::i18n)
4.设置 toolchain 确保 vcpkg 仅用作 toolchain
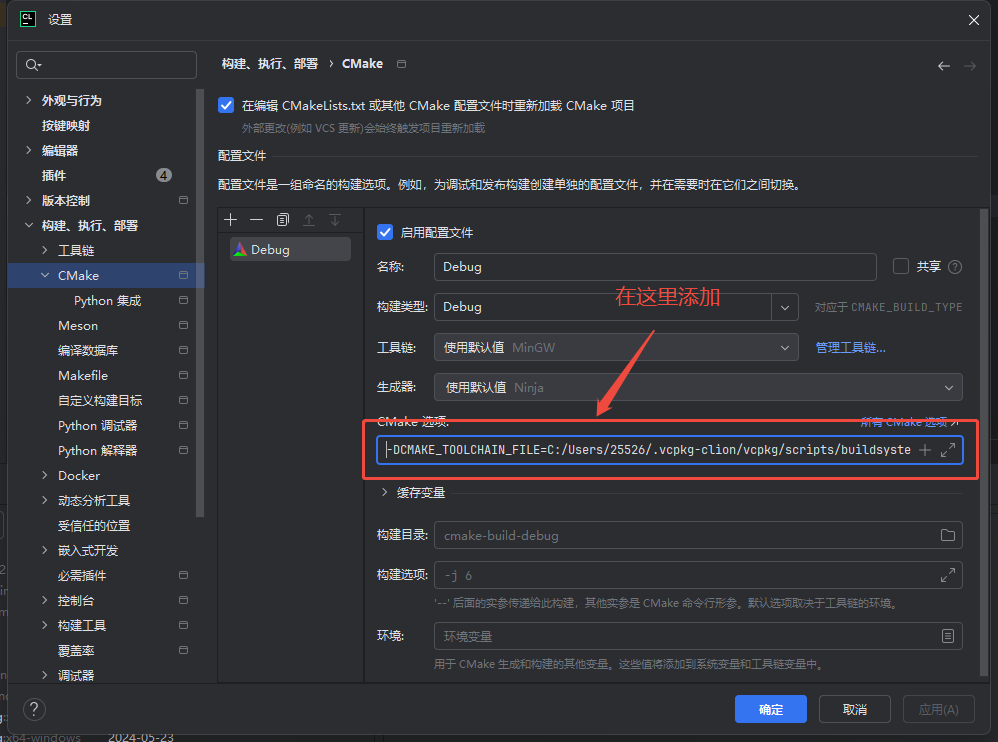
比如在 CLion CMake选项里添加(注意自己的路径):
-DCMAKE_TOOLCHAIN_FILE=C:/path/to/vcpkg/scripts/buildsystems/vcpkg.cmake
5.如果报 ICU_INCLUDE_DIR 缺失错误:
- 确保 vcpkg 使用正确目录
- 确保 ICU安装完整
- 确保使用正确版本的 CMake (3.20+)
ICU遇到的问题:
问题 1:接口复杂,需要实现类型转换 (UConverter API)
解决:实现 convertFileToUTF8 函数,转换完成编码统一
问题 2:检测ISO-8859-1错误,实际是UTF-8保存
解决:增加自定义校验:如果全部是ASCII(比如 0x00 ~ 0x7F),直接当作UTF-8处理
