0.简介
本推文介绍北京通用人工智能研究院和北京大学共同撰写的一篇发表于ECCV 2024的论文《VideoAgent: A Memory-augmented Multimodal Agent for Video Understanding》。该论文提出了一种新颖的工具化多模态视频理解框架VideoAgent,该框架通过统一记忆机制(Temporal Memory和Object Memory)与工具调用,实现了长视频中的高效推理与问题解答。论文展示了VideoAgent的灵活性和零样本泛化能力,在多个测试集基准(EgoSchema、Ego4D NLQ、WorldQA和NExT-QA)上超越现有方法,表现优秀。VideoAgent采用了简化的工具调用流程,无需昂贵训练即可达到强大的性能,未来有望在机器人、增强现实等领域的实际场景中发挥重要作用。
推文作者为黄星宇,审校为许东舟和邱雪。
论文链接:https://arxiv.org/abs/2403.11481
代码链接:https://videoagent.github.io
1.研究背景
视频理解是计算机视觉与人工智能领域的关键问题,广泛应用于视频问答、事件检索和行为分析等场景。然而,长视频中复杂的时空依赖关系、丰富的事件序列和多模态信息使得理解任务极具挑战性。现有方法(如端到端多模态大模型)在处理长视频时存在计算开销高、内存需求大、长时序推理能力有限等问题,难以在复杂任务中提供高效且准确的解答。
论文提出了 VideoAgent智能体,通过引入创新的统一记忆机制(时间记忆和对象记忆)来结构化表示视频中的时序事件和对象状态,并结合灵活的多模态工具调用框架,实现了高效的长视频理解。该方法显著提升了视频中长时空推理的能力,降低了计算成本,同时支持复杂的视频问答和内容检索任务。
2.方法

图1 VideoAgent和端到端多模态大模型在视频问题回答上的比较
图1展示了不同模型在回答“视频中有多少艘船?”这一问题时的性能对比。通过分析视频片段,VideoAgent利用Object Memory中的数据库执行查询(如SQL查询语句),精准统计了视频中出现的独立船只数量(6艘)。相比之下,其他端到端多模态大模型如mPLUG-Owl 和Video-LLAVA对该问题的回答(分别为2艘和3艘)不够准确,说明了VideoAgent在多帧信息整合、对象跟踪与去重分析方面的显著优势。
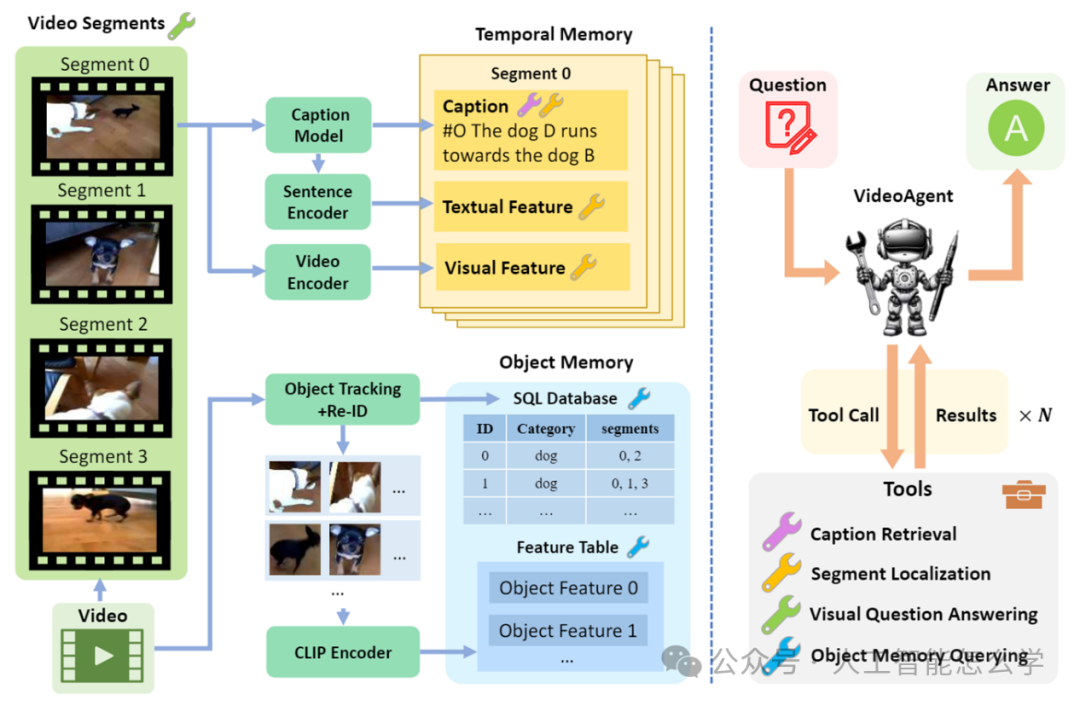
图2 VideoAgent的概述
2.1 视频分段与记忆构建
VideoAgent首先将输入的长视频划分为若干小片段,每段通常持续约2秒。这种分段方法减少了长视频处理的计算复杂度,同时捕捉了时间局部的信息。
为实现视频的结构化表示,VideoAgent构建了统一记忆机制,包括时间记忆(Temporal Memory)和对象记忆(Object Memory):
(1) 时间记忆(Temporal Memory)
时间记忆通过多模态数据表示每个视频片段的时间动态和语义内容:
字幕生成:使用字幕生成模型为每段视频生成自然语言描述(例如,“狗跑向另一只狗”)。
