介绍一:键值设计
一、优雅的key结构
Redis 的 Key 虽然可以自定义,但最好遵循下面的几个最佳实践约定:
- 遵循基本格式:[业务名称]:[数据名]:[id]
- 长度不超过 44 字节
- 不包含特殊字符
例如:
我们的登录业务,保存用户信息,其key可以设计成如下格式:
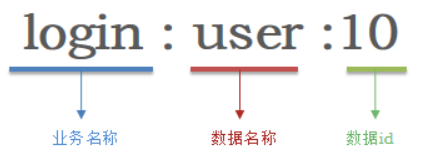
这样设计的好处:
- 可读性强
- 避免 key 冲突
- 方便管理
- 更节省内存
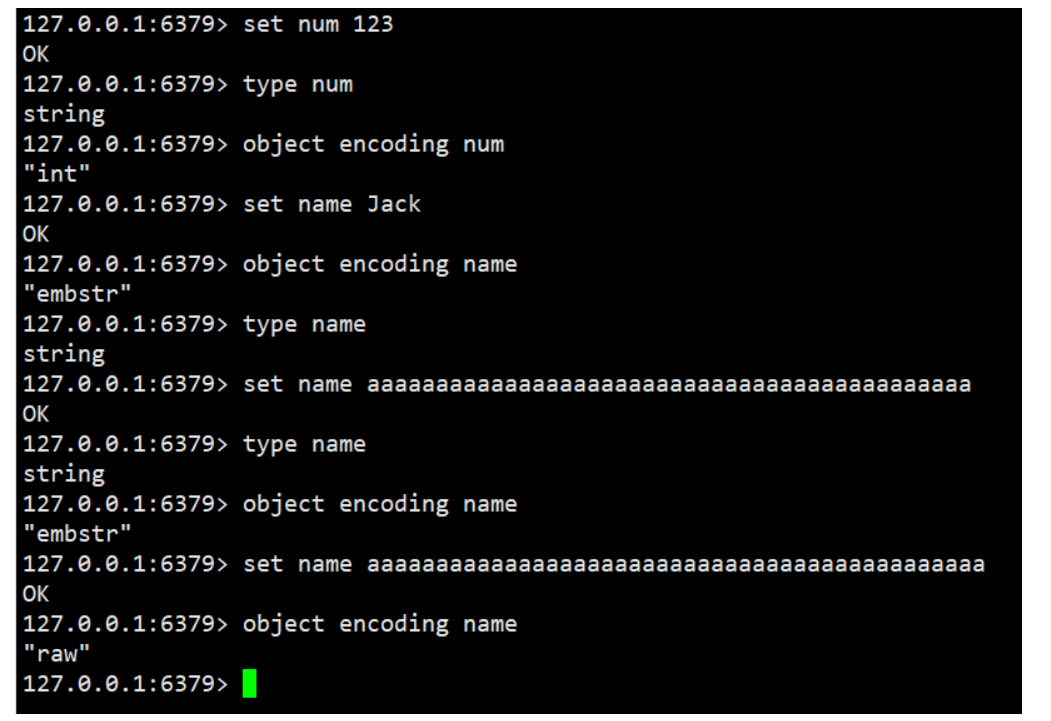
key 是 string 类型,底层编码包含 int、embstr 和 raw 三种。
embstr 在小于 44 字节使用,采用连续内存空间,内存占用更小。
当字节数大于 44 字节时,会转为 raw 模式存储,在 raw 模式下,内存空间不是连续的,
而是采用一个指针指向了另外一段内存空间,在这段空间里存储 SDS 内容,
这样空间不连续,访问的时候性能也就会收到影响,还有可能产生内存碎片
二、拒绝BigKey
BigKey 通常以 Key 的大小和 Key 中成员的数量来综合判定,例如:
- Key 本身的数据量过大:一个 String 类型的 Key,它的值为 5 MB
- Key 中的成员数过多:一个 ZSET 类型的 Key,它的成员数量为 10,000 个
- Key 中成员的数据量过大:一个 Hash 类型的 Key,它的成员数量虽然只有 1,000 个但这些成员的 Value(值)总大小为 100 MB
那么如何判断元素的大小呢?redis 也给我们提供了命令

推荐值:
- 单个 key 的 value 小于 10KB
- 对于集合类型的 key,建议元素数量小于 1000
1. BigKey的危害
1. 网络阻塞
对 BigKey 执行读请求时,少量的 QPS 就可能导致带宽使用率被占满,导致 Redis 实例,乃至所在物理机变慢
2. 数据倾斜
BigKey 所在的 Redis 实例内存使用率远超其他实例,无法使数据分片的内存资源达到均衡
3. Redis 阻塞
对元素较多的 hash、list、zset 等做运算会耗时较旧,使主线程被阻塞
4. CPU压力
对 BigKey 的数据序列化和反序列化会导致 CPU 的使用率飙升,影响 Redis 实例和本机其它应用
2. 如何发现BigKey
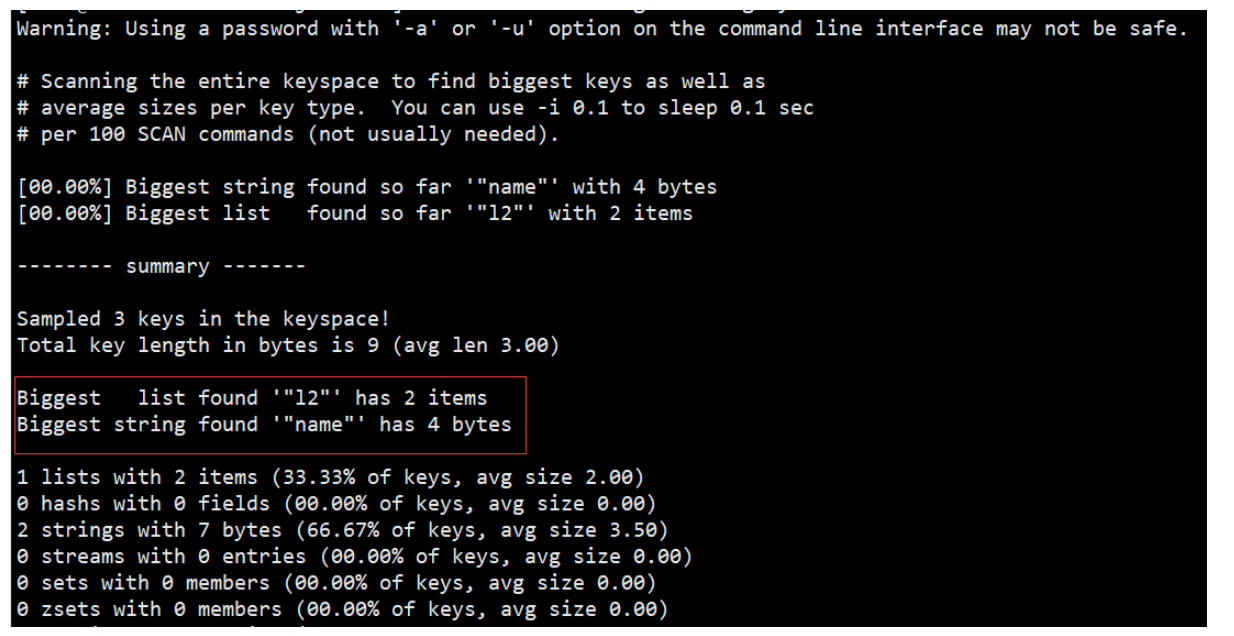
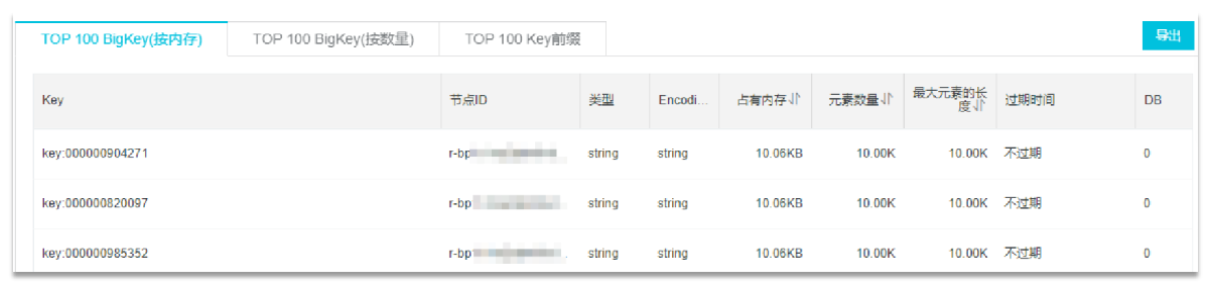
2.1. redis-cli --bigkeys
利用 redis-cli 提供的 --bigkeys 参数,可以遍历分析所有 key,并返回 Key 的整体统计信息与每个数据的 Top1
的 big key
命令:redis-cli -a 密码 --bigkeys

2.2. scan扫描
自己编程,利用 scan 扫描 Redis 中的所有 key,利用 strlen、hlen 等命令判断 key 的长度
(此处不建议使用 MEMORY USAGE)
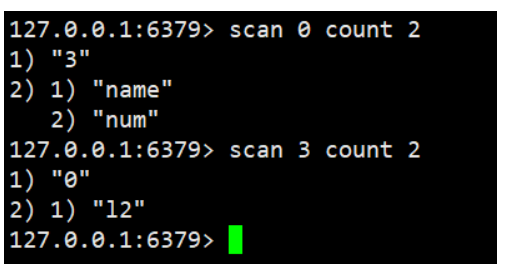
scan 命令调用完后每次会返回 2 个元素,第一个是下一次迭代的光标,第一次光标会设置为 0,当最后一次 scan 返回的光标等于 0 时,
表示整个 scan 遍历结束了,第二个返回的是 List,一个匹配的 key 的数组
import com.zhengge.jedis.util.JedisConnectionFactory;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.ScanResult;import java.util.HashMap;
import java.util.List;
