C++内存管理

C/C++内存分布
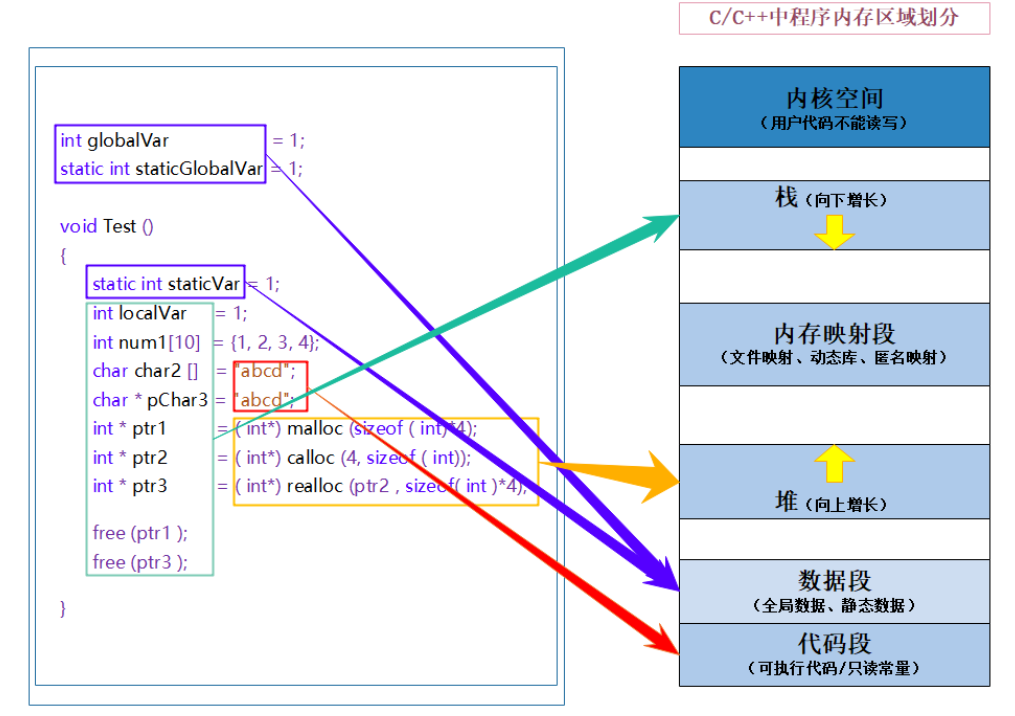
我们的内存区域是要进行划分的。
电脑上有哪些核心资源?CPU(GPU也是一种特殊的CPU)、内存、磁盘。
程序运行本质是把写好的程序编译成指令。操作系统就像一个工厂,进程就像里面的机器人或工人,需要干活,我们的代码以进程的角度运行。我们需要给进程分配资源和原料。
在电脑的任务管理器就可以看到进程。
C/C++是以什么样的方式给它们分配内存的呢?
程序运行本质上就是处理各种数据,执行各种指令,得到一个结果。我们写的程序中不同的数据要存储在不同的阶段。局部数据如函数调用建立栈帧,用一会就销毁了;或者需要长期允许的,全局数据和静态数据;还有不修改的常量数据;还有需要动态申请的数据。
每个进程都有虚拟进程地址空间,然后要通过页表,跟物理内存进行映射。
进程执行其实就是从代码段上依次去取指令放到CPU上执行。
……
- 栈又叫堆栈–非静态局部变量/函数参数/返回值等等,栈是向下增长的。
- 内存映射段是高效的I/O映射方式,用于装载一个共享的动态内存库。用户可使用系统接口创建共享共享内存,做进程间通信。
- 堆用于程序运行时动态内存分配,堆是可以上增长的。
- 数据段–存储全局数据和静态数据。
- 代码段–可执行的代码/只读常量。
题目
现在我们可以通过题目来巩固一下内存管理的知识:


这就是我们平时会遇到的一些数据,清楚它们存放的段是很重要的。
第一组:
第一个是全局变量,所以在数据段(静态区)。
第二个是全局静态变量,放在数据段。
第三个是局部静态,也在数据段。
第四个是静态变量,在栈。
第五个,数组名代表整个数组,是局部数组,所以在栈。
第二组:
第一个char2是一个数组,在栈。
第二个*char2代表首元素。我们分析一下char char2[]="abcd";,意思是在栈上开了5字节的数组,然后把a b c d \0字符拷贝过来放到内存中(严格来说存的是ASCII码)。所以首元素是’a’。所以char在栈上。
数组名,sizeof(数组名)的时候,是代表整个数组。进行运算的时候,是首元素地址。
第三个,pChar3是一个字符指针,本身也是局部变量,在栈上。
第四个,pChar3指向的是常量字符串,常量字符串放在常量区也就是代码段,所以*pChar3是首元素,也就在代码段上。
第五个,ptr1也是栈上一个指针变量,占4个字节,指向堆上开的一块空间 。
第六个,*ptr1就在堆上。
char2是一个数组,pChar3是一个指针,一定要注意区分。
局部变量都是在栈上的,因为函数调用会建立栈帧,局部变量都存在这个栈帧里,函数结束也就跟着销毁。
其实我们自己要管的是堆上的数据。
C语言中动态内存管理方式:malloc/calloc/realloc/free
void Test ()
{// 1.malloc/calloc/realloc的区别是什么?int* p2 = (int*)calloc(4, sizeof (int));int* p3 = (int*)realloc(p2, sizeof(int)*10);// 这里需要free(p2)吗?free(p3 );
}
//答案:这里不需要free(p2)。realloc是原地或者异地扩容,如果空间足够原地扩容,那么释放p3也就把p2释放了;如果是异地扩容,它会把p2先释放掉。也不需要管。
-
malloc/calloc/realloc的区别?
