Spark 的介绍与搭建:从理论到实践-CSDN博客
目录
一、Standalone 集群环境安装
(一)理解 Standalone 集群架构
(二)Standalone 集群部署
二、打开监控界面
(一)master监控界面
(二)日志服务监控界面
三、集群的测试
(一)圆周率测试
(二)测试 wordcount
四、关于 Spark 程序构成与监控界面
(一)4040 端口相关
(二)4040 与 8080 界面区别
五、总结
在大数据处理领域,Spark 是一款极为强大的工具。本文将重点介绍 Spark 的 Standalone 集群环境安装、测试相关内容,帮助大家更好地理解和使用 Spark 的集群模式。
一、Standalone 集群环境安装
(一)理解 Standalone 集群架构

对比图:

- 架构特点
Standalone 集群采用普通分布式主从架构。其中,Master 作为管理节点,其功能丰富,类似于 YARN 中的 ResourceManager,主要负责管理从节点、接收请求、资源管理以及任务调度。Worker 则是计算节点,它会利用自身节点的资源来运行 Master 分配的任务。这个架构为 Spark 提供了分布式资源管理和任务调度功能,和 YARN 的作用基本一致,而且它是 Spark 自带的计算平台。
- Python 环境注意事项
需要注意的是,每一台服务器上都要安装 Anaconda,因为其中包含 python3 环境。若没有安装,就会出现 python3 找不到的错误。
(二)Standalone 集群部署
第一步:将bigdata02和bigdata03安装Annaconda
因为里面有python3环境,假如没有安装的话,就报这个错误:
上传,或者同步
xsync.sh /opt/modules/Anaconda3-2021.05-Linux-x86_64.sh
# 添加执行权限
chmod u+x Anaconda3-2021.05-Linux-x86_64.sh
# 执行
sh ./Anaconda3-2021.05-Linux-x86_64.sh
# 过程
#第一次:【直接回车,然后按q】Please, press ENTER to continue>>>
#第二次:【输入yes】Do you accept the license terms? [yes|no][no] >>> yes
#第三次:【输入解压路径:/opt/installs/anaconda3】[/root/anaconda3] >>> /opt/installs/anaconda3#第四次:【输入yes,是否在用户的.bashrc文件中初始化
Anaconda3的相关内容】Do you wish the installer to initialize Anaconda3by running conda init? [yes|no][no] >>> yes
配置环境变量制作软连接
刷新环境变量:
# 刷新环境变量
source /root/.bashrc
# 激活虚拟环境,如果需要关闭就使用:conda deactivate
conda activate配置环境变量:
# 编辑环境变量
vi /etc/profile
# 添加以下内容
# Anaconda Home
export ANACONDA_HOME=/opt/installs/anaconda3
export PATH=$PATH:$ANACONDA_HOME/bin制作软链接:
# 刷新环境变量
source /etc/profile
Spark的客户端bin目录下:提供了多个测试工具客户端
# 创建软连接
ln -s /opt/installs/anaconda3/bin/python3 /usr/bin/python3
# 验证
echo $ANACONDA_HOME在bigdata01上安装spark
# 解压安装
cd /opt/modules
tar -zxf spark-3.1.2-bin-hadoop3.2.tgz -C /opt/installs
# 重命名
cd /opt/installs
