目录
1.体系结构
2.操作系统(Operator System)
1)概念:
2)结构 示意图(不完整)
3)尝试理解操作系统
4)系统调用和库函数概念
3.认识进程
1.启动
2.进程创建的代码方式 --- 重操作,轻原理
1)创进程
2)我们为什么要创建子进程呢?
1.体系结构
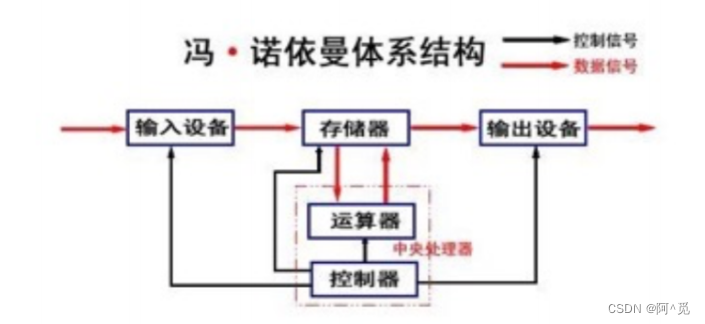 输入设备:键盘、鼠标、摄像头、话筒、磁盘、网卡......
输入设备:键盘、鼠标、摄像头、话筒、磁盘、网卡......
输出设备:显示器、声卡、磁盘、网卡......
CPU:运算器、控制器
存储器:内存
数据是要在计算机的体系结构中进行流动的,流动过程中,进行数据的加工处理从一个设备到另一个设备,本质:是一种拷贝!!!
又因为中央处理器的运行速度非常之快,因此数据设备间的拷贝的效率,决定了计算机整机的基本效率!
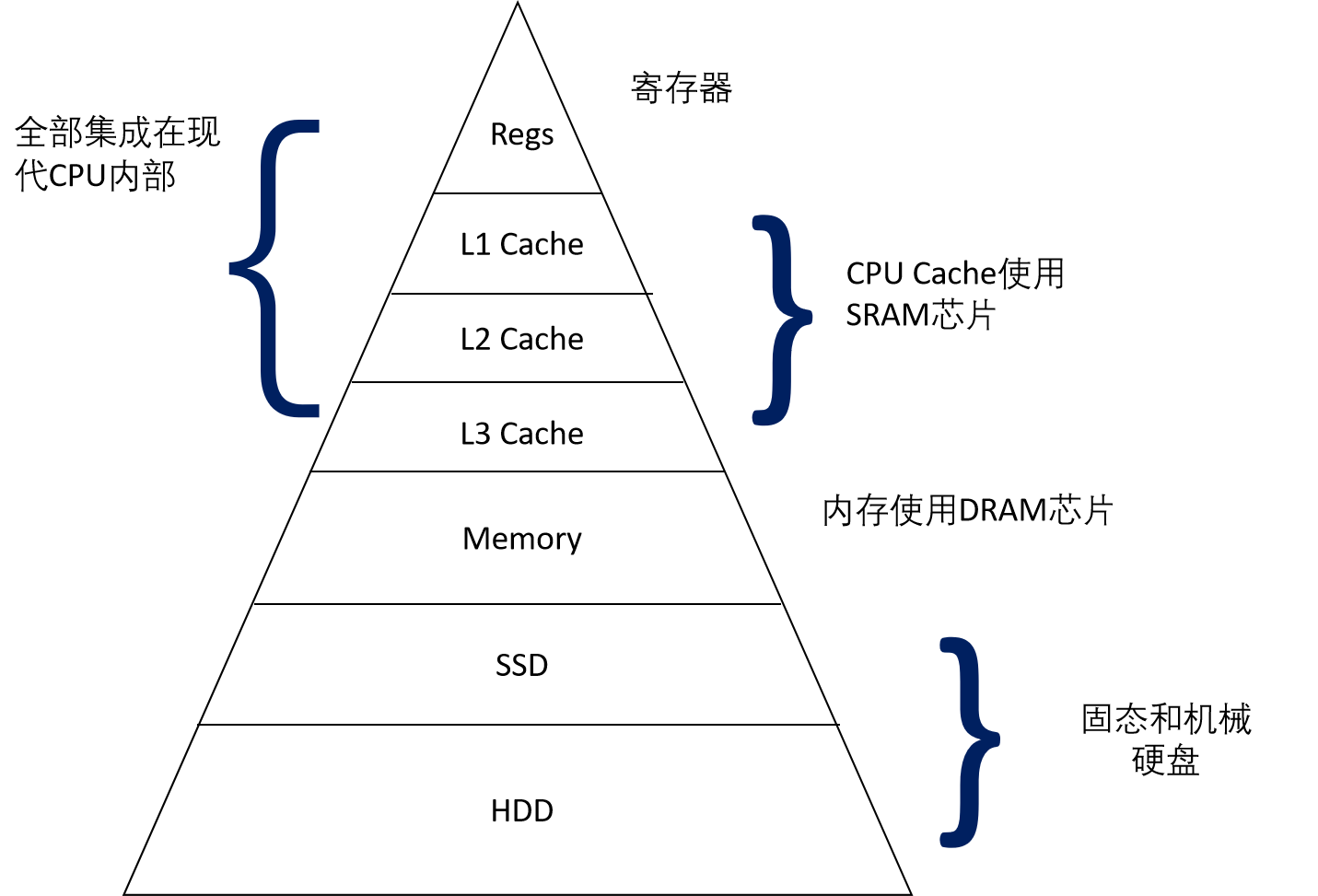
存储:距离CPU越近,效率越高,成本越高
若没有存储器,而是直接将CPU位于输入和输出设备两者的中间,那么将会导致一个类似于木桶效应似的缺点(装水的多少不是由长板子决定的,而是由短板子决定的),若是这样放置,由于输入输出设备拷贝的速度相比CPU来说非常的慢,导致CPU大部分时间不是在处理数据,而是在等待输入输出设备拷贝数据。

CPU 的速度远远快于外部设备(如磁盘、光驱等),内存作为介于 CPU 和外部设备之间的媒介,可以帮助平衡这种速度差异。CPU 可以快速地从内存中读取或写入数据,而内存则可以暂时存储来自外部设备的数据,使得 CPU 不必等待外部设备完成读写操作。
