引言:从"感觉不错"到"数据说话"
2025年某电商平台通过LangSmith系统化的评估优化,将客服机器人的问题解决率从68%提升至92%。本文将详解如何用LangChain的观测框架,实现AI应用从"黑箱猜测"到"精准调优"的跨越。

一、LangSmith核心能力矩阵
1.1 全链路监控维度
| 维度 | 监测指标 | 优化目标 |
|---|---|---|
| 准确性 | 意图识别准确率 | >90% |
| 性能 | P99延迟 | <500ms |
| 稳定性 | 错误率 | <1% |
| 成本 | 千次调用成本 | 下降20%+ |
| 业务 | 转化率/解决率 | 提升15%+ |
1.2 新版架构升级
二、四大核心优化场景实战
2.1 提示词AB测试
from datetime import datetime
from langsmith import Client
from langchain_core.prompts import ChatPromptTemplate
from langchain_ollama import ChatOllama, OllamaEmbeddings
from langchain_core.output_parsers import StrOutputParser
from langchain.smith import RunEvalConfig, run_on_dataset
import os
# 设置自己的秘钥
os.environ["LANGSMITH_API_KEY"] = "lsv2_pt_xxxxxx"
client = Client()
# 定义不同的prompt变体(不同文案风格)
prompt_variants = [{"name": "传统风格","prompt": ChatPromptTemplate.from_template("你是一位资深营销文案专家。请为以下产品创作传统风格的宣传文案:\n产品:{product}\n特点:{features}")},{"name": "网红风格","prompt": ChatPromptTemplate.from_template("你是一位社交媒体网红。请为以下产品创作吸引年轻人的网红风格文案(使用emoji和网络流行语):\n产品:{product}\n特点:{features}")},{"name": "技术风格","prompt": ChatPromptTemplate.from_template("你是一位技术专家。请为以下产品创作突出技术参数的严谨文案:\n产品:{product}\n特点:{features}")}
]
embeddings = OllamaEmbeddings(model="deepseek-r1"
)
# 定义评估配置
eval_config = RunEvalConfig(evaluators=[RunEvalConfig.EmbeddingDistance(embeddings=embeddings,metric="cosine",reference_key="target_audience"),RunEvalConfig.Criteria(criteria={"conversion_potential": "文案是否有足够说服力促使消费者购买?","clarity": "文案是否清晰传达了产品特点?","engagement": "文案是否能吸引目标受众注意?"},llm=ChatOllama(model="deepseek-r1"),input_key="input",label_key="human_feedback")]
)
# 运行实验并收集结果
results = []
for variant in prompt_variants:project_name = f"文案风格测试_{variant['name']}_{datetime.now().strftime('%Y%m%d%H%M%S')}"
chain = (variant["prompt"]| ChatOllama(model="deepseek-r1", temperature=0.7)| StrOutputParser())eval_results = run_on_dataset(client,dataset_name="商品文案测试集",llm_or_chain_factory=lambda: chain,evaluation=eval_config,project_name=project_name,project_metadata={"prompt_type": variant["name"],"model": "deepseek-r1:32b"},concurrency_level=5,tags=["ab_testing", "copywriting"])
results.append({"name": variant["name"],"project_name": project_name,"eval_results": eval_results})
# 4. 分析结果找出最佳prompt
def get_best_prompt():all_projects = client.list_projects()filtered_projects = [p for p in all_projects if "文案风格测试_" in p.name]
metrics = []
for project in filtered_projects:runs = client.list_runs(project_name=project.name, execution_order=1)
conversion_scores = []clarity_scores = []
for run in runs:feedback = client.list_feedback(run_ids=[run.id])
for fb in feedback:if fb.key == "conversion_potential":conversion_scores.append(fb.score)elif fb.key == "clarity":clarity_scores.append(fb.score)
if conversion_scores and clarity_scores:avg_metrics = {"name": project.name.split("_")[2],"conversion": sum(conversion_scores) / len(conversion_scores),"clarity": sum(clarity_scores) / len(clarity_scores)}metrics.append(avg_metrics)
