因为Django具有很强的可扩展性 , 所以延伸了第三方功能应用 .
通过本章的学习 , 读者能够在网站开发过程中快速实现API接口开发 , 验证码生成与使用 , 站内搜索引擎 ,
第三方网站实现用户注册 , 异步任务和定时任务 , 即时通信等功能 .
API接口简称API , 它与网站路由的实现原理相同 .
当用户使用GET或者POST方式访问API时 , API以JSON或字符串的数据内容返回给用户 ,
网站的路由返回的是HTML网页信息 , 这与API返回的数据格式有所不同 .
开发网站的API可以在视图函数中使用响应类JsonResponse实现 , 它将字典格式的数据作为响应内容 .
使用响应类JsonResponse开发API需要根据用户请求信息构建字典格式的数据内容 ,
数据构建的过程可能涉及模型的数据查询 , 数据分页处理等业务逻辑 , 这种方式开发API很容易造成代码冗余 , 不利于功能的变更和维护 . 为了简化API的开发过程 , 我们可以使用Django Rest Framework框架实现API开发 .
使用框架开发不仅能减少代码冗余 , 还可以规范代码的编写格式 ,
这对企业级开发来说很有必要 , 毕竟每个开发人员的编程风格存在一定的差异 , 开发规范化可以方便其他开发人员查看和修改 .
在使用Django Rest Framework之前 , 首先安装Django Rest Framework框架 ,
建议使用pip完成安装 , 安装指令如下 : pip install djangorestframework .
清华源 : pip install -i https : / / pypi . tuna . tsinghua . edu . cn / simple djangorestframework .
框架安装成功后 , 通过简单的例子来讲述如何在Django中配置Django Rest Framework的功能 .
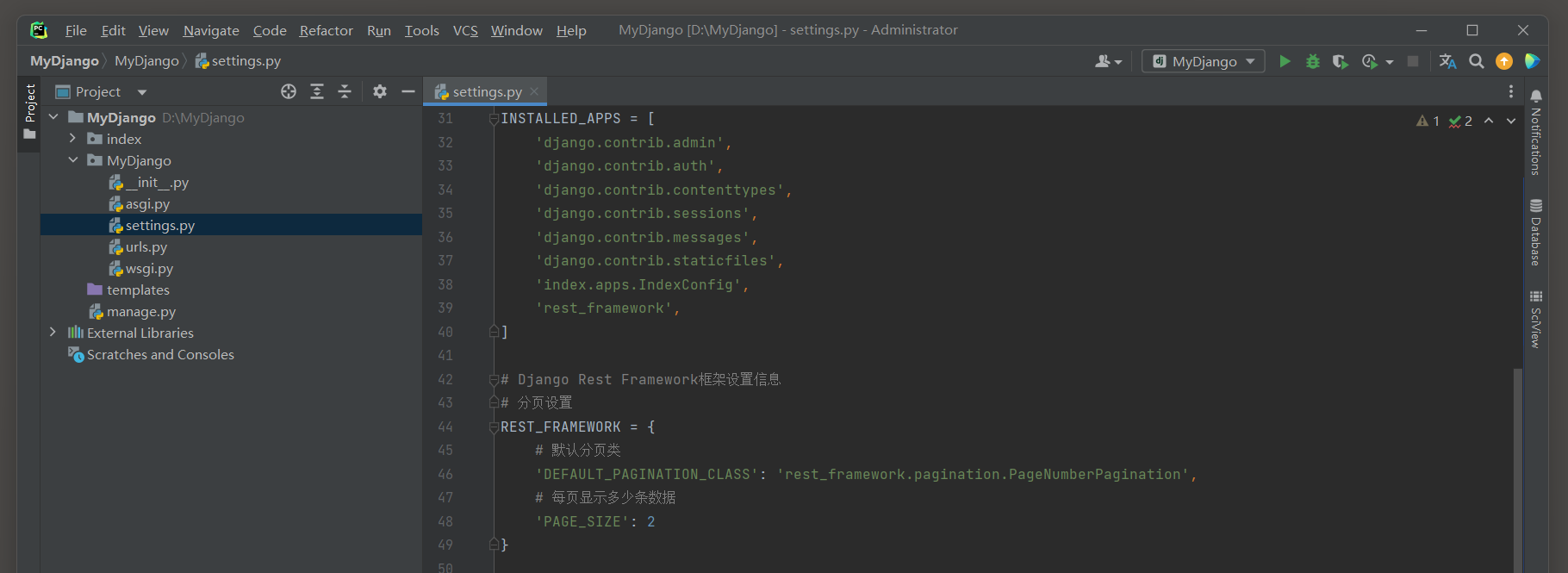
以MyDjango为例 , 首先在MyDjango的settings . py中设置功能配置 , 功能配置如下 :
INSTALLED_APPS = [ 'django.contrib.admin' , 'django.contrib.auth' , 'django.contrib.contenttypes' , 'django.contrib.sessions' , 'django.contrib.messages' , 'django.contrib.staticfiles' , 'index' , 'rest_framework'
] INSTALLED_APPS = [ 'django.contrib.admin' , 'django.contrib.auth' , 'django.contrib.contenttypes' , 'django.contrib.sessions' , 'django.contrib.messages' , 'django.contrib.staticfiles' , 'index.apps.IndexConfig' , 'rest_framework' ,
]
REST_FRAMEWORK = { 'DEFAULT_PAGINATION_CLASS' : 'rest_framework.pagination.PageNumberPagination' , 'PAGE_SIZE' : 2
}
上述配置信息用于实现Django Rest Framework的功能配置 , 配置说明如下 :
( 1 ) 在INSTALLED_APPS中添加API框架的功能配置 , 这样能使Django在运行过程中自动加载Django Rest Framework的功能 .
( 2 ) 配置属性REST_FRAMEWORK以字典的形式表示 , 用于设置Django Rest Framework的分页功能 .
完成settings . py的配置后 , 下一步定义项目的数据模型 .
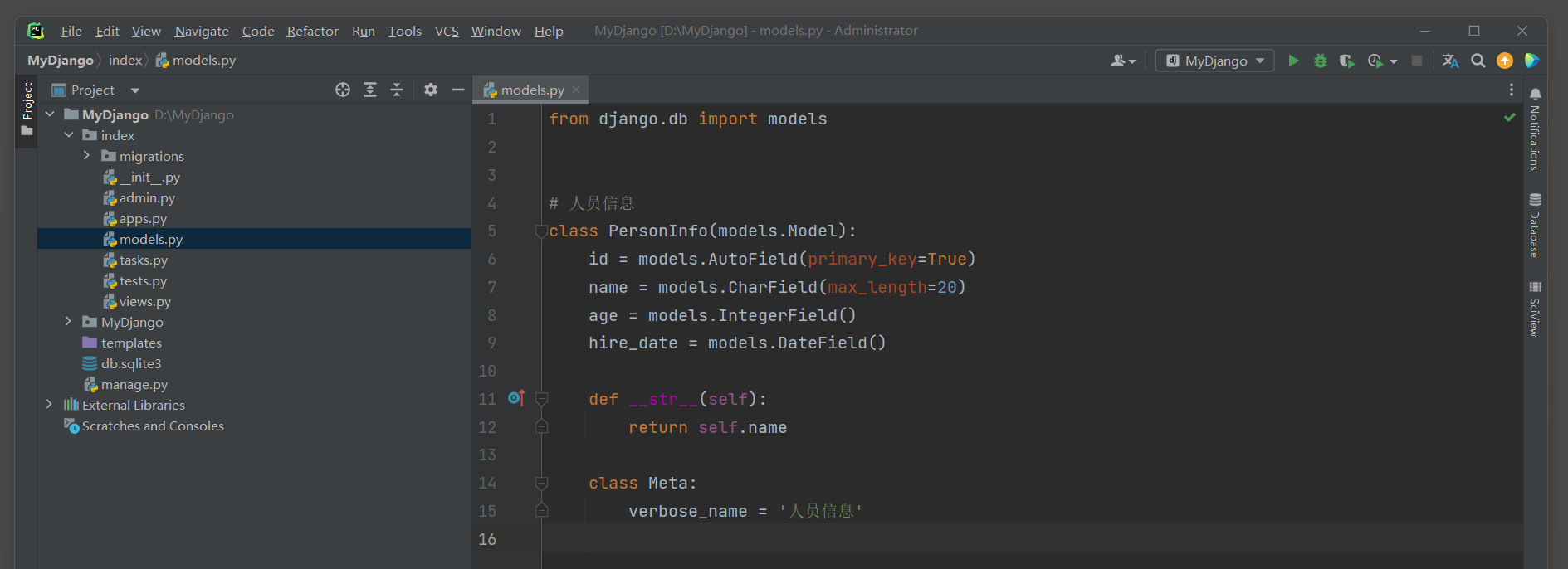
在index的models . py中分别定义模型PersonInfo和Vocation , 代码如下 :
from django. db import models
class PersonInfo ( models. Model) : id = models. AutoField( primary_key= True ) name = models. CharField( max_length= 20 ) age = models. IntegerField( ) hire_date = models. DateField( ) def __str__ ( self) : return self. nameclass Meta : verbose_name = '人员信息'
class Vocation ( models. Model) : id = models. AutoField( primary_key= True ) job = models. CharField( max_length= 20 ) title = models. CharField( max_length= 20 ) salary = models. IntegerField( null= True , blank= True ) person_id = models. ForeignKey( PersonInfo, on_delete= models. Case) def __str__ ( self) : return self. id class Meta : verbose_name = '职业信息' 将定义好的模型执行数据迁移 , 在项目的db . sqlite3数据库文件中生成数据表 .
PS D: \MyDjango> python manage. py makemigrations
Migrations for 'index' : index\migrations\0001_initial. py- Create model PersonInfo- Create model Vocation
PS D: \MyDjango> python manage. py migrate
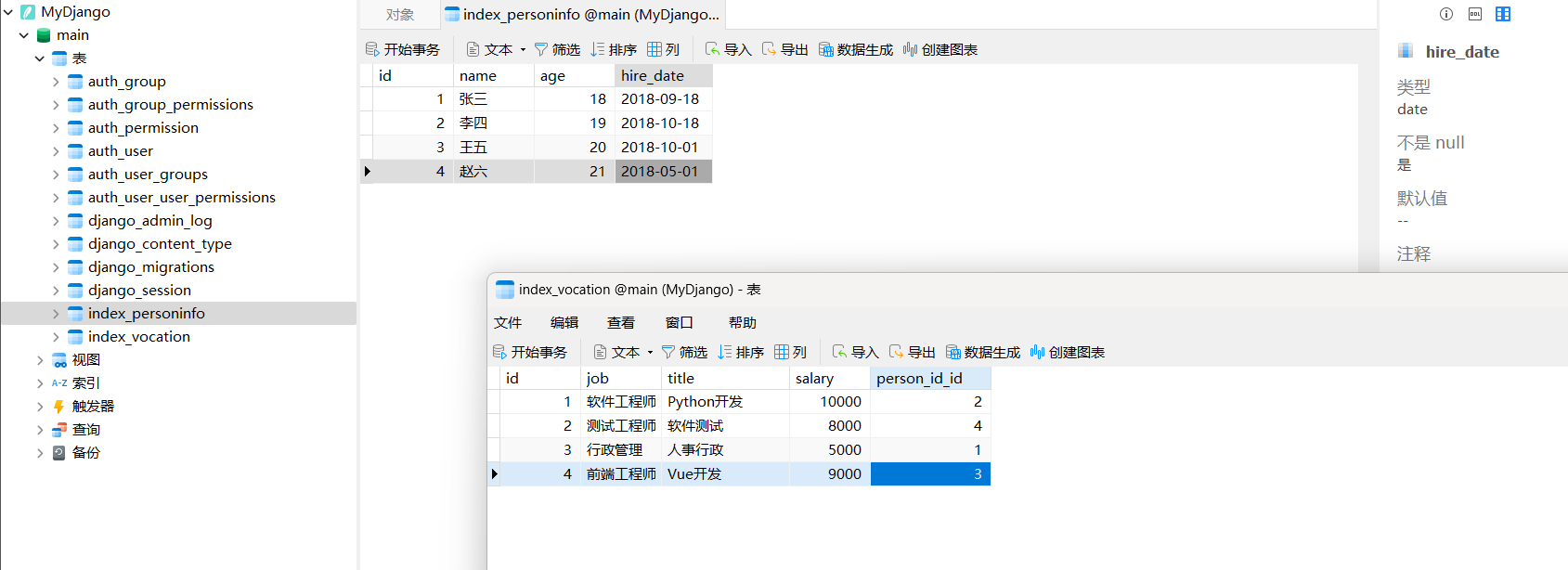
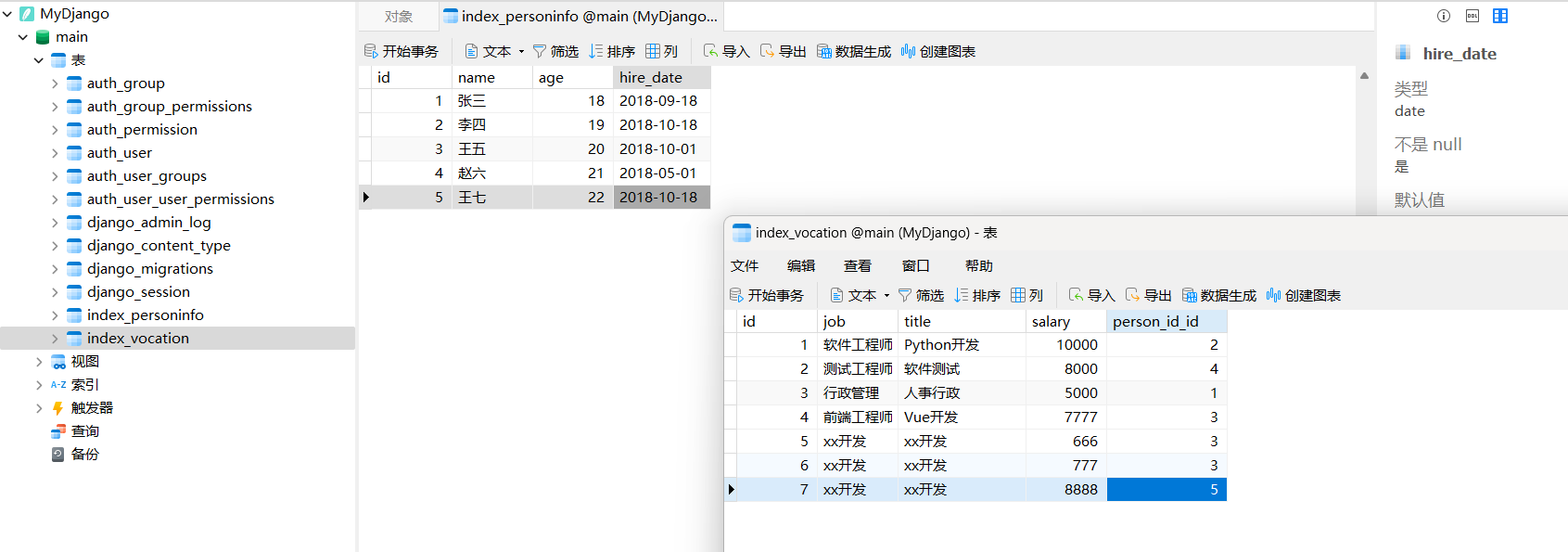
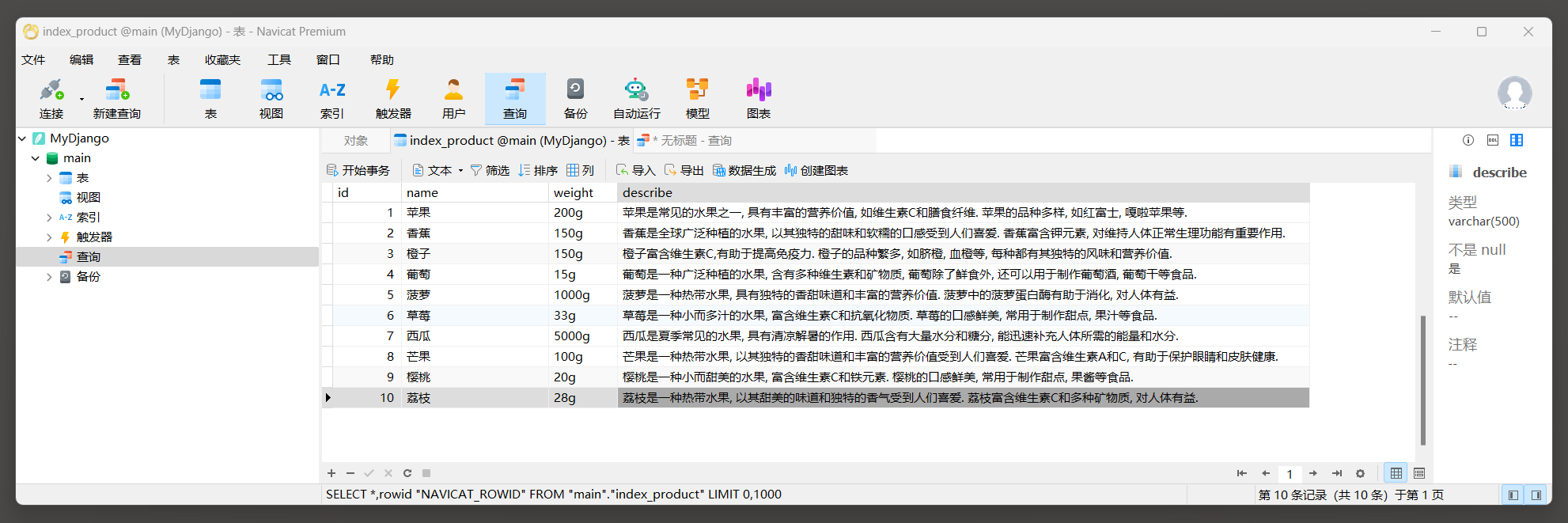
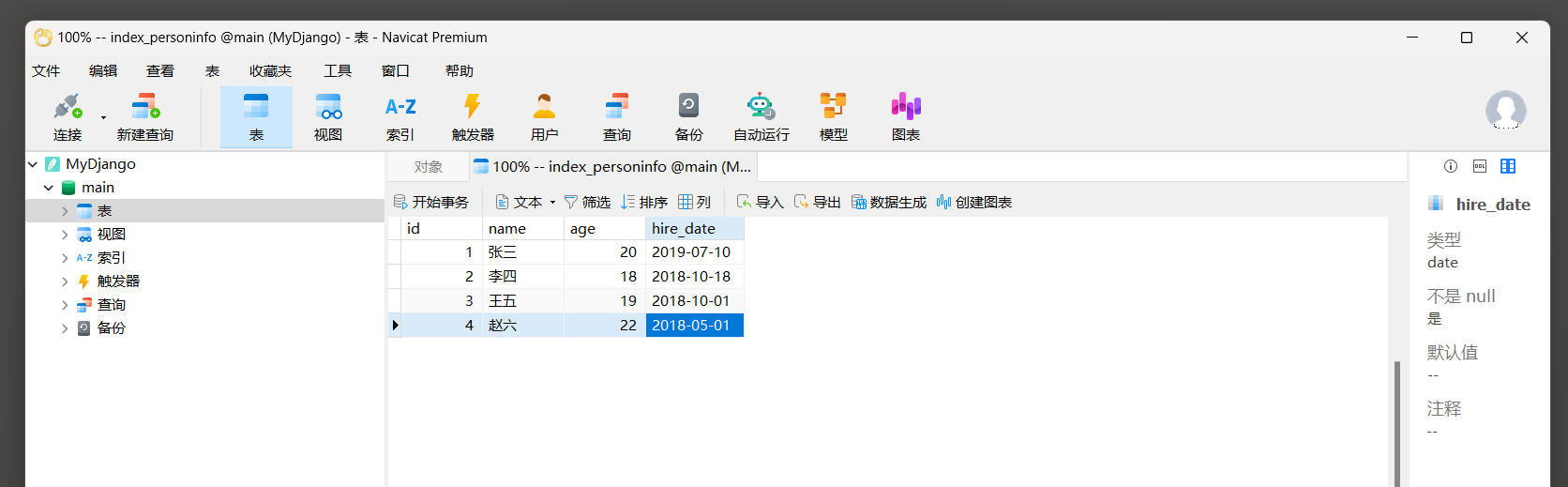
对数据表index_personinfo和index_vocation添加数据内容 , 如图 12 - 1 所示 .
图 12 - 1 数据表index_personinfo和index_vocation
INSERT INTO "index_personinfo" ( "id" , "name" , "age" , "hire_date" ) VALUES ( 1 , '张三' , 18 , '2018-09-18' ) ;
INSERT INTO "index_personinfo" ( "id" , "name" , "age" , "hire_date" ) VALUES ( 2 , '李四' , 19 , '2018-10-18' ) ;
INSERT INTO "index_personinfo" ( "id" , "name" , "age" , "hire_date" ) VALUES ( 3 , '王五' , 20 , '2018-10-01' ) ;
INSERT INTO "index_personinfo" ( "id" , "name" , "age" , "hire_date" ) VALUES ( 4 , '赵六' , 21 , '2018-05-01' ) ;
INSERT INTO "index_vocation"
( "id" , "job" , "title" , "salary" , "person_id_id" ) VALUES ( 1 , '软件工程师' , 'Python开发' , 10000 , 2 ) ;
INSERT INTO "index_vocation"
( "id" , "job" , "title" , "salary" , "person_id_id" ) VALUES ( 2 , '测试工程师' , '软件测试' , 8000 , 4 ) ;
INSERT INTO "index_vocation"
( "id" , "job" , "title" , "salary" , "person_id_id" ) VALUES ( 3 , '行政管理' , '人事行政' , 5000 , 1 ) ;
INSERT INTO "index_vocation"
( "id" , "job" , "title" , "salary" , "person_id_id" ) VALUES ( 4 , '前端工程师' , 'Vue开发' , 9000 , 3 ) ;
项目环境搭建完成后 , 我们将使用Django Rest Framework快速开发API .
首先在项目应用index中创建serializers . py文件 , 该文件用于定义Django Rest Framework的序列化类 ;
然后定义序列化类MySerializer , 代码如下:
from rest_framework import serializers
from . models import PersonInfo, Vocation
id_list = PersonInfo. objects. values_list( 'id' , flat= True ) class MySerializer ( serializers. Serializer) : id = serializers. IntegerField( read_only= True ) job = serializers. CharField( max_length= 100 ) title = serializers. CharField( max_length= 100 ) salary = serializers. CharField( max_length= 100 ) person_id = serializers. PrimaryKeyRelatedField( queryset= id_list) def create ( self, validate_data) : return Vocation. objects. create( ** validate_data) def update ( self, instance, validated_data) : return instance. update( ** validated_data) 自定义序列化类MySerializer继承父类Serializer ,
父类Serializer是由Django Rest Framework定义的 , 它的定义过程与表单类Form十分相似 .
在PyCharm里打开父类Serializer的源码文件 , 分析序列化类Serializer的定义过程 , 如图 12 - 2 所示 .
图 12 - 2 Serializer的定义过程
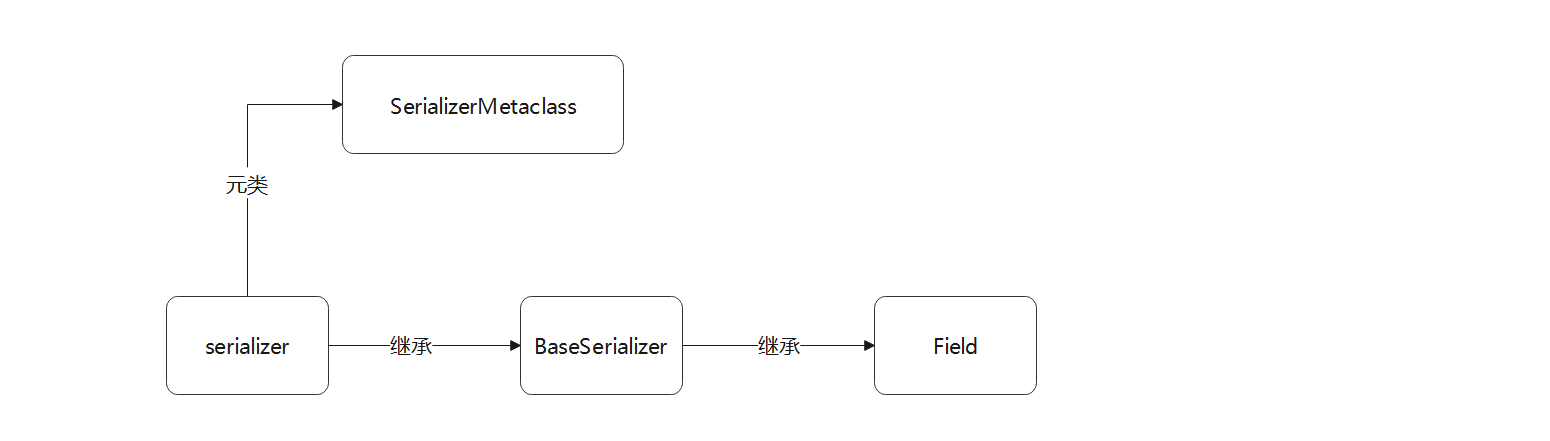
从图 12 - 2 得知,Serializer继承父类BaseSerializer , 设置元类SerializerMetaclass , ( 老版本装饰器add_metaclass设置元类 ) .
我们以流程图的形式说明Serializer的继承关系 , 如图 12 - 3 所示 .
图 12 - 3 Serializer的继承关系
自定义序列化类MySerializer的字段对应模型Vocation的字段 ,
序列化字段的数据类型可以在Django Rest Framework的源码文件fields . py中找到定义过程 ,
它们都继承父类Field , 序列化字段的数据类型与表单字段的数据类型相似 , 此处不再详细讲述 . 在定义序列化字段的时候 , 每个序列化字段允许设置参数信息 ,
我们分析父类Field的初始化参数 , 它们适用于所有序列化字段的参数设置 , 参数说明如下 :
● read_only : 设置序列化字段的只读属性 .
● write_only : 设置序列化字段的编辑属性 .
● required : 设置序列化字段的数据是否为空 , 默认值为True . ●default:设置序列化字段的默认值。
● initial : 设置序列化字段的初始值 .
● source : 为序列化字段指定一个模型字段来源 , 如 ( email = 'user.email' ) .
● label : 用于生成label标签的网页内容 .
● help_text : 设置序列化字段的帮助提示信息 .
● style : 以字典格式表示 , 控制模板引擎如何渲染序列化字段 .
● error_messages : 设置序列化字段的错误信息 , 以字典格式表示 , 包含null , blank , invalid , invalid_choice , unique等键值 .
● validators : 与表单类的validators相同 , 这是自定义数据验证规则 , 以列表格式表示 , 列表元素为数据验证的函数名 .
● allow_null : 设置序列化字段是否为None , 若为True , 则序列化字段的值允许为None .
自定义序列化类MySerializer还定义了关系字段name , 重写了父类BaseSerializer的create和update函数 .
关系字段可以在源码文件relations . py中找到定义过程 , 每个关系字段都有代码注释说明 , 本节不再重复讲述 .
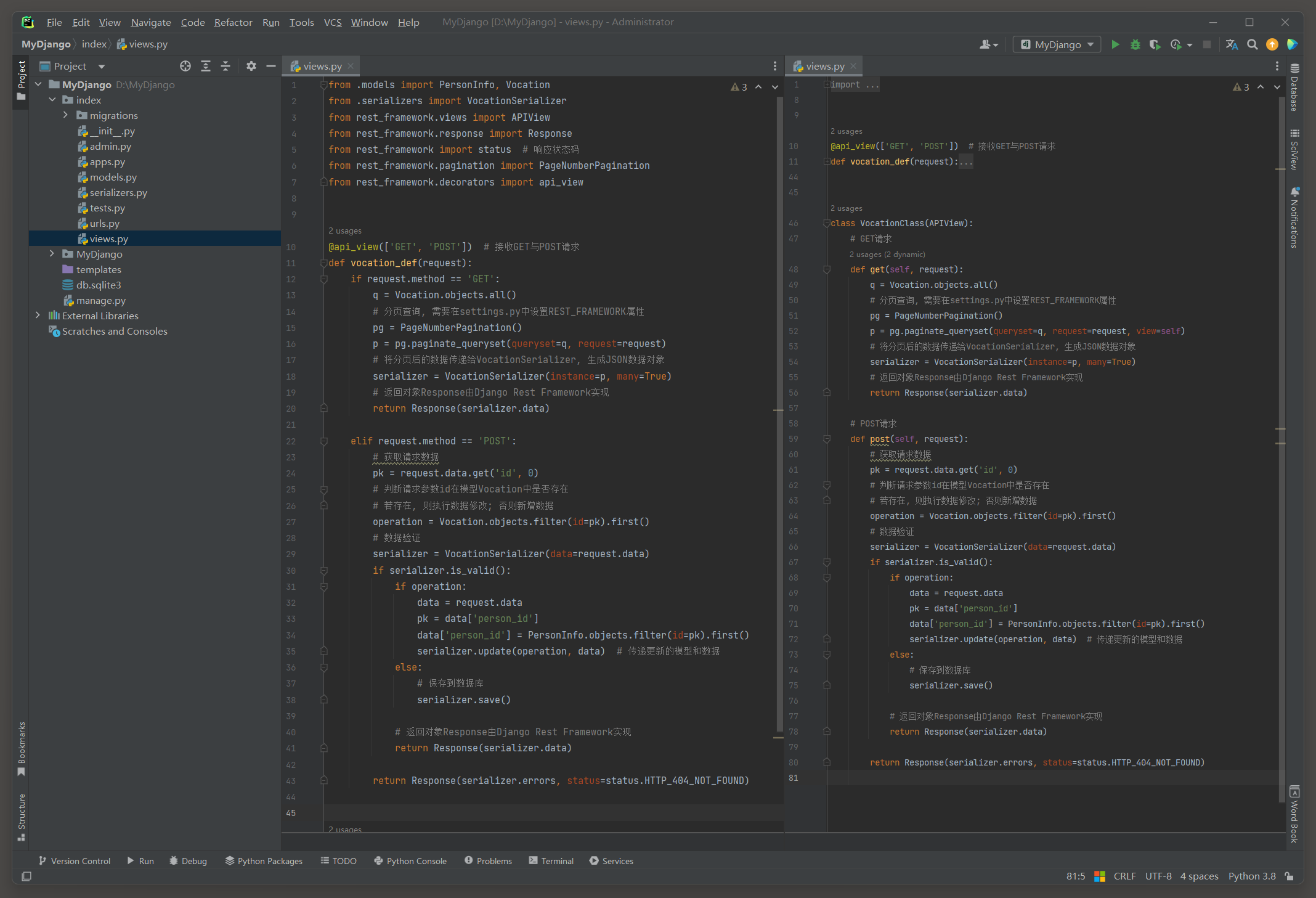
下一步使用序列化类MySerializer实现API开发 , 在index的urls . py中分别定义路由my_def和路由my_class , 路由信息的代码如下 :
from django. urls import path
from . views import *
urlpatterns = [ path( '' , vocationDef, name= 'my_def' ) , path( 'my_class/' , vocationClass. as_view( ) , name= 'my_class' ) ,
]
路由my_def对应视图函数vocation_def , 它以视图函数的方式使用MySerializer实现模型Vocation的API接口 ;
路由my_class对应视图类VocationClass , 它以视图类的方式使用MySerializer实现模型Vocation的API接口 .
因此 , 视图函数vocationDef和视图类vocationClass的定义过程如下 :
from . models import PersonInfo, Vocation
from . serializers import MySerializer
from rest_framework. views import APIView
from rest_framework. response import Response
from rest_framework import status
from rest_framework. pagination import PageNumberPagination
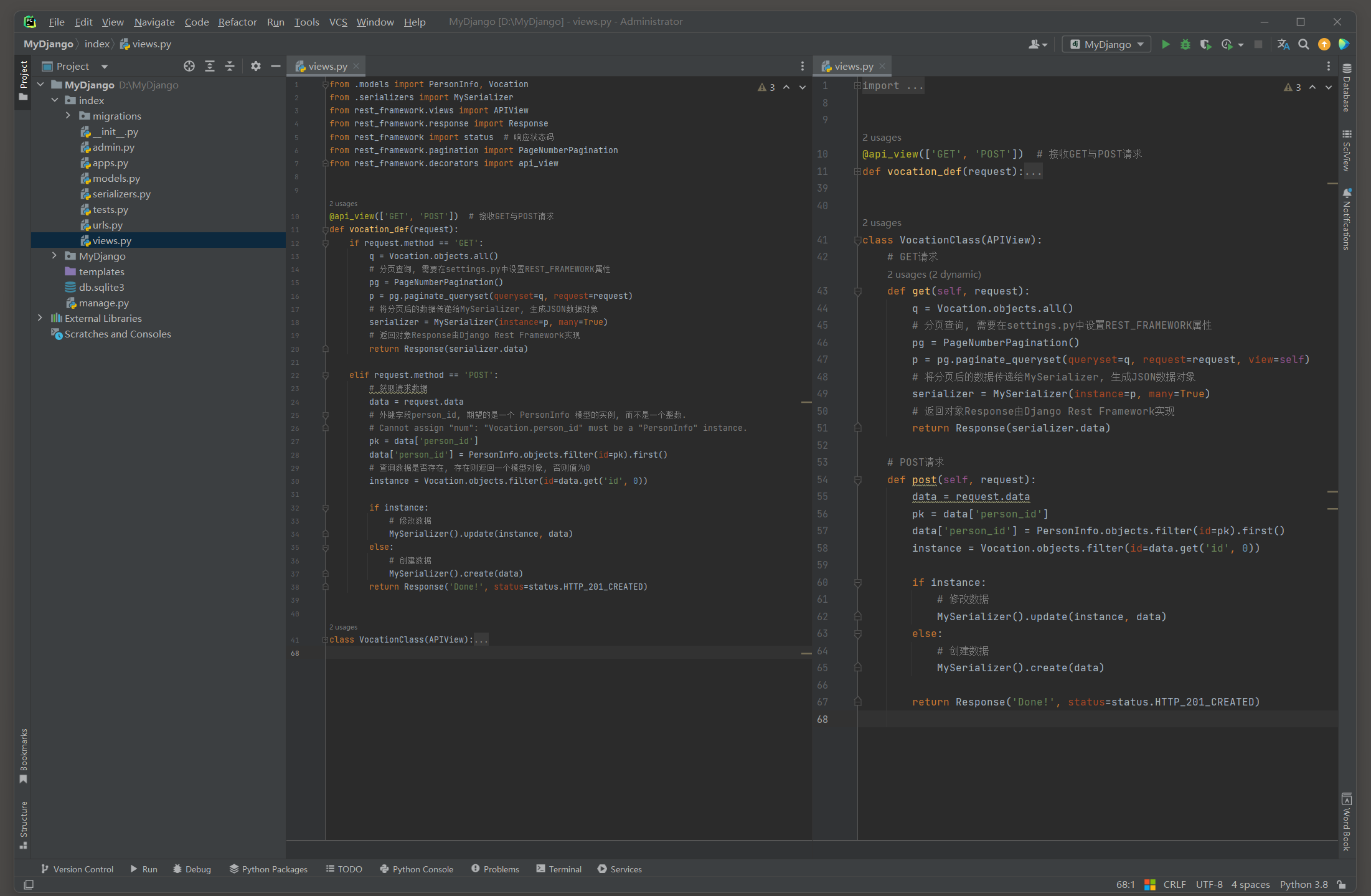
from rest_framework. decorators import api_view@api_view ( [ 'GET' , 'POST' ] )
def vocation_def ( request) : if request. method == 'GET' : q = Vocation. objects. all ( ) pg = PageNumberPagination( ) p = pg. paginate_queryset( queryset= q, request= request) serializer = MySerializer( instance= p, many= True ) return Response( serializer. data) elif request. method == 'POST' : data = request. datapk = data[ 'person_id' ] data[ 'person_id' ] = PersonInfo. objects. filter ( id = pk) . first( ) instance = Vocation. objects. filter ( id = data. get( 'id' , 0 ) ) if instance: MySerializer( ) . update( instance, data) else : MySerializer( ) . create( data) return Response( 'Done!' , status= status. HTTP_201_CREATED) class VocationClass ( APIView) : def get ( self, request) : q = Vocation. objects. all ( ) pg = PageNumberPagination( ) p = pg. paginate_queryset( queryset= q, request= request, view= self) serializer = MySerializer( instance= p, many= True ) return Response( serializer. data) def post ( self, request) : data = request. datapk = data[ 'person_id' ] data[ 'person_id' ] = PersonInfo. objects. filter ( id = pk) . first( ) instance = Vocation. objects. filter ( id = data. get( 'id' , 0 ) ) if instance: MySerializer( ) . update( instance, data) else : MySerializer( ) . create( data) return Response( 'Done!' , status= status. HTTP_201_CREATED)
视图函数vocation_def和视图类VocationClass实现的功能是一致的 ,
若使用视图函数开发API接口 , 则必须对视图函数使用装饰器api_view ;
若使用视图类 , 则必须继承父类APIView , 这是Django Rest Framework明确规定的 .
上述的视图函数vocation_def和视图类VocationClass对GET请求和POST请求进行不同的处理 . 当用户在浏览器上访问路由my_def或路由my_class的时候 ,
视图函数vocation_def或视图类VocationClass将接收GET请求 , 该请求的处理过程说明如下 :
( 1 ) 视图函数vocation_def或视图类VocationClass查询模型Vocation所有数据 , 并将数据进行分页处理 .
( 2 ) 分页功能由Django Rest Framework的PageNumberPagination实现 , 它是在Django内置分页功能的基础上进行封装的 , 分页属性设置在settings . py的REST_FRAMEWORK中 .
( 3 ) 分页后的数据传递给序列化类MySerializer , 转化成JSON数据 , 最后由Django Rest Framework框架的Response完成用户响应 . 运行MyDjango , 分别访问路由my_def和路由my_class , 发现两者返回的网页内容是一致的 .
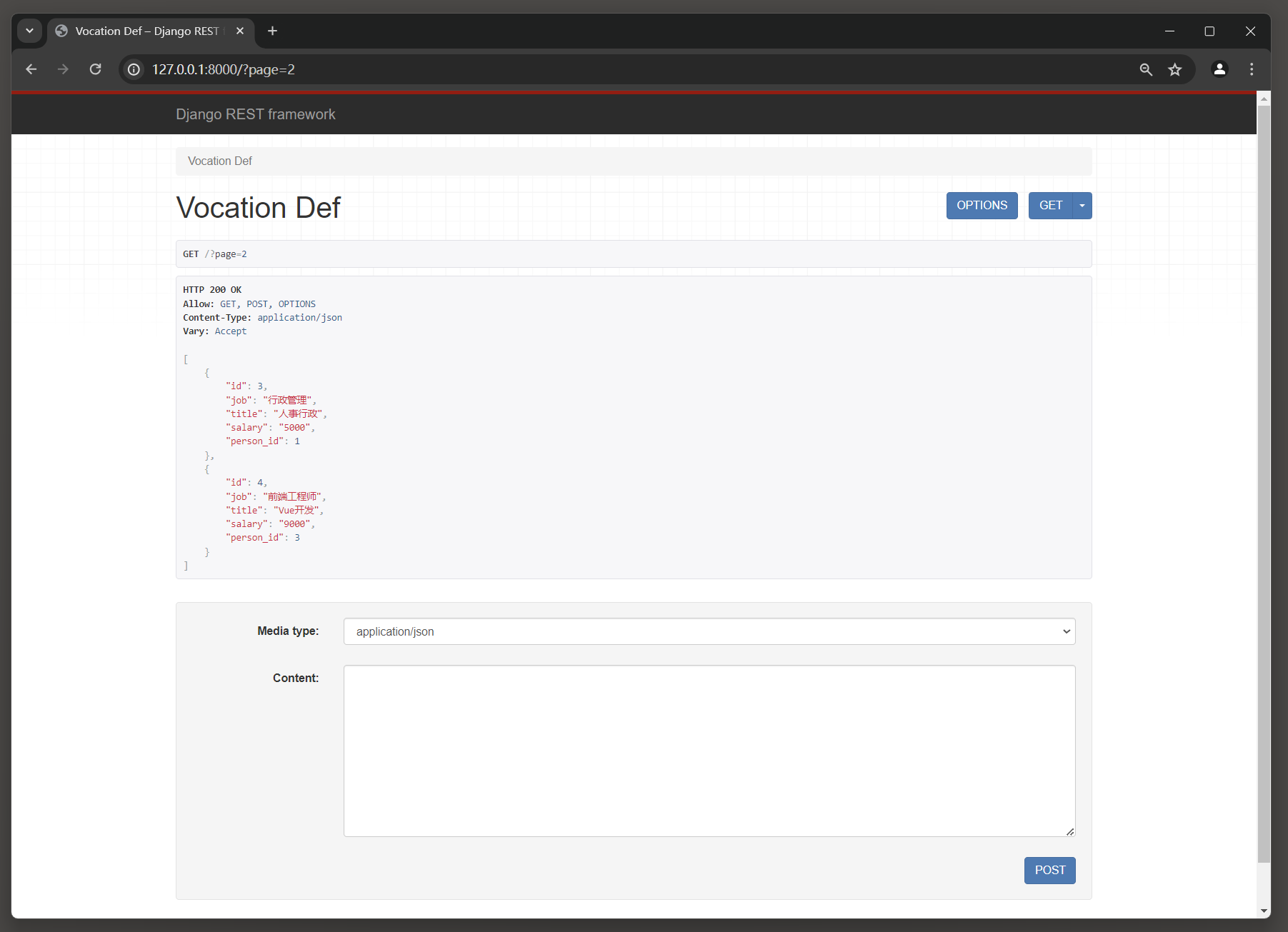
如果在路由地址中设置请求参数page , 就可以获取某分页的数据信息 , 如图 12 - 4 所示 .
图 12 - 4 运行结果
用户向路由my_def或路由my_class发送POST请求时 , 视图函数vocation_def或视图类VocationClass的处理过程说明如下 :
( 1 ) 视图函数vocationDef或视图类vocationClass获取请求参数 , 将请求参数id作为模型字段id的查询条件 , 在模型Vocation中进行数据查询 .
( 2 ) 如果存在查询对象 , 就说明模型Vocation已存在相应的数据信息 , 当前POST请求将视为修改模型Vocation的已有数据 .
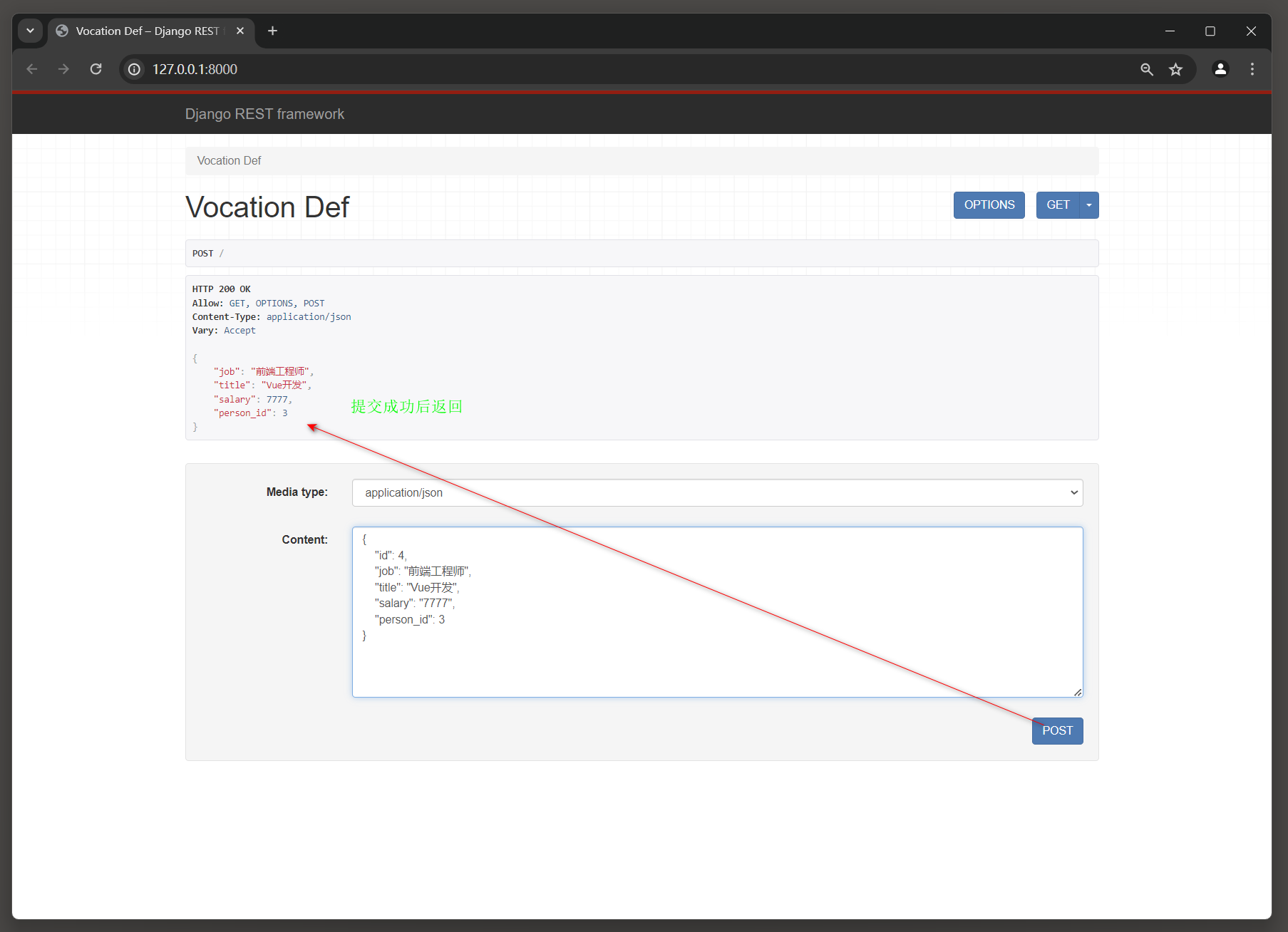
( 3 ) 如果不存在查询对象 , 就把当前请求的数据信息添加在模型Vocation中 . 在图 12 - 4 的网页正下方找到Content文本框 , 以模型Vocation的字段编写单个JSON数据 ,
单击 'POST' 按钮即可实现数据的新增或修改 , 如图 12 - 5 所示 .
