1.索引
Innodb
-
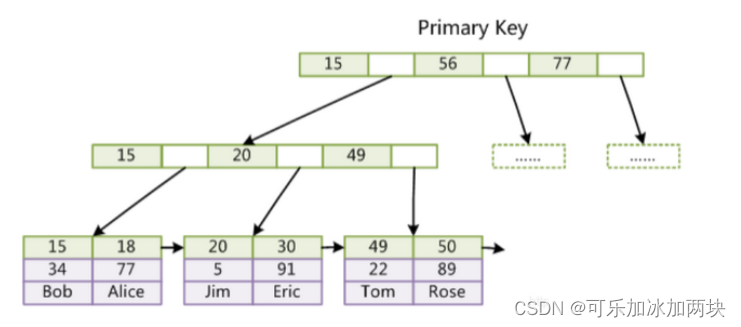
使用B+树作为索引结构,索引跟数据存放在同一个文件中。表数据文件本身就是按照B+树组织的一个索引结构,这颗树的叶子节点的data域保存了完整的数据记录,这个索引的key是数据表主键,InnoDB表数据文件本身就是主索引
-
InnoDB的主索引是聚簇索引(聚簇索引是数据存储与索引合二为一的)表中的数据行按主键的顺序存储在一起,因此每个表只能有一个聚簇索引。由于数据按主键顺序存储,主键查找效率非常高。
-
InnodDB存储引擎中,至少会有一个聚簇索引。在创建表时,如果表有主键,那么主键会成为聚簇索引。如果表没有主键,则第一个非空唯一索引将被用作聚簇索引。如果没有这样的索引,InnoDB会生成一个隐藏的行ID作为聚簇索引
-
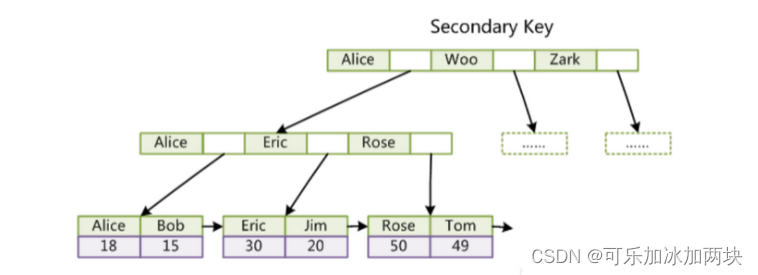
InnoDB的辅助索引是指聚簇索引外,用户定义的其他索引(非聚簇索引),只存储索引列和主键值:数据行不直接存储在辅助索引中。查找时先通过辅助索引找到主键值,然后再通过聚簇索引找到实际数据行
-
每个表可以有多个辅助索引,辅助索引有助于加速特定列上的查询
-
支持事务、外键
-
支持行级锁,能够提高并发性能。只有在实际需要时才锁定单行数据,适合高并发写操作的应用。
MyISAM
-
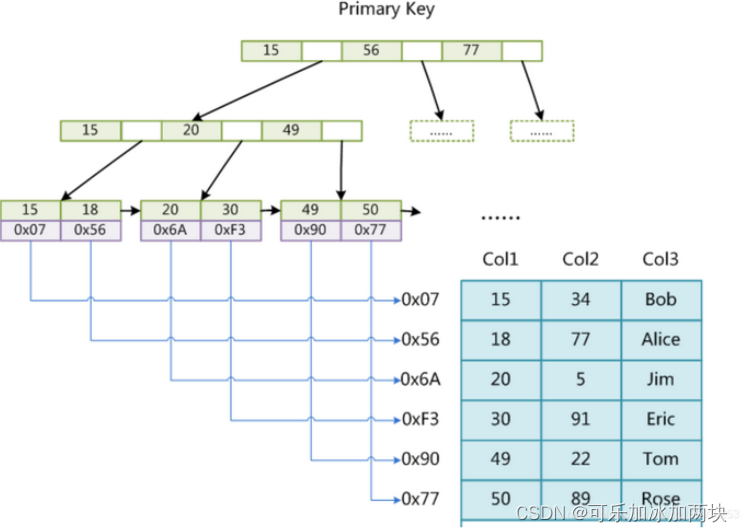
也是使用B+树作为索引结构,叶节点的data域存放的是数据记录的地址。MyISAM中索引检索的算法为首先按照B+Tree搜索算法搜索索引,如果指定的Key存在,则取出其data域的值,然后以data域的值为地址,读取相应数据记录(非聚簇索引)。
-
索引跟文件在不同的文件中存储
-
在MyISAM中,主索引和辅助索引(Secondary key)在结构上没有任何区别,只是主索引要求key是唯一的,而辅助索引的key可以重复
-
只支持表级锁,当执行查询或写操作时会锁定整个表,适合读操作多于写操作的应用。
-
不支持事务,因此不支持提交和回滚操作。不支持外键约束。
-
对全文索引的支持较好,适合需要全文搜索的应用。
2.索引失效情况及如何解决
使用函数或表达式
-
场景:在查询条件中对索引列使用了函数或表达式。
-
示例:
SELECT * FROM users WHERE YEAR(birth_date) = 2022;
-
解决方法:尽量避免在索引列上使用函数或表达式,将计算移到应用层或查询条件外部。
-
优化后
SELECT * FROM users WHERE birth_date BETWEEN '2022-01-01' AND '2022-12
类型转换导致索引失效
场景:查询条件中的字段类型与索引列类型不匹配,导致隐式类型转换。
示例:
SELECT * FROM users WHERE phone_number = 1234567890; -- phone_number 是字符串类型
解决方法:确保查询条件中的字段类型与索引列类型匹配。
优化后:
SELECT * FROM users WHERE phone_number = '1234567890';
使用前导模糊匹配
场景:在LIKE查询中使用前导通配符。
示例:
SELECT * FROM users WHERE name LIKE '%John%';
解决方法:避免在前导位置使用通配符,可以考虑使用全文索引或其他搜索引擎。
优化后:
SELECT * FROM users WHERE name LIKE 'John%';
不等运算符和范围查询
