一、scrapy爬虫框架
Scrapy 框架是一个基于Twisted的一个异步处理爬虫框架,应用范围非常的广泛,常用于数据采集、网络监测,以及自动化测试等。
scrapy框架包括5个主要的组件:
Scheduler:事件调度器,它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
Downloader:下载器,接收Scrapy Engine(引擎)发送的所有Requests请求,从网上下载数据,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理
Spiders:爬虫,发起爬虫请求,并解析DOWNLOADER返回的网页内容,同时和数据持久化进行交互,需要开发者编写
Item Pipeline:实体管道,它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方,需要开发者编写
Engine:Scrapy引擎,负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
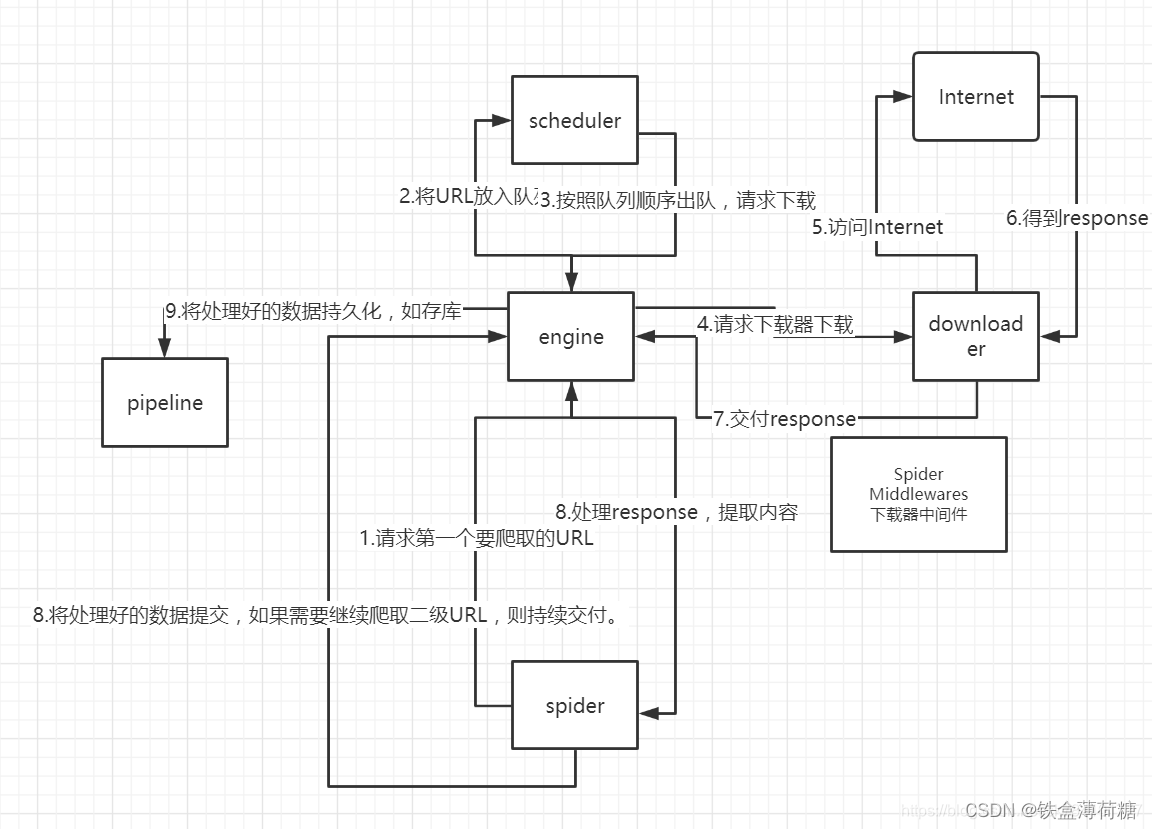
图来源: Scrapy爬虫框架,入门案例(非常详细)_scrapy爬虫案例python-CSDN博客
从上可知,我们只要实现SPIDERS(要爬什么网站,怎么解析)和ITEM PIPELINES(如何处理解析后的内容)就可以了。其他的都是有框架帮你完成了。
二、XPath基础
通过XPath来解析网页,提取内容
1 HTML节点和属性
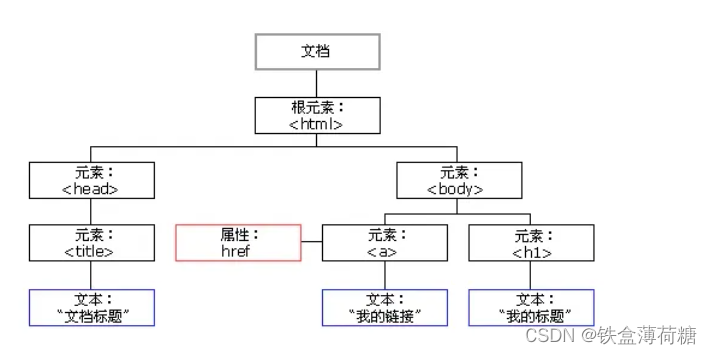
2 解析语法
(1)a / b:‘/’在 xpath里表示层级关系,左边的 a是父节点,右边的 b是子节点
(2)a // b:表示a下所有b,直接或者间接的
(3)[@]:选择具有某个属性的节点
例如://div[@classs], //a[@x]:选择具有 class属性的 div节点、选择具有 x属性的 a节点
//div[@class="container"]:选择具有 class属性的值为 container的 div节点
