目录
- 参考
- 概念
- 架构原理
- 运行单位Agent
- 传输基本单位Event
- 数据流向
- 多节点
- 多路复用
- flume+Kafka实时计算
参考
经典大数据开发实战(Hadoop &HDFS&Hive&Hbase&Kafka&Flume&Storm&Elasticsearch&Spark)
概念
Flume 是 Cloudera 提供的一个高可用的,高可靠的,分布式的海量日志采 集、聚合和传输的软件。
Flume 的核心是把数据从数据源(source)收集过来,再将收集到的数据送到 指定的目的地(sink)。为了保证输送的过程一定成功,在送到目的地(sink)之前, 会先缓存数据(channel),待数据真正到达目的地(sink)后,flume 在删除自己缓 存的数据。
Flume 支持定制各类数据发送方,用于收集各类型数据;同时,Flume 支持 定制各种数据接受方,用于最终存储数据。一般的采集需求,通过对 flume 的简 单配置即可实现。针对特殊场景也具备良好的自定义扩展能力。因此,flume 可 以适用于大部分的日常数据采集场景。
架构原理
运行单位Agent
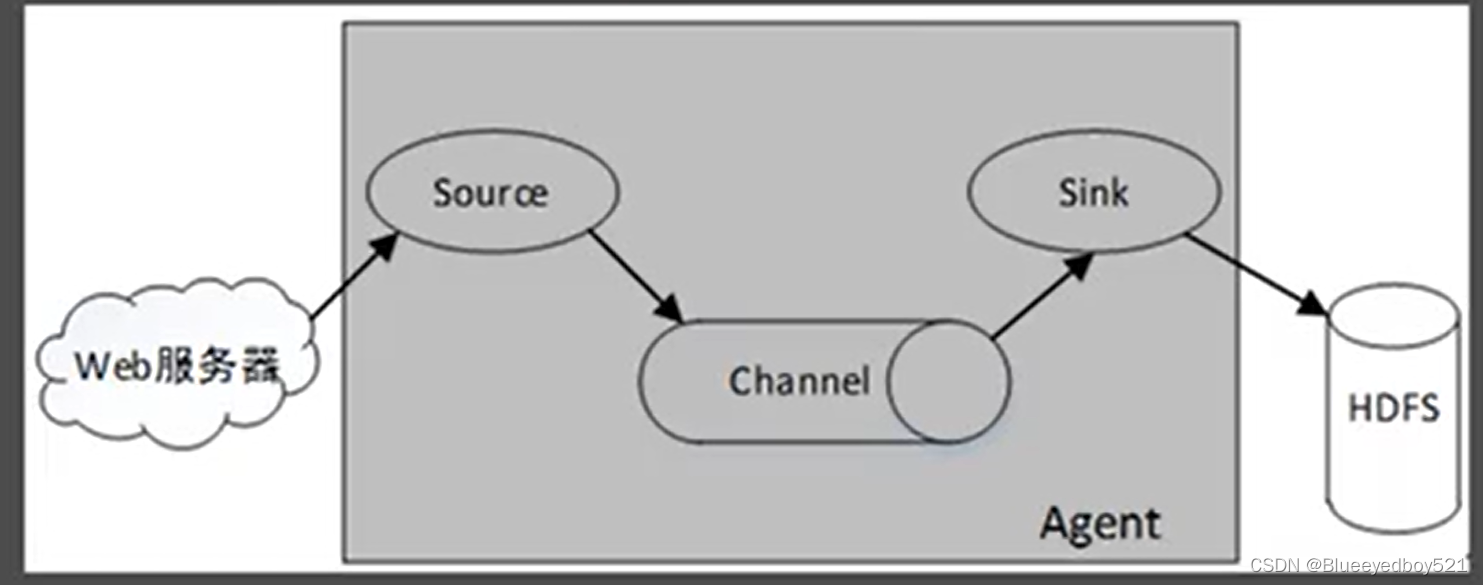
Flume中最小的独立运行单位是Agent,Agent是一个JVM进程,运行在日志收集节点(服务器节点),其包含三个组件Source(源)、Channel(通道)和Sink(接收地)。数据可以从外部数据源流入到这些组件,然后再输出到目的地。一个Flume单节点架构如图
传输基本单位Event
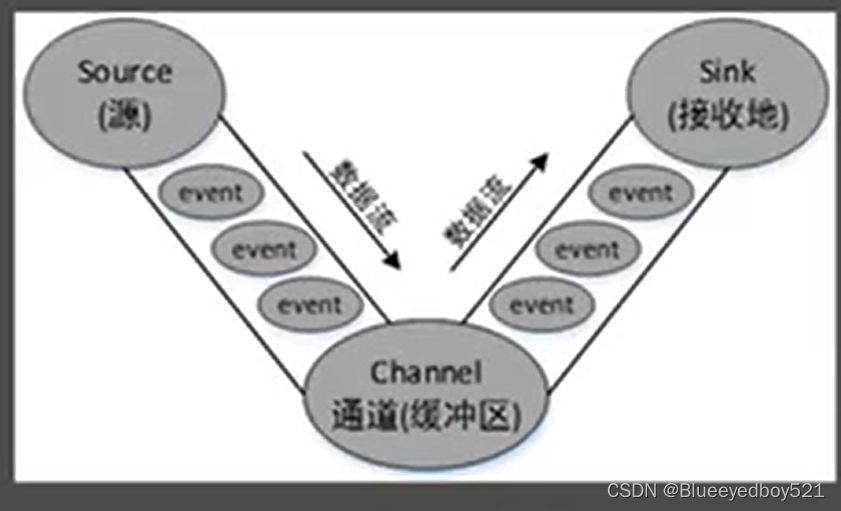
Flume中传输数据的基本单位是event(如果是文本文件,通常是一行记录),event包括event头(headers)和event体(body),