文章目录
- 一. 基于FastAPI之Web站点开发
- 1. 基于FastAPI搭建Web服务器
- 2. Web服务器和浏览器的通讯流程
- 3. 浏览器访问Web服务器的通讯流程
- 4. 加载图片资源代码
- 二. 基于Web请求的FastAPI通用配置
- 1. 目前Web服务器存在问题
- 2. 基于Web请求的FastAPI通用配置
- 三. Python爬虫介绍
- 1. 什么是爬虫
- 2. 爬虫的基本步骤
- 3. 安装requests模块
- 4. 爬取照片
- ① 查看index.html
- ② 爬取照片步骤
- ③ 获取index.html代码
- ④ 解析index.html代码获取图片url
- ⑤ 通过图片url获取图片
- 四. 使用Python爬取GDP数据
- 1. gdp.html
- 2. zip函数的使用
- 3.爬取GDP数据
- 五. 多任务爬虫实现
- 1. 为什么用多任务
- 2. 多任务爬取数据
- 3. 多任务代码实现
- 六. 数据可视化
- 1. 什么是数据可视化
- 2. pyecharts模块
- 3. 通过pyecharts模块创建饼状图
- 4. 完整代码
- 5. 小结
- 七. Logging日志模块
- 1. logging日志的介绍
- 2. logging日志级别介绍
- 3. logging日志的使用
- 4. logging日志在Web项目中应用
- 5. 小结
一. 基于FastAPI之Web站点开发
1. 基于FastAPI搭建Web服务器
# 导入FastAPI模块
from fastapi import FastAPI
# 导入响应报文Response模块
from fastapi import Response
# 导入服务器uvicorn模块
import uvicorn# 创建FastAPI框架对象
app = FastAPI()# 通过@app路由装饰器收发数据
# @app.get(参数) : 按照get方式接受请求数据
# 请求资源的 url 路径
@app.get("/index.html")
def main():with open("source/html/index.html", "rb") as f:data = f.read()# return 返回响应数据# Response(content=data, media_type="text/html"# 参数1: 响应数据# 参数2: 数据格式return Response(content=data, media_type="text/html")# 运行服务器
# 参数1: 框架对象
# 参数2: IP地址
# 参数3: 端口号
uvicorn.run(app, host="127.0.0.1", port=8000)
2. Web服务器和浏览器的通讯流程
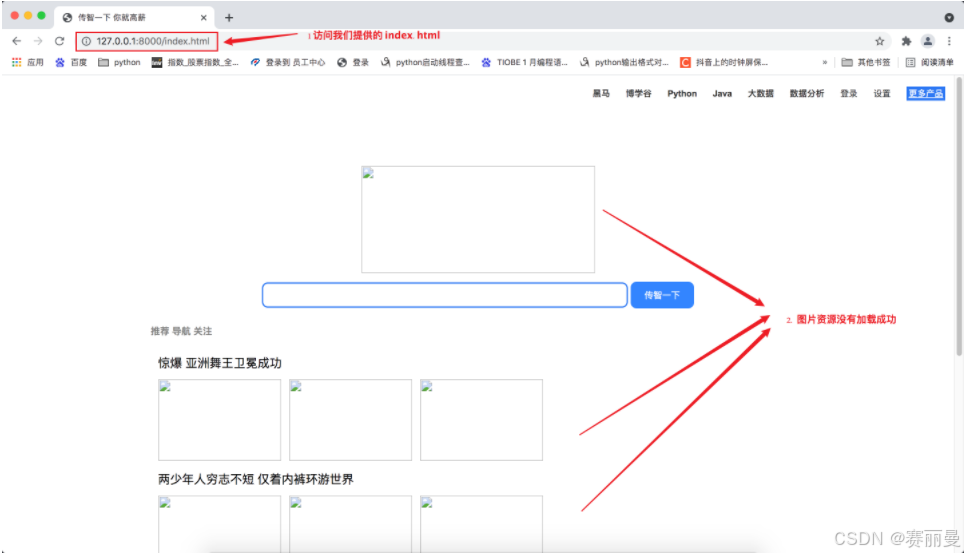
实际上Web服务器和浏览器的通讯流程过程并不是一次性完成的, 这里html代码中也会有访问服务器的代码, 比如请求图片资源。

那像0.jpg、1.jpg、2.jpg、3.jpg、4.jpg、5.jpg、6.jpg这些访问来自哪里呢 ?
