https://huggingface.co/docs/trl/main/en/grpo_trainer#example-3-reward-completions-based-on-a-reference
文章目录
- TRL文档-GRPO训练器
- 1 概述
- 2 快速开始
- 3 深入了解GRPO方法
- 生成完成内容
- 计算优势
- 估计KL散度
- 计算损失
- 损失类型
- 4 记录的指标
- 5 自定义
- 使用vLLM加速训练
- 大规模的GRPO:在多个节点上训练70B以上的模型
- 使用自定义奖励函数
- 示例1:奖励更长的完成内容
- 示例2:奖励具有特定格式的完成内容
- 示例3:基于参考内容奖励完成内容
- 示例4:多任务奖励函数
- 将奖励函数传递给训练器
- 6 GRPOTrainer
- 7 GRPOConfig
TRL文档-GRPO训练器
1 概述
TRL支持使用GRPO训练器来训练语言模型,这在 Qihao Zhu, Runxin Xu, Junxiao Song, Mingchuan Zhang, Y. K. Li, Y. Wu, Daya Guo.撰写的论文《DeepSeekMath:在开放语言模型中突破数学推理的极限》中有相关描述。
该论文的摘要如下:
“数学推理因其复杂和结构化的特性,对语言模型构成了重大挑战。在本文中,我们介绍了DeepSeekMath 7B,它在DeepSeek-Coder-Base-v1.5 7B的基础上,使用从Common Crawl获取的1200亿与数学相关的标记,以及自然语言和代码数据继续进行预训练。DeepSeekMath 7B在竞赛级别的MATH基准测试中,在不依赖外部工具包和投票技术的情况下,取得了令人瞩目的51.7%的成绩,接近Gemini-Ultra和GPT-4的性能水平。DeepSeekMath 7B从64个样本中进行自一致性计算,在MATH基准测试中达到了60.9%的成绩。DeepSeekMath的数学推理能力归因于两个关键因素:第一,我们通过精心设计的数据选择流程,利用了公开可用网络数据的巨大潜力。第二,我们引入了组相对策略优化(GRPO),这是近端策略优化(PPO)的一种变体,它在优化PPO内存使用的同时,增强了数学推理能力。”
这种后训练方法由昆汀·加洛埃代克(Quentin Gallouédec)贡献。
2 快速开始
本示例展示了如何使用GRPO方法训练模型。我们使用来自TLDR数据集的提示(忽略完成列!)来训练一个Qwen 0.5B指令模型。你可以在此处查看数据集中的数据:
https://huggingface.co/docs/trl/main/en/grpo_trainer#example-3-reward-completions-based-on-a-reference
以下是训练模型的脚本:
# train_grpo.py
from datasets import load_dataset
from trl import GRPOConfig, GRPOTrainerdataset = load_dataset("trl-lib/tldr", split="train")# 定义奖励函数,该函数奖励长度接近20个字符的完成内容
def reward_len(completions, **kwargs):return [-abs(20 - len(completion)) for completion in completions]training_args = GRPOConfig(output_dir="Qwen2-0.5B-GRPO", logging_steps=10)
trainer = GRPOTrainer(model="Qwen/Qwen2-0.5B-Instruct",reward_funcs=reward_len,args=training_args,train_dataset=dataset,
)
trainer.train()
使用以下命令执行脚本:
accelerate launch train_grpo.py
在8个GPU上分布式训练大约需要1天时间。
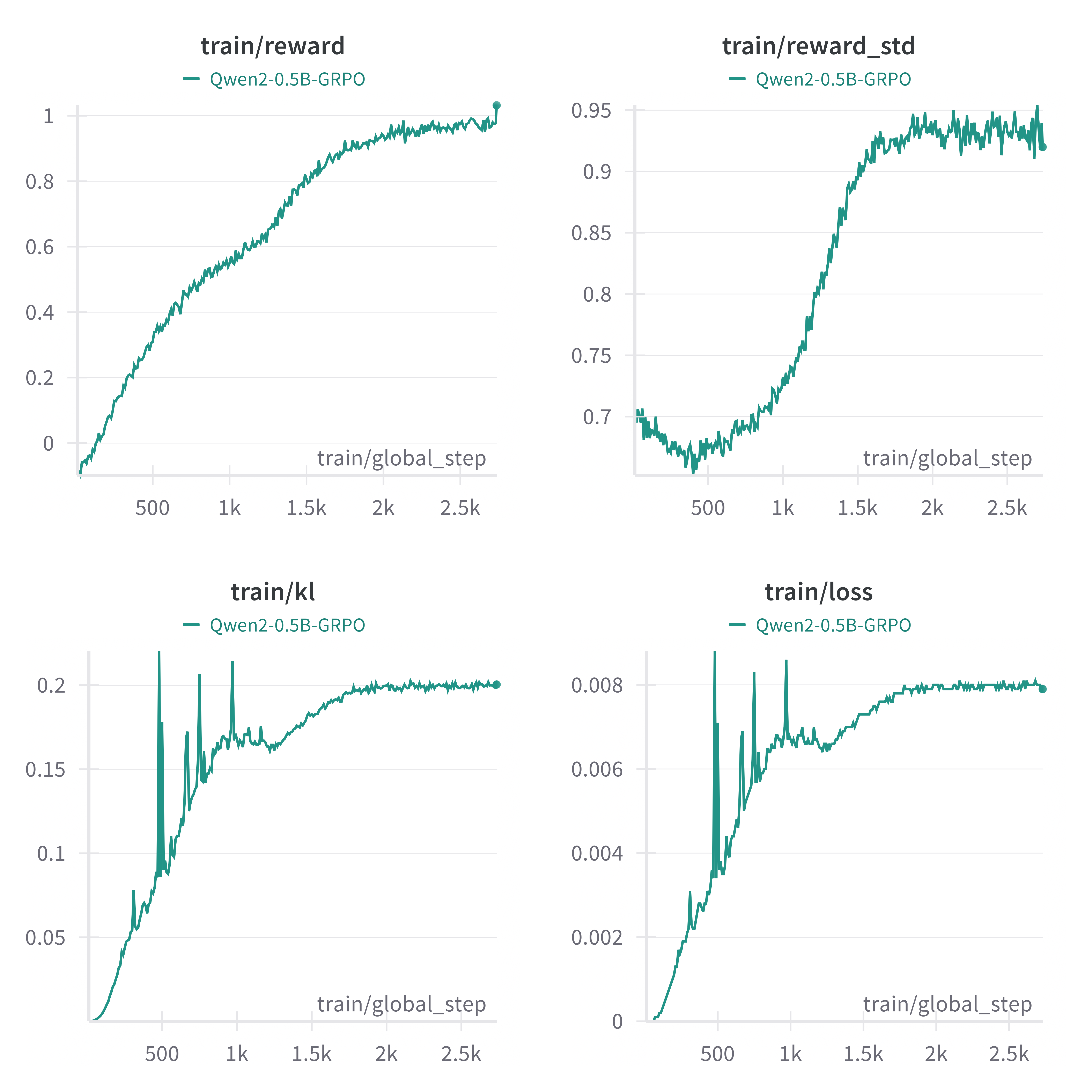
3 深入了解GRPO方法
GRPO是一种在线学习算法,这意味着它在训练过程中通过使用训练模型自身生成的数据进行迭代改进。GRPO目标背后的核心思想是最大化生成完成内容的优势,同时确保模型与参考策略保持接近。为了理解GRPO的工作原理,可以将其分解为四个主要步骤:生成完成内容、计算优势、估计KL散度和计算损失。
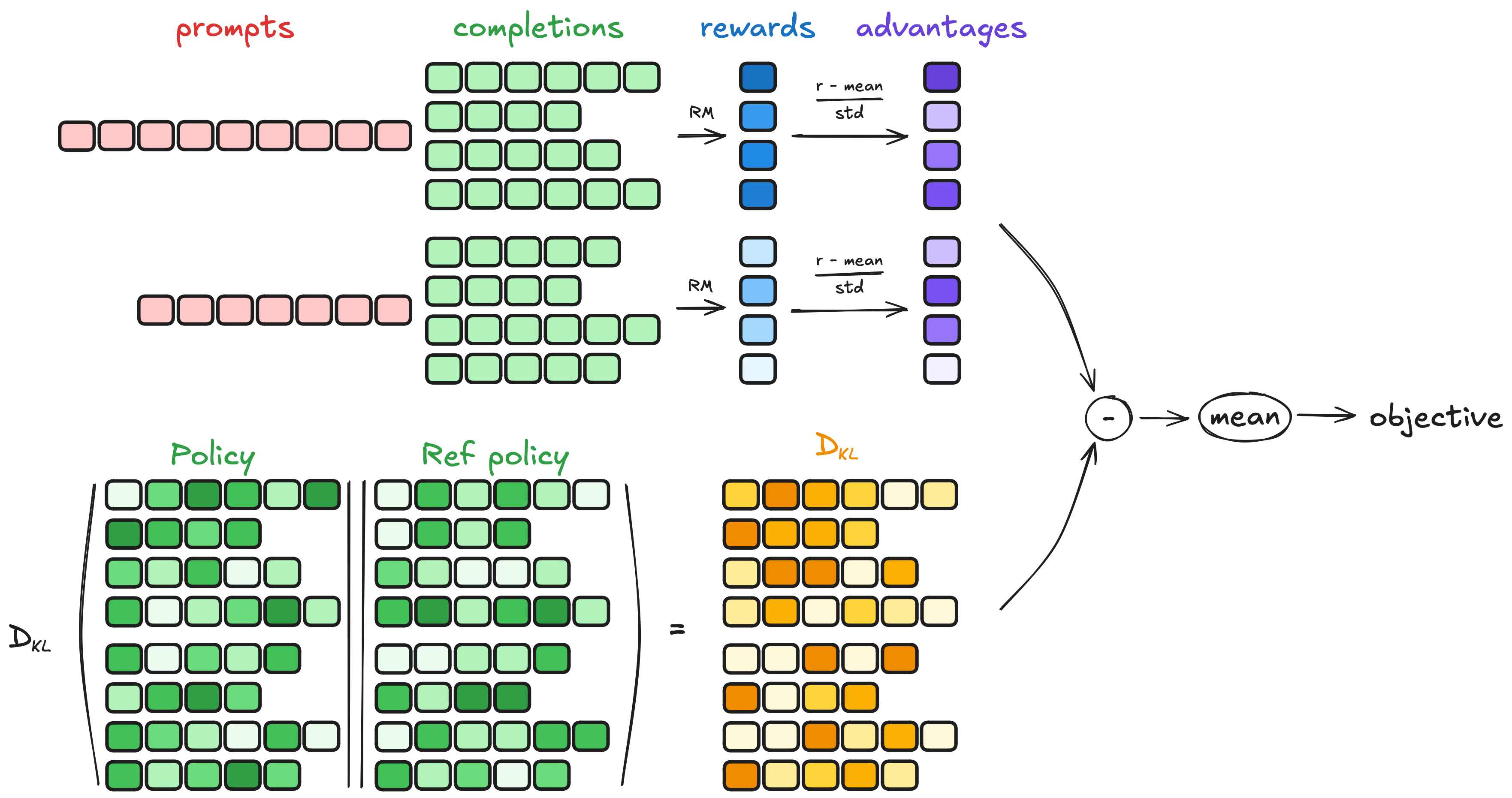
