为了本地测试和开发更丝滑,最近入手了一套新设备 ROG 幻 X Z13 和 ROG XG Mobile 4090 扩展坞。
基于这套设备,我搭了一套 Windows x WSL2 x CUDA 的开发环境。分享一下折腾记录,或许对有类似需求的你也有帮助。
写在前面
最近因为各种事情,包括各种社区合作,出门频率暴涨,之前“昼出夜归”的模式有了一些变化。虽然云上和家里的设备算力更强,但是远程设备的体验总归没有那么好。
于是,我入手了一套新的本地计算设备,用来扩展出行阶段,本地开发模型应用和验证模型基础能力的诉求。
不论是桌面版的 CPU、4060 还是 4090 移动端显卡,算力都比今年的 “AIPC” 强了不止一个档位,即使今年、明年 NPU 继续竞赛,满足 NPU 相关软件运行的算力也应该冗余不少,短时间不需要担心设备迭代的问题。本文章主要分享系统、基础软件相关的内容,如果你对硬件感兴趣,可以查看官方网站的幻 X 的产品规格。或者,移步各种评测类内容,已经剁手购买的用户,关注怎么用好硬件才是正经事,对吧。

为了让这个事情的“开发者”体验更好一些,我选择了 Nvidia 的 N 卡生态,搭配 Docker 来做可迁移的开发、运行环境管理。这套设备本体其实是一台平板搭配一块 4090 显卡坞,因为可以根据计算负载,选择切换相对重的计算到外置显卡重,设备本体没有暴力的涡轮风扇,所以散热和噪音控制都尚可。设备本身外形也比较讨我喜欢,赛博朋克风格拉满。完整的本地算力构成为 Intel 13900H + Nvidia 4060 移动版(8G) + Nvidia 4090 移动版(16G),除了 CUDA 生态外,其实还可以折腾下 OpenVINO。
至于为什么选择了这两个硬件,在“设备选型考虑”中,我有提到,这里就不再赘述啦。
此外,我对这(两)台设备的诉求是:运行在 Windows 环境下,能够在运行基础软件的同时,高效运行端侧大模型,进行轻量的 AI 应用调试开发。因为我的主力环境是 macOS 和 Ubuntu,所以我希望能够尽量保持 macOS、Linux 开发习惯,不要涉及 Windows 下的“方言开发”。
设备选型考虑