mv spark-3.1.2-bin-hadoop3.2 spark-standalone
# 重新构建软连接
rm -rf spark
ln -s spark-standalone spark修改 spark-env.sh配置文件
cd /opt/installs/spark/conf
mv spark-env.sh.template spark-env.sh
vim spark-env.sh# 22行:申明JVM环境路径以及Hadoop的配置文件路径
export JAVA_HOME=/opt/installs/jdk
export HADOOP_CONF_DIR=/opt/installs/hadoop/etc/hadoop
# 60行左右
export SPARK_MASTER_HOST=bigdata01 # 主节点所在的地址
export SPARK_MASTER_PORT=7077 #主节点内部通讯端口,用于接收客户端请求
export SPARK_MASTER_WEBUI_PORT=8080 #主节点用于供外部提供浏览器web访问的端口
export SPARK_WORKER_CORES=1 # 指定这个集群总每一个从节点能够使用多少核CPU
export SPARK_WORKER_MEMORY=1g #指定这个集群总每一个从节点能够使用多少内存
export SPARK_WORKER_PORT=7078
export SPARK_WORKER_WEBUI_PORT=8081
export SPARK_DAEMON_MEMORY=1g # 进程自己本身使用的内存
export SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://bigdata01:9820/spark/eventLogs/ -Dspark.history.fs.cleaner.enabled=true"
# Spark中提供了一个类似于jobHistoryServer的进程,就叫做HistoryServer, 用于查看所有运行过的spark程序在HDFS上创建程序日志存储目录
首先如果没有启动hdfs,需要启动一下
# 第一台机器启动HDFS
start-dfs.sh
# 创建程序运行日志的存储目录
hdfs dfs -mkdir -p /spark/eventLogs/spark-defaults.conf:Spark属性配置文件
mv spark-defaults.conf.template spark-defaults.conf
vim spark-defaults.conf# 末尾
spark.eventLog.enabled true
spark.eventLog.dir hdfs://bigdata01:9820/spark/eventLogs
spark.eventLog.compress trueworkers:从节点地址配置文件
mv workers.template workers
vim workers# 删掉localhost,添加以下内容
bigdata01
bigdata02
bigdata03log4j.properties:日志配置文件
mv log4j.properties.template log4j.properties
vim log4j.properties# 19行:修改日志级别为WARN
log4j.rootCategory=WARN, consolelog4j的5种 级别 debug --> info --> warn --error -->fatal同步bigdata01中的spark到bigdata02和03上
xsync.sh为自建脚本
大数据集群中实用的三个脚本文件解析与应用-CSDN博客
xsync.sh /opt/installs/spark-standalone/接着在第二台和第三台上,创建软链接
cd /opt/installs/
ln -s spark-standalone spark换个思路,是否可以同步软链接:
xsync.sh /opt/installs/spark集群的启动
启动master:
cd /opt/installs/spark