生成完成内容
在每个训练步骤中,我们对一批提示进行采样,并为每个提示生成一组G个完成内容(表示为 O O O)。
计算优势
模型通常在同一问题的输出比较数据集上进行训练,计算优势以反映这些相对比较。其归一化公式如下:对于 G G G个序列中的每一个,我们使用奖励模型计算奖励。为了与奖励的比较性质保持一致,公式为:
A ^ i , t = r i − m e a n ( r ) s t d ( r ) \hat{A}_{i, t}=\frac{r_{i}-mean(r)}{std(r)} A^i,t=std(r)ri−mean(r)
这种方法也正是“组相对策略优化(GRPO)”名称的由来。
在论文《理解类似R1-Zero的训练:批判性视角》中指出,通过 s t d ( r ) std(r) std(r)进行缩放可能会导致问题级别的难度偏差。你可以在GRPOConfig中设置scale_rewards=False来禁用此缩放。
估计KL散度
KL散度使用舒尔曼等人(2020年)提出的近似器进行估计。该近似器定义如下:
D K L [ π θ ∥ π r e f ] = π r e f ( o i , t ∣ q , o i , < t ) π θ ( o i , t ∣ q , o i , < t ) − l o g π r e f ( o i , t ∣ q , o i , < t ) π θ ( o i , t ∣ q , o i , < t ) − 1 \mathbb{D}_{KL}\left[\pi_{\theta} \| \pi_{ref}\right]=\frac{\pi_{ref}\left(o_{i, t} | q, o_{i,<t}\right)}{\pi_{\theta}\left(o_{i, t} | q, o_{i,<t}\right)}-log \frac{\pi_{ref}\left(o_{i, t} | q, o_{i,<t}\right)}{\pi_{\theta}\left(o_{i, t} | q, o_{i,<t}\right)}-1 DKL[πθ∥πref]=πθ(oi,t∣q,oi,<t)πref(oi,t∣q,oi,<t)−logπθ(oi,t∣q,oi,<t)πref(oi,t∣q,oi,<t)−1
计算损失
目标是在确保模型与参考策略保持接近的同时最大化优势。因此,损失定义如下:其中第一项表示缩放后的优势,第二项通过KL散度对偏离参考策略的情况进行惩罚。
L G R P O ( θ ) = − 1 ∑ i = 1 G ∣ o i ∣ ∑ i = 1 G ∑ t = 1 ∣ o i ∣ [ π θ ( o i , t ∣ q , o i , < t ) [ π θ ( o i , t ∣ q , o i , < t ) ] n o g r a d A ^ i , t − β D K L [ π θ ∥ π r e f ] ] \mathcal{L}_{GRPO}(\theta)=-\frac{1}{\sum_{i=1}^{G}\left|o_{i}\right|} \sum_{i=1}^{G} \sum_{t=1}^{\left|o_{i}\right|}\left[\frac{\pi_{\theta}\left(o_{i, t} | q, o_{i,<t}\right)}{\left[\pi_{\theta}\left(o_{i, t} | q, o_{i,<t}\right)\right]_{no grad}} \hat{A}_{i, t}-\beta \mathbb{D}_{KL}\left[\pi_{\theta} \| \pi_{ref}\right]\right] LGRPO(θ)=−∑i=1G∣oi∣1i=1∑Gt=1∑∣oi∣[[πθ(oi,t∣q,oi,<t)]nogradπθ(oi,t∣q,oi,<t)A^i,t−βDKL[πθ∥πref]]
注意,与论文《DeepSeekMath:在开放语言模型中突破数学推理的极限》中的原始公式相比,我们没有通过 ∣ a 1 ∣ |a_{1}| ∣a1∣进行缩放,因为在论文《理解类似R1-Zero的训练:批判性视角》中表明,这会引入响应级别的长度偏差。更多关于损失类型的详细信息,请参考相关内容。
在原始论文中,此公式进行了推广,以考虑每次生成后进行多次更新(表示为num_iterations,可在GRPOConfig中设置),通过使用裁剪后的代理目标:
