目录
文献论证过程分析
1. 研究问题的提出与逻辑框架
2. 数据与方法:支撑论证的技术路径
3. 结果呈现:从数据到发现的转化
4. 讨论与结论:从发现到意义的升华
整体评价与改进建议
仿写启示
实验设计:《生成式人工智能在学术写作中的应用趋势及其影响因素研究》
实验目标
实验流程
1. 数据模拟与变量设定
2. AI生成概率测量
3. 实验分组与分析
4. 统计分析与假设验证
模拟数据示例
预期结果
实验意义与局限性
改进方向
大家好这里是AIWritePaper官方账号,官网👉AIWritePaper~为了通过仿写来掌握论证方法,研究者需要深入剖析文章中的论证过程。这涉及细致分析论文是如何构建其论点的,运用了哪些证据来支撑这些论点,以及对这些论证的逻辑严密性和充分性进行评估。这一分析过程正是DeepSeek的强项所在,我们不妨来审视一下DeepSeek所分析的论证过程。
提示词:
仔细分析一下我上传的文献的论证过程。

DeepSeek:
好的,我需要仔细分析用户上传的文献的论证过程。首先,我需要回顾文献的结构和主要内容,包括引言、方法、结果、讨论和结论部分。然后,我需要理解作者是如何构建他们的论点,支持他们的假设,并使用数据来验证这些假设的。
首先,引言部分提到了ChatGPT的发布对科学研究和学术写作的影响,并提出了研究问题。作者引用了之前的研究,说明AIGC工具在学术写作中的应用现状和存在的争议。这里需要确定作者是如何通过这些背景信息引出他们的研究问题和目标的。
接下来是方法部分,作者详细描述了数据集的来源、筛选标准,以及如何量化AIGC生成概率。他们使用了三种在线检测工具和一种基于关键词的手动检测方法。此外,作者还解释了如何获取作者的背景信息,包括国籍、母语和学术表现。这里需要分析作者选择这些方法的原因,以及这些方法是否能够有效支持他们的研究问题。
在结果部分,作者展示了四个主要发现:AIGC生成概率的逐渐增加、非英语母语作者更倾向于使用AIGC工具、学术表现与AIGC使用的弱相关性,以及历史使用AIGC的作者更可能继续使用。需要理解这些结果是如何通过数据分析得出的,以及作者如何解释这些结果的意义。
讨论部分,作者对这些结果进行了进一步的解释,并讨论了研究的局限性。他们提到AIGC工具对非英语母语作者的帮助,以及学术表现与AIGC使用无关的可能原因。同时,作者也指出了研究方法的局限性,如检测工具的间接性、数据集的局限性等。需要评估作者是否充分讨论了这些结果的理论和实际意义,以及他们的解释是否合理。
结论部分总结了主要发现,并提出了未来的研究方向。需要确认这些结论是否与前面的结果和讨论部分一致,并且是否有足够的证据支持。
在整个过程中,我需要注意以下几点:
1. **逻辑连贯性**:作者的论点是否在引言、方法、结果、讨论和结论中保持一致。
2. **数据支持**:作者是否提供了足够的数据和分析来支持他们的结论。
3. **方法合理性**:所采用的研究方法是否适合解决研究问题,是否存在潜在的偏差或局限性。
4. **结果解释**:作者对结果的解释是否合理,是否存在其他可能的解释。
5. **讨论深度**:讨论部分是否充分探讨了研究的意义、局限性和未来方向。
如果在分析过程中发现任何不清晰或矛盾的地方,需要进一步验证作者的论证是否严谨。例如,在方法部分,作者仅使用第一作者的学术表现数据,这可能忽略了团队合作的影响。此外,通过作者姓名推断国籍和母语可能存在误差,需要评估这种误差对结果的影响程度。
