以下是关于 Spring Batch 的详细解析及其同类框架的对比分析:
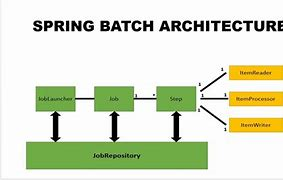
一、Spring Batch 核心详解
1. 核心概念
-
作业(Job):批处理任务的顶层容器,由多个步骤(Step)组成。
-
步骤(Step):最小执行单元,分为 Chunk-oriented(分块处理)和 Tasklet(自定义任务)。
-
分块处理(Chunk):
// 读取 → 处理 → 写入的分块模式 ItemReader → ItemProcessor → ItemWriter- ItemReader:从数据源(数据库、文件等)读取数据。
- ItemProcessor:对数据进行转换或过滤。
- ItemWriter:批量写入结果(如数据库、文件)。
-
事务管理:通过
Chunk的事务边界控制(如每100条提交一次)。 -
重启与恢复:支持作业中断后从断点恢复(通过
JobRepository记录状态)。
2. 核心组件
| 组件 | 作用 |
|---|---|
| JobLauncher | 启动作业 |
| JobRepository | 存储作业执行状态(如数据库表) |
| JobParameters | 传递作业运行时参数(如时间戳、文件路径) |
| TaskExecutor | 线程管理(如并发步骤执行) |
3. 典型场景
- 数据迁移:如从旧数据库迁移到新数据库。
- 报表生成:每日生成销售统计报表。
- ETL任务:从文件/数据库提取数据并转换加载到数据仓库。
4. 代码示例(分块处理)
@Configuration
public class BatchConfig {@Beanpublic Step step(ItemReader<User> reader,ItemProcessor<User, User> processor,ItemWriter<User> writer) {return steps.get("myStep").<User, User>chunk(10) // 每10条提交一次.reader(reader).processor(processor).writer(writer).build();}@Beanpublic Job job(Step step) {return jobs.get("myJob").start(step).build();}
}
二、Spring Batch 同类框架对比
1. 主流框架对比
| 框架 | 类型 | 优势 | 适用场景 | 缺点 |
|---|---|---|---|---|
| Spring Batch | Java批处理 | Java生态友好、事务控制精细、适合中等规模数据 | 企业级Java应用、复杂分步处理 | 性能不如Spark/Flink,分布式能力有限 |
| Apache Spark | 大数据批处理 | 内存加速计算、支持SQL/DSL、适合海量数据 | 大数据ETL、机器学习数据预处理 | 需要集群资源,学习成本高 |
| Apache Flink | 流批一体 | 流批统一处理、低延迟、状态管理 | 实时+批处理混合场景 | 配置复杂,社区活跃度低于Spark |
| Apache Airflow | 任务调度 | DAG可视化、动态依赖、支持Python/Java | 复杂依赖关系、跨系统调度 | 资源消耗大,需独立集群 |
| Luigi | 任务调度 | 简单易用、Python原生支持 | 小规模任务调度 | 可视化能力弱 |
| Hadoop MapReduce | 传统批处理 | 成熟稳定、适合离线批处理 | 传统Hadoop生态 | 性能低,编程模型复杂 |
| Dask | Python批处理 | 类Pandas接口、轻量级、适合快速开发 | 中等规模数据处理、Python生态 | 分布式性能有限 |
| Celery | 任务队列 | 分布式任务队列、支持异步/定时任务 | 实时任务与批处理结合 | 依赖消息中间件(如RabbitMQ) |
2. 关键维度对比
| 维度 | Spring Batch | Apache Spark | Apache Airflow |
|---|---|---|---|
| 语言支持 | Java | 多语言(Scala/Python/Java) | Python/Java(通过插件) |
| 分布式能力 | 有限(需集群扩展) | 原生分布式 | 支持分布式任务调度 |
| 事务控制 | 细粒度(Chunk级) | 全局事务(需配合Flink) | 依赖底层工具(如Spark/Flink) |
| 可视化 | 无内置UI | 通过Spark UI | 内置Web UI查看DAG |
| 学习成本 | 中等(需熟悉Spring生态) | 高(需掌握分布式概念) | 中等(DAG设计) |
三、选择建议
-
Spring Batch 适用场景:
- Java生态:与Spring Boot/Spring Cloud深度集成。
- 中等规模数据:单机或小规模集群,需精细控制事务和分步处理。