L GRPO ( θ ) = − 1 ∑ i = 1 G ∣ o i ∣ ∑ i = 1 G ∑ t = 1 ∣ o i ∣ [ π θ ( o i , t ∣ q , o i , < t ) [ π θ ( o i , t ∣ q , o i , < t ) ] no grad A ^ i , t − β D KL [ π θ ∥ π ref ] ] \mathcal{L}_{\text{GRPO}}(\theta)=-\frac{1}{\sum_{i = 1}^{G}|o_i|}\sum_{i = 1}^{G}\sum_{t = 1}^{|o_i|}\left[\frac{\pi_{\theta}(o_{i,t}\mid q, o_{i,<t})}{[\pi_{\theta}(o_{i,t}\mid q, o_{i,<t})]_{\text{no grad}}}\hat{A}_{i,t}-\beta\mathbb{D}_{\text{KL}}[\pi_{\theta}\|\pi_{\text{ref}}]\right] LGRPO(θ)=−∑i=1G∣oi∣1i=1∑Gt=1∑∣oi∣[[πθ(oi,t∣q,oi,<t)]no gradπθ(oi,t∣q,oi,<t)A^i,t−βDKL[πθ∥πref]]
其中 c l i p ( ⋅ , 1 − ϵ , 1 + ϵ ) clip(\cdot, 1-\epsilon, 1+\epsilon) clip(⋅,1−ϵ,1+ϵ)通过将策略比率限制在 1 − ϵ 1-\epsilon 1−ϵ和 1 + ϵ 1+\epsilon 1+ϵ之间,确保更新不会过度偏离参考策略。当 μ = 1 \mu = 1 μ=1(TRL中的默认值)时,裁剪后的代理目标简化为原始目标。
损失类型
文献中提出了几种目标函数的公式。最初,GRPO的目标定义如下:
L G R P O ( θ ) = − 1 G ∑ i = 1 G 1 ∣ o i ∣ ∑ t = 1 ∣ o i ∣ l i , t \mathcal{L}_{GRPO}(\theta)=-\frac{1}{G} \sum_{i=1}^{G} \frac{1}{\left|o_{i}\right|} \sum_{t=1}^{\left|o_{i}\right|} l_{i, t} LGRPO(θ)=−G1i=1∑G∣oi∣1t=1∑∣oi∣li,t
l i , t = π θ ( o i , t ∣ q , o i , < t ) [ π θ ( o i , t ∣ q , o i , < t ) ] n o g r a d A ^ i , t − β D K L [ π θ ∥ π r e f ] l_{i, t}=\frac{\pi_{\theta}\left(o_{i, t} | q, o_{i,<t}\right)}{\left[\pi_{\theta}\left(o_{i, t} | q, o_{i,<t}\right)\right]_{no grad}} \hat{A}_{i, t}-\beta \mathbb{D}_{KL}\left[\pi_{\theta} \| \pi_{ref}\right] li,t=[πθ(oi,t∣q,oi,<t)]nogradπθ(oi,t∣q,oi,<t)A^i,t−βDKL[πθ∥πref]
DAPO论文强调了GRPO算法在长思维链(long-CoT)场景中样本级损失的局限性,在这种场景中,较长的响应受到的惩罚不足,导致输出质量较差。提出的解决方案是进行标记级归一化,通过为单个标记分配更平衡的奖励,更好地处理较长的序列,而不受响应长度的影响:
L D A P O ( θ ) = − 1 ∑ i = 1 G ∣ o i ∣ ∑ i = 1 G ∑ t = 1 ∣ o i ∣ l i , t \mathcal{L}_{DAPO }(\theta)=-\frac{1}{\sum_{i=1}^{G}\left|o_{i}\right|} \sum_{i=1}^{G} \sum_{t=1}^{\left|o_{i}\right|} l_{i, t} LDAPO(θ)=−∑i=1G∣oi∣1i=1∑Gt=1∑∣oi∣li,t
此外,在论文《理解类似R1-Zero的训练:批判性视角》中表明,最初的GRPO公式会引入响应长度偏差。他们指出,虽然DAPO公式减少了这种偏差,但并没有完全消除它。为了完全消除这种偏差,他们建议除以一个常数,而不是序列长度,从而得到以下公式:
L D r . G R P O ( θ ) = − 1 L G ∑ i = 1 G ∑ t = 1 ∣ o i ∣ l i , t \mathcal{L}_{Dr. GRPO }(\theta)=-\frac{1}{L G} \sum_{i=1}^{G} \sum_{t=1}^{\left|o_{i}\right|} l_{i, t} LDr.GRPO(θ)=−LG1i=1∑Gt=1∑∣oi∣li,t