答:它们来自index.html

3. 浏览器访问Web服务器的通讯流程

浏览器访问Web服务器的通讯流程:
浏览器(127.0.0.1/index.html) ==> 向Web服务器请求index.htmlWeb服务器(返回index.html) ==>浏览器浏览器解析index.html发现需要0.jpg ==>发送请求给Web服务器请求0.jpgWeb服务器收到请求返回0.jpg ==>浏览器接受0.jpg
通讯过程能够成功的前提:
浏览器发送的0.jpg请求, Web服务器可以做出响应, 也就是代码如下
# 当浏览器发出对图片 0.jpg 的请求时, 函数返回相应资源
@app.get("/images/0.jpg")
def func_01():with open("source/images/0.jpg", "rb") as f:data = f.read()print(data)return Response(content=data, media_type="jpg")
4. 加载图片资源代码
# 导入FastAPI模块
from fastapi import FastAPI
# 导入响应报文Response模块
from fastapi import Response
# 导入服务器uvicorn模块
import uvicorn# 创建FastAPI框架对象
app = FastAPI()@app.get("/images/0.jpg")
def func_01():with open("source/images/0.jpg", "rb") as f:data = f.read()print(data)return Response(content=data, media_type="jpg")@app.get("/images/1.jpg")
def func_02():with open("source/images/1.jpg", "rb") as f:data = f.read()return Response(content=data, media_type="jpg")@app.get("/images/2.jpg")
def func_03():with open("source/images/2.jpg", "rb") as f:data = f.read()return Response(content=data, media_type="jpg")@app.get("/images/3.jpg")
def func_04():with open("source/images/3.jpg", "rb") as f:data = f.read()return Response(content=data, media_type="jpg")@app.get("/images/4.jpg")
def func_05():with open("source/images/4.jpg", "rb") as f:data = f.read()return Response(content=data, media_type="jpg")@app.get("/images/5.jpg")
def func_06():with open("source/images/5.jpg", "rb") as f:data = f.read()return Response(content=data, media_type="jpg")@app.get("/images/6.jpg")
def func_07():with open("source/images/6.jpg", "rb") as f:data = f.read()return Response(content=data, media_type="jpg")@app.get("/index.html")
def main():with open("source/html/index.html", "rb") as f:data = f.read()# return 返回响应数据# Response(content=data, media_type="text/source"# 参数1: 响应数据# 参数2: 数据格式return Response(content=data, media_type="text/html")# 运行服务器
# 参数1: 框架对象
# 参数2: IP地址
# 参数3: 端口号
uvicorn.run(app, host="127.0.0.1", port=8000)
二. 基于Web请求的FastAPI通用配置
1. 目前Web服务器存在问题
# 返回0.jpg
@app.get("/images/0.jpg")
def func_01():with open("source/images/0.jpg", "rb") as f:data = f.read()print(data)return Response(content=data, media_type="jpg")# 返回1.jpg
@app.get("/images/1.jpg")
def func_02():with open("source/images/1.jpg", "rb") as f:data = f.read()return Response(content=data, media_type="jpg")# 返回2.jpg
@app.get("/images/2.jpg")
def func_03():with open("source/images/2.jpg", "rb") as f:data = f.read()return Response(content=data, media_type="jpg")
对以上代码观察,会发现每一张图片0.jpg、1.jpg、2.jpg就需要一个函数对应, 如果我们需要1000张图片那就需要1000个函数对应, 显然这样做代码的重复太多了.