场景:使用不等运算符(!=, <>, <, >, <=, >=)或范围查询可能会导致部分索引失效。
示例:
SELECT * FROM users WHERE age != 30;
解决方法:在设计查询时尽量避免使用不等运算符,或使用合适的索引来优化范围查询。
优化后:
SELECT * FROM users WHERE age > 30 OR age < 30;
复合索引中的列顺序没有使用最左前缀原则
场景:查询条件没有使用复合索引的最左前缀列。
示例:
CREATE INDEX idx_name_age ON users (name, age);SELECT * FROM users WHERE age = 25; -- 索引失效
解决方法:确保查询条件使用了复合索引的最左前缀列。
优化后:
SELECT * FROM users WHERE name = 'John' AND age = 25;
OR条件
场景:使用OR条件时,如果OR两侧的条件列没有联合索引,索引可能失效。
示例:
SELECT * FROM users WHERE name = 'John' OR age = 25;
解决方法:使用UNION将查询分解为两个独立查询,或创建联合索引。
优化后:
SELECT * FROM users WHERE name = 'John'UNIONSELECT * FROM users WHERE age = 25;
ORDER BY和GROUP BY不使用索引
场景:ORDER BY和GROUP BY子句中的列没有索引。
示例:
SELECT * FROM users ORDER BY age;
解决方法:确保ORDER BY和GROUP BY列上有合适的索引。
优化后:
CREATE INDEX idx_age ON users (age);SELECT * FROM users ORDER BY age;
使用负面条件
-
场景:使用负面条件如NOT IN、NOT EXISTS、IS NULL或IS NOT NULL。
示例:
SELECT * FROM users WHERE name IS NOT NULL;
解决方法:重新设计查询条件,避免使用负面条件。
优化后:
SELECT * FROM users WHERE name LIKE '%'; -- 仅适用于非空字符串
3.如何使用explain命令分析mysql查询的执行计划
通过分析EXPLAIN输出,可以识别潜在的性能问题并优化查询和索引。
-
查看额外条件是否需要额外表或者排序,可以考虑给对应字段加索引
-
如果需要获取的字段不是全部字段,是否可以考虑使用复合索引,减少回表
-
如果执行计划的表是全表扫描,是否需要加索引
EXPLAIN SELECT * FROM `user`JOIN `post` ON `user`.id = `post`.uidWHERE user.`created_at` < '2018-10-01 00:00:00' AND `post`.status = 1;
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | user | range | PRIMARY,idx_created_at | idx_created_at | 7 | null | 19440 | Using index condition; Using where; Using temporary; Using filesort |
| 1 | SIMPLE | post | ref | idx_uid,idx_status | idx_uid | 8 | user.id | 1 | Using where |
