首先给大家介绍一下LMDeploy推理框架。LMDeploy 是一个高效且友好的 LLMs 模型部署工具箱,功能涵盖了量化、推理和分布式服务。LMDeploy在推理方面开发了 Persistent Batch(即Continuous Batch),Blocked K/V Cache,动态拆分和融合,张量并行,高效的计算 kernel等重要特性。官方宣称推理性能是 vLLM 的 1.8 倍。 LMDeploy 支持权重量化和 k/v 量化。4bit 模型推理效率是 FP16 下的 2.4 倍。量化模型的可靠性已通过 OpenCompass 评测得到充分验证。LMDeploy 通过请求分发服务,LMDeploy 支持多模型在多机、多卡上的推理服务。
有后续我会发文分享有关它的技术实现原理(虽说我也是一知半解,但我会努力的!)。下面我们一同来操作一下如果使用它来进行模型推理、在线量化推理和分布式推理吧!
〇、快速安装
建议使用python3.10(2025年4月25日)哦!使用conda创建一个全新的环境,然后再安装lmdeploy命令如下:
# 创建环境
conda create -n lmdeploy python=3.10 -y
# 激活环境
conda activate lmdeploy激活环境后,推荐pip安装lmdeploy==0.7.1版本,最新的0.7.2有点问题。如果后续测试没有问题了就当我没说0.0
pip install lmdeploy==0.7.1另外还有个重要的安装方式,从源码进行安装,命令如下:
# 拉取官方仓库
git clone https://github.com/InternLM/lmdeploy.git
# 进入本地lmdeploy仓库
cd lmdeploy# 从源码进行可编辑模式安装
pip install -e .一、LMDeploy基础推理
它最基础的部署推理的用法,就是使用lmdeploy cli工具,在lmdeploy项目路径下执行命令:
lmdeploy serve api_server internlm/internlm2_5-1.8b-chat【注】如果你执行lmdeploy输出:ModuleNotFoundError: No module named 'partial_json_parser'错误别怕,只需要安装 pip install partial-json-parser 就能解决。

api_server启动时的参数可以通过下面这个命令查看
