转载至:何骏昊 开放知识图谱
原文地址:论文浅尝 | Interactive-KBQA:基于大语言模型的多轮交互KBQA(ACL2024)

笔记整理:何骏昊,东南大学硕士,研究方向为语义解析
论文链接:https://arxiv.org/abs/2402.15131
发表会议:ACL 2024
1. 动机
知识库问答(KBQA)是一个日益重要的研究领域,它利用结构化知识库(KB)为自然语言(NL)问题提供精确答案。大语言模型(LLM)的出现为增强KBQA系统开辟了新途径。这些模型在KBQA领域中的推理和少样本学习方面显示出惊人的结果。该工作的动机主要源于解决KBQA领域中的以下关键挑战:
(1)复杂查询处理的局限性:现有基于信息检索(IR)的方法在处理涉及类型约束、数值比较或多跳推理的复杂查询时表现不足。例如,类似“身高超过2米的篮球运动员有多少人?”的问题需要更深入的语义理解,而传统方法难以有效捕捉此类复杂逻辑。
(2)语义解析(SP)方法的高标注成本:基于语义解析的方法依赖大量标注数据来生成可执行的逻辑形式(如SPARQL查询),但数据标注成本高昂,限制了方法的可扩展性。此外,这类方法的推理过程通常缺乏透明性,形成“黑箱”问题。
(3)大语言模型的潜力未充分释放:尽管LLMs在少样本学习和复杂推理任务中展现了强大能力,但现有KBQA系统主要将其用作分类器或简单生成器,未充分利用其交互式推理能力。例如,许多方法仅用LLMs生成逻辑形式的初稿,而非通过多轮交互动态优化结果。
基于这些挑战,论文提出Interactive-KBQA框架,核心思路是将LLM视为与知识库交互的“智能体”,通过多轮对话逐步生成逻辑形式。这种方法不仅降低了标注成本,还通过交互式工具(如搜索节点、图模式匹配)增强了复杂问题的处理能力,并通过人工干预机制提高了系统的灵活性和可解释性。最终目标是实现一个高效、透明且适应低资源场景的KBQA系统。
2. 贡献
该工作的主要贡献为以下四点:
(1)提出交互式KBQA框架(Interactive-KBQA),将LLM视为与KB交互的智能体,通过多轮对话逐步生成逻辑形式(如SPARQL查询)。
(2)设计统一工具集与交互逻辑:开发了三个通用API,适配不同知识库(Freebase、Wikidata、Movie KB);通过标准化工具接口,实现了跨异构知识库的兼容性,简化了复杂查询(如多跳、数值约束、限定符)的处理流程。
(3)实现低资源场景下的高效性能。针对每类复杂问题(如多跳、CVT、限定符),仅需标注2个示例即可引导LLM完成推理。在三个数据集上,使用极少量标注达到或超越传统全监督方法的性能。
(4)发布高质量标注数据集,包含逐步推理过程的人工标注(如交互历史、错误修正记录),涵盖多种复杂问题类型。
3. 方法
3.1 问题定义
KB定义为三元组集合K∈E×R×(E∪L∪C),其中E为实体集合,R为关系集合,C为类别集合,L为字面值。给定自然语言问题Q和知识库K,目标是通过语义解析生成可执行的SPARQL查询S,即建模为条件概率p(S|Q,K)。
3.2 框架设计
提出Interactive-KBQA框架(如图1所示),将LLM视为与知识库交互的智能体,通过多轮对话生成逻辑形式(SPARQL)。