import java.util.Map;public class JedisTest {private Jedis jedis;@BeforeEachvoid setUp() {// 1.建立连接// jedis = new Jedis("192.168.150.101", 6379);jedis = JedisConnectionFactory.getJedis();// 2.设置密码jedis.auth("123321");// 3.选择库jedis.select(0);}final static int STR_MAX_LEN = 10 * 1024;final static int HASH_MAX_LEN = 500;@Testvoid testScan() {int maxLen = 0;long len = 0;String cursor = "0";do {// 扫描并获取一部分keyScanResult<String> result = jedis.scan(cursor);// 记录cursorcursor = result.getCursor();List<String> list = result.getResult();if (list == null || list.isEmpty()) {break;}// 遍历for (String key : list) {// 判断key的类型String type = jedis.type(key);switch (type) {case "string":len = jedis.strlen(key);maxLen = STR_MAX_LEN;break;case "hash":len = jedis.hlen(key);maxLen = HASH_MAX_LEN;break;case "list":len = jedis.llen(key);maxLen = HASH_MAX_LEN;break;case "set":len = jedis.scard(key);maxLen = HASH_MAX_LEN;break;case "zset":len = jedis.zcard(key);maxLen = HASH_MAX_LEN;break;default:break;}if (len >= maxLen) {System.out.printf("Found big key : %s, type: %s, length or size: %d %n", key, type, len);}}} while (!cursor.equals("0"));}@AfterEachvoid tearDown() {if (jedis != null) {jedis.close();}}}2.3. 第三方工具
- 利用第三方工具,如 Redis-Rdb-Tools 分析 RDB 快照文件,全面分析内存使用情况
- GitHub - sripathikrishnan/redis-rdb-tools: Parse Redis dump.rdb files, Analyze Memory, and Export Data to JSON
2.4. 网络监控
- 自定义工具,监控进出Redis的网络数据,超出预警值时主动告警
- 一般阿里云搭建的云服务器就有相关监控页面
3. 如何删除BigKey
BigKey 内存占用较多,即便时删除这样的 key 也需要耗费很长时间,导致 Redis 主线程阻塞,引发一系列问题。
1、redis 3.0 及以下版本
如果是集合类型,则遍历 BigKey 的元素,先逐个删除子元素,最后删除 BigKey
2、Redis 4.0 以后
Redis 在 4.0 后提供了异步删除的命令:unlink
三、恰当的数据类型
例1
例1:比如存储一个User对象,我们有三种存储方式:
方式一:json字符串
| user:1 | {"name": "Jack", "age": 21} |
优点:实现简单粗暴
缺点:数据耦合,不够灵活
方式二:字段打散
| user:1:name | Jack |
| user:1:age | 21 |
优点:可以灵活访问对象任意字段
缺点:占用空间大、没办法做统一控制
方式三:hash(推荐)
| user:1 | name | jack |
| age | 21 |
优点:底层使用 ziplist,空间占用小,可以灵活访问对象的任意字段
缺点:代码相对复杂
例2