calloc相当于malloc+memset,也就是要初始化。realloc主要是扩容。
-
malloc的实现原理?这里不说了。
C++内存管理方式
C语言内存管理方式在C++中可以继续使用,但有些地方就无能为力,而且使用起来比较麻烦,因 此C++又提出了自己的内存管理方式:
通过new和delete操作符进行动态内存管理。
new是一个关键字,不是一个函数,new后面直接跟类型就可以申请对象。
//申请一个int类型的对象:
int main()
{int* p1 = new int;//不需要类型强转、计算大小int* p2 = new int[10];delete p1;delete[] p2;//要匹配//申请对象+初始化int* p3 = new int(1);int* p4 = new int[10]{0};//全部初始化为0int* p5 = new int[10]{1,2,3,4,5};//初始化前5个delete p3;delete[] p4;delete[] p5;return 0;
}
C++弄出new,只是为了使用更方便吗?
回答这个问题之前,这前面我们看的都是内置类型,现在我们来看自定义类型。
int main()
{A* p1 = new A;A* p2 = new A(1);delete p1;delete p2;return 0;
}
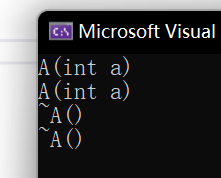
可以看到,我们用new和delete的时候,C++对于自定义类型,自己去调用了构造函数和析构函数。这才是真正的区别。
那么,我们就会有一个疑问,自己去调用构造函数和析构函数,真的这么重要吗?
我们回忆一下链表结点,在C语言中,申请一个新的链表我们一般调用已经写好的BuyNode函数,而在C++中,struct升级成为了类,也就是说有了构造函数。
struct ListNode
{int val;ListNode* next;ListNode(int x):val(x),next(nullptr){}
};int main()
{return 0;
}
那么现在我们要得到一个新的结点,可以看到,这个构造函数干的事情基本上就是我们原来BuyNode干的事。
我们可以快速得到一个链表:
struct ListNode
{int val;ListNode* next;ListNode(int x):val(x),next(nullptr){}
};int main()
{ListNode* n1 = new ListNode(1);ListNode* n2 = new ListNode(1);ListNode* n3 = new ListNode(1);ListNode* n4 = new ListNode(1);n1->next = n2;n1->next = n3;n1->next = n4;return 0;
}
new一个结点的时候我们不仅申请了空间,还调用了构造函数进行初始化。而malloc只开空间无法做到开空间时同时初始化。
我们再看这个场景:
没有默认构造了
class A
{
public:A(int a1,int a2 = 0)//现在没有默认构造了:_a1(a1),_a2(a2){cout << "A(int a1 = 0,int a2 = 0)" << endl;}private:int _a1 = 1;int _a2 = 1;
};struct ListNode
{int val;ListNode* next;ListNode(int x):val(x),next(nullptr){}
};int main()
{A* p1 = new A(1);A* p2 = new A(2,2);//创建并初始化一个A类型数组——有名对象写法A aa1(1, 1);A aa2(2, 2);A aa3(3, 3);A* p3 = new A[3]{ aa1,aa2,aa3 };//严格来说调用的是拷贝构造而不是构造了,因为这三个有名对象是已存在的//匿名对象写法A* p4 = new A[3]{ A(1,1),A(2,2),A(3,3) };//构造匿名对象再去拷贝构造,编译器会进行优化。return 0;
}
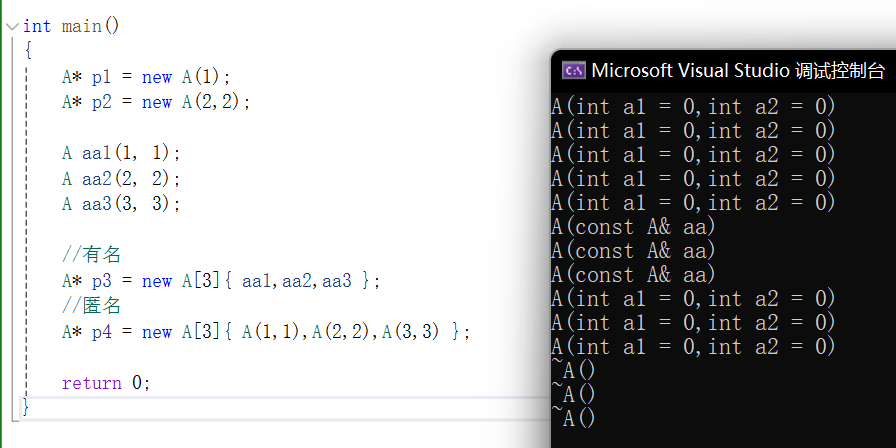
在上一句有名对象的三次拷贝构造结束后,可以看到只进行了三次直接的构造,并没有再拷贝构造。
这只是第二种写法,其实还有第三种写法:
int main()
{A aa1(1, 1);A aa2(2, 2);A aa3(3, 3); //有名对象A* p3 = new A[3]{ aa1,aa2,aa3 };//匿名对象A* p4 = new A[3]{ A(1,1),A(2,2),A(3,3) };//隐式类型转换写法A* p5 = new A[3]{ {1,1},{2,2},{3,3} };return 0;
}
我们之前就说过,单参数构造函数支持隐式类型转换,多参数构造函数在C++11之后也支持隐式类型转换,需要用一个花括号括起来。
我们可以再深入梳理一下,第一种就是构造有名对象去拷贝构造数组;第二种是构造匿名对象去拷贝构造数组,但是编译器优化成 ;第三种本质上其实和第二种还是一样的:先构造临时对象,再去拷贝构造数组。编译器优化后第三种也是直接构造。
同时,也再次体现了默认构造函数的重要性。
这些各种括号的不同使用场景,要理解。
从此以后,一般情况下,不管是内置类型还是自定义类型需要申请内存,我们不再使用malloc而是使用new和delete。
申请资源失败
还有一个问题,以前malloc失败了我们需要检查。现在怎么不检查了呢?