因此要在三者间设置一个存储器。
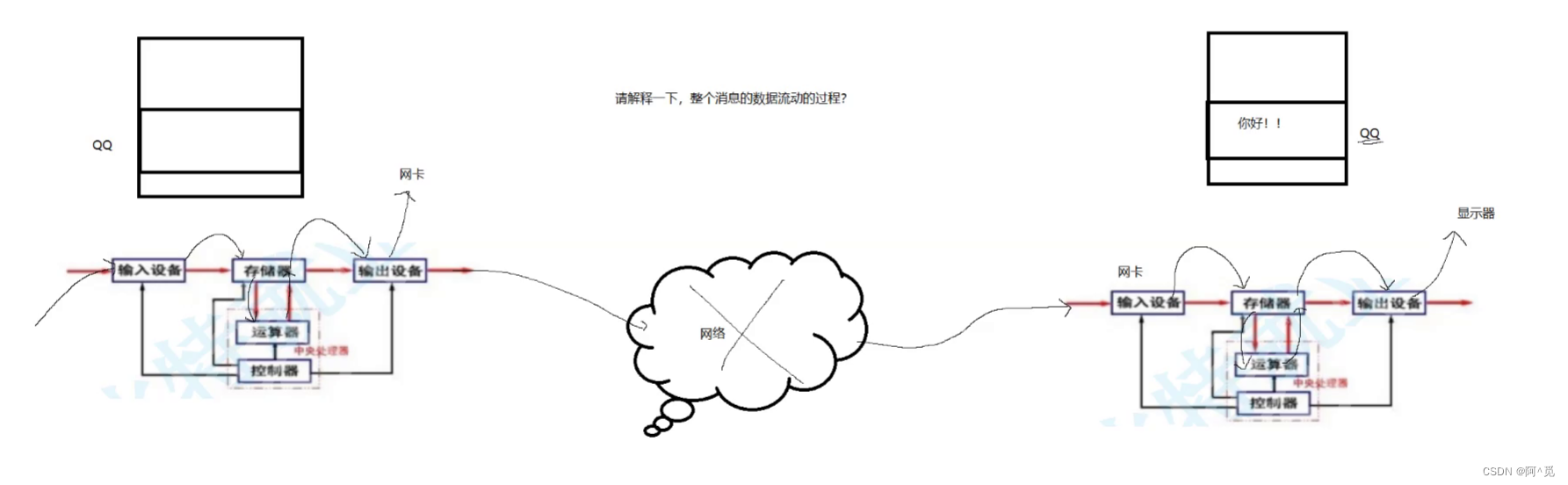
输入设备:您在电脑或手机等设备上输入登录 QQ 的账号、密码以及与朋友聊天的信息,这些输入设备(如键盘、触摸屏)将您的操作转换为电信号。
存储器:输入的数据首先被存储在本地设备的存储器(如内存)中。
控制器:控制器指挥数据的流动和处理,它协调各个部件的工作,将登录和聊天数据发送到运算器进行处理。
运算器:对登录和聊天数据进行处理,如加密、编码等操作。
输出设备:处理后的数据通过网络接口(可视为一种输出设备)发送到网络中。
网络传输:数据通过网络以数据包的形式传输,经过多个路由器和网络节点,最终到达 QQ 服务器。
QQ 服务器接收:服务器的输入设备接收数据包,数据存储在服务器的存储器中。
服务器处理:服务器的控制器和运算器对数据进行处理,如验证登录信息、查找接收方的连接信息、转发聊天数据等。
服务器输出:处理后的聊天数据再次通过网络发送给接收方的设备。
接收方设备接收:接收方设备的输入设备接收数据,经过类似的处理流程,最终在输出设备(如屏幕)上显示聊天内容。
在硬件数据流动角度,在数据层面:
1.CPU不和外设直接打交道,CPU只和内存打交道2.外设(输入和输出)的数据,不是直接给CPU的,而是先要放入内存中
2.操作系统(Operator System)
1)概念:
是一款软件,对软硬件资源进行管理的软件
广义上的认识:操作系统的内核 + 操作系统的外壳周边程序(给用户提供使用操作系统的方式)
狭义上的认识:只是操作系统的内核
2)结构 示意图(不完整)
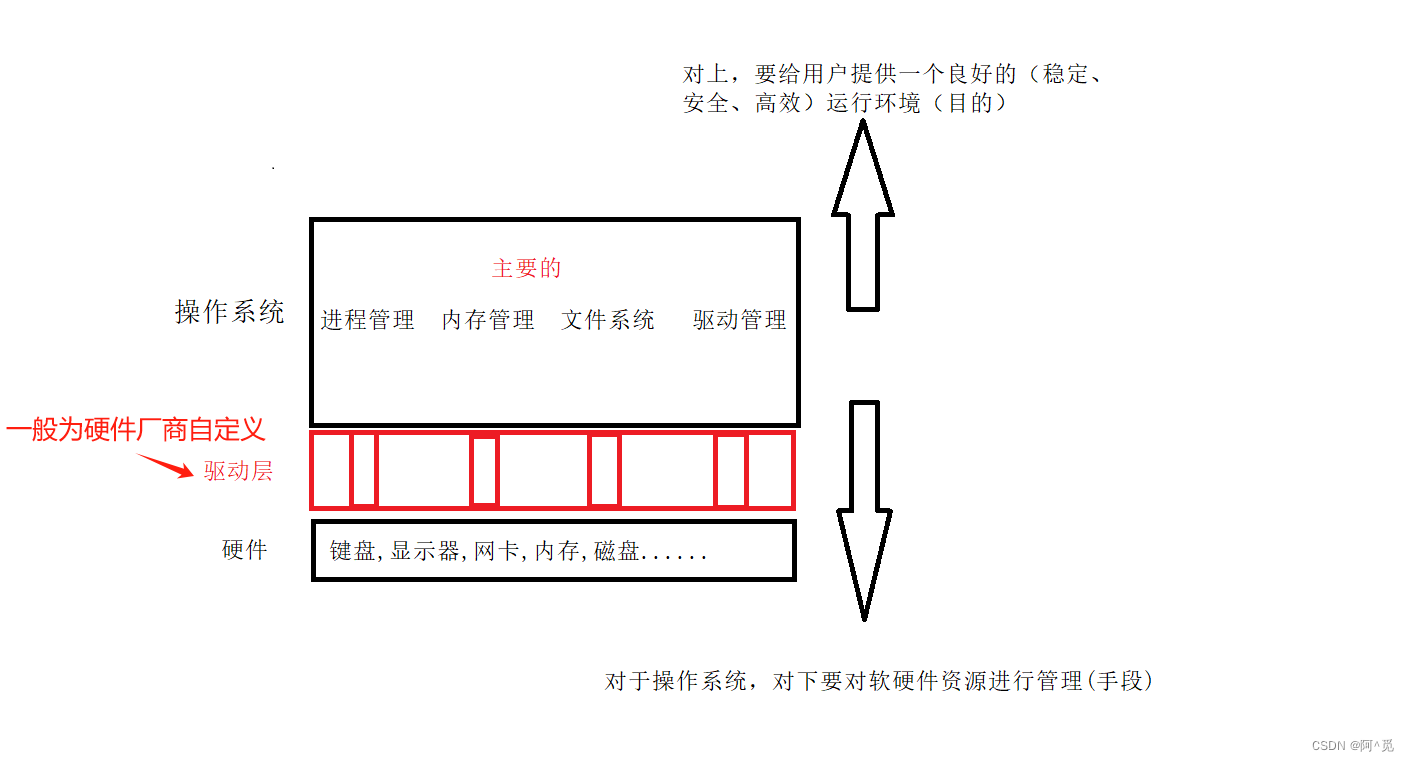