if (encoding == "ISO-8859-1" || encoding == "windows-1252") {if (isPureAscii(buffer)) {encoding = "UTF-8";}
}
问题 3:Windows控制台不支持UTF-8输出,显示乱码
解决:使用 Windows API 切换编码页:
SetConsoleOutputCP(CP_UTF8);
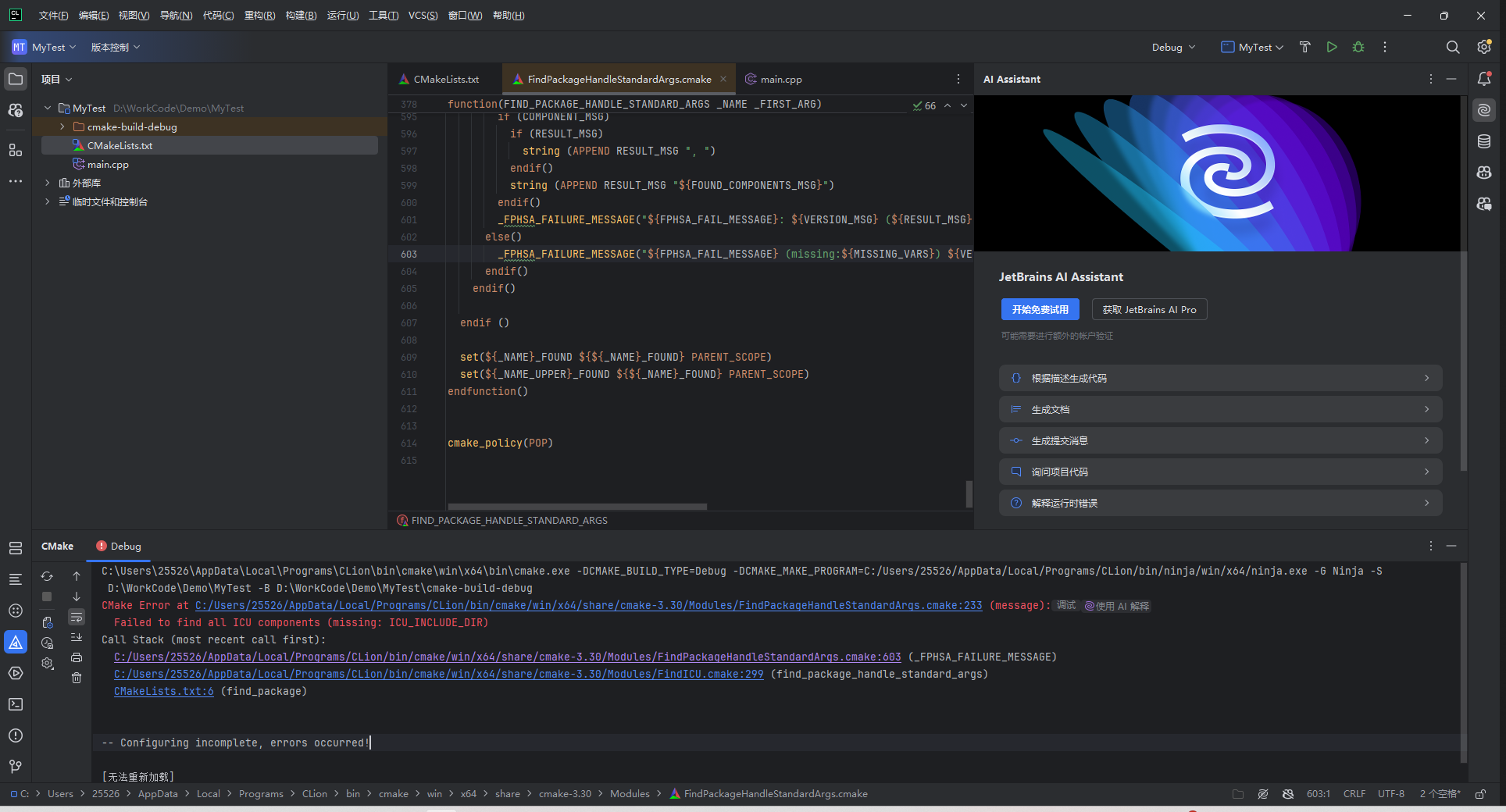
问题4:ICU_INCLUDE_DIR 缺失错误
解决:设置 CMake Toolchain File,确保通过 vcpkg 正确寻找 ICU
🎯 错误本质
如果已经用 vcpkg 装好了 ICU。
但是在 CMake configure阶段,CMake没有正确通过 vcpkg 找到 ICU 的路径。
也就是说:没有告诉 CMake:去 vcpkg 里面找!🔥 为什么会这样?
因为 CLion 默认 CMake 配置,没有指定 vcpkg toolchain!
