Logistic Regression(逻辑回归)是一种用于处理二分类问题的统计学习方法。它基于线性回归 模型,通过Sigmoid函数将输出映射到[0, 1]范围内,表示概率。逻辑回归常被用于预测某个实 例属于正类别的概率。
一、数据集介绍
本例使用了一个的蘑菇数据集 Mushroom - UCI Machine Learning Repository 该数据集包含对23种有褶菌的蘑菇进行描述的假设样本。每个物种被确定为绝对可食用、绝对 有毒。后者的类别与有毒物种合并。即二元分类有毒和没毒。
数据集地址
Mushroom - UCI Machine Learning Repository
| 变量名称 | 角色 | 类型 | 描述 | 单位 | 缺失值 |
|---|---|---|---|---|---|
| 有毒 | 目标 | 分类 | 不 | ||
| Cap-Shape (盖形) | 特征 | 分类 | 钟 = b,圆锥 = c,凸 = x,扁平 = f,旋钮 = k,下沉 = s | 不 | |
| Cap-Surface (盖板表面) | 特征 | 分类 | 纤维状 = f,凹槽 = g,鳞状 = y,光滑 = S | 不 | |
| 大写字母颜色 | 特征 | 二元的 | 棕色=n,buff=b,肉桂=c,灰色=g,绿色=r,粉红色=p,紫色=u,红色=e,白色=w,黄色=y | 不 | |
| 瘀 伤 | 特征 | 分类 | 瘀伤=t,no=f | 不 | |
| 气味 | 特征 | 分类 | 杏仁=a,茴香=l,杂酚油=c,鱼=y,污秽=f,霉味=m,无=n,辛辣=p,辣=s | 不 | |
| 鳃附件 | 特征 | 分类 | attached=a,降序=d,free=f,notched=n | 不 | |
| 鳃间距 | 特征 | 分类 | close=c,crowded=w,distant=d | 不 | |
| 鳃大小 | 特征 | 分类 | 宽=b,窄=n | 不 | |
| 鳃色 | 特征 | 分类 | 黑色=k,棕色=n,buff=b,巧克力=h,灰色=g,绿色=r,橙色=o,粉红色=p,紫色=u,红色=e,白色=w,黄色=y | 不 | |
| sstem-shape | 特征 | 分类 | 放大 = e,锥度 = t | 不 | |
| 柄根 | 特征 | 分类 | 球茎=b,俱乐部=c,杯=u,等于=e,根形体=z,rooted=r,缺失=? | 是的 | |
| stalk-surface-above-ring (茎表面在环上方) | 特征 | 分类 | 纤维=f,鳞片=y,丝滑=k,光滑=S | 不 | |
| stalk-surface-below-ring (茎表面低于环) | 特征 | 分类 | 纤维=f,鳞片=y,丝滑=k,光滑=S | 不 | |
| stalk-color-above-ring (茎颜色在环上方) | 特征 | 分类 | 棕色=n,浅黄色=b,肉桂=c,灰色=g,橙色=o,粉红色=p,红色=e,白色=w,黄色=y | 不 | |
| stalk-color-below-ring (茎颜色在环下) | 特征 | 分类 | 棕色=n,浅黄色=b,肉桂=c,灰色=g,橙色=o,粉红色=p,红色=e,白色=w,黄色=y | 不 | |
| 面纱型 | 特征 | 二元的 | 部分=p,通用=u | 不 | |
| 面纱颜色 | 特征 | 分类 | 棕色=n,橙色=o,白色=w,黄色=y | 不 | |
| 环号 | 特征 | 分类 | 无=n,一=o,二=t | 不 | |
| 环型 | 特征 | 分类 | 蜘蛛网=c,倏逝=e,扩口=f,大=l,无=n,吊坠=p,护套=s,区域=z | 不 | |
| 孢子打印颜色 | 特征 | 分类 | 黑色=k,棕色=n,buff=b,巧克力=h,绿色=r,橙色=o,紫色=u,白色=w,黄色=y | 不 | |
| 人口 | 特征 | 分类 | 丰富=a,聚集=c,数量=n,分散=s,几个=v,孤儿=y | 不 | |
| 生境 | 特征 | 分类 | 草地=g,树叶=l,草地=m,路径=p,城市=u,废物=w,树林=d | 不 |
该数据集包括对应于姬松茸和鳃蘑菇科 23 种鳃蘑菇的假设样本的描述(第 500-525 页)。每个物种都被确定为绝对可食用、绝对有毒或可食用未知,因此不推荐。后一类与有毒的一类结合在一起。该指南明确指出,确定蘑菇的可食用性没有简单的规则;没有像 Poisonous Oak 和 Ivy 的 ''leaflets three, let it be'' 这样的规则。
二、设计思路
2.1、读取数据
import pandas as pd
df=pd.read_table('agaricus-lepiota.data',header=None,sep=',')
df2.2、数据清洗
import numpy as np
df=df.replace('?',np.nan)
df.dropna(axis=0,inplace=True)2.3、划分特征
X=df.iloc[:,1:]
y=df.iloc[:,0]2.4、one-hot独热编码
X=pd.get_dummies(X)2.5、划分训练集和测试集
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test=train_test_split(X,y,train_size=0.75,random_state=42)2.6、标准化
from sklearn.preprocessing import StandardScaler
scaler=StandardScaler()
X_train_scaler=scaler.fit_transform(X_train)
X_test_scaler=scaler.transform(X_test)2.7、特征标签
from sklearn.preprocessing import LabelEncoder
labelencoder=LabelEncoder()