建议将此常数设置为最大完成长度。要使用此公式,请在GRPOConfig中设置loss_type=“dr_grpo”。
4 记录的指标
- num_tokens:到目前为止处理的总标记数,包括提示和完成内容。
- completions/mean_length:生成的完成内容的平均长度。
- completions/min_length:生成的完成内容的最小长度。
- completions/max_length:生成的完成内容的最大长度。
- completions/mean_terminated_length:以EOS结束的生成完成内容的平均长度。
- completions/min_terminated_length:以EOS结束的生成完成内容的最小长度。
- completions/max_terminated_length:以EOS结束的生成完成内容的最大长度。
- completions/clipped_ratio:被截断(裁剪)的完成内容的比例。
- reward/{reward_func_name}/mean:特定奖励函数的平均奖励。
- reward/{reward_func_name}/std:特定奖励函数的奖励标准差。
- reward:应用奖励权重后的总体平均奖励。
- reward_std:应用奖励权重后每个批次内总体奖励的标准差。
- kl:模型与参考模型之间的平均KL散度,基于生成的完成内容计算。仅当beta不为零时记录。
- clip_ratio:PPO目标在信任区域内被裁剪的标记比例:
c l i p ( π θ ( o i , t ∣ q , o i , < t ) π θ o l d ( o i , t ∣ q , o i , < t ) , 1 − ϵ , 1 + ϵ ) clip\left(\begin{array}{c}\pi_{\theta}\left(o_{i, t} | q, o_{i,<t}\right) \\ \pi_{\theta_{old }}\left(o_{i, t} | q, o_{i,<t}\right)\end{array}, 1-\epsilon, 1+\epsilon\right) clip(πθ(oi,t∣q,oi,<t)πθold(oi,t∣q,oi,<t),1−ϵ,1+ϵ)
较高的值意味着更多的标记受到裁剪的影响,限制了策略的变化程度。
5 自定义
使用vLLM加速训练
生成过程通常是在线训练方法中导致训练缓慢的主要瓶颈。为了加速生成过程,你可以使用vLLM,这是一个能够实现快速生成的库。要启用它,首先使用以下命令安装该软件包:
pip install trl[vllm]
然后,使用所需的模型启动vLLM服务器:
trl vllm-serve --model <model_name>
接着,在训练参数中传入use_vllm=True并运行训练脚本:
from trl import GRPOConfig
training_args = GRPOConfig(..., use_vllm=True)
更多信息,请参阅《使用vLLM加速训练》。
大规模的GRPO:在多个节点上训练70B以上的模型
在训练像Qwen2.5 - 72B这样的大型模型时,需要进行一些关键优化,以使训练在多个GPU和节点上高效且可扩展。这些优化包括:
- DeepSpeed ZeRO Stage 3:ZeRO利用数据并行性将模型状态(权重、梯度、优化器状态)分布到多个GPU和CPU上,减少每个设备上的内存和计算需求。由于大型模型无法在单个GPU上容纳,因此训练此类模型需要使用ZeRO Stage 3。更多详细信息,请参阅《DeepSpeed集成》。
- Accelerate:Accelerate是一个简化跨多个GPU和节点进行分布式训练的库。它提供了一个简单的API来启动分布式训练,并处理分布式训练的复杂性,如数据并行性、梯度累积和分布式数据加载。更多详细信息,请参阅《分布式训练》。
- vLLM:有关如何使用vLLM加速生成的方法,请参阅上一节内容。
以下是一个使用GRPO在多个节点上训练70B模型的SLURM脚本示例。此脚本在4个节点上训练模型,并使用第5个节点进行基于vLLM的生成。
#!/bin/bash
#SBATCH --nodes=5
#SBATCH --gres=gpu:8# 获取分配的节点列表
NODELIST=($(scontrol show hostnames $SLURM_JOB_NODELIST))
# 分配前4个节点用于训练,第5个节点用于vLLM
TRAIN_NODES="${NODELIST[@]:0:4}" # 节点0、1、2、3用于训练