这套设备的选择依旧是功能向的,所以能否运行模型应用是关键。通常情况下,硬件计算能力、硬件生态、硬件显存容量,是最关键的三个因素。
虽然 AMD 的设备看起来更有性价比,Apple Max、Ultra 芯片的设备超大联合内存带来的超大带宽跑超大尺寸的模型也非常吸引人。但是,实际上手后,你会发现:前者的生态一塌糊涂,除了四个月前的“民间项目” github.com/vosen/ZLUDA 算是惊鸿一瞥之外,想要愉快验证较新的项目,基本属于给自己“上难度”的没事找事;后者的生态完善情况,虽然在今年有了相对更快的变化,但是普遍支持速度还是比较堪忧的,尤其是大参数量的模型,其实也不过是能跑而已,完全没有效率,更大的优势是功耗,这个优势对我的这个场景来说,毫无吸引力。
所以,想要愉快的折腾,尤其是在移动工作站场景,暂时还是选 Nvidia 生态吧。
因为这套设备是出行时携带的,所以对于重量和便携性的需求也是比较靠前的。虽然纸面算力较强,但是重量爆棚的“16~18寸 4090笔记本”,不光是挑战了我的负重能力,也在挑战我的 16 寸书包的“吞吐能力”。所以,这类设备是不能选的。
所以,我需要一台尺寸小巧,不那么锻炼负重的设备,并且,最好能上到移动版的 4090。 虽然算力只有台式的一半左右,但是 16G 的显存,对于验证场景、尤其是端侧小模型而言,已经是非常友好的规格了。而且,因为移动场景设备追求紧凑,多数硬件规格都是“固定的”,和台式或者机柜场景,硬件可以后续慢慢升级替换还不太一样,所以,尽量选择一步到位的规格吧。
不过上面也提到了,体积和算力是不能兼得的。所以,如果想要小巧的设备,算力最好是可以被拆开的,或者说,可以跟着设备一起移动的。
我想到了显卡坞。
但是,如果我们从 4090 显卡来找显卡坞,其实可选并不多:
- 一些一线 PC 厂商的显卡坞,内置一张 4090 全尺寸显卡,价格接近 2 万,通过雷电 3 或者雷电 4,只损失 20% 的显卡性能,但是整体尺寸堪比 ITX 主机,并且供电要求较高。
- 做定制配置厂商的显卡坞:类似上面,采用开放式显卡坞,价格比较贵(6000+),显卡需要自购,同样供电要求比较高。一些产品的额外优点是能够改造纯 CPU 的笔记本支持 OCulink 方式,支持两倍于雷电的有效带宽。