文本编码:将字幕通过句子编码器转化为语义嵌入,便于后续查询与推理。
视觉特征提取:通过视频编码器提取帧级别的视觉特征,提供时间轴上的精确信息。
时间记忆的结构化数据包括字幕文本、文本嵌入和视觉特征。
(2) 对象记忆(Object Memory)
对象记忆用于捕捉视频中对象的动态信息,支持对象级别的推理任务:
对象跟踪与重识别:通过对象跟踪和重识别技术,确保跨帧对象的唯一性,避免重复计数。
特征提取:使用CLIP编码器提取对象的多模态特征嵌入。
数据库存储:构建SQL数据库,存储对象的类别、时间片段、特征表等信息。
通过统一记忆机制,VideoAgent将视频内容组织为结构化的多模态数据,支持高效的推理和查询。
2.2 工具化推理与答案生成
VideoAgent采用模块化的工具化推理框架,根据用户的自然语言问题动态调用工具,从记忆中提取相关信息并生成答案。
(1) 工具调用流程
根据用户输入问题,VideoAgent 调用以下工具:
字幕检索工具:从时间记忆中提取字幕信息,用于处理语言相关任务。
片段定位工具:根据问题关键词或语义匹配,从视频中定位相关的时间片段。
视觉问答工具:分析指定片段中的视觉内容以解答视觉问题。
对象记忆查询工具:通过 SQL 查询对象记忆中的数据,用于对象数量统计、分类和轨迹查询。
(2) 答案生成
VideoAgent整合多轮工具调用的中间结果,生成最终答案:
中间结果整合:聚合字幕、视觉特征或对象查询的结果。
答案输出:基于整合结果,生成符合自然语言的最终回答。
例如,用户提问“视频中有几艘船?”,VideoAgent会首先定位包含“船”的片段,然后查询对象记忆中的SQL数据库,去重统计船只数量,并输出答案。
3.实验结果
为了验证所提出方法的有效性,论文在四个常用的公开数据集(EgoSchema、Ego4D NLQ、WorldQA和NExT-QA)上进行实验。
3.1 EgoSchema
表1 EgoSchema数据集的准确度

表1比较了不同模型在 EgoSchema 数据集(完整集和子集)上的性能表现。对于完整数据集,VideoAgent 的得分为 60.2,仅次于表现最好的 Gemini 1.5 Pro(63.2),显示了其优越的长视频理解能力。在子集测试中(500个问题),VideoAgent 的得分为 62.8,超越了所有其他模型(如 LLoVi 的 51.8 和 mPLUG-Owl 的 33.8),进一步凸显了其在多模态推理任务中的强大表现。
3.2 Ego4D NLQ
表2 Ego4D NLQ验证集上不同工具和 VideoAgent 之间的比较
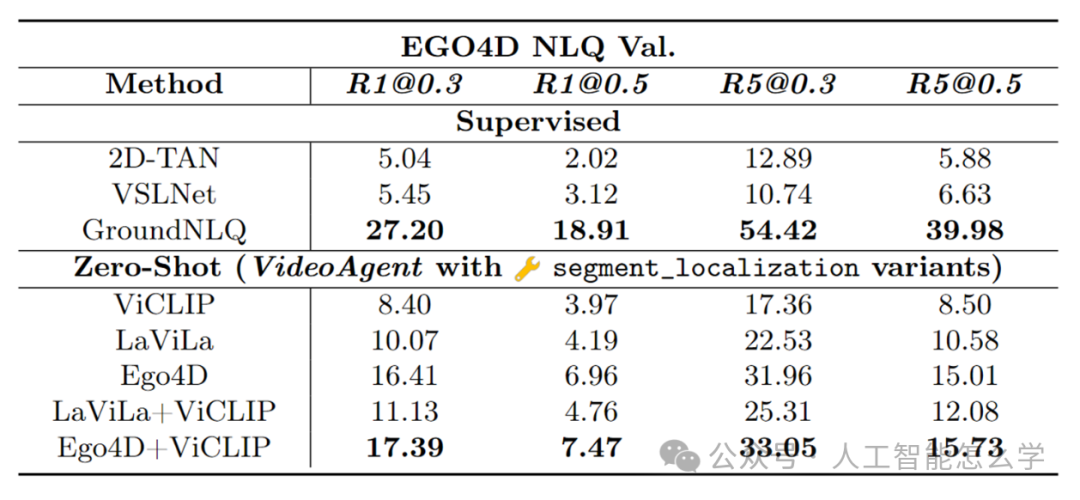
表2对比了 Ego4D NLQ验证集上监督学习方法和零样本(Zero-Shot)方法的性能表现。对于监督学习方法,GroundNLQ表现最佳,例如在R1@0.3(前1个预测中IoU≥0.3的准确率)上达到了27.20,在R5@0.3(前5个预测中IoU≥0.3的准确率)上达到54.42。而在零样本条件下,VideoAgent使用不同的特征提取器(如ViCLIP、LaViLa、Ego4D等)展现了强大的泛化能力,其中Ego4D + ViCLIP的组合特征取得了最佳表现,R1@0.3达到17.39,R5@0.3达到33.05。这表明VideoAgent在无需标注数据的情况下,通过灵活的工具化设计与高效特征提取器,能够在复杂的视频理解任务中接近监督方法的性能。
