paper主要提出了在transformer中替代layer norm的方案,dynamic tanh函数,它是逐元素计算的,避免了layer norm在计算中需要计算channel整体的均值,方差,进行reduce和broad cast计算,天然并行,且硬件友好。
这篇论文专注于 Transformer 中的 LayerNorm 替代,不涉及 CNN 中使用的 BatchNorm 或其他归一化方法。DyT 的设计完全围绕“token 向量级别的标准化”,所以在 CNN 上并不适用。
先复习一下什么是layer norm.
Transformer 中输入通常是:[B, T, C]
B: batch size (样本数)
T: token个数(LLM中是词数,图像中是patch数)
C: channel, 在token中指的是向量维度,也就是embedding dim.
layer norm是对每个 token 的向量 [C] 做归一化,即对最后一个维度做均值/方差计算。
输入形状: [B, T, C]
LayerNorm 就是对每个 [x_t1, x_t2, ..., x_tC] 做归一化↑每个 token 的 channel 向量
layer norm原理:

下面进入DyT的介绍,也就是paper部分,然后讨论为什么DyT比layer norm更快。
Abstract
归一化层在现代神经网络中无处不在,长期以来被认为是不可或缺的。
本研究表明,即使不使用归一化层,Transformer 也能通过一种非常简单的技术达到相同甚至更好的性能。
我们提出了一种逐元素操作,称为 Dynamic Tanh(DyT),其形式为:
DyT(x)=tanh(αx)
它可直接替代 Transformer 中的归一化层。
DyT 的灵感来自这样一个观察:在 Transformer 中,LayerNorm 的输入输出关系常常呈现类似 tanh 的 S 形曲线。通过使用 DyT,不含归一化层的 Transformer 模型在各种任务和设置下都能达到甚至超越原有性能,且几乎无需调参。
Introduction
在过去十年中,归一化层已经成为现代神经网络中最基础的组成部分之一。这一切始于 2015 年提出的 Batch Normalization(BN),它显著加快并稳定了视觉识别模型的收敛,并迅速被各类模型采纳。此后,针对不同架构和领域,研究者又提出了许多归一化层的变体,比如:
LayerNorm(LN)
InstanceNorm
GroupNorm
RMSNorm 等