vcpkg 是需要在 CMake 配置阶段主动加一个参数,让 CMake知道怎么找库的。
问题 5:ICU版本不一致,导致符号找不到
原因:
- 旧编译器或环境与新版ICU不配套,导致不能找到出另外API
解决:
- 在 vcpkg.json 中锁定 ICU 版本,例如 73.2
- 在 CMake 中指定 ICU 版本:
find_package(ICU 73.2 REQUIRED COMPONENTS uc i18n)
问题 6:打包部署时找不到 ICU 动态库
原因:
- ICU 默认使用动态链接,如
.so/.dylib - 部署时未拷贝相关动态库
解决:
- 使用静态链接:
vcpkg install icu:x64-linux-static
- 或者设置 rpath,确保运行时找到库:
set(CMAKE_INSTALL_RPATH_USE_LINK_PATH TRUE)
五、支持系统默认编码与任意编码互转
在实际场景中,不是所有情况下都需要统一转成UTF-8:
- 旧项目需要转成GBK(如Windows环境)
- 日本系统需要转成Shift-JIS
- Linux 下需要转成当前locale指定编码
1.读取系统默认编码
#include <locale>
#include <string>std::string getSystemEncoding() {
#ifdef _WIN32// 注意这里是系统ANSI代码页,不是控制台的UINT codePage = GetACP();return "CP" + std::to_string(codePage);
#elsestd::locale loc("");return loc.name();
#endif
}
根据返回的 locale 名,可转换成 ICU 支持的编码名称。也可以做一个映射表:
std::string fixEncodingName(const std::string& encoding) {if (encoding == "CP936") return "GBK";if (encoding == "CP65001") return "UTF-8";return encoding;
}
2.全局指定目标编码
可以设置一个全局变量:
std::string g_targetEncoding = "UTF-8"; // 默认转成UTF-8,也可根据系统设置
在编码转换时,使用这个 targetEncoding,而不是固定写 “UTF-8”。
3.扩展编码转换函数
将原 convertFileToUTF8 扩展成:
bool convertFileEncoding(const std::string& inputPath, // 输入文件路径const std::string& outputPath, // 输出文件路径const std::string& srcEncoding, // 输入文件的编码格式const std::string& dstEncoding // 输出转换成的目标编码格式
);
bool convertFileEncoding(const std::string& inputPath, const std::string& outputPath,const std::string& srcEncoding, const std::string& dstEncoding) {UErrorCode status = U_ZERO_ERROR;UConverter* srcConv = ucnv_open(srcEncoding.c_str(), &status);UConverter* dstConv = ucnv_open(dstEncoding.c_str(), &status);if (U_FAILURE(status)) {if (srcConv) ucnv_close(srcConv);if (dstConv) ucnv_close(dstConv);return false;}std::ifstream inFile(inputPath, std::ios::binary);std::vector<char> inputBuffer((std::istreambuf_iterator<char>(inFile)), std::istreambuf_iterator<char>());std::vector<char> outputBuffer(inputBuffer.size() * 4);const char* src = inputBuffer.data();const char* srcLimit = src + inputBuffer.size();char* dst = outputBuffer.data();char* dstLimit = dst + outputBuffer.size();ucnv_convertEx(dstConv, srcConv,&dst, dstLimit,&src, srcLimit,nullptr, nullptr,nullptr, nullptr,true, true,&status);if (U_FAILURE(status)) {ucnv_close(srcConv);ucnv_close(dstConv);return false;}std::ofstream outFile(outputPath, std::ios::binary);outFile.write(outputBuffer.data(), dst - outputBuffer.data());ucnv_close(srcConv);ucnv_close(dstConv);return true;