交互范式:采用“思考-行动-观察”(Thought-Action-Observation)循环:1. 思考(Thought):LLM生成自然语言推理步骤(如问题分解、谓词选择);2. 行动(Action):调用预定义工具(如搜索节点、执行查询),生成Python风格的API调用指令。3. 观察(Observation):执行工具后返回结果(如实体列表、子图模式),作为下一轮输入。
终止条件:当LLM生成Action: Done时,输出最终SPARQL查询结果。
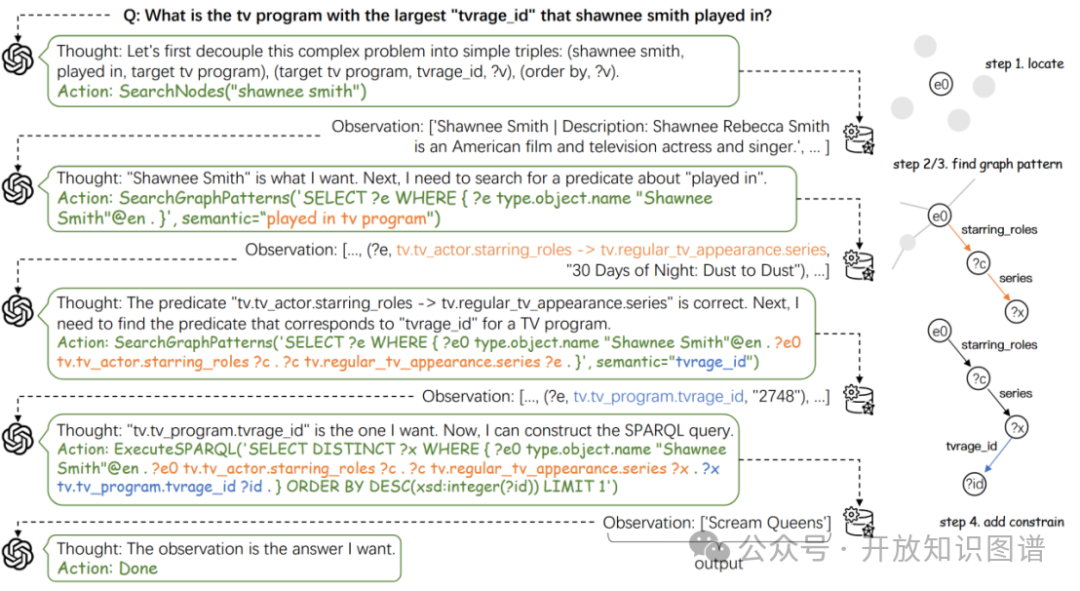
图1 Interactive-KBQA框架的交互过程示例
3.3 知识库交互工具
框架基于三个通用工具(SearchNodes、SearchGraphPatterns、ExecuteSPARQL)引导LLM逐步推理复杂问题:
(1)SearchNodes(name):通过实体表面名称(如“Tom Hanks”)搜索知识库中的节点,返回节点的规范化名称、描述和类型(如“Barack Obama | 美国前总统”)。
(2)SearchGraphPatterns(sparql, semantic):输入需以“SELECT ?e WHERE”开头的SPARQL片段,返回以 ?e 为中心的一跳子图,并根据语义参数(如“play in film”)对谓词排序。特别优化了Freebase的复合值类型(CVT)结构,例如将“Tom Hanks参演电影”映射为两个单跳关系(film.actor.film → film.performance.film)。
(3)ExecuteSPARQL(sparql):直接执行任意SPARQL查询,支持灵活探索知识库。
3.4 交互流程
构建提示模板Prompt={Inst,E,Q},其中Inst为任务指令,E为示例集合,Q为当前问题。每轮交互中,LLM根据历史H={c0,a0,o0,……,ct-1,at-1,ot-1} 生成动作at=LLM{Prompt,H},其中ct为自然语言推理步骤(如“需查找Tom Hanks参演的电影”),at为工具调用(如SearchNodes、ExecuteSPARQL),ot为工具返回结果。若生成动作“Done”,则输出最终答案。
针对多跳查询,逐步解析谓词而非具体实体(例如“法国的总统是谁?”需先定位国家节点,再搜索“president”关系);针对Freebase的CVT结构,显式分解为多个单跳关系(如将“演员-角色-电影”拆分为两跳);针对Wikidata的限定符(如“纽约市2010年人口”),设计专用SPARQL模式,通过修饰符(如point_in_time)约束查询。每类问题提供2个标注示例,引导LLM遵循特定推理路径。
3.5 人机协同标注
允许人工在交互过程中修正LLM的错误动作(如生成不存在谓词),形成修正后的历史{c0,a0,o0,……,a't,o't},并继续生成后续步骤。标注数据集包含详细的逐步推理过程,用于微调开源LLM(如Mistral-7B),降低对商业API的依赖。
4. 实验
4.1 实验设置