y_train_labelencoder=labelencoder.fit_transform(y_train)
y_test_labelencoder=labelencoder.transform(y_test)2.8、转换为Tensor张量
import torch
X_train_tensor=torch.tensor(X_train_scaler,dtype=torch.float32)
y_train_tensor=torch.tensor(y_train_labelencoder,dtype=torch.float32)
X_test_tensor=torch.tensor(X_test_scaler,dtype=torch.float32)
y_test_tensor=torch.tensor(y_test_labelencoder,dtype=torch.float32)2.9、创建数据加载器
from torch.utils.data import DataLoader,TensorDatasettrain_dataset=TensorDataset(X_train_tensor,y_train_tensor)
train_loader=DataLoader(train_dataset,batch_size=64,shuffle=True)2.10、定义逻辑回归模型
import torch.nn as nn
class LogisticRegression(nn.Module):def __init__(self,inputsize):super().__init__()self.linear=nn.Linear(inputsize,1)def forward(self,x):return torch.sigmoid(self.linear(x))
inputsize=X_train_tensor.shape[1]
model=LogisticRegression(inputsize)2.11、定义损失函数和优化器
import torch.utils
criterion=nn.BCELoss()
optimizer=torch.optim.Adam(model.parameters(),lr=0.01)2.12、训练模型
for i in range(1,101):total_loss=0model.train()for x,y in train_loader:optimizer.zero_grad()y_hat=model(x)loss=criterion(y_hat,y.view(-1,1))loss.backward()optimizer.step()total_loss+=lossavg_loss=total_loss/len(train_loader)if i%10==0 or i==1:print(i,avg_loss.item())
2.13、模型评估
from sklearn.metrics import roc_curve,auc
with torch.no_grad():model.eval()y_pred=model(X_test_tensor)fpr,tpr,threshold=roc_curve(y_test_labelencoder,y_pred.numpy())roc_auc=auc(fpr,tpr)2.14、可视化
from matplotlib import pylab as plt
plt.figure(figsize=(10, 6))
plt.plot(fpr, tpr, color='darkorange', lw=2, label=f'AUC = {roc_auc:.2f}')
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic (ROC) Curve')
plt.legend(loc='lower right')
plt.show()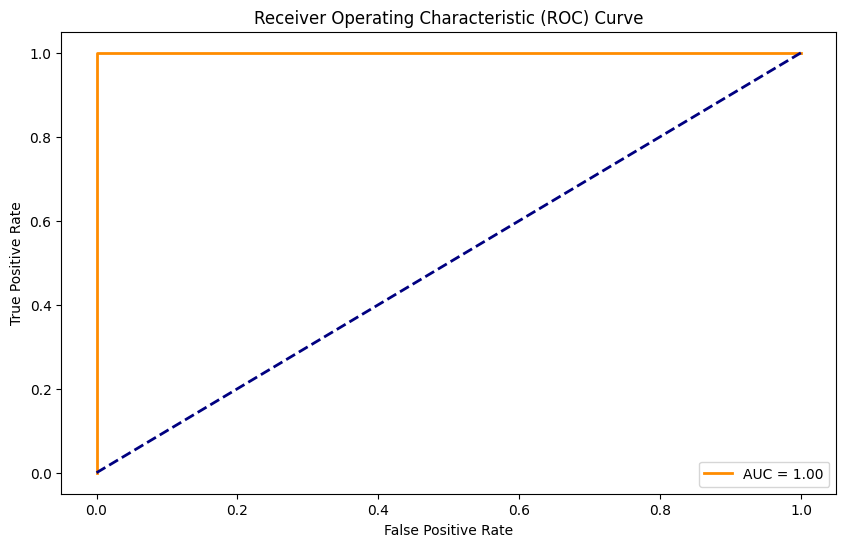
三、完整代码
import pandas as pd
from matplotlib import pylab as plt
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
import torch
import torch.nn as nn
from torch.utils.data import DataLoader, TensorDataset
from sklearn.preprocessing import LabelEncoder
import numpy as np
from sklearn.metrics import roc_curve, auc # 读取数据集,使用制表符作为分隔符
df = pd.read_table('agaricus-lepiota.data', header=None, sep=',') # 将缺失值(用"?"表示)替换为NaN并删除含缺失值的行
df = df.replace('?', np.nan)
df.dropna(axis=0, inplace=True) # 分离特征和标签
X = df.iloc[:, 1:] # 特征
y = df.iloc[:, 0] # 标签(种类:食用或有毒) # 将分类特征进行独热编码
X = pd.get_dummies(X) # 划分训练集和测试集,训练集占75%
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.75, random_state=42) # 数据标准化
scaler = StandardScaler()
X_train_scaler = scaler.fit_transform(X_train) # 对训练数据进行标准化
X_test_scaler = scaler.transform(X_test) # 对测试数据进行标准化 # 标签编码