VLLM_NODE="${NODELIST[4]}" # 节点4用于vLLM# 在第1个到第4个节点(组1)上运行训练
srun --nodes=4 --ntasks=4 --nodelist="${NODELIST[@]:0:4}" accelerate launch \
--config_file examples/accelerate_configs/deepspeed_zero3.yaml \
--num_processes 32 \
--num_machines 4 \
--main_process_ip ${NODELIST[0]} \
--machine_rank $SLURM_PROCID \
--rdzv_backend c10d \
train_grpo.py \
--server_ip $VLLM_NODE &# 在第5个节点(组2)上运行vLLM服务器
srun --nodes=1 --ntasks=1 --nodelist="${NODELIST[4]}" trl vllm-serve --model Qwen/Qwen2.5-72B --tensor_parallel_siz
wait
import argparse
from datasets import load_dataset
from trl import GRPOTrainer, GRPOConfigdef main():parser = argparse.ArgumentParser()parser.add_argument("--vllm_server_host", type=str, default="", help="The server IP")args = parser.parse_args()# 来自TLDR的示例数据集dataset = load_dataset("trl-lib/tldr", split="train")# 虚拟奖励函数:计算完成内容中唯一字符的数量def reward_num_unique_chars(completions, **kwargs):return [len(set(c)) for c in completions]training_args = GRPOConfig(output_dir="Qwen2.5-72B-GRPO",per_device_train_batch_size=4,bf16=True,gradient_checkpointing=True,logging_steps=10,use_vllm=True,vllm_server_host=args.vllm_server_host.replace("ip-", "").replace("-", "."), # 从ip-X-X-X-X转换为X.X.X.X)trainer = GRPOTrainer(model="Qwen/Qwen2.5-72B", args=training_args, reward_funcs=reward_num_unique_chars, train_dataset=dataset)trainer.train()if __name__=="__main__":main()
使用自定义奖励函数
GRPOTrainer支持使用自定义奖励函数,而不是密集奖励模型。为确保兼容性,你的奖励函数必须满足以下要求:
1 输入参数
函数必须接受以下作为关键字参数:
- prompts(包含提示)
- completions(包含生成的完成内容)
- 数据集中除prompt外的所有列名。例如,如果数据集包含名为ground_truth的列,则函数将以ground_truth作为关键字参数被调用。
满足此要求的最简单方法是在函数签名中使用**kwargs。
根据数据集格式的不同,输入会有所变化:
- 对于标准格式,prompts和completions将是字符串列表。
- 对于对话格式,prompts和completions将是消息字典列表。
2 返回值
函数必须返回一个浮点数列表。每个浮点数代表对应单个完成内容的奖励。
示例1:奖励更长的完成内容
以下是一个针对标准格式的奖励函数示例,该函数奖励更长的完成内容:
def reward_func(completions, **kwargs):"""奖励函数,对更长的完成内容给予更高的分数。"""return [float(len(completion)) for completion in completions]
你可以如下测试它:
>>> prompts = ["The sky is", "The sun is"]
>>> completions = [" blue.", " in the sky."]