另外,作者提到三种检测工具的结果存在差异,特别是Sapling的高阳性率,但未深入讨论这些差异可能对结论产生的影响。需要思考作者是否充分考虑了这些方法的局限性,以及如何通过多种方法的结合来增强结论的稳健性。
最后,需要总结作者的论证过程是否有效,是否能够回答他们提出的研究问题,并为未来的研究提供有价值的见解。
文献论证过程分析
1. 研究问题的提出与逻辑框架
-
核心问题:
作者围绕两个核心问题构建论证:-
AIGC在学术写作中的使用程度及其随时间的变化;
-
AIGC使用与作者背景(母语、学术表现、历史使用)的关系。
通过引言中的文献综述,作者将研究定位在填补现有研究空白(如缺乏对作者背景的深入分析),并强调其创新性。
-
-
逻辑链条:
从“AIGC工具的普及(背景)” → “现有研究忽视作者背景因素(问题)” → “通过量化分析填补空白(目标)”,逻辑清晰,但文献对比稍显简略。
2. 数据与方法:支撑论证的技术路径
-
数据选择:
基于arXiv平台筛选2023年与生成式AI相关的4,889篇论文,聚焦LLM领域(作者认为该领域学者更熟悉AIGC工具)。
合理性:数据来源透明,但领域局限性可能影响结论的普适性。 -
AIGC生成概率的测量:
采用三种在线工具(GPTKit、Smodin、Sapling)和基于“GPT词”的手动检测,以多方法交叉验证增强结果稳健性。
潜在问题:-
工具间的低相关性(如Sapling的高阳性率)未充分解释,可能削弱结论的可信度;
-
“GPT词”检测过于简化(仅依赖5个关键词),可能遗漏其他语言特征。
-
-
作者背景的获取:
-
母语推断:通过姓名推断国籍,再结合官方语言数据,存在跨国合作、多语言作者的误差风险;
-
学术表现:仅提取第一作者的Google Scholar数据,忽略了团队合作对写作分工的影响。
-
3. 结果呈现:从数据到发现的转化
-
趋势分析:
通过时间序列图表(图1c)展示AI生成概率的逐步上升,结合ChatGPT发布时间点,验证工具普及对写作风格的影响。
论证有效性:数据直观,但未排除其他干扰因素(如领域内研究热点的自然语言演变)。 -
语言差异的影响:
使用非参数检验(Mann-Whitney U、Kruskal-Wallis H)对比英语与非英语母语作者的AI生成概率,发现显著差异。
解释深度:仅指出“语言障碍驱动使用”,未探讨具体机制(如语言焦虑、写作效率需求)。 -
学术表现与AIGC弱相关性:
通过分组对比和Spearman相关系数,显示引用次数、h指数等与AI生成概率无显著关联。
潜在偏差:仅依赖第一作者数据可能掩盖团队内部的分工差异(如资深学者可能更少参与写作)。 -
历史使用的路径依赖:
发现既往使用AIGC的作者更可能继续使用,体现技术采纳的惯性。
论证亮点:通过纵向数据关联揭示行为模式,但未区分主动选择与工具依赖的差异。
4. 讨论与结论:从发现到意义的升华
-
主要发现的解释:
-
强调AIGC对非英语母语学者的辅助作用,呼应学术公平性议题;
-
弱化学术表现与工具使用的关联,暗示AIGC工具可能独立于科研能力;
-
指出历史使用的延续性,为技术采纳理论提供实证支持。
-
-
伦理与实践意义:
提出AIGC工具需规范使用(如披露要求),但未结合具体政策案例(如期刊指南),讨论稍显抽象。 -
研究局限性:
坦承检测工具的间接性(无法区分修改后的AI文本)、数据集领域局限性、因果推断缺失,为未来研究指明方向。
整体评价与改进建议
-
论证优势:
-
多方法交叉验证:结合检测工具与手动分析,增强结果可信度;
-
数据驱动结论:通过统计检验明确变量关系,避免主观臆断;
-
透明性与可复现性:公开数据来源与方法细节,符合开放科学原则。
-
-
论证不足:
-
工具差异未充分讨论:如Sapling的高阳性率是否反映模型过拟合或检测逻辑差异;
-
机制解释薄弱:未深入分析“为何非英语母语者更依赖AIGC”(如通过访谈或语言能力测试);
-
团队合作忽略:仅关注第一作者,可能遗漏多作者协作中的AIGC使用差异。
-
-
改进方向:
-
补充混合方法:如结合问卷调查,探讨作者使用AIGC的具体动机;
-
扩展数据范围:纳入多学科论文,验证结论的普适性;
-
深入因果分析:采用工具变量或实验设计,区分AIGC使用的驱动因素。
-
仿写启示
若以《生成式人工智能在学术写作中的应用趋势及其影响因素研究》为题,需注意:
-
方法透明性:详细说明工具选择依据与数据处理逻辑;
-
结果解释深度:结合理论与实际案例,避免仅描述统计关联;
-
伦理讨论具体化:链接现有政策(如期刊AIGC披露指南),增强建议的可操作性。





整个流程描述的并没有什么问题,比较关心的是研究方法、实验的设计。这个流程我们也使用DeepSeek-R1模型来分析。
提示词:
请参考我刚才上传的论文,给我的选题《生成式人工智能在学术写作中的应用趋势及其影响因素研究》设计一个实验,包括实验流程,实验数据你可以自己模拟。

DeepSeek:
好的,我需要为用户设计一个实验,题目是《生成式人工智能在学术写作中的应用趋势及其影响因素研究》。首先,我需要回顾用户上传的论文内容,了解其研究方法和发现。用户之前的论文主要基于arXiv平台的数据,使用AI检测工具分析摘要的AI生成概率,并结合作者背景(如母语、学术表现)进行相关分析。
接下来,我需要根据这个选题设计一个实验。用户可能希望这个实验能够进一步验证或扩展原有研究的结论,或者探索新的影响因素。考虑到用户之前的论文已经涉及时间趋势、语言差异、学术表现和历史使用,或许可以设计一个实验来补充或深化这些方面。
首先,我需要确定实验的目标。可能的实验目标包括:
1. **验证AIGC工具使用的时间趋势**:通过模拟不同时间段的数据,观察AI生成概率是否持续增长。
2. **探索新的影响因素**:例如,学科领域差异、作者合作模式对AIGC使用的影响。
3. **评估不同检测工具的一致性**:比较多种AI检测工具在相同数据集上的表现,验证结果的稳健性。
接下来,设计实验流程。用户提到“实验数据可以自己模拟”,因此需要生成或模拟符合现实的数据集。可能的步骤包括:
1. **数据收集与模拟**:生成一个包含论文摘要、作者背景信息(母语、学术表现)、提交时间等字段的模拟数据集。
2. **AI生成概率的测量**:使用多个AI检测工具(如GPTKit、Smodin、Sapling)对模拟摘要进行评分。
3. **变量操作与分析**:设定不同的实验组和对照组,例如按母语分组、按学科领域分组,分析各组间的AI生成概率差异。
4. **统计检验与结果解释**:应用适当的统计方法(如t检验、回归分析)验证假设。
在模拟数据时需要注意以下几点:
- **真实性**:数据分布应尽量接近真实情况,例如非英语母语作者的AI生成概率较高。