例2:假如有hash类型的key,其中有100万对field和value,field是自增id,这个key存在什么问题?如何优化?
| key | field | value |
| someKey | id:0 | value0 |
| ..... | ..... | |
| id:999999 | value999999 |
存在的问题:
- hash 的 entry 数量超过 500 时,会使用哈希表而不是 ZipList,内存占用较多
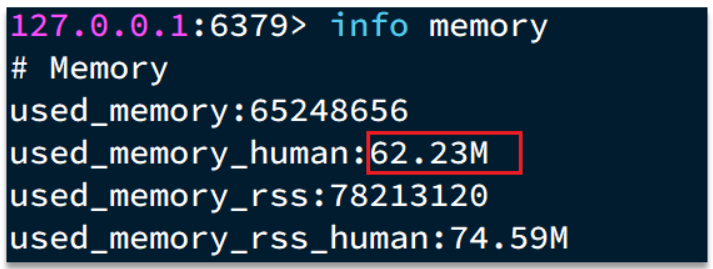
- 可以通过 hash-max-ziplist-entries 配置 entry 上限。但是如果 entry 过多就会导致 BigKey 问题
方案一
拆分为string类型
| key | value |
| id:0 | value0 |
| ..... | ..... |
| id:999999 | value999999 |
存在的问题:
- string 结构底层没有太多内存优化,内存占用较多
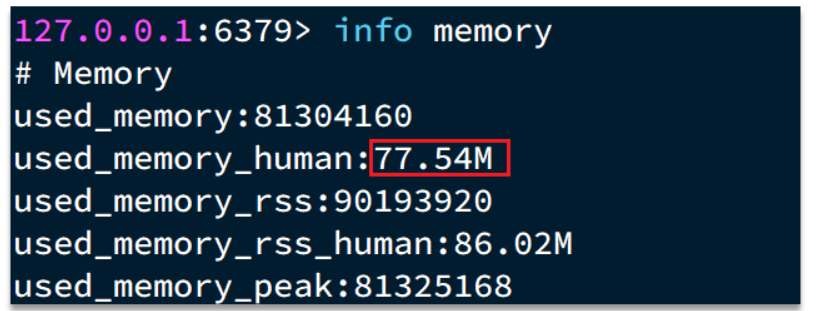
- 想要批量获取这些数据比较麻烦
方案二
拆分为小的 hash,将 id / 100 作为 key, 将 id % 100 作为 field,这样每 100 个元素为一个 Hash
| key | field | value |
| key:0 | id:00 | value0 |
| ..... | ..... | |
| id:99 | value99 | |
| key:1 | id:00 | value100 |
| ..... | ..... | |
| id:99 | value199 | |
| .... | ||
| key:9999 | id:00 | value999900 |
| ..... | ..... | |
| id:99 | value999999 | |
package com.zhengge.test;import com.project.jedis.util.JedisConnectionFactory;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.Pipeline;
import redis.clients.jedis.ScanResult;import java.util.HashMap;
import java.util.List;
import java.util.Map;public class JedisTest {private Jedis jedis;@BeforeEachvoid setUp() {// 1.建立连接// jedis = new Jedis("192.168.150.101", 6379);jedis = JedisConnectionFactory.getJedis();// 2.设置密码jedis.auth("123321");// 3.选择库jedis.select(0);}@Testvoid testSetBigKey() {Map<String, String> map = new HashMap<>();for (int i = 1; i <= 650; i++) {map.put("hello_" + i, "world!");}jedis.hmset("m2", map);}@Testvoid testBigHash() {Map<String, String> map = new HashMap<>();for (int i = 1; i <= 100000; i++) {map.put("key_" + i, "value_" + i);}jedis.hmset("test:big:hash", map);}@Testvoid testBigString() {for (int i = 1; i <= 100000; i++) {jedis.set("test:str:key_" + i, "value_" + i);}}@Testvoid testSmallHash() {int hashSize = 