sbin/start-master.sh
启动所有worker:
sbin/start-workers.sh
如果你想启动某一个worker
sbin/start-worker.sh启动日志服务:
sbin/start-history-server.sh要想关闭某个服务,将start换为stop二、打开监控界面
(一)master监控界面
http://bigdata01:8080/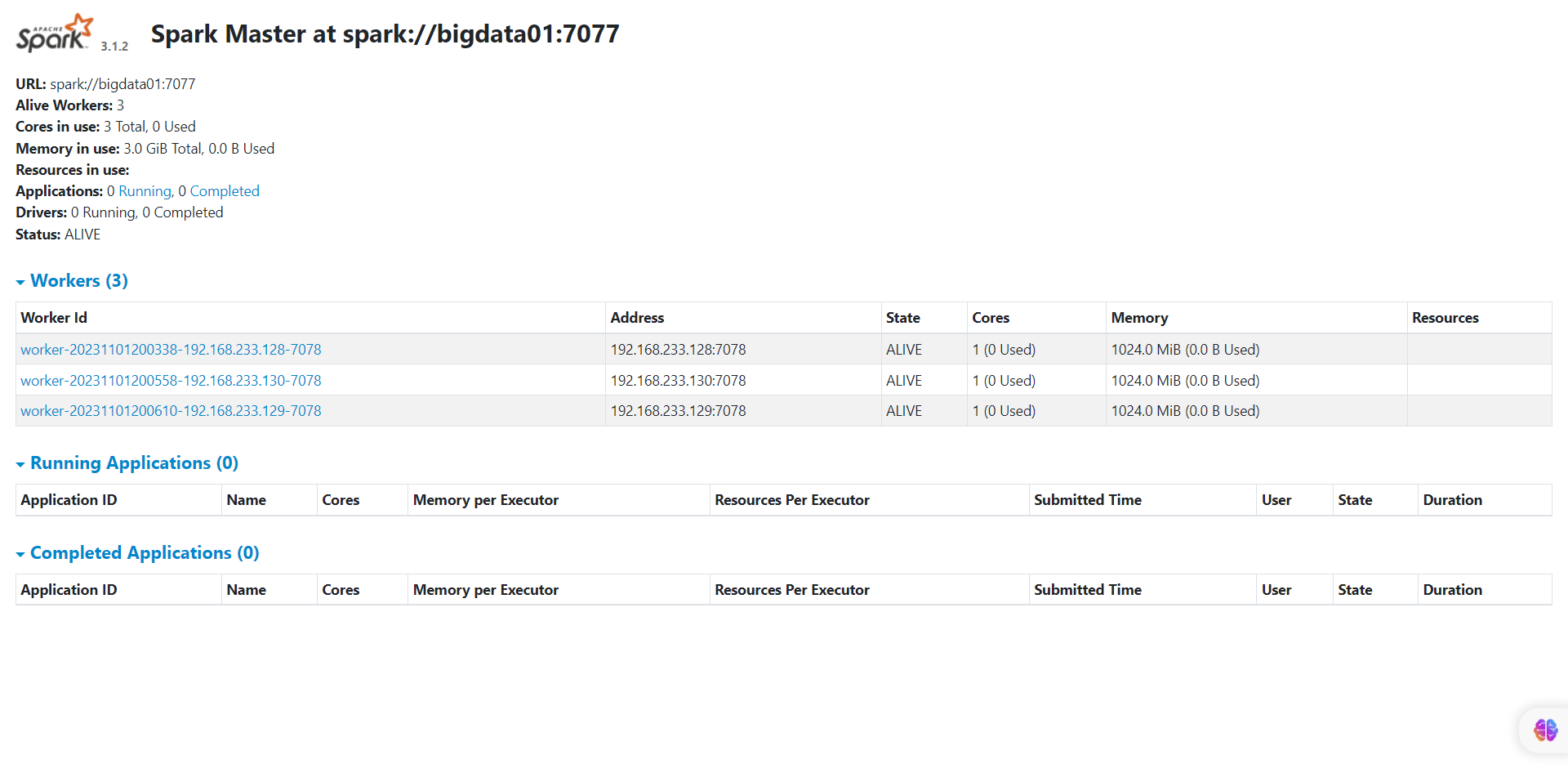
(二)日志服务监控界面
http://bigdata01:18080/假如启动报错,查看日志发现说没有文件夹:
mkdir /tmp/spark-eventshdfs dfs -mkdir -p /spark/eventLogs
再启动即可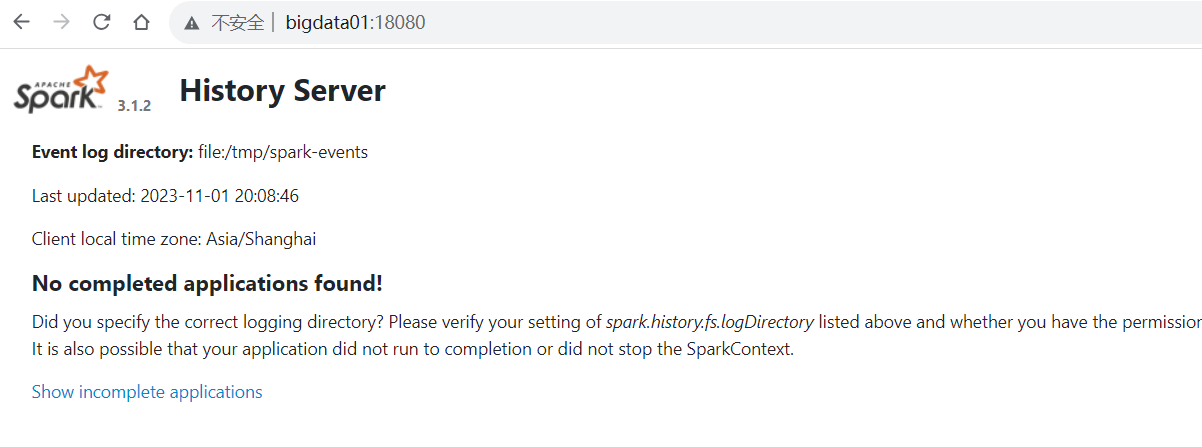
三、集群的测试
(一)圆周率测试
在集群环境下进行圆周率测试,与本地模式运行的区别主要在 --master 后面的参数。
# 提交程序脚本:bin/spark-submit
/opt/installs/spark/bin/spark-submit --master spark://bigdata01:7077 /opt/installs/spark/examples/src/main/python/pi.py 200
(二)测试 wordcount
将本地数据上传至 HDFS
参考:Spark 的介绍与搭建:从理论到实践-CSDN博客
hdfs dfs -mkdir -p /spark/wordcount/input
hdfs dfs -put /home/data.txt /spark/wordcount/input使用集群环境编写测试 wordcount
本地模式:
/opt/installs/spark/bin/pyspark --master local[2]
standalone集群模式:
/opt/installs/spark/bin/pyspark --master spark://bigdata01:7077读取数据 读取是hdfs上的数据
# 读取数据 读取是hdfs上的数据
input_rdd = sc.textFile("/spark/wordcount/input")
# 转换数据
rs_rdd = input_rdd.filter(lambda line : len(line.strip())> 0).flatMap(lambda line :line.strip().split(r" ")).map(lambda word : (word,1)).reduceByKey(lambda tmp,item : tmp+item)
# 保存结果
rs_rdd.saveAsTextFile("/spark/wordcount/output3")以上这些代码跟昨天没区别只是运行环境变了。
本地数据 --> hdfs上的数据
本地资源 --> 集群的资源 这些算子都是在spark自带的standalone集群平台上运行的。解决一个问题:
spark-env.sh
# 22行:申明JVM环境路径以及Hadoop的配置文件路径
export JAVA_HOME=/opt/installs/jdk
export HADOOP_CONF_DIR=/opt/installs/hadoop/etc/hadoop
# 60行左右
export SPARK_MASTER_HOST=bigdata01 # 主节点所在的地址
export SPARK_MASTER_PORT=7077 #主节点内部通讯端口,用于接收客户端请求
export SPARK_MASTER_WEBUI_PORT=8080 #主节点用于供外部提供浏览器web访问的端口
export SPARK_WORKER_CORES=1 # 指定这个集群总每一个从节点能够使用多少核CPU
export SPARK_WORKER_MEMORY=1g #指定这个集群总每一个从节点能够使用多少内存
export SPARK_WORKER_PORT=7078
