3 编译与调试
3.1 gcc/g++编译器
- 当我们进行编译的时候,要使用一系列的工具,我们称之为工具链。SDK就是编译工具链的简写,我们所使用的是gcc系列编译工具链。
- 使用-v参数来查看gcc的版本,从而确定某些语法特性是否可用,比如是否允许使用时声明。
gcc -v - 对于.c格式的C文件,可以采用gcc或g++编译。
- 对于 .cc、.cpp格式的C++文件,应该采用g++进行编译。
| 选项 | 效果 |
|---|---|
| -c | 表示编译源文件 |
| -o | 表示输出目标文件 |
| -g | 表示在目标文件中产生调试信息,用于gdb调试 |
| -D | <宏定义> 编译时将宏定义传入进去 |
| -Wall | 打开所有类型的警告 |
3.1.1 gcc编译过程
- 使用gcc编译程序的过程是预处理–>编译–>汇编–>链接。期间所使用的工具依次是预处理器,编译器,汇编器as,链接器ld。
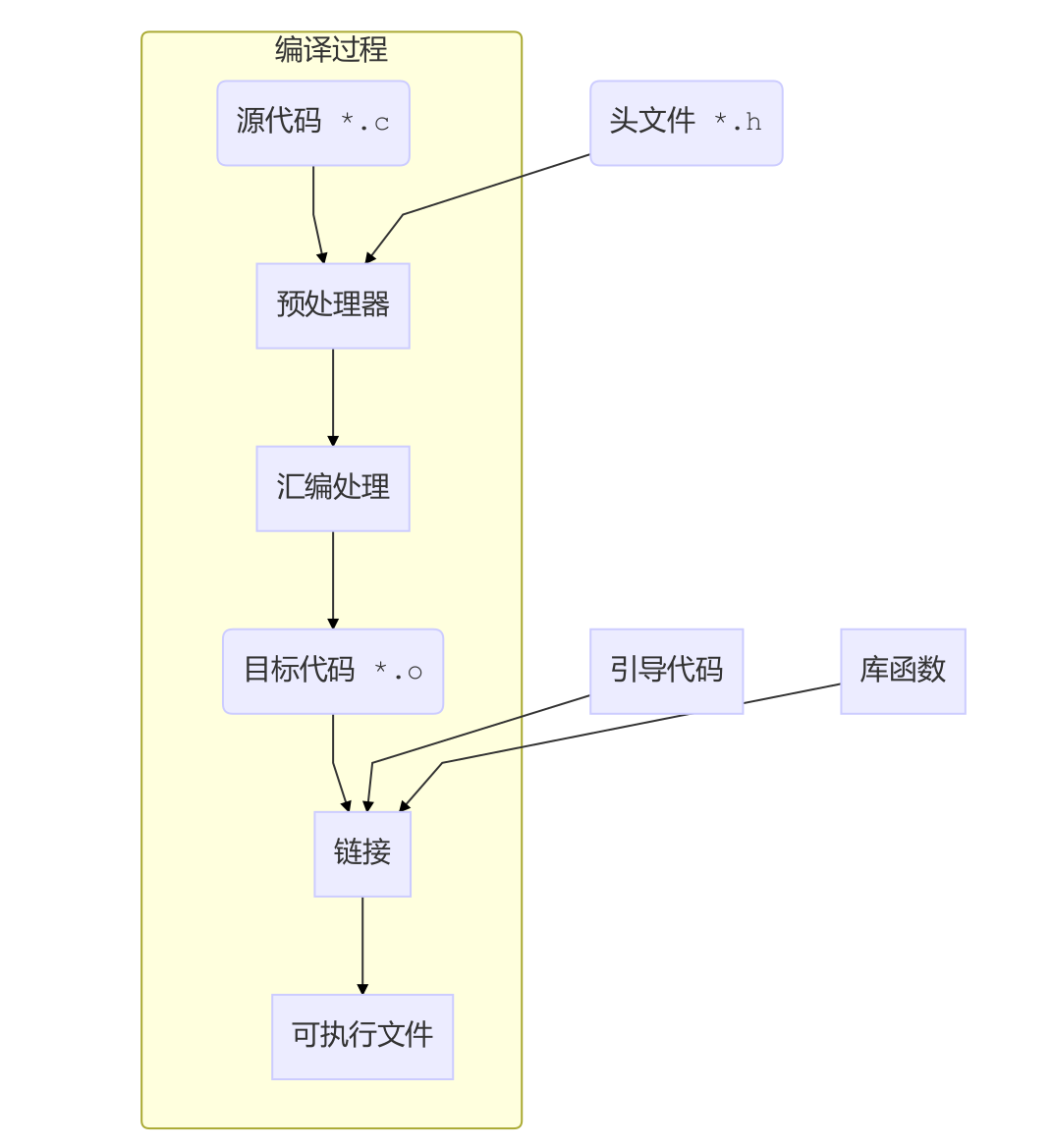
- 编译过程的几个阶段具体如下:
(1) 预处理:预处理器将对源文件中的宏进行展开
(2) 编译:gcc将c文件编译成汇编文件
(3) 汇编:as将汇编文件编译成机器码
(4) 链接:ld将目标文件和外部符号进行连接,得到一个可执行二进制文件
3.2 程序调试gdb
3.2.1 gdb常用命令
- Linux 包含了一个叫gdb的调试程序。gdb可以用来调试C和C++ 程序。在程序编译时用 -g 选项可打开调试选项
- 常见的调试程序的步骤如下:
$ gcc –o filename –Wall filename.c –g //编译一定要加-g
gdb filename//进入调试
l //显示代码(list)
b 4 //在第四行设置断点,相当于VS的F9(break)
r //运行(run)
n //下一步不进入函数,相当于VS的F10(next)
s //表示单步进入函数, 相当于VS的F11(step)
p I //打印变量I,相当于VS的Watch窗口 (print)
c //运行到最后,相当于VS的F5(continue)
q //退出,相当于VS的Shift+F5 (quit)
3.2.2 gdb调试命令列表
- 按 Tab 键补齐命令,用光标键上下翻动历史命令。用help up看帮助
| 命令格式 | 含义 |
|---|---|
| set args 运行时的参数 | 指定运行时的参数 |
| show args | 查看设置好的参数 |
| info b | 查看断点信息 |
| break [文件名:] 行号或者函数名 [ if <条件表达式>] | 设置断点 示例:b 23 if i2 当i2时,在23行触发断点 |
| tbreak [文件名:] 行号或者函数名 [if <条件表达式>] | 设置临时断点,触发断点以后会被自动删除 |
| delete [断点号] | 删除指定的断点(如果没有断点号就是所有断点) |
| disable [断点号] | 停止指定的断点(如果没有断点号就是所有断点) |