尤其是在 Transformer 架构中,LayerNorm 几乎成为了默认标准,广泛应用于 NLP、CV 和多模态任务中。
归一化层之所以被广泛使用,是因为它们在优化过程中带来了非常显著的经验性好处,比如:
更快收敛
更稳定训练过程
更高的最终性能
随着网络变得越来越深、越来越宽,归一化层显得尤为关键。几乎所有新提出的架构虽然不断尝试替代注意力机制或卷积层,但都保留了归一化层,这本身就说明了社区对其“不可替代性”的默认共识。
本研究提出:这个共识可能是 不必要的。
我们从一个直观出发:LN 层的输入输出之间的关系,常常像一个 tanh 函数——它将输入按比例缩放,并“压缩”那些极端的数值。
受此启发,我们提出了一个简单的替代方案:
Dynamic Tanh(DyT)
形式为:
DyT(x)=tanh(αx)
其中 α 是一个可学习的缩放参数
这个函数具备两个目标:
1.通过 α 学习合适的缩放比例(类似 LN 的标准差归一化)
2.通过 tanh 的有界性压缩极端值(类似 LN 对极值的处理)
它和传统归一化层最大的区别是:DyT 完全不依赖均值或方差的计算,因此也不需要统计操作。
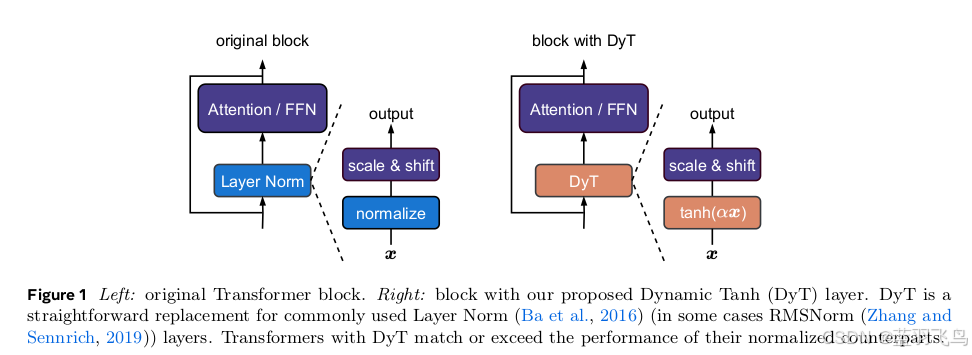
如图所示(图1):我们只需在 Transformer 架构中直接将 LayerNorm 或 RMSNorm 替换为 DyT,即可构建新的网络。
实验表明,使用 DyT 的 Transformer 在各种设置下都能:
稳定训练
达到和原模型类似甚至更好的最终性能
几乎不需要调超参数
归一化层为何看起来像 Tanh?
作者设计了一个实验:
在 ViT-Small(ViT-S)模型 上进行了训练,并在 ImageNet 上进行了标准训练流程(使用 LayerNorm)。
训练完成后,我们收集了训练集图像通过某一层 LayerNorm 的输入张量 x 和输出张量
y=LayerNorm(x)。
然后绘制了 x 与 y 的关系图。
想要看看 LN 的输入输出是否存在某种函数关系,特别是是否具有像 tanh 那样的 S 形结构。
从多个样本中提取出来的成千上万个 (x,y) 对进行绘图。
结果发现:
输出值整体分布在 [−2,2] 之间
和输入 x 的值形成一条平滑的 S 形曲线
随着 x 的绝对值增大,输出 y 趋于饱和(即边界附近变化不大)
和 tanh 曲线非常相似
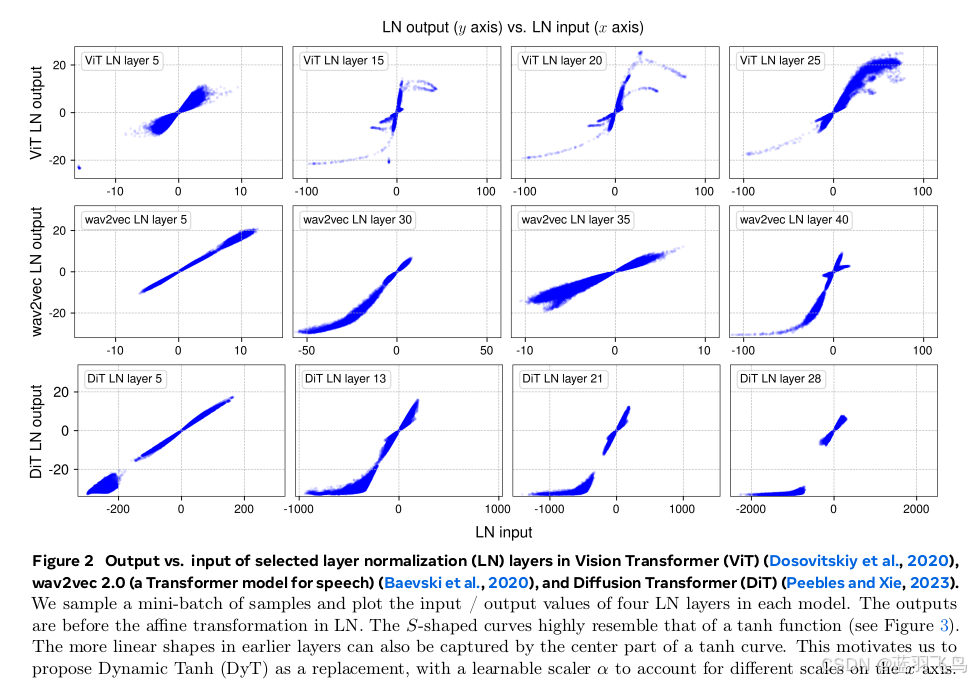
图中可以看到layer norm的输出不像ReLU那样是线性的,更像一种非线性压缩函数。
这个压缩行为可以通过 LayerNorm 的数学公式来解释:

即使没有可学习参数(即 γ=1,β=0),LayerNorm 的标准化部分也会将输入 x 压缩到标准正态分布附近。
这相当于一种“柔性”形式的值域限制,像 tanh 一样,将极值控制在一个有限范围内。
既然 LayerNorm 的作用和 tanh 的输出形态如此相似,我们是否可以用一个可学习参数 α 来控制 tanh 的缩放程度,从而近似模拟 LayerNorm 的作用?
于是我们提出:

结果发现,这个简单的函数就可以稳定训练 Transformer,而且在多个任务上能达到与 LayerNorm 相当甚至更好的效果。

当 α 较小时,tanh 函数近似于线性函数(保持信息流畅);
当 α 较大时,tanh 函数输出趋于饱和(起到“压缩极值”的作用);
因此,通过学习合适的 α,DyT 可以模仿 LayerNorm 的“柔性标准化”效果。
论文中默认使用的是 通道级 α(向量),即每个通道都有一个独立的可学习 α。
DyT 可以直接用于替代 Transformer 中所有的归一化层。
看下面的图:
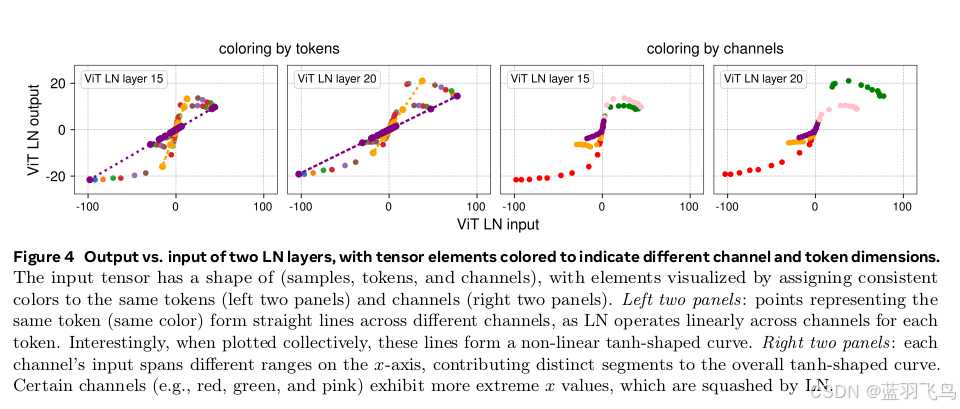
这4个小图是ViT 第 15 层 & 20 层 LayerNorm 输出 vs 输入。
左边两个小图是按token着色,每个颜色是一组 token,展示它在不同 channel 上的表现。
右边两个小图是按channel着色,每种颜色表示一个 channel(特征维度)。
横轴是输入 x,纵轴是输出 y=LayerNorm(x)
可以看到按token着色的情况是:
每个颜色的点 沿着一条直线排列,
因为 LayerNorm 是对每个 token(一个向量)做归一化 → 对该 token 的所有 channel 线性变换,
所以每个 token 被映射成一条直线。
但多个 token 的线条拼在一起时:
整体形成了一条弯曲的 “S 形”——类似 tanh 曲线,
说明 LayerNorm 整体的作用就像一个 “对不同 token 的线性函数集合”,它们一起构成非线性
按channel着色:
每个颜色是一个 channel
同一个 channel 会跨不同 token 取值
某些颜色(比如红、绿、粉)分布在输入值的极端位置(x 值很大)
但经过 LayerNorm 后,这些极端值都被压缩在 [-10, 10] 甚至更窄范围内
LayerNorm 起到了压缩极端值的作用
α \alpha α的初始化
我们发现,对 α 的初始值(记为 α₀)进行调节,在大多数任务中对性能影响不大。唯一的例外是大模型(LLM)训练,在这种情况下,精细调节 α₀ 会显著提升性能。
1.非LLM模型中 α \alpha α的初始化
非LLM模型对 α₀ 的设置不敏感。图9展示了在多个任务上调整 α₀ 的验证表现。所有实验都遵循各自公开训练配方中的原始超参数。我们观察到,在 α₀ ∈ [0.5, 1.2] 的范围内,模型性能都比较稳定。
调节 α₀ 通常只影响训练初期的收敛曲线。唯一的例外是 ViT-L 的有监督训练,当 α₀ > 0.6 时,训练变得不稳定甚至发散。在这种情况下,降低学习率可以恢复稳定性。
此外,我们进一步发现:
较小的 α₀ 更容易获得稳定训练
当模型尺寸变大,或者学习率变大时,也需要适当降低 α₀来避免不稳定
图10展示了在 ImageNet-1K 上训练 ViT 模型时,调节模型大小、学习率、α₀ 的稳定性表现。可以看到,模型越大越容易发散,需要较小的 α₀ 或学习率才能稳定训练。
2.LLM中的 α \alpha α的初始化
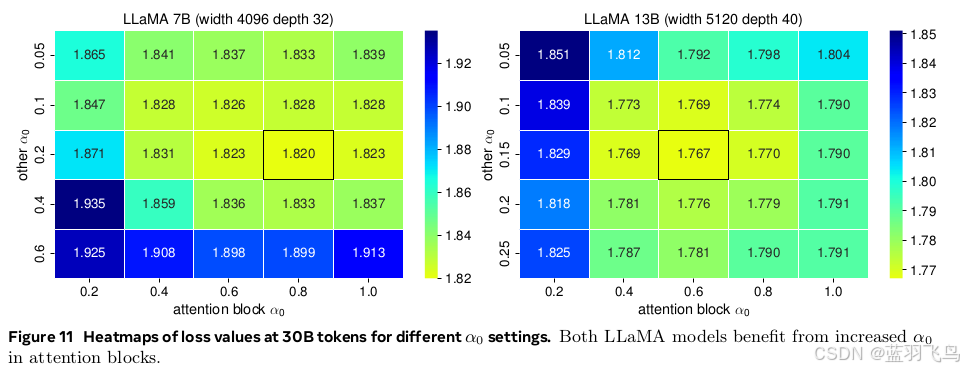
调节 α₀ 能显著提升性能。我们以 LLaMA 系列模型为例,在每个模型上用 30B token 做预训练,比较不同 α₀ 的训练损失,并得出两条核心结论:
1.模型越大,α₀ 越小