100;Map<String, String> map = new HashMap<>(hashSize);for (int i = 1; i <= 100000; i++) {int k = (i - 1) / hashSize;int v = i % hashSize;map.put("key_" + v, "value_" + v);if (v == 0) {jedis.hmset("test:small:hash_" + k, map);}}}@AfterEachvoid tearDown() {if (jedis != null) {jedis.close();}}
}四、知识小结
1. Key的最佳实践
- 固定格式:[业务名]:[数据名]:[id
- 足够简短:不超过 44 字节
- 不包含特殊字符
2. Value的最佳实践
- 合理的拆分数据,拒绝 BigKey
- 选择合适数据结构
- Hash 结构的 entry 数量不要超过 1000
- 设置合理的超时时间
介绍二:批处理优化
一、Pipeline
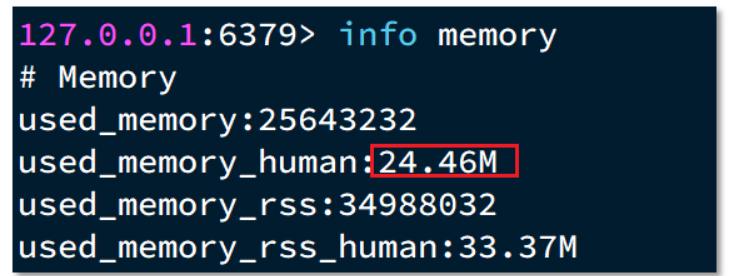
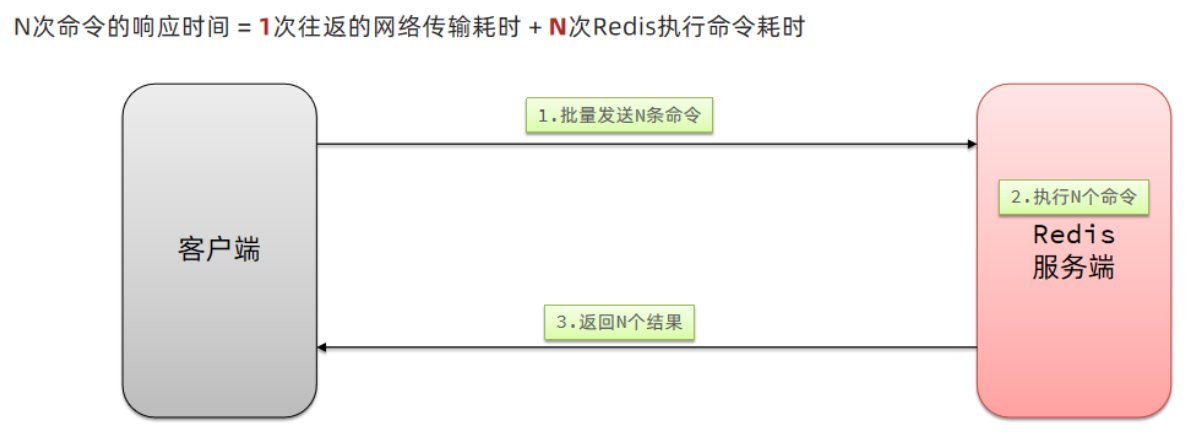
1. 我们的客户端与redis服务器是这样交互的
单个命令的执行流程

N 条命令的执行流程

redis 处理指令是很快的,主要花费的时候在于网络传输。于是乎很容易想到将多条指令批量的传输给 redis
2. MSet
Redis 提供了很多 Mxxx 这样的命令,可以实现批量插入数据,例如:
- mset
- hmset
利用 mset 批量插入 10 万条数据
@Test
void testMxx() {String[] arr = new String[2000];int j;long b = System.currentTimeMillis();for (int i = 1; i <= 100000; i++) {j = (i % 1000) << 1;arr[j] = "test:key_" + i;arr[j + 1] = "value_" + i;if (j == 0) {jedis.mset(arr);}}long e = System.currentTimeMillis();System.out.println("time: " + (e - b));
}3. Pipeline
MSET 虽然可以批处理,但是却只能操作部分数据类型,因此如果有对复杂数据类型的批处理需要,建议使用
Pipeline
@Test
void testPipeline() {// 创建管道Pipeline pipeline = jedis.pipelined();long b = System.currentTimeMillis();for (int i = 1; i <= 100000; i++) {// 放入命令到管道pipeline.set("test:key_" + i, "value_" + i);if (i % 1000 == 0) {// 每放入1000条命令,批量执行pipeline.sync();}}long e = System.currentTimeMillis();System.out.println("time: " + (e - b));
}二、集群下的批处理
如 MSET 或 Pipeline 这样的批处理需要在一次请求中携带多条命令,而此时如果 Redis 是一个集群,那批处理命
令的多个 key 必须落在一个插槽中,否则就会导致执行失败。大家可以想一想这样的要求其实很难实现,因为我
们在批处理时,可能一次要插入很多条数据,这些数据很有可能不会都落在相同的节点上,这就会导致报错了
这个时候,我们可以找到 4 种解决方案
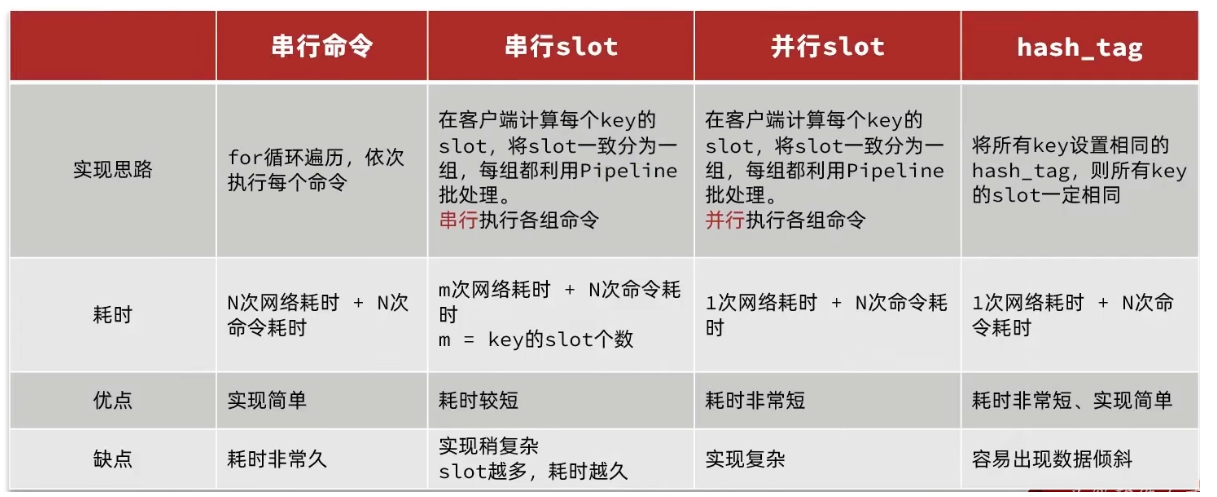
第一种方案:串行执行,所以这种方式没有什么意义,当然,执行起来就很简单了,缺点就是耗时过久。
第二种方案:串行 slot,简单来说,就是执行前,客户端先计算一下对应的 key 的 slot,一样 slot 的 key 就放到