其实是因为我们改用抛异常了。
我们malloc失败,返回的是空,而new失败返回的不是空。所以检查返回值是没用的。
日常中,动态开辟内存基本不会失败,所以我们一般不去管。
1M(兆)约等于100wByte。1G约等于10亿Byte。
1 T B = 1024 G B 1TB=1024GB 1TB=1024GB
1 G = 1024 M B = 1024 ✕ 1024 K B = 1024 ✕ 1024 ✕ 1024 B y t e 1G=1024MB=1024✕1024KB=1024✕1024✕1024Byte 1G=1024MB=1024✕1024KB=1024✕1024✕1024Byte
int main()
{void* p1 = new char[1024 * 1024 * 1024];cout << p1 << endl;void* p2 = new char[1024 * 1024 * 1024];cout << p2 << endl;void* p3 = new char[1024 * 1024 * 1024];cout << p3 << endl;return 0;
}
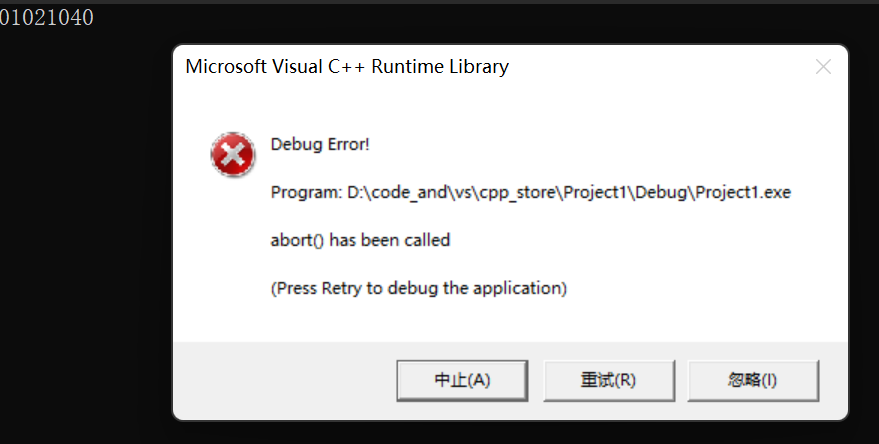
可以看到,程序终止了。
我们这里其实是一次就申请了一个G,在申请第二个G的时候就出错了。
这是一种捕获异常的写法。
还有一种:
那么我们现在看一下能申请多少兆的空间:
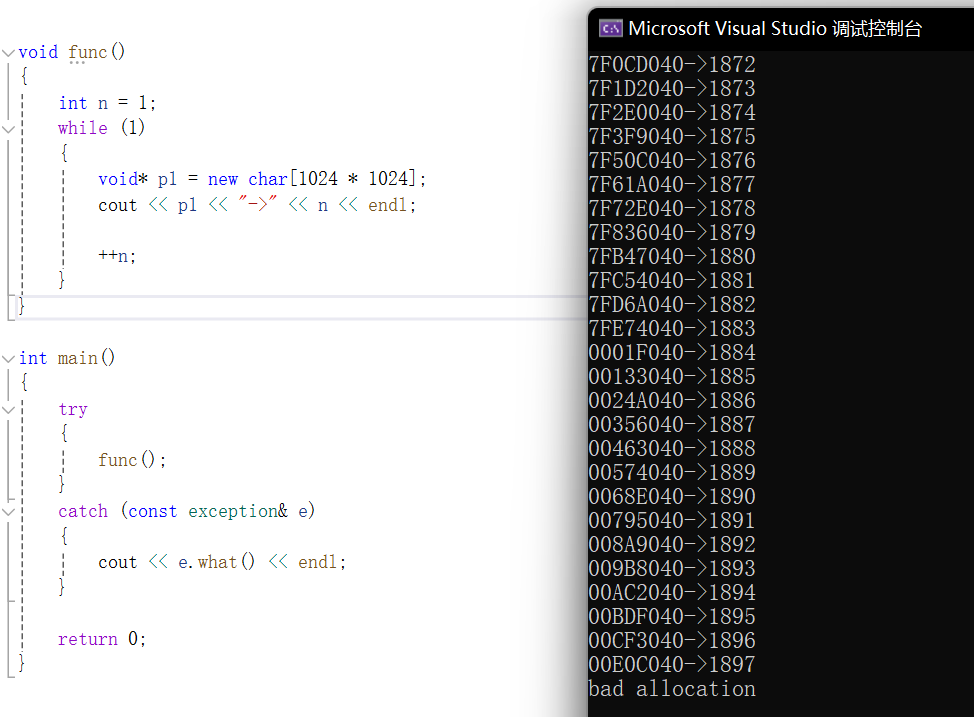
32位下,最多能在堆上申请1897兆,不到2G内存。现在申请的是虚拟内存。32位的进程地址空间都是4G,而实际内存条是16G。这之间存在虚拟内存和物理内存的映射。
64位的虚拟空间非常大,大概是42亿乘4G,一百六十多亿G。 2 64 2^{64} 264。 2 32 2^{32} 232是4G
回到我们刚才的程序,32位下4G的虚拟内存,堆就已经给了将近2G,已经很大了。
32位程序指的到底是什么?