>>> print(reward_func(prompts=prompts, completions=completions))
[6.0, 12.0]
示例2:奖励具有特定格式的完成内容
以下是一个检查完成内容是否具有特定格式的奖励函数示例。此示例受论文《DeepSeek-R1:通过强化学习激励大语言模型的推理能力》中使用的格式奖励函数启发。它专为对话格式设计,其中prompts和completions由结构化消息组成。
import redef format_reward_func(completions, **kwargs):"""奖励函数,检查完成内容是否具有特定格式。"""pattern = r"^<think>.*?</think><answer>.*?</answer>$"completion_contents = [completion[0]["content"] for completion in completions]matches = [re.match(pattern, content) for content in completion_contents]return [1.0 if match else 0.0 for match in matches]
你可以如下测试这个函数:
>>> prompts = [
[{"role": "assistant", "content": "What is the result of (1 + 2) * 4?"}],
[{"role": "assistant", "content": "What is the result of (3 + 1) * 2?"}],
... ]
>>> completions = [
[{"role": "assistant", "content": "<think>The sum of 1 and 2 is 3, which we multiply by 4 to get 12.</think><answer>12</answer>"},
{"role": "assistant", "content": "The sum of 3 and 1 is 4, which we multiply by 2 to get 8. So (3 + 1) * 2"}
... ]
>>> format_reward_func(prompts=prompts, completions=completions)
[1.0, 0.0]
示例3:基于参考内容奖励完成内容
以下是一个检查完成内容是否正确的奖励函数示例。此示例受论文《DeepSeek-R1:通过强化学习激励大语言模型的推理能力》中使用的准确率奖励函数启发。这个示例专为标准格式设计,其中数据集包含名为ground_truth的列。
import redef reward_func(completions, ground_truth, **kwargs):# 用于捕获\boxed{}内内容的正则表达式matches = [re.search(r"\\boxed\{(.*?)\}", completion) for completion in completions]contents = [match.group(1) if match else "" for match in matches]# 如果内容与ground_truth相同则奖励1,否则奖励0return [1.0 if c == gt else 0.0 for c, gt in zip(contents, ground_truth)]
你可以如下测试这个函数:
>>> prompts = ["Problem: Solve the equation $2x + 3 = 7$. Solution:", "Problem: Solve the equation $3x - 5 = 10$."]
>>> completions = [r" The solution is \boxed{2}.", r" The solution is \boxed{6}."]