一个组里边,不同的,就放到不同的组里边,然后对每个组执行 pipeline 的批处理,他就能串行执行各个组的命
令,这种做法比第一种方法耗时要少,但是缺点呢,相对来说复杂一点,所以这种方案还需要优化一下
第三种方案:并行 slot,相较于第二种方案,在分组完成后串行执行,第三种方案,就变成了并行执行各个命
令,所以他的耗时就非常短,但是实现呢,也更加复杂。
第四种:hash_tag,redis 计算 key 的 slot 的时候,其实是根据 key 的有效部分来计算的,通过这种方式就能一
次处理所有的 key,这种方式耗时最短,实现也简单,但是如果通过操作 key 的有效部分,那么就会导致所有的
key 都落在一个节点上,产生数据倾斜的问题,所以,我们推荐使用第三种方式。
1. 串行化执行代码实践
public class JedisClusterTest {private JedisCluster jedisCluster;@BeforeEachvoid setUp() {// 配置连接池JedisPoolConfig poolConfig = new JedisPoolConfig();poolConfig.setMaxTotal(8);poolConfig.setMaxIdle(8);poolConfig.setMinIdle(0);poolConfig.setMaxWaitMillis(1000);HashSet<HostAndPort> nodes = new HashSet<>();nodes.add(new HostAndPort("192.168.150.101", 7001));nodes.add(new HostAndPort("192.168.150.101", 7002));nodes.add(new HostAndPort("192.168.150.101", 7003));nodes.add(new HostAndPort("192.168.150.101", 8001));nodes.add(new HostAndPort("192.168.150.101", 8002));nodes.add(new HostAndPort("192.168.150.101", 8003));jedisCluster = new JedisCluster(nodes, poolConfig);}@Testvoid testMSet() {jedisCluster.mset("name", "Jack", "age", "21", "sex", "male");}@Testvoid testMSet2() {Map<String, String> map = new HashMap<>(3);map.put("name", "Jack");map.put("age", "21");map.put("sex", "Male");//对Map数据进行分组。根据相同的slot放在一个分组//key就是slot,value就是一个组Map<Integer, List<Map.Entry<String, String>>> result = map.entrySet().stream().collect(Collectors.groupingBy(entry -> ClusterSlotHashUtil.calculateSlot(entry.getKey())));//串行的去执行mset的逻辑for (List<Map.Entry<String, String>> list : result.values()) {String[] arr = new String[list.size() * 2];int j = 0;for (int i = 0; i < list.size(); i++) {j = i<<2;Map.Entry<String, String> e = list.get(0);arr[j] = e.getKey();arr[j + 1] = e.getValue();}jedisCluster.mset(arr);}}@AfterEachvoid tearDown() {if (jedisCluster != null) {jedisCluster.close();}}