- 企业级需求:需要重启、监控、事务回滚的稳定任务。
-
替代方案选择:
- 大数据量:Spark/Flink(Spark适合批处理,Flink适合流批一体)。
- 复杂调度:Airflow(可视化DAG管理跨系统任务)。
- 轻量级Python:Dask(快速开发,类Pandas接口)。
- 实时任务:Flink 或 Celery(结合Kafka触发)。
四、Spring Batch 最佳实践
-
性能优化:
- 调整
chunk size(如增大到500-1000条)。 - 使用
GridSize或MultiResourceItemReader并行读取文件。 - 启用
TaskExecutor实现多线程处理。
- 调整
-
监控与日志:
- 集成 Spring Boot Actuator 监控作业状态。
- 使用 ELK Stack 或 Prometheus 记录作业指标。
-
扩展性:
- 通过
Partitioner将作业分片到多节点(分布式处理)。 - 与 Airflow 集成,实现跨框架任务调度。
- 通过
五、总结表格
| 需求 | 推荐框架 |
|---|---|
| Java生态+精细事务控制 | Spring Batch |
| 大数据处理 | Apache Spark/Flink |
| 复杂任务调度 | Apache Airflow |
| 实时+批处理混合场景 | Apache Flink |
| 轻量级Python开发 | Dask |
如需具体场景的配置示例(如分布式分片、与Airflow集成),可进一步说明需求。
番外
以下是针对 Java 生态 中主流批处理框架的详细对比分析,涵盖核心功能、适用场景及优缺点:
一、核心 Java 批处理框架对比
1. Spring Batch
- 定位:企业级 Java 批处理框架,专注于复杂任务的事务管理和可恢复性。
- 核心特性:
- 分块处理(Chunk-based):读取 → 处理 → 写入的事务性分块模式。
- 事务控制:支持细粒度事务边界(如每100条提交一次)。
- 重启与恢复:通过
JobRepository记录状态,支持从断点恢复。 - 分布式扩展:通过分片(Partitioning)实现多节点并行处理。
- 适用场景:
- 企业级 Java 应用(如数据迁移、报表生成)。
- 需要事务控制、复杂分步处理的场景。
- 优缺点:
- 优点:与 Spring 生态深度集成,功能全面,学习曲线适中。
- 缺点:分布式性能有限,需额外配置集群。
2. Hadoop MapReduce
- 定位:传统分布式批处理框架,适合海量数据离线处理。
- 核心特性:
- 分布式计算:通过 Map(分片)和 Reduce(聚合)阶段处理数据。
- 容错性:基于 HDFS 存储,支持任务重试。
- 生态支持:与 Hadoop 生态(如 Hive、HBase)无缝集成。
- 适用场景:
- 大规模数据 ETL(如日志分析、数据仓库构建)。
- 需要与 Hadoop 生态整合的场景。
- 优缺点:
- 优点:成熟稳定,适合海量数据离线处理。
- 缺点:编程模型复杂,性能较低,学习成本高。
3. Apache Spark(Java SDK)
- 定位:高性能内存计算框架,支持 Java API 的大数据批处理。
- 核心特性:
- 内存加速:利用内存计算提升性能(比 Hadoop 快10-100倍)。
- DataFrame/Dataset API:提供类似 SQL 的数据处理能力。
- 流批一体:通过 Spark Streaming 支持实时+批处理。
- 适用场景:
- 大规模数据清洗、转换、聚合(如用户行为分析)。
- 需要快速迭代计算的场景(如机器学习预处理)。
- 优缺点:
- 优点:性能优异,支持丰富的数据格式(Parquet、JSON)。
- 缺点:需管理集群资源,分布式配置复杂。
4. Apache Flink(Java SDK)
- 定位:流批一体框架,Java API 支持复杂事件处理。
- 核心特性:
- 流批统一:通过相同 API 处理流数据和批数据。
- 状态管理:内置状态后端(如 RocksDB),支持高吞吐低延迟。
- Exactly-Once 语义:保证数据处理的精确一次。
- 适用场景:
- 需要流批混合处理的场景(如实时报表+离线分析)。
- 高并发、低延迟的批处理任务。
- 优缺点:
- 优点:流批统一,容错性强,适合复杂场景。
- 缺点:配置复杂,社区活跃度低于 Spark。
5. Quartz Scheduler
- 定位:任务调度框架,常用于简单批处理触发。
- 核心特性:
- 定时任务:支持 Cron 表达式定义任务执行时间。
- 分布式调度:通过集群模式实现高可用。
- 轻量级:适合简单任务调度。
- 适用场景:
- 触发其他批处理框架的任务(如定时启动 Spark 作业)。
- 独立的轻量级定时任务(如每日数据同步)。
- 优缺点:
- 优点:简单易用,Java 原生支持。
- 缺点:无数据处理能力,需结合其他框架。
6. Apache Beam(Java SDK)