2. 基于Web请求的FastAPI通用配置
# 当请求为 /images/0.jpg 时, path ==> 0.jpg
@app.get("/images/{path}")
# 注意这里的参数需要设置为 path
# path : str ==> 指定path为字符串类型的数据
def get_pic(path: str):# 这里open()的路径就是 ==> f"source/images/0.jpg"with open(f"source/images/{path}", "rb") as f:data = f.read()# return 返回响应数据# Response(content=data, media_type="jpg")# 参数1: 响应数据# 参数2: 数据格式return Response(content=data, media_type="jpg")
完整代码
# 导入FastAPI模块
from fastapi import FastAPI
# 导入响应报文Response模块
from fastapi import Response
# 导入服务器uvicorn模块
import uvicorn# 创建FastAPI框架对象
app = FastAPI()# 当请求为 /images/0.jpg 时, path ==> 0.jpg
@app.get("/images/{path}")
# 注意这里的参数需要设置为 path
# path : str ==> 指定path为字符串类型的数据
def get_pic(path: str):# 这里open()的路径就是 ==> f"source/images/0.jpg"with open(f"source/images/{path}", "rb") as f:data = f.read()# return 返回响应数据# Response(content=data, media_type="jpg")# 参数1: 响应数据# 参数2: 数据格式return Response(content=data, media_type="jpg")@app.get("/{path}")
def get_html(path: str):with open(f"source/html/{path}", 'rb') as f:data = f.read()# return 返回响应数据# Response(content=data, media_type="text/source"# 参数1: 响应数据# 参数2: 数据格式return Response(content=data, media_type="text/html")# 运行服务器
# 参数1: 框架对象
# 参数2: IP地址
# 参数3: 端口号
uvicorn.run(app, host="127.0.0.1", port=8000)
运行结果

三. Python爬虫介绍
1. 什么是爬虫
网络爬虫:
又被称为网页蜘蛛,网络机器人,是一种按照一定的规则,自动地抓取网络信息的程序或者脚本,另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
通俗理解:
简单来讲,爬虫就是一个探测机器,它的基本操作就是模拟人的行为去各个网站溜达,点点按钮,查查数据,或者把看到的信息背回来. 就像一只虫子在一幢楼里不知疲倦地爬来爬去.
你可以简单地想象: 每个爬虫都是你的「分身」。就像孙悟空拔了一撮汗毛,吹出一堆猴子一样
**百度:**其实就是利用了这种爬虫技术, 每天放出无数爬虫到各个网站,把他们的信息抓回来,然后化好淡妆排着小队等你来检索。
有了这样的特性, 对于一些自己公司数据量不足的小公司, 这个时候还想做数据分析就可以通过爬虫获取同行业的数据然后进行分析, 进而指导公司的策略指定。
2. 爬虫的基本步骤
基本步骤:
-
起始URL地址
-
发出请求获取响应数据
-
对响应数据解析
-
数据入库
3. 安装requests模块
- requests : 可以模拟浏览器的请求
- 官方文档 :http://cn.python-requests.org/zh_CN/latest/
- 安装 :pip install requests
快速入门(requests三步走):
