1 文章信息
文章名为PromptCast: A New Prompt-based Learning Paradigm for Time Series Forecasting。于2023 年 12 月 13 日发表在 IEEE Transactions on Knowledge and Data Engineering(TKDE),作者来自澳大利亚的新南威尔士大学,被引83次。
2 摘要
本文提出了一种用于时间序列预测的新视角。在现有方法中,模型使用数值序列作为输入并输出预测值。现有的SOTA模型通常基于Transformer架构,改进后能够融入上下文和语义信息。受预训练语言模型成功的启发,本文探讨了是否可以将这些模型应用于时间序列预测,提出了一种新的预测范式:基于提示的时间序列预测(PromptCast)。在该任务中,数值输入和输出被转换为提示,预测任务被表述为句子间的转换,使得可以直接应用语言模型来进行预测。为了支持这一研究,作者还提出了一个大规模的数据集(PISA),包含三个真实世界的预测场景。实验结果表明,PromptCast具有比传统方法更好的泛化能力,尤其是在零样本设定下。
3 简介
时间序列预测是一个研究密集的领域,尤其是在应用各种基于深度学习的框架进行预测方面,例如基于LSTM 、时间卷积网络(TCN) 和Transformer 的模型。最近,我们正在见证自然语言处理(NLP)领域的大规模预训练模型的快速增长。然而,我们也注意到,这种发展似乎主要限于NLP和CV领域。因此,我们特别感兴趣的是探讨是否可以利用大规模预训练基础模型并适配这些模型来预测时间序列。为了解决这个问题,本文我们首次介绍了一个新的任务:基于提示的时间序列预测(PromptCast)。现有的预测方法,包括最先进的基于Transformer的预测模型,可以简化为如图1(a)所示的数值预测范式。数值预测方法总是采用数值作为输入并生成数值作为下一个时间步的预测结果。相反,基于提示的预测(图1(b))的输入和输出是自然语言序列。这一范式使语言生成模型能够用于预测。
这个新的预测范式在多个方面具有优势。PromptCast 提供了一种新的“无代码”解决方案,用一种新的视角预测时间序列,而不是纯粹专注于设计越来越复杂的深度学习预测模型(例如,基于Transformer的Informer、Autoformer 和FEDformer)。这是首次从语言基础模型的角度出发,探索面向时间序列预测的一般方法,而无需对模型架构进行任何修改。这项任务使用了第一个大规模数据集PISA(Prompt-based Time Series Forecasting),涵盖多种时间序列预测场景。它涵盖了三个真实世界的预测场景:天气温度预测、能源消耗预测以及客户行为预测。我们还开发了一个基准测试,在该基准中报告了预测方法的性能。为了评估PromptCast的泛化能力,该基准还探索了多种预测设置,例如从头开始训练、零样本预测、多步预测和多变量预测。总之,我们的贡献有三点:(1)我们提出了一种新的基于提示的预测范式,它不同于现有的预测方法。这是第一次用自然语言生成的方式解决时间序列预测问题。(2)我们发布了一个大规模数据集PISA,其中包含总共311,932条数据实例,涵盖了多个时间序列预测场景。(3)我们开发了一个基准,用于评估PISA数据集上最先进的数值预测方法和流行的语言生成模型。
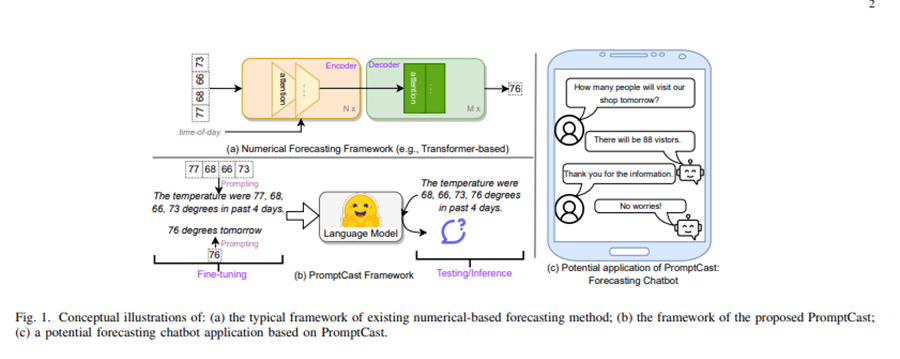
4 问题描述
<1 style="color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;letter-spacing: 1px;text-wrap: wrap;">1><1 style="color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;letter-spacing: 1px;text-wrap: wrap;">基于提示的时间序列预测任务是从一般的时间序列任务发展而来的。