lmdeploy serve api_server -h我给大家列出几个关键的:
| 参数 | 描述 | 默认值 | 类型 |
|---|---|---|---|
--server-name SERVER_NAME | 服务绑定的主机 IP 地址。 | 0.0.0.0 | str |
--server-port SERVER_PORT | 服务监听的端口号。 | 23333 | int |
--model-name MODEL_NAME | 被服务模型的名称,可通过 RESTful API /v1/models 访问。如果未指定,则采用 model_path。 | None | str |
--tp TP | 用于张量并行计算的 GPU 数量,应为 2 的幂。 | 1 | int |
--session-len SESSION_LEN | 单个序列的最大会话长度。 | None | int |
--cache-max-entry-count ... | k/v 缓存占用的空闲 GPU 内存百分比(不包括权重)。 | 0.8 | float |
除serve之外cli还有其他几个命令我给大家列在下面:
| CLI命令 | 描述 |
|---|---|
| lite | 使用 lmdeploy.lite 模块压缩和加速大语言模型 (LLMs)。 |
| serve | 使用 Gradio、OpenAI API 或 Triton 服务器部署大语言模型 (LLMs)。 |
| convert | 将大语言模型 (LLMs) 转换为 Turbomind 格式。 |
| list | 列出支持的模型名称。 |
| check_env | 检查环境信息。 |
| chat | 使用 PyTorch 或 Turbomind 引擎与模型进行聊天交互。 |
【注】如果你在客户端推理的时候出现了下面这个报错,这说明你的显卡架构是 Turing 架构,比如你用的是RTX20系列,那么它的算力是sm_75无法直接支持 .bf16,而最新的lmdeploy只支持sm_80算力的卡(比如A100、RTX 30 系列显卡)
RuntimeError: Internal Triton PTX codegen error `ptxas` stderr: ptxas /tmp/tmpy4hhoi2w.ptx, line 97; error : Feature '.bf16' requires .target sm_80 or higher ptxas /tmp/tmpy4hhoi2w.ptx, line 97; error : Feature 'cvt with .f32.bf16' requires .target sm_80 or higher”