3)尝试理解操作系统
管理好,不需要管理者和被管理者直接接触
管理的本质不是对被管理的对象做管理,而是对被管理者的数据做管理
任何管理,要建模:
先描述,再组织
(先把被管理对象先描述起来,有几个被管理对象,就把几个被管理对象所对应的数据对象用特定的数据结构组织起来)
C++语言中封装 --- 就是描述对象!!! 而它的STL则是组织方式


比如实践通讯录时,要先构建结构体,然后定义 本质上就是先描述,再组织
所以凡是要对特定的对象进行管理:都是先描述,再组织
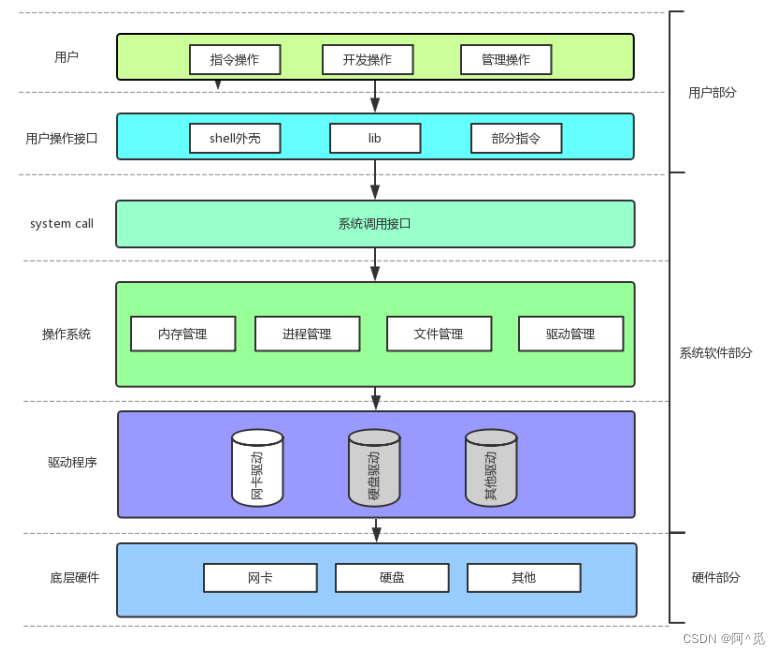
任何上层用户想要访问操作系统的功能,都必须直接或间接的使用系统调用(system call),而不是直接访问
4)系统调用和库函数概念
在开发角度,操作系统对外会表现为一个整体,但是会暴露自己的部分接口,供上层开发使用,这部分由操作系统提供的接口,叫做系统调用。系统调用在使用上,功能比较基础,对用户的要求相对也比较高,所以,有心的开发者可以对部分系统调用进行适度封装,从而形成库,有了库,就很有利于更上层用户或者开发者进行二次开发。
3.认识进程
在操作系统中,进程可以同时存在非常多!!!


1.启动
a. ./XXXX,本质就是让系统创建进程并运行 --- 我们自己写的代码形成的可执行 == 系统命令 == 可执行文件。在linux中运行的大部分指令操作,本质都是运行进程!!!
b. 每一个进程都要有自己的唯一标识符,叫做进程pid
c. 一个进程,想知道自己的pid???d. ctrl +c 就是在用户层面终止进程, kill -9 pid 可以用来直接杀掉进程