我们平时说的指针,本质是一个编号。空指针也是有编号的,对应第0个字节。一个字节对应一个编号,有 2 32 2^{32} 232个字节,对应 2 32 2^{32} 232个编号。 2 30 2^{30} 230是1G,所以 2 32 2^{32} 232是4G。32位下的指针是4字节,因为4字节的编号就能从00000000存到FFFFFFFF
64位下的地址从0000000000000000到FFFFFFFFFFFFFFFF,需要8个字节来存这个编号。64位下内存的各个区域都会大很多。大概整个空间有160亿G。因为 2 64 2^{64} 264不是 2 32 2^{32} 232的两倍,而是 2 32 2^{32} 232倍。42亿乘4G。
那么我们把刚才写的程序切换到64位环境运行一下:
void func()
{int n = 1;while (1){void* p1 = new char[1024*1024 * 1024];cout << p1 << "->" << n << endl;++n;}
}int main()
{try{func();}catch (const exception& e){cout << e.what() << endl;}return 0;
}
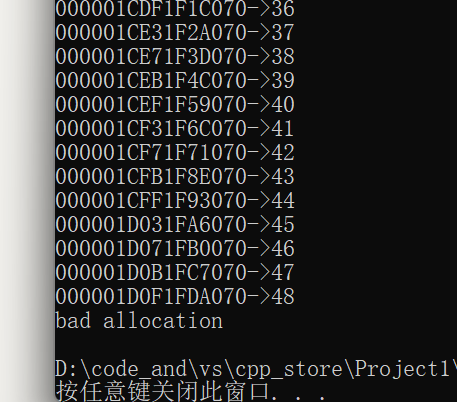
申请了48G空间左右。
如果更深去了解,160多亿G其实留了一部分没有用,因为实在太大了。
申请的是虚拟内存。会分块进行映射。当然这都是简单的说法,只是提一嘴。
一般情况下,32位下的线程,栈只分配8M,800w字节;堆是1.8G左右。所以递归深度太深栈会溢出。所以数据量很大的时候要去堆上申请,而不能借助栈。除了递归不要太深外,在栈上也不要定义大数组。
new和delete的底层原理
new和delete是用户进行动态内存申请和释放的操作符,operator new 和operator delete是系统提供的全局函数,new在底层调用operator new全局函数来申请空间,delete在底层通过operator delete全局函数来释放空间。
/*
operator new:该函数实际通过malloc来申请空间,当malloc申请空间成功时直接返回;申请空间失败,尝试执行空间不足应对措施,如果该应对措施用户设置了,则继续申请,否则抛异常。
*/
void *__CRTDECL operator new(size_t size) _THROW1(_STD bad_alloc)
{// try to allocate size bytesvoid *p;while ((p = malloc(size)) == 0)if (_callnewh(size) == 0){// report no memory// 如果申请内存失败了,这里会抛出bad_alloc 类型异常static const std::bad_alloc nomem;_RAISE(nomem);}return (p);
}/*
operator delete: 该函数最终是通过free来释放空间的*/void operator delete(void *pUserData)
{_CrtMemBlockHeader * pHead;RTCCALLBACK(_RTC_Free_hook, (pUserData, 0));if (pUserData == NULL)return;_mlock(_HEAP_LOCK); /* block other threads */__TRY/* get a pointer to memory block header */pHead = pHdr(pUserData);/* verify block type */_ASSERTE(_BLOCK_TYPE_IS_VALID(pHead->nBlockUse));_free_dbg( pUserData, pHead->nBlockUse );__FINALLY_munlock(_HEAP_LOCK); /* release other threads */__END_TRY_FINALLYreturn;
}/*
free的实现
*/
#define free(p) _free_dbg(p, _NORMAL_BLOCK)
里面有很多我们暂且看不明白的内容,但是总的来说,operator new和operator delete调用的就是malloc和free。
operator new和operator delete与new和delete的关系是什么呢?