- 定位:跨框架批流统一编程模型,支持多种执行引擎(如 Spark/Flink)。
- 核心特性:
- 统一 API:通过 Pipeline 定义任务,支持切换执行引擎。
- 可移植性:代码一次编写,可在不同后端运行。
- 复杂转换:支持窗口、状态管理等高级功能。
- 适用场景:
- 需要跨平台兼容性(如同时支持 Spark 和 Flink)。
- 复杂的数据转换逻辑。
- 优缺点:
- 优点:抽象层降低框架切换成本。
- 缺点:学习曲线陡峭,需理解底层引擎差异。
二、关键对比维度分析
1. 性能对比
| 框架 | 吞吐量 | 延迟 | 资源占用 |
|---|---|---|---|
| Spark | 高 | 中 | 高(内存密集) |
| Flink | 高 | 低 | 中 |
| Spring Batch | 中 | 高 | 低 |
| MapReduce | 低 | 高 | 高 |
| Quartz | 无 | 无 | 极低 |
2. 适用场景对比
| 需求 | 推荐框架 |
|---|---|
| 企业级 Java 事务控制 | Spring Batch |
| 大数据离线处理 | Spark |
| 流批一体处理 | Flink |
| 简单任务调度 | Quartz |
| 跨引擎兼容性 | Apache Beam |
3. 学习与生态
| 框架 | 学习成本 | 社区支持 | 生态集成 |
|---|---|---|---|
| Spring Batch | 中 | 高(Spring 生态) | 与 Spring Boot 深度集成 |
| Spark | 高 | 高 | 大数据生态(Hadoop/Kafka) |
| Flink | 高 | 中 | 流处理生态(Kubernetes) |
| Quartz | 低 | 中 | 独立调度,需结合其他框架 |
三、选择建议
-
优先选 Spring Batch:
- 场景:企业级 Java 应用、需要事务控制、与 Spring 生态整合。
- 示例:每日订单数据汇总、用户画像生成。
-
选择 Spark/Flink:
- 场景:海量数据处理(TB/PB 级)、需高性能计算。
- 示例:日志分析、用户行为统计。
-
使用 Quartz:
- 场景:简单定时任务触发(如每周数据备份)。
-
尝试 Apache Beam:
- 场景:需同时支持 Spark 和 Flink 的混合架构。
四、代码示例(Spring Batch 分片处理)
@Configuration
public class BatchConfig {@Beanpublic Step step(ItemReader<User> reader, ItemWriter<User> writer) {return steps.get("step").<User, User>chunk(100).reader(reader).writer(writer).build();}@Beanpublic Job job(Step step) {return jobs.get("job").start(step).build();}@Beanpublic Partitioner partitioner() {return new MultiResourcePartitioner(); // 分片读取多个文件}
}
五、总结
| 框架 | 最佳使用场景 | 避坑提示 |
|---|---|---|
| Spring Batch | 企业级 Java 应用、事务敏感型任务 | 避免处理 PB 级数据 |
| Spark | 大数据离线处理、需内存加速 | 需管理集群资源 |
| Flink | 流批一体、低延迟场景 | 配置复杂,需熟悉状态管理 |
| Quartz | 独立任务调度 | 无数据处理能力,需组合其他框架 |
如需具体场景的配置细节(如 Spark 集群部署、Flink 状态后端配置),可进一步说明需求。
以下是设计和开发一个类似 Spring Batch 的 Java 批处理框架的详细步骤和核心模块设计,涵盖架构设计、核心组件实现、扩展性及性能优化:
一、总体设计目标
-
核心目标:
- 支持 分块处理(Chunk-based) 和 任务(Tasklet) 模式。
- 提供 事务控制 和 作业状态管理(如重启、暂停、失败恢复)。
- 支持 分布式分片 和 多线程处理。
- 提供 监控与日志 功能(如作业进度、错误记录)。
-
设计原则:
- 模块化:核心组件可插拔(如数据源、处理器、存储)。
- 可扩展性:通过 SPI(Service Provider Interface)扩展算法或适配器。
- 轻量级:避免依赖复杂外部库,核心功能自包含。
二、核心组件设计
1. 作业(Job)
- 定义:批处理任务的顶层容器,由多个步骤(Step)组成。
- 关键接口:
public interface Job {JobExecution execute(JobParameters parameters); }public class SimpleJob implements Job {private List<Step> steps;@Overridepublic JobExecution execute(JobParameters parameters) {JobExecution execution = new JobExecution();for (Step step : steps) {StepExecution stepExecution = step.execute(parameters);execution.addStepExecution(stepExecution);if (stepExecution.getStatus() == Status.FAILED) {execution.setStatus(Status.FAILED);break;}}return execution;} }
2. 步骤(Step)
- 两种模式:
- 分块处理(Chunk-oriented):读取 → 处理 → 写入。
- 任务(Tasklet):自定义单步骤任务(如执行 SQL 脚本)。
- 核心接口:
public interface Step {StepExecution execute(JobParameters parameters); }public class ChunkStep implements Step {private ItemReader<?> reader;private ItemProcessor<?, ?> processor;private ItemWriter<?> writer;private int chunkSize;@Overridepublic StepExecution execute(JobParameters parameters) {StepExecution execution = new StepExecution();List items = new ArrayList<>(chunkSize);while (true) {Object item = reader.read();if (item == null) break;items.add(processor.process(item));if (items.size() == chunkSize) {writer.write(items);items.clear();}}if (!items.isEmpty()) writer.write(items);execution.setStatus(Status.COMPLETED);return execution;} }
3. 作业执行器(JobLauncher)
- 职责:启动作业并管理其生命周期。
- 实现:
public class SimpleJobLauncher {public JobExecution run(Job job, JobParameters parameters) {return job.execute(parameters);} }
4. 作业仓库(JobRepository)
- 职责:持久化作业状态(如数据库表记录)。
- 核心接口:
public interface JobRepository {void saveExecution(JobExecution execution);JobExecution getLastJobExecution(String jobName); }
5. 数据源与处理器
- ItemReader:从数据库、文件或消息队列读取数据。
- ItemProcessor:数据转换或过滤(如字段映射、数据清洗)。
- ItemWriter:批量写入结果(如数据库、文件)。
6. 事务管理
- 分块事务:每
chunkSize条数据提交一次事务。 - 实现:
@Transactional public void processChunk(List items) {// 处理并提交事务 }
三、扩展与优化
1. 分布式分片(Partitioning)
- 场景:将作业分片到多个节点并行处理。
- 实现步骤:
- 分片生成器:定义分片策略(如按文件分片、按数据库分页)。
- 分片执行器:通过
TaskExecutor并行执行分片任务。
public class Partitioner {public Map<String, ExecutionContext> partition(int gridSize) {Map<String, ExecutionContext> partitions = new HashMap<>();for (int i = 0; i < gridSize; i++) {ExecutionContext context = new ExecutionContext();context.putInt("partitionId", i);partitions.put("partition" + i, context);}return partitions;} }
2. 任务执行器(TaskExecutor)
- 多线程支持:通过