Prompt1><1 style="color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;letter-spacing: 1px;text-wrap: wrap;">1><1 style="color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;letter-spacing: 1px;text-wrap: wrap;">Cast任务的总体目标是利用语言基础模型通过句子到句子的方式进行时间序列预测。为实现这一目标,基于上面提出的数值时间序列预测形式,数值需要被转换并描述为自然语言句子。这种数据到文本的转换称为本研究中的提示过程(提示的具体细节将在下一节中介绍)。具体来说,输入的数值序列被转化为输入提示,预测目标值则转化为输出提示。因此,时间序列预测可以通过自然语言生成范式进行,而语言基础模型可以作为PromptCast任务的核心预测模型1><1 style="color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;letter-spacing: 1px;text-wrap: wrap;">。1>
<1 style="color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;letter-spacing: 1px;text-wrap: wrap;">1><1 style="color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;letter-spacing: 1px;text-wrap: wrap;">5 PISA数据1><1 style="color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;letter-spacing: 1px;text-wrap: wrap;">1>
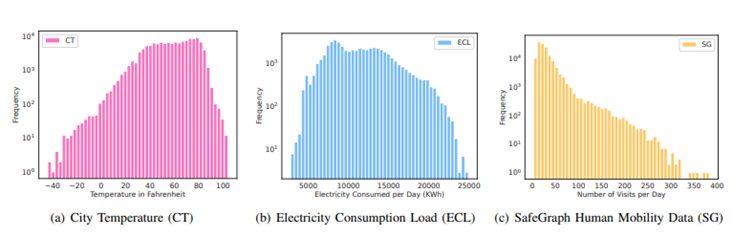
本文所使用的数据来自三个方面,分别是天气温度数据、电力消耗数据、人类移动数据,这三种数据内容丰富,包含负数,数值度量差异较大
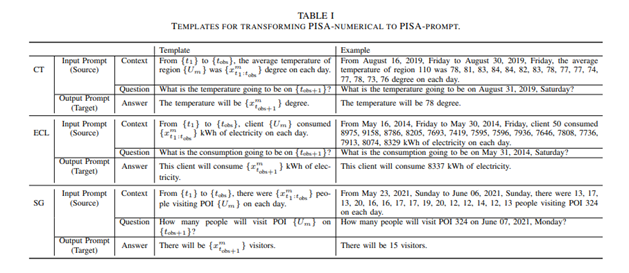
<1 style="color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;letter-spacing: 1px;text-wrap: wrap;">因为是进行句-句的模型训练,因此要将原来的数字型数据转化为语言型数据,本文使用固定的语言模板将数据处理为包含数据的语言1>
<1 style="color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;letter-spacing: 1px;text-wrap: wrap;">6实验部分1>
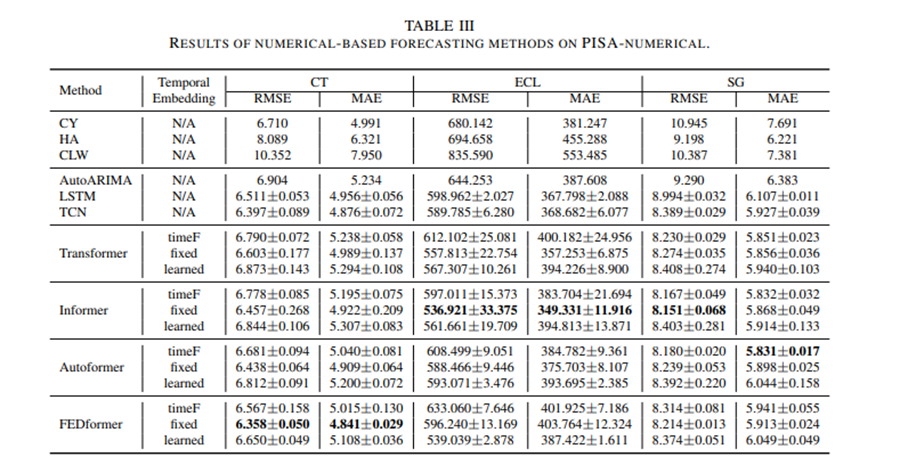
6.1数字-数字的SOTA模型
本文先是使用PISA数据在若干数字-数字的模型上进行测试,所选模型中包含Copy Yesterday(CY), Historical Average (HA), and Copy Last Week (CLW),LSTM,AutoARIMA, and temporal convolutional network (TCN). 以Transformer为基础的包括 Transformer , Informer , Autoformer, and FEDformer
。
6.2基于PromptCast方法的语言模型预测
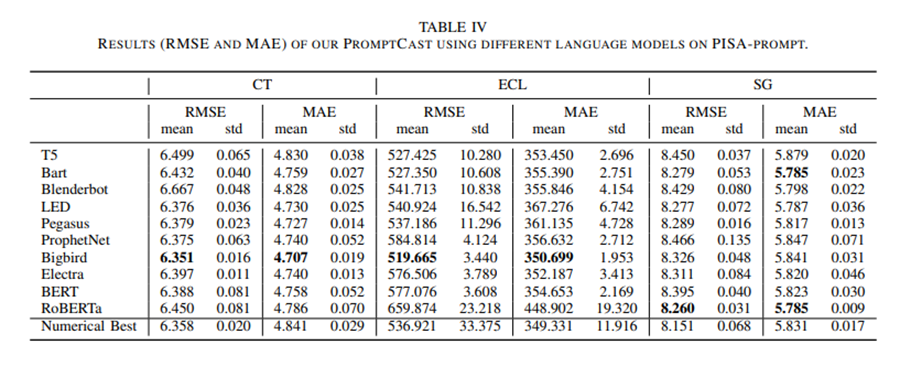