labelencoder = LabelEncoder()
y_train_labelencoder = labelencoder.fit_transform(y_train) # 将训练标签编码
y_test_labelencoder = labelencoder.transform(y_test) # 将测试标签编码 # 将数据转换为PyTorch张量
X_train_tensor = torch.tensor(X_train_scaler, dtype=torch.float32) # 特征张量
y_train_tensor = torch.tensor(y_train_labelencoder, dtype=torch.float32) # 标签张量
X_test_tensor = torch.tensor(X_test_scaler, dtype=torch.float32) # 测试特征张量
y_test_tensor = torch.tensor(y_test_labelencoder, dtype=torch.float32) # 测试标签张量 # 创建训练数据集和数据加载器
train_dataset = TensorDataset(X_train_tensor, y_train_tensor)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True) # 随机打乱数据 # 定义逻辑回归模型
class LogisticRegression(nn.Module): def __init__(self, inputsize): super().__init__() self.linear = nn.Linear(inputsize, 1) # 单层线性层 def forward(self, x): return torch.sigmoid(self.linear(x)) # 使用sigmoid激活函数 # 实例化模型
inputsize = X_train_tensor.shape[1] # 输入特征的数量
model = LogisticRegression(inputsize) # 定义损失函数和优化器
criterion = nn.BCELoss() # 二元交叉熵损失
optimizer = torch.optim.Adam(model.parameters(), lr=0.01) # Adam优化器,学习率为0.01 # 训练模型
for i in range(1, 101): total_loss = 0 # 初始化总损失 model.train() # 切换到训练模式 for x, y in train_loader: optimizer.zero_grad() # 清空上一步的梯度 y_hat = model(x) # 前向传播,得到预测值 loss = criterion(y_hat, y.view(-1, 1)) # 计算损失 loss.backward() # 反向传播,计算梯度 optimizer.step() # 更新模型参数 total_loss += loss # 累加损失 avg_loss = total_loss / len(train_loader) # 计算平均损失 if i % 10 == 0 or i == 1: print(i, avg_loss.item()) # 每10个epoch打印一次损失值 # 评估模型
with torch.no_grad(): # 关闭梯度计算,以减少内存使用 model.eval() # 切换到评估模式 y_pred = model(X_test_tensor) # 在测试数据上做预测 fpr, tpr, threshold = roc_curve(y_test_labelencoder, y_pred.numpy()) # 计算ROC曲线的假阳率和真阳率 roc_auc = auc(fpr, tpr) # 计算AUC值 # 绘制ROC曲线
plt.figure(figsize=(10, 6))
plt.plot(fpr, tpr, color='darkorange', lw=2, label=f'AUC = {roc_auc:.2f}') # 绘制ROC曲线
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--') # 绘制随机猜测的对角线
plt.xlabel('假阳率 (False Positive Rate)')
plt.ylabel('真阳率 (True Positive Rate)')
plt.title('接收者操作特征 (ROC) 曲线')
plt.legend(loc='lower right')
plt.show() 设计思路
-
数据预处理:
首先读取数据集,并用
NaN替换掉缺失值(“?”),然后删除所有包含缺失值的行。分离特征和目标变量。这里特征是从第二列到最后一列,目标是第一列(表示蘑菇是否可食用)。对分类特征进行独热编码,以便模型能处理这些离散特征。 -
数据分割:
使用
train_test_split将数据集划分为训练集(75%)和测试集(25%),确保模型的训练和测试都基于不同的数据。 -
数据标准化:
利用
StandardScaler对特征数据进行标准化,使特征具有均值0和方差1,这有助于模型训练的稳定性。 -
标签编码:
对目标变量(可食用和有毒)进行标签编码,使其可以被模型处理。
-
模型构建:
定义了一个逻辑回归模型,模型结构很简单,仅包含一个线性层,使用sigmoid激活函数进行二分类。
-
模型训练:
设置二元交叉熵损失函数
BCELoss和Adam优化器进行模型训练。在训练过程中打印每10个epoch的平均损失,以监测模型收敛情况。 -
模型评估:
在测试集上进行预测,并使用
roc_curve计算假阳率和真阳率,同时计算AUC值,以评估模型的性能。 -
可视化结果:
使用Matplotlib绘制ROC曲线,便于直观展示模型分类能力,AUC越接近1表示模型效果越好。