# 导入模块
import requests
# 通过requests.get()发送请求
# data保存返回的响应数据(这里的响应数据不是单纯的html,需要通过content获取html代码)
data = requests.get("http://www.baidu.com")
# 通过data.content获取html代码
data = data.content.decode("utf-8")
4. 爬取照片
① 查看index.html
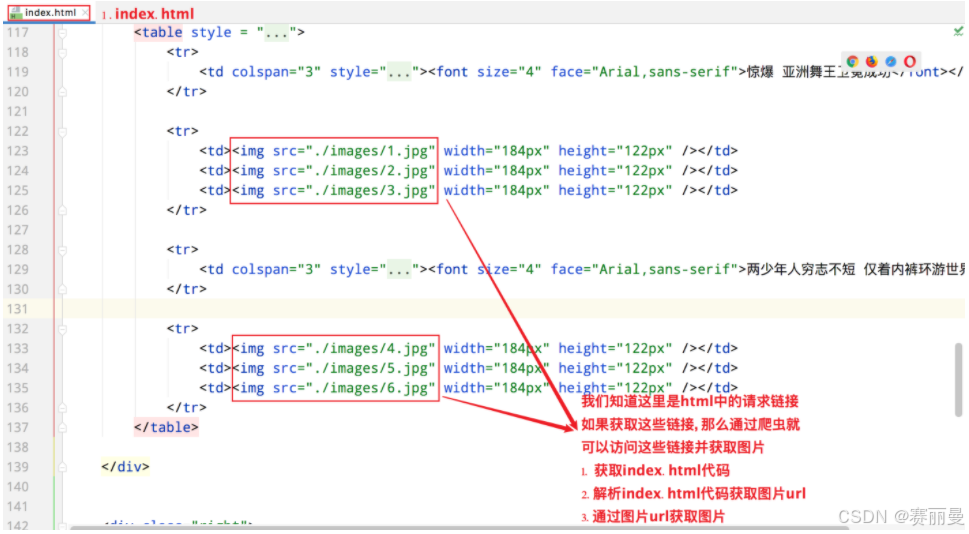
② 爬取照片步骤
- 获取index.html代码
- 解析index.html代码获取图片url
- 通过图片url获取图片
③ 获取index.html代码
# 通过爬虫向index.html发送请求
# requests.get(网址): 向一个网址发送请求,和在浏览器中输入网址是一样的
data = requests.get("http://127.0.0.1:8000/index.html")
# content可以把requests.get()获取的返回值中的html内容获取到
data = data.content.decode("utf-8")
④ 解析index.html代码获取图片url
# 获取图片的请求url
def get_pic_url():# 通过爬虫向index.html发送请求# requests.get(网址): 向一个网址发送请求,和在浏览器中输入网址是一样的data = requests.get("http://127.0.0.1:8000/index.html")# content可以把requests.get()获取的返回值中的html内容获取到data = data.content.decode("utf-8")# html每一行都有"\n", 对html进行分割获得一个列表data = data.split("\n")# 创建一个列表存储所有图片的url地址(也就是图片网址)url_list = []for url in data:# 通过正则解析出所有的图片urlresult = re.match('.*src="(.*)" width.*', url)if result is not None:# 把解析出来的图片url添加到url_list中url_list.append(result.group(1))return url_list
⑤ 通过图片url获取图片
# 把爬取到的图片保存到本地
def save_pic(url_list):# 通过num给照片起名字 例如:0.jpg 1.jpg 2.jpgnum = 0for url in url_list:# 通过requests.get()获取每一张图片pic = requests.get(f"http://127.0.0.1:8000{url[1:]}")# 保存每一张图片with open(f"./source/spyder/{num}.jpg", "wb") as f:f.write(pic.content)num += 1
完整代码
# 把爬取到的图片保存到本地
def save_pic(url_list):# 通过num给照片起名字 例如:0.jpg 1.jpg 2.jpgnum = 0for url in url_list:# 通过requests.get()获取每一张图片pic = requests.get(f"http://127.0.0.1:8000{url[1:]}")# 保存每一张图片with open(f"./source/spyder/{num}.jpg", "wb") as f:f.write(pic.content)num += 1
四. 使用Python爬取GDP数据
1. gdp.html
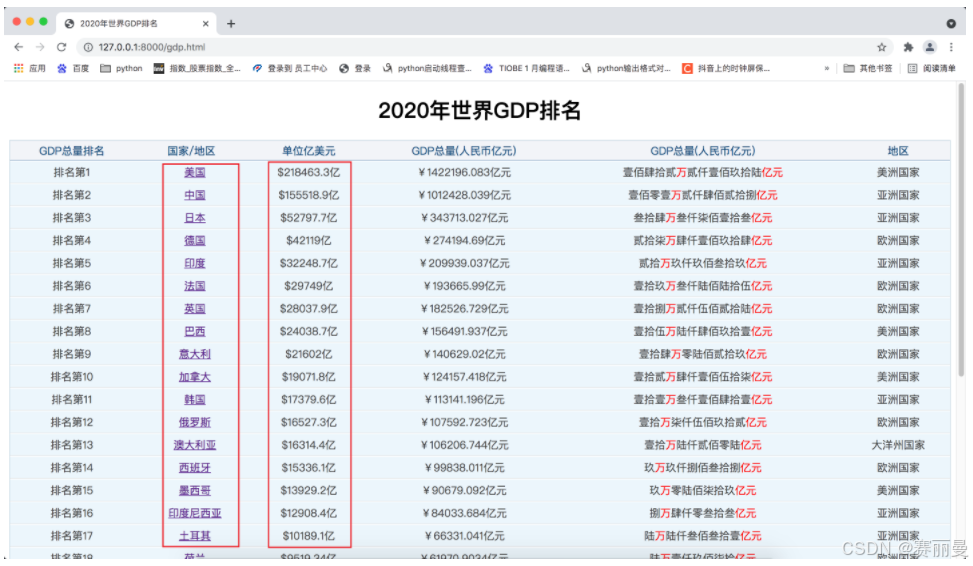
通过访问 http://127.0.0.1:8080/gdp.html 可以获取2020年世界GDP排名. 在这里我们通过和爬取照片一样的流程步骤获取GDP数据。
2. zip函数的使用
zip() 函数: 用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表.