| enable [断点号] | 激活指定的断点 |
| condition [断点号] <条件表达式> | 修改对应断点的条件 |
| ignore [断点号] <忽略次数> | 忽略断点num次 |
| step | 单步调试,进入函数调用 |
| next | 单步调试,不进入函数调用 |
| finish | 跳出当前函数 |
| continue | 继续执行,直到遇到下个断点 |
| list [文件名:] 行号或者函数名 | 显示程序文本10行 |
| print 表达式或变量 | 监视表达式或者变量的值 |
| x <n/f/u> | 查看内存内容 n表示内存的长度 f表示内存的格式 u表示内存的单位 |
| display 表达式 | 单步调试的时候,设置自动显示的表达式内容 |
| backtrace | 查看调用堆栈 |
3.2.3 gdb调试段错误
- 当程序运行的时候出现了segmentation fault(即段错误)之类的错误以后,使用gdb可以进行调试
- 首先使用ulimit -a 来查看当前系统的各项属性的大小限制
ulimit -a - 再使用ulimit -c unlimited 设置core file size为不限制大小
ulimit -c unlimited - 设置完毕后,可以通过ulimit -a来检查是否成功设置
ulimit -a - 再次运行程序,会产生core文件,通过gdb 可执行程序 core文件,进行调试。直接通过bt可以看到程序段错误时的现场
gdb ./test2 core
3.3 Makefile工程项目管理器
3.3.1 Makefile简述
- 一个工程中的源文件不计数,其按类型、功能、模块分别放在若干个目录中。由于文件非常多,分布比较广,编译这些源文件的命令非常的复杂,此外,为了减少不必要的编译时间,工程中主要采用增量编译的模式,这也对编译命令脚本的设计带来了风险。Makefile是一种按照增量编译模式设计的命令脚本。它建立了各个文件(可执行程序-目标文件-库文件-源代码文件等等)之间的依赖关系,根据依赖关系和修改时间,来决定哪些命令需要定义了一系列的规则来指定,哪些文件需要先编译,哪些文件需要后编译,哪些文件需要重新编译,甚至于进行更复杂的功能操作,因为Makefile就像一个Shell脚本一样,其中也可以执行操作系统的命令。
- 使用Makefile的步骤非常简单,先建立一个名为makefile或者是Makefile的文件,然后在里面写入符合语法规则的编译命令,完成以后只需要在文件所在目录使用make命令就能运行编译命令。
make
3.3.2 规则、目标文件和依赖文件
- Makefile文件的书写逻辑是这样的:首先,先确定需要生成的目标文件,然后,根据目标文件确定它所需的依赖文件,此后,递归地找到依赖文件的依赖文件,直到依赖文件是没有子依赖文件(例如,.c文件,.h文件等)。
- 以上从目标文件来找到依赖文件的就是makefile当中的规则
- 表述目标文件和依赖文件的规则需要采用如下的语法结构
[target]:[prerequisites]