-
ptxas是 NVIDIA 提供的 PTX 汇编器,用于将 PTX 中间代码编译为二进制代码(CUBIN)。它明确指出.bf16和相关指令需要sm_80或更高的架构版本。
二、LMDeploy在线量化推理
这部分重点给大家介绍Key-Value(KV) Cache 量化,从直观上看,量化 kv 有利于增加 kv block 的数量。与 fp16 相比,int4/int8 kv 的 kv block 分别可以增加到 4 倍和 2 倍。这意味着,在相同的内存条件下,kv 量化后,系统能支撑的并发数可以大幅提升,从而最终提高吞吐量。而且int8 kv 精度几乎无损,int4 kv 略有损失。
那么具体咋操作呢?只需要在CLI命令后面加一个 --quant-policy 参数就行了:
lmdeploy serve api_server 模型绝对路径 --quant-policy 8
关于KV Cache量化的原理我用单独一篇文章来阐述清楚(这个技术很吊)。这里还有个关键,就是KV Cache量化虽然厉害,但不是所有的显卡的都支持的哦!你可以移步官方文档的对应部分查看,链接在这里:lmdploy 官方文档 kv_cache量化技术
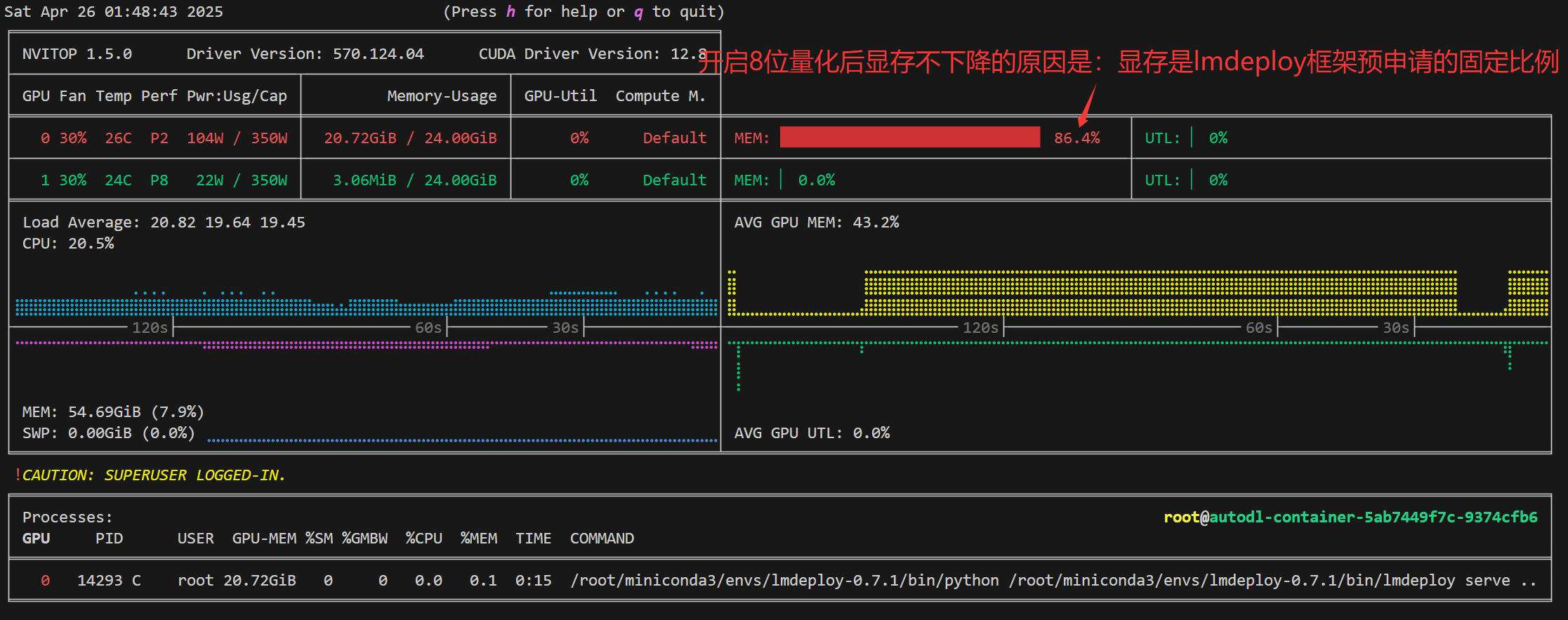
【注】从后台看显存占用会发现并没有减少,其实是因为lmdeploy框架自己事先向系统申请了80%多的显存。并不是都是模型的显存占用。
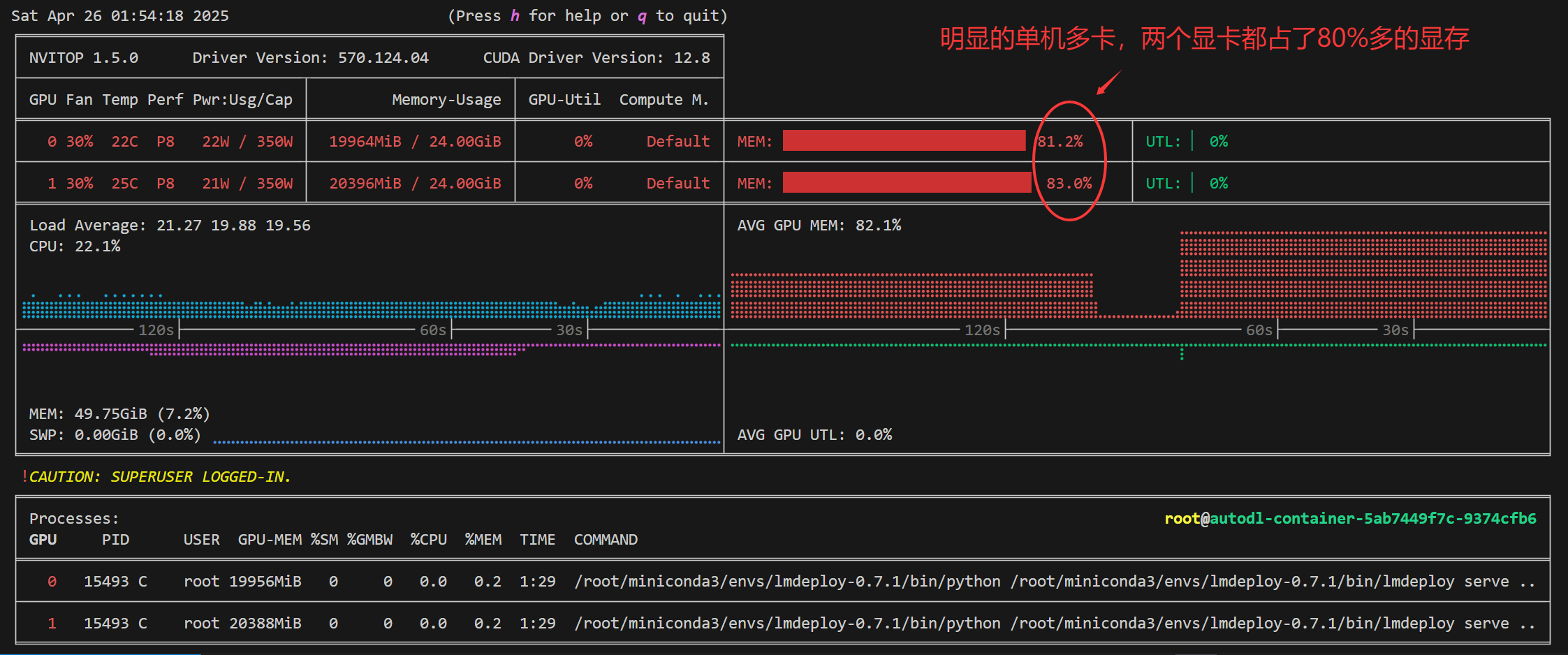
三、LMDeploy分布式推理
这部分,我只讲单机多卡如何设置(因为我只有单机多卡环境,笑哭)。上面我们在api_server参数中提到了一个tp参数,它就是分布式推理的关键。用来开启张量并行,关于分布式我另外单独写一篇文章介绍(敬请期待!挖坑大师)
lmdeploy serve api_server 模型绝对路径 --tp 2上面这个命令里面--tp设置成2意思就是单机双卡来进行分布式推理。如果你不带这个参数,默认是用一张卡来推理,这里我想吐槽一下llamafactory的cli工具,默认就是用所有GPU一起推理。

我们使用nvitop工具来看看显卡的显存占用和利用率情况。