{ "id" : 4 , "job" : "前端工程师" , "title" : "Vue开发" , "salary" : "6666" , "person_id" : 3
}
{ "id" : 5 , "job" : "xx开发" , "title" : "xx开发" , "salary" : "666" , "person_id" : 3
}
图 12 - 5 新增或修改数据
序列化类Serializer可以与模型结合使用 , 从而实现模型的数据读写操作 .
但序列化类Serializer定义的字段必须与模型字段相互契合 , 否则在使用过程中很容易提示异常信息 .
为了简化序列化类Serializer的定义过程 , Django Rest Framework定义了模型序列化类ModelSerializer ,
它与模型表单ModelForm的定义和使用十分相似 .
以 12.1 .2 小节的MyDjango为例 , 将自定义的MySerializer改为VocationSerializer ,
序列化类VocationSerializer继承父类ModelSerializer , 它能与模型Vocation完美结合 , 无须开发者定义序列化字段 .
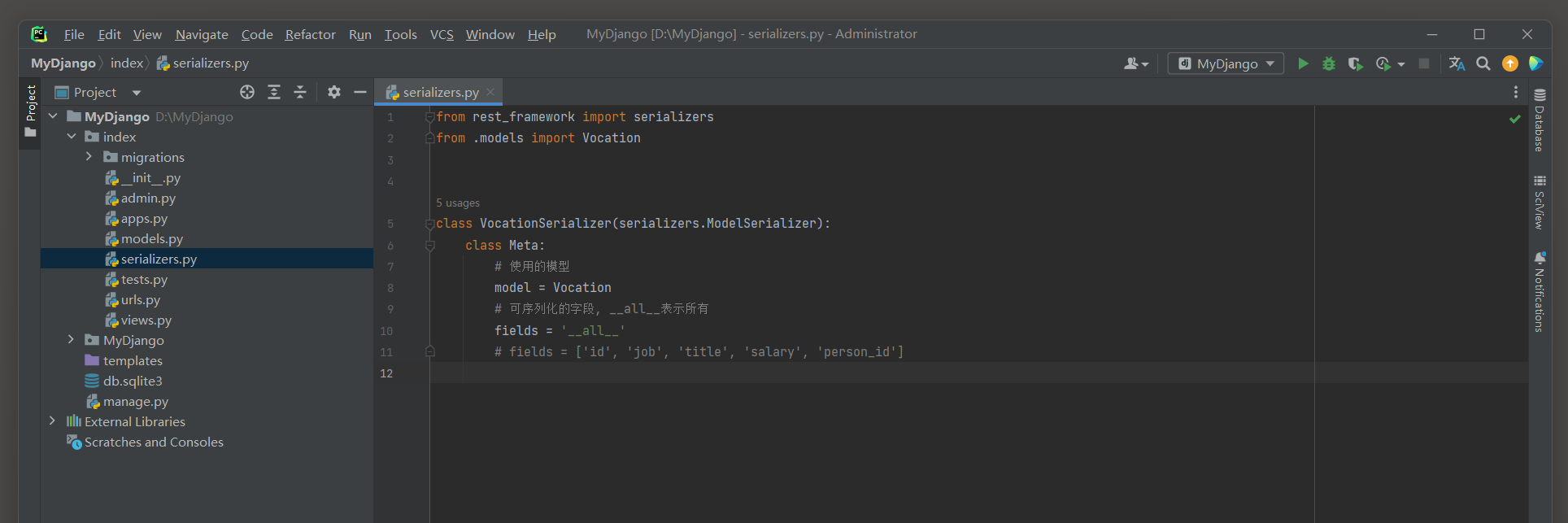
在index的serializers . py中定义VocationSerializer , 代码如下 :
from rest_framework import serializers
from . models import Vocationclass VocationSerializer ( serializers. ModelSerializer) : class Meta : model = Vocationfields = '__all__'
分析VocationSerializer得知 , 属性model将模型Vocation与ModelSerializer进行绑定 ;
属性fields用于设置哪些模型字段转化为序列化字段 , 属性值__all__代表模型所有字段转化为序列化字段 ,
如果只设置部分模型字段 , 属性fields的值就可以使用元组或列表表示 , 元组或列表的每个元素代表一个模型字段 .
下一步重新定义视图函数vocation_def和视图类VocationClass , 使用模型序列化类VocationSerializer实现模型Vocation的API接口 .
视图函数vocation_def和视图类VocationClass的代码如下 :
from . models import PersonInfo, Vocation
from . serializers import VocationSerializer
from rest_framework. views import APIView
from rest_framework. response import Response
from rest_framework import status
from rest_framework. pagination import PageNumberPagination
from rest_framework. decorators import api_view@api_view ( [ 'GET' , 'POST' ] )
def vocation_def ( request) : if request. method == 'GET' : q = Vocation. objects. all ( ) pg = PageNumberPagination( ) p = pg. paginate_queryset( queryset= q, request= request) serializer = VocationSerializer( instance= p, many= True ) return Response( serializer. data) elif request. method == 'POST' : pk = request. data. get( 'id' , 0 ) operation = Vocation. objects. filter ( id = pk) . first( ) serializer = VocationSerializer( data= request. data) if serializer. is_valid( ) : if operation: data = request. datapk = data[ 'person_id' ] data[ 'person_id' ] = PersonInfo. objects. filter ( id = pk) . first( ) serializer. update( operation, data) else : serializer. save( ) return Response( serializer. data) return Response( serializer. errors, status= status. HTTP_404_NOT_FOUND) class VocationClass ( APIView) : def get ( self, request) : q = Vocation. objects. all ( ) pg = PageNumberPagination( ) p = pg. paginate_queryset( queryset= q, request= request, view= self) serializer = VocationSerializer( instance= p, many= True ) return Response( serializer. data) def post ( self, request) : pk = request. data. get( 'id' , 0 ) operation = Vocation. objects. filter ( id = pk) . first( ) serializer = VocationSerializer( data= request. data) if serializer. is_valid( ) : if operation: data = request. datapk = data[ 'person_id' ] data[ 'person_id' ] = PersonInfo. objects. filter ( id = pk) . first( ) serializer. update( operation, data) else : serializer. save( ) return Response( serializer. data) return Response( serializer. errors, status= status. HTTP_404_NOT_FOUND)
视图函数vocation_def和视图类VocationClass的业务逻辑与 12.1 .2 小节的业务逻辑是相同的 ,
而对于POST请求的处理过程 , 本节与 12.1 .2 小节实现的功能一致 , 但使用的函数方法有所不同 .
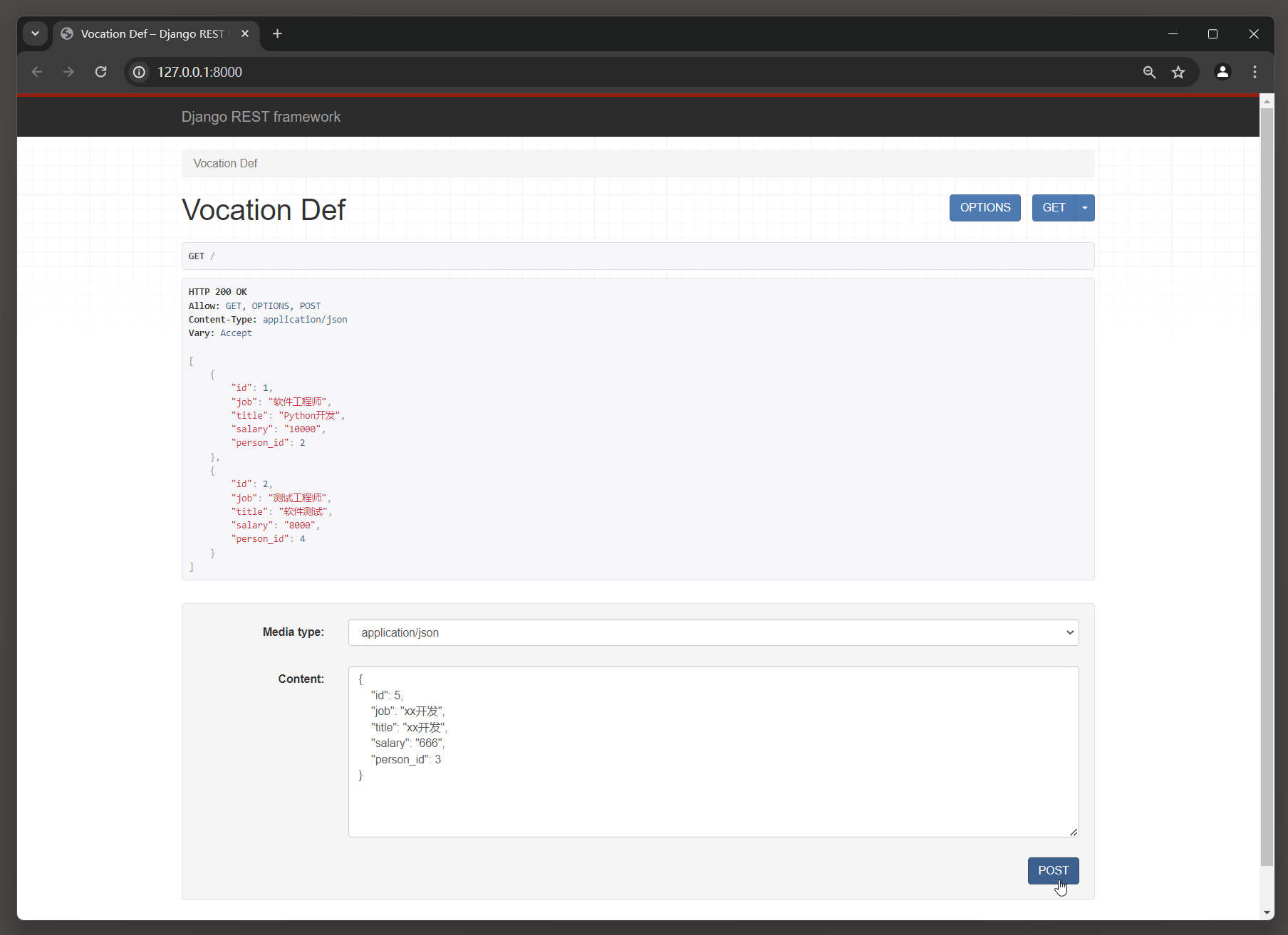
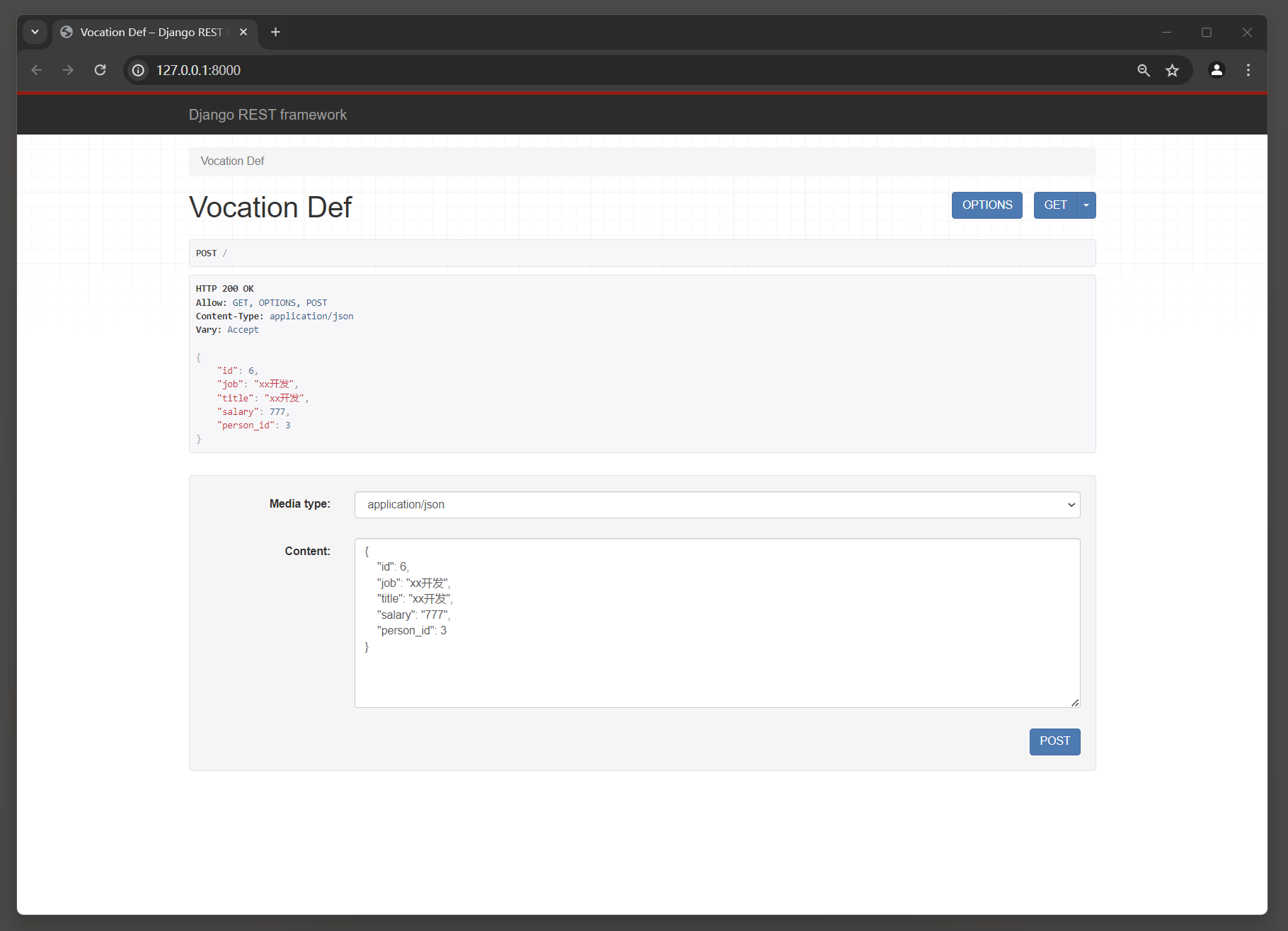
启动项目 , 访问 : 127.0 .0 .1 : 8000 / .
# 修改数据 :
{ "id" : 4 , "job" : "前端工程师" , "title" : "Vue开发" , "salary" : "7777" , "person_id" : 3
}
# 新增数据 :
{ "id" : 6 , "job" : "xx开发" , "title" : "xx开发" , "salary" : "777" , "person_id" : 3
}
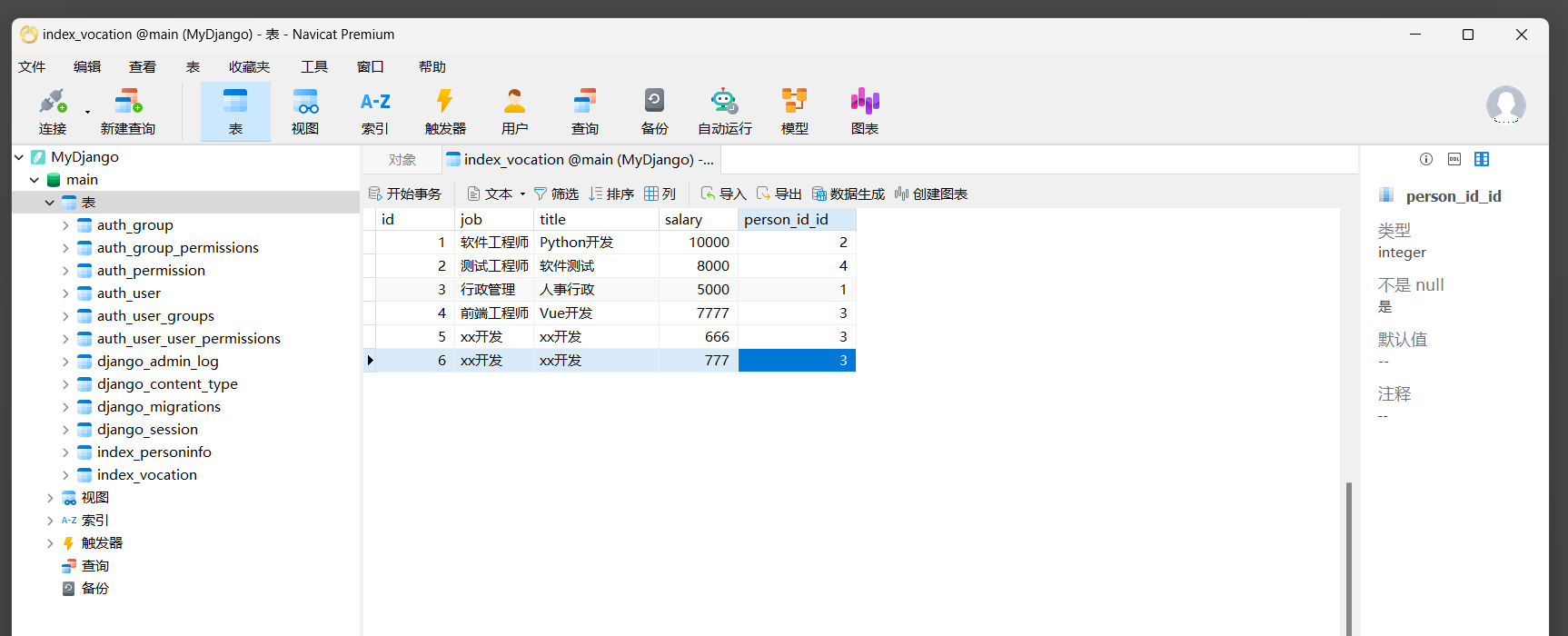
查看数据库 .
在开发过程中 , 我们需要对多个JSON数据进行嵌套使用 ,
比如将模型PersonInfo和Vocation的数据组合存放在同一个JSON数据中 , 两个模型的数据通过外键字段person_id进行关联 . 模型之间必须存在数据关系才能实现数据嵌套 , 数据关系可以是一对一 , 一对多或多对多的 .
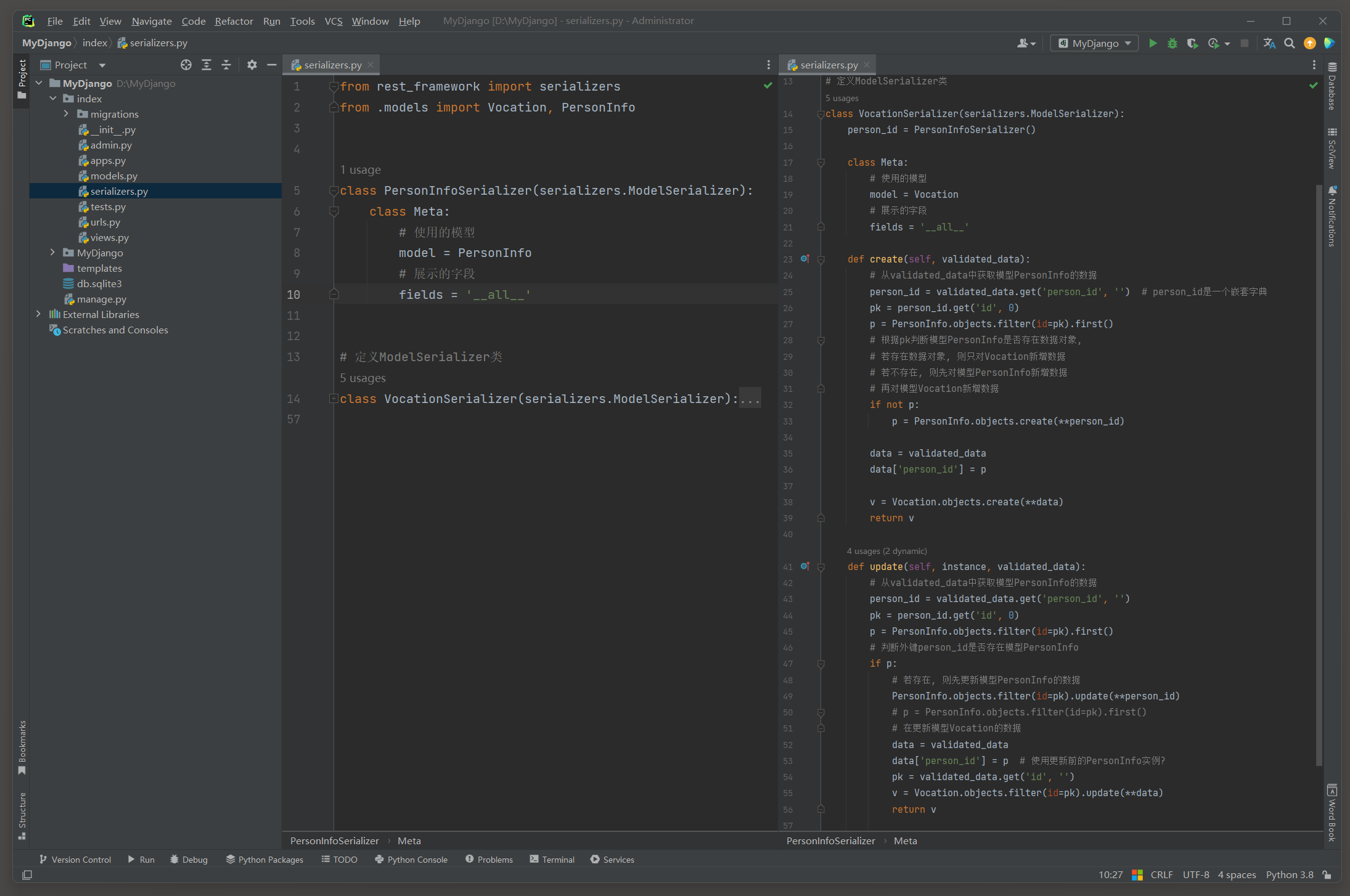
不同的数据关系对数据嵌套的读写操作会有细微的差异 . 以 12.1 .3 小节的MyDjango为例 , 在index的serializers . py中定义PersonInfoSerializer和VocationSerializer .
分别对应模型PersonInfo和Vocation , 模型序列化类的定义如下 :
from rest_framework import serializers
from . models import Vocation, PersonInfoclass PersonInfoSerializer ( serializers. ModelSerializer) : class Meta : model = PersonInfofields = '__all__'
class VocationSerializer ( serializers. ModelSerializer) : person_id = PersonInfoSerializer( ) class Meta : model = Vocationfields = '__all__' def create ( self, validated_data) : person_id = validated_data. get( 'person_id' , '' ) pk = person_id. get( 'id' , 0 ) p = PersonInfo. objects. filter ( id = pk) . first( ) if not p: p = PersonInfo. objects. create( ** person_id) data = validated_datadata[ 'person_id' ] = pv = Vocation. objects. create( ** data) return vdef update ( self, instance, validated_data) : person_id = validated_data. get( 'person_id' , '' ) pk = person_id. get( 'id' , 0 ) p = PersonInfo. objects. filter ( id = pk) . first( ) if p: PersonInfo. objects. filter ( id = pk) . update( ** person_id) data = validated_datadata[ 'person_id' ] = pk v_pk = validated_data. get( 'id' , '' ) v = Vocation. objects. filter ( id = v_pk) . update( ** data) return v
从上述代码看到 , 序列化类VocationSerializer对PersonInfoSerializer进行实例化并赋值给变量person_id ,
而属性fields的person_id代表模型Vocation的外键字段person_id , 同时也是变量person_id .
换句话说 , 序列化字段person_id代表模型Vocation的外键字段person_id , 而变量person_id作为序列化字段person_id的数据内容 . 变量person_id的名称必须与模型外键字段名称或者序列化字段名称一致 ,
否则模型外键字段或者序列化字段无法匹配变量person_id , 从而提示异常信息 . 序列化类VocationSerializer还重写了数据的新增函数create和修改函数update ,
因为不同数据关系的数据读写方式各不相同 , 并且不同的开发需求可能导致数据读写方式有所不同 .
新增函数create和修改函数update的业务逻辑较为相似 , 业务逻辑说明如下 :
( 1 ) 从用户的请求参数 ( 函数参数validated_data ) 获取模型PersonInfo的主键id , 根据主键id查询模型PersonInfo是否已存在数据对象 .
( 2 ) 如果存在模型PersonInfo的数据对象 , 那么update函数首先修改模型PersonInfo的数据 , 然后修改模型Vocation的数据 .
( 3 ) 如果不存在模型PersonInfo的数据对象 , 那么create函数在模型PersonInfo中新增数据 , 然后在模型Vocation中新增数据 . 确保模型Vocation的外键字段name不为空 , 使两个模型之间构成一对多的数据关系 .
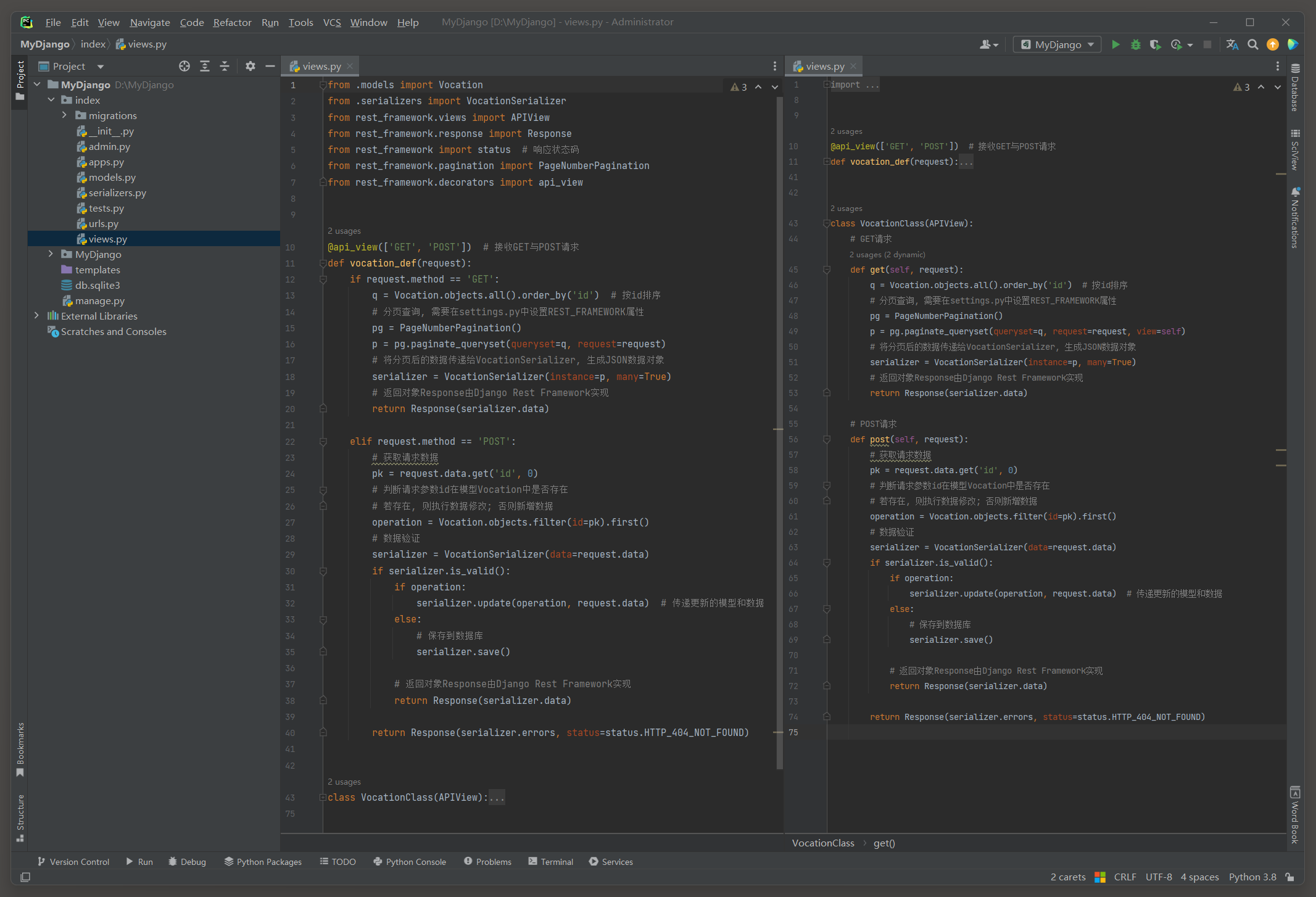
下一步对视图函数vocation_def和视图类VocationClass的代码进行调整 , 代码的业务逻辑与 12.1 .3 小节的相同 , 代码调整如下 :
from . models import Vocation
from . serializers import VocationSerializer
from rest_framework. views import APIView
from rest_framework. response import Response
from rest_framework import status
from rest_framework. pagination import PageNumberPagination
from rest_framework. decorators import api_view@api_view ( [ 'GET' , 'POST' ] )
def vocation_def ( request) : if request. method == 'GET' : q = Vocation. objects. all ( ) . order_by( 'id' ) pg = PageNumberPagination( ) p = pg. paginate_queryset( queryset= q, request= request) serializer = VocationSerializer( instance= p, many= True ) return Response( serializer. data) elif request. method == 'POST' : pk = request. data. get( 'id' , 0 ) operation = Vocation. objects. filter ( id = pk) . first( ) serializer = VocationSerializer( data= request. data) if serializer. is_valid( ) : if operation: serializer. update( operation, request. data) else : serializer. save( ) return Response( serializer. data) return Response( serializer. errors, status= status. HTTP_404_NOT_FOUND) class VocationClass ( APIView) : def get ( self, request) : q = Vocation. objects. all ( ) . order_by( 'id' ) pg = PageNumberPagination( ) p = pg. paginate_queryset( queryset= q, request= request, view= self) serializer = VocationSerializer( instance= p, many= True ) return Response( serializer. data) def post ( self, request) : pk = request. data. get( 'id' , 0 ) operation = Vocation. objects. filter ( id = pk) . first( ) serializer = VocationSerializer( data= request. data) if serializer. is_valid( ) : if operation: serializer. update( operation, request. data) else : serializer. save( ) return Response( serializer. data) return Response( serializer. errors, status= status. HTTP_404_NOT_FOUND)
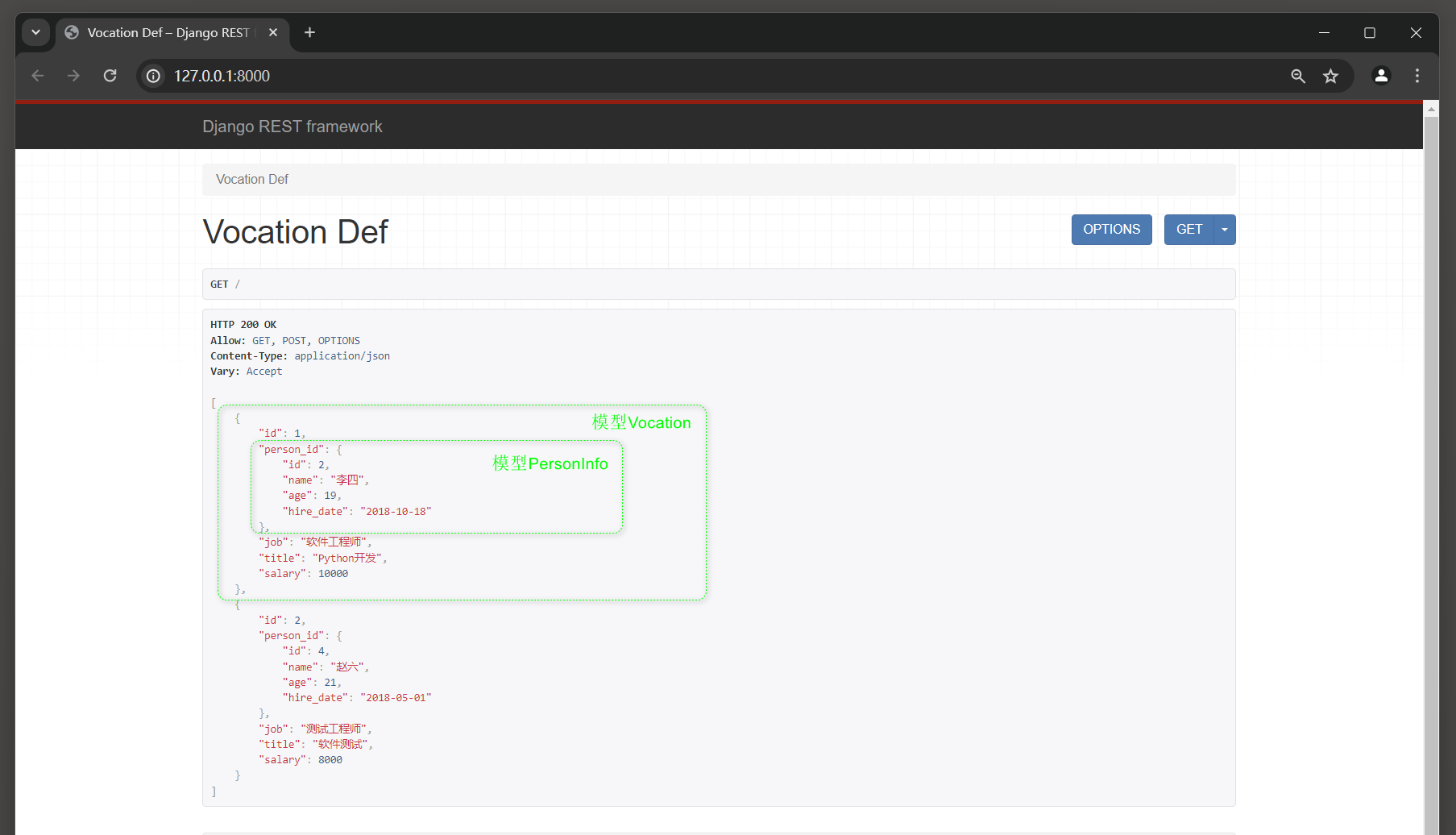
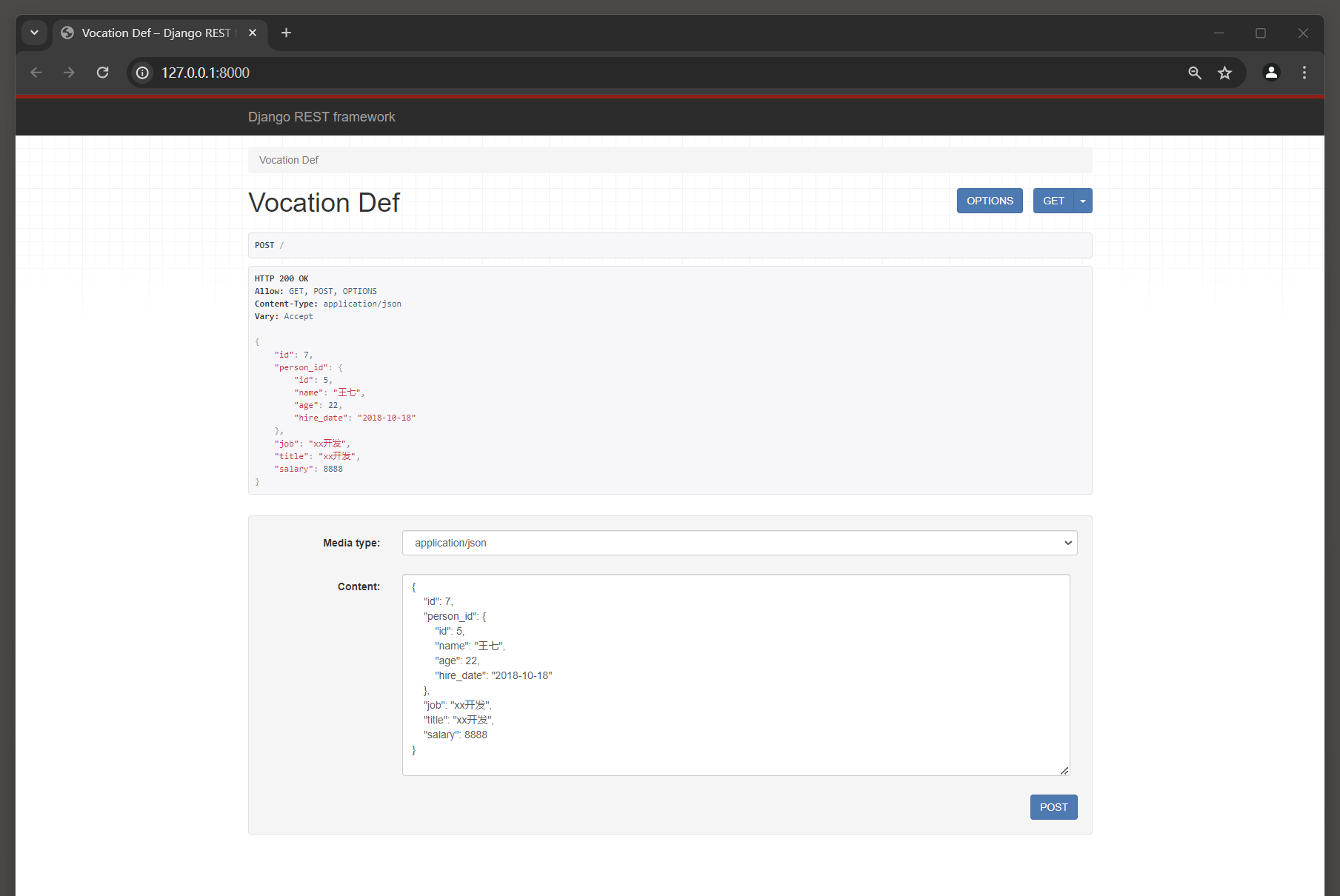
最后运行MyDjango , 在浏览器上访问 : 127.0 .0 .1 : 8000 , 模型Vocation的每行数据嵌套了模型PersonInfo的某行数据 ,
两个模型的数据嵌套主要由模型Vocation的外键字段name实现关联 , 如图 12 - 6 所示 .
{ "id" : 7 , "person_id" : { "id" : 5 , "name" : "王七" , "age" : 22 , "hire_date" : "2018-10-18" } , "job" : "xx开发" , "title" : "xx开发" , "salary" : 8888
}
图 12 - 6 数据嵌套
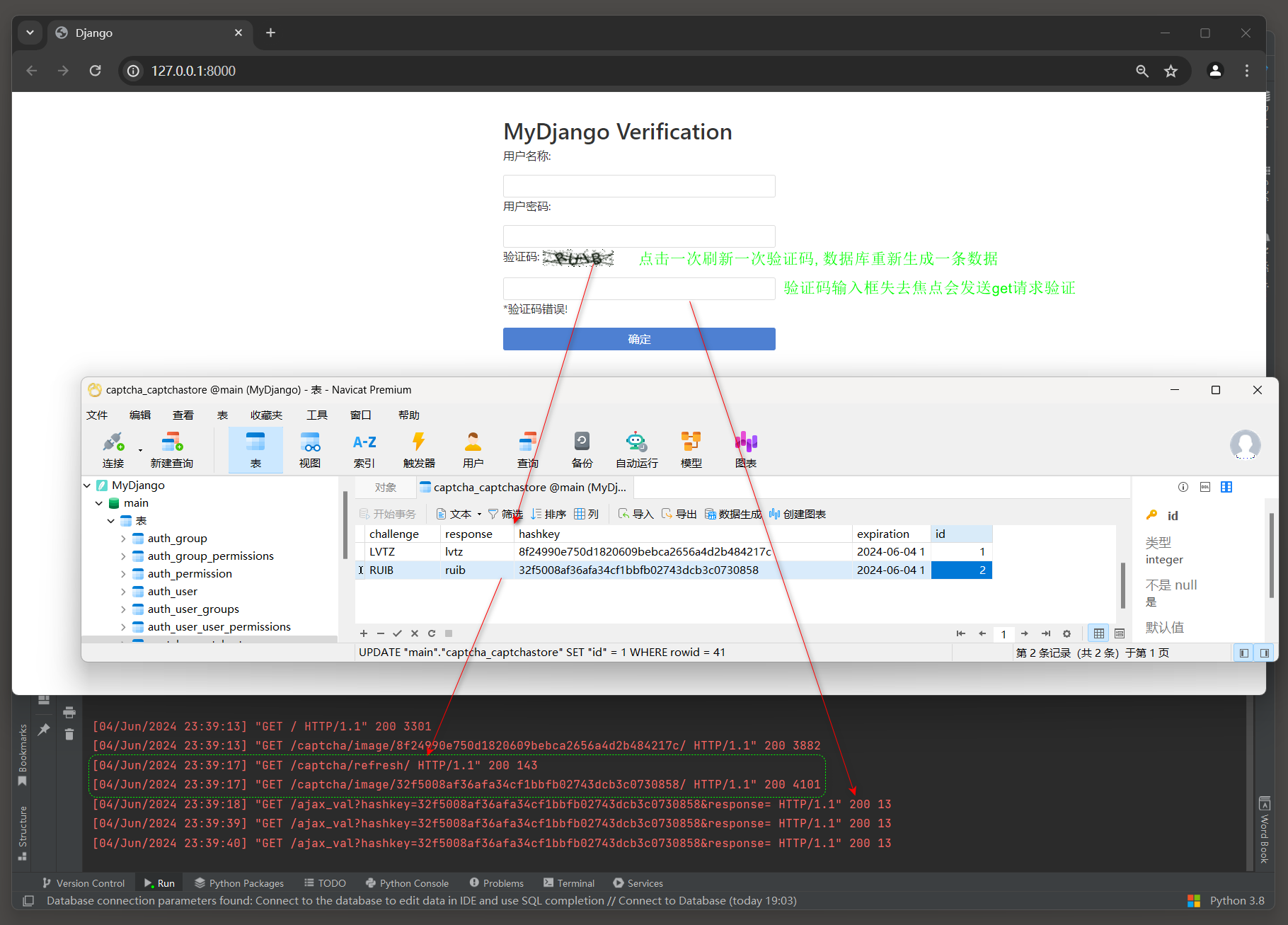
现在很多网站都采用验证码功能 , 这是反爬虫常用的策略之一 .
目前常用的验证码类型如下 :
● 字符验证码 : 在图片上随机产生数字 , 英文字母或汉字 , 一般有 4 位或者 6 位验证码字符 .
● 图片验证码 : 图片验证码采用字符验证码的技术 , 不再使用随机的字符 , 而是让用户识别图片 , 比如 12306 的验证码 .
● GIF动画验证码 : 由多张图片组合而成的动态验证码 , 使得识别器不容易辨识哪一张图片是真正的验证码图片 .
● 极验验证码 : 在 2012 年推出的新型验证码 , 采用行为式验证技术 , 通过拖曳滑块完成拼图的形式实现验证 , 是目前比较有创意的验证码 , 安全性具有新的突破 .
● 手机验证码 : 通过短信的形式发送到用户手机上面的验证码 , 一般为 6 位的数字 .
● 语音验证码 : 属于手机端验证的一种方式 .
● 视频验证码 : 视频验证码是验证码中的新秀 , 在视频验证码中 , 将随机数字 , 字母和中文组合而成的验证码动态嵌入MP4 , FLV等格式的视频中 , 增大破解难度 .