}2. Spring集群环境下批处理代码
@Testvoid testMSetInCluster() {Map<String, String> map = new HashMap<>(3);map.put("name", "Rose");map.put("age", "21");map.put("sex", "Female");stringRedisTemplate.opsForValue().multiSet(map);List<String> strings = stringRedisTemplate.opsForValue().multiGet(Arrays.asList("name", "age", "sex"));strings.forEach(System.out::println);}原理分析
在 RedisAdvancedClusterAsyncCommandsImpl 类中,首先根据 slotHash 算出来一个 partitioned 的 map,
map 中的 key 就是 slot,而他的 value 就是对应的对应相同 slot 的 key 对应的数据
通过 RedisFuture mset = super.mset(op); 进行异步的消息发送
@Override
public RedisFuture<String> mset(Map<K, V> map) {Map<Integer, List<K>> partitioned = SlotHash.partition(codec, map.keySet());if (partitioned.size() < 2) {return super.mset(map);}Map<Integer, RedisFuture<String>> executions = new HashMap<>();for (Map.Entry<Integer, List<K>> entry : partitioned.entrySet()) {Map<K, V> op = new HashMap<>();entry.getValue().forEach(k -> op.put(k, map.get(k)));RedisFuture<String> mset = super.mset(op);executions.put(entry.getKey(), mset);}return MultiNodeExecution.firstOfAsync(executions);
}介绍三:服务器端优化
一、持久化配置
Redis的持久化虽然可以保证数据安全,但也会带来很多额外的开销,因此持久化请遵循下列建议:
- 用来做缓存的 Redis 实例尽量不要开启持久化功能
- 建议关闭 RDB 持久化功能,使用 AOF 持久化
- 利用脚本定期在 slave 节点做 RDB,实现数据备份
- 设置合理的 rewrite 阈值,避免频繁的 bgrewrite
- 配置 no-appendfsync-on-rewrite = yes,禁止在 rewrite 期间做 aof,避免因 AOF 引起的阻塞
部署有关建议:
- Redis 实例的物理机要预留足够内存,应对 fork 和 rewrite
- 单个 Redis 实例内存上限不要太大,例如 4G 或 8G 。可以加快 fork 的速度、减少主从同步、数据迁移压力。
- 不要与 CPU 密集型应用部署在一起
- 不要与高硬盘负载应用一起部署。例如:数据库、消息队列
二、慢查询优化
1. 什么是慢查询
并不是很慢的查询才是慢查询,而是:在Redis执行时耗时超过某个阈值的命令,称为慢查询。
慢查询的危害:由于Redis是单线程的,所以当客户端发出指令后,他们都会进入到redis底层的queue来执行,如
果此时有一些慢查询的数据,就会导致大量请求阻塞,从而引起报错,所以我们需要解决慢查询问题。
慢查询的阈值可以通过配置指定:
slowlog-log-slower-than:慢查询阈值,单位是微秒。默认是10000,建议1000
慢查询会被放入慢查询日志中,日志的长度有上限,可以通过配置指定:
slowlog-max-len:慢查询日志(本质是一个队列)的长度。默认是128,建议1000
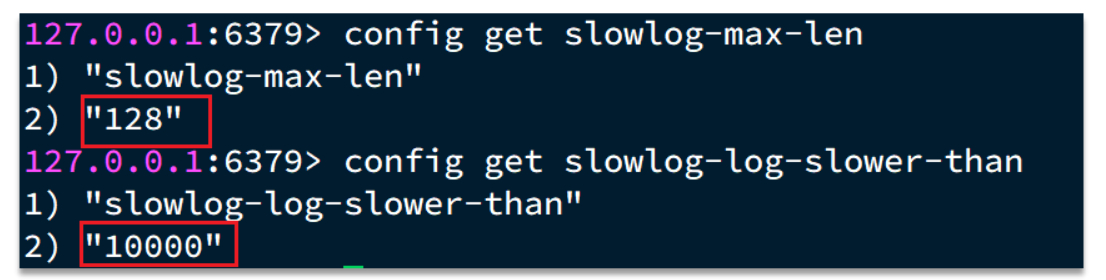
修改这两个配置可以使用:config set命令:

2. 如何查看慢查询
知道了以上内容之后,那么咱们如何去查看慢查询日志列表呢:
- slowlog len:查询慢查询日志长度
- slowlog get [n]:读取n条慢查询日志
- slowlog reset:清空慢查询列表
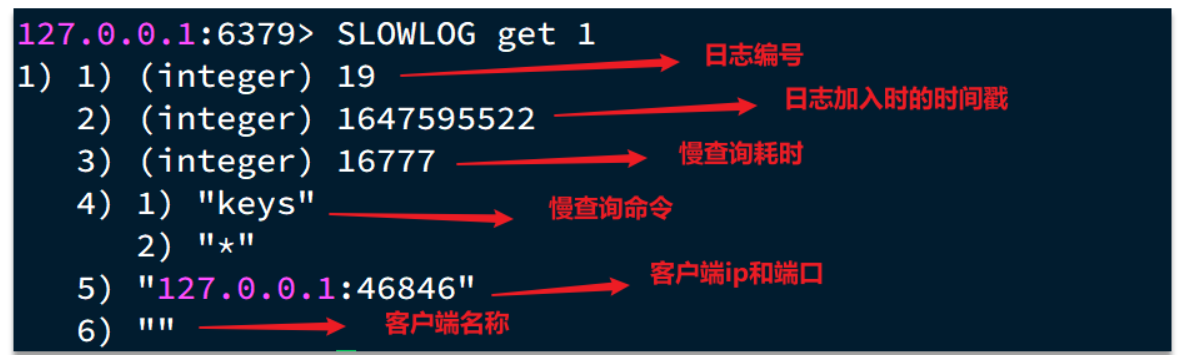
三、命令及安全配置
安全可以说是服务器端一个非常重要的话题,如果安全出现了问题,那么一旦这个漏洞被一些坏人知道了之后,
并且进行攻击,那么这就会给咱们的系统带来很多的损失,所以我们这节课就来解决这个问题。
Redis会绑定在0.0.0.0:6379,这样将会将Redis服务暴露到公网上,而Redis如果没有做身份认证,会出现严重的
安全漏洞。
漏洞重现方式:Redis未授权访问配合SSH key文件利用分析-腾讯云开发者社区-腾讯云
为什么会出现不需要密码也能够登录呢,主要是 Redis 考虑到每次登录都比较麻烦,所以 Redis 就有一种 ssh 免
秘钥登录的方式,生成一对公钥和私钥,私钥放在本地,公钥放在redis端,当我们登录时服务器,再登录时候,
他会去解析公钥和私钥,如果没有问题,则不需要利用 redis 的登录也能访问,这种做法本身也很常见,但是这里
有一个前提,前提就是公钥必须保存在服务器上,才行,但是 Redis 的漏洞,由于在不登录的情况下,也能把秘
钥送到 Linux 服务器,从而产生漏洞
漏洞出现的核心的原因有以下几点:
Redis 未设置密码
- 利用了 Redis 的 config set 命令动态修改 Redis 配置
- 使用了 Root 账号权限启动 Redis
所以:如何解决呢?我们可以采用如下几种方案
为了避免这样的漏洞,这里给出一些建议:
- Redis 一定要设置密码
- 禁止线上使用下面命令:keys、flushall、flushdb、config set等命令。
可以利用 rename-command 禁用。
- bind:限制网卡,禁止外网网卡访问
- 开启防火墙
- 不要使用 Root 账户启动 Redis
- 尽量不是有默认的端口
四、Redis内存划分和内存配置
当 Redis 内存不足时,可能导致 Key 频繁被删除、响应时间变长、QPS 不稳定等问题。当内存使用率达到90%
以上时就需要我们警惕,并快速定位到内存占用的原因。
1. 有关碎片问题分析
Redis 底层分配并不是这个 key 有多大,他就会分配多大,而是有他自己的分配策略,比如 8,16,20 等等,假定
当前 key 只需要 10 个字节,此时分配 8 肯定不够,那么他就会分配 16 个字节,多出来的 6 个字节就不能被使
用,这就是我们常说的碎片问题
2. 进程内存问题分析
这片内存,通常我们都可以忽略不计
3. 缓冲区内存问题分析
一般包括客户端缓冲区、AOF 缓冲区、复制缓冲区等。客户端缓冲区又包括输入缓冲区和输出缓冲区两种。这部
分内存占用波动较大,所以这片内存也是我们需要重点分析的内存问题。
| 内存占用 | 说明 |
| 数据内存 | 是Redis最主要的部分,存储Redis的键值信息。主要问题是BigKey问题、内存碎片问题 |
| 进程内存 | Redis主进程本身运⾏肯定需要占⽤内存,如代码、常量池等等;这部分内存⼤约⼏兆,在⼤多数⽣产环境中与Redis数据占⽤的内存相⽐可以忽略。 |
| 缓冲区内存 | 一般包括客户端缓冲区、AOF缓冲区、复制缓冲区等。客户端缓冲区又包括输入缓冲区和输出缓冲区两种。这部分内存占用波动较大,不当使用BigKey,可能导致内存溢出。 |
于是我们就需要通过一些命令,可以查看到 Redis 目前的内存分配状态:
1. info memory:查看内存分配的情况
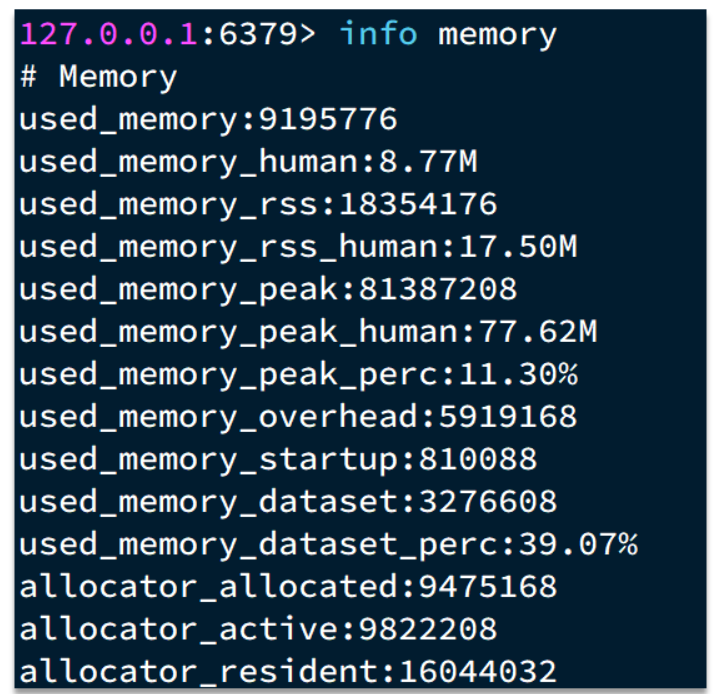
2. memory xxx:查看 key 的主要占用情况

接下来我们看到了这些配置,最关键的缓存区内存如何定位和解决呢?