}
编码转换的目标,可以自由指定(UTF-8,GBK,Shift-JIS,ISO-8859-1)。
// 遍历处理文件夹
void processFolder(const std::string& folderPath) {int totalFiles = 0;int needConvertFiles = 0;int successConvertFiles = 0;int failConvertFiles = 0;// 获取当前系统的默认编码std::string systemEncoding = getSystemEncoding();std::cout << "当前系统默认字符集: " << systemEncoding << std::endl;for (const auto& entry : fs::recursive_directory_iterator(folderPath)) {if (entry.is_regular_file()) {totalFiles++;std::string filePath = entry.path().string();// 读一段内容std::ifstream file(filePath, std::ios::binary);std::vector<char> buffer(4096);file.read(buffer.data(), buffer.size());std::streamsize bytesRead = file.gcount();std::string srcEncoding = detectEncodingICU(filePath);// 修正 ISO-8859-1 的检测误判(如果内容是ASCII,强制归为UTF-8)if (srcEncoding == "ISO-8859-1" || srcEncoding == "windows-1252") {if (isPureAscii(buffer)) {srcEncoding = "UTF-8";}}std::cout << "文件: " << filePath << " -> 检测编码: " << srcEncoding << std::endl;if (srcEncoding != systemEncoding) {needConvertFiles++;std::string outputPath = filePath + ".converted.txt";if (convertFileEncoding(filePath, outputPath, srcEncoding, systemEncoding)) {successConvertFiles++;std::cout << "✅ 转换成功: " << outputPath << " (" << srcEncoding << " -> " << systemEncoding << ")" << std::endl;} else {failConvertFiles++;std::cout << "❌ 转换失败: " << filePath << std::endl;}}}}// 输出总结std::cout << "\n====== 扫描总结 ======\n";std::cout << "总扫描文件数: " << totalFiles << "\n";std::cout << "需要转换的文件数: " << needConvertFiles << "\n";std::cout << "成功转换: " << successConvertFiles << "\n";std::cout << "转换失败: " << failConvertFiles << "\n";std::cout << "=======================\n";
}
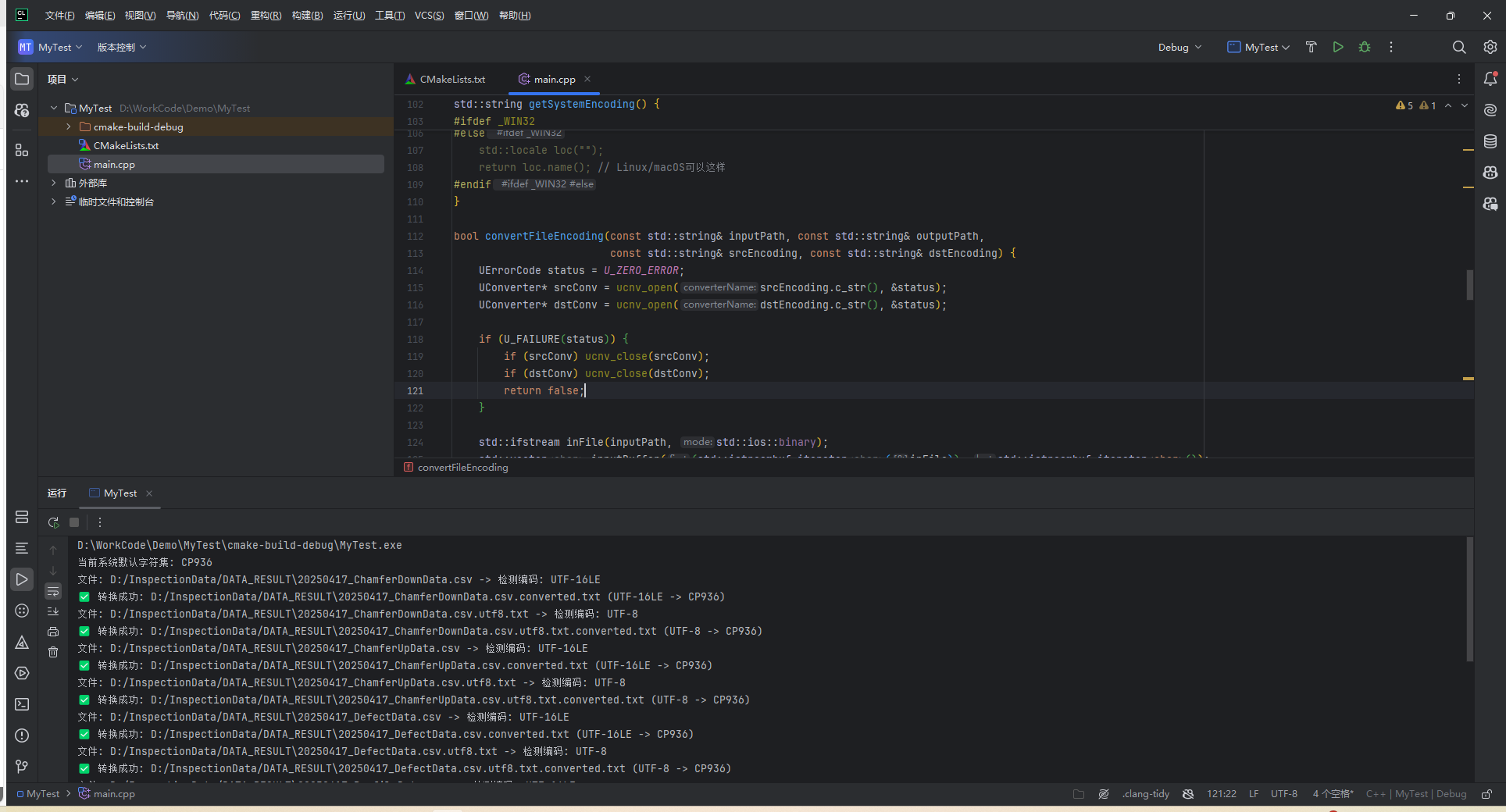
4.效果流程
- ICU检测来源编码
- 获取系统locale(或用户指定编码)
- 对比,如果不一致,执行转换
这样,可以适配各种系统和项目实际需求!
六、总结
经过这些步骤,我完成了一套实用系统:
- 连续检测所有文件编码
- 需要时统一转换为UTF-8
- 自动处理特殊编码错别情况
- 控制台没有乱码,可以直接看到正确日志
ICU的全面支持,使得我的编码检测和处理较乎完善,在处理实际工程中非常有效!