>>> ground_truth = ["2", "5"]
>>> reward_func(prompts=prompts, completions=completions, ground_truth=ground_truth)
[1.0, 0.0]
示例4:多任务奖励函数
以下是在GRPOTrainer中使用多个奖励函数的示例。在这个示例中,我们定义了两个特定任务的奖励函数:math_reward_func和coding_reward_func。math_reward_func根据数学问题的正确性给予奖励,而coding_reward_func根据代码问题的解决方案是否有效给予奖励。
from datasets import Dataset
from trl import GRPOTrainer# 定义一个同时包含数学和代码问题的数据集
dataset = Dataset.from_list([
{"prompt": "What is 2+2?", "task": "math"},
{"prompt": "Write a function that returns the sum of two numbers.", "task": "code"},
{"prompt": "What is 3*4?", "task": "math"},
{"prompt": "Write a function that returns the product of two numbers.", "task": "code"},
])# 数学特定的奖励函数
def math_reward_func(prompts, completions, task, **kwargs):rewards = []for prompt, completion, t in zip(prompts, completions, task):if t == "math":# 计算数学特定的奖励correct = check_math_solution(prompt, completion)reward = 1.0 if correct else -1.0rewards.append(reward)else:# 对于非数学任务返回Nonerewards.append(None)return rewards# 代码特定的奖励函数
def coding_reward_func(prompts, completions, task, **kwargs):rewards = []for prompt, completion, t in zip(prompts, completions, task):if t == "coding":# 计算代码特定的奖励works = test_code_solution(prompt, completion)reward = 1.0 if works else -1.0rewards.append(reward)else:# 对于非代码任务返回Nonerewards.append(None)return rewards# 使用两个特定任务的奖励函数
trainer = GRPOTrainer(model="Qwen/Qwen2-0.5B-Instruct",reward_funcs=[math_reward_func, coding_reward_func],train_dataset=dataset,
)
trainer.train()
在这个示例中,math_reward_func和coding_reward_func旨在处理同时包含数学和代码问题的混合数据集。数据集中的task列用于确定对每个问题应用哪个奖励函数。如果数据集中的某个样本没有相关的奖励函数,奖励函数将返回None,并且GRPOTrainer将继续使用有效的函数和任务。这使得GRPOTrainer能够处理具有不同适用性的多个奖励函数。
请注意,GRPOTrainer将忽略奖励函数返回的None奖励,仅考虑相关函数返回的奖励。这确保了模型在相关任务上进行训练,并忽略没有相关奖励函数的任务。
将奖励函数传递给训练器
要使用自定义奖励函数,请按如下方式将其传递给GRPOTrainer:
from trl import GRPOTrainertrainer = GRPOTrainer(reward_funcs=reward_func,...
)
如果你有多个奖励函数,可以将它们作为列表传递:
from trl import GRPOTrainertrainer = GRPOTrainer(reward_funcs=[reward_func1, reward_func2],...
)
奖励将计算为每个函数的奖励之和,如果在配置中提供了reward_weights,则计算为加权和。
请注意,GRPOTrainer支持不同类型的多个奖励函数。更多详细信息,请参阅参数文档。
6 GRPOTrainer
class trl.GRPOTrainer(model,reward_funcs: typing.Union[str, transformers.modeling_utils.PreTrainedModel, typing.Callable[[list, list], list[float]], list[typing.Union[str, transformers.modeling_utils.PreTrainedModel, typing.Callable[[list, list], list[float]]]]],args: typing.Optional[trl.trainer.grpo_config.GRPOConfig] = None,train_dataset: typing.Union[datasets.arrow_dataset.Dataset, datasets.iterable_dataset.IterableDataset, NoneType] = None,eval_dataset: typing.Union[datasets.arrow_dataset.Dataset, datasets.iterable_dataset.IterableDataset, dict[str, typing.Union[datasets.arrow_dataset.Dataset, datasets.iterable_dataset.IterableDataset]], NoneType] = None,processing_class: typing.Optional[transformers.tokenization_utils_base.PreTrainedTokenizerBase] = None,reward_processing_classes: typing.Union[transformers.tokenization_utils_base.PreTrainedTokenizerBase, list[transformers.tokenization_utils_base.PreTrainedTokenizerBase], NoneType] = None,callbacks: typing.Optional[list[transformers.trainer_callback.TrainerCallback]] = None,optimizers: tuple = (None, None),peft_config: typing.Optional[ForwardRef('PeftConfig')] = None
)
Group Relative Policy Optimization(GRPO)方法的训练器。该算法最初在论文《DeepSeekMath:在开放语言模型中突破数学推理的极限》中提出。
示例:
from datasets import load_dataset
from trl import GRPOTrainerdataset = load_dataset("trl-lib/tldr", split="train")def reward_func(completions, **kwargs):# 虚拟奖励函数,奖励包含更多唯一字母的完成内容return [float(len(set(completion))) for completion in completions]trainer = GRPOTrainer(model="Qwen/Qwen2-0.5B-Instruct",reward_funcs=reward_func,train_dataset=dataset,
)
trainer.train()
create_model_card
create_model_card(model_name: typing.Optional[str] = None,dataset_name: typing.Optional[str] = None,tags: typing.Union[str, list[str], NoneType] = None
)
- 参数:
model_name(str或None,可选,默认值为None) - 模型名称。dataset_name(str或None,可选,默认值为None) - 用于训练的数据集名称。tags(str、list[str]或None,可选,默认值为None) - 与模型卡片关联的标签。
使用训练器可用的信息创建模型卡片草稿。
7 GRPOConfig