(4)//a[contains(@id, "abc")]:选择 id属性里有 abc的 a标签
示例代码;
response.xpath('//div[@class="taglist"]/ul//li//a//img/@data-original').get_all()
# 获取所有class属性(css)为taglist的div, 下一个层ul下的所有li下所有a下所有img标签下data-original属性# data-original这里放的是图片的url地址更多详见XML数据定位神器:详解XPath语法大全以及使用方法 - 知乎
三、安装部署
pip install scrapy四、配置文件settings.py 介绍
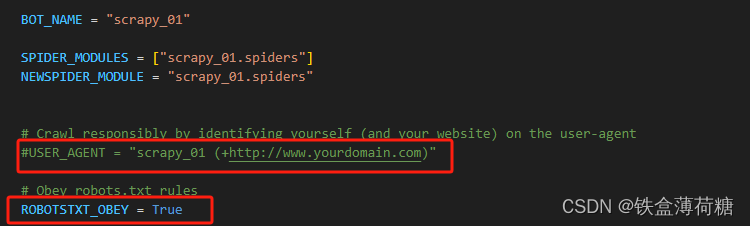
(1)BOT_NAME:项目名
(2)USER_AGENT:默认是注释的,这个东西非常重要,如果不写很容易被判断为电脑,简单写一个Mozilla/5.0即可
(3)ROBOTSTXT_OBEY:是否遵循机器人协议,默认是true,运行爬虫的时候仍然没有内容查询,则需要考虑需要改为false或注释掉,君子协议 一般情况下我们不遵守
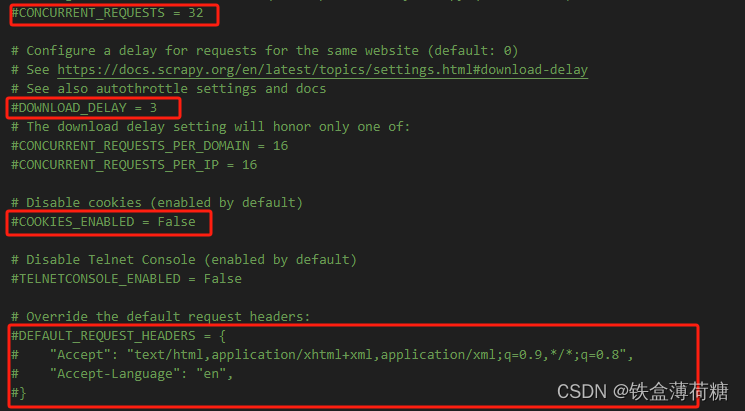
(4)CONCURRENT_REQUESTS:最大并发数,即同时允许开启多少个爬虫线程
(5)DOWNLOAD_DELAY:下载延迟时间,单位是秒,控制爬虫爬取的频率,根据项目调整,默认是3秒,即爬一个停3秒,设置为1秒性价比较高,如果要爬取的文件较多,写零点几秒也行
(6)COOKIES_ENABLED:是否保存COOKIES,默认关闭,开启可以记录爬取过程中的COKIE,非常好用的一个参数
(7)DEFAULT_REQUEST_HEADERS:默认请求头,上面写了一个USER_AGENT,其实这个东西就是放在请求头里面的,可以根据你爬取的内容做相应设置。
(8)ITEM_PIPELINES:项目管道,300为优先级,越低越爬取的优先度越高
例如:pipelines.py里面写了两个管道,一个爬取网页的管道,一个存数据库的管道,通过调整优先级,使爬虫优先执行存库操作。

参考自:Scrapy爬虫框架,入门案例(非常详细)_scrapy爬虫案例python-CSDN博客