<tab>[command]
- 下面是一个简单的Makefile文件。可以看出,初始的目标文件是main,首先需要得到依赖文件main.o 和func.o,依赖文件又分别依赖于.c的代码文件,然后利用gcc -c命令得到.o的依赖文件,最后再执行gcc -o main main.o func.o得到main的可执行文件
main:main.o func.o
gcc -o main main.o func.o
main.o:main.c
gcc -c main.c
func.o:func.c
gcc -c func.c
- Makefile会自动根据文件的修改时间来判断是否执行指令。如果目标比所有的依赖文件都要“新”,那么就不会执行有关这个目标的所有指令,这个规则对于依赖文件也生效,如果修改了某个原始代码文件,make命令只会根据修改时间,来调整有影响文件。
3.3.3 伪目标
- 有些时候,使用make时并不希望得到最开始的目标文件,而是中间的目标文件。在make命令以后添加目标文件的名字就能完成需求
make [target] - 例如使用make main.o可以只生成main.o这个目标文件,而不会执行前面的命令。
- 利用上述特点,可以专门设置一些伪目标(.PHONY),伪目标并不是生成程序所必须的可执行文件或者依赖 文件,它们更加类似于实现其他功能的命令,例如清理二进制文件,重新生成代码等等
.PHONY:clean rebuild
rebuild:clean main
clean:
rm -rf main.o file.o main
- 伪目标设计的主要是为了避免中间依赖文件和clean、rebuild重名的情况(这种情况,make命令会认为clean已经存在,就不再需要修改的情况),执行伪目标的用法和一般目标一样
make clean
make rebuild
3.3.4 变量
Makefile可以定义变量,在调用的时候,需要使用$()来引用变量(实际上就是字符串替换)
out = main #out代表了main,在运行的时候会进行字符串替代
$(out):main.o func.o
gcc -o $(out) main.o func.o
因为 = 定义变量会在执行的时候出现字符串替代,所以出现递归定义的时候,会进行递归展开。但是有些情况,我们不希望递归展开,只希望进行一次字符串替换,这种情况可以采用 := 来定义变量,这也是工作当中的主流用法
out := main #out代表了main,在定义完成的时候会进行字符串替代
$(out):main.o func.o
gcc -o $(out) main.o func.o
= 和 := 的区别可以从下面的例子当中区别,两次执行的结果会有区别
##case 1 =
#out = hello
#rout = $(out)
#out = world
#$(rout):
# @echo $(rout)
#case 2 :=
out := hello
rout := $(out)
out := world
$(rout):
@echo $(rout)