new由两部分构成,一部分是开空间,一部分是调用构造函数。
- new的原理
- 调用operator new函数申请空间
- 在申请的空间上执行构造函数,完成对象的构造
为什么要弄出一个operator new(披着马甲的malloc)而不是直接用malloc呢?因为我们知道malloc申请失败直接就返回空了,而C++期望的是申请失败后走抛异常的机制,所以用operator new给malloc套了一个马甲。
对于内置类型,new直接调用operator new申请空间就行了,对于自定义类型,还会去执行构造函数。
我们看一下编译后生成的指令:
看看反汇编:
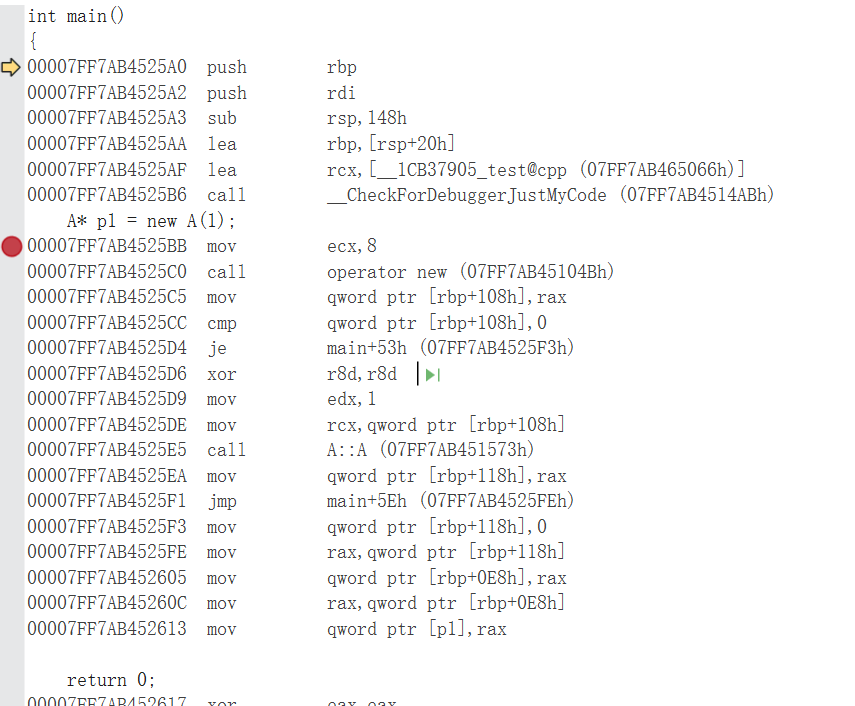
可以看到编译器做了两件事,申请空间和调用构造函数。
再看看delete:
int main()
{A* p1 = new A(1);delete p1;return 0;
}
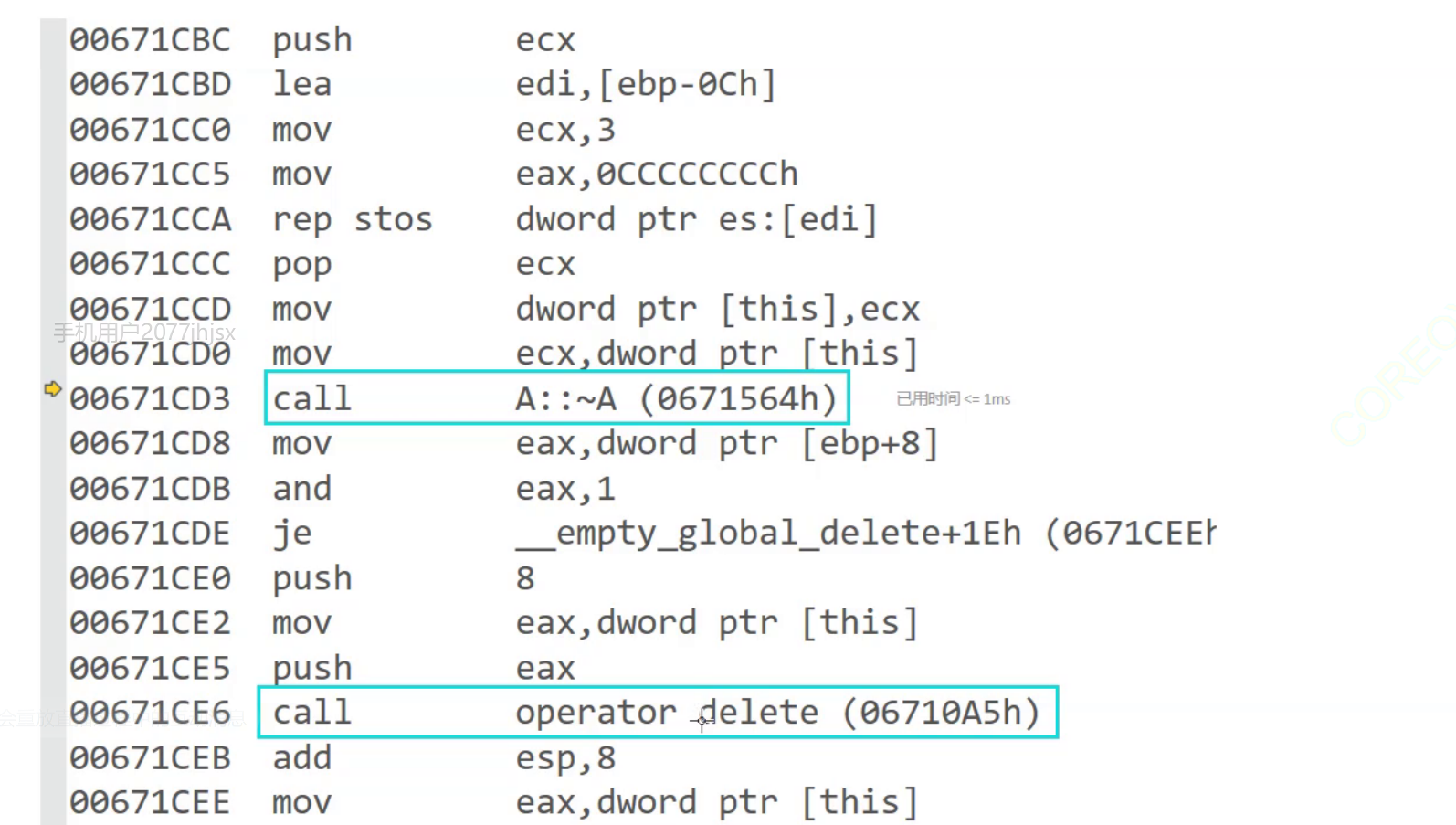
-
delete的原理
- 在空间上执行析构函数,完成对象中资源的清理工作
- 调用operator delete函数释放对象的空间
-
new T[N]的原理
- 调用operator new[]函数,在operator new[]中实际调用operator new函数完成N个对象空间的申请
- 在申请的空间上执行N次构造函数
-
delete[]的原理
- 在释放的对象空间上执行N次析构函数,完成N个对象中资源的清理
- 调用**operator delete[]**释放空间,实际在operator delete[]中调用operator delete来释放空间
看看这段代码:
int main()