- **多样性**:涵盖不同学科领域、作者合作模式(单作者 vs 多作者团队)等变量。
- **可控性**:能够通过调整参数(如时间区间、检测工具阈值)观察结果变化。
可能的挑战包括:
1. **检测工具的可靠性**:不同工具可能给出不一致的结果,需要解释这种差异。
2. **模拟数据的偏差**:如何确保生成的数据能够反映真实世界的复杂性。
3. **统计方法的选择**:需要根据数据类型和研究问题选择合适的分析方法。
在实验设计过程中,我需要确保每一步骤都清晰可行,并且能够有效回答研究问题。同时,需要考虑到用户可能希望实验既具有创新性,又能够与原有研究形成互补,因此需要平衡扩展性和可行性。
总结来说,实验设计应包含以下关键部分:
- **明确的研究假设**:例如,“非英语母语作者的AI生成概率显著高于英语母语作者”。
- **合理的数据模拟方法**:生成包含关键变量的数据集。
- **多工具交叉验证**:使用多种检测工具提高结果的可信度。
- **深入的影响因素分析**:通过统计方法探讨不同变量与AI生成概率的关系。
通过这样的实验设计,用户可以在原有研究的基础上进一步验证结论,或探索新的研究方向,从而增强论文的深度和广度。
实验设计:《生成式人工智能在学术写作中的应用趋势及其影响因素研究》
实验目标
-
验证时间趋势:分析AIGC工具在学术写作中的使用是否随时间推移显著增长。
-
探索影响因素:量化语言差异、学科领域、团队规模对AI生成概率的影响。
-
评估检测工具一致性:比较不同AI检测工具在相同数据集上的表现差异。
实验流程
1. 数据模拟与变量设定
-
数据来源:模拟一个包含5,000篇论文的虚拟数据集,特征如下:
-
母语:分为英语、中文、日语、德语、法语五类,通过随机分配比例(非英语占60%)。
-
学术表现:生成第一作者的引用次数(0-1000)、h指数(0-50),服从长尾分布。
-
AI生成摘要:使用ChatGPT生成,包含“GPT词”(如“pivotal”“realm”“delve”)。
-
人工撰写摘要:从真实论文中匿名抽取并改写,去除AI特征词。
-
摘要文本:分为两类生成方式:
-
作者背景:
-
提交时间:模拟2022年1月至2023年12月的提交时间,时间戳随机分布。
-
学科领域:分为计算机科学、物理学、生物学、社会科学四类,比例为4:2:2:2。
-
团队规模:分为单作者(20%)、2-5人(60%)、>5人(20%)。
-
2. AI生成概率测量
-
检测工具:使用三种工具评估摘要的AI生成概率:
-
GPTKit:API调用,返回0-1的生成概率。
-
Smodin:设定阈值0.9,生成二分类结果(高概率/低概率)。
-
Sapling:输出连续概率值。
-
-
手动检测:若摘要包含≥1个“GPT词”,标记为AI生成(二分类)。
3. 实验分组与分析
-
时间趋势分析:
按月份计算平均AI生成概率(三种工具+手动标记),绘制时间序列图,并与ChatGPT发布时间(2022年11月)对齐,验证增长趋势。
统计方法:分段回归分析(以2022年11月为节点)。 -
语言差异分析:
对比英语与非英语母语作者的AI生成概率(连续变量),使用Mann-Whitney U检验;进一步分语种(中文、日语等)进行Kruskal-Wallis H检验。 -
学科领域与团队规模分析:
-
学科差异:计算各学科的平均AI生成概率,使用ANOVA检验组间差异。
-