如果想在Django中实现验证码功能 , 那么可以使用PIL模块生成图片验证码 , 但不建议使用这种实现方式 .
除此之外 , 还可以通过第三方应用Django Simple Captcha实现 ,
验证码的生成过程由该应用自动执行 , 开发者只需考虑如何应用到Django项目中即可 .
Django Simple Captcha使用pip安装 , 安装指令如下 : pip install django-simple-captcha .
清华源 : pip install -i https : / / pypi . tuna . tsinghua . edu . cn / simple django-simple-captcha .
安装成功后 , 下一步讲述如何在Django中使用Django Simple Captcha生成网站验证码 .
以MyDjango项目为例 , 首先创建项目应用user , 并在项目应用user中创建forms . py文件 ;
然后在templates文件夹中放置user . html文件 , 目录结构如图 12 - 7 所示 .
图 12 - 7 目录结构
本节将实现带验证码的用户登录功能 , 因此在settings . py中需要配置INSTALLED_APPS , TEMPLATES和DATABASES , 配置信息如下 :
INSTALLED_APPS = [ 'django.contrib.admin' , 'django.contrib.auth' , 'django.contrib.contenttypes' , 'django.contrib.sessions' , 'django.contrib.messages' , 'django.contrib.staticfiles' , 'user.apps.UserConfig' , 'captcha' ,
]
配置属性INSTALLED_APPS添加了captcha , 这是将Django Simple Captcha的功能引入MyDjango项目 .
Django Simple Captcha设有多种验证码的生成方式 , 如设置验证码的内容 , 图片噪点和图片大小等 ,
这些功能设置可以在Django Simple Captcha的源码文件 ( site-packages \ captcha \ conf \ settings . py ) 中查看 .
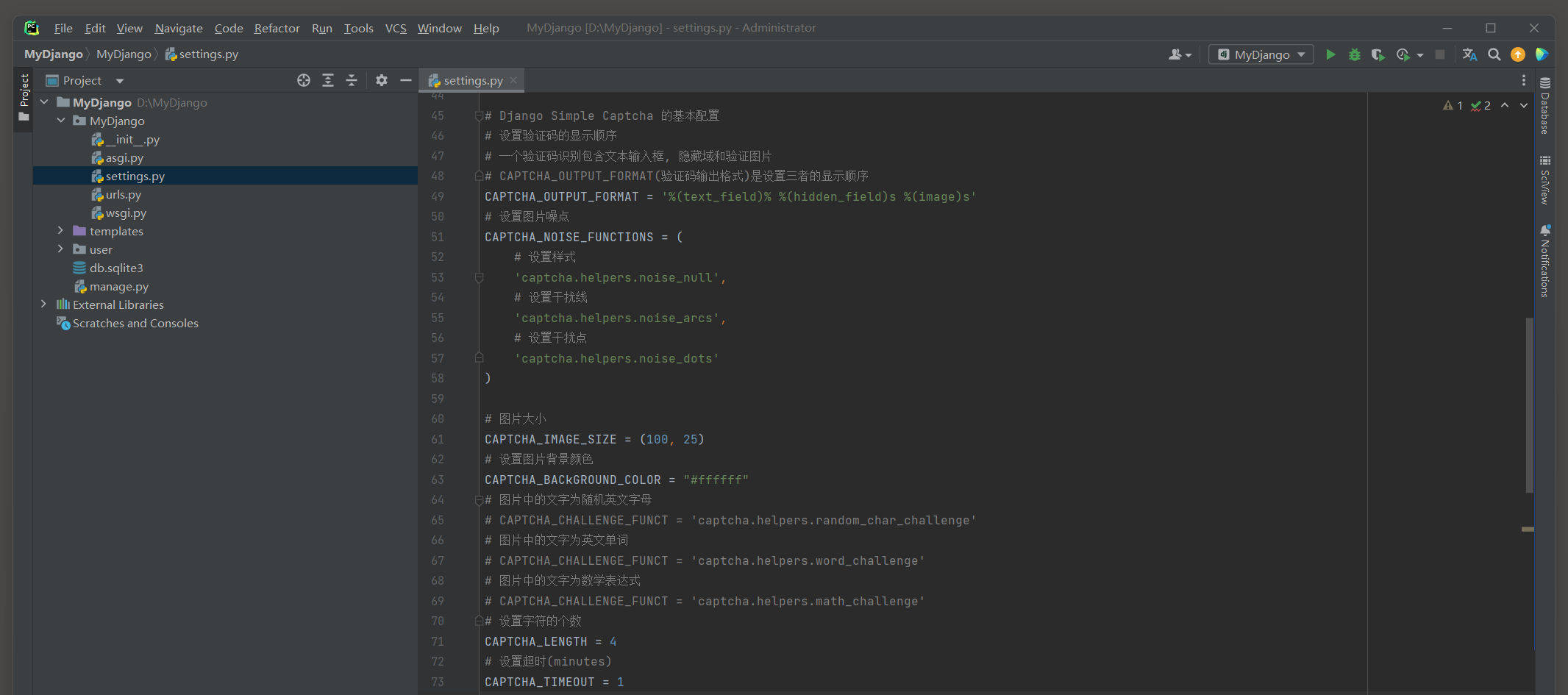
本节只说明验证码的常用功能设置 , 在MyDjango的settings . py中添加以下属性 :
CAPTCHA_OUTPUT_FORMAT = '%(text_field)% %(hidden_field)s %(image)s'
CAPTCHA_NOISE_FUNCTIONS = ( 'captcha.helpers.noise_null' , 'captcha.helpers.noise_arcs' , 'captcha.helpers.noise_dots'
)
CAPTCHA_IMAGE_SIZE = ( 100 , 25 )
CAPTCHA_BACkGROUND_COLOR = "#ffffff"
CAPTCHA_LENGTH = 4
CAPTCHA_TIMEOUT = 1
上述配置主要设置验证码的显示顺序 , 图片噪点 , 图片大小 , 背景颜色和验证码内容 , 具体的配置以及配置说明可以查看源代码及注释 .
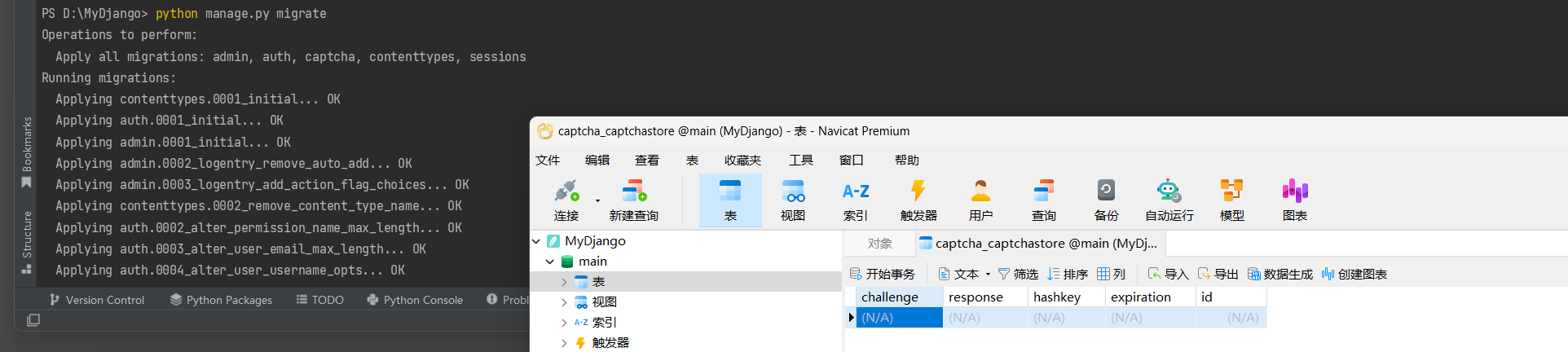
完成上述配置后 , 下一步执行数据迁移 , 因为验证码需要依赖数据表才能得以实现 . 通过python manage . py migrate指令完成数据迁移 , 然后查看项目所生成的数据表 ,
发现新增数据表captcha_captchastore , 如图 12 - 8 所示 .
PS D: \MyDjango> python manage. py migrate
Operations to perform: Apply all migrations: admin, auth, captcha, contenttypes, sessions
Running migrations: Applying contenttypes. 0001_initial. . . OKApplying auth. 0001_initial. . . OKApplying admin. 0001_initial. . . OK. . .
图 12 - 8 数据表captcha_captchastore
完成Django Simple Captcha与MyDjango的功能搭建 , 下一步在用户登录页面实现验证码功能 .
我们将用户登录页面划分为多个不同的功能 , 详细说明如下 :
● 用户登录页面 : 由表单生成 , 表单类在项目应用user的forms . py中定义 .
● 登录验证 : 触发POST请求 , 用户信息以及验证功能由Django内置的Auth认证系统实现 .
● 验证码动态刷新 : 由Ajax向Captcha功能应用发送GET请求完成动态刷新 .
● 验证码动态验证 : 由Ajax向Django发送GET请求完成验证码验证 .
根据上述功能进行分析 , 整个用户登录过程由MyDjango的urls . py和项目应用user的forms . py , urls . py , views . py和user . html共同实现 .
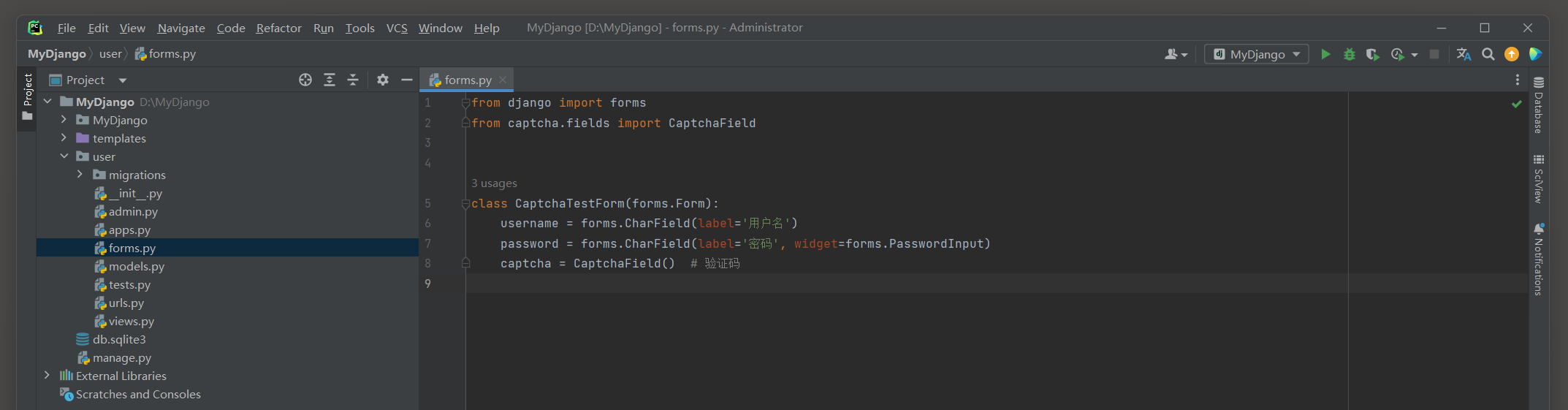
首先在项目应用user的forms . py中定义用户登录表单类 , 代码如下 :
from django import forms
from captcha. fields import CaptchaField
class CaptchaTestForm ( forms. Form) : username = forms. CharField( label= '用户名' ) password= forms. CharField( label= '密码' , widget= forms. PasswordInput) captcha = CaptchaField( )
从表单类CaptchaTestForm可以看到 , 字段captcha是由Django Simple Captcha定义的CaptchaField对象 ,
该对象在生成HTML网页信息时 , 将自动生成文本输入框 , 隐藏控件和验证码图片 .
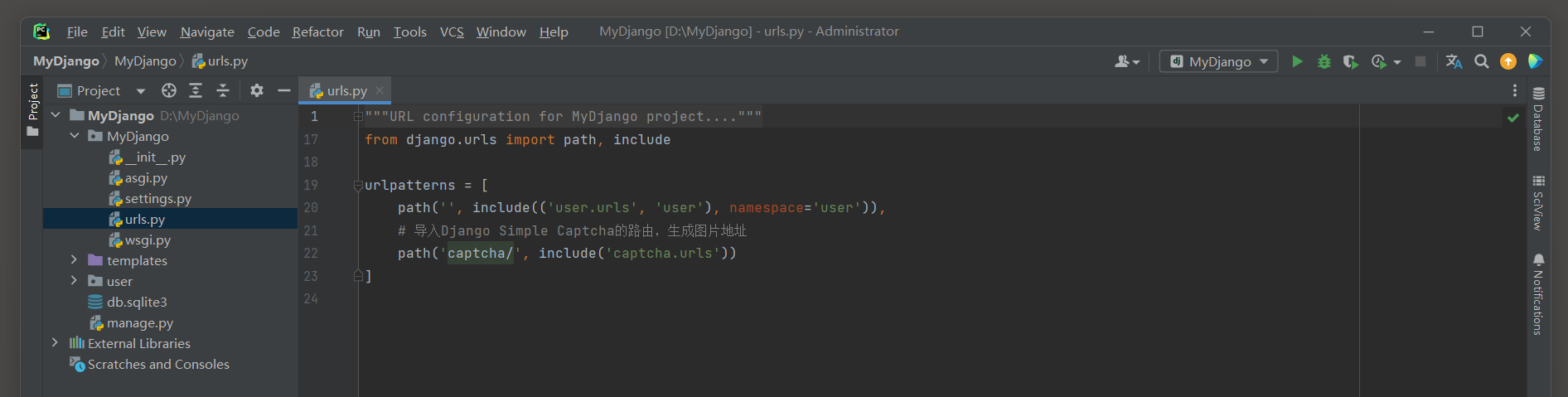
下一步在MyDjango的urls . py和项目应用user的urls . py中定义用户登录页面的路由信息 , 代码如下 :
from django. urls import path, includeurlpatterns = [ path( '' , include( ( 'user.urls' , 'user' ) , namespace= 'user' ) ) , path( 'captcha/' , include( 'captcha.urls' ) )
]
from django. urls import re_pathfrom captcha import viewsurlpatterns = [ re_path( r"image/(?P<key>\w+)/$" , views. captcha_image, name= "captcha-image" , kwargs= { "scale" : 1 } , ) , re_path( r"image/(?P<key>\w+)@2/$" , views. captcha_image, name= "captcha-image-2x" , kwargs= { "scale" : 2 } , ) , re_path( r"audio/(?P<key>\w+).wav$" , views. captcha_audio, name= "captcha-audio" ) , re_path( r"refresh/$" , views. captcha_refresh, name= "captcha-refresh" ) ,
]
views . captcha_image : 这个视图函数可能是用来生成和提供验证码图片的 .
它接收一个key参数 , 这个key ( hashkey字段的值 ) 用于从数据库中检索特定的验证码 .
此外 , 它还接收一个额外的scale参数 , 这个参数是用来控制文字的大小的 .
当scale为 1 时 , 生成正常大小的文字 ; 当scale为 2 时 , 生成两倍大小的文字 .
( 注意 : 图片尺寸不会改变 , 只是文字大小改变 ! ! !
http : / / 127.0 .0 .1 : 8000 /captcha/image/c81aecfa4b4d8d92d1c7da68caf3cb30e8f51a6a/ 文字正常大小
http : / / 127.0 .0 .1 : 8000 /captcha/image/c81aecfa4b4d8d92d1c7da68caf3cb30e8f51a6a@ 2 / 文字正常大小 * 2
) views . captcha_audio : 这个视图函数可能是用来生成和提供验证码音频的 .
它也接收一个key参数 , 用于检索特定的验证码 .
音频验证码对于视觉障碍的用户特别有用 , 因为它们可以通过听音频中的字符来输入验证码 . views . captcha_refresh : 刷新验证码 . 在web表单中 , 当用户需要一个新的验证码时 ( 例如 , 他们可能认为当前的验证码难以识别 ) ,
他们可能会点击一个刷新按钮 , 这个按钮会触发对captcha-refresh URL的请求 .
视图函数接收到这个请求后 , 可能会生成一个新的验证码 , 并可能将其与原来的表单字段相关联 , 或者将新的验证码的图片或音频返回给用户 .
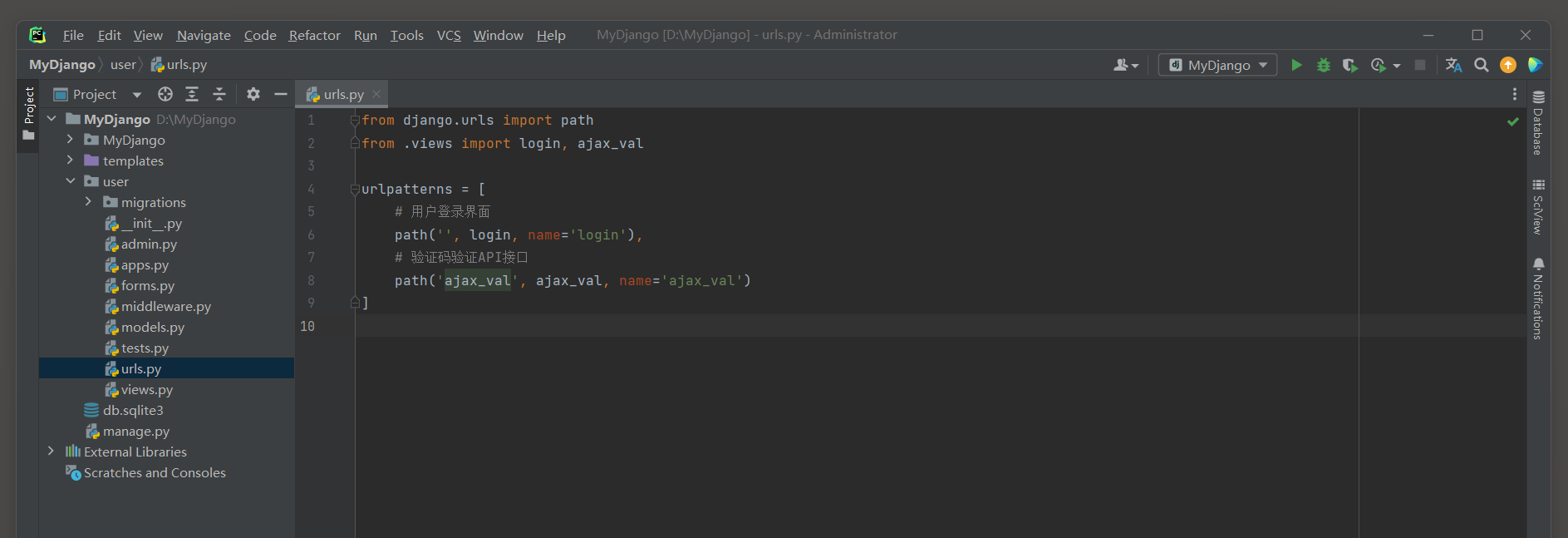
from django. urls import path
from . views import login, ajax_valurlpatterns = [ path( '' , login, name= 'login' ) , path( 'ajax_val' , ajax_val, name= 'ajax_val' )
]
MyDjango的urls . py中分别引入了Django Simple Captcha的urls . py和项目应用user的urls . py .
前者是为验证码图片提供路由地址以及为Ajax动态刷新验证码提供API接口 ;
后者设置用户登录页面的路由地址以及为Ajax动态校对验证码提供API接口 .
项目应用user的路由login和ajax_val分别指向视图函数login和ajax_val ,
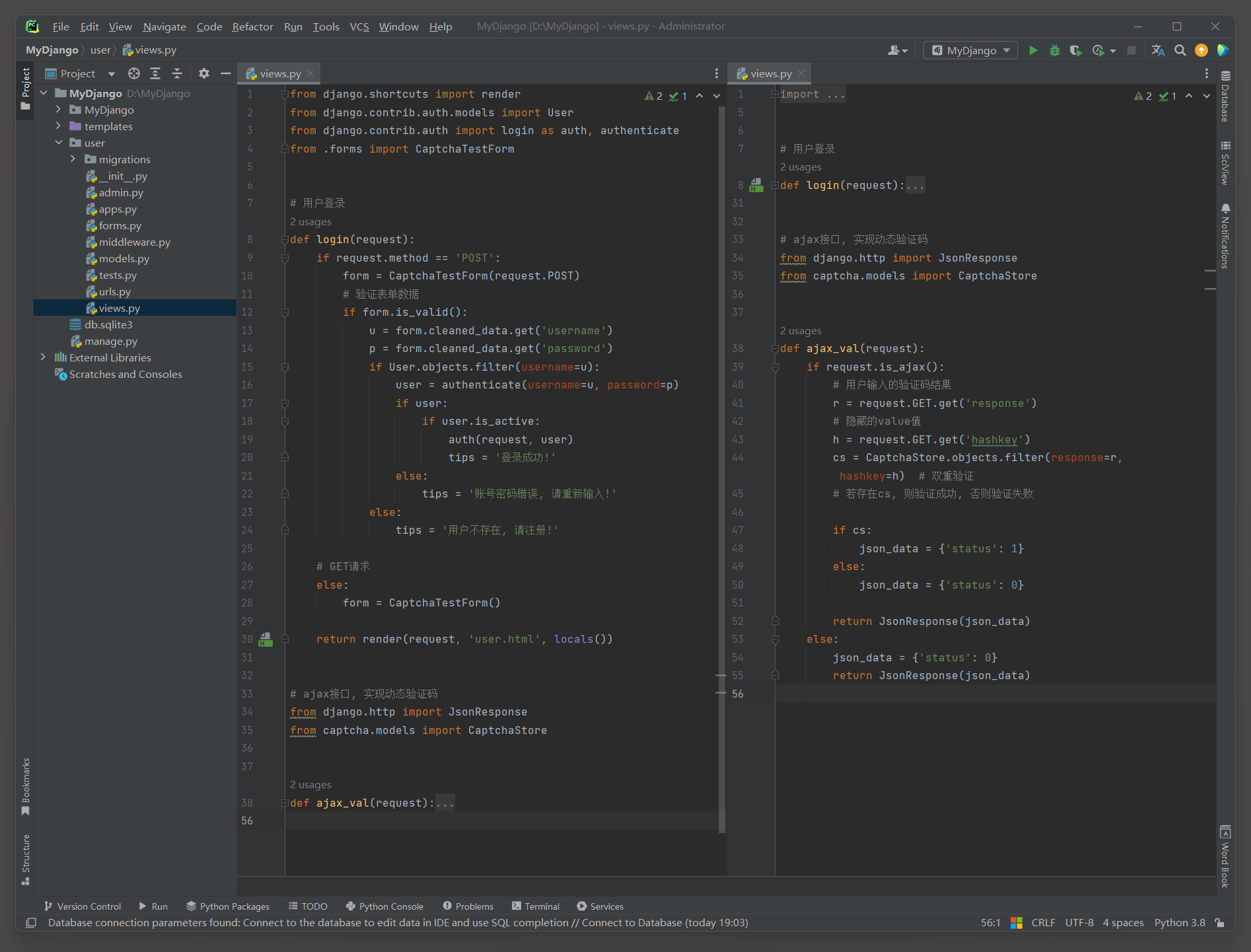
因此在user的views . py中分别定义视图函数loginView和ajax_val , 代码如下 :
from django. shortcuts import render
from django. contrib. auth. models import User
from django. contrib. auth import login as auth, authenticate
from . forms import CaptchaTestForm
def login ( request) : if request. method == 'POST' : form = CaptchaTestForm( request. POST) if form. is_valid( ) : u = form. cleaned_data. get( 'username' ) p = form. cleaned_data. get( 'password' ) if User. objects. filter ( username= u) : user = authenticate( username= u, password= p) if user: if user. is_active: auth( request, user) tips = '登录成功!' else : tips = '账号密码错误, 请重新输入!' else : tips = '用户不存在, 请注册!' else : form = CaptchaTestForm( ) return render( request, 'user.html' , locals ( ) )
from django. http import JsonResponse
from captcha. models import CaptchaStoredef ajax_val ( request) : if request. is_ajax( ) : r = request. GET. get( 'response' ) h = request. GET. get( 'hashkey' ) cs = CaptchaStore. objects. filter ( response= r, hashkey= h) if cs: json_data = { 'status' : 1 } else : json_data = { 'status' : 0 } return JsonResponse( json_data) else : json_data = { 'status' : 0 } return JsonResponse( json_data)
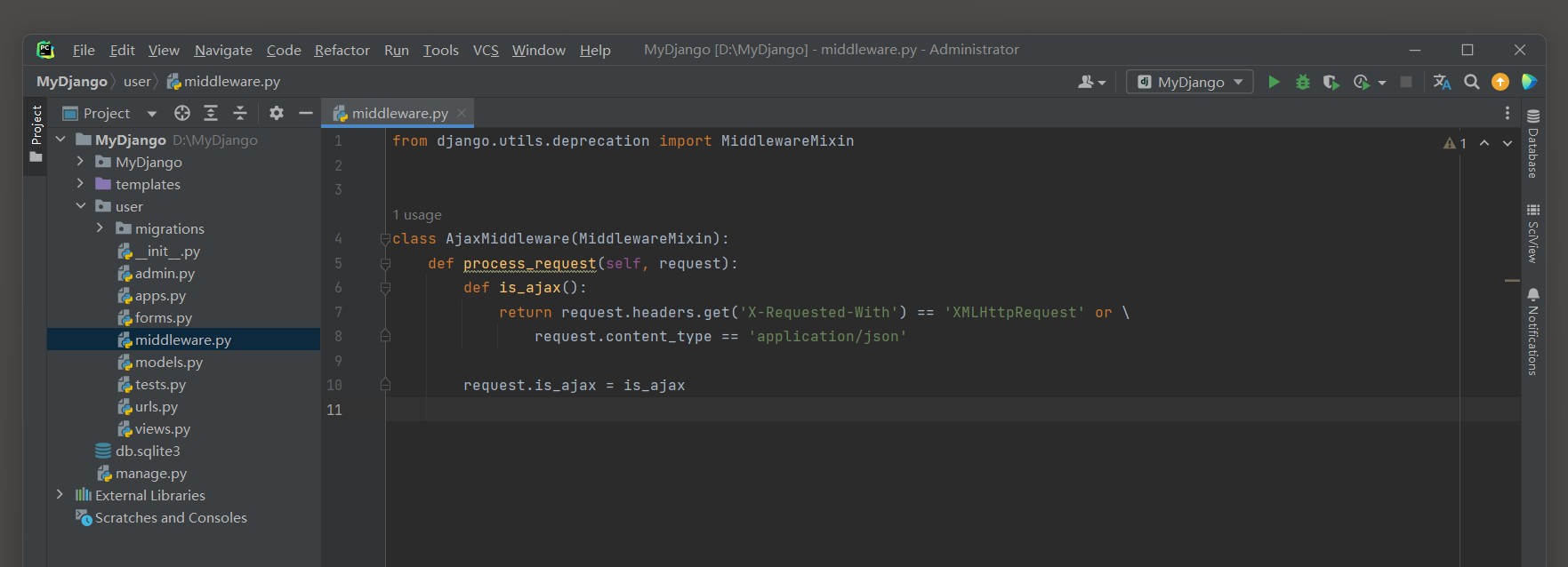
可以使用Django的中间件来添加自己的is_ajax ( ) 方法 .
from django. utils. deprecation import MiddlewareMixinclass AjaxMiddleware ( MiddlewareMixin) : def process_request ( self, request) : def is_ajax ( ) : return request. headers. get( 'X-Requested-With' ) == 'XMLHttpRequest' or \request. content_type == 'application/json' request. is_ajax = is_ajax
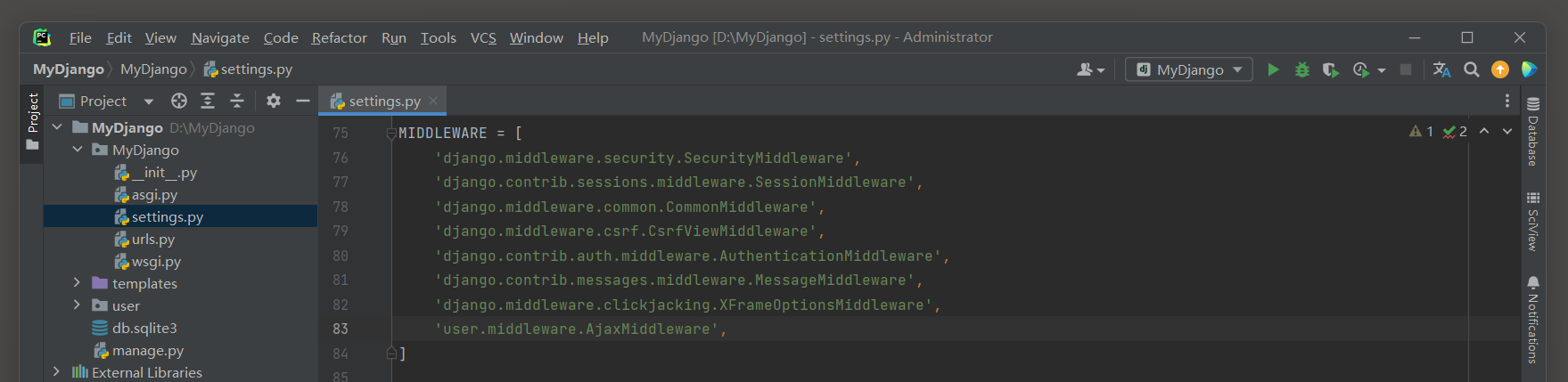
MIDDLEWARE = [ 'user.middleware.AjaxMiddleware' ,
]
在以上代码中 , AjaxMiddleware中间件会给每个request对象添加一个is_ajax属性 , 可以像以前一样使用 request . is_ajax ( ) .
视图函数login根据不同的请求方式执行不同的处理 , 如果用户发送GET请求 ,
视图函数loginView就使用表单类CaptchaTestForm生成带验证码的用户登录页面 ;
如果用户发送POST请求 , 视图函数login就将请求参数传递给表单类CaptchaTestForm ,
通过表单的实例化对象调用Auth认证系统 , 完成用户登录过程 .
视图函数ajax_val判断用户是否通过AJAX方式发送HTTP请求 , 判断方法由请求对象request调用函数is_ajax .
如果当前请求由AJAX发送 , 视图函数ajax_val就获取请求参数response和hashkey ,
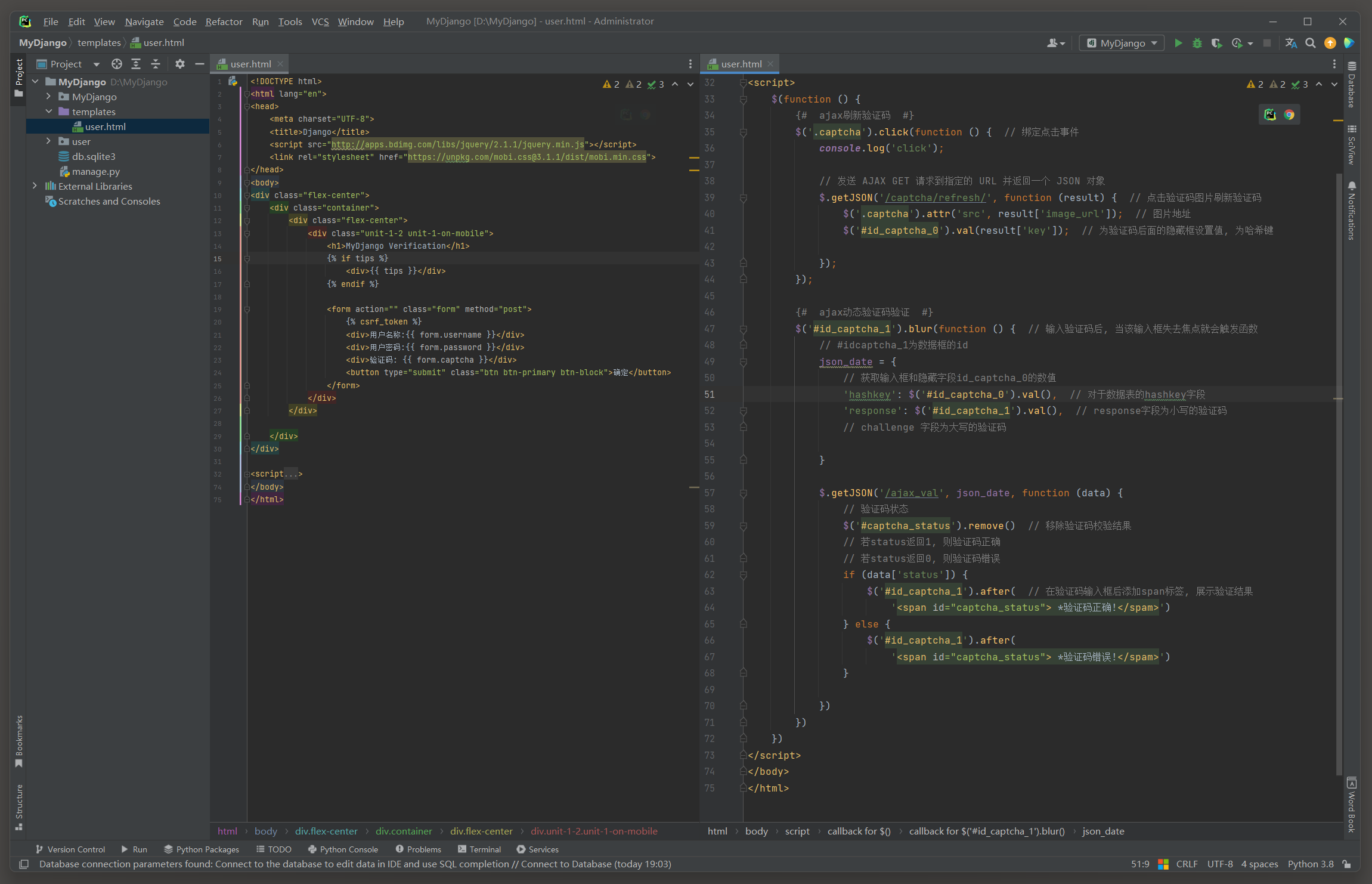
并将请求参数与Django Simple Captcha的模型CaptchaStore进行匹配 , 若匹配成功 , 则说明用户输入的验证码是正确的 , 否则是错误的 . 最后在模板文件user . html中编写用户登录页面的HTML代码和AJAX的请求过程 ,
AJAX的请求过程分别实现验证码的动态刷新和动态验证 . 模板文件user . html的代码如下 :
<! DOCTYPE html > < htmllang = " en" > < head> < metacharset = " UTF-8" > < title> </ title> < scriptsrc = " http://apps.bdimg.com/libs/jquery/2.1.1/jquery.min.js" > </ script> < linkrel = " stylesheet" href = " https://unpkg.com/mobi.css@3.1.1/dist/mobi.min.css" > </ head> < body> < divclass = " flex-center" > < divclass = " container" > < divclass = " flex-center" > < divclass = " unit-1-2 unit-1-on-mobile" > < h1> </ h1> < div> </ div> < formaction = " " class = " form" method = " post" > < div> </ div> < div> </ div> < div> </ div> < buttontype = " submit" class = " btn btn-primary btn-block" > </ button> </ form> </ div> </ div> </ div> </ div> < script> $ ( function ( ) { { # ajax刷新验证码 #} $ ( '.captcha' ) . click ( function ( ) { console. log ( 'click' ) ; $. getJSON ( '/captcha/refresh/' , function ( result ) { $ ( '.captcha' ) . attr ( 'src' , result[ 'image_url' ] ) ; $ ( '#id_captcha_0' ) . val ( result[ 'key' ] ) ; } ) ; } ) ; { # ajax动态验证码验证 #} $ ( '#id_captcha_1' ) . blur ( function ( ) { json_date = { 'hashkey' : $ ( '#id_captcha_0' ) . val ( ) , 'response' : $ ( '#id_captcha_1' ) . val ( ) , } $. getJSON ( '/ajax_val' , json_date, function ( data ) { $ ( '#captcha_status' ) . remove ( ) if ( data[ 'status' ] ) { $ ( '#id_captcha_1' ) . after ( '<span id="captcha_status"> *验证码正确!</spam>' ) } else { $ ( '#id_captcha_1' ) . after ( '<span id="captcha_status"> *验证码错误!</spam>' ) } } ) } ) } )
</ script> </ body> </ html>
< div> < imgsrc = " /captcha/image/hashkey字段值/" alt = " captcha" class = " captcha" > < inputtype = " hidden" name = " captcha_0" value = " hashkey字段值" required = " " id = " id_captcha_0" autocomplete = " off" > < inputtype = " text" name = " captcha_1" required = " " id = " id_captcha_1" autocapitalize = " off" autocomplete = " off" autocorrect = " off" spellcheck = " false" > </ div>
至此 , 我们已完成网站验证码功能的开发 .
运行MyDjango , 访问 127.0 .0 .1 : 8000 即可看到带验证码的用户登录页面 .
单击图片验证码将触发AJAX请求 , Django动态刷新验证码图片 , 并在数据表captcha_captchastore中创建验证码信息 , 如图 12 - 9 所示 .
图 12 - 9 动态刷新验证码
在PyCharm里使用createsuperuser指令创建超级管理员账号 ( 账号和密码皆为admin ) ,
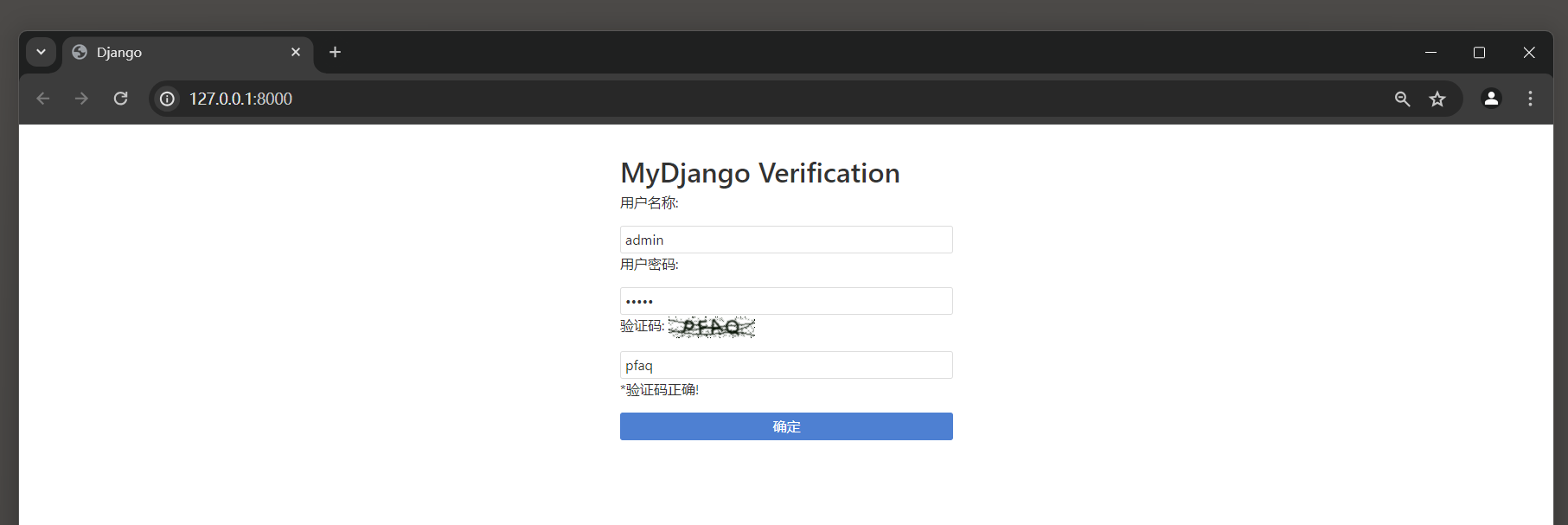
并在用户登录页面完成用户登录 , 如果在验证码文本框输入正确的验证码 , 那么单击页面某空白处将触发AJAX请求 ,
Django动态验证验证码是否正确 , 如图 12 - 10 所示 .
PS D: \MyDjango> python manage. py createsuperuser
Username ( leave blank to use 'blue' ) : admin
Email address: ( 回车)
Password: ( admin)
Password ( again) : ( admin)
The password is too similar to the username.
This password is too short. It must contain at least 8 characters.
This password is too common.
Bypass password validation and create user anyway? [ y/ N] : y
Superuser created successfully.
图 12 - 10 动态校对验证码
站内搜索是网站常用的功能之一 , 其作用是方便用户快速查找站内数据以便查阅 .
对于一些初学者来说 , 站内搜索可以使用SQL模糊查询实现 ,
从某个角度来说 , 这种实现方式只适用于个人小型网站 , 对于企业级的开发 , 站内搜索是由搜索引擎实现的 . Django Haystack是一个专门提供搜索功能的Django第三方应用 , 它支持Solr , Elasticsearch , Whoosh和Xapian等多种搜索引擎 ,
配合著名的中文自然语言处理库jieba分词可以实现全文搜索系统 .
本节在Whoosh搜索引擎和jieba分词的基础上使用Django Haystack实现网站搜索引擎 .
因此 , 在安装Django Haystack的过程中 , 需要自行安装Whoosh搜索引擎和jieba分词 , 具体的pip安装指令如下 :
pip install django- haystack
pip install whoosh
pip install jieba
pip install - i https: // pypi. tuna. tsinghua. edu. cn/ simple django- haystack
pip install - i https: // pypi. tuna. tsinghua. edu. cn/ simple whoosh
pip install - i https: // pypi. tuna. tsinghua. edu. cn/ simple whoosh jieba
django-haystack : 提供了全文搜索 , 即时搜索和地理空间搜索等功能 .
pip install whoosh : 用于Python的全文搜索引擎库 , 它提供了高效的文本搜索功能 .
pip install jieba : 用于中文文本的分词库 .
分词是将连续的文本切分成具有意义的词或短语的过程 , 这在中文自然语言处理中非常重要 , 因为中文的单词之间没有明显的分隔符 ( 如空格 ) .
完成上述模块的安装后 , 接着在MyDjango中搭建项目环境 .
在项目应用index中添加文件search_indexes . py和whoosh_cn_backend . py ,
在项目的根目录创建文件夹static和templates , static存放CSS样式文件 ,
templates存放模板文件search . html和搜索引擎文件product_text . txt , 其中product_text . txt需要存放在特定的文件夹里 .
整个MyDjango的目录结构如图 12 - 11 所示 .
图 12 - 11 MyDjango的目录结构
MyDjango的项目环境创建了多个文件和文件夹 , 每个文件与文件夹负责实现不同的功能 , 详细说明如下 :
( 1 ) search_indexes . py : 定义模型的索引类 , 使模型的数据能被搜索引擎搜索 .
( 2 ) whoosh_cn_backend . py : 自定义的Whoosh搜索引擎文件 . 由于Whoosh不支持中文搜索 , 因此重新定义Whoosh搜索引擎文件 , 将jieba分词器添加到搜索引擎中 , 使得它具有中文搜索功能 .
( 3 ) static : 存放模板文件search . html的网页样式common . css和search . css .
( 4 ) search . html : 搜索页面的模板文件 , 用于生成网站的搜索页面 .
( 5 ) product_text . txt : 搜索引擎的索引模板文件 , 模板文件命名以及路径有固定格式 , 如 / templates / search / indexes / 项目应用的名称 / 模型名称 ( 小写 ) _text . txt .