2.进程创建的代码方式 --- 重操作,轻原理
1)创进程
fork()
开启监视窗口指令:
while :; do ps axj | head -1 && ps axj | grep myprocess | grep -v grep; sleep 1; done


第二个出现的进程,他的ppid为第一个进程的pid,因此下一个进程为上一个进程的子进程
在fork之后,父子代码共享创建一个进程,本质是系统中多了一个进程,多了一个进程,就是多了--->1.内核task_struct2 有自己的代码和数据父进程的代码和数据是从磁盘加案的子进程的代码和教据?? 默认情况继承父进程的代码和教据
2)我们为什么要创建子进程呢?
我们想让子进程头行和父进程执行不一样的代码



fork()是一个函数吗,答案是是的,只不过是有OS提供的那么问题又来了,为什么fork()这个函数能提供两个返回值呢?原因是当我们执行到 return 的时候,函数的核心工作已做完了,这时候是不是 子进程已经存在了(即可以被调度使用了!!),因此return执行两次也不是很奇怪吧
进程一定要做到:进程具有独立性(即一个进程被杀掉,不会影响别的进程)-- 因此当你杀掉父进程时,不会影响子进程的运行。
进程 = 内核数据结构task_struct + 代码和数据其中代码是只读的,不可修改,因此父子 共用代码,但是 数据不一样,父子各自独立,原则上数据要分开



这又是为什么呢?因为 原则上一个程序要被变成进程调度,他就已经在内存中以及存在一份了,这时候你把他在磁盘上的可执行程序删除时,还能跑。
那为什么是原则上呢?因为当该程序 在磁盘上的占用空间大于内存空间时,接着跑下去肯定会出现问题的。