2.注意力层的 α₀ 应该更高
图11是热力图,展示了不同 α₀ 设置下 LLaMA 7B 和 13B 模型在训练30B token后的 loss。可以看到,在 attention 层设置较高 α₀,确实能显著降低训练损失。
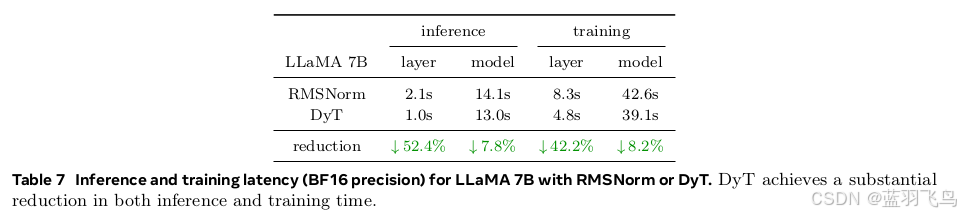
DyT 的计算效率
分别使用 RMSNorm 和 DyT,测量其在 推理(inference)和训练(training)阶段运行 100 次所需时间。
输入序列长度:4096
设备:NVIDIA H100 GPU,使用 BF16 精度
DyT 显著减少了单层计算时间,推理和训练整体也有明显加速,尤其适合效率导向的网络设计
替换或移除 tanh 的影响

移除 α 的影响

DyT伪代码