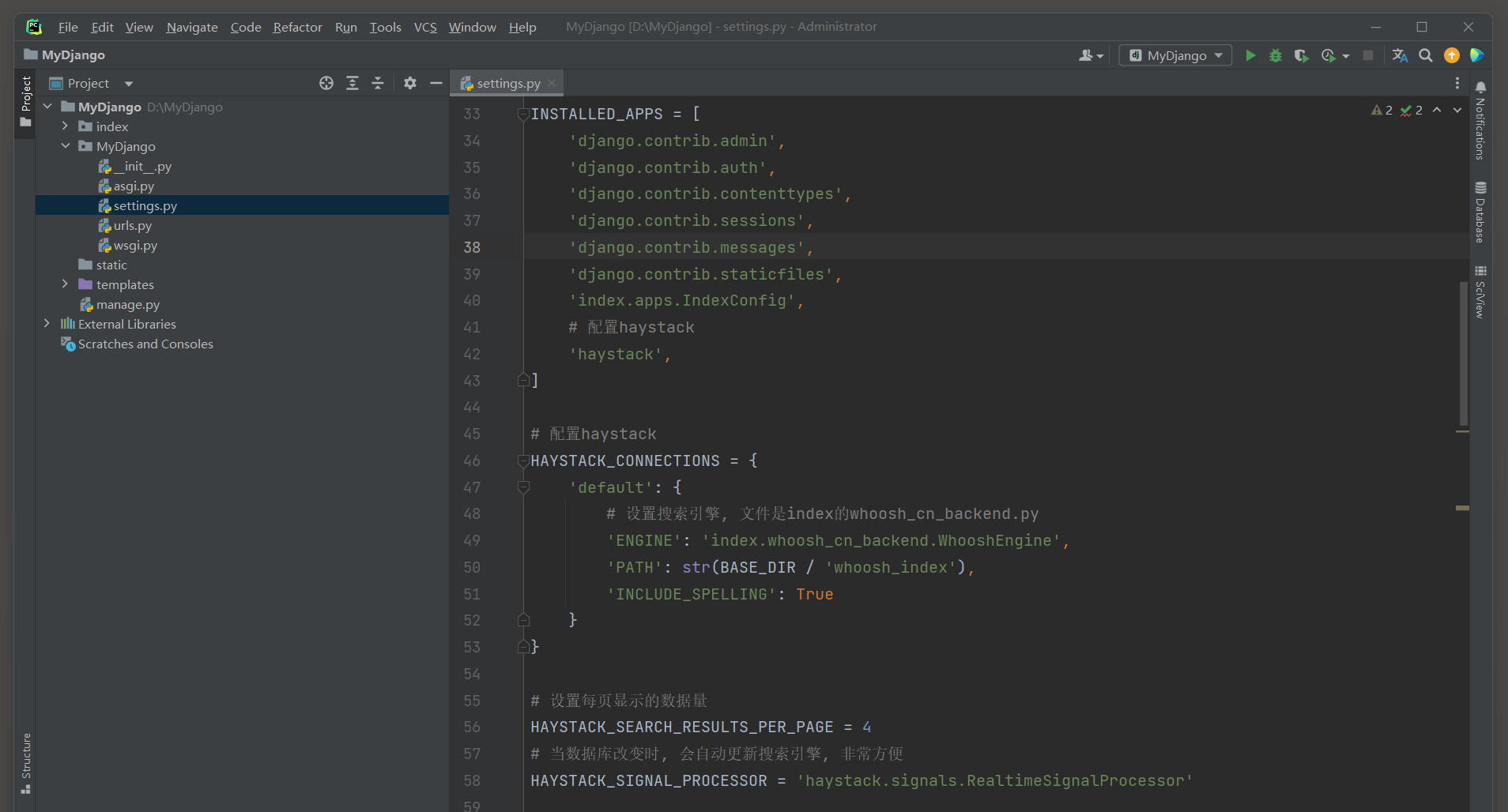
完成MyDjango的环境搭建后 , 下一步在settings . py中配置站内搜索引擎Django Haystack .
在INSTALLED_APPS中引入Django Haystack以及设置该应用的功能配置 , 具体的配置信息如下 :
INSTALLED_APPS = [ 'django.contrib.admin' , 'django.contrib.auth' , 'django.contrib.contenttypes' , 'django.contrib.sessions' , 'django.contrib.messages' , 'django.contrib.staticfiles' , 'index.apps.IndexConfig' , 'haystack' ,
]
HAYSTACK_CONNECTIONS = { 'default' : { 'ENGINE' : 'index.whoosh_cn_backend.WhooshEngine' , 'PATH' : str ( BASE_DIR / 'whoosh_index' ) , 'INCLUDE_SPELLING' : True }
}
HAYSTACK_SEARCH_RESULTS_PER_PAGE = 4
HAYSTACK_SIGNAL_PROCESSOR = 'haystack.signals.RealtimeSignalProcessor'
除了Django Haystack的功能配置之外 , 还需要配置项目的静态资源文件夹static .
STATIC_URL = 'static/'
STATICFILES_DIRS = [ BASE_DIR / 'static' ,
]
观察上述配置可以发现 , 配置属性HAYSTACK_CONNECTIONS的ENGINE指向项目应用index的whoosh_cn_backend . py文件的WhooshEngine类 ,
该类的属性backend和query分别指向WhooshSearchBackend和WhooshSearchQuery , 这是Whoosh搜索引擎的定义过程 .
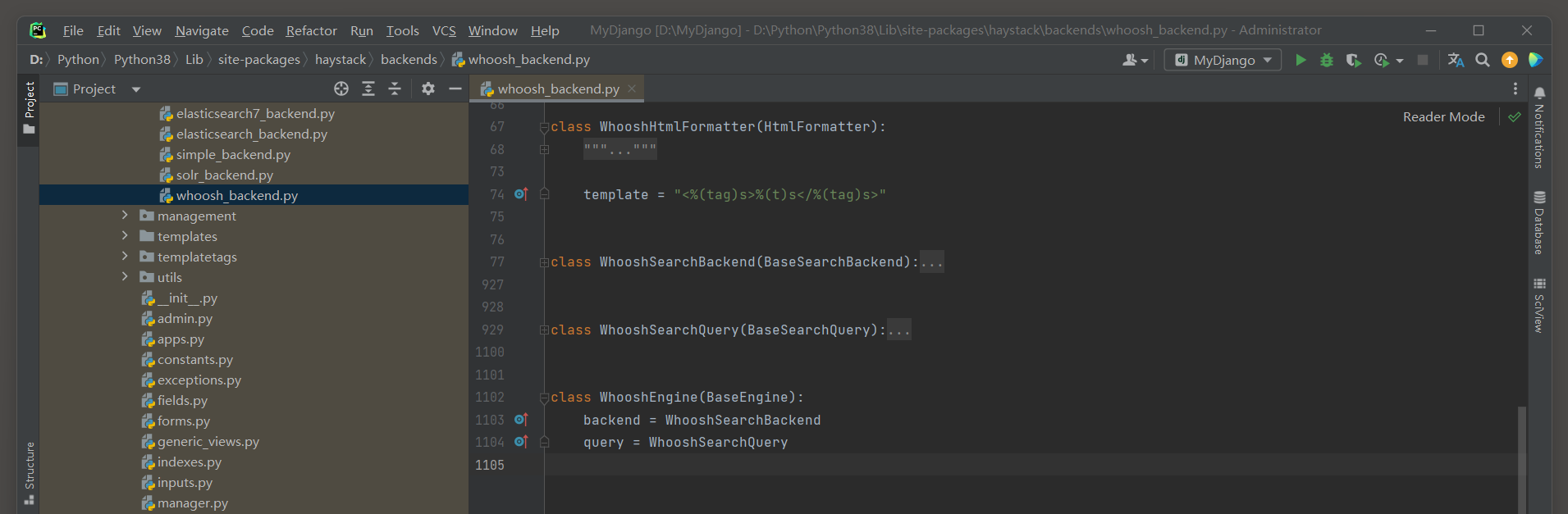
在Python的安装目录中可以找到Whoosh源码文件whoosh_backend . py , 如图 12 - 12 所示 .
图 12 - 12 源码文件whoosh_backend . py
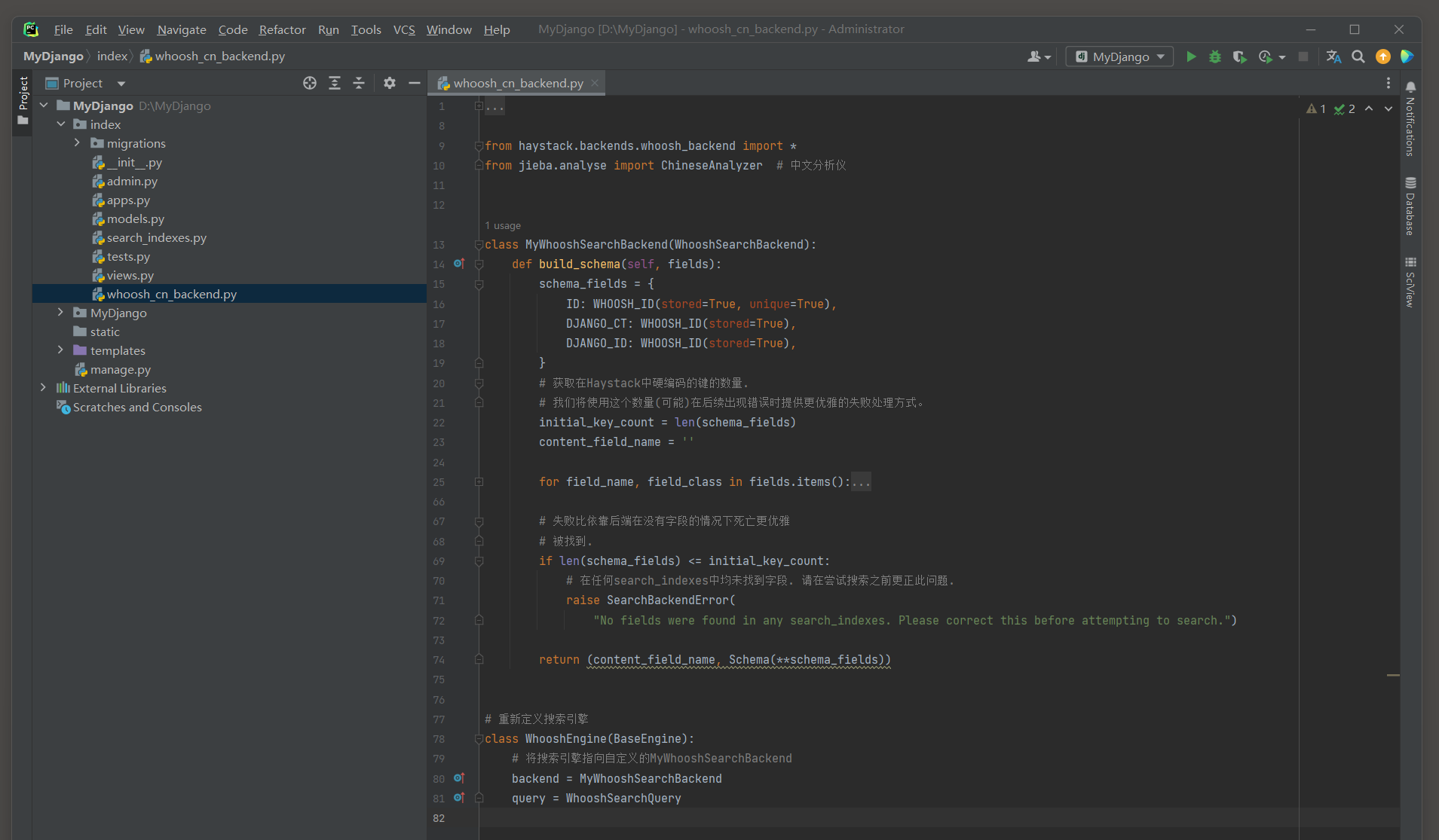
我们在项目应用index的whoosh_cn_backend . py中重新定义WhooshEngine , 类属性backend指向自定义的MyWhooshSearchBackend ,
然后重写MyWhooshSearchBackend的类方法build_schema , 在类方法build_schema的功能上加入jieba分词 , 使其支持中文搜索 .
因此 , 在index的whoosh_cn_backend . py中定义MyWhooshSearchBackend和WhooshEngine , 定义过程如下 :
from haystack. backends. whoosh_backend import *
from jieba. analyse import ChineseAnalyzer class MyWhooshSearchBackend ( WhooshSearchBackend) : def build_schema ( self, fields) : schema_fields = { ID: WHOOSH_ID( stored= True , unique= True ) , DJANGO_CT: WHOOSH_ID( stored= True ) , DJANGO_ID: WHOOSH_ID( stored= True ) , } initial_key_count = len ( schema_fields) content_field_name = '' for field_name, field_class in fields. items( ) : if field_class. is_multivalued: if field_class. indexed is False : schema_fields[ field_class. index_fieldname] = IDLIST( stored= True , field_boost= field_class. boost) else : schema_fields[ field_class. index_fieldname] = KEYWORD( stored= True , commas= True , scorable= True , field_boost= field_class. boost) elif field_class. field_type in [ 'date' , 'datetime' ] : schema_fields[ field_class. index_fieldname] = DATETIME( stored= field_class. stored, sortable= True ) elif field_class. field_type == 'integer' : schema_fields[ field_class. index_fieldname] = NUMERIC( stored= field_class. stored, numtype= int , field_boost= field_class. boost) elif field_class. field_type == 'float' : schema_fields[ field_class. index_fieldname] = NUMERIC( stored= field_class. stored, numtype= float , field_boost= field_class. boost) elif field_class. field_type == 'boolean' : schema_fields[ field_class. index_fieldname] = BOOLEAN( stored= field_class. stored) elif field_class. field_type == 'ngram' : schema_fields[ field_class. index_fieldname] = NGRAM( minsize= 3 , maxsize= 15 , stored= field_class. stored, field_boost= field_class. boost) elif field_class. field_type == 'edge_ngram' : schema_fields[ field_class. index_fieldname] = NGRAMWORDS( minsize= 2 , maxsize= 15 , at= 'start' , stored= field_class. stored, field_boost= field_class. boost) else : schema_fields[ field_class. index_fieldname] = TEXT( stored= True , analyzer= ChineseAnalyzer( ) , field_boost= field_class. boost, sortable= True ) if field_class. document is True : content_field_name = field_class. index_fieldnameschema_fields[ field_class. index_fieldname] . spelling = True if len ( schema_fields) <= initial_key_count: raise SearchBackendError( "No fields were found in any search_indexes. Please correct this before attempting to search." ) return ( content_field_name, Schema( ** schema_fields) )
class WhooshEngine ( BaseEngine) : backend = MyWhooshSearchBackendquery = WhooshSearchQuery
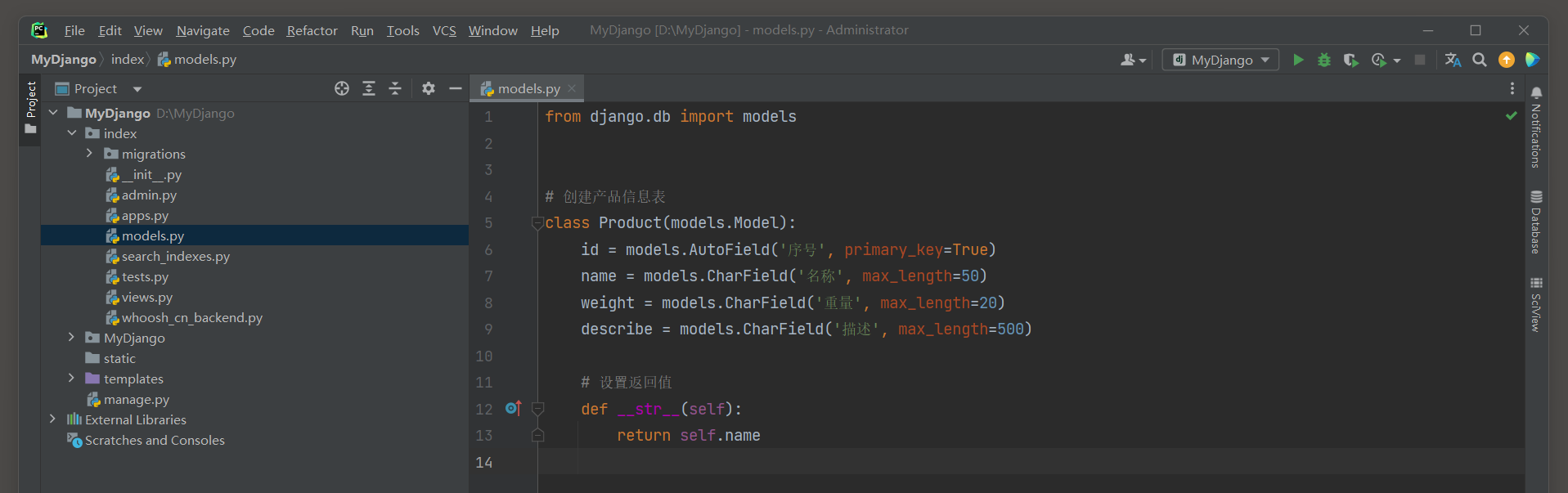
下一步在index的models . py中定义模型Product , 模型设有 4 个字段 , 主要记录产品的基本信息 , 如产品名称 , 重量和描述等 .
模型Product的定义过程如下 :
from django. db import models
class Product ( models. Model) : id = models. AutoField( '序号' , primary_key= True ) name = models. CharField( '名称' , max_length= 50 ) weight = models. CharField( '重量' , max_length= 20 ) describe = models. CharField( '描述' , max_length= 500 ) def __str__ ( self) : return self. name
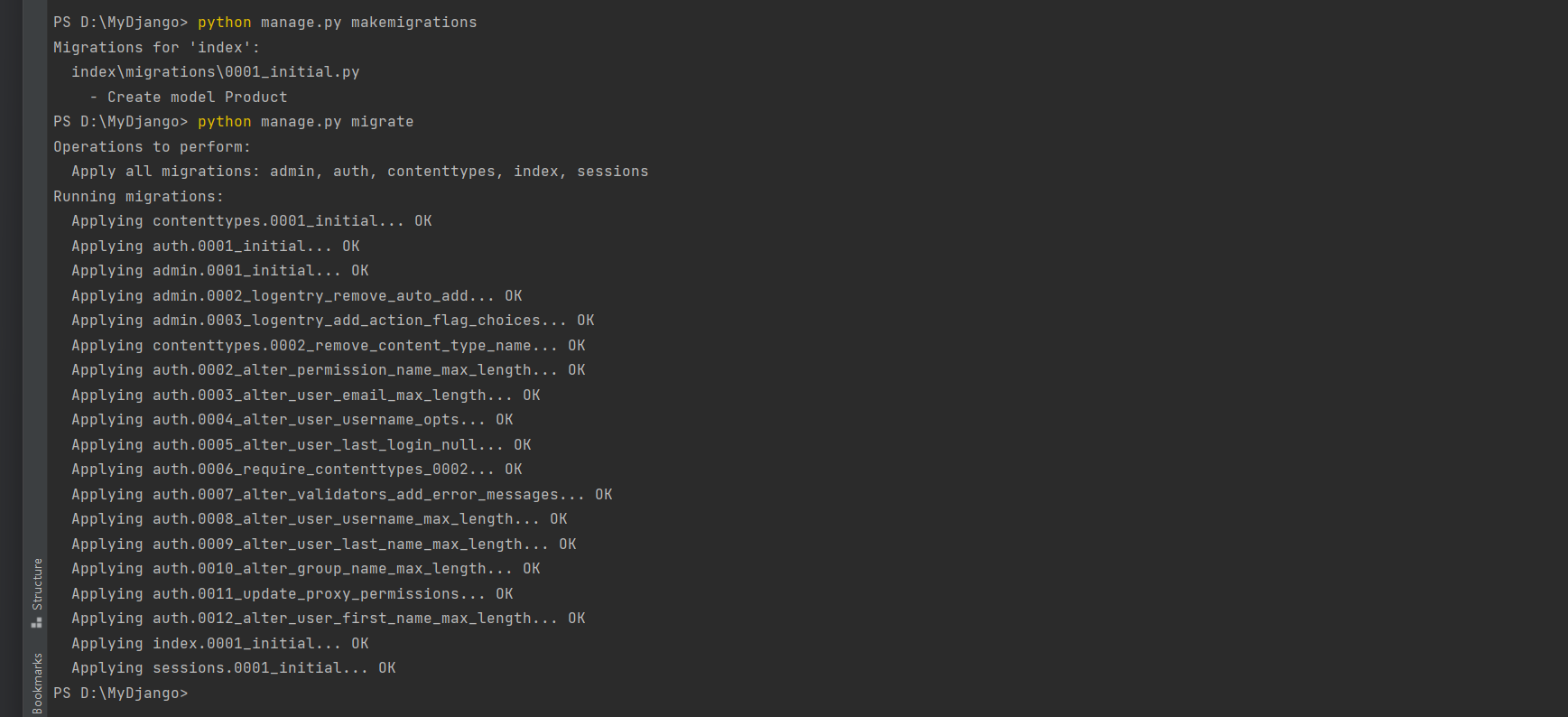
然后在PyCharm的Terminal中为MyDjango项目执行数据迁移 .
PS D: \MyDjango> python manage. py makemigrations
Migrations for 'index' : index\migrations\0001_initial. py- Create model Product
PS D: \MyDjango> python manage. py migrate
Operations to perform: Apply all migrations: admin, auth, contenttypes, index, sessions
Running migrations: . . .
使用Navicat Premium打开MyDjango的db . sqlite3数据库文件 , 在数据表index_product中添加产品信息 , 如图 12 - 13 所示 .
苹果 : 200 g , 苹果是常见的水果之一 , 具有丰富的营养价值 , 如维生素C和膳食纤维 . 苹果的品种多样 , 如红富士 , 嘎啦苹果等 .
香蕉 : 150 g , 香蕉是全球广泛种植的水果 , 以其独特的甜味和软糯的口感受到人们喜爱 . 香蕉富含钾元素 , 对维持人体正常生理功能有重要作用 .
橙子 : 150 g , 橙子富含维生素C , 有助于提高免疫力 . 橙子的品种繁多 , 如脐橙 , 血橙等 , 每种都有其独特的风味和营养价值 .
葡萄 : 15 g , 葡萄是一种广泛种植的水果 , 含有多种维生素和矿物质 , 葡萄除了鲜食外 , 还可以用于制作葡萄酒 , 葡萄干等食品 .
菠萝 : 1000 g , 菠萝是一种热带水果 , 具有独特的香甜味道和丰富的营养价值 . 菠萝中的菠萝蛋白酶有助于消化 , 对人体有益 .
草莓 : 33 g , 草莓是一种小而多汁的水果 , 富含维生素C和抗氧化物质 . 草莓的口感鲜美 , 常用于制作甜点 , 果汁等食品 .
西瓜 : 5000 g , 西瓜是夏季常见的水果 , 具有清凉解暑的作用 . 西瓜含有大量水分和糖分 , 能迅速补充人体所需的能量和水分 .
芒果 : 100 g , 芒果是一种热带水果 , 以其独特的香甜味道和丰富的营养价值受到人们喜爱 . 芒果富含维生素A和C , 有助于保护眼睛和皮肤健康 .
樱桃 : 20 g , 樱桃是一种小而甜美的水果 , 富含维生素C和铁元素 . 樱桃的口感鲜美 , 常用于制作甜点 , 果酱等食品 .
荔枝 : 28 g , 荔枝是一种热带水果 , 以其甜美的味道和独特的香气受到人们喜爱 . 荔枝富含维生素C和多种矿物质 , 对人体有益 .
INSERT INTO index_product ( name, weight, describe ) VALUES
( '苹果' , '200g' ,
'苹果是常见的水果之一, 具有丰富的营养价值, 如维生素C和膳食纤维. 苹果的品种多样, 如红富士, 嘎啦苹果等.' ) ,
( '香蕉' , '150g' ,
'香蕉是全球广泛种植的水果, 以其独特的甜味和软糯的口感受到人们喜爱. 香蕉富含钾元素, 对维持人体正常生理功能有重要作用.' ) ,
( '橙子' , '150g' ,
'橙子富含维生素C,
有助于提高免疫力. 橙子的品种繁多, 如脐橙, 血橙等, 每种都有其独特的风味和营养价值.' ) ,
( '葡萄' , '15g' ,
'葡萄是一种广泛种植的水果, 含有多种维生素和矿物质, 葡萄除了鲜食外, 还可以用于制作葡萄酒, 葡萄干等食品.' ) ,
( '菠萝' , '1000g' ,
'菠萝是一种热带水果, 具有独特的香甜味道和丰富的营养价值. 菠萝中的菠萝蛋白酶有助于消化, 对人体有益.' ) ,
( '草莓' , '33g' ,
'草莓是一种小而多汁的水果, 富含维生素C和抗氧化物质. 草莓的口感鲜美, 常用于制作甜点, 果汁等食品.' ) ,
( '西瓜' , '5000g' ,
'西瓜是夏季常见的水果, 具有清凉解暑的作用. 西瓜含有大量水分和糖分, 能迅速补充人体所需的能量和水分.' ) ,
( '芒果' , '100g' ,
'芒果是一种热带水果, 以其独特的香甜味道和丰富的营养价值受到人们喜爱. 芒果富含维生素A和C, 有助于保护眼睛和皮肤健康.' ) ,
( '樱桃' , '20g' ,
'樱桃是一种小而甜美的水果, 富含维生素C和铁元素. 樱桃的口感鲜美, 常用于制作甜点, 果酱等食品.' ) ,
( '荔枝' , '28g' ,
'荔枝是一种热带水果, 以其甜美的味道和独特的香气受到人们喜爱. 荔枝富含维生素C和多种矿物质, 对人体有益.' ) ;
图 12 - 13 数据表index_product
完成settings . py , whoosh_cn_backend . py和模型Product的配置和定义后 , 我们可以在MyDjango中实现站内搜索引擎的功能开发 .
首先创建搜索引擎的索引 , 创建索引主要能使搜索引擎快速找到符合条件的数据 ,
索引就像是书本的目录 , 可以为读者快速地查找内容 , 在这里也是同样的道理 .
当数据量非常大的时候 , 要从这些数据中找出所有满足搜索条件的数据是不太可能的 ,
并且会给服务器带来极大的负担 , 所以我们需要为指定的数据添加一个索引 . 索引是在search_indexes . py中定义的 , 然后由指令执行创建过程 .
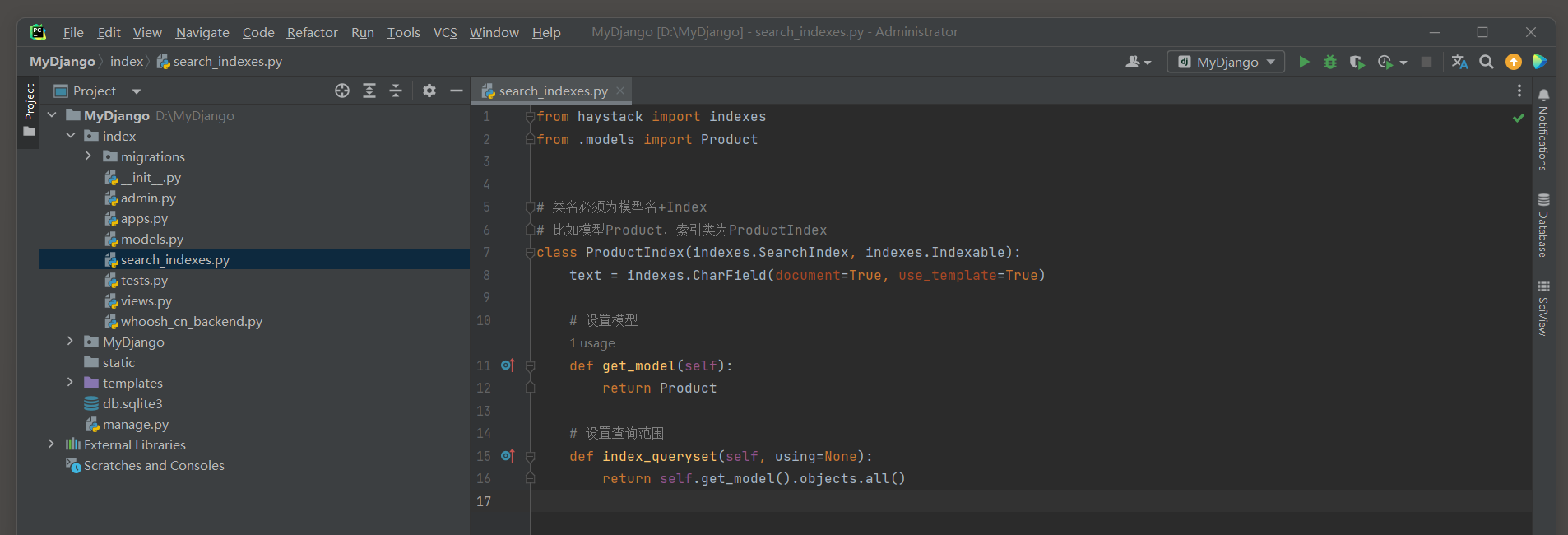
以模型Product为例 , 在search_indexes . py中定义该模型的索引类 , 代码如下 :
from haystack import indexes
from . models import Product
class ProductIndex ( indexes. SearchIndex, indexes. Indexable) : text = indexes. CharField( document= True , use_template= True ) def get_model ( self) : return Productdef index_queryset ( self, using= None ) : return self. get_model( ) . objects. all ( )
从上述代码来看 , 在定义模型的索引类ProductIndex时 , 类的定义要求以及定义说明如下 :
( 1 ) 定义索引类的文件名必须为search_indexes . py , 不得修改文件名 , 否则程序无法创建索引 .
( 2 ) 模型的索引类的类名格式必须为 "模型名+Index" , 每个模型对应一个索引类 , 如模型Product的索引类为ProductIndex .
( 3 ) 字段text设置document = True , 代表搜索引擎使用此字段的内容作为索引 . ( 在Haystack中 , 当定义多个搜索索引 ( 即多个继承自haystack . indexes . SearchIndex的类 ) 时 , Haystack期望每个索引类都有一个特殊的字段 , 这个字段用于存储文档的主要内容 , 以便进行全文搜索 . 这个字段通常被命名为text , 并且它被标记为document = True . )
( 4 ) use_template = True使用索引模板文件 , 可以理解为在索引中设置模型的查询字段 , 如设置Product的describe字段 , 这样可以通过describe的内容检索Product的数据 .
( 5 ) 类函数get_model是将该索引类与模型Product进行绑定 , 类函数index_queryset用于设置索引的查询范围 .
由上述分析得知 , use_template = True代表搜索引擎使用索引模板文件进行搜索 , 索引模板文件的路径是固定不变的 ,
路径格式为 / templates / search / indexes / 项目应用名称 / 模型名称 ( 小写 ) _text . txt ,
如MyDjango的templates / search / indexes / index / product_text . txt .
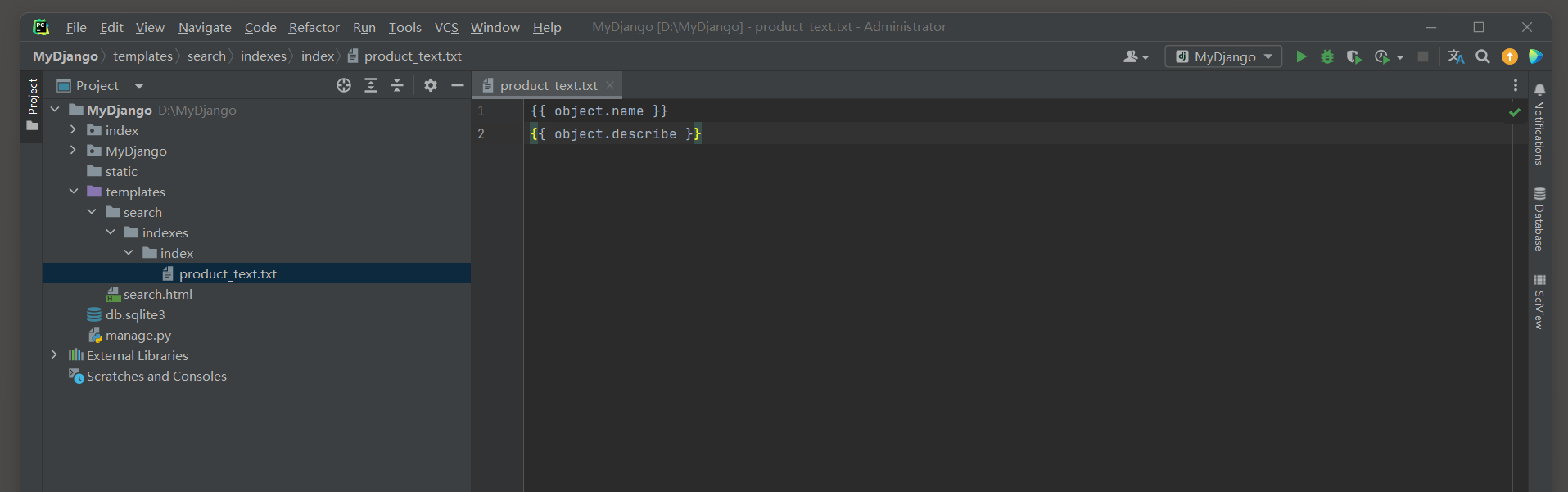
我们在索引模板文件product_text . txt中设置模型Product的字段name和describe作为索引的检索字段 ,
因此在索引模板文件product_text . txt中编写以下代码 :
{ { object . name } }
{ { object . describe } }
上述设置是对模型Product的字段name和describe建立索引 , 当搜索引擎进行搜索时 ,
Django根据搜索条件对这两个字段进行全文检索匹配 , 然后将匹配结果排序并返回 .
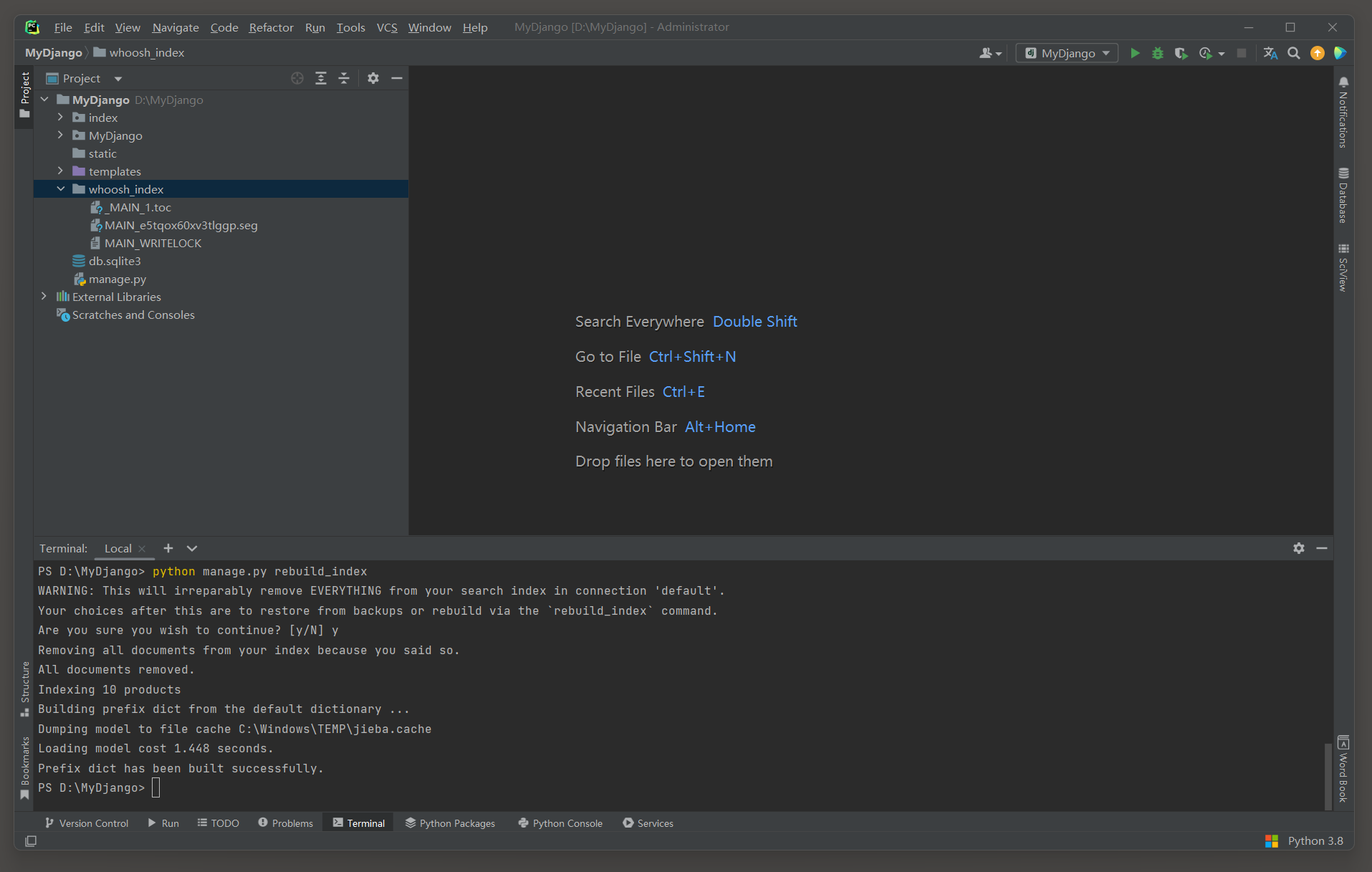
现在只是定义了搜索引擎的索引类和索引模板文件 , 下一步根据索引类和索引模板文件创建搜索引擎的索引文件 .
在PyCharm的Terminal中运行 : python manage . py rebuild_index , 指令即可完成索引文件的创建 ,
MyDjango的根目录自动创建whoosh_index文件夹 , 该文件夹中含有索引文件 , 如图 12 - 14 所示 .
PS D: \MyDjango> python manage. py rebuild_index
WARNING: This will irreparably remove EVERYTHING from your search index in connection 'default' .
Your choices after this are to restore from backups or rebuild via the `rebuild_index` command.
Are you sure you wish to continue ? [ y/ N] y
Removing all documents from your index because you said so.
All documents removed.
Indexing 10 products
Building prefix dict from the default dictionary . . .
Dumping model to file cache C: \Windows\TEMP\jieba. cache
Loading model cost 1.448 seconds.
Prefix dict has been built successfully.
当运行 : python manage . py rebuild_index 命令时 , 正在尝试重建 Django 项目中使用的搜索索引 .
该命令会清空 ( 或删除 ) 当前的索引 , 然后重新创建它 , 以便从数据库或其他数据源中重新填充数据 . 输出中 , 会有一个警告信息 , 提示这个操作会不可逆地删除所有在默认连接 ( 'default' ) 上的搜索索引内容 .
这是非常重要的 , 因为一旦索引被清空 , 除非你有备份 , 否则你将无法恢复它 . 如果确定要继续并清空索引 , 应该输入 y并按回车键 . 如果你不想继续 , 只需按回车键或输入任何非 y 的字符 .
图 12 - 14 whoosh_index文件夹
最后在MyDjango中实现模型Product的搜索功能 , 在MyDjango的urls . py和index的urls . py中定义路由haystack , 代码如下 :
from django. urls import path, includeurlpatterns = [ path( '' , include( ( 'index.urls' , 'index' ) , namespace= 'index' ) ) ,
]
from django. urls import path
from . views import MySearchurlpatterns = [ path( '' , MySearch( ) , name= 'haystack' ) ,
]
路由haystack指向视图类MySearch , 视图类MySearch继承Django Haystack定义的视图类SearchView ,
它与Django内置视图类的定义过程十分相似 , 本书就不再深入分析视图类SearchView的定义过程 ,
我们在index的views . py中定义视图MySearch , 并且重写父类的方法get ( ) ,
这是自定义视图类MySearch接收HTTP的GET请求的响应内容 , 实现代码如下 :
from django. core. paginator import *
from django. shortcuts import render
from django. conf import settings
from . models import Product
from haystack. generic_views import SearchView
class MySearch ( SearchView) : template_name = 'search.html' def get ( self, request, * args, ** kwargs) : if not self. request. GET. get( 'q' , ) : product = Product. objects. all ( ) . order_by( 'id' ) per = settings. HAYSTACK_SEARCH_RESULTS_PER_PAGE p = Paginator( product, per) try : num = int ( self. request. GET. get( 'page' , 1 ) ) page_obj = p. page( num) except PageNotAnInteger: page_obj = p. page( 1 ) except EmptyPage: page_obj = p. page( p. num_pages) return render( request, self. template_name, locals ( ) ) else : return super ( ) . get( * args, request, * args, ** kwargs) 修改一下 , 页码使用内置的get_page方法获取 .
from django. core. paginator import *
from django. shortcuts import render
from django. conf import settings
from . models import Product
from haystack. generic_views import SearchView
class MySearch ( SearchView) : template_name = 'search.html' def get ( self, request, * args, ** kwargs) : if not self. request. GET. get( 'q' , ) : product = Product. objects. all ( ) . order_by( 'id' ) per = settings. HAYSTACK_SEARCH_RESULTS_PER_PAGE p = Paginator( product, per) num = int ( self. request. GET. get( 'page' , 1 ) ) page_obj = p. get_page( num) return render( request, self. template_name, locals ( ) ) else : return super ( ) . get( * args, request, * args, ** kwargs)
视图类MySearch指定模板文件search . html作为HTML网页文件 ;
并且自定义GET请求的处理函数get ( ) , 通过判断当前请求是否存在请求参数q ,
若不存在 , 则将模型Product的全部数据进行分页显示 , 否则使用搜索引擎全文搜索模型Product的数据 .
模板文件search . html用于显示搜索结果的数据 , 网页实现的功能包括搜索文本框 , 产品信息列表和产品信息分页 .
模板文件search . html的代码如下 :
<! DOCTYPE html > < htmllang = " en" > < head> < metacharset = " UTF-8" > < title> </ title> < linkrel = " stylesheet" href = " {% static " common.css" %}" > < linkrel = " stylesheet" href = " {% static " search.css" %}" > </ head> < body> < divclass = " header" > < divclass = " search-box" > < formaction = " " method = " get" > < divclass = " search-keyword" > < inputname = " q" type = " text" class = " keyword" > </ div> < inputtype = " submit" class = " search-button" value = " 搜 索" > </ form> </ div> </ div> < divclass = " wrapper clearfix" > < divclass = " listinfo" > < ulclass = " listheader" > < liclass = " name" > </ li> < liclass = " weight" > </ li> < liclass = " describe" > </ li> </ ul> < ulclass = " ullsit" > < li> < divclass = " item" > < divclass = " nameinfo" > </ div> < divclass = " weightinfo" > </ div> < divclass = " describeinfo" > </ div> </ div> </ li> < li> < divclass = " item" > < divclass = " nameinfo" > </ div> < divclass = " weightinfo" > </ div> < divclass = " describeinfo" > </ div> </ div> </ li> </ ul> < divclass = " page-box" > < divclass = " pagebar" id = " pageBar" > < ahref = " {% url 'index:haystack' %}?q={{ query }}&page={{ page_obj.previous_page_number }}" class = " prev" > </ a> < ahref = " {% url 'index:haystack' %}?page={{ page_obj.previous_page_number }}" class = " prev" > </ a> < spanclass = " sel" > </ span> < ahref = " {% url 'index:haystack' %}?q={{ query }}&page={{ num }}" > </ a> < ahref = " {% url 'index:haystack' %}?page={{ num }}" > </ a> < ahref = " {% url 'index:haystack' %}?q={{ query }}&page={{ page_obj.next_page_number }}" class = " next" > </ a> < ahref = " {% url 'index:haystack' %}?page={{ page_obj.next_page_number }}" class = " next" > </ a> </ div> </ div> </ div> </ div> </ body> </ html>
模板文件search . html分别使用了模板上下文page_obj , query和模板标签highlight , 具体说明如下 :
● page_obj来自视图类MySearch , 这是模型Product分页处理后的数据对象 .
● query来自Django Haystack定义的视图类SearchView , 它的值来自请求参数q , 即搜索文本框的内容 .
● Highlight是由Django Haystack定义的模板标签 , 它将用户输入的关键词进行高亮处理 .
( 搜索和高亮 : 代码包含一个判断逻辑 { % if query % } , 用于检查是否存在一个搜索查询 ( query ) .
如果存在查询 , 代码会导入一个名为highlight的模板标签库 ,
并使用 { % highlight . . . with query % } 来高亮显示与查询匹配的文本 .
这允许用户搜索列表中的对象 , 并快速识别出与搜索查询相关的部分 . )
至此 , 我们已完成站内搜索引擎的功能开发 .
