近日,阿里云人工智能平台PAI与华南理工大学合作在国际多媒体顶级会议ACM MM2024上发表VICTORIA算法,这是一种面向StableDiffusion的多目标图像编辑算法。VICTORIA通过文本依存关系来修正图像编辑过程中的交叉注意力图,从而确保关系对象的一致性,支持用户通过修改描述性提示一次性编辑多个目标。
论文:
Bingyan Liu, Chengyu Wang, Jun Huang, Kui Jia.Attentive Linguistic Tracking in Diffusion Models for Training-free Text-guided Image Editing. ACM MM 2024
背景
近年来,文本到图像合成(TIS)模型,尤其是如Stable Diffusion、DALL-E 2和Imagen等,展现出卓越的性能,并在学术界和工业界中引起了广泛关注。这些模型利用大规模的图像-文本对数据集进行训练,并结合先进的技术,比如大规模预训练语言模型、变分自编码器和扩散模型,能够生成高质量的图像。此外,这些TIS模型还具备强大的图像编辑能力。
文本引导图像编辑(TIE)已成为一个重要的研究方向,其中的零样本图像编辑算法可以直接利用预训练的文图生成模型来完成图像编辑任务。当前,无需再进行训练的TIE技术在图像转换、风格转换与视觉属性修改等方面表现出色,同时有效保留了原始图像的结构与构图完整性。例如,Prompt-to-Prompt的方法通过替换源提示中与目标编辑词相关的交叉注意图(CAM),来精准修改图像的特定区域。同时,InstructPix2Pix方法则通过使用P2P生成的图像创建图像转换训练数据集,以提升基于指令的模型性能。
尽管现有的TIE算法取得了一定的成果,但依然存在一些局限性。如图1所示,现有流行的TIE方法在对图像中的多个对象进行编辑时,往往会面临一些挑战,主要体现在对象丢失(如丢失苹果)、对象属性缺失(如斑点)以及背景表达不完整等问题。这些编辑准确性的缺陷往往是由于交叉注意力层在表示多个对象时的精确度不足所导致的。解决这些问题将是未来研究的重要方向,以进一步提升图像编辑的效果和质量。

图1. 图像编辑的效果对比以及我们提出方法的结果
在本论文中,我们重点介绍了 VIOTRIA 编辑算法,它应用语言知识来应对对象场景编辑中因目标缺失(如对象、属性和背景)所引发的问题。VICTORIA 通过分析编辑文本中单词之间的依存关系,将这种关系融入注意力机制的中间表示中,从而修正并生成所需的目标图像。实验结果显示,VICTORIA 在新的及现有的公共基准数据集上均表现优异,能够实现更精确的编辑对齐。
算法架构
图2展示了 VICTORIA 的整体框架。首先,确保图像之间的空间一致性至关重要,我们通过控制自注意机制来实现这一目标。其次,VICTORIA 分析输入编辑文本中单词之间的依存关系,并在生成目标编辑图像的过程中主动干预交叉注意力图来丰富了编辑区域的生成结果。最后,VICTORIA 通过提取编辑对象相关的交叉注意图并转换掩码,有效保留图像中未被编辑的区域。

图 2:VICTORIA在对图像进行编辑的过程示意图
自注意控制源图像结构保留
我们从自注意力层中提取查询和键
并替换到目标图像的对应的生成过程。该过程公式如下:
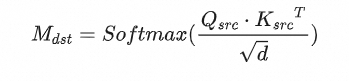
其中 是编辑过程中目标图像的SAM,d是键和查询的特征维度。
语言链接增强
我们首先通过依存句法分析从输入Prompt中提取修饰语-中心词关系。我们将S定义为分析结果中的修饰语-中心词对的集合。用 表示对应于修饰语-中心词对
的Cross Attention矩阵
和
之间的距离,其中
和
分别表示修饰语和中心词。例如,在Prompt“一个粉红色的光滑苹果和一个有斑点的水罐”中,集合 S 包含三对:
1) s_m =“粉红色”和 s_n =“苹果”,
2) s_m =“光滑”和 s_n =“苹果”,
3) s_m =“有斑点”和 s_n =“水罐”。
在这一模块中,我们首先构建一个正损失函数,以最小化修饰词和中心词之间的Cross Attention矩阵距离,其定义为:
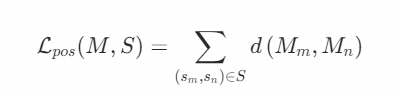
此外,我们设计了一个负向损失函数,从而促进不具有依存关系的单词对在表征上互相远离。令U表示目标提示中未包含在S中的单词集合, 表示与不相关单词
(例如 "a"、"and'')相对应的Cross Attention矩阵。因此,负损失定义采用对称的Kullback–Leibler (KL) 散度,如下所示:
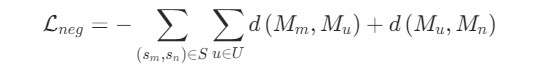
此外,为了鼓励修饰语-中心词对中的中心词(例如,“苹果”、“水罐”)的Cross Attention矩阵具有较高的激活值,从而将注意力图更精确地聚焦在相应的对象区域上,我们将注意力损失定义如下:
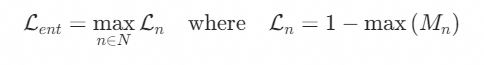
我们的语言链接增强任务的整体损失函数汇总如下:

语言混合掩码
我们将 表示为包含待编辑的词w及其相关修饰语/中心词的集合。以Prompt“一张彩色松鸡的照片”为例,对于编辑词“彩色”,
不仅包含“彩色”本身,还包含“松鸡”。令W表示所有编辑词的集合,并定义
来表示与W中任何词在语义上相关的词的集合。进一步,我们将每个词
相关的Cross Attention矩阵表示为
。语言混合掩码生成过程如下所示:
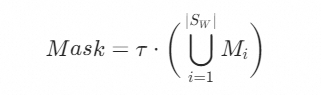
其中 是从 {0.3,0.4,0.5} 中选择的经验阈值。在扩散去噪过程中,源图像和目标图像的latent code分别为
和
。如果加入语言混合掩码掩码,我们生成图像的latent code(表示为
)可以通过以下公式进行计算:
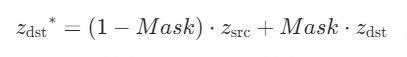
此公式有助于平衡源图像和目标图像的混合,同时考虑到语言知识。
算法伪代码
将上述技术融合,算法为代码如下:

图 3:VICTORIA在合成图像编辑和真实图像编辑场景下的伪代码
实验结果
图4展示了VICTORIA的编辑结果,它成功地修改了原始图像的中多个对象的属性、风格、场景和类别。

图 4:VICTORIA编辑结果示例
图5对比展示了VICTORIA与其他一些SOTA图像编辑技术的效果。在所有的案例中,VICTORIA都能够实现与描述提示高度一致的精细编辑,同时最大限度地保留了原图的结构细节。

图 5:VICTORIA 与其他编辑方法的对比
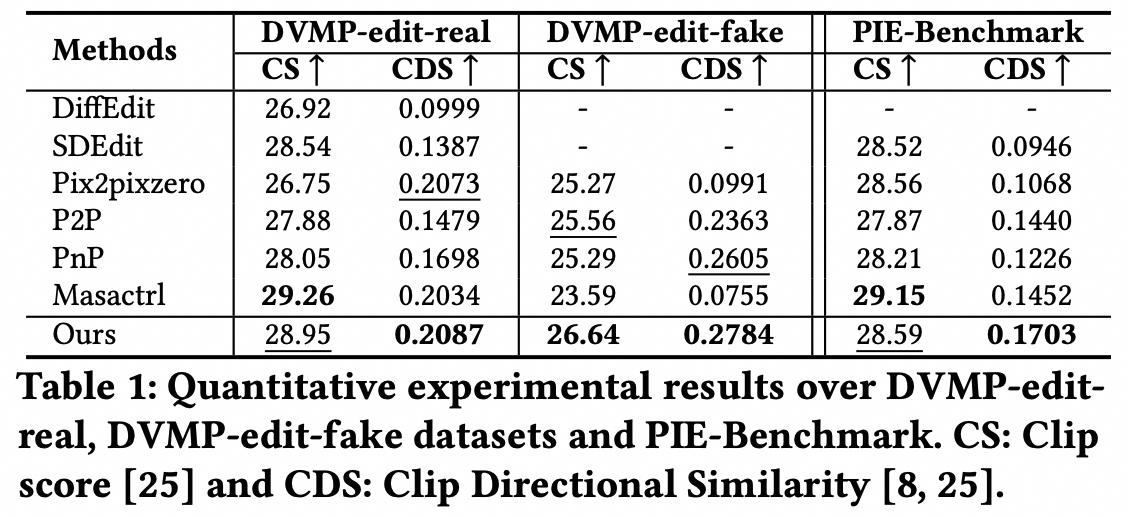
下表展示了不同编辑算法在多个基准数据集上的定量实验结果。可以看出,我们的方法在CDS指标方面明显优于所有其他方法,这表明我们的方法能够很好地保留原始图像的空间结构,并根据目标提示的要求进行编辑。
更多的实验结果及讨论,欢迎阅读论文: Attentive Linguistic Tracking in Diffusion Models for Training-free Text-guided Image Editing。目前 VICTORIA 已经在 EasyNLP(https://github.com/alibaba/EasyNLP/tree/master/diffusion/VICTORIA)开源。欢迎广大用户试用!
阿里云人工智能平台PAI长期招聘正式员工/实习生。团队专注于深度学习算法研究与应用,重点聚焦大语言模型和多模态AIGC大模型的应用算法研究和应用。简历投递和咨询:chengyu.wcy@alibaba-inc.com。
参考文献
-
Rombach R, Blattmann A, Lorenz D, et al. High-resolution image synthesis with latent diffusion models[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2022: 10684-10695.
-
Hertz A, Mokady R, Tenenbaum J, et al. Prompt-to-prompt image editing with cross attention control[J]. arXiv preprint arXiv:2208.01626, 2022.
-
Tumanyan N, Geyer M, Bagon S, et al. Plug-and-play diffusion features for text-driven image-to-image translation[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023: 1921-1930.
-
Meng, Chenlin et al. “SDEdit: Guided Image Synthesis and Editing with Stochastic Differential Equations.” International Conference on Learning Representations (2021).
-
Parmar G, Kumar Singh K, Zhang R, et al. Zero-shot image-to-image translation[C]//ACM SIGGRAPH 2023 Conference Proceedings. 2023: 1-11.
-
Rassin R, Hirsch E, Glickman D, et al. Linguistic binding in diffusion models: Enhancing attribute correspondence through attention map alignment[J]. Advances in Neural Information Processing Systems, 2024, 36.
论文信息
论文名字:Attentive Linguistic Tracking in Diffusion Models for Training-free Text-guided Image Editing
论文作者:刘冰雁、汪诚愚、黄俊、贾奎
论文pdf链接:https://openreview.net/pdf?id=efTur2naAS