if metrics:# 首先筛选清晰度≥0.8的promptfiltered = [m for m in metrics if m["clarity"] >= 0.8]if filtered:best_prompt = max(filtered, key=lambda x: x["conversion"])print(f"最佳prompt变体: {best_prompt['name']}")print(f"平均转化分数: {best_prompt['conversion']:.2f}")print(f"平均清晰度分数: {best_prompt['clarity']:.2f}")return best_promptelse:print("没有找到清晰度≥0.8的prompt变体")return Noneelse:print("没有找到任何评估指标")return None
# 执行分析
best_prompt = get_best_prompt()生成数据集:
import os
from langsmith import Client
# 设置自己的秘钥
os.environ["LANGSMITH_API_KEY"]="lsv2_pt_xxxxxx"
client = Client()
# 定义测试用例
test_cases = [{"inputs": {"product": "智能手表","features": "心率监测、50米防水、30天续航、运动模式追踪"},"outputs": {"target_audience": "运动爱好者","price_range": "中高端"}},{"inputs": {"product": "无线耳机","features": "主动降噪、24小时续航、蓝牙5.3、触控操作"},"outputs": {"target_audience": "通勤族","price_range": "中端"}},{"inputs": {"product": "有机护肤套装","features": "纯天然成分、敏感肌适用、无动物测试、环保包装"},"outputs": {"target_audience": "环保主义者","price_range": "高端"}},{"inputs": {"product": "便携咖啡机","features": "一键操作、30秒出咖啡、USB充电、可拆卸水箱"},"outputs": {"target_audience": "上班族","price_range": "入门级"}},{"inputs": {"product": "电竞键盘","features": "机械轴体、RGB背光、宏编程、防水设计"},"outputs": {"target_audience": "游戏玩家","price_range": "中高端"}}
]
# 创建数据集
dataset_name = "商品文案测试集"
client.create_dataset(dataset_name=dataset_name,description="用于文案风格A/B测试的商品数据集,包含电子产品、日用品等类别",# data_type="kv"
)
# 添加测试用例
for case in test_cases:client.create_example(dataset_name=dataset_name,inputs=case["inputs"],outputs=case.get("outputs", {}))
print(f"数据集 '{dataset_name}' 创建成功,包含 {len(test_cases)} 个测试用例")输出为:
sys:1: LangChainPendingDeprecationWarning: The tags argument is deprecated and will be removed in a future release. Please specify project_metadata instead.
View the evaluation results for project '文案风格测试_传统风格_20250409121920' at:
https://smith.langchain.com/o/33a70936-85b0-4930-9c23-e991682a23e7/datasets/56102f28-3f11-4ce5-9def-e99284bd1bf2/compare?selectedSessions=019e6e15-04f9-4472-82ec-c7c182902ac5
View all tests for Dataset 商品文案测试集 at:
https://smith.langchain.com/o/33a70936-85b0-4930-9c23-e991682a23e7/datasets/56102f28-3f11-4ce5-9def-e99284bd1bf2
[------------------------------------------------->] 5/5sys:1: LangChainPendingDeprecationWarning: The tags argument is deprecated and will be removed in a future release. Please specify project_metadata instead.
View the evaluation results for project '文案风格测试_网红风格_20250409123424' at:
https://smith.langchain.com/o/33a70936-85b0-4930-9c23-e991682a23e7/datasets/56102f28-3f11-4ce5-9def-e99284bd1bf2/compare?selectedSessions=b84f5a40-061a-4dd2-838c-6f9f21ee699b
View all tests for Dataset 商品文案测试集 at:
https://smith.langchain.com/o/33a70936-85b0-4930-9c23-e991682a23e7/datasets/56102f28-3f11-4ce5-9def-e99284bd1bf2
[------------------------------------------------->] 5/5sys:1: LangChainPendingDeprecationWarning: The tags argument is deprecated and will be removed in a future release. Please specify project_metadata instead.