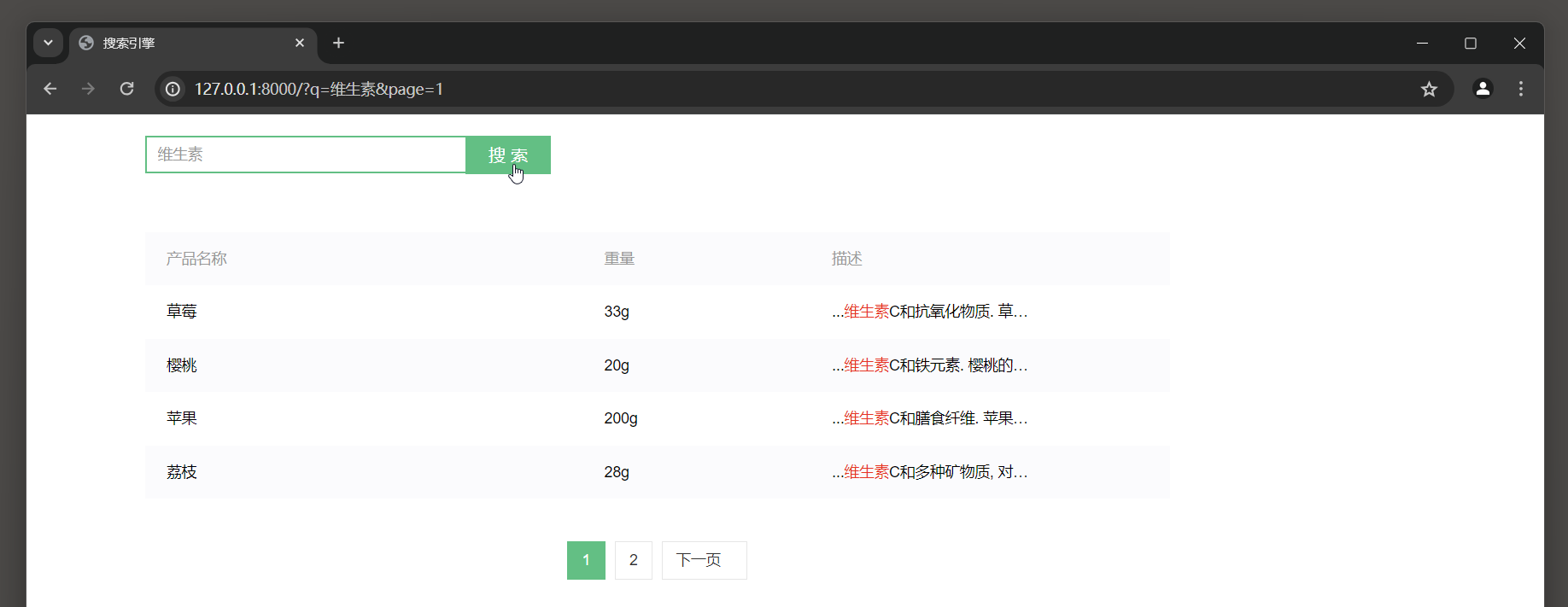
运行MyDjango并访问 : 127.0 .0 .1 : 8000 , 网页首先显示模型Product所有数据 , 当在搜索页面的文本框中输入 '维生素' , ( 至少两个字 )
并单击 '搜索' 按钮即可实现模型Product的字段name和describe的全文搜索 , 如图 12 - 15 所示 .
图 12 - 15 运行结果
( 跳过吧 , 没有说怎么登录 , 还不会弄 , 以后补上 ! ! ! )
用户注册与登录是网站必备的功能之一 , Django内置的Auth认证系统可以帮助开发人员快速实现用户管理功能 .
但很多网站为了加强社交功能 , 在用户管理功能上增设了第三方网站的用户注册与登录功能 , 这是通过OAuth 2.0 认证与授权来实现的 .
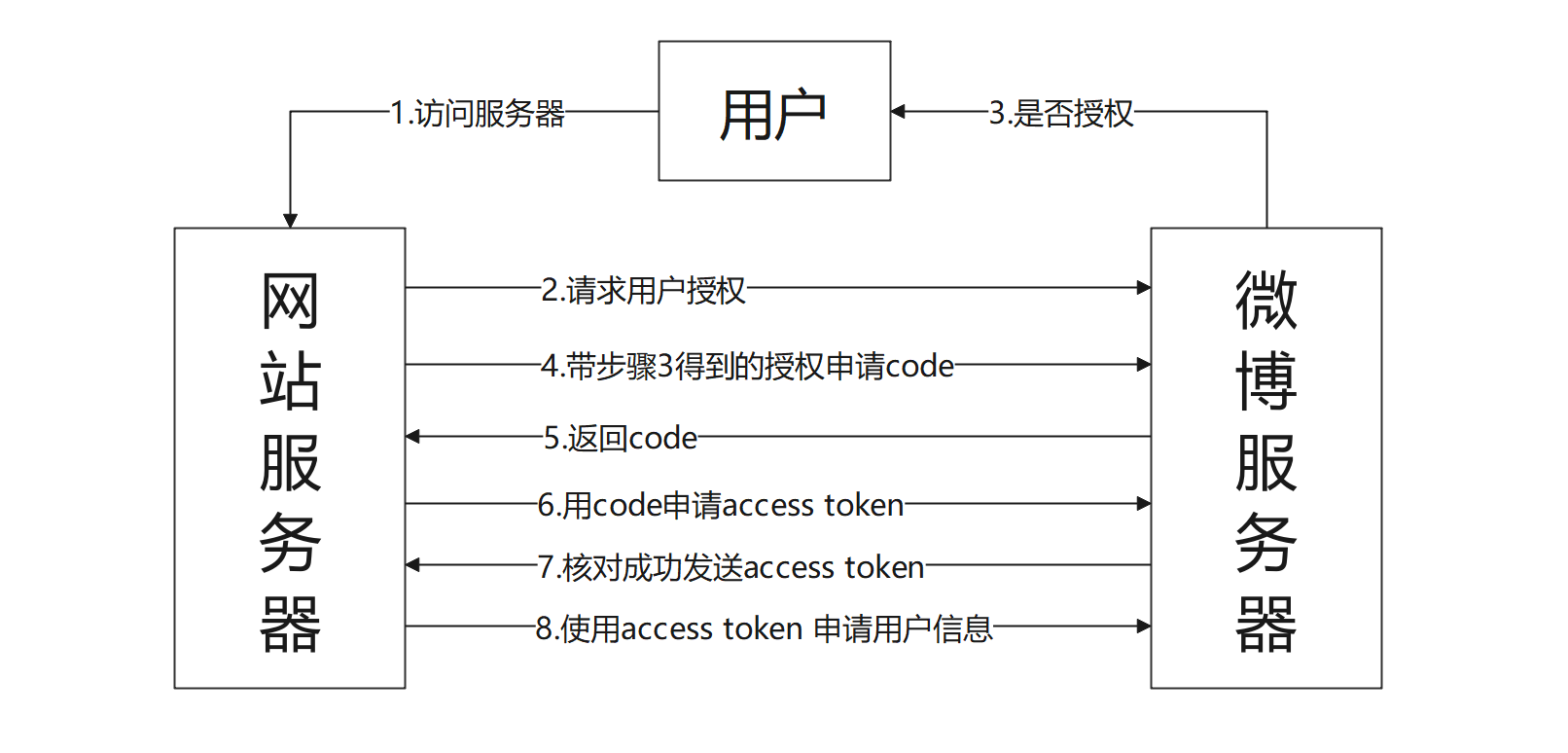
OAuth 2.0 的实现过程相对烦琐 , 我们通过流程图来大致了解OAuth 2.0 的实现过程 , 如图 12 - 16 所示 .
图 12 - 16 OAuth 2.0 的实现过程
分析图 12 - 16 的实现过程 , 我们可以简单理解OAuth 2.0 认证与授权是两个网站的服务器后台进行通信交流 .
根据实现原理 , 可以使用requests或urllib模块实现OAuth 2.0 认证与授权 , 从而实现第三方网站的用户注册与登录功能 .
但是一个网站可能同时使用多个第三方网站 , 这种实现方式就不太可取 , 而且代码会出现重复使用的情况 .
因此 , 我们可以使用Django第三方功能应用Social-Auth-App-Django , 它为我们提供了各大网站平台的认证与授权功能 .
Social-Auth-App-Django是在Python Social Auth的基础上进行封装而成的 , 而Python Social Auth支持多个Python的Web框架使用 ,
如Django , Flask , Pyramid , CherryPy和Webpy .
除了安装Social-Auth-App-Django之外 , 还需要安装Python Social Auth , 我们通过pip方式进行安装 , 安装指令如下 :
pip install python- social- auth
pip install social- auth- app- django
pip install social- auth- app- django- mongoengine
pip install - i https: // pypi. tuna. tsinghua. edu. cn/ simple python- social- auth
pip install - i https: // pypi. tuna. tsinghua. edu. cn/ simple social- auth- app- django
功能模块安装成功后 , 以MyDjango为例 , 讲述如何使用Social-Auth-App-Django实现第三方网站的用户注册 .
在MyDjango中创建项目应用user , 模板文件夹templates创建模板文件user . html , MyDjango的目录结构如图 12 - 17 所示 .
图 12 - 17 MyDjango的目录结构
MyDjango的目录结构较为简单 , 因为Social-Auth-App-Django的本质是一个Django的项目应用 .
我们可以在Python的安装目录下找到Social-Auth-App-Django的源代码文件 ,
发现它具有urls . py , views . py和models . py等文件 , 这与Django的项目应用的文件架构是一样的 , 如图 12 - 18 所示 .
图 12 - 18 Social-Auth-App-Django的源码文件
了解Social-Auth-App-Django的本质 , 在后续的使用中可以更加清晰地知道它的实现过程 .
Social-Auth-App-Django支持国内外多个网站认证 ,
可以在官方文档中查阅网站认证信息 ( https : / / python-social-auth . readthedocs . io / en / latest / ) .
( https : / / python-social-auth . readthedocs . io / en / latest / index . html )
本节以微博为例 , 通过微博认证实现MyDjango的用户注册功能 .
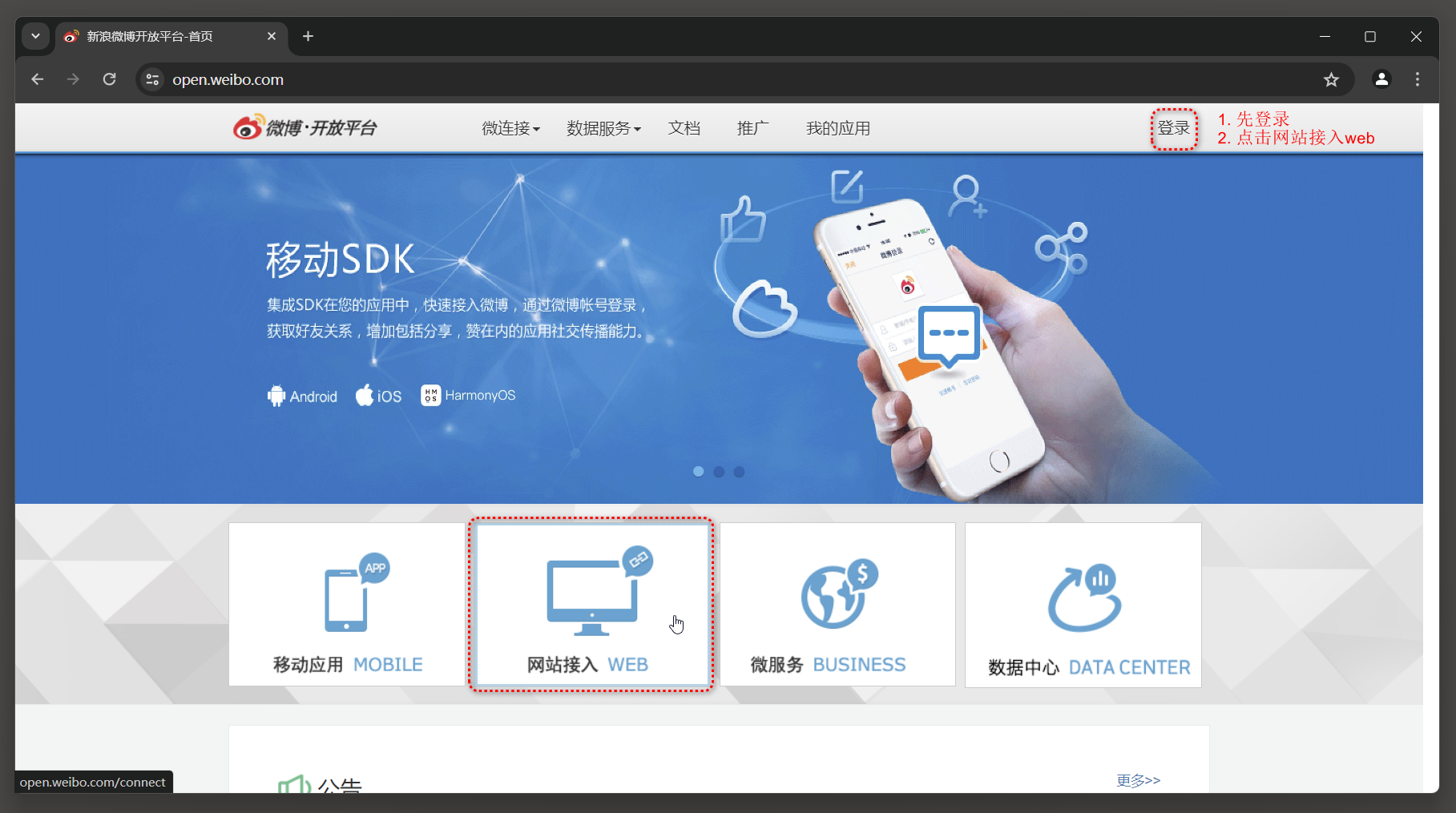
首先在浏览器中打开微博开放平台 ( http : / / open . weibo . com / ) , 登录微博并新建网站接入应用 , 如图 12 - 19 所示 .
* 1. 先登录 .
* 2. 点击网站接入WEB .
图 12 - 19 新建网站接入应用
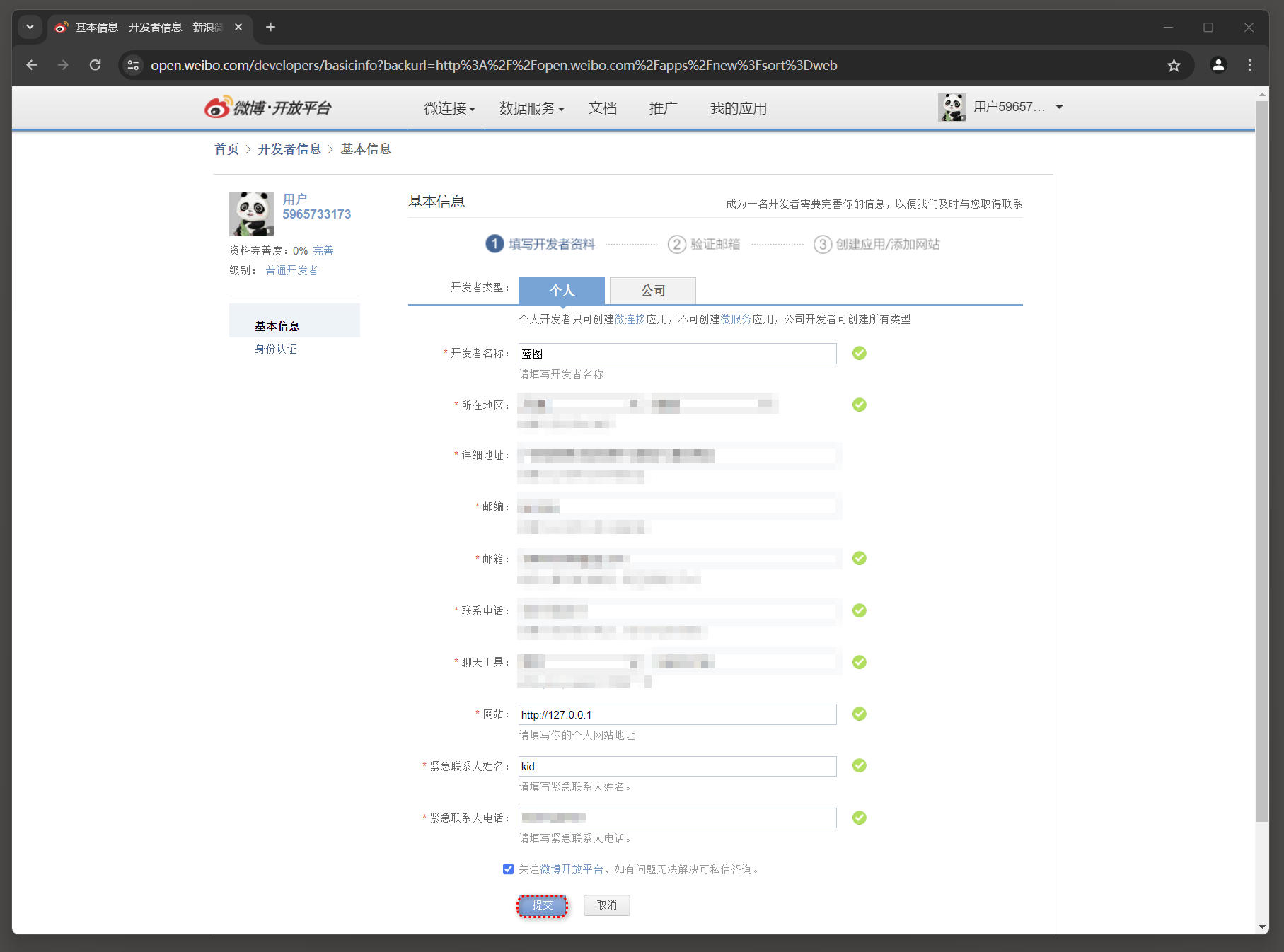
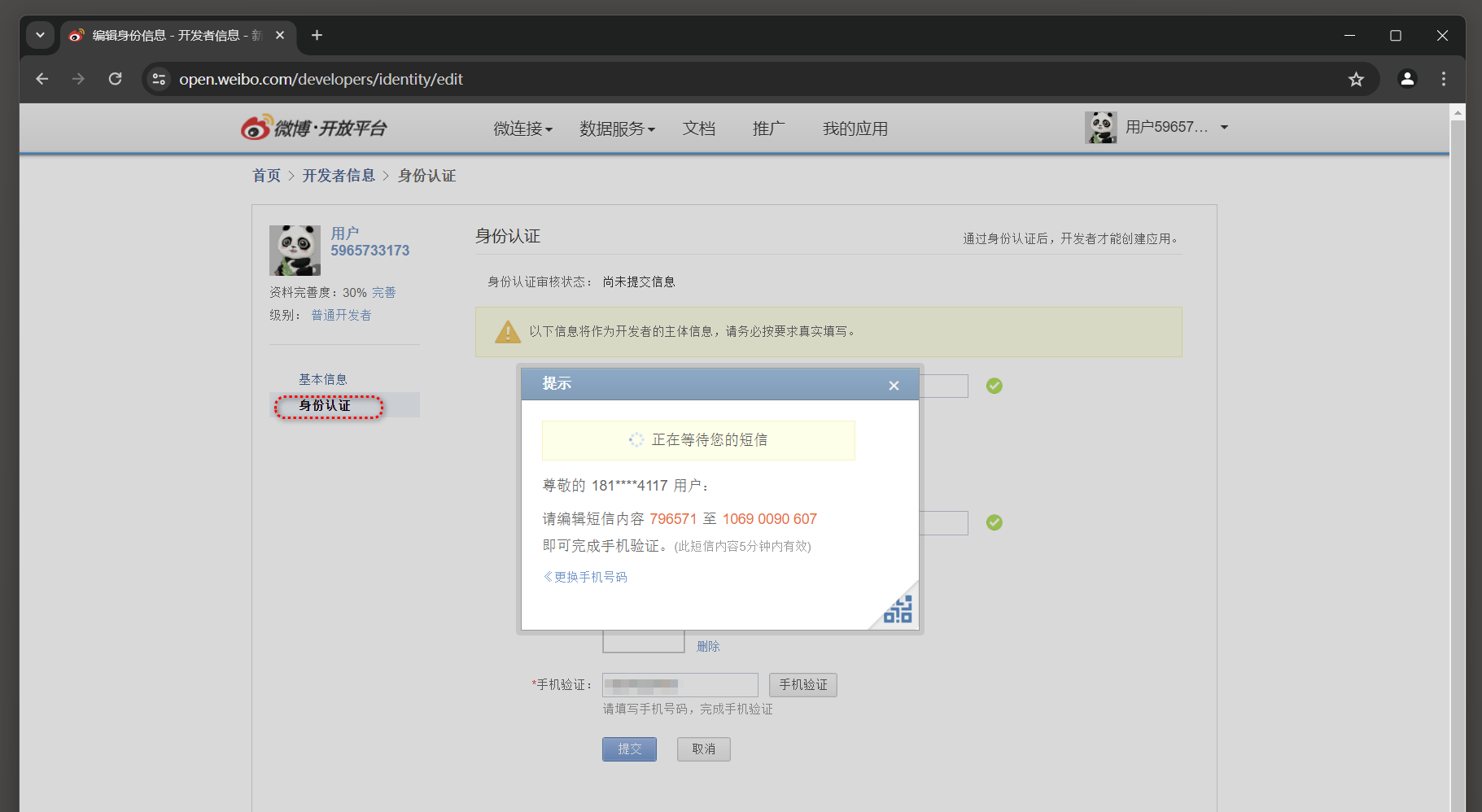
* 3. 填写基本信息和身份认证 .
* 4. 打开邮箱 , 点击完成确认注册的连接 .
* 5. 完成身份验证 .
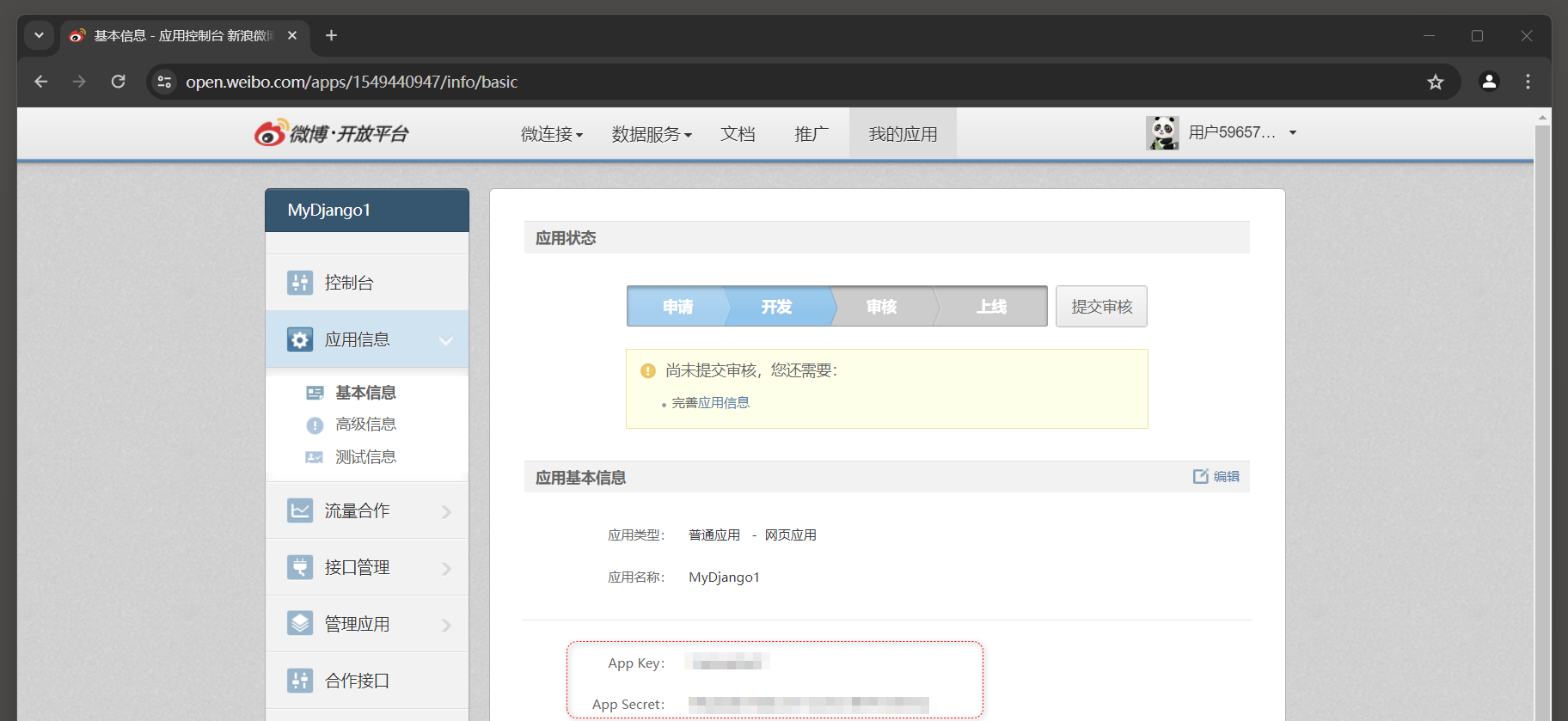
* 6. 创建新应用 . 我们将网站接入应用命名为MyDjango1 , 在网站接入应用的页面中找到 "应用信息" , 从中获取网站接入应用的App Key和App Secret , 如图 12 - 20 所示 .
* 7. 保存App Key和App Secret App Key : 154944094721 _21 App Secret : e96a606e700b33714c657d95937d937a21_21
图 12 - 20 应用信息
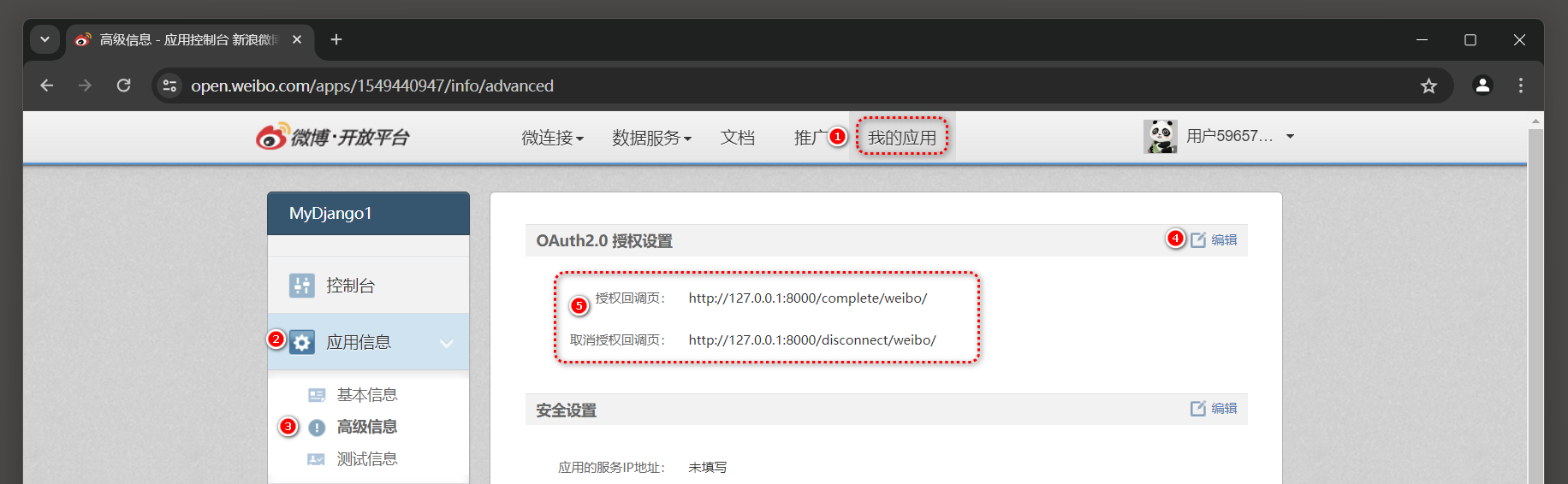
* 8. 设置OAuto2 . 0 授权设置 . 下一步设置网站接入应用的OAuth 2.0 授权设置 , 在 '应用信息' 的标签里单击 '高级信息' , 编辑OAuth 2.0 授权设置的授权回调页 , 如图 12 - 21 所示 . 授权回调页 : http : / / 127.0 .0 .1 : 8000 /complete/weibo/ 取消授权回调页 : http : / / 127.0 .0 .1 : 8000 /disconnect/weibo/
图 12 - 21 OAuth 2.0 授权设置
授权回调页和取消授权回调页的路由地址是有格式要求的 , 因为两者的执行过程是由Social-Auth-App-Django实现的 ,
而Social-Auth-App-Django的源码文件urls . py已为授权回调页和取消授权回调页设置具体的路由地址 .
打开源码文件urls . py , 查看路由定义过程 , 如图 12 - 22 所示 .
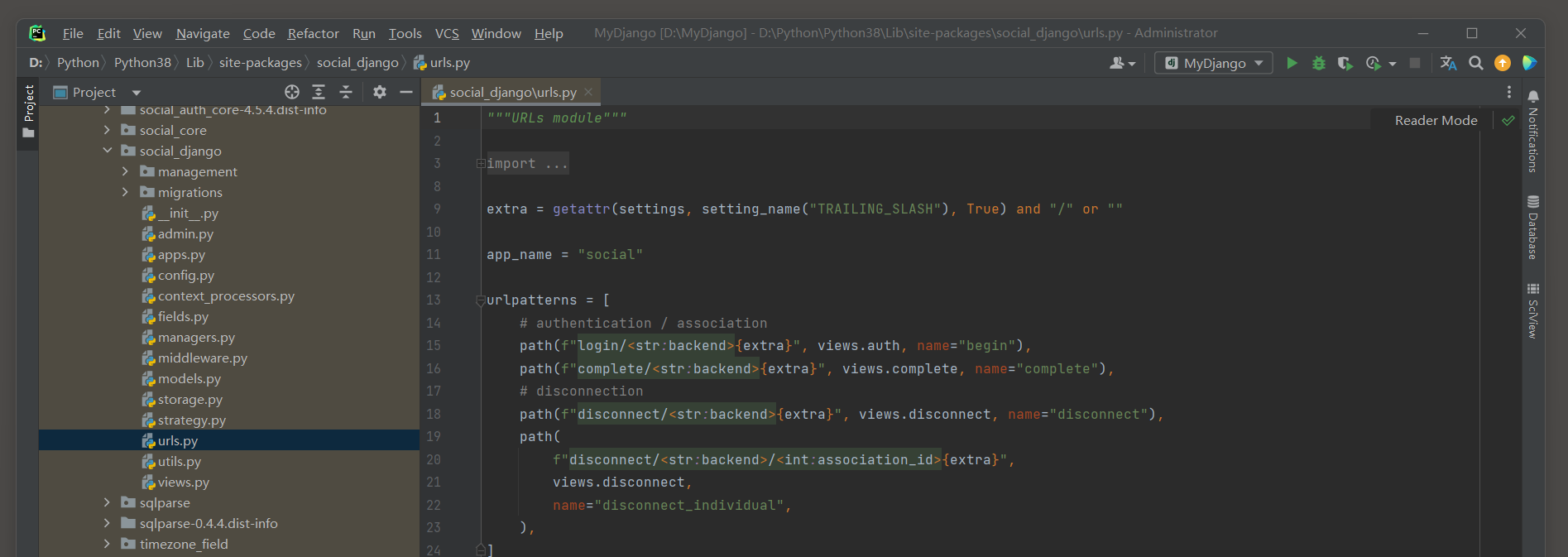
图 12 - 22 源码文件urls . py
( 每个路由的说明 :
* 1. 登录 / 关联路由 : path ( f "login/<str:backend>{extra}" , views . auth , name = "begin" ) URL模式 : login / 后面跟随一个字符串 ( : backend ) , 这个字符串可能是一个认证后端 ( 例如 : google , facebook等 ) . { extra } : 这里的 { extra } 是一个占位符 , 但它在您给出的代码段中并未定义 . 通常 , 它可能是为了后续添加额外的URL参数或模式 ( 例如 , 查询参数 , 可选的路径部分等 ) . 但在没有具体定义的情况下 , 它可能不会正常工作 . 视图函数 : views . auth是处理登录 / 关联逻辑的视图函数 . 名称 : 这个路由的URL名称是begin , 可以在Django模板或其他URL重定向中使用这个名称 . * 2. 完成路由 : path ( f "complete/<str:backend>{extra}" , views . complete , name = "complete" ) URL模式 : 与登录路由类似 , complete / 后面跟随一个字符串 ( : backend ) , 表示完成某个认证后端的流程 . 视图函数 : views . complete是处理认证后端完成逻辑的视图函数 . 名称 : 这个路由的URL名称是complete . * 3. 断开连接路由 : path ( f "disconnect/<str:backend>{extra}" , views . disconnect , name = "disconnect" ) URL模式 : disconnect / 后面跟随一个字符串 ( : backend ) , 表示断开与某个认证后端的连接。 视图函数 : views . disconnect是处理断开连接逻辑的视图函数 . 名称 : 这个路由的URL名称是disconnect . path ( f "disconnect/<str:backend>/<int:association_id>{extra}" , views . disconnect , name = "disconnect_individual" ) / URL模式 : 与上面的断开连接路由类似 , 但它还包含了一个整数 ( : association_id ) , 可能表示特定的关联ID , 用于断开与特定服务或用户的连接 . 视图函数 : 同样使用 views . disconnect 视图函数来处理逻辑 , 但这次它可能会根据提供的association_id来断开特定的连接 . 名称 : 这个路由的URL名称是disconnect_individual . )
源码文件urls . py的路由变量backend代表网站名称 , 如 / complete / weibo / 代表微博网站的OAuth 2.0 授权设置 .
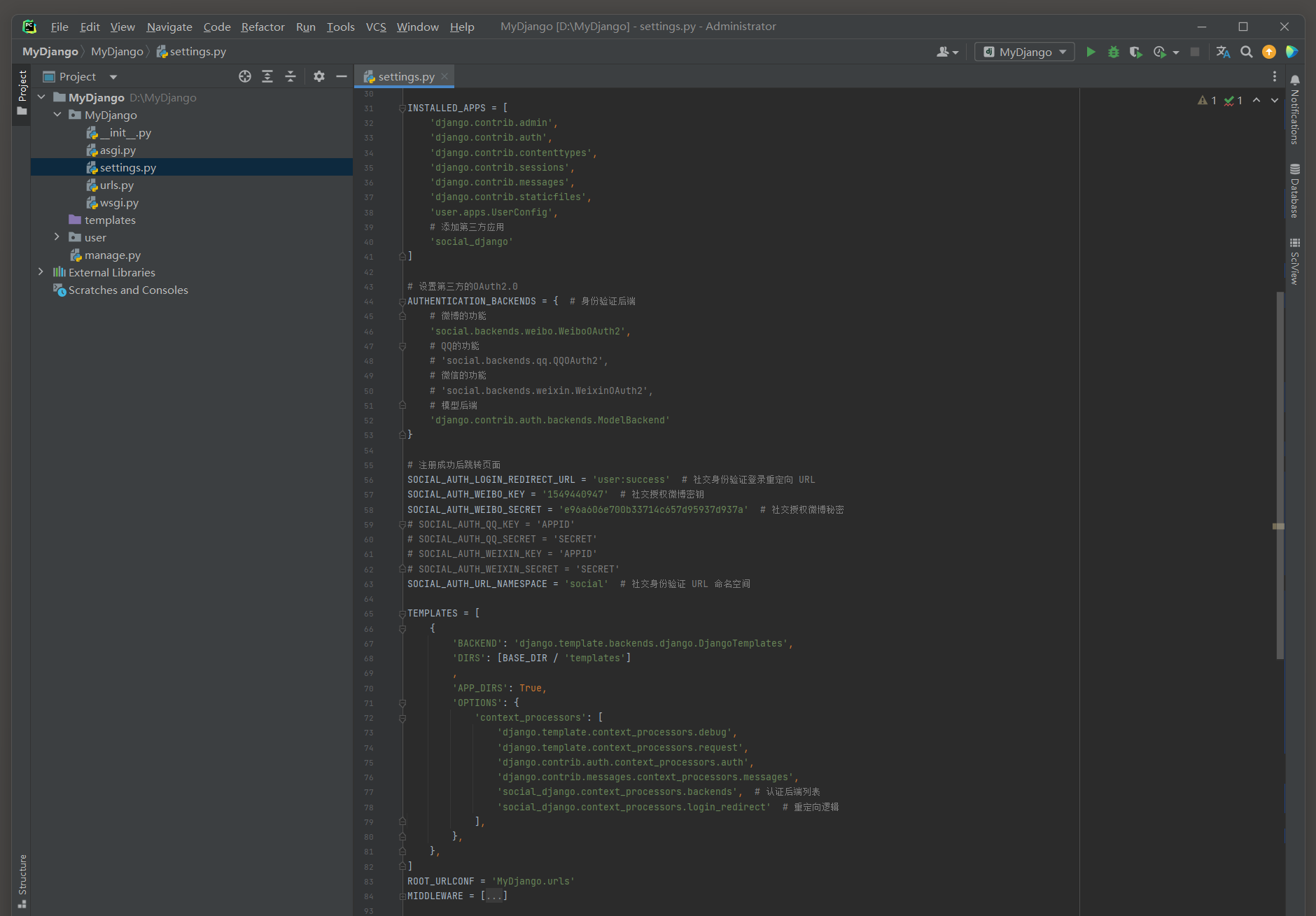
完成上述配置后 , 接着在settings . py中设置Social-Auth-App-Django的配置信息 ,
主要在INSTALLED_APPS和TEMPLATES中引入功能模块以及设置功能配置 , 配置信息如下 :
INSTALLED_APPS = [ 'django.contrib.admin' , 'django.contrib.auth' , 'django.contrib.contenttypes' , 'django.contrib.sessions' , 'django.contrib.messages' , 'django.contrib.staticfiles' , 'user.apps.UserConfig' , 'social_django'
]
AUTHENTICATION_BACKENDS = { 'social.backends.weibo.WeiboOAuth2' , 'django.contrib.auth.backends.ModelBackend'
}
SOCIAL_AUTH_LOGIN_REDIRECT_URL = 'user:success'
SOCIAL_AUTH_WEIBO_KEY = '1549440947'
SOCIAL_AUTH_WEIBO_SECRET = 'e96a606e700b33714c657d95937d937a'
SOCIAL_AUTH_URL_NAMESPACE = 'social' TEMPLATES = [ { 'BACKEND' : 'django.template.backends.django.DjangoTemplates' , 'DIRS' : [ BASE_DIR / 'templates' ] , 'APP_DIRS' : True , 'OPTIONS' : { 'context_processors' : [ 'django.template.context_processors.debug' , 'django.template.context_processors.request' , 'django.contrib.auth.context_processors.auth' , 'django.contrib.messages.context_processors.messages' , 'social_django.context_processors.backends' , 'social_django.context_processors.login_redirect' ] , } , } ,
]
( context_processors是用于向模板上下文添加额外变量的函数 .
这些变量可以在所有的模板中直接使用 , 无需在每个视图函数中都显式地传递它们 .
'social_django.context_processors.backends' 和 'social_django.context_processors.login_redirect'
是两个由social-django应用提供的上下文处理器 . 'social_django.context_processors.backends' : 这个上下文处理器通常用于向模板中添加当前可用的认证后端列表 .
这对于在模板中动态显示第三方登录按钮 ( 如Google , Facebook等 ) 非常有用 .
例如 , 如果在模板中需要显示多个第三方登录按钮 , 并且这些按钮应该基于当前配置和可用的认证后端来动态显示 ,
那么这个上下文处理器会非常有用 . 'social_django.context_processors.login_redirect' : 这个上下文处理器通常用于处理登录后的重定向逻辑 .
当用户使用第三方认证登录后 , 可能想将他们重定向到一个特定的页面 ,
这个页面可能是他们之前试图访问的受保护页面 , 或者是你的应用的主页 .
这个上下文处理器可以帮助你管理这个重定向逻辑 . )
由于Social-Auth-App-Django的源码文件models . py中定义了多个模型 , 完成MyDjango的配置后 ,
还需要使用migrate指令执行数据迁移 , 在MyDjango的数据库文件db . sqlite3中生成数据表 .
PS D: \MyDjango> python manage. py makemigrations
No changes detected
PS D: \MyDjango> python manage. py migrate
SystemCheckError: System check identified some issues: ERRORS:
social_django. Partial: ( fields. E180) SQLite does not support JSONFields.
social_django. UserSocialAuth: ( fields. E180) SQLite does not support JSONFields.
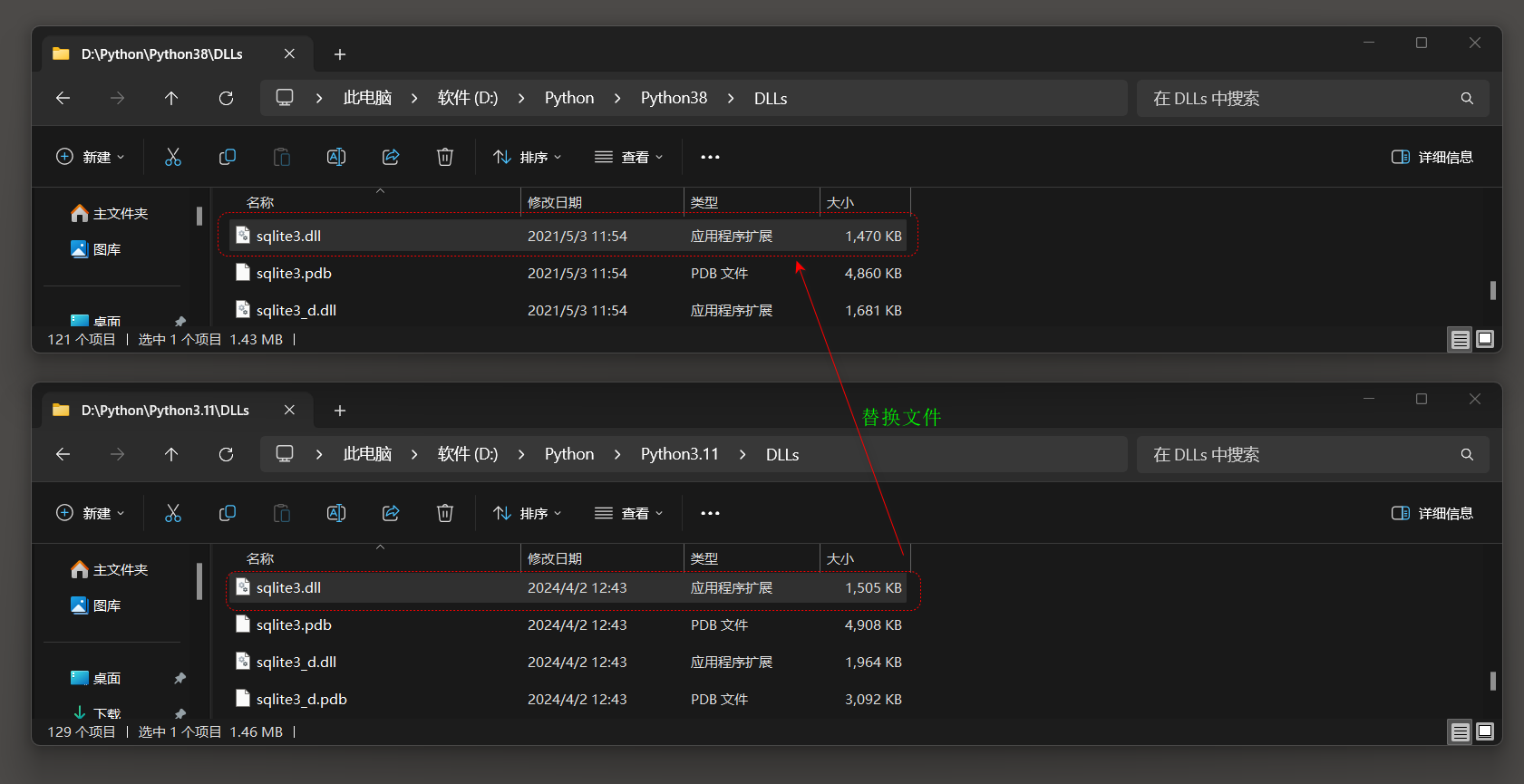
对于使用JSONField与Django 3.1 + 和sqlite , 必须安装sqlite扩展 . 要在sqlite上启用JSON1 , 请按照Django的wiki : https : / / code . djangoproject . com / wiki / JSON1Extension上的说明操作 . 从Python 3.9 开始 , Windows上的官方Python安装程序已经包含JSON1默认情况下扩展名 .
如果您使用的是早期版本的Python或非官方安装程序 , 您可以执行以下操作 : 下载与您的 Python 安装 ( 32 位或 64 位 ) 匹配的预编译 DLL .
找到您的Python安装 .
默认情况下 , 它应该位于 % localappdata % \ Programs \ Python \ PythonXX中 , 其中XX是Python版本 .
例如 , 它位于 C : \ Users \ < username > \ AppData \ Local \ Programs \ Python \ Python37 中 .
如果将Python安装目录添加到PATH环境变量中 , 则可以运行命令 , 其中python在命令提示符下找到它 .
在Python安装中输入DLL目录 .
重命名 ( 或删除 ) DLLs目录中的sqlite3 . dll .
从下载的DLL存档中提取sqlite3 . dll并将其放在DLL目录中 .
现在 , JSON1扩展应该可以在Python和Django中使用了 . 意思就是用 3.9 版本以后的sqlite3 . dll文件替换旧版本的sqlite3 . dll文件 .