<1 style="color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;letter-spacing: 1px;"><1 style="text-wrap-style: initial;"> 本文选取了10个语言模型进行测试,这10个语言模型分别为属于EncoderDecoderModel框架的BERT,RoBERTa,Electra.和ConditionalGeneration框1>1><1 style="letter-spacing: 0.578px;text-wrap-mode: wrap;"><1>1>1><1 style="letter-spacing: 0.578px;text-wrap-mode: wrap;"><1>架的bird1>1><1 style="letter-spacing: 0.578px;text-wrap-mode: wrap;"><1>,Blenderbot,Pegasus,T5,Bart1>1><1 style="text-indent: 2em;color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;letter-spacing: 1px;"><1 style="text-wrap-style: initial;">,<1 style="text-align: left;text-indent: 34px;"><1 style="text-wrap-style: initial;">LED 1>1><1 style="text-align: left;text-indent: 2em;"><1 style="text-wrap-style: initial;">ProphetNet1>1>1>1><1 style="text-indent: 2em;color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;letter-spacing: 1px;"><1 style="text-wrap-style: initial;"><1 style="text-align: left;text-indent: 2em;"><1 style="text-wrap-style: initial;">1>1>。1>1><1 style="text-indent: 2em;color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;letter-spacing: 1px;"><1 style="text-wrap-style: initial;">从结果来看本文所提出的PromptCast方法的精度基本优于现有数字-数字模型。1>1><1 style="text-indent: 2em;color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;letter-spacing: 1px;"><1 style="text-wrap-style: initial;">1>1>
<1 style="text-indent: 2em;text-align: justify;color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;letter-spacing: 1px;text-wrap-style: initial;"><1 style="text-wrap-style: initial;">1>1>
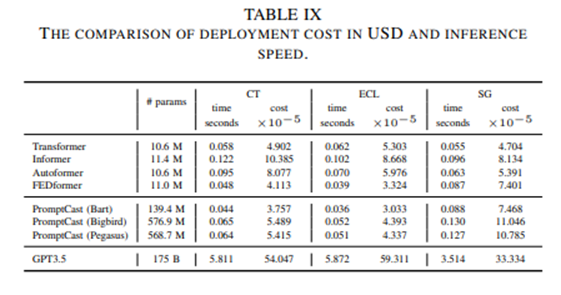
现有的利用语言模型预测方法中,预测所消耗的时间也是一个十分重要的考量,本文所提出的方法预测方法与现有SOTA模型相当。
6.3从零训练和Zero-shot表现
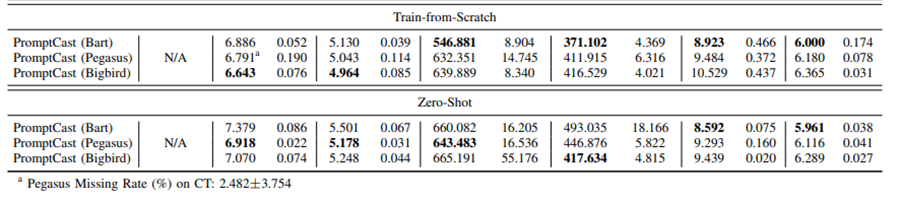
作者探讨了在不使用预训练权重的情况下,语言模型能否仍然有效进行时间序列预测。为了验证这一点,此部分研究取消了预训练权重,使用PISA数据集的训练集从头开始训练语言模型。选取了表现优秀的三个语言模型:Bart、Pegasus和Bigbird。实验结果表明,不使用预训练权重时,各个方法的预测性能都有所下降,表明预训练权重确实能进一步提高性能。然而,即使在没有预训练的情况下,像Bart这样的语言模型仍能提供可比较的预测结果,说明PromptCast具有稳健性,不完全依赖于预训练权重。尽管从头开始训练的模型能够产生可接受的预测,使用预训练权重的模型在提升预测性能方面显然有更大的优势。不同模型对预训练权重的依赖程度不同,例如Bart受影响较小,而Pegasus和Bigbird的性能下降则更为显著。