{A* p1 = new A(1);delete p1;A* p2 = new A[5];delete[] p2;return 0;
}
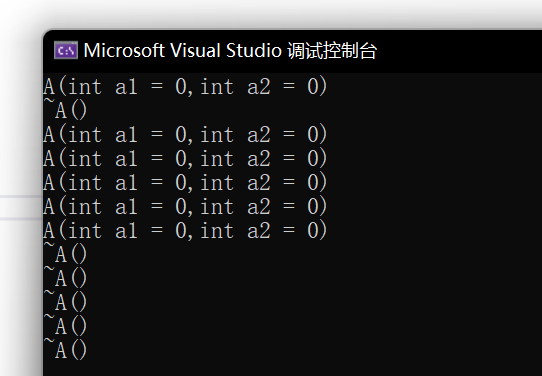
可以看到,对于A* p2 = new A[5];我们调用了5次构造和5次析构。
错配
int main()
{int* p1 = new int;free(p1);return 0;
}
像这样,我们去错配,会发生什么呢?
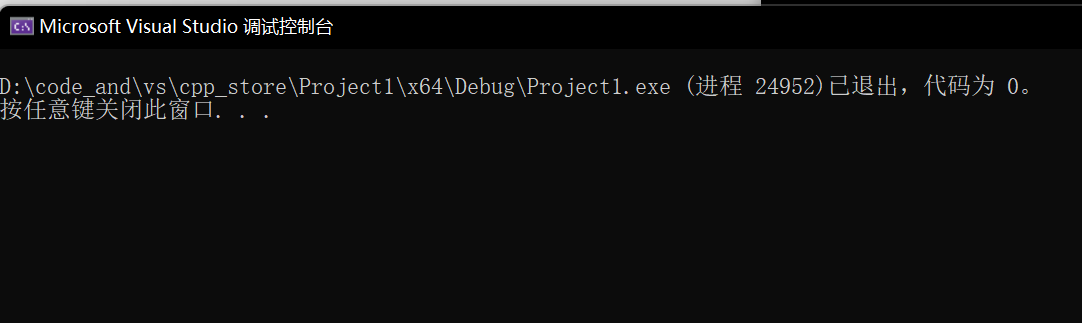
并没有崩溃。(内存泄漏是不会报错的)
这里有内存泄漏吗?没有。这里是内置类型。
但是不要这样去乱写。
那现在如果是自定义类型呢?
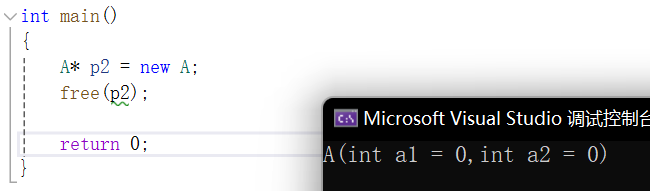
也没有崩溃。但是比起delete,其实少调用了一个A的析构函数:
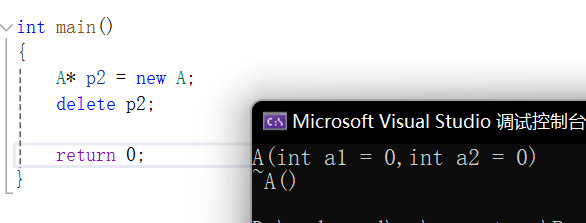
如果A的析构函数没做什么事还好,如果在里面释放一些资源,那么就会因为没有调用到析构函数而内存泄漏。
再看:
这里没有正确使用delete[],漏写[]
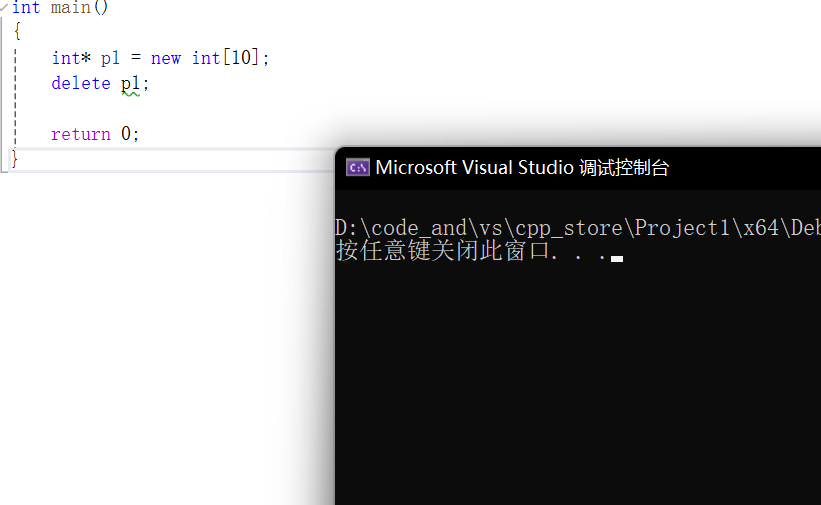
没有崩溃,其实也不会有内存泄漏。
这里内置类型没有构造函数析构函数,new去调用operator new,operator new调用malloc,最本质的还是malloc来一块空间。
delete去调用operator delete,然后调用free,本质也是free。
所以空间不涉及构造和析构时,还是malloc和free。空间的申请和释放最终还是malloc和free解决的。
自定义类型:
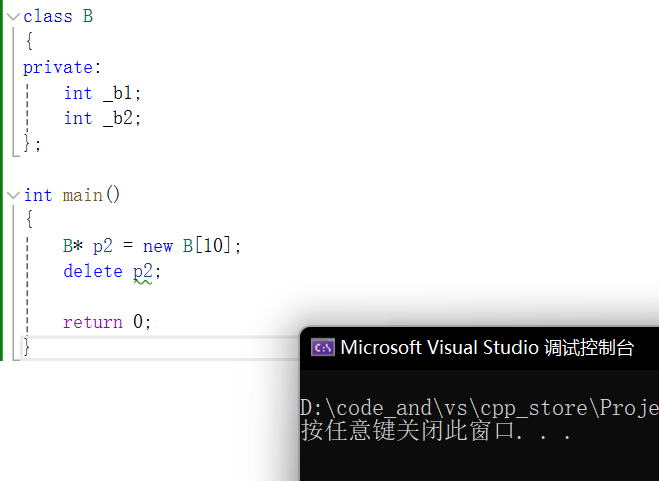
可以看到也没有问题。
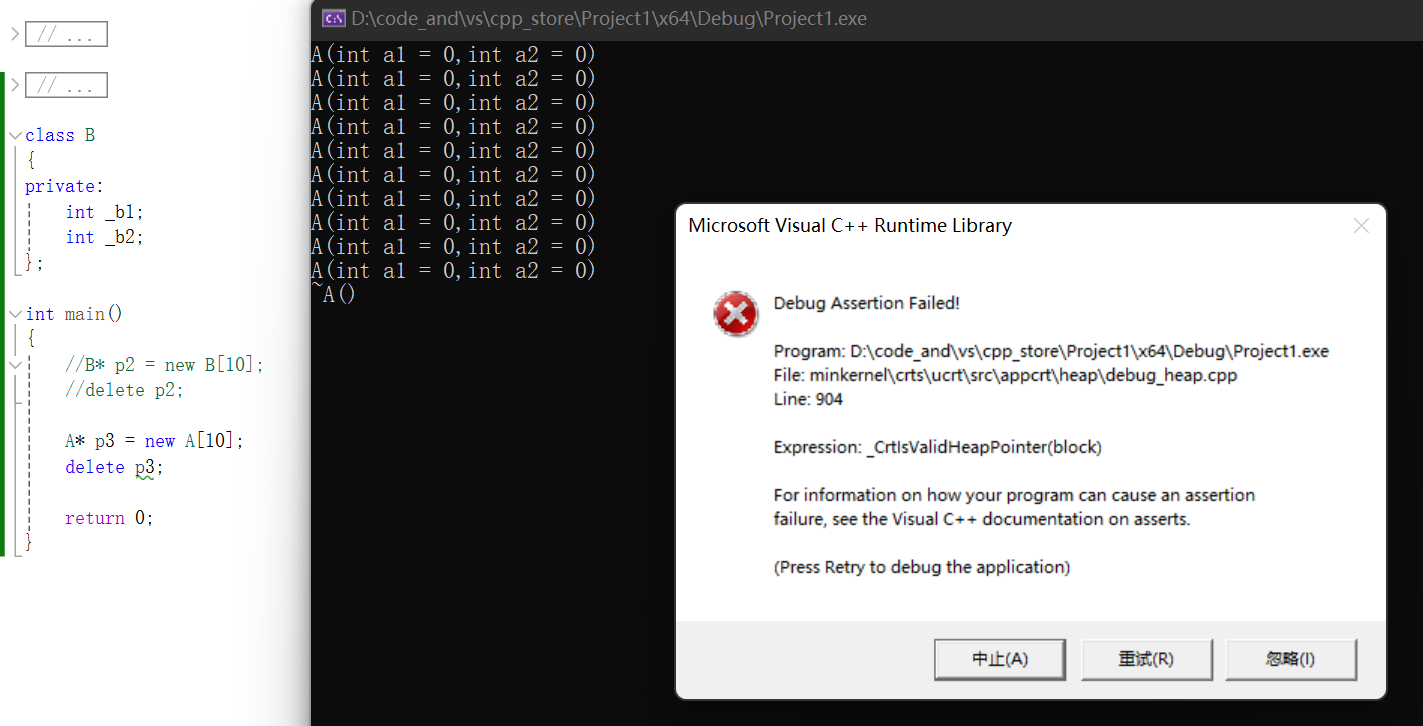
但是这样,却崩溃了。
A和B根据内存对齐,都是8字节。
10个A对象是84字节,10个B对象却是80。
编译器遇到A这种类型,会在头上多开4个字节,用来存储对象个数。

这个程序在不同编译器下可能情况不同。
new A的时候我们返回的不是malloc起始的位置:

所以我们delete的时候要往前偏移4字节才对。释放空间不能在中间释放。
那么为什么A要多开4字节呢?严格来说都应该开4字节存个数。B没有开是因为编译器进行了优化。因为编译器看到B没有写析构函数,不需要知道要析构几次。编译器看到B没有析构函数也不需要析构,自动生成的也没做什么事情,所以编译器干脆不调用析构函数了。
总之,一定要匹配使用,不要错配。

定位new表达式(placement-new)
定位new表达式是在已分配的原始内存空间中调用构造函数初始化一个对象。
int main()
{A* p1 = new A(1);//开空间并初始化A* p2 = (A*)operator new(sizeof(A));//只开了空间,没有初始化return 0;
}
如果现在想要对这块已经开好的空间去显示调用构造函数呢?定位new可以帮我们做到这一点。
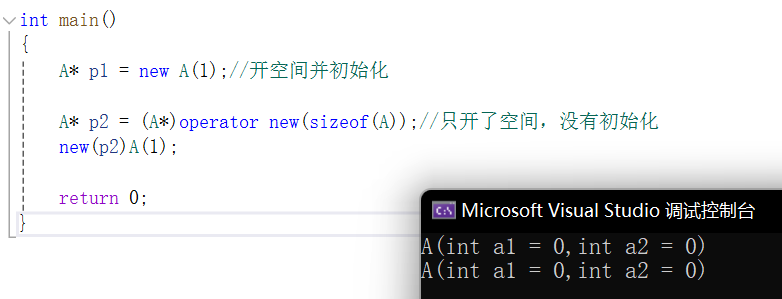
可以看到,这样就也调用构造了。
那现在如果想要调用析构呢?
int main()