a = [1, 2, 3]
b = [4, 5, 6]
c = [4, 5, 6, 7, 8]
# 打包为元组的列表
zipped = zip(a, b)
# 注意使用的时候需要list转化
print(list(zipped))
>>> [(1, 4), (2, 5), (3, 6)]# 元素个数与最短的列表一致
zipped = zip(a, c)
# 注意使用的时候需要list转化
print(list(zipped))
>>> [(1, 4), (2, 5), (3, 6)]
3.爬取GDP数据
import requests
import re# 存储爬取到的国家的名字
country_list = []
# 存储爬取到的国家gdp的数据
gdp_list = []# 获取gdp数据
def get_gdp_data():global country_listglobal gdp_list# 获取gdp的html数据data = requests.get("http://localhost:8000/gdp.html")# 对获取数据进行解码data = data.content.decode("utf8")# 对gdp的html数据进行按行分割data_list = data.split("\n")for i in data_list:# 对html进行解析获取<国家名字>country_result = re.match('.*<a href=""><font>(.*)</font></a>', i)# 匹配成功就存放到列表中if country_result is not None:country_list.append(country_result.group(1))# 对html进行解析获取<gdp数据>gdp_result = re.match(".*¥(.*)亿元", i)# 匹配成功就存储到列表中if gdp_result is not None:gdp_list.append(gdp_result.group(1))# 把两个列表融合成一个列表gdp_data = list(zip(country_list, gdp_list))print(gdp_data)if __name__ == '__main__':get_gdp_data()
五. 多任务爬虫实现
1. 为什么用多任务
在我们的案例中, 我们只是爬取了2个非常简单的页面, 这两个页面的数据爬取并不会使用太多的时间, 所以我们也没有太多的考虑效率问题.
但是在真正的工作环境中, 我们爬取的数据可能非常的多, 如果还是使用单任务实现, 这时候就会让我们爬取数据的时间很长, 那么显然使用多任务可以大大提升我们爬取数据的效率
2. 多任务爬取数据
实际上实现多任务并不难, 只需要使用多任务就可以了
3. 多任务代码实现
# 获取gdp
def get_gdp_data():pass# 获取照片
def get_pic():passif __name__ == '__main__':p1 = multiprocessing.Process(target=get_picp2 = multiprocessing.Process(target=get_gdp_data)p1.start()p2.start()
六. 数据可视化
1. 什么是数据可视化

数据可视化:顾名思义就是让数据看的到, 他的作用也很明显, 让人们不用再去阅读枯燥无味的数据, 一眼看去就可以明白数据是什么, 数据间的关系是什么, 更好的让我们通过数据发现潜在的规律进而进行商业决策。
2. pyecharts模块

概况 :
Echarts 是个由百度开源的数据可视化,凭借着良好的交互性,精巧的图表设计,得到了众多开发者的认可. 而 Python 是门富有表达力的语言,很适合用于数据处理. 当数据分析遇上数据可视化时pyecharts 诞生了.
特性 :
- 简洁的API设计,使用如丝滑般流畅,支持链式调用
- 囊括了**30+**种常见图表,应有尽有
- 支持主流Notebook 环境,Jupyter Notebook 和JupyterLab
- 可轻松集成至Flask, Django等主流Web框架
- 高度灵活的配置项,可轻松搭配出精美的图表
- 详细的文档和示例,帮助开发者更快的上手项目
- 多达400+地图文件以及原生的百度地图,为地理数据可视化提供强有力的支持
3. 通过pyecharts模块创建饼状图
导入模块
# 导入饼图模块
from pyecharts.charts import Pie
# 导入配置选项模块
import pyecharts.options as opts
初始化饼状图:
Pie()函数: 创建饼图
opts.InitOpts参数: Pie(init_opts=opts.InitOpts(width=“1400px”, height=“800px”))
init_opts: 指定参数名
opts.InitOpts: 配置选项
**width=“1400px” height=“800px” 😗*界面的宽度和高度
# 创建饼图并设置这个界面的长和高
# px:像素单位
pie = Pie(init_opts=opts.InitOpts(width="1400px", height="800px"))
给饼图添加数据:
add()函数:
参数1: 名称
参数2: 具体数据, 数据类型为==>[(a,b),(a,b),(a,b)]==>a为数据名称,b为数据大小
参数3: 标签设置 label_opts=opts.LabelOpts(formatter=‘{b}:{d}%’) 符合百分比的形式
# 给饼图添加数据
pie.add("GDP",data,label_opts=opts.LabelOpts(formatter='{b}:{d}%')
)
给饼图添设置标题:
set_global_opts()函数 :
title_opts=opts.TitleOpts : 设置标题
title=“2020年世界GDP排名”, subtitle=“美元” : 设置主标题和副标题