本工作采用:WebQuestionsSP (WebQSP) 和 ComplexWebQuestions 1.1 (CWQ):基于Freebase,分别包含简单(1-hop)和复杂(多类型)问题,问题类型包括Conjunction (Conj)、Composition (Compo)、Comparative (Compa)、Superlative (Super);KQA Pro:基于Wikidata,覆盖9类复杂问题(如计数、属性限定符、关系查询);MetaQA:基于Movie KB,包含1-hop至3-hop问题。
本工作从每个数据集均匀采样900个实例确保问题类型分布平衡。
4.2 基线方法
本工作采用以下基线方法:
(1)全数据微调方法:DeCAF(WebQSP)、BART-SPARQL(KQA Pro)、Edge-aware(MetaQA)。
(2)提示方法:KB-BINDER(少样本)、Chain-of-Thought (CoT) + Self-Consistency (SC)。
(3)低资源微调方法:在标注数据集上微调开源LLMs(Mistral-7B、Llama2-7B/13B)。
(4)对比方法:StructGPT、ToG(假设实体已链接)。
4.3 评估指标
本工作采用以下评估指标:
(1)F1分数:逻辑形式生成的匹配程度。
(2)RHits@1(随机命中率@1):答案实体排名第一的比例。
(3)EM(精确匹配):生成的SPARQL与标注完全一致的比例。
(4)准确率(KQA Pro):答案集合完全匹配的比例。
4.4 主要结果
如表1所示,该工作在WebQSP和KQA Pro上,由于训练数据量差异,GPT-4 Turbo的性能略低于全监督方法,但在CWQ和MetaQA(表2)上显著超越(如CWQ的总体F1为49.07%,MetaQA的Hits@1达99.67%)。 在复杂问题类型上表现突出,例如CWQ的“比较类”(Compa)和“最高级”(Super)问题分别提升29.85%和13.96%。
Mistral-7B微调后在CWQ和KQA Pro上的F1分别达到39.90%和64.40%,优于同等规模的基准方法(如SFT-SPARQL的28.10%和57.78%)。
Llama2-13B在部分任务(如CWQ的Compa问题)上表现接近GPT-4 Turbo(55.98% vs. 47.89%)。
表1 Interactive-KBQA在WebQSP 和 CWQ 上的结果
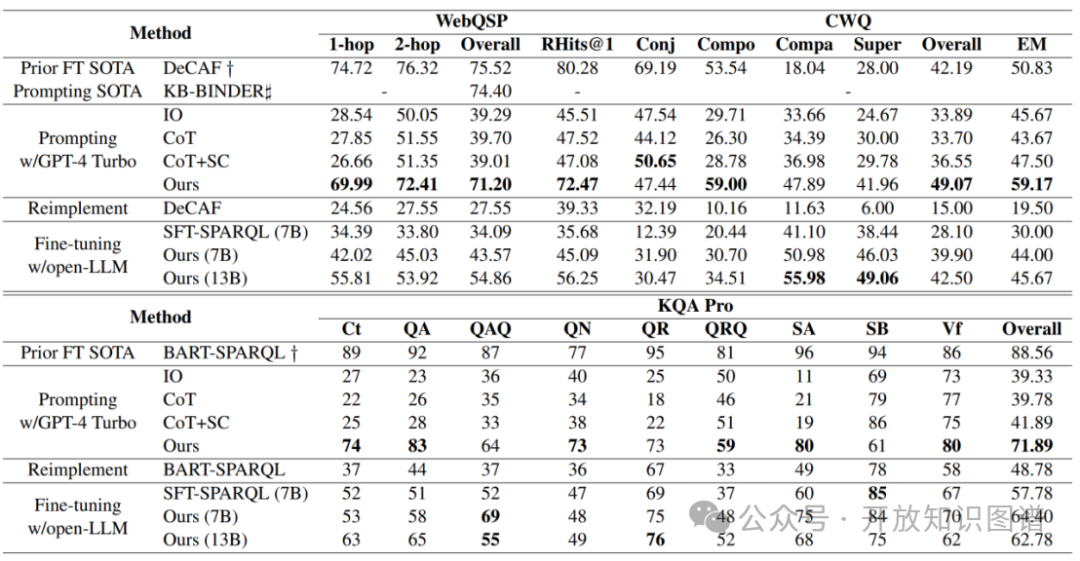
表2 Interactive-KBQA在MetaQA上的结果
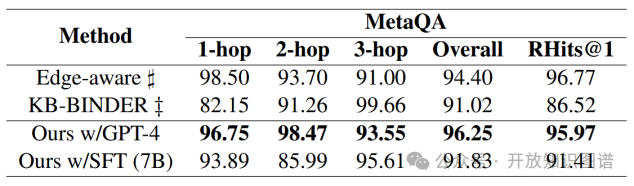
4.5 实体链接的影响
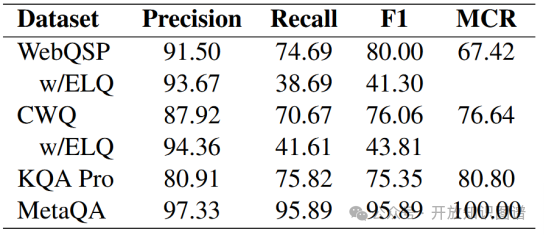
通过对比ELQ工具与论文方法,发现实体链接是性能瓶颈之一。在WebQSP和CWQ上,论文方法的F1分别为80.00%和76.06%,而ELQ仅41.30%和43.81%。引入提及覆盖率(MCR)指标(黄金实体名称在问题中的出现比例)后发现,KQA Pro和MetaQA的MCR较高(80.80%和100%),而WebQSP和CWQ较低(67.42%和76.64%)。
表3 实体链接的结果
4.6 消融实验