- 特定设备的显卡坞:比如我选择的 ROG 厂商,定向服务于自家产品的 ROG XG Mobile RTX 4090 显卡坞,内置移动版的 4090,性能和价格目前都是一张全尺寸 4090 的一半左右。因为是移动版的 4090,所以供电差不多是一台游戏本的功耗,同时还能给其他设备做 Hub 和电源使。缺点是,定制接口,只能对特定设备使用。

因为我的需求是“移动场景”,所以我最终选择了这台原本设计是给游戏玩家的扩展坞。同时,搭配扩展坞,选择了一台多形态的超级本:幻 X Z13 ,本身搭载 4060 移动版和桌面版 CPU 13900H。(《家用工作站方案:ThinkBook 14 2023 版》中的设备,CPU 是 13700H)
这样,就能够满足以下场景:
- 需要和朋友一起折腾离线的模型和做简单验证的时候,如果在市内,多带一台平板就行。
- 需要折腾完整 Pipeline 的时候,书包里塞一下这个显卡坞就行。
- 需要较长时间出远门,或者做演示的时候,行李箱里塞一下就行。
系统和基础环境相关
想要愉快的折腾,首先是要有个相对靠谱的系统环境,包括系统的选择、
切换系统类型
我原本想选择 Ubuntu 作为系统环境,Nvidia 生态在 Ubuntu 下非常好用。但是这类原本服务于游戏场景的设备,通常只针对 Windows 环境进行了驱动和细节改进,总体来说 Windows 的软硬件联动体验会更好一些。于是,我选择基于 Windows WSL 2 搭建一套最简单的移动工作站开发环境。
尽管选择了 Windows,设备的系统还是要进行切换。
设备原版系统是 “Windows 中文家庭版”,作为打游戏场景的系统应该是足够了。但是,如果我们要把设备变成便携的移动开发工作站,那么我们需要将它升级为专业版。
因为专业版包含了我们更方便开发和使用的功能:“控制何时更新”、“Hyper-V 虚拟化”、“沙盒”、“远程桌面” 等等。
通常来说升级方法很简单,购买一个正版的序列号进行替换即可。
升级系统版本后,别忘记使用 Windows 自带的“系统升级”、“华硕管家”把各种软件、驱动更新到最新,来减少一些不必要的问题。
CUDA 环境准备