( 不推荐跨太多版本 , 我从 3.11 版本提取出来的文件复制过去后 , 无法启动Django项目 . . . )
PS D: \MyDjango> python manage. py makemigrations
PS D: \MyDjango> python manage. py migrate
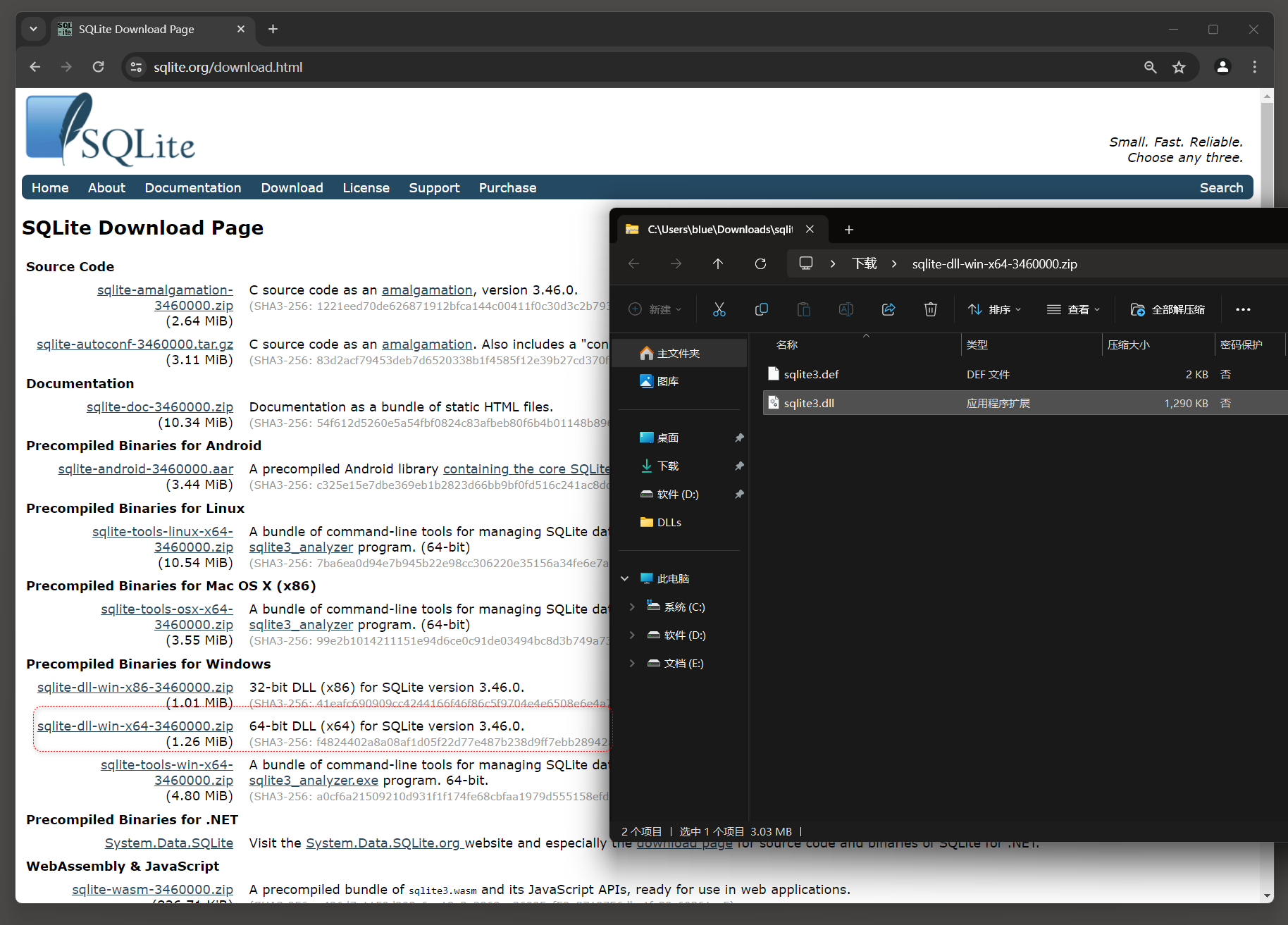
推荐 : sqlite3下载地址 : https : / / www . sqlite . org / download . html , ( 成功 ) .
PS D: \MyDjango> python manage. py migrate
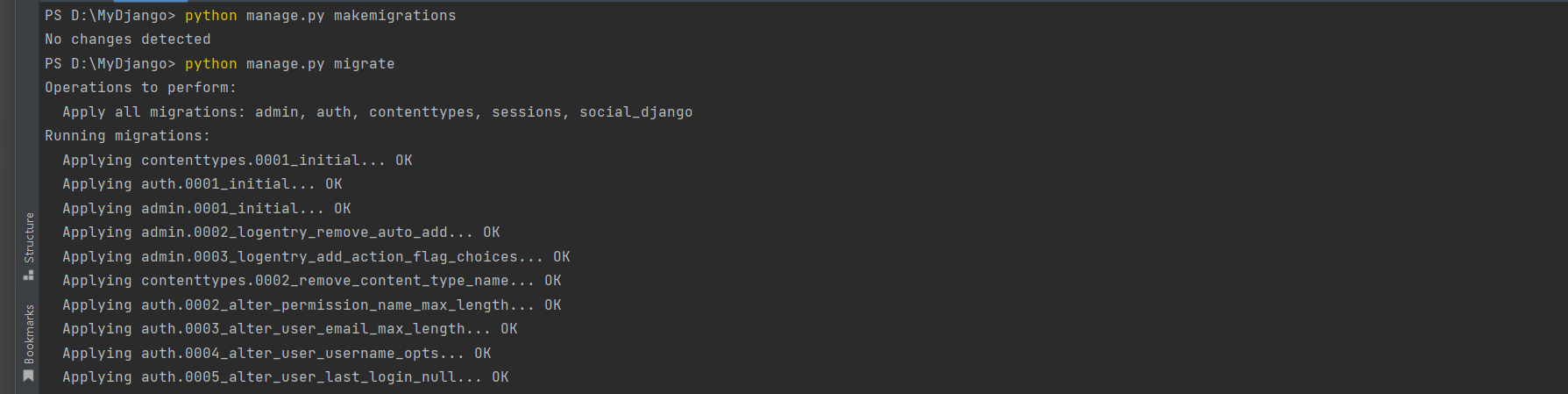
Operations to perform: Apply all migrations: admin, auth, contenttypes, sessions, social_django
Running migrations: Applying contenttypes. 0001_initial. . . OKApplying auth. 0001_initial. . . OKApplying admin. 0001_initial. . . OKApplying admin. 0002_logentry_remove_auto_add. . . OKApplying admin. 0003_logentry_add_action_flag_choices. . . OKApplying contenttypes. 0002_remove_content_type_name. . . OKApplying auth. 0002_alter_permission_name_max_length. . . OKApplying auth. 0003_alter_user_email_max_length. . . OKApplying auth. 0004_alter_user_username_opts. . . OKApplying auth. 0005_alter_user_last_login_null. . . OKApplying auth. 0006_require_contenttypes_0002. . . OKApplying auth. 0007_alter_validators_add_error_messages. . . OKApplying auth. 0008_alter_user_username_max_length. . . OKApplying auth. 0009_alter_user_last_name_max_length. . . OKApplying auth. 0010_alter_group_name_max_length. . . OKApplying auth. 0011_update_proxy_permissions. . . OKApplying auth. 0012_alter_user_first_name_max_length. . . OKApplying sessions. 0001_initial. . . OKApplying social_django. 0001_initial. . . OKApplying social_django. 0002_add_related_name. . . OKApplying social_django. 0003_alter_email_max_length. . . OKApplying social_django. 0004_auto_20160423_0400. . . OKApplying social_django. 0005_auto_20160727_2333. . . OKApplying social_django. 0006_partial. . . OKApplying social_django. 0007_code_timestamp. . . OKApplying social_django. 0008_partial_timestamp. . . OKApplying social_django. 0009_auto_20191118_0520. . . OKApplying social_django. 0010_uid_db_index. . . OKApplying social_django. 0011_alter_id_fields. . . OKApplying social_django. 0012_usersocialauth_extra_data_new. . . OKApplying social_django. 0013_migrate_extra_data. . . OKApplying social_django. 0014_remove_usersocialauth_extra_data. . . OKApplying social_django. 0015_rename_extra_data_new_usersocialauth_extra_data. . . OK
在MyDjango中完成Social-Auth-App-Django的环境搭建后 ,
下一步在MyDjango中实现用户注册页面和Social-Auth-App-Django的回调页面 . 首先定义路由register和success ,
并且引入Social-Auth-App-Django的路由文件 , 实现代码如下 :
from django. urls import path, includeurlpatterns = [ path( '' , include( ( 'user.urls' , 'user' ) , namespace= 'user' ) ) , path( '' , include( 'social_django.urls' , namespace= 'social' ) )
]
( 当用户访问根URL ( / ) 时 , Django会首先检查第一个include ( 即user . urls中的模式 ) .
如果在user . urls中没有找到与根URL匹配的模式 , Django会继续检查第二个include ( 即social_django . urls中的模式 ) . 这意味着 , 如果第一个include中没有匹配的项 , Django确实会 '去第二个路由中找' .
然而 , 这种配置可能导致预期之外的匹配行为 , 因为两个include都试图处理相同的URL路径 .
通常 , 为了避免混淆和潜在的冲突 , 最好为每个include指定一个独特的路径前缀 ,
除非你有明确的理由让它们都匹配根URL , 并且你已经仔细设计了每个include中的URL模式以避免冲突 . )
from django. urls import path
from . views import * urlpatterns = [ path( '' , login, name= 'login' ) , path( 'success' , success, name= 'success' )
]
路由login和success分别指向视图函数register和success , 视图函数无须实现任何功能 ,
因为整个授权认证过程都是由Social-Auth-App-Django实现的 .
视图函数register和success的代码如下 :
from django. shortcuts import render
from django. http import HttpResponse
def register ( request) : title = '用户注册' return render( request, 'register.html' , locals ( ) )
def success ( request) : return HttpResponse( '注册成功' )
视图函数register使用模板文件register . html作为网页内容 ,
模板文件register . html将使用Social-Auth-App-Django定义的路由地址作为第三方网站的认证链接 , 具体代码如下 :
<! DOCTYPE html > < htmllang = " zh-cn" > < head> < metacharset = " utf-8" > < title> </ title> < linkrel = " stylesheet" href = " https://unpkg.com/mobi.css/dist/mobi.min.css" > </ head> < body> < divclass = " flex-center" > < divclass = " container" > < divclass = " flex-center" > < div> < h1> </ h1> < div> < aclass = " btn btn-primary btn-block" href = " {% url " social: begin""weibo" %}" > </ a> </ div> </ div> </ div> </ div> </ div> </ body> </ html>
( href = "{% url " social : begin " " weibo " %}" > 微博注册 < / a > 对应路由
path ( f "login/<str:backend>{extra}" , views . auth , name = "begin" ) )
至此 , 我们通过微博认证实现了MyDjango的用户注册功能 .
运行MyDjango , 在浏览器上访问 : 127.0 .0 .1 : 8000 , 在用户登录页面单击 '微博注册' 按钮 ,
Django将触发Social-Auth-App-Django的路由begin , 由路由begin向微博平台发送OAuth 2.0 授权认证 ,
如果认证成功 , 就访问Social-Auth-App-Django的路由complete完成认证过程 ,
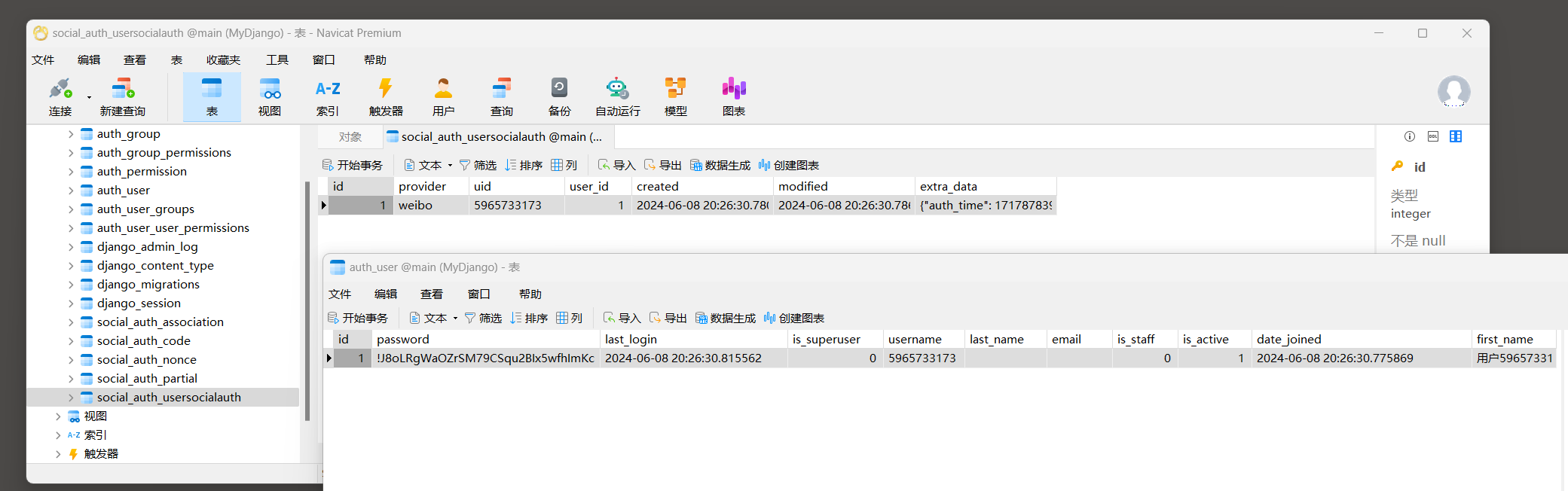
再由路由complete重定向路由success , 从而完成整个用户注册过程 . 微博授权成功后 , 打开数据表social_auth_usersocialauth和auth_user可以看到用户注册信息 , 如图 12 - 23 所示 .
网站的并发编程主要处理网站烦琐的业务流程 , 网站从收到HTTP请求到发送响应内容的过程中 ,
Django处理用户请求主要在视图中执行 , 视图是一个函数或类 , 而且是单线程执行的 .
在视图函数或视图类处理用户请求时 , 如果遇到烦琐的数据读写或高密度计算 , 往往会造成响应时间过长 ,
在网页上容易出现卡死的情况 , 不利于用户体验 .
为了解决这种情况 , 我们可以在视图中加入异步任务 , 让它处理一些耗时的业务流程 , 从而缩短用户的响应时间 .
Django的分布式主要由Celery框架实现 , 这是Python开发的异步任务队列 .
它支持使用任务队列的方式在分布的机器 , 进程和线程上执行任务调度 .
Celery侧重于实时操作 , 每天处理数以百万计的任务 .
Celery本身不提供消息存储服务 , 它使用第三方数据库来传递任务 , 目前第三方数据库支持RabbitMQ , Redis和MongoDB等 .
本节使用第三方应用Django Celery Results , Django Celery Beat , Celery和Redis数据库实现Django的异步任务和定时任务开发 .
值得注意的是 , 定时任务是异步任务的一种特殊类型的任务 .
首先需要安装Redis数据库 , 在Windows中安装Redis数据库有两种方式 : 在官网下载压缩包安装或者在GitHub下载MSI安装程序 .
前者的数据库版本是最新的 , 但需要通过指令安装并设置相关的环境配置 ;
后者是旧版本 , 安装方法是傻瓜式安装 , 启动安装程序后按照安装提示即可完成安装 .
两者的下载地址如下 :
https: // redis. io/ download
https: // github. com/ MicrosoftArchive/ redis/ releases
https: // github. com/ microsoftarchive/ redis/ releases/ download/ win- 3.2 .100 / Redis- x64- 3.2 .100 . msi
Redis数据库的安装过程本书就不详细讲述了 , 读者可以自行查阅相关的资料 .
安装完成后会自动启动 .
除了安装Redis数据库之外 , 还可以安装Redis数据库的可视化工具 , 可视化工具可以帮助初次接触Redis的读者了解数据库结构 .
本书使用Redis Desktop Manager作为Redis的可视化工具 , 如图 12 - 24 所示 . 下载地址 : https : / / wwx . lanzoui . com / i5C6Ntpf9qj
密码 : 21 wh
图 12 - 24 Redis Desktop Manager
接下来介绍安装异步任务所需要的功能模块 , 这些功能模块有celery , redis , django-celery-results , django-celery-beat和eventlet . 它们都能使用pip指令实现安装 , 安装指令如下 :
pip install celery
pip install redis
pip install django- celery- results
pip install django- celery- beat
pip install eventlet
pip install - i https: // pypi. tuna. tsinghua. edu. cn/ simple celery
pip install - i https: // pypi. tuna. tsinghua. edu. cn/ simple redis
pip install - i https: // pypi. tuna. tsinghua. edu. cn/ simple django- celery- results
pip install - i https: // pypi. tuna. tsinghua. edu. cn/ simple django- celery- beat
pip install - i https: // pypi. tuna. tsinghua. edu. cn/ simple eventlet
每个功能模块负责实现不同的功能 , 在此简单讲解各个功能模块的具体作用 , 分别说明如下 :
( 1 ) celery : 安装Celery框架 , 实现异步任务和定时任务的调度控制 .
( 2 ) redis : 使Python与Redis数据库实现连接 .
( 3 ) django-celery-results : 基于Celery封装的异步任务功能 .
( 4 ) django-celery-beat : 基于Celery封装的定时任务功能 .
( 5 ) eventlet : Python的协程并发库 , 这是Celery实现的异步并发运行模式之一 . 详细说明 :
* 1. celery 作用 : Celery是一个简单 , 灵活且可靠的分布式任务队列 , 它可以让你的应用进行异步和周期性 ( 定时 ) 任务 ( jobs ) 的处理 . 它专注于实时处理 , 同时也支持任务调度 . 应用场景 : 在Web应用中 , 可以使用Celery来执行后台任务 , 如发送电子邮件 , 图片处理 , 数据分析等 , 从而避免阻塞Web请求 .
* 2. redis 作用 : Redis是一个开源的 , 内存中的数据结构存储系统 , 它可以用作数据库 , 缓存和消息代理 . 在这里 , 它被用作Celery的消息代理 ( broker ) , 用于在Celery的工作节点和任务队列之间传递任务 .
* 3. django-celery-results 作用 : 这是一个Django应用 , 用于将Celery的结果后端 ( result backend ) 存储在Django的数据库中 . 结果后端用于存储任务的状态和结果 , 使得你可以查询和检索它们 . 应用场景 : 在Django项目中 , 可能希望将Celery的任务结果存储在Django的数据库中 , 以便进行进一步的查询和处理 .
* 4. django-celery-beat 作用 : 这是一个Django应用 , 用于添加周期性任务 ( 定时任务 ) 到Celery . 它提供了一个数据库模型来定义周期性任务 , 并使用Django的admin界面进行管理 . 应用场景 : 在Django项目中 , 可能希望定期执行某些任务 , 如每天发送报告 , 每周清理旧数据等 . 使用django-celery-beat , 可以轻松定义和管理这些周期性任务 .
* 5. eventlet 作用 : Eventlet是一个网络库 , 用于构建并发网络应用 . 它基于Greenlet库 , 支持异步I / O , 并提供了一个高性能的事件循环 . 应用场景 : 虽然Eventlet本身与Celery或Django没有直接的联系 , 但它可以用于提高网络应用的性能 , 特别是当应用需要处理大量并发连接时 .
完成功能模块的安装后 , 在MyDjango里创建项目应用index , 并且在index里创建文件tasks . py , 该文件用于定义异步任务 ;
在MyDjango文件夹创建celery . py , 该文件用于将Celery框架引入Django框架 .
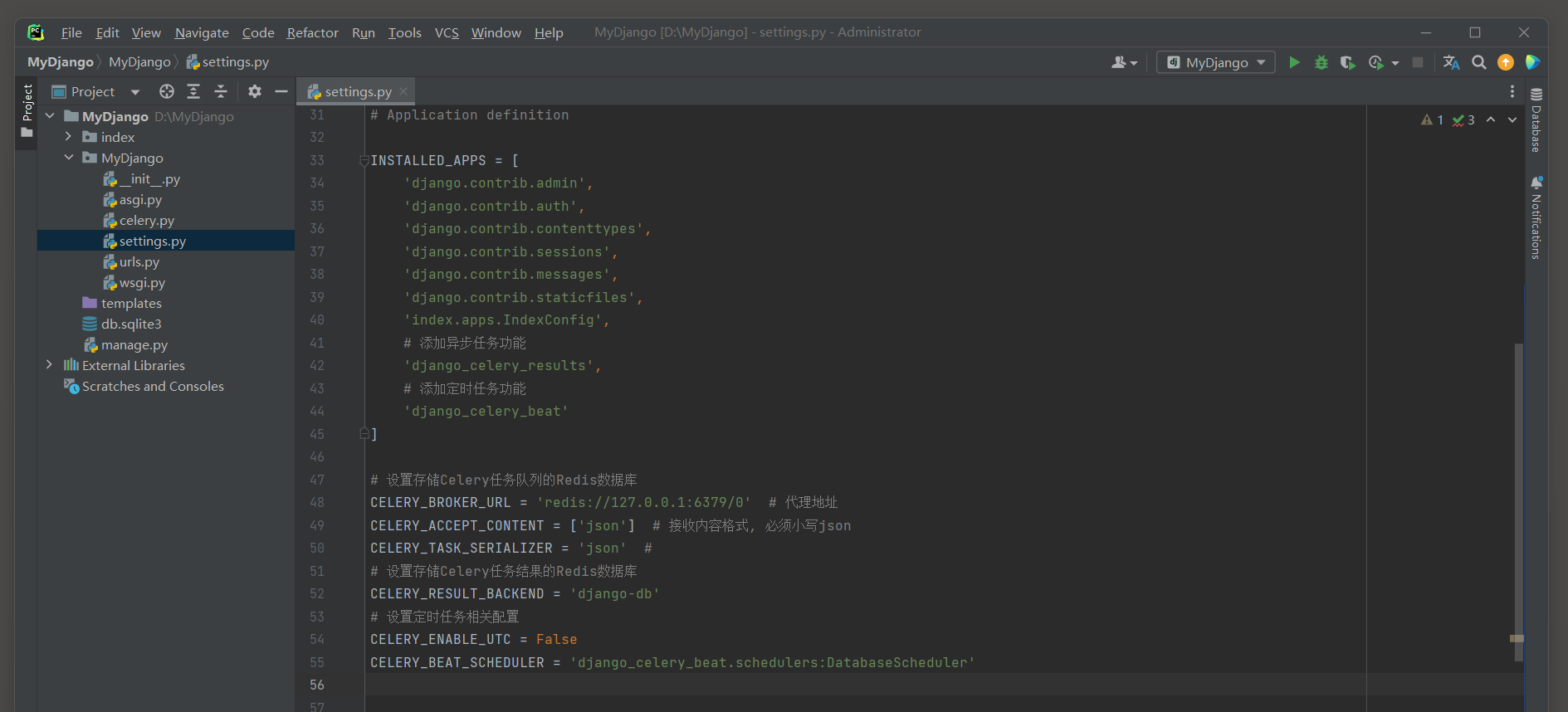
然后在配置文件settings . py中配置异步任务和定时任务的功能模块和功能设置 , 配置代码如下 :
INSTALLED_APPS = [ 'django.contrib.admin' , 'django.contrib.auth' , 'django.contrib.contenttypes' , 'django.contrib.sessions' , 'django.contrib.messages' , 'django.contrib.staticfiles' , 'index.apps.IndexConfig' , 'django_celery_results' , 'django_celery_beat'
]
CELERY_BROKER_URL = 'redis://127.0.0.1:6379/0'
CELERY_ACCEPT_CONTENT = [ 'json' ]
CELERY_TASK_SERIALIZER = 'json'
CELERY_RESULT_BACKEND = 'django-db'
CELERY_ENABLE_UTC = False
CELERY_BEAT_SCHEDULER = 'django_celery_beat.schedulers:DatabaseScheduler'
CELERY_ENABLE_UTC = False 是个坑 , 后面有解释 !
配置属性解释如下 :
* 1. CELERY_BROKER_URL : 这行指定了Celery使用的消息代理 ( Broker ) 的URL . 'redis://127.0.0.1:6379/0' : 表示Celery将使用运行在本地 ( 127.0 .0 .1 ) 的Redis服务器 , 端口为 6379 , 并使用默认的Redis数据库 0 作为消息代理 .
* 2. CELERY_ACCEPT_CONTENT 定义了 Celery 接受的序列化内容类型 . 在这个例子中 , 它只接受 'JSON' 格式的内容 .
* 3. CELERY_TASK_SERIALIZER 定义了用于序列化任务的序列化器 . 这里它被设置为 'JSON' , 意味着任务将以JSON格式进行序列化 .
* 4. CELERY_RESULT_BACKEND : 结果后端存储数据使用的数据库 .
* 5. CELERY_ENABLE_UTC : 这个设置决定是否使用UTC时间来调度定时任务 . 当设置为False时 , Celery将使用服务器的本地时间 . 然而 , 为了避免时区相关的问题 , 通常建议将其设置为True .
* 6. CELERY_BEAT_SCHEDULER : 这行指定了Celery Beat使用的调度器 . django_celery_beat . schedulers : DatabaseScheduler表示将使用django-celery-beat这个Django应用来管理定时任务 , 并使用其提供的数据库调度器 . django-celery-beat允许通过Django管理界面来创建 , 编辑和删除定时任务 , 并将这些任务存储在Django数据库中 .
最后在index的models . py中定义模型PersonInfo , 利用异步任务实现模型PersonInfo的数据修改功能 .
模型PersonInfo的定义过程如下 :
from django. db import models
class PersonInfo ( models. Model) : id = models. AutoField( primary_key= True ) name = models. CharField( max_length= 20 ) age = models. IntegerField( ) hire_date = models. DateField( ) def __str__ ( self) : return self. nameclass Meta : verbose_name = '人员信息'
将整个项目执行数据迁移 , 因为异步任务和定时任务在运行过程中需要依赖数据表才能完成任务执行 .
PS D: \MyDjango> python manage. py makemigrations
Migrations for 'index' : index\migrations\0001_initial. py- Create model PersonInfo
PS D: \MyDjango> python manage. py migrate
Operations to perform: Apply all migrations: admin, auth, contenttypes, django_celery_beat, django_celery_results, index, sessions
Running migrations: Applying contenttypes. 0001_initial. . . OKApplying auth. 0001_initial. . . OKApplying admin. 0001_initial. . . OKApplying admin. 0002_logentry_remove_auto_add. . . OKApplying admin. 0003_logentry_add_action_flag_choices. . . OKApplying django_celery_beat. 0005_add_solarschedule_events_choices. . . OKApplying django_celery_beat. 0006_auto_20180322_0932. . . OKApplying django_celery_beat. 0007_auto_20180521_0826. . . OKApplying django_celery_beat. 0008_auto_20180914_1922. . . OKApplying django_celery_beat. 0006_auto_20180210_1226. . . OKApplying django_celery_beat. 0006_periodictask_priority. . . OKApplying django_celery_beat. 0009_periodictask_headers. . . OKApplying django_celery_beat. 0010_auto_20190429_0326. . . OKApplying django_celery_beat. 0011_auto_20190508_0153. . . OKApplying django_celery_beat. 0012_periodictask_expire_seconds. . . OKApplying django_celery_beat. 0013_auto_20200609_0727. . . OKApplying django_celery_beat. 0014_remove_clockedschedule_enabled. . . OKApplying django_celery_beat. 0015_edit_solarschedule_events_choices. . . OKApplying django_celery_beat. 0016_alter_crontabschedule_timezone. . . OKApplying django_celery_beat. 0017_alter_crontabschedule_month_of_year. . . OKApplying django_celery_beat. 0018_improve_crontab_helptext. . . OKApplying django_celery_results. 0001_initial. . . OKApplying django_celery_results. 0002_add_task_name_args_kwargs. . . OKApplying django_celery_results. 0003_auto_20181106_1101. . . OKApplying django_celery_results. 0004_auto_20190516_0412. . . OKApplying django_celery_results. 0005_taskresult_worker. . . OKApplying django_celery_results. 0006_taskresult_date_created. . . OKApplying django_celery_results. 0007_remove_taskresult_hidden. . . OKApplying django_celery_results. 0008_chordcounter. . . OKApplying django_celery_results. 0009_groupresult. . . OKApplying django_celery_results. 0010_remove_duplicate_indices. . . OKApplying django_celery_results. 0011_taskresult_periodic_task_name. . . OKApplying index. 0001_initial. . . OKApplying sessions. 0001_initial. . . OK
数据迁移后, 打开项目的db.sqlite3数据库文件, 可以看到项目一共生成了20个数据表.
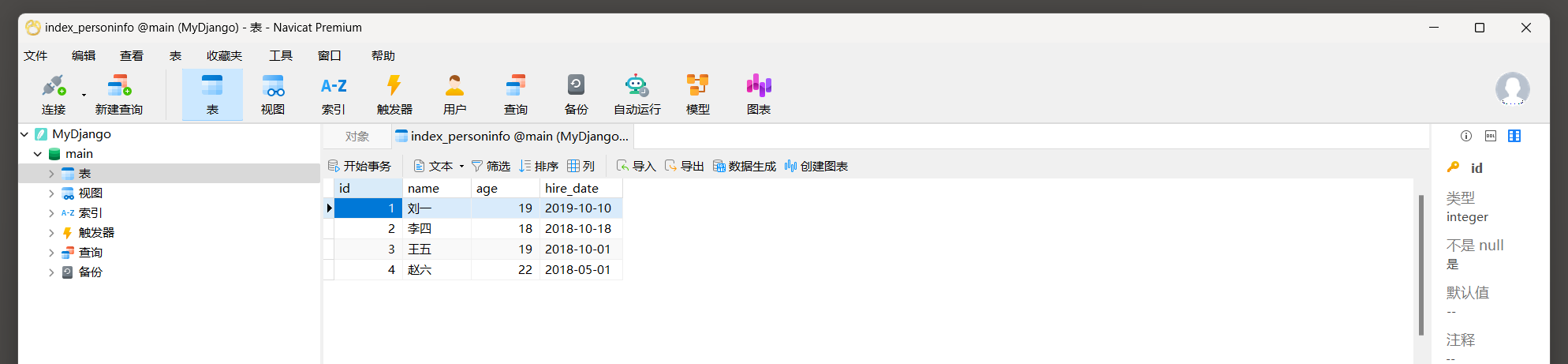
然后在数据表index_personinfo中添加人员信息 , 如图 12 - 25 所示 .
图 12 - 25 数据表index_personinfo
在 12.5 .1 小节 , 我们已经完成了MyDjango的开发环境搭建 , 接下来在MyDjango中实现异步任务开发 .
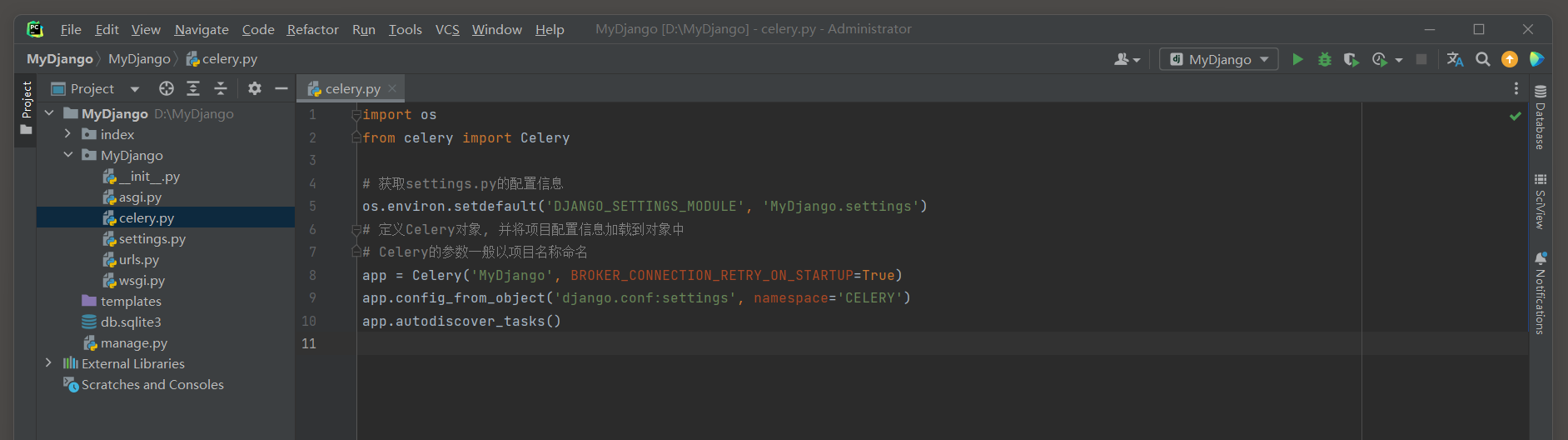
首先在MyDjango的celery . py文件中实现Celery框架和Django框架组合使用 , Celery框架根据Django的运行环境进行实例化并生成app对象 .
celery . py的代码如下 :
import os
from celery import Celery
os. environ. setdefault( 'DJANGO_SETTINGS_MODULE' , 'MyDjango.settings' )
app = Celery( 'MyDjango' , BROKER_CONNECTION_RETRY_ON_STARTUP= True )
app. config_from_object( 'django.conf:settings' , namespace= 'CELERY' )
app. autodiscover_tasks( )
( 代码的含义 :
* 1. import os : 这行代码导入了Python的os模块 , 它提供了很多与操作系统交互的功能 .
* 2. from celery import CeleryL 这行代码从Celery库中导入了Celery类 . Celery类用于创建和管理Celery应用实例 .
* 3. os . environ . setdefault ( 'DJANGO_SETTINGS_MODULE' , 'MyDjango.settings' ) 这行代码设置了一个环境变量DJANGO_SETTINGS_MODULE , 其值为 'MyDjango.settings' . 这个环境变量告诉Django哪个模块包含项目的设置 ( 通常是一个名为settings . py的文件 ) . 虽然Django通常会自动设置这个环境变量 , 但在某些情况下 ( 比如在独立的Celery进程中 ) , 可能需要手动设置 .
* 4. app = Celery ( 'MyDjango' ) : 这行代码创建了一个名为app的Celery应用实例 , 并使用项目名称 'MyDjango' 作为其名称 . Celery应用的名称通常用于在日志和消息中标识应用 . BROKER_CONNECTION_RETRY_ON_STARTUP = True : 如果不进行此设置 , 消息代理在Celery Worker启动时不可用 , 那么Worker可能无法成功连接到消息代理 , 从而导致任务无法被正确处理 . 进行了上述设置后 , 即使在启动时消息代理暂时不可用 , Celery也会尝试重新连接 , 增加了系统的健壮性 .
* 5. app . config_from_object ( 'django.conf:settings' , namespace = 'CELERY' ) 这行代码告诉Celery从Django的设置文件中加载配置 . 它指定了从 'django.conf:settings' ( 这是Django设置模块的路径 ) 加载配置 , 并使用namespace = 'CELERY' 来指定只加载以CELERY_开头的设置项 . 这意味着你可以在Django的 settings . py文件中使用如CELERY_BROKER_URL这样的设置来配置Celery .
* 6. app . autodiscover_tasks ( ) : 这行代码告诉Celery自动发现任务 . 在Django项目中 , Celery 任务通常定义在应用 ( app ) 的tasks . py文件中 . autodiscover_tasks ( ) 会遍历所有已安装的Django应用 , 并尝试导入这些应用中的tasks . py模块 , 从而发现这些应用中定义的任务 . )
上述代码只是在MyDjango中创建Celery框架的实例化对象app , 我们还需要将实例化对象app与MyDjango进行绑定 ,
使Django运行的时候能自动加载Celery框架的实例化对象app .
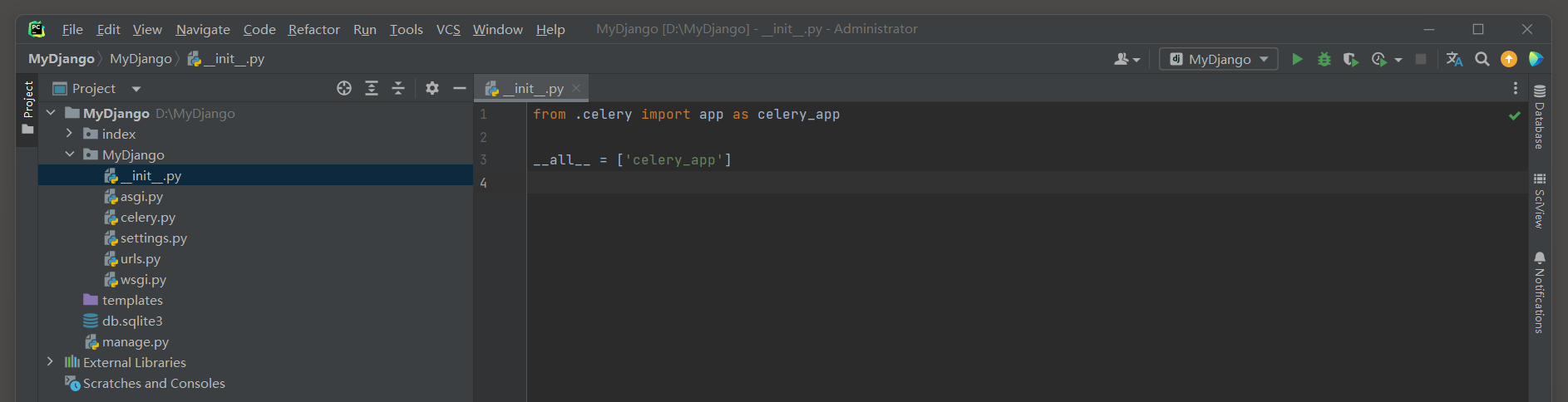
因此 , 在MyDjango的初始化文件__init__ . py中编写加载过程 , 代码如下 :
from . celery import app as celery_app__all__ = [ 'celery_app' ]
现在已将Celery框架加载到Django框架 , 下一步讲述如何在Django中使用Celery框架实现异步任务开发 ,
将MyDjango定义的函数与Celery框架的实例化对象app进行绑定 , 使该函数转变为异步任务 .
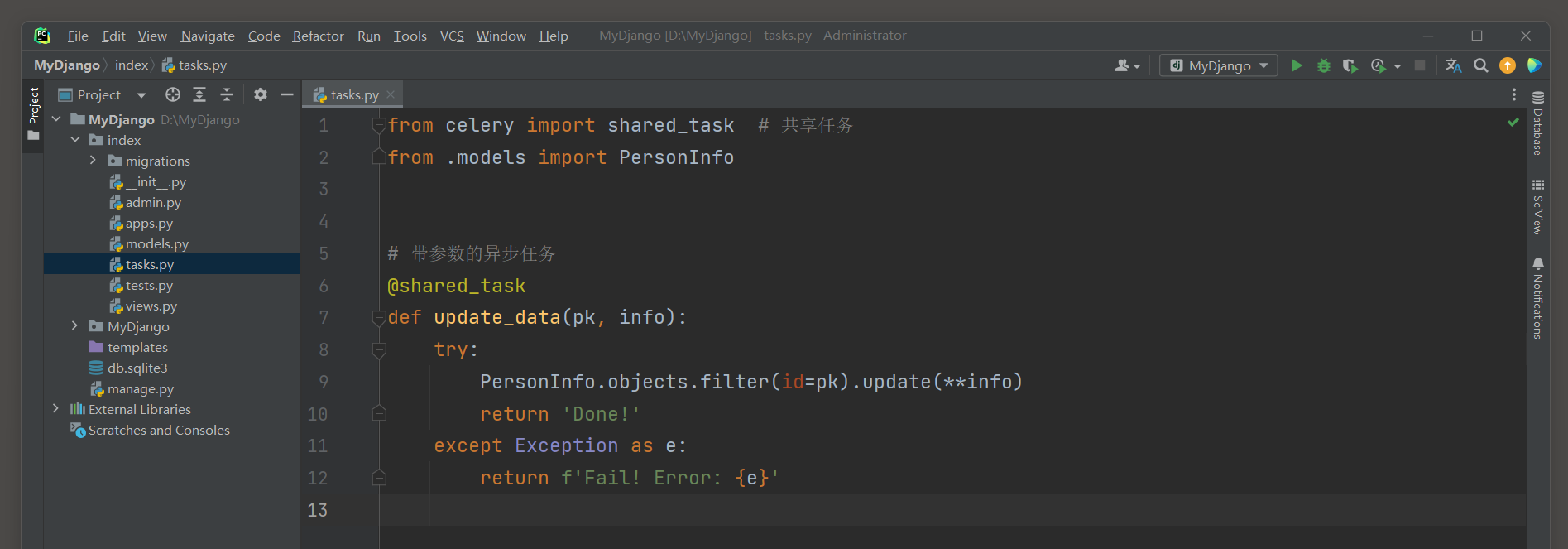
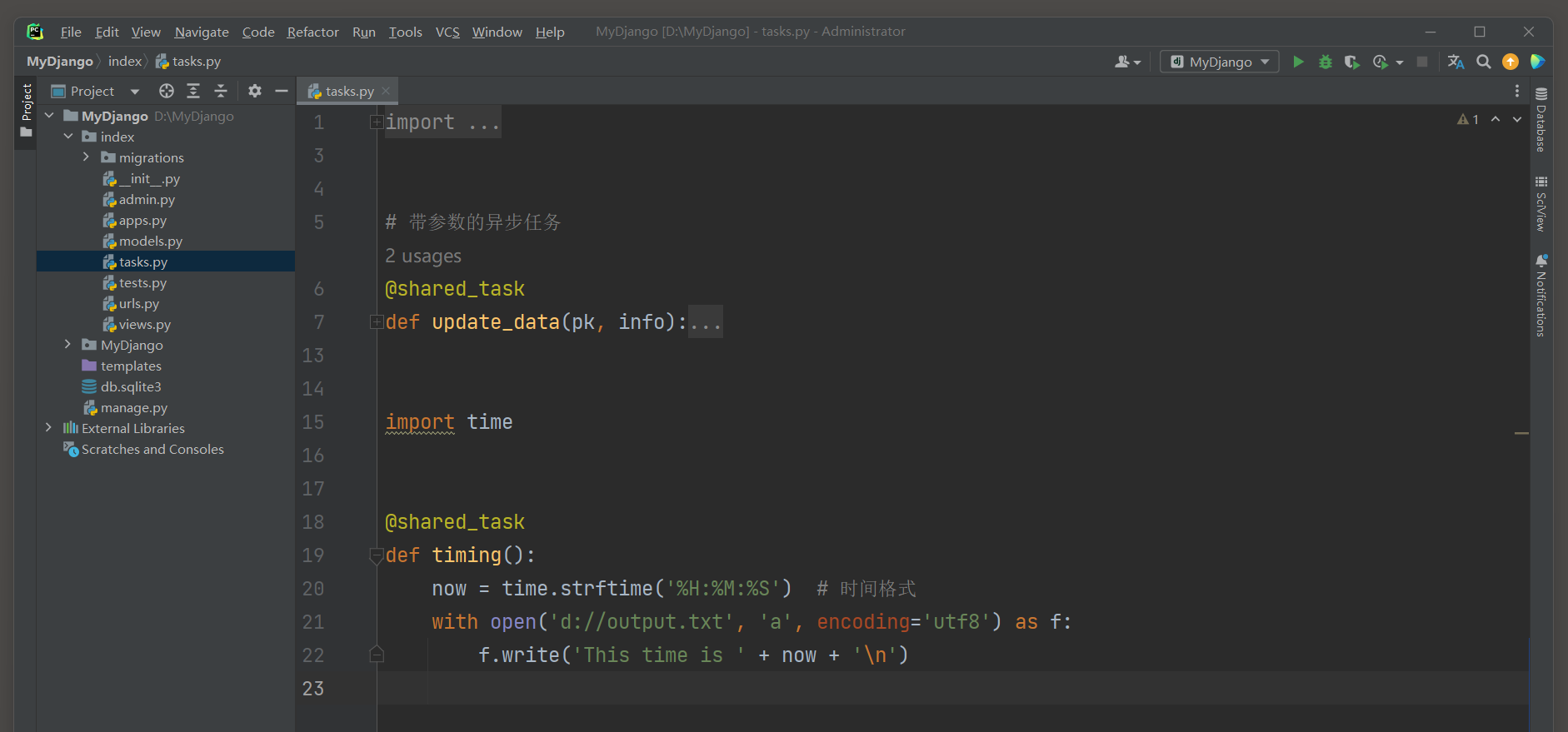
我们在index的task . py中定义函数update_data , 函数代码如下 :
from celery import shared_task
from . models import PersonInfo
@shared_task
def update_data ( pk, info) : try : PersonInfo. objects. filter ( id = pk) . update( ** info) return 'Done!' except Exception as e: return f'Fail! Error: { e} '
函数update_data由装饰器shared_task转化成异步任务updateData , 它设有参数pk和info ,
分别代表模型PersonInfo的主键id和模型字段的修改内容 . 异步任务没有要求函数设置返回值 , 如果函数设有返回值 , 它就作为异步任务的执行结果 , 否则将执行结果设为None ,
所有的执行结果都会记录在数据表django_celery_results_taskresult的result字段中 . 最后在MyDjango中编写异步任务update_data的触发条件 ,
换句话说 , 当用户访问特定的网址时 , 视图函数或视图类将调用异步任务update_data ,
由Celery框架执行异步任务 , 视图函数或视图类只需返回响应内容即可 , 无须等待异步任务的执行过程 .