# 给饼图设置标题
pie.set_global_opts(title_opts=opts.TitleOpts(title="2020年世界GDP排名", subtitle="美元"))
保存数据:
# 保存结果
pie.render()
4. 完整代码
import requests
import re
# 导入饼图模块
from pyecharts.charts import Pie
# 导入配置选项模块
import pyecharts.options as opts# 存储爬取到的国家的名字
country_list = []
# 春初爬取到的国家gdp的数据
gdp_list = []def get_gdp_data():global country_listglobal gdp_list# 获取gdp的html数据data = requests.get("http://localhost:8000/gdp.html")# 对获取数据进行解码data = data.content.decode("utf8")# 对gdp的html数据进行按行分割data_list = data.split("\n")for i in data_list:# 对html进行解析获取<国家名字>country_result = re.match('.*<a href=""><font>(.*)</font></a>', i)# 匹配成功就存放到列表中if country_result is not None:country_list.append(country_result.group(1))# 对html进行解析获取<gdp数据>gdp_result = re.match(".*¥(.*)亿元", i)# 匹配成功就存储到列表中if gdp_result is not None:gdp_list.append(gdp_result.group(1))# 创建一个饼状图显示GDP前十的国家
def data_view_pie():# 获取前十的过的GDP数据, 同时让数据符合[(),()...]的形式data = list(zip(country_list[:10], gdp_list[:10]))# 创建饼图pie = Pie(init_opts=opts.InitOpts(width="1400px", height="800px"))# 给饼图添加数据pie.add("GDP",data,label_opts=opts.LabelOpts(formatter='{b}:{d}%'))# 给饼图设置标题pie.set_global_opts(title_opts=opts.TitleOpts(title="2020年世界GDP排名", subtitle="美元"))# 保存结果pie.render()if __name__ == '__main__':# 获取GDP数据get_gdp_data()# 生成可视化饼图data_view_pie()
5. 小结
可视化
- Pie()函数 : 创建饼图
- add()函数 : 添加数据
- set_global_opts()函数 : 设置标题
- render()函数 : 保存数据
七. Logging日志模块
1. logging日志的介绍
在现实生活中,记录日志非常重要,比如:银行转账时会有转账记录;飞机飞行过程中,会有个黑盒子(飞行数据记录器)记录着飞机的飞行过程,那在咱们python程序中想要记录程序在运行时所产生的日志信息,怎么做呢?
可以使用 logging 这个包来完成
记录程序日志信息的目的是:
- 可以很方便的了解程序的运行情况
- 可以分析用户的操作行为、喜好等信息
- 方便开发人员检查bug
2. logging日志级别介绍
日志等级可以分为5个,从低到高分别是:
- DEBUG
- INFO
- WARNING
- ERROR
- CRITICAL
日志等级说明:
- DEBUG:程序调试bug时使用
- INFO:程序正常运行时使用
- WARNING:程序未按预期运行时使用,但并不是错误,如:用户登录密码错误
- ERROR:程序出错误时使用,如:IO操作失败
- CRITICAL:特别严重的问题,导致程序不能再继续运行时使用,如:磁盘空间为空,一般很少使用
- 默认的是WARNING等级,当在WARNING或WARNING之上等级的才记录日志信息。
- 日志等级从低到高的顺序是: DEBUG < INFO < WARNING < ERROR < CRITICAL
3. logging日志的使用
在 logging 包中记录日志的方式有两种:
- 输出到控制台
- 保存到日志文件
日志信息输出到控制台的示例代码:
import logginglogging.debug('这是一个debug级别的日志信息')
logging.info('这是一个info级别的日志信息')
logging.warning('这是一个warning级别的日志信息')
logging.error('这是一个error级别的日志信息')
logging.critical('这是一个critical级别的日志信息')
运行结果:
WARNING:root:这是一个warning级别的日志信息
ERROR:root:这是一个error级别的日志信息
CRITICAL:root:这是一个critical级别的日志信息
说明:
- 日志信息只显示了大于等于WARNING级别的日志,这说明默认的日志级别设置为WARNING
logging日志等级和输出格式的设置:
import logging# 设置日志等级和输出日志格式
logging.basicConfig(level=logging.DEBUG,format='%(asctime)s - %(filename)s[line:%(lineno)d] - %(levelname)s: %(message)s')logging.debug('这是一个debug级别的日志信息')