event头是一些key-value键值对,存储在Map集合中,就好比HTTP的头信息,用于传递与体不同的额外信息,event体为一个字节数组,存储实际要传递的数据。event的结构如图

数据流向
event从Source流向Channel,再流向Sink,最终输出到目的地,event的数据流向如图
Source用于消费外部数据源中的数据(event,例如Web系统产生的日志)
,一个外部数据源(如Web服务器)可以以Source识别的格式向Source发送数据。
Channel用于存储Source传入的数据,当这些数据被Sink消费后则会自动删除。
Sink用于消费Channel中的数据,然后将其存放进外部持久化的文件系统中(例如HDFS、HBase和Hive等).
Flume可以在一个配置文件中指定一个或者多个Agent,每个Agent都需要指定Source、Channel和Sink三个组件以及他们的绑定关系,从而形成一个完整的数据流,
多节点
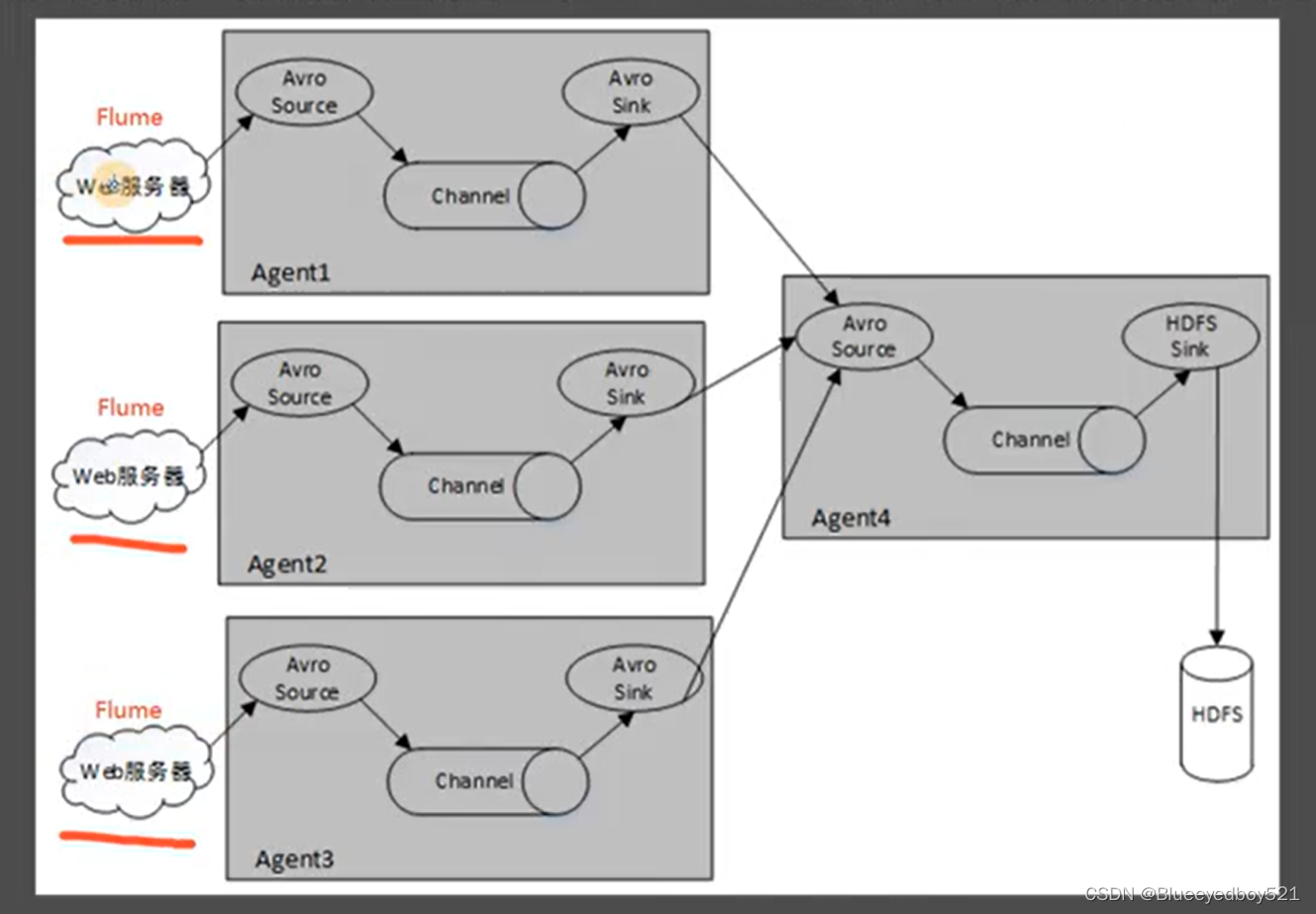
Flume除了可以单节点直接采集数据外,也提供了多节点共同采集数据的功能,多个Agent位于不同的服务器上,每个Agent的Avro Sink将数据输出到了另一台服务器上的同一个Avro Source进行汇总,最终将数据输出到了HDFS文件系统中
多路复用
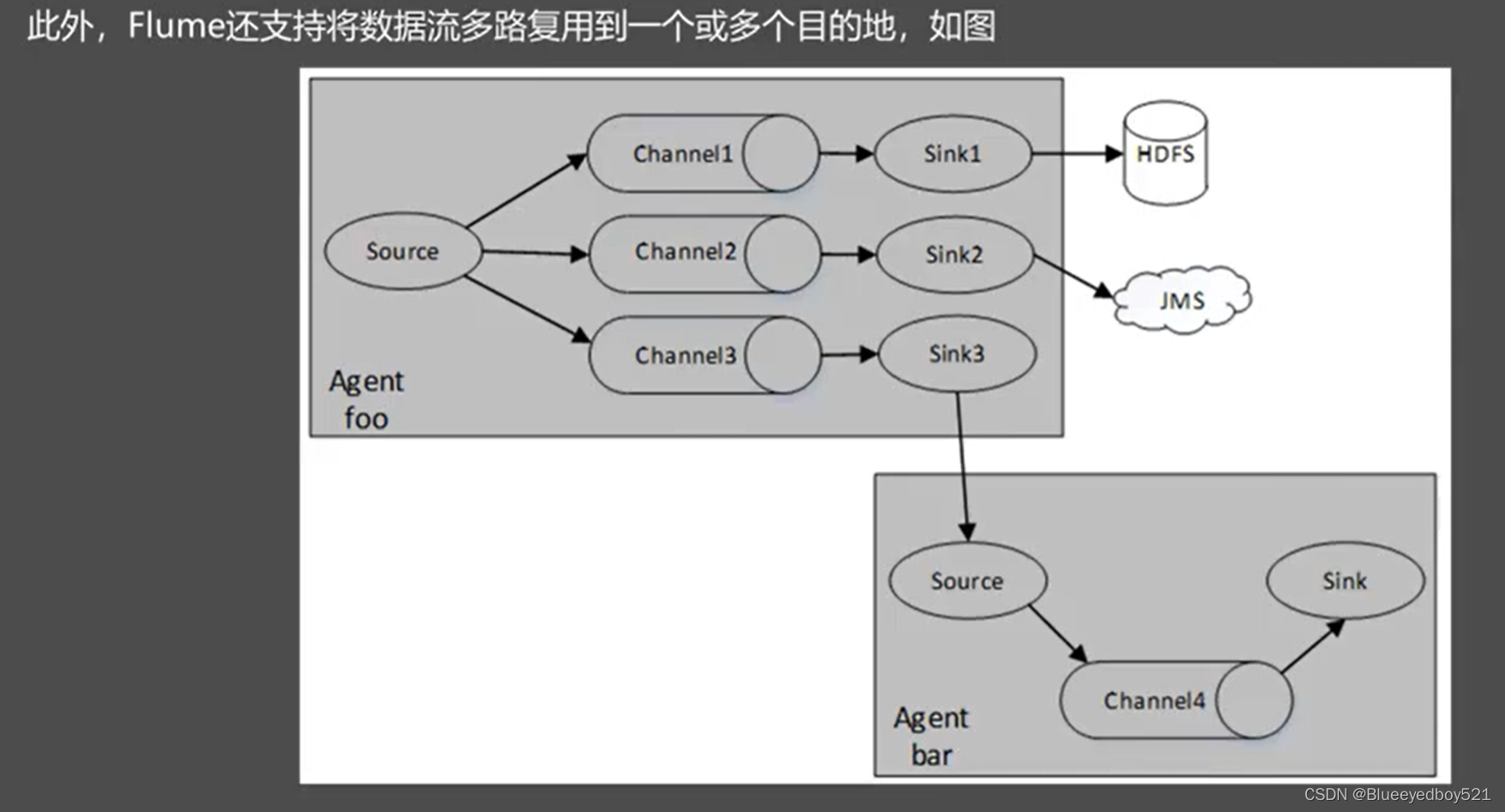
一个 Source 可以对应多个 Channel,一个 Channel 对应多个 Source,多对多的关系。
一个 Channel 可以对应多个 Sink,一个 sink 不能对应多个 Channel,一对多的关系。
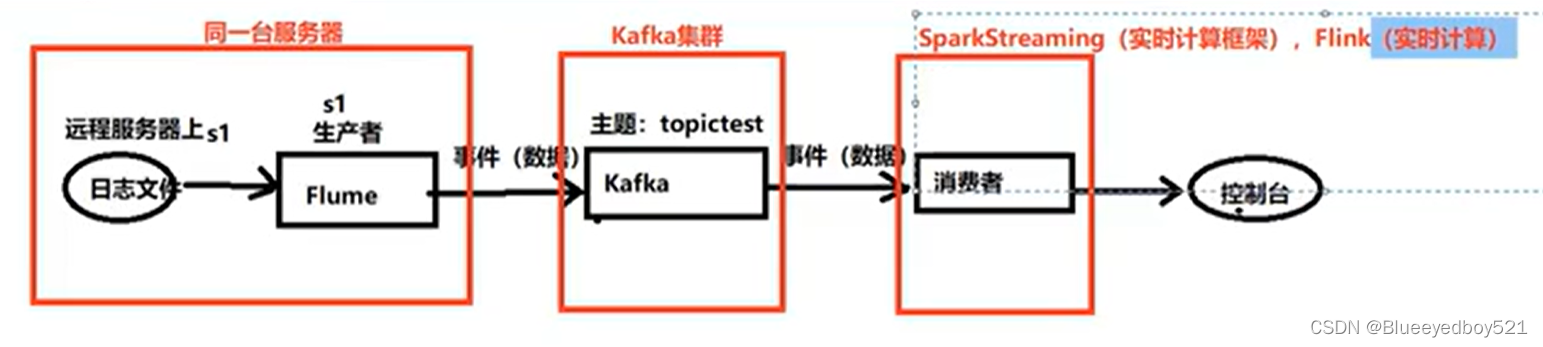
flume+Kafka实时计算