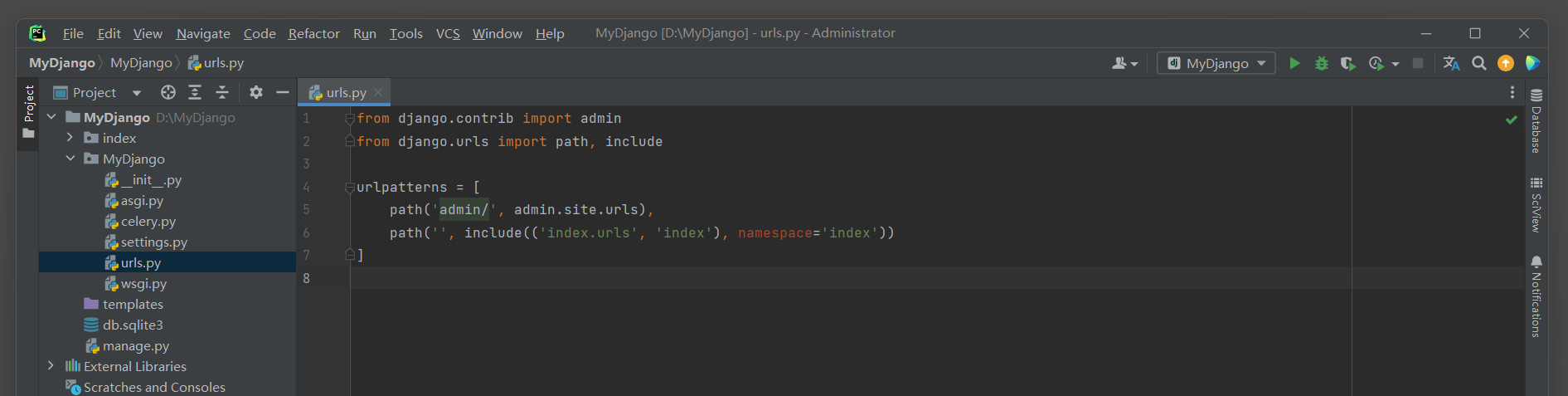
我们在MyDjango的urls . py和index的urls . py中定义路由index和Admin后台系统的路由 , 路由信息如下 :
from django. contrib import admin
from django. urls import path, includeurlpatterns = [ path( 'admin/' , admin. site. urls) , path( '' , include( ( 'index.urls' , 'index' ) , namespace= 'index' ) )
]
from django. urls import path
from . views import * urlpatterns = [ path( '' , index, name= 'index' ) ,
]
上述代码中 , Admin后台系统的路由是为了设置定时任务 , 定时任务将在下一节详细讲述 .
路由index为异步任务update_data的触发条件提供路由地址 ,
路由的请求处理由视图函数index执行 , 因此在index的views . py中定义视图函数index , 代码如下 :
from django. http import HttpResponse
from . tasks import update_datadef index ( request) : pk = request. GET. get( 'id' , 1 ) info = dict ( name= '刘一' , age= 19 , hire_date= '2019-10-10' ) update_data. delay( pk, info) return HttpResponse( "Hello Celery" )
视图函数index设置变量pk和infom 异步任务update_data调用delay方法创建任务队列 ,
由Celery框架完成执行过程 , 如果异步任务设有参数 , 那么可以在delay方法里添加异步任务的函数参数 . 至此 , 我们已完成Django的异步任务开发 . 最后讲述如何启动异步任务的运行环境 .
因为异步任务由Celery框架执行 , 除了启动MyDjango之外 , 还需要启动Celery框架 .
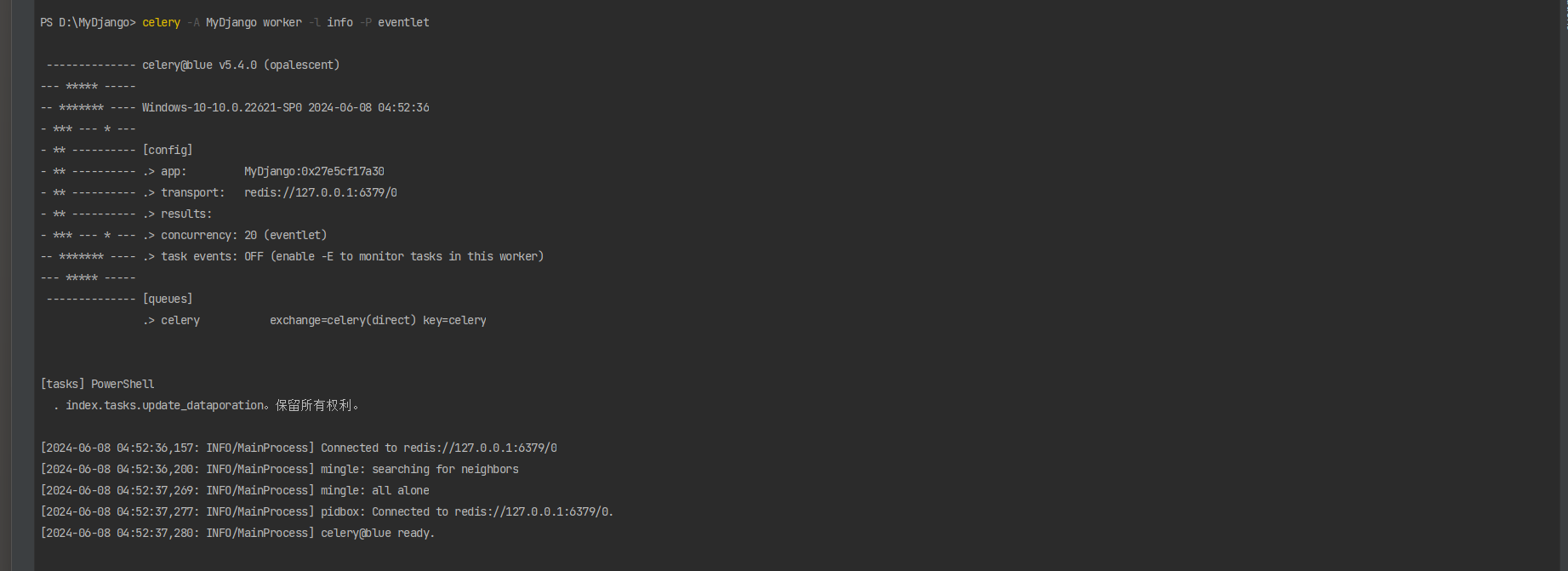
首先运行MyDjango , 然后在PyCharm的Terminal中输入以下指令启动Celery :
celery - A MyDjango worker - l info - P eventlet
上述指令是通过eventlet模块运行Celery框架的 , Celery框架有多种运行方式 , 读者可以自行在网上查阅相关资料 .
当Celery框架成功启动后 , 它会自动加载MyDjango定义的异步任务update_data ,
并在PyCharm的Terminal中显示Redis数据库连接信息 , 如图 12 - 26 所示 .
PS D: \MyDjango> celery - A MyDjango worker - l info - P eventlet- - - - - - - - - - - - - - celery@blue v5. 4.0 ( opalescent)
- - - ** ** * - - - - -
- - ** ** ** * - - - - Windows- 10 - 10.0 .22621 - SP0 2024 - 06 - 08 04 : 52 : 36
- ** * - - - * - - -
- ** - - - - - - - - - - [ config]
- ** - - - - - - - - - - . > app: MyDjango: 0x27e5cf17a30
- ** - - - - - - - - - - . > transport: redis: // 127.0 .0 .1 : 6379 / 0
- ** - - - - - - - - - - . > results:
- ** * - - - * - - - . > concurrency: 20 ( eventlet)
- - ** ** ** * - - - - . > task events: OFF ( enable - E to monitor tasks in this worker)
- - - ** ** * - - - - - - - - - - - - - - - - - - - [ queues] . > celery exchange= celery( direct) key= celery[ tasks] PowerShell. index. tasks. update_dataporation。保留所有权利。[ 2024 - 06 - 08 04 : 52 : 36 , 157 : INFO/ MainProcess] Connected to redis: // 127.0 .0 .1 : 6379 / 0
[ 2024 - 06 - 08 04 : 52 : 36 , 200 : INFO/ MainProcess] mingle: searching for neighbors
[ 2024 - 06 - 08 04 : 52 : 37 , 269 : INFO/ MainProcess] mingle: all alone
[ 2024 - 06 - 08 04 : 52 : 37 , 277 : INFO/ MainProcess] pidbox: Connected to redis: // 127.0 .0 .1 : 6379 / 0.
[ 2024 - 06 - 08 04 : 52 : 37 , 280 : INFO/ MainProcess] celery@blue ready.
图 12 - 26 Celery启动信息
在浏览器上输入 : 127.0 .0 .1 : 8000 , 视图函数index将触发异步任务update_data ,
如果当前请求没有请求参数id , 就默认修改模型PersonInfo的主键id等于 1 的数据 .
当异步任务执行成功后 , 执行结果将会显示在PyCharm的Terminal界面 ,
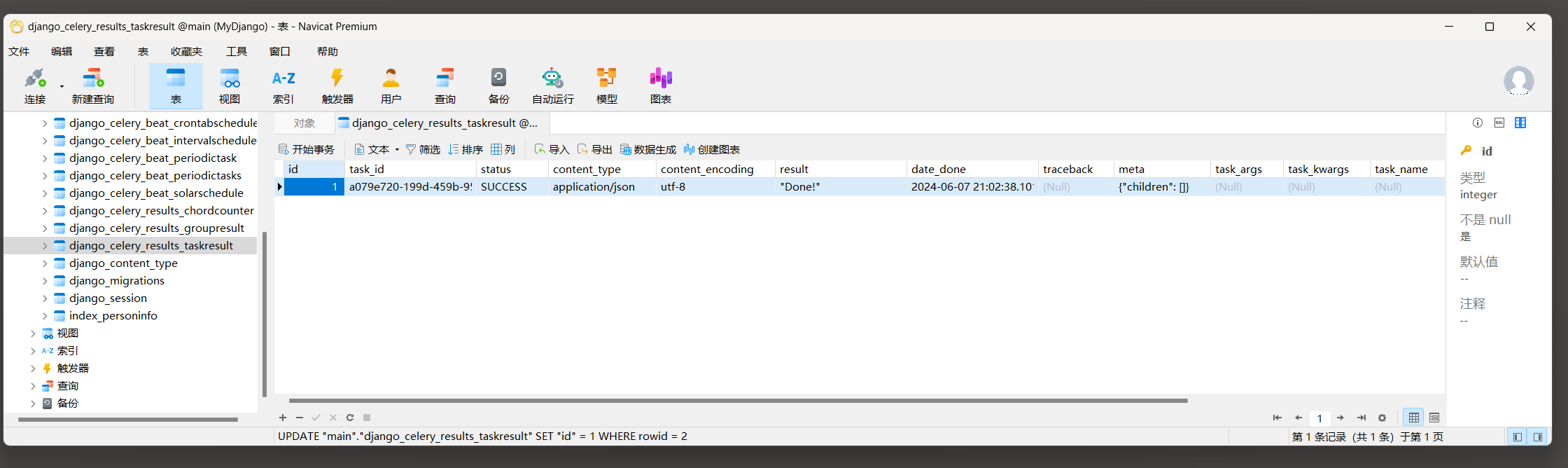
并且保存到数据表django_celery_results_taskresult中 , 如图 12 - 27 所示 .
图 12 - 27 数据表django_celery_results_taskresult
定时任务是一种较为特殊的异步任务 , 它在特定的时间内触发并执行某个异步任务 , 换句话说 , 所有异步任务都可以设为定时任务 .
我们为了区分 12.5 .2 小节的异步任务update_Data , 在index的tasks . py中定义异步任务timing , 具体代码如下 :
import time@shared_task
def timing ( ) : now = time. strftime( '%H:%M:%S' ) with open ( 'd://output.txt' , 'a' , encoding= 'utf8' ) as f: f. write( 'This time is ' + now + '\n' ) ( a为追加模式 , 文件不存在会自动创建 . )
下一步将异步任务timing设为定时任务 , 首先在PyCharm的Terminal中使用Django指令创建超级管理员账号 ( 账号和密码皆为admin ) ,
然后运行MyDjango , 在浏览器上访问Admin后台系统并使用超级管理员登录 .
PS D: \MyDjango> python manage. py createsuperuser
Username ( leave blank to use 'blue' ) : admin
Email address: ( 回车)
Password: ( admin)
Password ( again) : ( admin)
The password is too similar to the username.
This password is too short. It must contain at least 8 characters.
This password is too common.
Bypass password validation and create user anyway? [ y/ N] : y
Superuser created successfully.
PS D: \MyDjango>
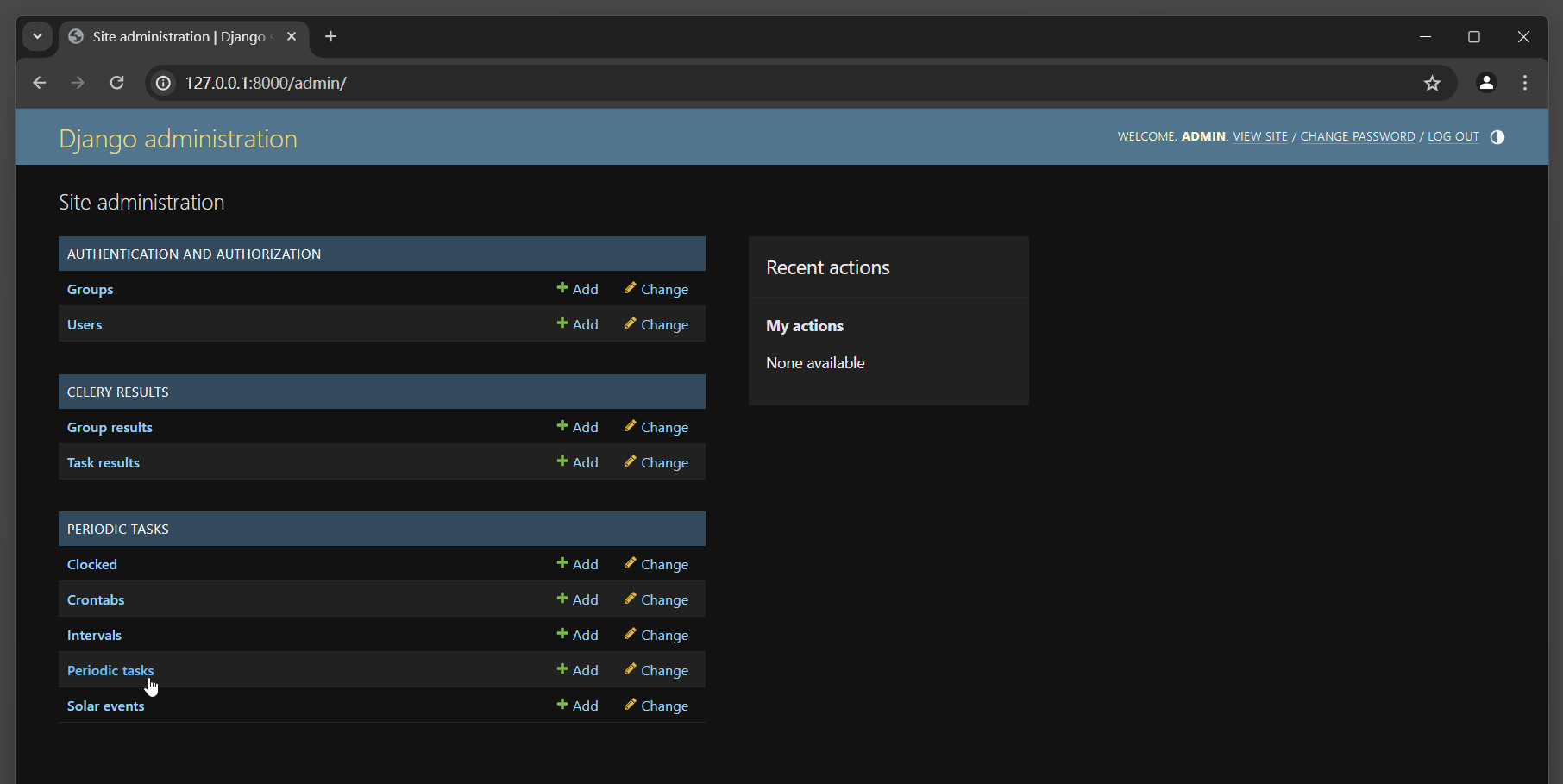
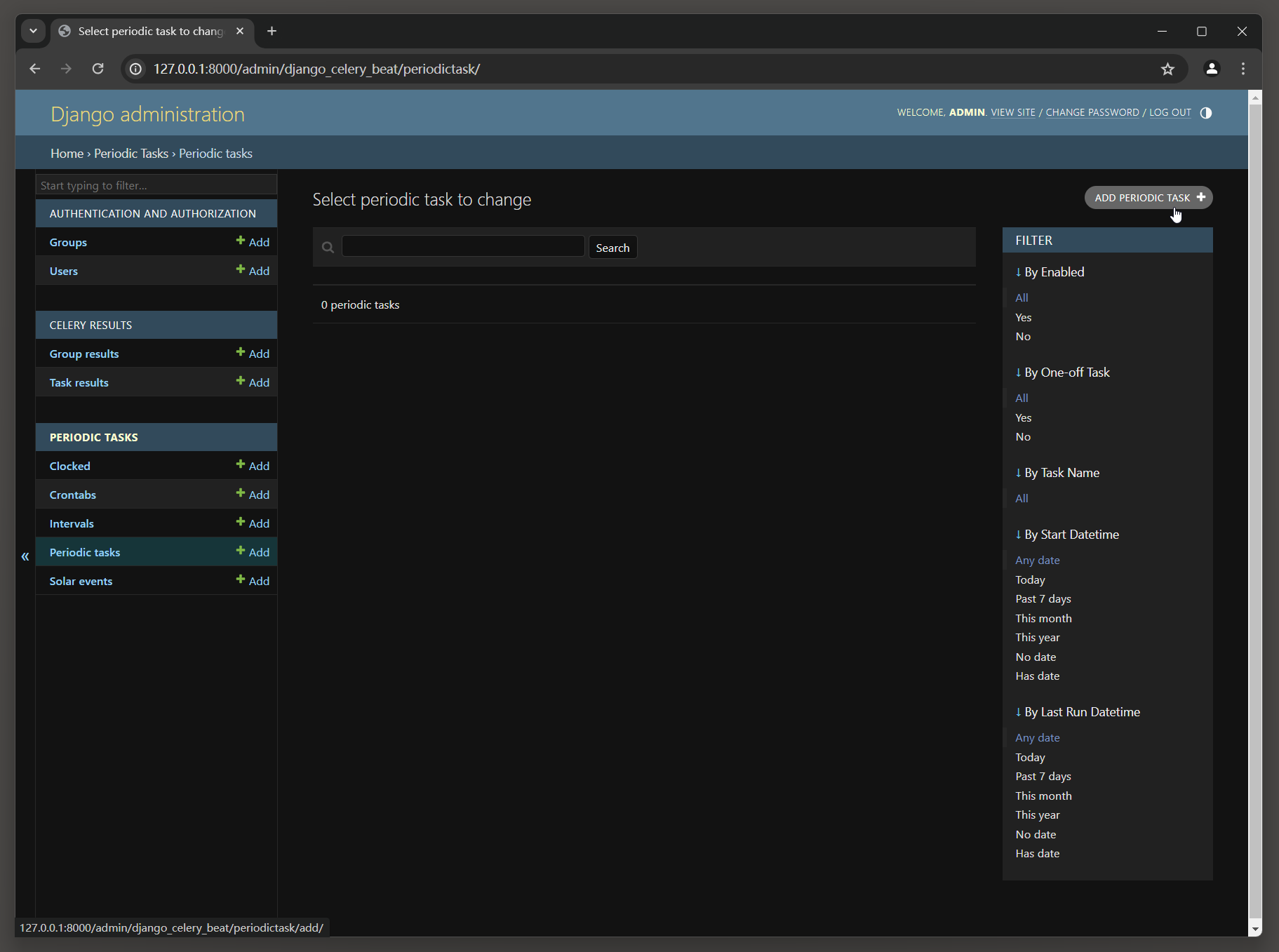
最后在Admin后台系统的主页面找到Periodic Tasks , 单击该链接进入Periodic Tasks页面 ,
在Periodic Tasks页面单击Add periodic task链接 , 如图 12 - 28 所示 .
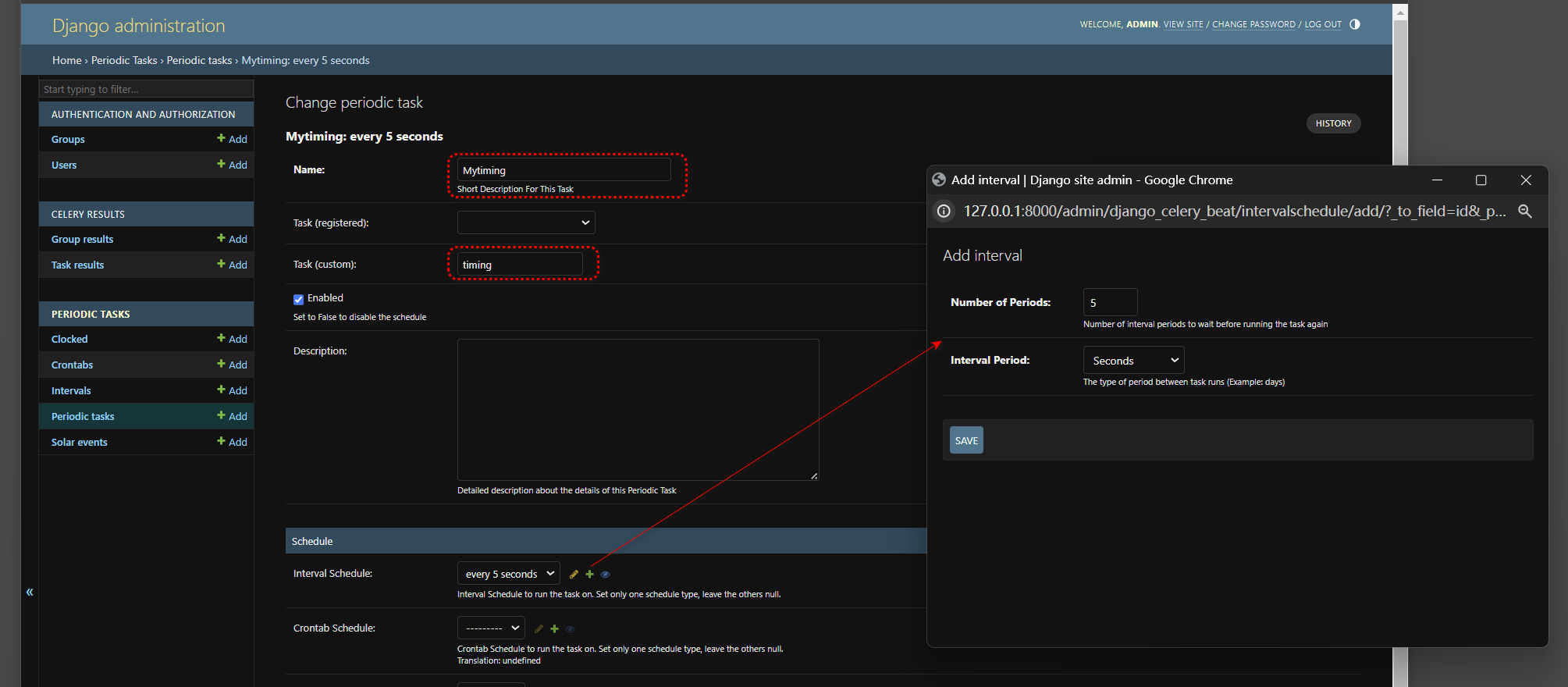
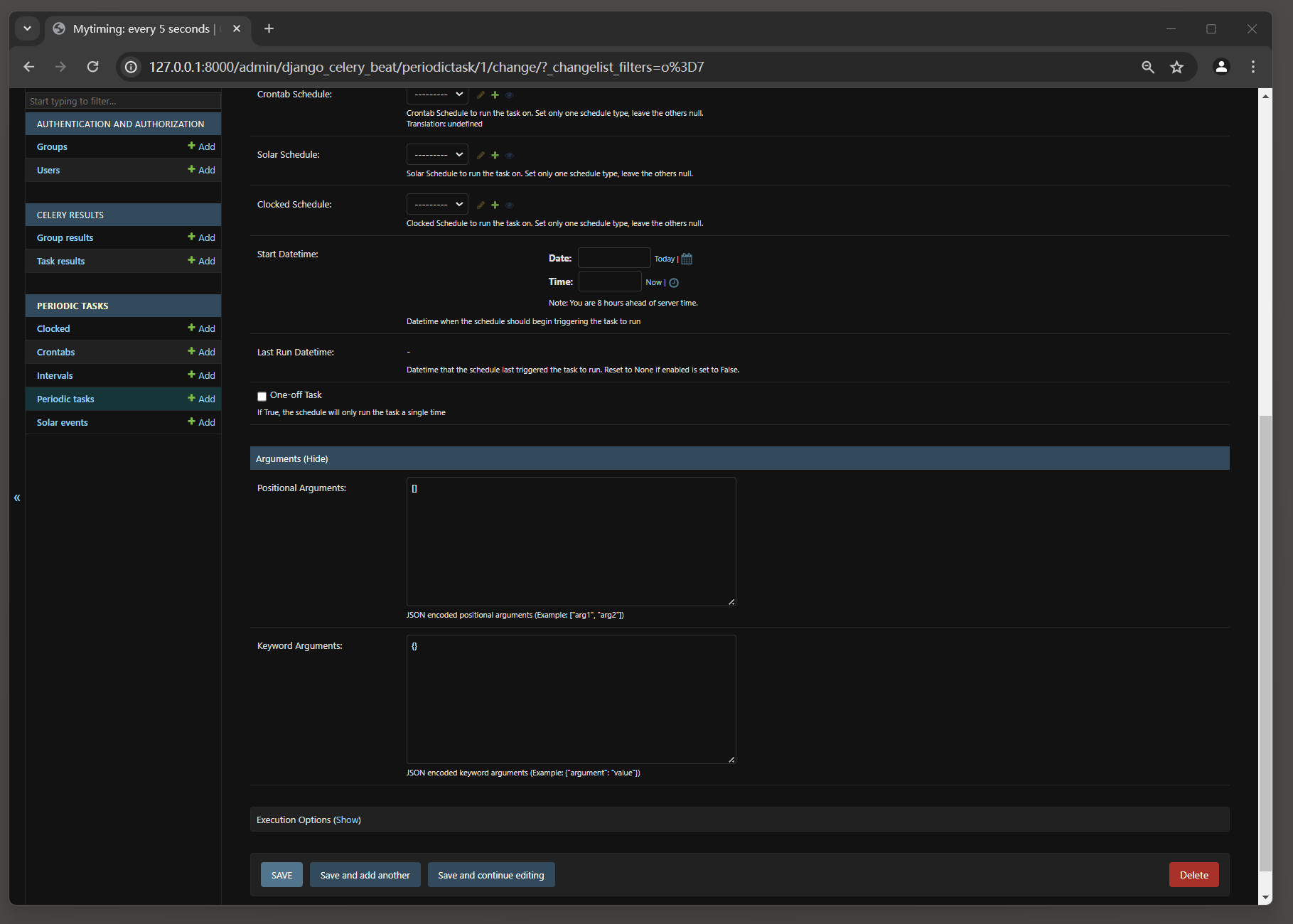
在Add periodic task页面 , 我们将name设置为 : Mytiming , Task设置为异步任务 : timing , Interval设置为 5 秒 ,
这是创建定时任务Mytiming , 每间隔 5 秒就会执行异步任务timing .
设置完成后 , 下拉页面点击save保存 .
图 12 - 28 创建定时任务
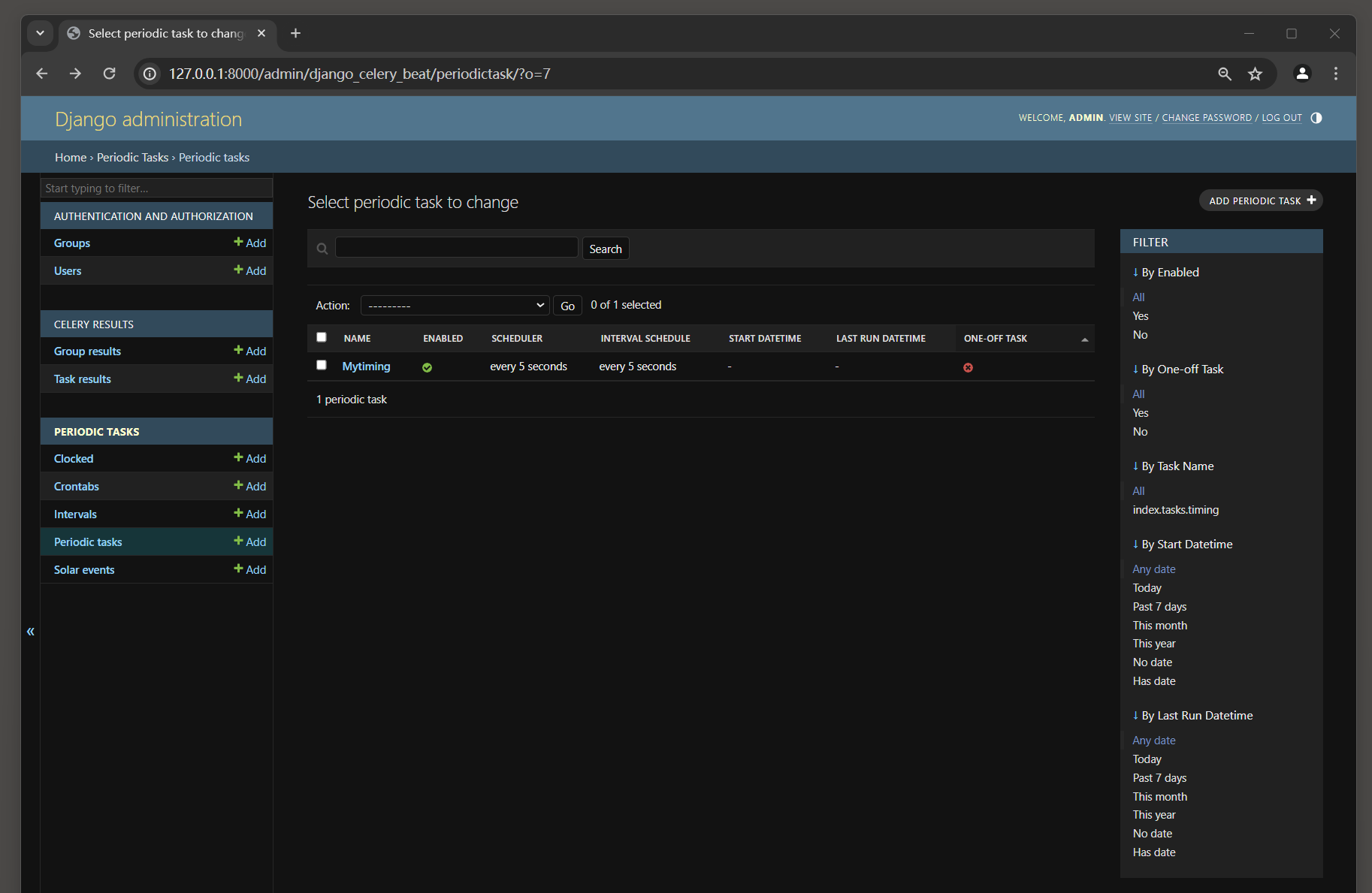
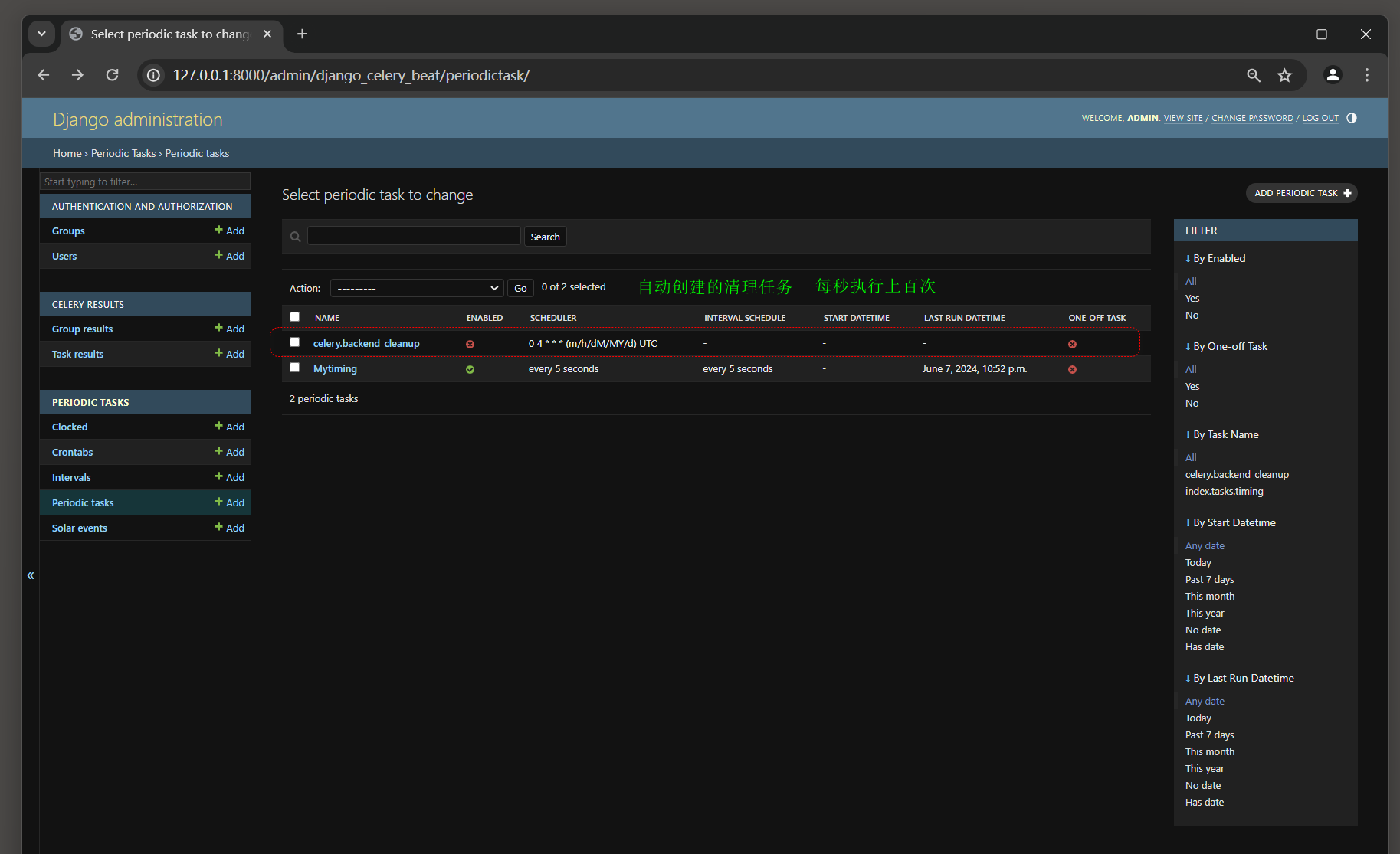
定时任务创建成功后 , 可以在数据表django_celery_beat_periodictask中查看任务信息 , 如图 12 - 29 所示 .
图 12 - 29 数据表django_celery_beat_periodictask
如果异步任务设有参数 , 那么可以在Add periodic task页面设置Arguments或Keyword arguments ,
参数以JSON格式表示 , 它们分别对应数据表字段args和kwargs .
定时任务设置后 , 我们通过输入指令来启动定时任务 .
在输入指令之前 , 必须保证MyDjango和Celery处于运行状态 .
换句话说 , 如果使用PyCharm启动定时任务 , 就需要运行MyDjango , 启动Celery和Celery的定时任务 .
在PyCharm中创建两个Terminal界面 , 每个Terminal界面依次输入以下指令 :
celery - A MyDjango worker - l info - P eventlet
celery - A MyDjango beat - l info - S django
定时任务启动后 , 数据表django_celery_beat_periodictask所有的定时任务都会进入等待状态 ,
只有Django的系统时间达到定时任务的触发时间 , Celery才会运行符合触发条件的定时任务 .
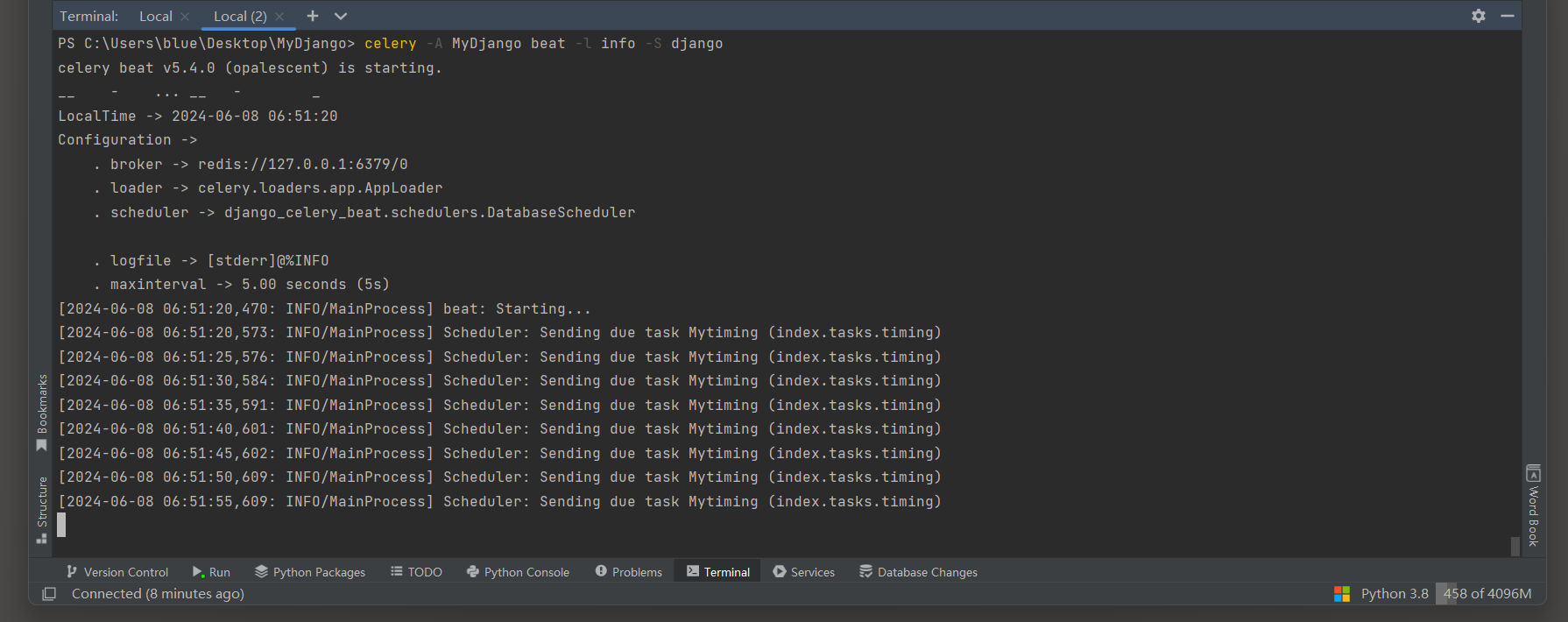
比如定时任务Mytiming , 它是每间隔 5 秒就会执行异步任务timing ,
我们在Terminal或数据表django_celery_results_taskresult中都可以查看定时任务的执行情况 , 如图 12 - 30 所示 .
图 12 - 30 定时任务的执行情况
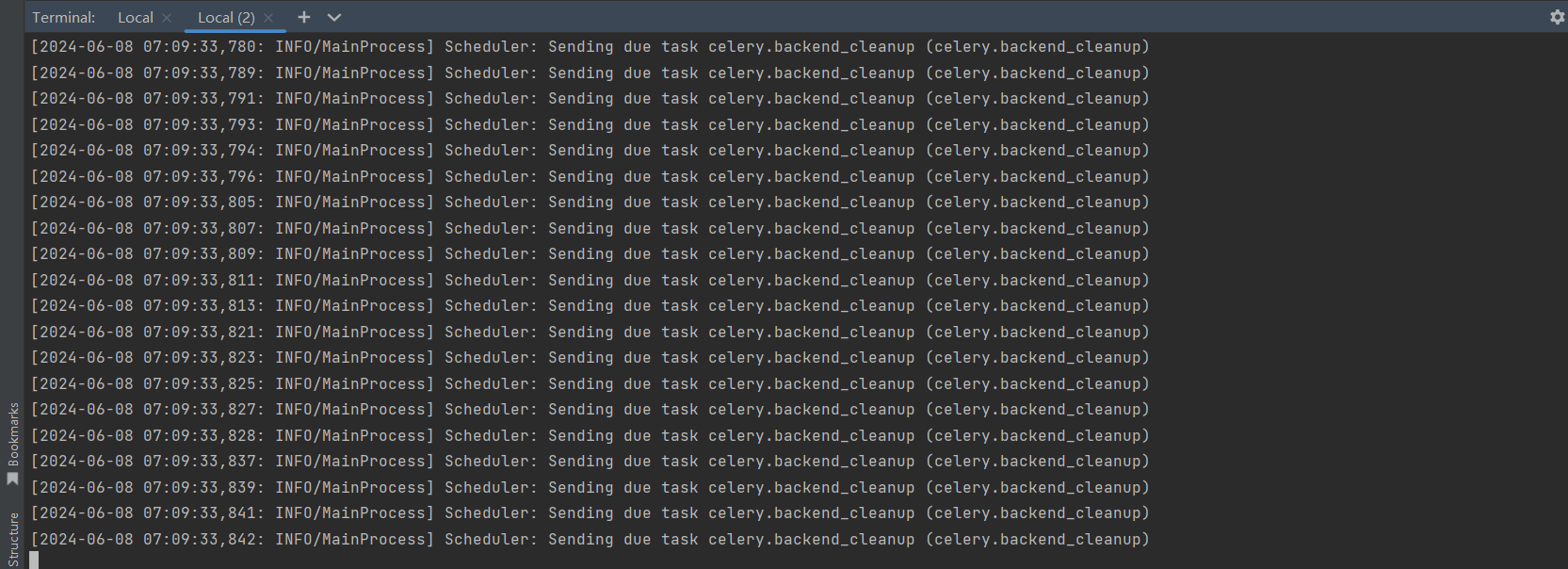
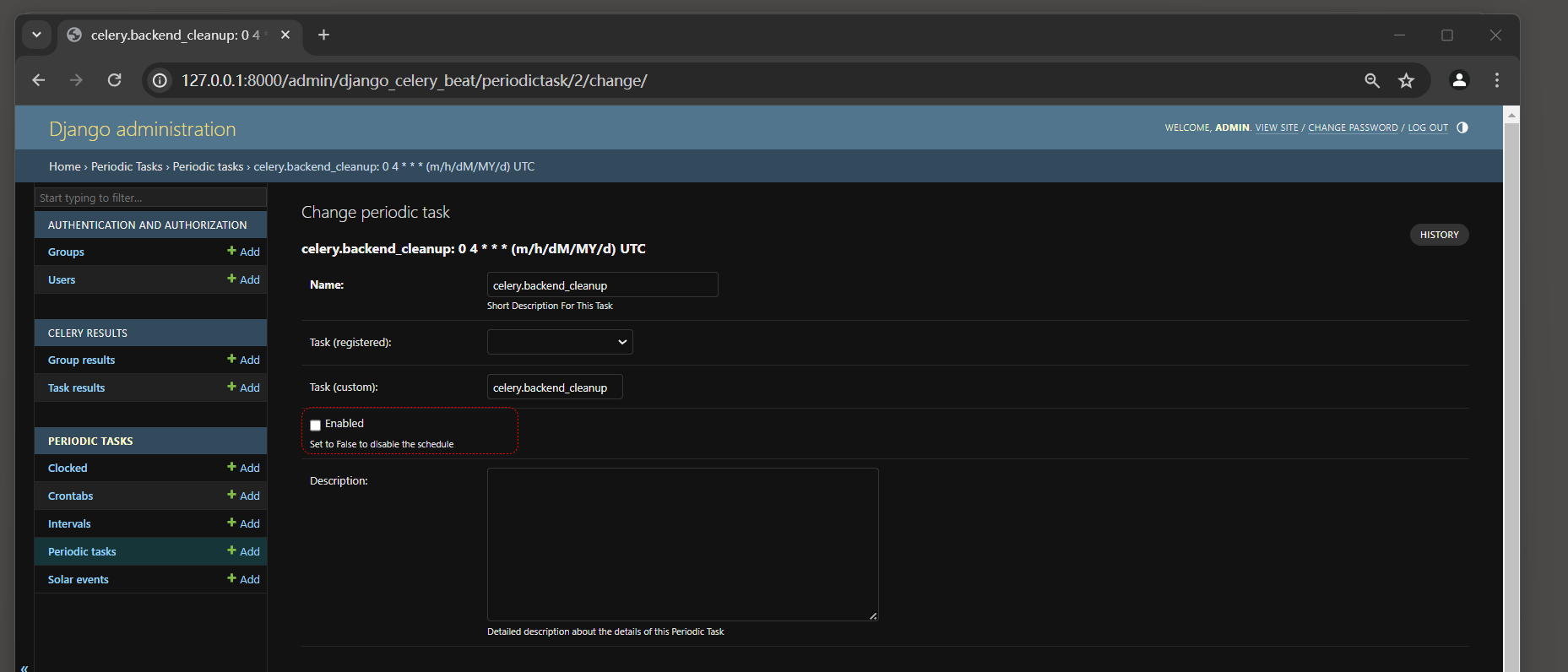
django celery . backend_cleanup是一个用于清理Celery任务结果的函数 .