export SPARK_WORKER_WEBUI_PORT=8081
export SPARK_DAEMON_MEMORY=1g # 进程自己本身使用的内存
export SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://bigdata01:9820/spark/eventLogs/ -Dspark.history.fs.cleaner.enabled=true"
# Spark中提供了一个类似于jobHistoryServer的进程,就叫做HistoryServer, 用于查看所有运行过的spark程序修改完之后,同步给bigdata02和03,重新启动各个服务即可。
四、关于 Spark 程序构成与监控界面
在分布式集群模式下,任何一个 Spark 程序都由 1 个 Driver 和多个 Executor 进程所构成。
任何一个spark程序在集群模式下运行,都有两种进程:
Driver、Executor
Driver: 驱动程序,每一个spark程序都只有一个
Executor: 执行进程,负责计算,可以有多个,运行在不同节点Master和Worker进程,是spark的standalone平台服务启动后的进程,不管是否有任务执行,它都会启动的
Driver、Executor 是只有有任务执行的时候才会有的进程!!
假如一个任务,你看到如下的场景,说明任务没有执行完,需要等......

(一)4040 端口相关
http://bigdata01:4040 查看正在运行的任务
4040这个界面,只要有新任务,就会生成一个新的界面,比如你要是再执行一个任务,端口会变为4041,再来一个任务,端口变4042
默认情况下,当一个Spark Application运行起来后,可以通过访问hostname:4040端口来访问UI界面。hostname是提交任务的Spark客户端ip地址,端口号由参数spark.ui.port(默认值4040,如果被占用则顺序往后探查)来确定。由于启动一个Application就会生成一个对应的UI界面,所以如果启动时默认的4040端口号被占用,则尝试4041端口,如果还是被占用则尝试4042,一直找到一个可用端口号为止
通过这个 界面,可以看到一个任务执行的全部情况。这个界面跟 http://bigdata01:8080界面很像。
(二)4040 与 8080 界面区别
通过案例查看 4040 界面和 8080 界面的区别:
/opt/installs/spark/bin/spark-submit --master spark://bigdata01:7077 /opt/installs/spark/examples/src/main/python/pi.py 1000假如启动了一个任务在集群上运行,4040端口中查看的所有信息都只跟这个任务有关系,
假如又启动一个任务,4040是看不到了,可以使用4041来查看,依次类推。当任务结束后,404x 这些界面都会销毁掉,相当于只能查看正在运行的一个任务。
8080这个界面是一个总指挥,不仅能看到正在运行的任务,还可以看到已经执行完的任务。
五、总结
本文围绕 Spark 的 Standalone 集群环境展开。首先介绍其安装,包括理解架构(主从架构,Master 管理资源和任务调度,Worker 执行任务,类似 YARN,且需安装 Anaconda 保证 python3 环境)和部署(在 bigdata02、03 安装 Anaconda,在 bigdata01 安装 Spark 并修改配置文件、创建日志存储目录、配置 Spark 属性、从节点地址和日志等文件),还讲了集群同步与启动方法。接着是测试,圆周率测试和 wordcount 测试,强调了与本地模式在参数和数据来源上的区别。最后阐述 Spark 程序构成(1 个 Driver 和多个 Executor)和监控界面,如 4040 端口可查看正在运行任务(新任务会使端口递增),8080 端口能查看所有任务情况。
希望本文能帮助大家更好地理解 Spark 的 Standalone 集群环境相关知识,在大数据处理实践中更加得心应手。