内存缓冲区常见的有三种:
- 复制缓冲区:主从复制的 repl_backlog_buf,如果太小可能导致频繁的全量复制,影响性能。通过 replbacklog-size 来设置,默认1mb
- AOF缓冲区:AOF 刷盘之前的缓存区域,AOF 执行 rewrite 的缓冲区。无法设置容量上限
- 客户端缓冲区:分为输入缓冲区和输出缓冲区,输入缓冲区最大 1G 且不能设置。输出缓冲区可以设置
以上复制缓冲区和 AOF 缓冲区 不会有问题,最关键就是客户端缓冲区的问题
客户端缓冲区:指的就是我们发送命令时,客户端用来缓存命令的一个缓冲区,也就是我们向 redis 输入数据的输
入端缓冲区和 redis 向客户端返回数据的响应缓存区,输入缓冲区最大 1G 且不能设置,所以这一块我们根本不用
担心,如果超过了这个空间,redis 会直接断开,因为本来此时此刻就代表着 redis 处理不过来了,我们需要担心
的就是输出端缓冲区
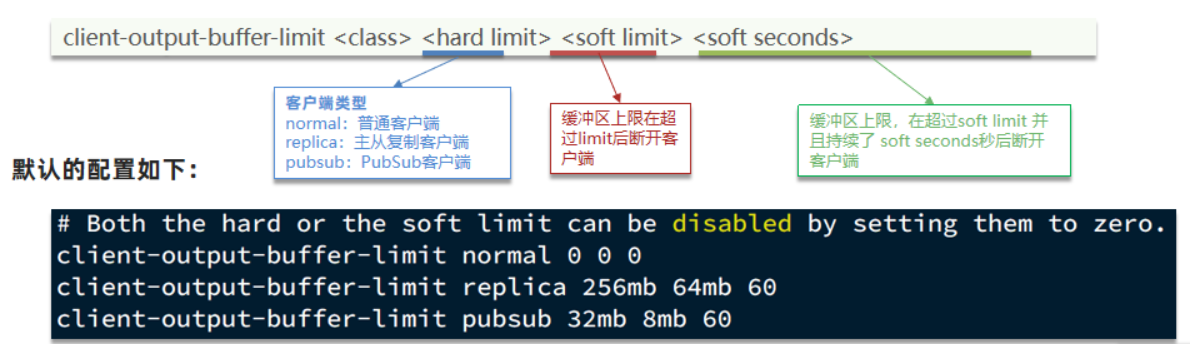
我们在使用 redis 过程中,处理大量的 big value,那么会导致我们的输出结果过多,如果输出缓存区过大,会导
致 redis 直接断开,而默认配置的情况下, 其实他是没有大小的,这就比较坑了,内存可能一下子被占满,会直
接导致咱们的 redis 断开,所以解决方案有两个
- 设置一个大小
- 增加我们带宽的大小,避免我们出现大量数据从而直接超过了 redis 的承受能力
介绍四:服务端集群优化(集群还是主从)
集群虽然具备高可用特性,能实现自动故障恢复,但是如果使用不当,也会存在一些问题:
- 集群完整性问题
- 集群带宽问题
- 数据倾斜问题
- 客户端性能问题
- 命令的集群兼容性问题
- lua 和事务问题
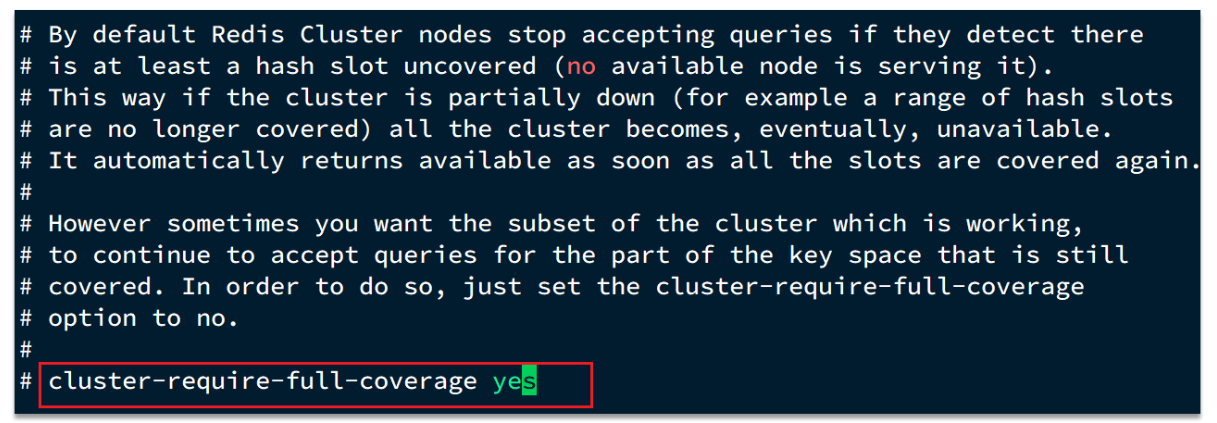
问题1:在 Redis 的默认配置中,如果发现任意一个插槽不可用,则整个集群都会停止对外服务:
大家可以设想一下,如果有几个 slot 不能使用,那么此时整个集群都不能用了,我们在开发中,其实最重要的是
可用性,所以需要把如下配置修改成 no,即有 slot 不能使用时,我们的 redis 集群还是可以对外提供服务
问题2:集群带宽问题
集群节点之间会不断的互相 Ping 来确定集群中其它节点的状态。每次 Ping 携带的信息至少包括:
- 插槽信息
- 集群状态信息
集群中节点越多,集群状态信息数据量也越大,10 个节点的相关信息可能达到 1kb,此时每次集群互通需要的带
宽会非常高,这样会导致集群中大量的带宽都会被 ping 信息所占用,这是一个非常可怕的问题,所以我们需要去
解决这样的问题
解决途径:
- 避免大集群,集群节点数不要太多,最好少于 1000,如果业务庞大,则建立多个集群。
- 避免在单个物理机中运行太多Redis实例
- 配置合适的 cluster-node-timeout 值
问题3:命令的集群兼容性问题
有关这个问题咱们已经探讨过了,当我们使用批处理的命令时,redis 要求我们的 key 必须落在相同的 slot 上,
然后大量的 key 同时操作时,是无法完成的,所以客户端必须要对这样的数据进行处理,这些方案我们之前已经
探讨过了,所以不再这个地方赘述了。
问题4:lua和事务的问题
lua 和事务都是要保证原子性问题,如果你的 key 不在一个节点,那么是无法保证 lua 的执行和事务的特性的,所
以在集群模式是没有办法执行 lua 和事务的
那我们到底是集群还是主从
单体 Redis(主从 Redis )已经能达到万级别的 QPS,并且也具备很强的高可用特性。如果主从能满足业务需求
的情况下,所以如果不是在万不得已的情况下,尽量不搭建 Redis 集群