EXPLAIN 输出字段
id:
-
查询的序列号,标识查询中每个选择部分的顺序。一般来说,id越大,优先级越高。
-
同一个id的行表示是联合查询的一部分(如子查询或联合查询)。
select_type:
-
查询的类型,如SIMPLE(简单查询)、PRIMARY(主查询)、SUBQUERY(子查询)等。
-
常见类型包括:
-
SIMPLE: 简单查询,不包含子查询或UNION。 -
PRIMARY: 包含子查询的最外层查询。 -
SUBQUERY: 子查询中的第一个SELECT。 -
DERIVED: 派生表(子查询的结果作为临时表)。
-
table:
-
正在访问的表的名称。
type:
-
表示MySQL如何查找表中的行。性能从好到差的类型如下:
-
system: 表仅有一行(系统表)。 -
const: 表包含一行匹配行。 -
eq_ref: 对于每个来自前一张表的行,读取一行。 -
ref: 使用非唯一索引扫描查找匹配行。 -
range: 使用索引范围扫描。 -
index: 全索引扫描。 -
ALL: 全表扫描。
-
possible_keys:
-
查询中可能使用的索引。
key:
-
实际使用的索引。如果是NULL,则没有使用索引。
key_len:
-
使用索引的长度(字节数)。显示MySQL从索引中使用的部分。
ref:
-
显示索引用于查找值的列或常量。
rows:
-
MySQL估计要读取的行数。
filtered:
-
通过条件过滤的行百分比。
Extra:
-
额外信息,描述查询计划的详细信息,如是否使用文件排序、临时表等。
优化建议
-
user表的优化:-
现状:
user表使用idx_created_at索引进行范围扫描。额外的信息显示需要使用临时表和文件排序,这可能影响性能。
-
- **建议**:- 尽量减少使用临时表和文件排序。如果查询结果需要排序,考虑在索引中包含排序列。- 例如,如果`user`表经常按`created_at`排序,可以创建复合索引 `(created_at, id)`,以减少排序开销。
-
post表的优化: - 现状:post表使用idx_uid索引进行引用查找。 - 建议: - 确保post表上的idx_uid索引高效。如果有必要,也可以创建复合索引(uid, status),以便更好地支持WHERE条件中的status过滤。
CREATE INDEX idx_uid_status ON post(uid, status);
-
进一步优化: - 使用覆盖索引:如果查询中选择的列都包含在索引中,可以使用覆盖索引来提高查询性能。 - 避免SELECT *:选择具体的列而不是使用
SELECT *,这可以减少传输的数据量,并可能使索引更加有效。
例如,优化后的查询:```sqlEXPLAIN SELECT user.id, user.created_at, post.uid, post.statusFROM `user`JOIN `post` ON `user`.id = `post`.uidWHERE user.`created_at` < '2018-10-01 00:00:00' AND `post`.status = 1;```
4.查询计划分析工具: - 使用MySQL的ANALYZE功能分析表的统计信息,确保查询优化器能够正确选择最佳的索引。
```sqlANALYZE TABLE user;ANALYZE TABLE post;```
ANALYZE TABLE 是 MySQL 中的一条命令,用于更新表的索引统计信息。通过收集并存储表的统计信息,MySQL 查询优化器可以更好地选择合适的索引和执行计划,从而提高查询性能。