为了进一步探索语言模型在PromptCast中的应用,研究还进行了零样本预测实验。具体来说,分别对两个子集进行微调,然后测试其在第三个子集上的性能,类似地,Transformer-based模型也在相同的零样本设置下进行了评估。结果表明,在这种困难的设置下,固定嵌入(fixed embedding)在6个指标中的5个上表现最佳,而可学习的嵌入(learned embedding)在遇到未见过的场景时表现较差,特别是时间序列的时间嵌入在新的场景下不适用。
此外,除在ECL数据集上的Autoformer和FEDformer模型外,数值预测方法在零样本设置下的表现也不理想。与此相对,语言模型的表现虽然低于标准设置下的表现,但在零样本设置下依然能够产生合理的预测,展示了其较强的泛化能力。
<1 style="color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;letter-spacing: 1px;text-wrap: wrap;"><1 style="color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;letter-spacing: 1px;text-wrap: wrap;"><1 style="color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;letter-spacing: 1px;text-wrap: wrap;">1>1>1><1 style="color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;letter-spacing: 1px;text-wrap: wrap;"><1 style="color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;letter-spacing: 1px;text-wrap: wrap;"><1 style="color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;letter-spacing: 1px;text-wrap: wrap;"><1 style="color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;letter-spacing: 1px;text-wrap: wrap;">7 1>1>1>1><1 style="color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;letter-spacing: 1px;text-wrap: wrap;"><1 style="color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;letter-spacing: 1px;text-wrap: wrap;"><1 style="color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;letter-spacing: 1px;text-wrap: wrap;">总结1>1>1>
<1 style="color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;letter-spacing: 1px;text-wrap: wrap;">1>本文提出一种创新方法使用包含时序数据的句-句数据来微调大模型,并比对其与数字-数字模型以及不同语言模型的效果,证明了本文所提出方法的有效性。同时本文所提出的PISA数据也为后续更加广泛的研究提供了基础。