ThreadPoolTaskExecutor实现并行处理。 - 配置:
public class ThreadPoolTaskExecutor implements TaskExecutor {private ExecutorService executor;public void execute(Runnable task) {executor.submit(task);} }
3. 监控与日志
- 作业状态跟踪:通过
JobExecution记录进度、错误日志。 - 集成监控工具:如 Prometheus、ELK Stack。
- 实现:
public class JobExecution {private Status status;private List<StepExecution> stepExecutions;private Date startTime;private Date endTime;// getters/setters }
4. 异常处理与重试
- 重试机制:通过
RetryTemplate实现失败重试。 - 配置:
public class RetryTemplate {public void executeWithRetry(RetryCallback callback) {int retryCount = 0;while (retryCount < maxAttempts) {try {callback.doWithRetry();break;} catch (Exception e) {retryCount++;}}} }
四、架构设计图(文字描述)
五、实现步骤
1. 模块划分
| 模块 | 职责 |
|---|---|
| core | 核心接口与基础实现(Job/Step/Item) |
| repository | 作业状态持久化(数据库/内存) |
| executor | 任务调度与并行执行 |
| monitor | 作业监控与日志 |
| extensions | 扩展模块(如分片、重试、适配器) |
2. 开发流程
- 定义核心接口:Job、Step、ItemReader/Processor/Writer。
- 实现基础组件:SimpleJob、ChunkStep、Tasklet。
- 集成事务管理:通过
@Transactional或手动管理。 - 实现分片与并行:Partitioner + TaskExecutor。
- 持久化状态:JobRepository 的数据库实现。
- 添加监控与日志:记录作业执行状态。
- 测试与优化:压力测试、性能调优(如分块大小、线程池配置)。
3. 示例代码结构
// 定义作业
public class MyJob implements Job {@Overridepublic JobExecution execute(JobParameters parameters) {Step step = new ChunkStep().reader(new DatabaseReader()).processor(new DataTransformer()).writer(new FileWriter()).chunkSize(100);return step.execute(parameters);}
}// 启动作业
public class Main {public static void main(String[] args) {JobLauncher launcher = new SimpleJobLauncher();Job job = new MyJob();JobExecution execution = launcher.run(job, new JobParameters());}
}
六、性能优化建议
- 分块大小优化:
- 根据数据量和内存容量调整
chunkSize(如 100-1000 条)。
- 根据数据量和内存容量调整
- 并行处理:
- 使用
ThreadPoolTaskExecutor并行执行步骤或分片。
- 使用
- 资源管理:
- 避免在
ItemReader中频繁打开/关闭数据库连接。
- 避免在
- 缓存中间结果:
- 对于重复计算的数据(如字典映射),使用内存缓存。
七、常见问题与解决方案
1. 作业状态丢失
- 原因:未实现
JobRepository持久化。 - 解决:集成数据库存储(如 MySQL、H2)。
2. 分片数据不均衡
- 原因:分片策略不合理(如固定分片数)。
- 解决:动态分片(如按数据总量分配)。
3. 事务性能瓶颈
- 原因:过大的分块导致事务提交耗时。
- 解决:调整分块大小或使用更高效的数据库索引。
八、总结
通过以上步骤,可以逐步构建一个具备核心功能的批处理框架。关键点在于:
- 模块化设计:将作业、步骤、数据处理分离。
- 事务与状态管理:确保作业的可恢复性。
- 扩展性:通过 SPI 或插件机制支持自定义组件。
如需进一步优化(如与 Spring Boot 集成、支持流处理),可参考 Spring Batch 的实现细节并逐步扩展。