{A* p1 = new A(1);//开空间并初始化A* p2 = (A*)operator new(sizeof(A));//只开了空间,没有初始化new(p2)A(1);//p2->A(1);构造函数不能这样显式写,想要显示调用构造要写成上面定位new形式delete p1;p2->~A();//析构函数可以这样显式写return 0;
}
int main()
{A* p1 = new A(1);//开空间并初始化delete p1;A* p2 = (A*)operator new(sizeof(A));//只开了空间,没有初始化new(p2)A(1);//定位new,显式构造p2->~A();//析构函数可以这样显式写operator delete(p2);return 0;
}
其实上面p1和p2的效果是一样的,失败了都是抛异常。
但是两行就写好了更方便,后面这种写法很冗余。
但是在很少数的情况下会需要后面这种写法:
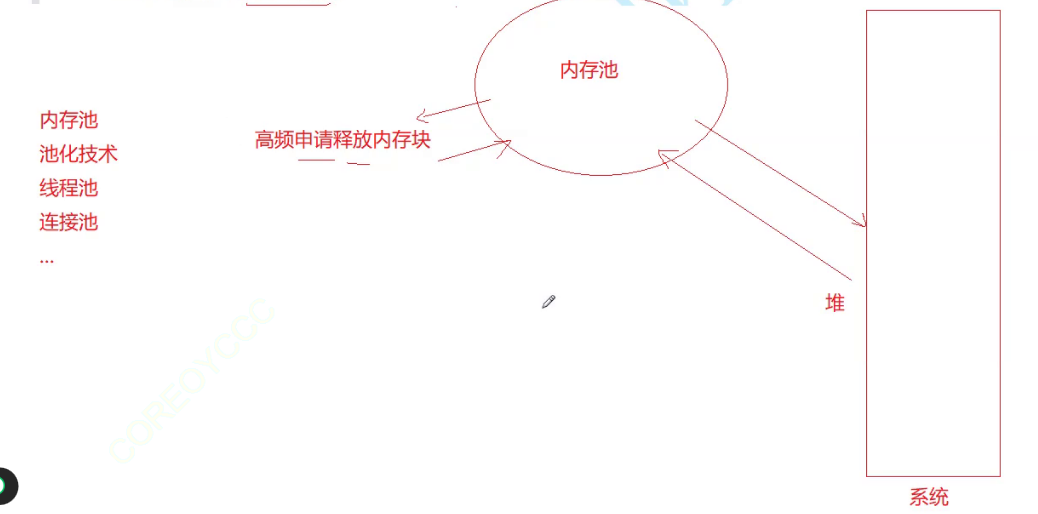
这涉及到池化技术:内存池,线程池,连接池……。
当我们需要高频地申请释放内存块时,从堆里面搞出一块专供的内存池,效率就会比较高。(具体细节现在无法多说)
int main()
{Type* p2 = new Type;Type* p1 = pool.Alloc(sizeof(Type));new(p1)Type;return 0;
}
但是当我们向内存池申请空间时只有空间,没有初始化,但是又想达到和new一样的功能,所以就得去调用。
所以是这样的场景有需求。以后再说。
现在我们的系统都是多核的,CPU是多少核其实就是有多少个CPU,就能支持并发执行。每次执行的时候再去创建线程,消耗很大,所以就会提前创建比如10个线程,有任务来了就直接执行,执行完了让线程再回来。连接池也一样,去连接数据库的时候不用现场去连接,减少消耗。
本文到此结束=_=