logging.info('这是一个info级别的日志信息')
logging.warning('这是一个warning级别的日志信息')
logging.error('这是一个error级别的日志信息')
logging.critical('这是一个critical级别的日志信息')
运行结果:
2019-02-13 20:41:33,080 - hello.py[line:6] - DEBUG: 这是一个debug级别的日志信息
2019-02-13 20:41:33,080 - hello.py[line:7] - INFO: 这是一个info级别的日志信息
2019-02-13 20:41:33,080 - hello.py[line:8] - WARNING: 这是一个warning级别的日志信息
2019-02-13 20:41:33,080 - hello.py[line:9] - ERROR: 这是一个error级别的日志信息
2019-02-13 20:41:33,080 - hello.py[line:10] - CRITICAL: 这是一个critical级别的日志信息
代码说明:
- level 表示设置的日志等级
- format 表示日志的输出格式, 参数说明:
- %(levelname)s: 打印日志级别名称
- %(filename)s: 打印当前执行程序名
- %(lineno)d: 打印日志的当前行号
- %(asctime)s: 打印日志的时间
- %(message)s: 打印日志信息
日志信息保存到日志文件的示例代码:
import logginglogging.basicConfig(level=logging.DEBUG,format='%(asctime)s - %(filename)s[line:%(lineno)d] - %(levelname)s: %(message)s',filename="log.txt",filemode="w")logging.debug('这是一个debug级别的日志信息')
logging.info('这是一个info级别的日志信息')
logging.warning('这是一个warning级别的日志信息')
logging.error('这是一个error级别的日志信息')
logging.critical('这是一个critical级别的日志信息')
运行结果:

4. logging日志在Web项目中应用
使用logging日志示例:
- 程序入口模块设置logging日志的设置
# 导入FastAPI模块from fastapi import FastAPI# 导入响应报文Response模块from fastapi import Response# 导入服务器uvicorn模块import uvicorn# 导入日志模块import logging# 配置日志logging.basicConfig(level=logging.INFO,format='%(asctime)s - %(filename)s[line:%(lineno)d] - %(levelname)s: %(message)s',filename="log.txt",filemode="w")
- 访问index.html时进行日志输出,示例代码:
# 当请求为 /images/0.jpg 时, path ==> 0.jpg
@app.get("/images/{path}")
# 注意这里的参数需要设置为 path
# path : str ==> 指定path为字符串类型的数据
def get_pic(path: str):# 这里open()的路径就是 ==> f"source/images/0.jpg"with open(f"source/images/{path}", "rb") as f:data = f.read()# 打loglogging.info("访问了" + path)# return 返回响应数据# Response(content=data, media_type="jpg")# 参数1: 响应数据# 参数2: 数据格式return Response(content=data, media_type="jpg")
- 访问gdp.html时进行日志输出,示例代码:
@app.get("/{path}")
def get_html(path: str):with open(f"source/html/{path}") as f:data = f.read()# 打loglogging.info("访问了" + path)# return 返回响应数据# Response(content=data, media_type="text/source"# 参数1: 响应数据# 参数2: 数据格式return Response(content=data, media_type="text/html")
logging日志:

通过日志信息我们得知, index.html被访问了2次, gdp.html被访问了2次.
说明:
- logging日志配置信息在程序入口模块设置一次,整个程序都可以生效。
- logging.basicConfig 表示 logging 日志配置操作
5. 小结
- 记录python程序中日志信息使用 logging 包来完成
- logging日志等级有5个:
- DEBUG
- INFO
- WARNING
- ERROR
- CRITICAL
- 打印(记录)日志的函数有5个:
- logging.debug函数, 表示: 打印(记录)DEBUG级别的日志信息
- logging.info函数, 表示: 打印(记录)INFO级别的日志信息
- logging.warning函数, 表示: 打印(记录)WARNING级别的日志信息
- logging.error函数, 表示: 打印(记录)ERROR级别的日志信息
- logging.critical函数, 表示: 打印(记录)CRITICAL级别的日志信息