它的主要作用是删除已经过期的任务结果 , 以避免数据库中的任务结果数据过多导致性能下降 . 启动定时任务后会 , 自动创建celery . backend_cleanup任务 , 这个任务是UTC时间凌晨 4 点执行一次 .
由于配置文件中我们设置关闭UTC时间 : CELERY_ENABLE_UTC = False , 这会出现一个BUG ,
启动定时后 , celery . backend_cleanup任务每秒执行上百次 . . . 修改了间隔时间后 , 启动beat后自动还原 . . .
解决方式 1 : CELERY_ENABLE_UTC = True
解决方式 1 : 禁用任务
Web在线聊天室的实现方法有多种 , 每一种实现方法的基本原理各不相同 , 详细说明如下 :
( 1 ) 使用AJAX技术 : 通过AJAX实现网页与服务器的无刷新交互 , 在网页上每隔一段时间就通过AJAX从服务器中获取数据 , 然后将数据更新并显示在网页上 , 这种方法简单明了 , 缺点是实时性不高 .
( 2 ) 使用Comet ( Pushlet ) 技术 : Comet是一种Web应用架构 , 服务器以异步方式向浏览器推送数据 , 无须浏览器发送请求 . Comet架构非常适合事件驱动的Web应用 , 以及对交互性和实时性要求较高的应用 , 如股票交易行情分析 , 聊天室和Web版在线游戏等 .
( 3 ) 使用XMPP协议 : XMPP ( 可扩展消息处理现场协议 ) 是基于XML的协议 , 这是专为即时通信系统设计的通信协议 , 用于即时消息以及在线现场探测 , 这个协议允许用户向其他用户发送即时消息 .
( 4 ) 使用Flash的XmlSocket : Flash Media Server是一个强大的流媒体服务器 , 它基于RTMP协议 , 提供了稳定的流媒体交互功能 , 内置远程共享对象 ( Shared Object ) 的机制 , 是浏览器创建并连接服务器的远程共享对象 .
( 5 ) 使用WebSocket协议 : WebSocket是通过单个TCP连接提供全双工 ( 双向通信 ) 通信信道的计算机通信协议 , 可在浏览器和服务器之间进行双向通信 , 允许多个用户连接到同一个实时服务器 , 并通过API进行通信并立即获得响应 . WebSocket不仅限于聊天 / 消息传递应用程序 , 还适用于实时更新和即时信息交换的应用程序 , 比如现场体育更新 , 股票行情 , 多人游戏 , 聊天应用 , 社交媒体等 .
如果想在Django里开发Web在线聊天功能 , 建议使用WebSocket协议实现 .
虽然Django 3 版本新增了ASGI服务 , 但它对WebSocket的功能支持尚未完善 , 所以还需要借助第三方模块Channels ,
通过Channels使用WebSocket协议实现浏览器和服务器的双向通信 , 它的实现原理是在Django里定义Channels的API接口 ,
由网页的JavaScript与API接口构建通信连接 , 使浏览器和服务器之间相互传递数据 .
Channels的功能必须依赖于Redis数据库 , 除了安装channels模块之外 , 还需要安装channels_redis模块 .
我们使用pip指令分别安装channels和channels_redis模块 , 安装指令如下 :
pip install channels
pip install channels_redis
pip install pypiwin32
pip install - i https: // pypi. tuna. tsinghua. edu. cn/ simple channels
pip install - i https: // pypi. tuna. tsinghua. edu. cn/ simple channels_redis
pip install - i https: // pypi. tuna. tsinghua. edu. cn/ simple pypiwin32
完成第三方功能应用Channels的安装后 , 下一步在Django中配置Channels .
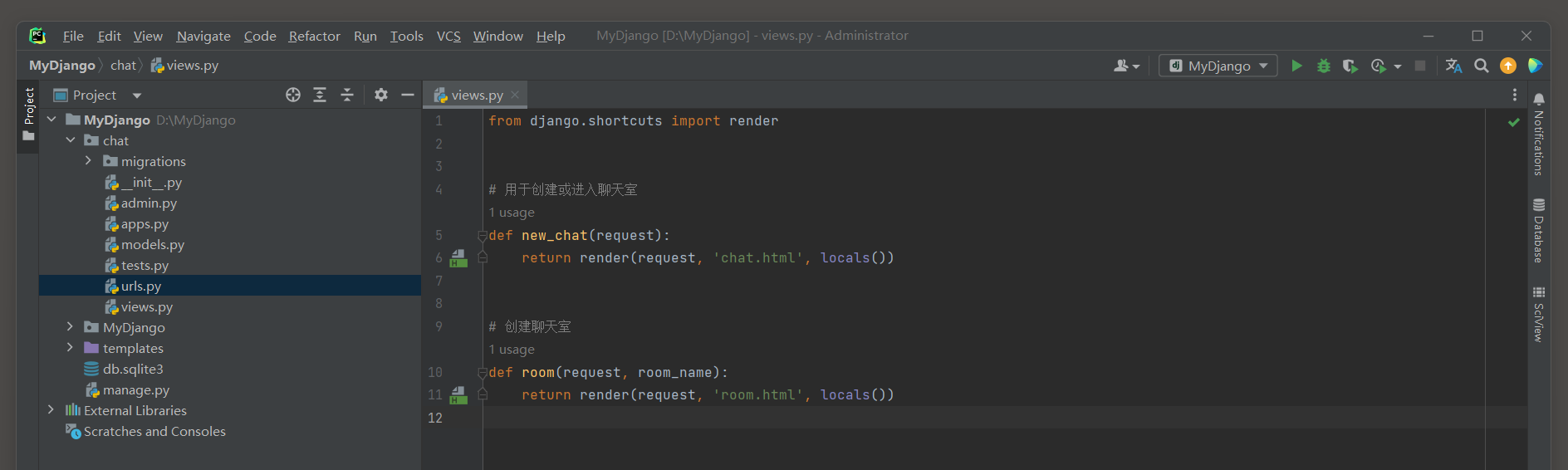
以MyDjango为例 , 首先创建项目应用chat , 并在项目应用chat里新建urls . py文件 ;
然后在MyDjango文件夹里创建文件consumers . py和routing . py , 文件名称没有硬性要求 , 读者可以自行命名 ,
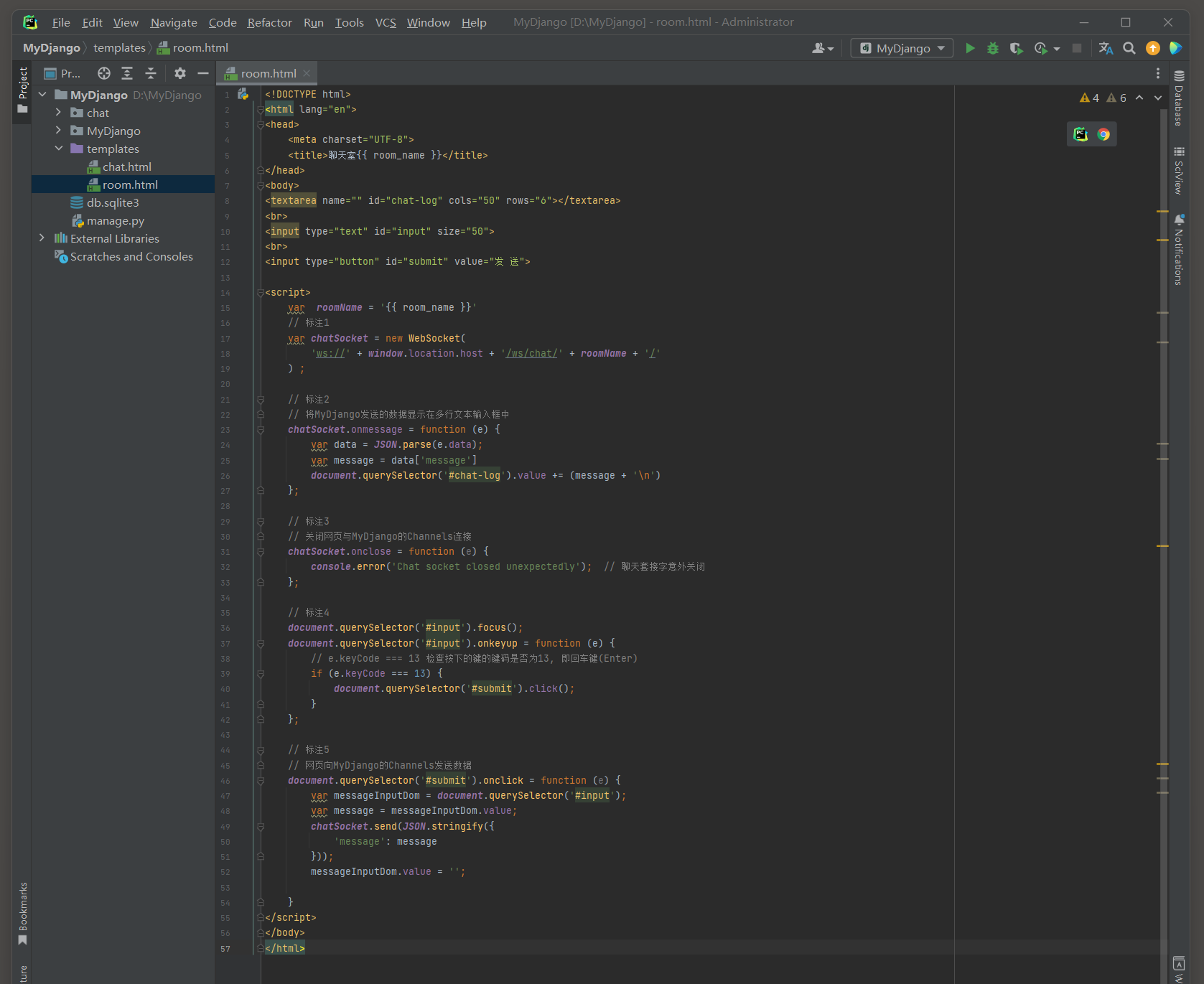
在templates文件夹中创建模板文件chat . html和room . html ;
最后执行整个项目的数据迁移 , 因为Channels需要使用Django内置的会话Session机制 , 用于区分和识别每个用户的身份信息 .
PS D: \MyDjango> python manage. py migrate
Operations to perform: Apply all migrations: admin, auth, contenttypes, sessions
Running migrations: Applying contenttypes. 0001_initial. . . OKApplying auth. 0001_initial. . . OKApplying admin. 0001_initial. . . OKApplying admin. 0002_logentry_remove_auto_add. . . OKApplying admin. 0003_logentry_add_action_flag_choices. . . OKApplying contenttypes. 0002_remove_content_type_name. . . OKApplying auth. 0002_alter_permission_name_max_length. . . OKApplying auth. 0003_alter_user_email_max_length. . . OKApplying auth. 0004_alter_user_username_opts. . . OKApplying auth. 0005_alter_user_last_login_null. . . OKApplying auth. 0006_require_contenttypes_0002. . . OKApplying auth. 0007_alter_validators_add_error_messages. . . OKApplying auth. 0008_alter_user_username_max_length. . . OKApplying auth. 0009_alter_user_last_name_max_length. . . OKApplying auth. 0010_alter_group_name_max_length. . . OKApplying auth. 0011_update_proxy_permissions. . . OKApplying auth. 0012_alter_user_first_name_max_length. . . OKApplying sessions. 0001_initial. . . OK
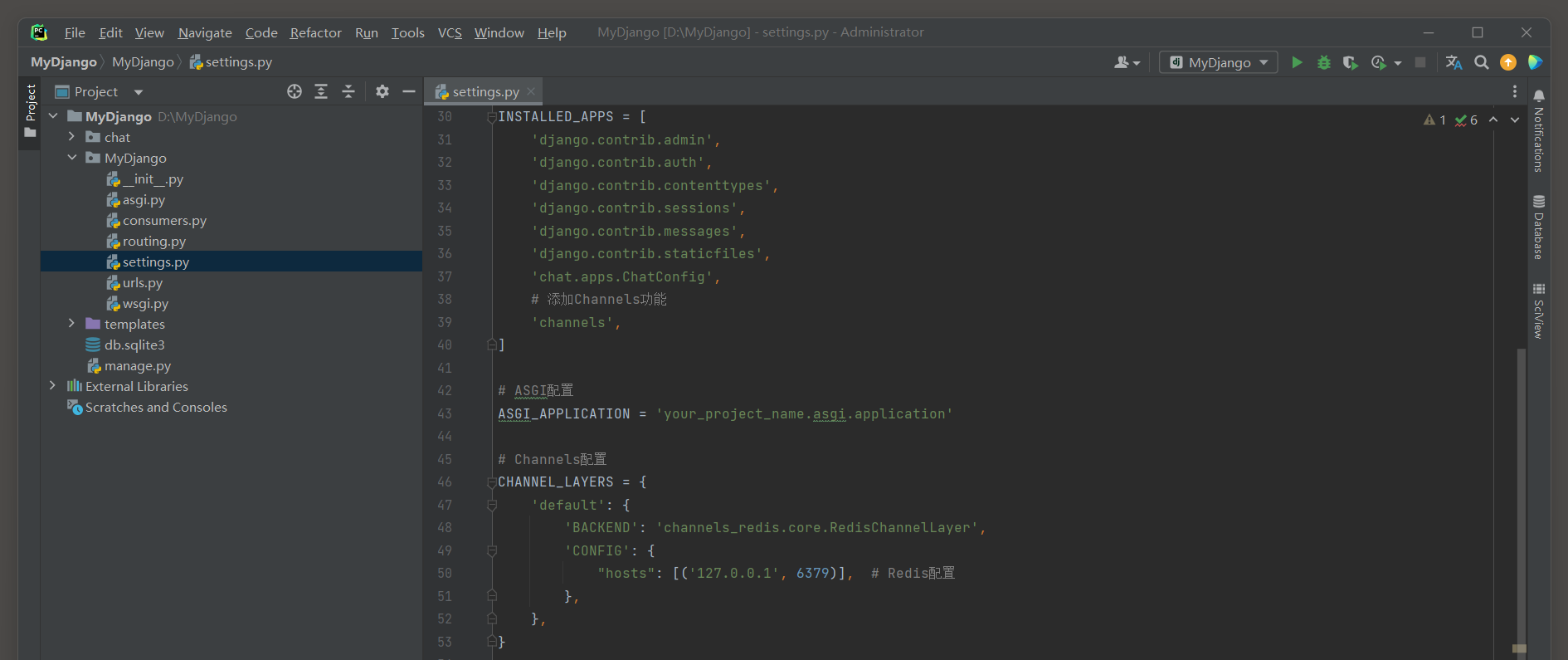
打开MyDjango的settings . py , 将第三方功能应用Channels添加到MyDjango .
首先在配置属性INSTALLED_APPS中分别添加channels和chat , 前者是第三方功能应用Channels , 后者是项目应用chat .
第三方功能应用Channels以项目应用的形式添加到MyDjango , 由于Channels的功能依赖于Redis数据库 ,
因此还需要在settings . py中设置Channels的功能配置 , 配置信息如下 :
INSTALLED_APPS = [ 'django.contrib.admin' , 'django.contrib.auth' , 'django.contrib.contenttypes' , 'django.contrib.sessions' , 'django.contrib.messages' , 'django.contrib.staticfiles' , 'chat.apps.ChatConfig' , 'channels' ,
]
ASGI_APPLICATION = 'MyDjngo.routing.application'
CHANNEL_LAYERS = { 'default' : { 'BACKEND' : 'channels_redis.core.RedisChannelLayer' , 'CONFIG' : { "hosts" : [ ( '127.0.0.1' , 6379 ) ] , } , } ,
}
功能配置CHANNEL_LAYERS用于设置Redis数据库的连接方式 ,
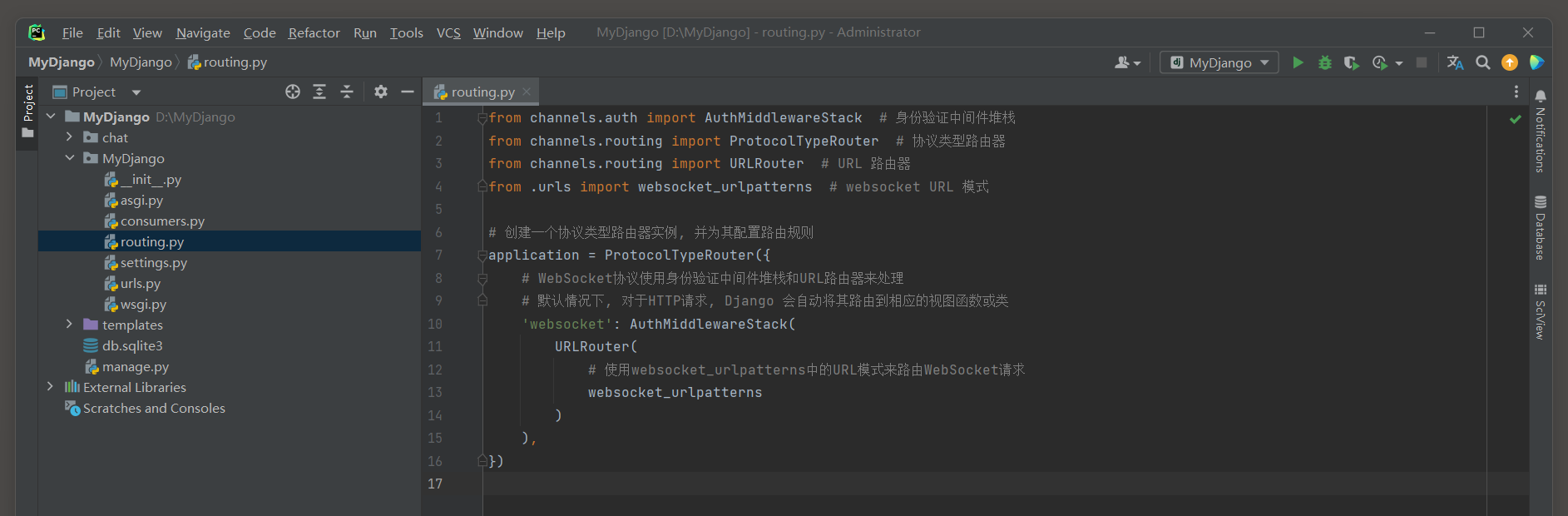
ASGI_APPLICATION指向MyDjango的routing . py定义的application对象 , 该对象把Django与Channels建立连接 , 具体的定义过程如下 :
from channels. auth import AuthMiddlewareStack
from channels. routing import ProtocolTypeRouter
from channels. routing import URLRouter
from . urls import websocket_urlpatterns
application = ProtocolTypeRouter( { 'websocket' : AuthMiddlewareStack( URLRouter( websocket_urlpatterns) ) ,
} )
上述代码的application对象由ProtocolTypeRouter实例化生成 ,
在实例化过程中 , 需要传入参数application_mapping ,
参数以字典格式表示 , 字典的key为websocket , 代表使用WebSocket协议 ;
字典的value是Channels的路由对象websocket_urlpatterns , 它定义在MyDjango的urls . py中 .
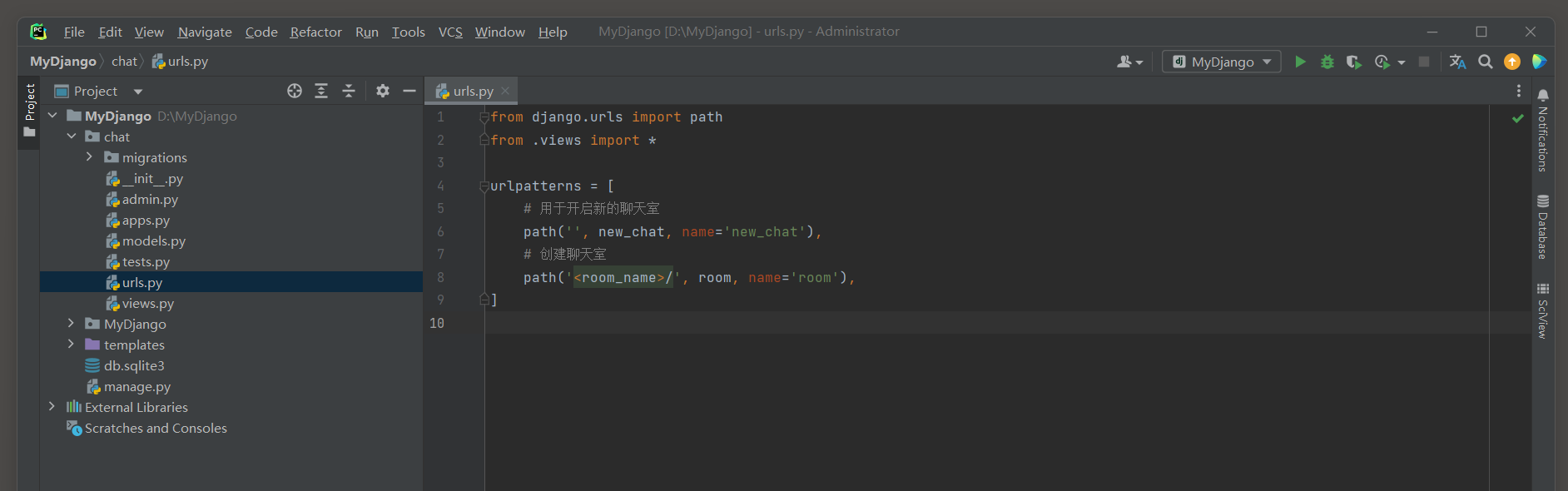
因此 , 在MyDjango的urls . py中定义路由对象urlpatterns和websocket_urlpatterns , 代码如下 :
from django. urls import path, include
from . consumers import ChatConsumerurlpatterns = [ path( '' , include( ( 'chat.urls' , 'chat' ) , namespace= 'chat' ) )
]
websocket_urlpatterns = [ path( 'ws/chat/<room_name>/' , ChatConsumer. as_asgi( ) ) ,
] 路由对象urlpatterns用于定义项目应用chat的路由信息 , websocket_urlpatterns用于定义Channels的路由信息 .
上述代码只定义路由ws / chat / < room_name > / , 它是由视图类ChatConsumer处理和响应HTTP请求的 ,
该路由作为Channels的API接口 , 由网页的JavaScript与该路由构建通信连接 , 使浏览器和服务器之间相互传递数据 .
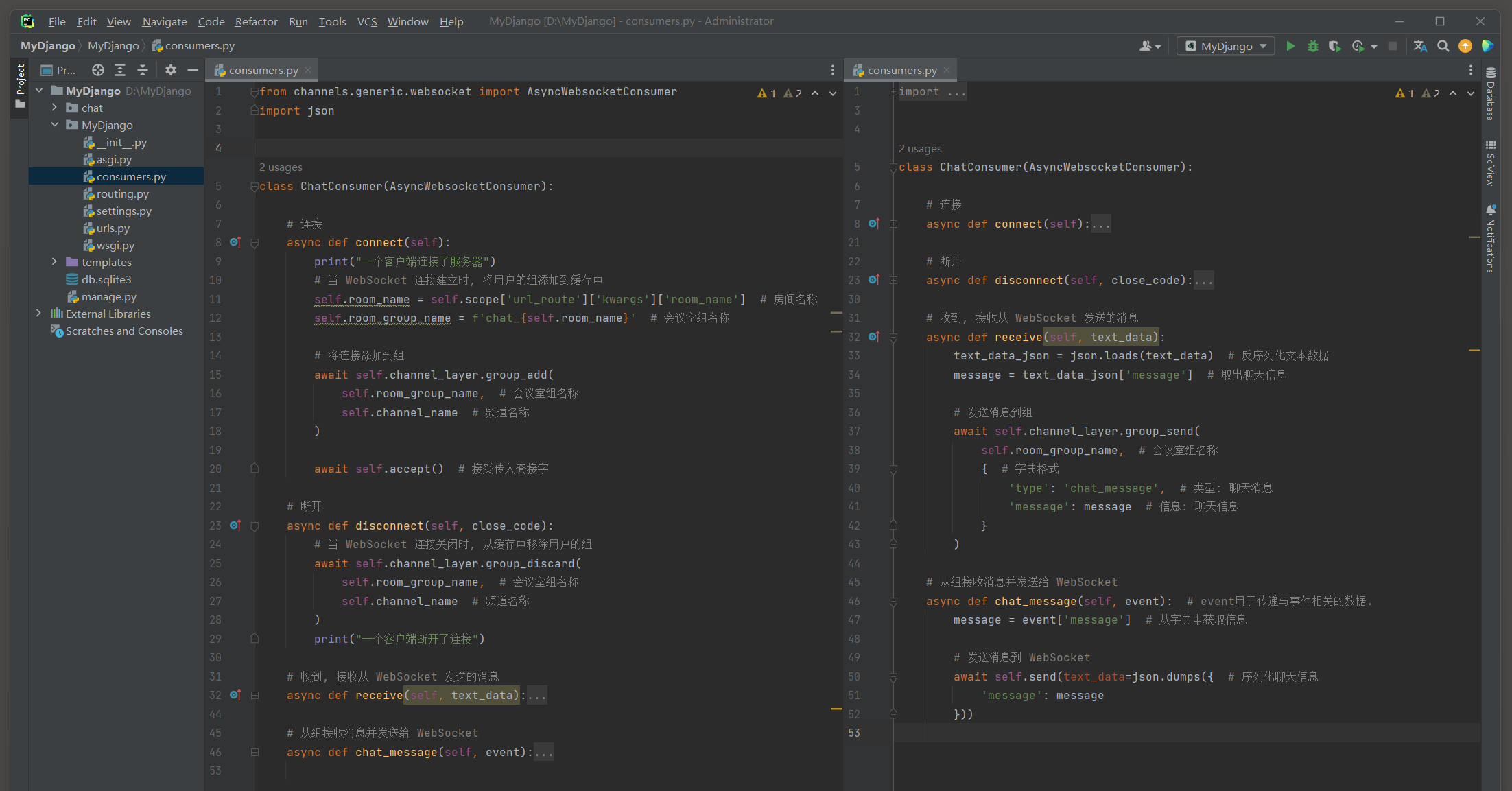
在MyDjango的consumers . py中定义视图类ChatConsumer , 代码如下 :
from channels. generic. websocket import AsyncWebsocketConsumer
import jsonclass ChatConsumer ( AsyncWebsocketConsumer) : async def connect ( self) : print ( "一个客户端连接了服务器" ) self. room_name = self. scope[ 'url_route' ] [ 'kwargs' ] [ 'room_name' ] self. room_group_name = f'chat_ { self. room_name} ' await self. channel_layer. group_add( self. room_group_name, self. channel_name ) await self. accept( ) async def disconnect ( self, close_code) : await self. channel_layer. group_discard( self. room_group_name, self. channel_name ) print ( "一个客户端断开了连接" ) async def receive ( self, text_data) : text_data_json = json. loads( text_data) message = text_data_json[ 'message' ] await self. channel_layer. group_send( self. room_group_name, { 'type' : 'chat_message' , 'message' : message } ) async def chat_message ( self, event) : message = event[ 'message' ] await self. send( text_data= json. dumps( { 'message' : message} ) )
视图类ChatConsumer继承父类AsyncWebsocketConsumer , 父类定义WebSocket协议的异步通信方式 ,
从视图类ChatConsumer的类方法看到 , 每个类方法都使用async语法标识 , async语法从Python 3.5 开始引入 ,
该语法能将函数方法以异步方式运行 , 从而提高代码的运行速度和性能 . 除此之外 , Channels还定义WebsocketConsumer类 , 它与AsyncWebsocketConsumer实现的功能一致 ,
但是以同步方式运行 , 对比AsyncWebsocketConsumer而言 , 它的运行速度和性能较低 .
WebsocketConsumer和AsyncWebsocketConsumer是通过字符串格式进行数据通信的 ,
如果使用JSON格式进行数据通信 , 那么可以采用Channels定义的JsonWebsocketConsumer或AsyncJsonWebsocketConsumer .
综上所述 , 在Django里配置第三方功能应用Channels的步骤如下 :
( 1 ) 在settings . py的INSTALLED_APPS中添加channels , 第三方功能应用Channels以项目应用的形式添加到Django中 ; 同时设置Channels的功能配置属性ASGI_APPLICATION和CHANNEL_LAYERS .
( 2 ) 功能配置ASGI_APPLICATION设置了Django与Channels的连接方式 , 连接过程由application对象实现 . application对象是由ProtocolTypeRouter实例化生成的 , 在实例化过程中 , 需要传入Channels的路由对象websocket_urlpatterns .
( 3 ) 路由对象websocket_urlpatterns定义在MyDjango的urls . py中 , 这是定义Channels的API接口 , 由网页的JavaScript与API接口构建通信连接 , 使浏览器和服务器之间相互传递数据 .
( 4 ) 路由ws / chat / < room_name > / 由视图类ChatConsumer处理和响应HTTP请求 , 视图类ChatConsumer继承父类AsyncWebsocketConsumer , 这是使用WebSocket协议的异步通信方式实现浏览器和服务器之间的数据传递 .
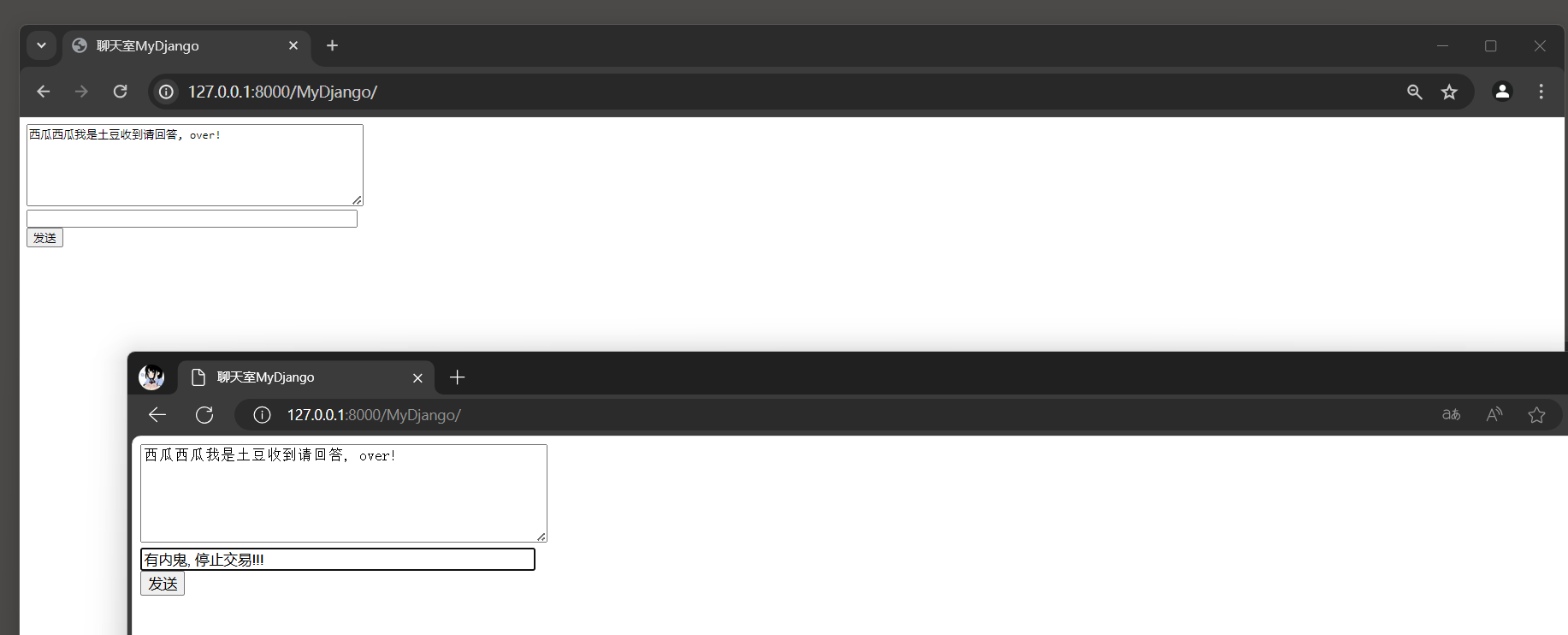
在 12.6 .1 小节实现了Django和Channels的异步通信连接 , 本节将讲述如何在Django中使用Channels实现Web在线聊天功能 .
我们在MyDjango的urls . py中定义了项目应用chat的路由空间 , 它指向项目应用chat的urls . py ,
在项目应用chat的urls . py中分别定义路由new_chat和room , 代码如下 :
from django. urls import path
from . views import * urlpatterns = [ path( '' , new_chat, name= 'new_chat' ) , path( '<room_name>/' , room, name= 'room' ) ,
]
路由new_chat供用户创建或进入某个聊天室 , 由视图函数newChat处理和响应HTTP请求 .
路由room是聊天室的聊天页面 , 路由地址设有路由变量room_name , 它代表聊天室名称 , 由视图函数room处理和响应HTTP请求 .
在chat的views . py中定义视图函数new_chat和room , 视图函数的定义过程如下 :
from django. shortcuts import render
def new_chat ( request) : return render( request, 'chat.html' , locals ( ) )
def room ( request, room_name) : return render( request, 'room.html' , locals ( ) )
视图函数new_chat和room分别使用模板文件chat . html和room . html生成网页内容 .
由于路由new_chat供用户创建或进入某个聊天室 , 因此模板文件chat . html需要生成路由room的路由地址 , 实现代码如下 :
<! DOCTYPE html > < htmllang = " en" > < head> < metacharset = " UTF-8" > < title> </ title> </ head> < body> < div> </ div> < br> < inputtype = " text" id = " input" size = " 30" > < br> < inputtype = " button" id = " submit" value = " 进入" > < script> document. querySelector ( '#input' ) . focus ( ) ; document. querySelector ( '#input' ) . onkeyup = function ( e ) { if ( e. keyCode === 13 ) { document. querySelector ( '#submit' ) . click ( ) ; } } document. querySelector ( '#submit' ) . onclick = function ( e ) { var roomName = document. querySelector ( '#input' ) . value; window. location. pathname = '/' + roomName + '/' ; } ;
</ script> </ body> </ html>
模板文件chat . html设有文本输入框和 '进入' 按钮 , 当用户在文本输入框输入聊天室名称后 ,
单击 '进入' 按钮或按回车键将触发网页的JavaScript脚本 ,
JavaScript将用户输入的聊天室名称作为路由room的路由变量room_name , 控制浏览器访问路由room .
我们在路由new_chat的页面使用JavaScript脚本访问路由room ,
此外还可以使用网页表单方式实现 , 由视图函数new_chat重定向访问路由room .
路由room使用模板文件room . html生成聊天室的聊天页面 , 因此模板文件room . html的代码如下 :
<! DOCTYPE html > < htmllang = " en" > < head> < metacharset = " UTF-8" > < title> </ title> </ head> < body> < textareaname = " " id = " chat-log" cols = " 50" rows = " 6" > </ textarea> < br> < inputtype = " text" id = " input" size = " 50" > < br> < inputtype = " button" id = " submit" value = " 发 送" > < script> var roomName = '{{ room_name }}' var chatSocket = new WebSocket ( 'ws://' + window. location. host + '/ws/chat/' + roomName + '/' ) ; chatSocket. onmessage = function ( e ) { var data = JSON . parse ( e. data) ; var message = data[ 'message' ] document. querySelector ( '#chat-log' ) . value += ( message + '\n' ) } ; chatSocket. onclose = function ( e ) { console. error ( 'Chat socket closed unexpectedly' ) ; } ; document. querySelector ( '#input' ) . focus ( ) ; document. querySelector ( '#input' ) . onkeyup = function ( e ) { if ( e. keyCode === 13 ) { document. querySelector ( '#submit' ) . click ( ) ; } } ; document. querySelector ( '#submit' ) . onclick = function ( e ) { var messageInputDom = document. querySelector ( '#input' ) ; var message = messageInputDom. value; chatSocket. send ( JSON . stringify ( { 'message' : message} ) ) ; messageInputDom. value = '' ; }
</ script> </ body> </ html>
WebSocket连接 ( 标注 1 ) : 创建一个新的WebSocket连接 , 连接到后端服务器上的特定端点 .
这个端点由当前页面的主机名 , WebSocket路径和从后端传递的room_name变量组成 . 接收消息 ( 标注 2 ) : 当WebSocket接收到来自后端的消息时 , 会触发onmessage事件 .
在这个事件处理程序中 , 接收到的数据被解析为JSON格式 , 然后提取其中的message字段 .
将接收到的消息追加到chat-log文本框的末尾 , 并添加一个换行符以分隔不同的消息 . 连接关闭处理 ( 标注 3 ) : 如果WebSocket连接意外关闭 ( 例如 , 由于网络问题或后端服务器关闭 ) , 会触发onclose事件 .
在这个事件处理程序中 , 将一条错误消息打印到控制台 . 输入框处理 ( 标注 4 ) : 当用户将焦点放在输入框 ( # input_上并按下回车键 ( 键码为 13 ) 时 , 触发一个键盘事件 .
在这个事件处理程序中 , 模拟点击 '发送' 按钮 ( # submit ) . 发送消息 ) 标注 5 ) : 当用户点击 '发送' 按钮时 , 触发一个点击事件 .
在这个事件处理程序中 , 从输入框获取用户输入的消息 , 并将其作为JSON对象发送到后端 .
发送的消息包含一个message字段 , 其值为用户输入的消息 .
发送消息后 , 清空输入框以便用户可以输入新的消息 .
聊天室的聊天页面设有多行文本输入框 ( < textarea > 标签 ) , 单行文本输入框 ( < input type = "text" > 标签 ) 和 '发送' 按钮 .
多行文本输入框用于显示用户之间的聊天记录 ; 单行文本输入框供当前用户输入聊天内容 ;
'发送' 按钮可以将聊天内容发送给所有在线的用户 , 并且显示在多行文本输入框中 . 聊天功能的实现过程由JavaScript脚本执行 , 上述的JavaScript代码设有 5 个标注 , 每个标注实现的功能说明如下 :
( 1 ) 标注①创建WebSocket对象 , 对象命名为chatSocket , 它连接了MyDjango定义的路由ws / chat / < room_name > / , 使网页与MyDjango的Channels实现通信连接 .
( 2 ) 标注②设置chatSocket对象的onmessage事件触发 , 该事件接收MyDjango发送的数据 , 并将数据显示在多行文本输入框中 .
( 3 ) 标注③设置chatSocket对象的onclose事件触发 , 如果JavaScript与MyDjango的通信连接发生异常 , 就会触发此事件 , 该事件在浏览器的开发者工具中输出提示信息 .
( 4 ) 标注④设置 '发送' 按钮的onkeyup事件触发 , 如果用户按回车键即可触发此事件 , 那么该事件将会触发 '发送' 按钮的onclick事件 .
( 5 ) 标注⑤设置 '发送' 按钮的onclick事件触发 , 该事件将单行文本输入框的内容发送给MyDjango的Channels . Channels接收某用户的数据后 , 将数据发送给同一个聊天室的所有用户 , 此时就会触发chatSocket对象的onmessage事件 , 将数据显示在每个用户的多行文本输入框中 , 这样同一个聊天室的所有用户都能看到某个用户发送的信息 .
最后运行MyDjango , 打开谷歌浏览器并访问 127.0 .0 .1 : 8000 , 在文本输入框中输入聊天室名称并单击 '进入' 按钮 , 如图 12 - 31 所示 .
图 12 - 31 创建或进入聊天室
( 启动的时候会遇到问题两个问题 :
问题 1 : https : / / blog . csdn . net / qq_46137324 / article / details / 139568935 ?spm = 1001.2014 .3001 .5501
问题 2 : https : / / blog . csdn . net / qq_46137324 / article / details / 139568922 ?spm = 1001.2014 .3001 .5501 )
当成功创建聊天室MyDjango后 , 打开IE浏览器访问 127.0 .0 .1 : 8000 /MyDjango.
聊天室MyDjango已有两位在线用户 , 谷歌浏览器代表用户A,EDGE浏览器代表用户B .
我们使用用户A发送信息 , 在用户B的页面可以即时看到信息内容 , 如图 12 - 32 所示 .
图 12 - 32 Web在线聊天
因为Django具有很强的可扩展性 , 从而延伸了第三方功能应用 .
通过本章的学习 , 读者能够在网站开发过程中快速实现API接口开发 , 验证码生成与使用 , 站内搜索引擎 ,
第三方网站实现用户注册 , 异步任务和定时任务 , 即时通信等功能 . 开发网站的API可以在视图函数中使用响应类JsonResponse实现 , 它将字典格式的数据作为响应内容 .
使用响应类JsonResponse开发API需要根据用户请求信息构建字典格式的数据内容 ,
数据构建的过程可能涉及模型的数据查询 , 数据分页处理等业务逻辑 , 这种方式开发API很容易造成代码冗余 , 不利于功能的变更和维护 .
为了简化API的开发过程 , 我们可以使用Django Rest Framework框架实现API开发 .
使用框架开发不仅能减少代码冗余 , 还可以规范代码的编写格式 , 这对企业级开发来说很有必要 ,
毕竟每个开发人员的编程风格存在一定的差异 , 开发规范化可以方便其他开发人员查看和修改 .
如果想在Django中实现验证码功能 , 那么可以使用PIL模块生成图片验证码 , 但不建议使用这种实现方式 .
除此之外 , 还可以通过第三方应用Django Simple Captcha实现 ,
验证码的生成过程由该应用自动执行 , 开发者只需考虑如何应用到Django项目中即可 .
站内搜索是网站常用的功能之一 , 其作用是方便用户快速查找站内数据以便查阅 .
对于一些初学者来说 , 站内搜索可以使用SQL模糊查询实现 ,
从某个角度来说 , 这种实现方式只适用于个人小型网站 , 对于企业级的开发 , 站内搜索是由搜索引擎实现的 .
Django Haystack是一个专门提供搜索功能的Django第三方应用 , 它支持Solr , Elasticsearch , Whoosh和Xapian等多种搜索引擎 ,
配合著名的中文自然语言处理库jieba分词可以实现全文搜索系统 .
用户注册与登录是网站必备的功能之一 , Django内置的Auth认证系统可以帮助开发人员快速实现用户管理功能 .
但很多网站为了加强社交功能 , 在用户管理功能上增设了第三方网站的用户注册与登录功能 , 这是通过OAuth 2.0 认证与授权来实现的 .
Django的异步主要由Celery框架实现 , 这是Python开发的异步任务队列 ,
它支持使用任务队列的方式在分布的机器 , 进程和线程上执行任务调度 . Celery侧重于实时操作 , 每天处理数以百万计的任务 .
Celery本身不提供消息存储服务 , 它使用第三方数据库来传递任务 , 目前第三方数据库支持RabbitMQ , Redis和MongoDB等 .
Channels是使用WebSocket协议实现浏览器和服务器的双向通信的 , 它的实现原理是在Django中定义Channels的API接口 ,
由网页的JavaScript与API接口构建通信连接 , 使浏览器和服务器之间相互传递数据 .