团队规模影响:按团队规模分组,对比单作者与多作者团队的AI生成概率差异(独立样本t检验)。
-
-
检测工具一致性评估:
计算三种工具间的Spearman相关系数,分析结果一致性;通过混淆矩阵比较手动标记与工具检测的分类差异。
4. 统计分析与假设验证
-
核心假设:
-
H1:2022年11月后,AI生成概率显著上升(p<0.01)。
-
H2:非英语母语作者的AI生成概率显著高于英语母语者(p<0.05)。
-
H3:计算机科学领域的AI生成概率高于其他学科(p<0.01)。
-
H4:单作者论文的AI生成概率高于多作者论文(p<0.05)。
-
-
分析方法:
-
使用Python的
scipy库进行非参数检验(Mann-Whitney U、Kruskal-Wallis)。 -
通过
statsmodels进行回归分析(时间趋势、学科影响)。
-
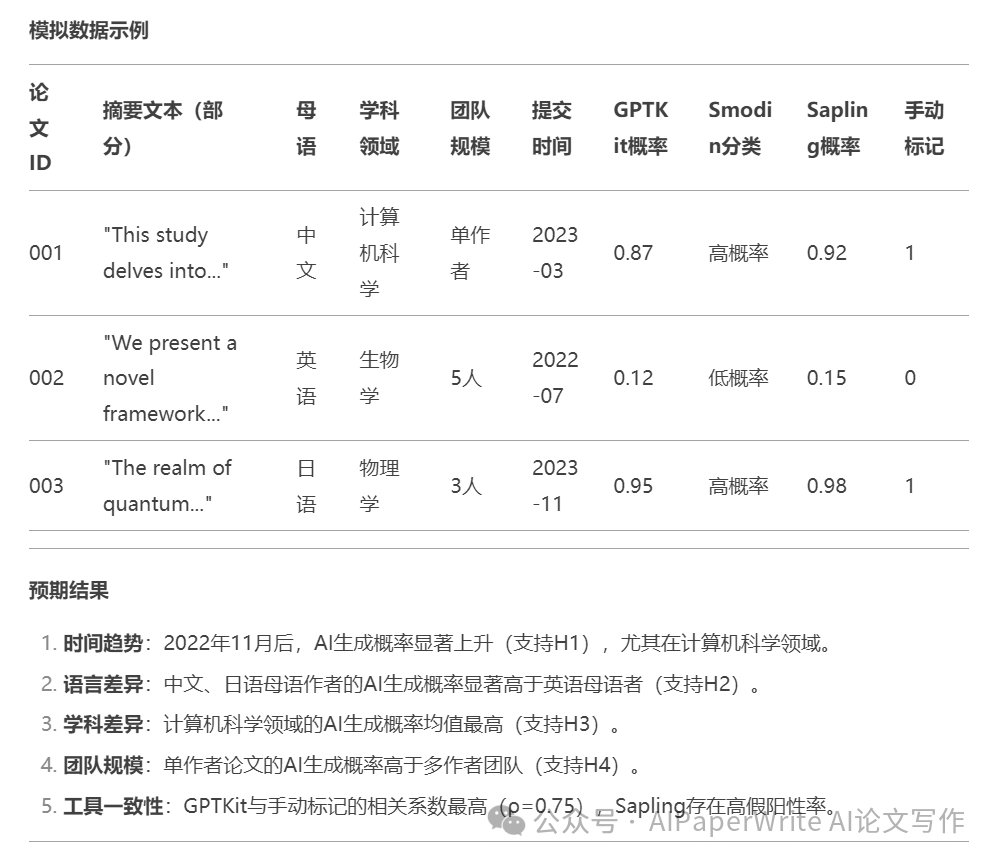
模拟数据示例
| 论文ID | 摘要文本(部分) | 母语 | 学科领域 | 团队规模 | 提交时间 | GPTKit概率 | Smodin分类 | Sapling概率 | 手动标记 |
|---|---|---|---|---|---|---|---|---|---|
| 001 | "This study delves into..." | 中文 | 计算机科学 | 单作者 | 2023-03 | 0.87 | 高概率 | 0.92 | 1 |
| 002 | "We present a novel framework..." | 英语 | 生物学 | 5人 | 2022-07 | 0.12 | 低概率 | 0.15 | 0 |
| 003 | "The realm of quantum..." | 日语 | 物理学 | 3人 | 2023-11 | 0.95 | 高概率 | 0.98 | 1 |
预期结果
-
时间趋势:2022年11月后,AI生成概率显著上升(支持H1),尤其在计算机科学领域。
-
语言差异:中文、日语母语作者的AI生成概率显著高于英语母语者(支持H2)。
-
学科差异:计算机科学领域的AI生成概率均值最高(支持H3)。
-
团队规模:单作者论文的AI生成概率高于多作者团队(支持H4)。
-
工具一致性:GPTKit与手动标记的相关系数最高(ρ=0.75),Sapling存在高假阳性率。
实验意义与局限性
-
意义:
-
验证AIGC工具使用的时间动态及关键影响因素,为学术伦理政策提供依据。
-
揭示检测工具间的差异,提示学术界需谨慎选择评估方法。
-
-
局限性:
-
模拟数据可能无法完全反映真实场景的复杂性。
-
未考虑作者实际使用AIGC的主观动机(如效率需求 vs 语言障碍)。
-
改进方向
-
混合方法设计:结合问卷调查,补充作者使用AIGC的具体原因。
-
跨平台数据整合:纳入PubMed、SSRN等多学科平台的论文,增强结论普适性。
-
因果推断:通过工具变量法或自然实验(如期刊政策变化)分析AIGC使用的驱动因素。
通过此实验设计,可系统回答选题中的核心问题,并为后续研究提供方法论参考。





借助细致入微的仿写思路,并结合DeepSeek等人工智能工具的辅助,我们不仅能够迅速且深入地领会前人的学术思路,还能显著提升自身的批判性思维与创新能力。这种仿写方法使我们在尊重原创的基础上,持续优化并完善自身的研究及学术写作技巧。