View the evaluation results for project '文案风格测试_技术风格_20250409124757' at:
https://smith.langchain.com/o/33a70936-85b0-4930-9c23-e991682a23e7/datasets/56102f28-3f11-4ce5-9def-e99284bd1bf2/compare?selectedSessions=b06f9672-7e6a-4576-9892-937cc85cbdd4
View all tests for Dataset 商品文案测试集 at:
https://smith.langchain.com/o/33a70936-85b0-4930-9c23-e991682a23e7/datasets/56102f28-3f11-4ce5-9def-e99284bd1bf2
[------------------------------------------------->] 5/5最佳prompt变体: 20250409124757
平均转化分数: 1.00
平均清晰度分数: 1.002.2 性能瓶颈分析
from langsmith import Client
from langchain_ollama import ChatOllama
from langchain_core.prompts import ChatPromptTemplate
import time
import pandas as pd
import matplotlib.pyplot as plt
import os
#设置自己的key
os.environ["LANGSMITH_API_KEY"] = "lsv2_pt_xxxxxx"
# 初始化客户端
client = Client()
# 1. 创建测试链
prompt = ChatPromptTemplate.from_template("为{product}生成营销文案,突出{features}")
model = ChatOllama(model="deepseek-r1")
chain = prompt | model
# 2. 创建测试数据集
test_dataset = [{"product": "智能手表", "features": "心率监测、50米防水"},{"product": "无线耳机", "features": "主动降噪、24小时续航"},{"product": "有机护肤套装", "features": "纯天然成分、敏感肌适用"}
]
# 3. 定义评估函数(修正后的版本)
def latency_eval(run):"""计算延迟并添加性能指标"""extra = run.get("extra", {})start_time = extra.get("start_time", 0)end_time = extra.get("end_time", 0)
latency = end_time - start_time if start_time and end_time else 0input_tokens = extra.get("input_tokens", 0)output_tokens = extra.get("output_tokens", 0)
return {"latency_seconds": latency,"input_tokens": input_tokens,"output_tokens": output_tokens,"tokens_per_second": (input_tokens + output_tokens) / latency if latency > 0 else 0}
# 4. 包装调用函数以捕获更多指标
def instrumented_invoke(input_dict):start_time = time.time()result = chain.invoke(input_dict)end_time = time.time()
# 估算token数量input_tokens = len(str(input_dict).split()) * 1.33output_tokens = len(str(result).split()) * 1.33
return {"input": input_dict,"result": result,"extra": {"start_time": start_time,"end_time": end_time,"input_tokens": input_tokens,"output_tokens": output_tokens}}