class trl.GRPOConfig(output_dir: typing.Optional[str] = None,overwrite_output_dir: bool = False,do_train: bool = False,do_eval: bool = False,do_predict: bool = False,eval_strategy: typing.Union[transformers.trainer_utils.IntervalStrategy, str] = 'no',prediction_loss_only: bool = False,per_device_train_batch_size: int = 8,per_device_eval_batch_size: int = 8,per_gpu_train_batch_size: typing.Optional[int] = None,per_gpu_eval_batch_size: typing.Optional[int] = None,gradient_accumulation_steps: int = 1,eval_accumulation_steps: typing.Optional[int] = None,eval_delay: typing.Optional[int] = None,torch_empty_cache_steps: typing.Optional[int] = None,learning_rate: float = 1e-06,weight_decay: float = 0.0,adam_beta1: float = 0.9,adam_beta2: float = 0.999,adam_epsilon: float = 1e-08,max_grad_norm: float = 1.0,num_train_epochs: float = 3.0,max_steps: int = -1,lr_scheduler_type: typing.Union[transformers.trainer_utils.SchedulerType, str] = 'linear',lr_scheduler_kwargs: typing.Union[dict, str, NoneType] = <factory>,warmup_ratio: float = 0.0,warmup_steps: int = 0,log_level: typing.Optional[str] = 'passive',log_level_replica: typing.Optional[str] = 'warning',log_on_each_node: bool = True,logging_dir: typing.Optional[str] = None,logging_strategy: typing.Union[transformers.trainer_utils.IntervalStrategy, str] ='steps',logging_first_step: bool = False,logging_steps: float = 500,logging_nan_inf_filter: bool = True,save_strategy: typing.Union[transformers.trainer_utils.SaveStrategy, str] ='steps',save_steps: float = 500,save_total_limit: typing.Optional[int] = None,save_safetensors: typing.Optional[bool] = True,save_on_each_node: bool = False,save_only_model: bool = False,restore_callback_states_from_checkpoint: bool = False,no_cuda: bool = False,use_cpu: bool = False,use_mps_device: bool = False,seed: int = 42,data_seed: typing.Optional[int] = None,jit_mode_eval: bool = False,use_ipex: bool = False,bf16: bool = False,fp16: bool = False,fp16_opt_level: str = 'O1',half_precision_backend: str = 'auto',bf16_full_eval: bool = False,fp16_full_eval: bool = False,tf32: bool = False,local_rank: typing.Optional[bool] = None,ddp_backend: int = -1,tpu_num_cores: typing.Optional[str] = None,tpu_metrics_debug: typing.Optional[int] = None,debug: bool = False,dataloader_drop_last: bool = False,eval_steps: typing.Optional[float] = None,dataloader_num_workers: int = 0,dataloader_prefetch_factor: typing.Optional[int] = None,past_index: int = -1,run_name: typing.Optional[str] = None,disable_tqdm: typing.Optional[bool] = None,remove_unused_columns: typing.Optional[bool] = None,label_names: typing.Optional[bool] = False,load_best_model_at_end: typing.Optional[list[str]] = None,metric_for_best_model: typing.Optional[str] = None,greater_is_better: typing.Optional[bool] = False,ignore_data_skip: typing.Optional[bool] = None,fsdp: bool = False,fsdp_min_num_params: int = 0,fsdp_config: typing.Union[list[transformers.trainer_utils.FSDPOption], str, NoneType] = '',fsdp_transformer_layer_cls_to_wrap: typing.Union[dict, str, NoneType] = None,accelerator_config: typing.Union[dict, str, NoneType] = None,deepspeed: typing.Union[dict, str, NoneType] = None,label_smoothing_factor: float = 0.0,optim: typing.Union[transformers.training_args.OptimizerNames, str] = 'adamw_torch',optim_args: typing.Optional[str] = None,adafactor: bool = False,group_by_length: bool = False,length_column_name: typing.Optional[str] = 'length',report_to: typing.Union[NoneType, str, list[str]] = None,ddp_find_unused_parameters: typing.Optional[bool] = None,ddp_bucket_cap_mb: typing.Optional[int] = None,ddp_broadcast_buffers: typing.Optional[bool] = None,dataloader_pin_memory: typing.Optional[bool] = None,dataloader_persistent_workers: bool = True,skip_memory_metrics: bool = True,use_legacy_prediction_loop: bool = False,push_to_hub: bool = False,resume_from_checkpoint: typing.Optional[str] = None,hub_model_id: typing.Optional[str] = None,hub_strategy: typing.Union[transformers.trainer_utils.HubStrategy, str] = 'every_save',hub_token: typing.Optional[str] = None,hub_private_repo: typing.Optional[bool] = None,hub_always_push: bool = False,gradient_checkpointing: bool = False,gradient_checkpointing_kwargs: typing.Union[dict, str, NoneType] = None,include_inputs_for_metrics: bool = False,include_for_metrics: list = <factory>,eval_do_concat_batches: bool = True,fp16_backend: str = 'auto',push_to_hub_model_id: typing.Optional[str] = None,push_to_hub_organization: typing.Optional[str] = None,push_to_hub_token: typing.Optional[str] = None,mp_parameters: str = '',auto_find_batch_size: bool = False,full_determinism: bool = False,torchdynamo: typing.Optional[str] = None,ray_scope: typing.Optional[str] = 'last',ddp_timeout: typing.Optional[int] = 1800,torch_compile: bool = False,torch_compile_backend: typing.Optional[str] = None,torch_compile_mode: typing.Optional[str] = None,include_tokens_per_second: typing.Optional[bool] = False,include_num_input_tokens_seen: typing.Optional[bool] = False,neftune_noise_alpha: typing.Optional[float] = None,optim_target_modules: typing.Union[NoneType, str, list[str]] = None,batch_eval_metrics: bool = False,eval_on_start: bool = False,use_liger_kernel: bool = False,eval_use_gather_object: typing.Optional[bool] = False,average_tokens_across_devices: typing.Optional[bool