3.3 WorldQA
表3 WorldQA的结果

表3展示了不同方法在WorldQA数据集上的表现,分为两种任务类型:开放式问答 (Open-Ended)和多选(Multi-Choice)。可以看到,VideoAgent方法在两种任务类型上都表现最优,其中开放式问答的分数为32.53,仅次于GPT-4V的35.37;而在多选任务中,VideoAgent的分数为39.28,明显高于其他方法,尤其相比Video-LLLaMA的4.81和Video-ChatGPT的 13.25,优势显著。这表明VideoAgent在理解多模态信息和回答复杂问题上具备强大的能力,特别是在多选任务中体现了明显的提升。
3.4 NExT-QA
表4 NExT-QA的结果
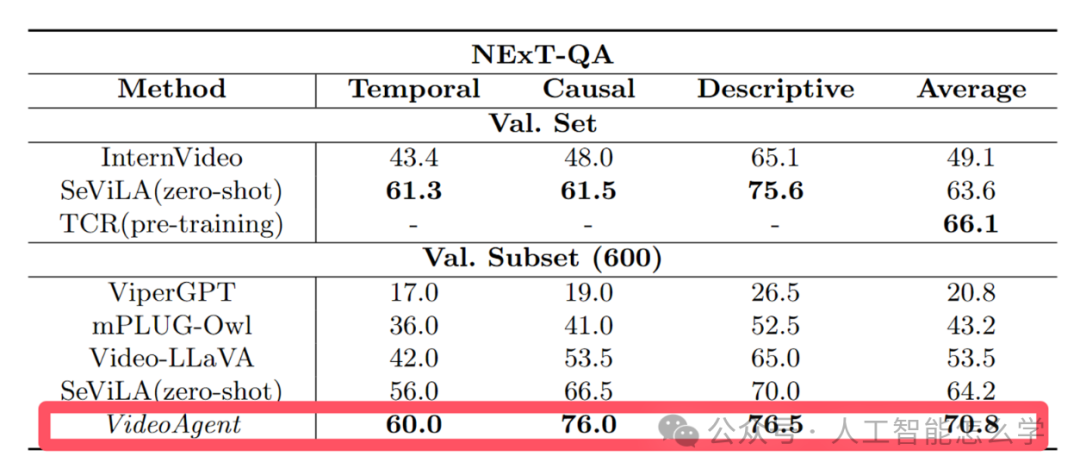
表4展示了不同方法在NExT-QA数据集上的表现,分为三种任务类型:时间推理 (Temporal)、因果推理 (Causal)和描述性问题 (Descriptive),同时还计算了平均分数。结果显示,VideoAgent在所有任务和平均分上均取得了最优表现,其中时间推理得分60.0,因果推理得分76.0,描述性问题得分76.5,平均得分70.8。相比其他方法,如SeViLA的平均得分64.2和Video-LLLaVA的53.5,VideoAgent显示出了显著的优势,尤其是在因果推理和描述性问题上,体现了其在多模态理解和复杂问题回答上的强大能力。
表5 VideoAgent在NExT-QA子集上消融实验

表5比较了不同方法和设置在多模态任务中的表现,具体包括时间推理 (Temporal)、因果推理(Causal)和描述性问题(Descriptive)的得分,以及平均分(Avg.)。表格中的方法依赖于是否具备VQA(视觉问答)、Grounding(目标定位)、Captions(生成字幕)以及数据库(是否使用带有 re-ID 的数据库)。
从结果来看:
-
GPT-4V(Type1)取得了最佳表现,平均分74.7,在所有任务中分数均领先,体现了其强大的综合能力。
-
Video-LLLaVA(Type2)在开启re-ID数据库的情况下平均分71.3,次于GPT-4V,但显著优于没有re-ID数据库的配置(Type3、Type5)。
-
不使用数据库或其他组件(Type6)的配置得分最低,平均分40.7,显示出数据库和多模态组件对性能的关键作用。
4.总结
该论文提出了VideoAgent智能体,结合了多个基础模型和统一记忆机制,用于视频理解。与端到端多模态大模型和其他工具化智能体相比,VideoAgent采用了简化的工具使用流程,无需昂贵的训练,同时在EgoSchema、Ego4D NLQ、WorldQA和NExT-QA等长视频理解基准上表现出色。未来方向包括探索其在机器人、制造业和增强现实等实际场景中的应用。