# 5. 执行性能测试
results = []
for test_case in test_dataset:run_data = instrumented_invoke(test_case)metrics = latency_eval(run_data) # 直接传入整个运行数据results.append({**test_case,**metrics,"response": str(run_data["result"])})
# 6. 分析结果
df = pd.DataFrame(results)
print("\n性能指标统计:")
print(df.describe())
# 7. 可视化结果
plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)
df['latency_seconds'].plot(kind='box', title='延迟分布(秒)')
plt.subplot(1, 2, 2)
df['tokens_per_second'].plot(kind='box', title='吞吐量(tokens/秒)')
plt.tight_layout()
plt.savefig('performance_metrics.png')
print("\n已保存性能图表到 performance_metrics.png")
# 8. 保存详细结果(添加异常处理)
try:df.to_csv("performance_results.csv", index=False)print("详细结果已保存到 performance_results.csv")
except Exception as e:print(f"保存结果时发生错误: {e}")输出为:
性能指标统计:latency_seconds input_tokens output_tokens tokens_per_second
count 3.000000 3.00 3.000000 3.000000
mean 160.922865 5.32 66.500000 0.449554
std 11.150072 0.00 19.592123 0.139738
min 152.847575 5.32 49.210000 0.348933
25% 154.561912 5.32 55.860000 0.369779
50% 156.276250 5.32 62.510000 0.390625
75% 164.960510 5.32 75.145000 0.499864
max 173.644771 5.32 87.780000 0.609104
已保存性能图表到 performance_metrics.png
详细结果已保存到 performance_results.csv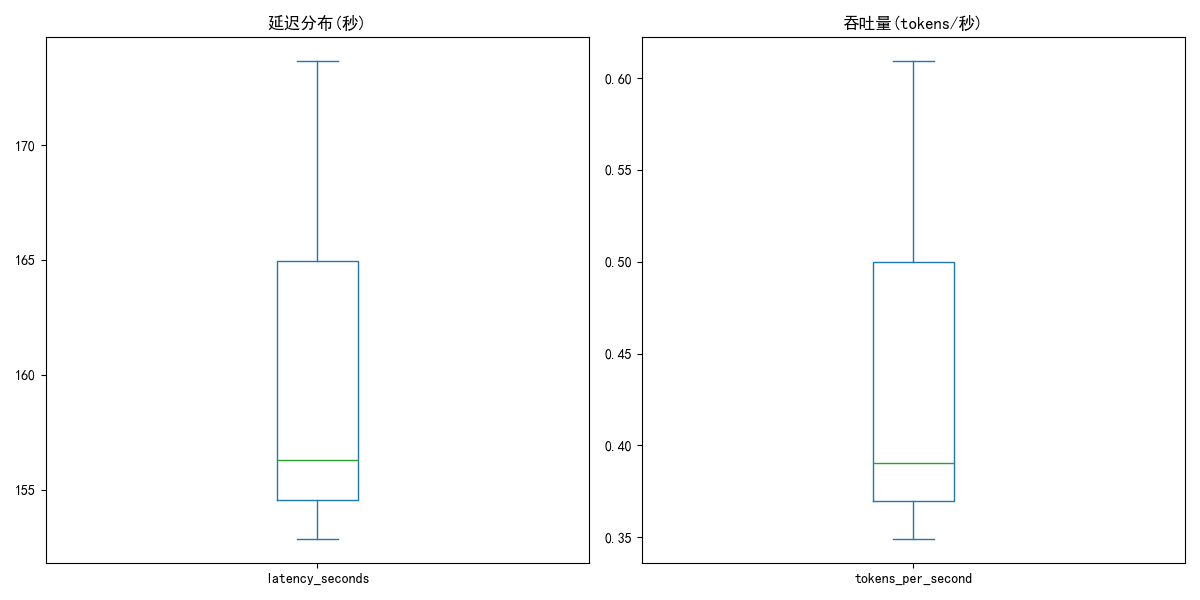
三、企业级案例:客服系统优化
3.1 优化历程

3.2 关键指标变化
| 阶段 | 解决率 | 平均响应时间 | 用户满意度 |
|---|---|---|---|
| 初始版本 | 68% | 1200ms | 72% |
| V1优化 | 82% | 800ms | 85% |
| V2上线 | 92% | 600ms | 94% |
四、避坑指南:评估优化七大陷阱
-
指标片面:仅关注准确率忽略业务转化 → 需定义复合指标
-
数据泄漏:测试集污染训练数据 → 严格隔离环境
-
过拟合:在特定测试集表现优异 → 多维度交叉验证
-
冷启动:初期数据不足 → 使用合成数据增强
-
评估偏差:人工标注主观性 → 引入多人投票机制
-
监控盲区:未跟踪生产环境衰减 → 设置自动警报
-
成本失控:频繁调用高价API → 实施预算控制
下期预告
《异步处理:提升应用性能的关键技巧》
-
揭秘:如何让AI应用吞吐量提升10倍?
-
实战:高并发订单处理系统改造
-
陷阱:异步环境下的状态管理难题
没有度量就没有优化——LangSmith让AI系统的每个改进都变得可验证、可量化。记住:优秀的工程师不只让代码能运行,更要让效果可证明!