以下为本人自学回顾使用,请支持javaGuide原版。
1.CDN概述
CDN 就是将静态资源分发到多个不同的地方以实现就近访问,进而加快静态资源的访问速度,减轻服务器以及带宽的负担。
你可以将 CDN 看作是服务上一层的特殊缓存服务,分布在全国各地,主要用来处理静态资源的请求。
我们经常拿全站加速和内容分发网络做对比,不要把两者搞混了!全站加速(不同云服务商叫法不同,腾讯云叫 ECDN、阿里云叫 DCDN)既可以加速静态资源又可以加速动态资源,内容分发网络(CDN)主要针对的是 静态资源 。
绝大部分公司都会在项目开发中使用 CDN 服务,但很少会有自建 CDN 服务的公司。基于成本、稳定性和易用性考虑,建议直接选择专业的云厂商(比如阿里云、腾讯云、华为云等)
CDN最关心三个问题:
- 静态资源是如何被缓存到 CDN 节点中的?
- 如何找到最合适的 CDN 节点?
- 如何防止静态资源被盗用?
1.1.资源如何缓存到CDN节点?
你可以通过 预热 的方式将源站的资源同步到 CDN 的节点中。这样的话,用户首次请求资源可以直接从 CDN 节点中取,无需回源。这样可以降低源站压力,提升用户体验。
如果不预热的话,你访问的资源可能不在 CDN 节点中,这个时候 CDN 节点将请求源站获取资源,这个过程是大家经常说的 回源。
如果资源有更新的话,你也可以对其 刷新 ,删除 CDN 节点上缓存的旧资源,并强制 CDN 节点回源站获取最新资源。
命中率 和 回源率 是衡量 CDN 服务质量两个重要指标。命中率越高越好,回源率越低越好。
1.2.什么是静态资源?
| 特征 | 说明 | 示例 |
|---|---|---|
| 内容不变性 | 文件内容在发布后不会动态变化 | logo.png、jquery.min.js |
| 无服务端计算 | 请求处理不依赖后端逻辑(如数据库查询、用户会话) | CSS 文件、字体文件 |
| 可缓存性 | 支持 HTTP 缓存头(如 Cache-Control: max-age=3600) | 视频切片(.ts)、PDF 文档 |
| 高频访问 | 被大量用户重复访问,适合边缘节点缓存 | 热门商品图片、软件安装包 |
2.负载均衡
负载均衡可以简单分为 服务端负载均衡 和 客户端负载均衡 这两种。
2.1.服务端负载均衡(Nginx)
服务端负载均衡 主要应用在 系统外部请求 和 网关层 之间,可以使用 软件(Nginx) 或者 硬件(F5,很贵,别想) 实现。
根据 OSI 模型,服务端负载均衡可以分为:四层和七层负载均衡。
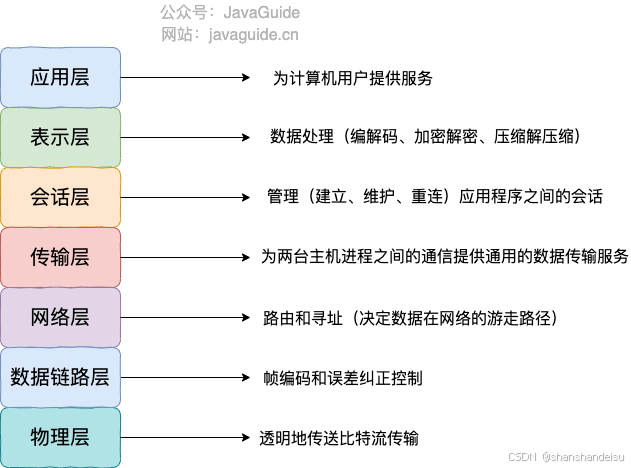
四层负载均衡 工作在 OSI 模型第四层,也就是传输层,这一层的主要协议是 TCP/UDP,负载均衡器在这一层能够看到数据包里的源端口地址以及目的端口地址,会基于这些信息通过一定的负载均衡算法将数据包转发到后端真实服务器。也就是说,四层负载均衡的核心就是 IP+端口层面的负载均衡,不涉及具体的报文内容。
七层负载均衡 工作在 OSI 模型第七层,也就是应用层,这一层的主要协议是 HTTP 。这一层的负载均衡比四层负载均衡路由网络请求的方式更加复杂,它会读取报文的数据部分(比如说我们的 HTTP 部分的报文),然后根据读取到的数据内容(如 URL、Cookie)做出负载均衡决策。也就是说,七层负载均衡器的核心是报文内容(如 URL、Cookie)层面的负载均衡,执行第七层负载均衡的设备通常被称为 反向代理服务器 。
七层负载均衡比四层负载均衡会消耗更多的性能,不过,也相对更加灵活,能够更加智能地路由网络请求,比如说你可以根据请求的内容进行优化如缓存、压缩、加密。
在工作中,我们通常会使用 Nginx 来做七层负载均衡
2.2.客户端负载均衡
Java 领域主流的微服务框架 Dubbo、Spring Cloud 等都内置了开箱即用的客户端负载均衡实现。Dubbo 属于是默认自带了负载均衡功能,Spring Cloud 是通过组件的形式实现的负载均衡,属于可选项,比较常用的是 Spring Cloud Load Balancer(官方,推荐) 和 Ribbon(Netflix,已被弃用)。
轮询法
未加权重的轮询算法适合于服务器性能相近的集群,其中每个服务器承载相同的负载。加权轮询算法适合于服务器性能不等的集群,权重的存在可以使请求分配更加合理化。
哈希法
将请求的参数信息通过哈希函数转换成一个哈希值,然后根据哈希值来决定请求被哪一台服务器处理。在服务器数量不变的情况下,相同参数的请求总是发到同一台服务器处理,比如同个 IP 的请求、同一个用户的请求。
一致性 Hash 法
和哈希法类似,一致性 Hash 法也可以让相同参数的请求总是发到同一台服务器处理。不过,它解决了哈希法存在的一些问题。常规哈希法在服务器数量变化时,哈希值会重新落在不同的服务器上,这明显违背了使用哈希法的本意。而一致性哈希法的核心思想是将数据和节点都映射到一个哈希环上,然后根据哈希值的顺序来确定数据属于哪个节点。当服务器增加或删除时,只影响该服务器的哈希,而不会导致整个服务集群的哈希键值重新分布。
3.主从复制(原理和canal)
- 主库将数据库中数据的变化写入到 binlog
- 从库连接主库
- 从库会创建一个 I/O 线程向主库请求更新的 binlog
- 主库会创建一个 binlog dump 线程来发送 binlog ,从库中的 I/O 线程负责接收
- 从库的 I/O 线程将接收的 binlog 写入到 relay log 中。
- 从库的 SQL 线程读取 relay log 同步数据到本地(也就是再执行一遍 SQL )。
canal 可以帮助我们实现 MySQL 和其他数据源比如 Elasticsearch 或者另外一台 MySQL 数据库之间的数据同步。
canal 的原理就是模拟 MySQL 主从复制的过程,解析 binlog 将数据同步到其他的数据源。