示例数量与覆盖率:如表4和表5所示,在CWQ(4类问题)和KQA Pro(9类问题)上,增加示例覆盖率可提升性能(如CWQ 4-shot比0-shot F1提升2.5%),但成本增加37.86%。
表4 问题类型分类器的性能
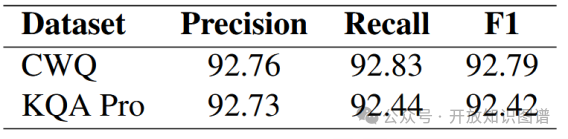
表5 示例编号和平均价格的影响
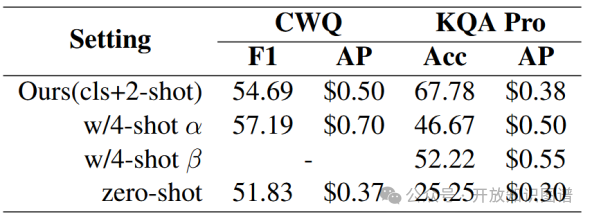
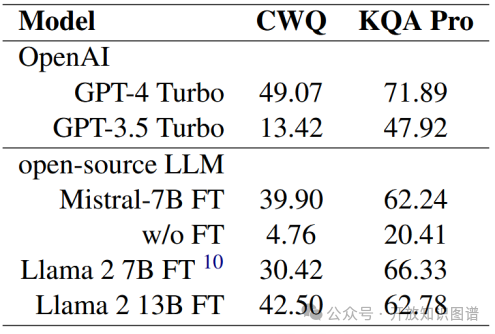
骨干模型对比:如表6所示,GPT-4 Turbo显著优于GPT-3.5(CWQ F1为49.07% vs. 13.42%),微调后的Mistral-7B优于未训练版本(CWQ 39.90% vs. 4.76%)。
表6不同骨干模型的性能
4.7 错误分析
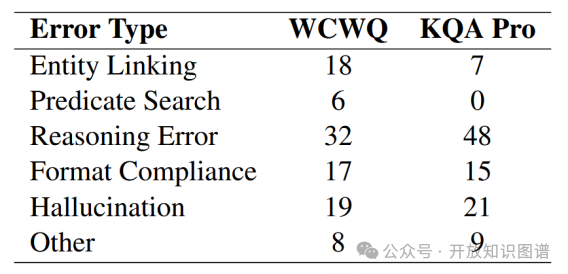
如表7所示,错误类型分为六类:实体链接(18%)、谓词搜索(6%)、推理(32%)、格式合规性(17%)、幻觉(19%)及其他(8%)。案例分析显示,人工干预可有效修正幻觉(如生成不存在谓词)和推理错误(如多跳路径遗漏)。例如,在问题“Justin Bieber的兄弟是谁?”中,LLM需通过性别约束修正初始错误答案,最终生成正确的SPARQL查询。
表7 错误类型的分布
5. 总结
该工作提出了Interactive-KBQA框架,通过将大型语言模型(LLM)作为与知识库交互的智能体,以多轮对话形式逐步生成可执行的逻辑形式(如SPARQL查询),解决了传统KBQA方法在处理复杂查询、高标注成本及模型黑箱问题上的瓶颈。其核心创新在于交互式工具设计(如SearchNodes、SearchGraphPatterns)与“思考-行动”范式的结合,允许LLM动态探索知识库结构,并通过少量标注示例引导推理。此外,该方法支持人工干预,能够修正模型错误,形成迭代优化机制,显著提升了低资源场景下的性能与可解释性。
该工作中实验设计覆盖了四个主流数据集,涵盖从简单到复杂的多类问题(如多跳、数值约束、限定符)。亮点在于:首先,该工作仅用2-4个标注示例即可达到或超越传统方法,凸显了框架的样本效率。其次,该工作通过分类错误类型(如实体链接、幻觉)和案例研究,揭示了模型瓶颈与改进方向。最后,该工作量化交互轮次与推理成本(如GPT-4 Turbo每轮$0.3–$0.5),为实际应用提供参考。
尽管方法在低资源场景下表现突出,但仍存在明显局限:首先,框架性能高度受限于LLM的推理质量,例如GPT-4 Turbo在复杂问题上的成功率显著高于开源模型(如Mistral-7B)。若LLM生成错误推理步骤(如幻觉谓词),需依赖人工干预修正,这在实际应用中可能增加操作成本。其次,多轮对话导致推理时间与API调用成本上升,尤其对需要高频查询的场景(如实时问答)不够友好。最后,实验集中于特定领域(如电影、人物),未验证在开放域或动态更新知识库中的适应性,且人工标注数据集的规模较小,可能影响模型鲁棒性。
未来工作需进一步优化工具自动化程度、降低对商业API的依赖,并探索更高效的交互策略(如压缩历史信息),以推动方法在实际系统中的落地。