虽然上一步中,我们已经完成了各种硬件驱动的更新。但是,为了确保后续折腾顺利(适配 CUDA Toolkit),建议还是前往 Nvidia 官方驱动下载站,下载完整版本的最新的驱动,进行覆盖安装。这里随便选择一个 40 系的型号就行,实际上和 4090 的驱动是相同的安装包。(后续激活显卡扩展坞无需再安装任何驱动)
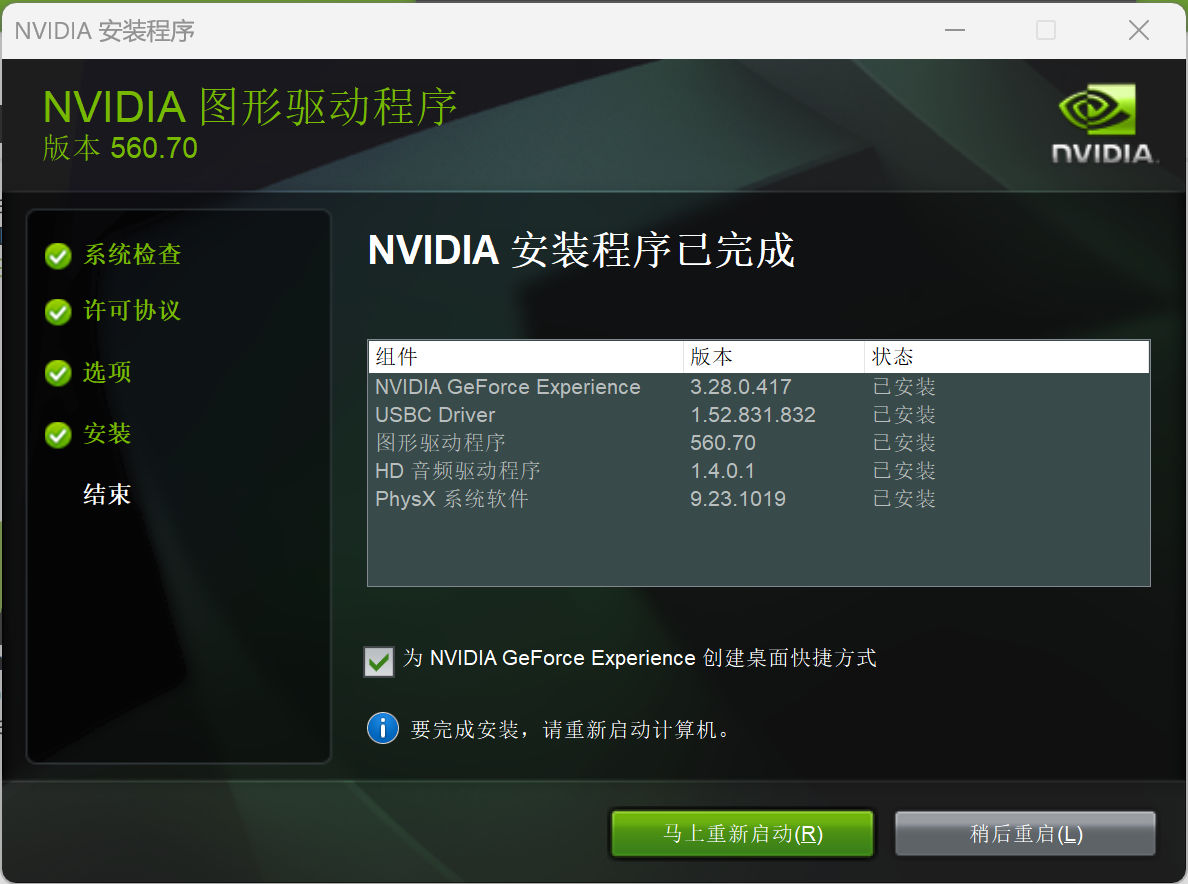
完成安装后,我们能够在结束界面看到显卡驱动的具体版本。
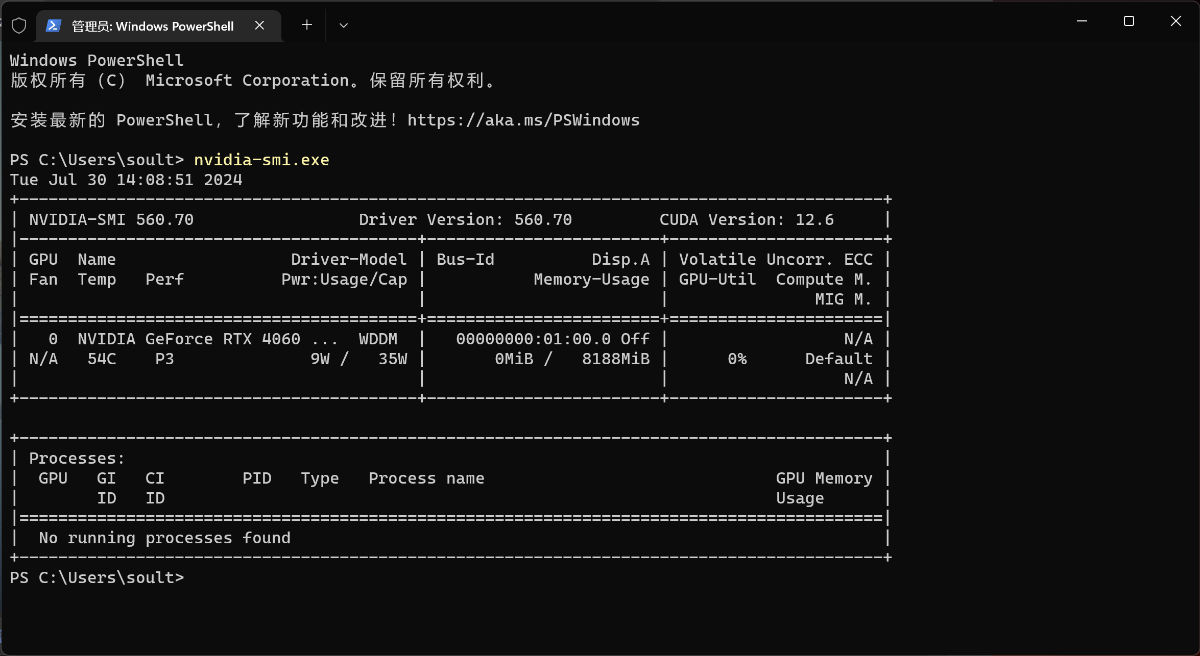
此时,我们就能够使用命令行来查看显卡状态啦:nvidia-smi.exe。
配置 Docker 环境和 WSL2 功能
时过境迁,曾几何时 Docker 对于 Windows 下的虚拟化方案选择的态度很不明确,选择站在 Hyper-V 和 WSL 功能的中间。而现在,我们不再需要纠结这个问题,因为最新版本的 WSL 2 是 Hyper-V 虚拟化的子集,微软也已经在 WSL 2 中发布了支持访问 GPU 的功能,同样的,Docker 也跟进了 WSL 2 环境中的 Docker 访问 GPU 的功能。
如果你已经按照上面的方式,完成了基础的驱动安装。那么你可以访问 Docker 官方网站,来获取适用于 Windows 的安装包。
如果你在之前还安装了 VSCode,那么在安装过程中,Docker 会贴心的问你是否要安装一个 VSCode Docker 插件。
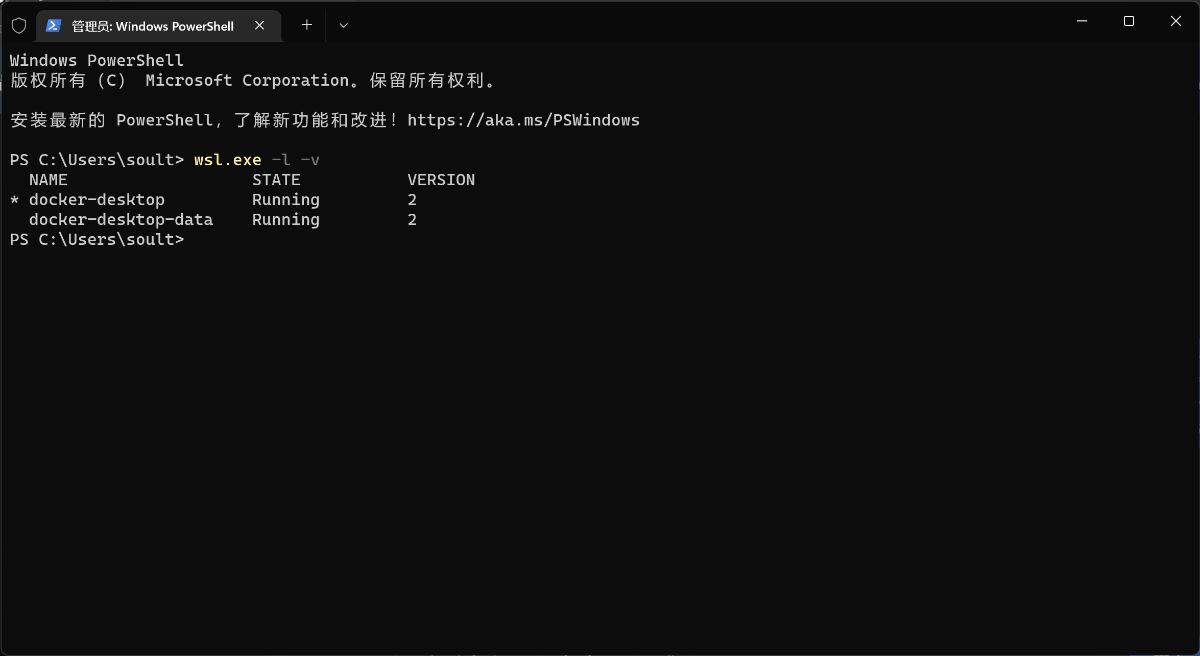
当我们完成 Docker 的安装后,你会发现 WSL 2 环境就被顺带简单的激活了。我们可以通过下面的命令,来验证环境是否正确:
wsl.exe -l -v
如果你的安装出现了问题,可以参考下面的两个官方文档来解决问题:《Install Docker Desktop on Windows》(检查是否缺少前置安装条件)、《Docker Desktop WSL 2 backend on Windows》(切换或升级你的 WSL 环境)。当然,如果你需要更详细的方案,也可以参考之前的文章《基于 Docker 的深度学习环境:Windows 篇》来完成相关的配置。
CUDA Toolkit 和开发者工具
在完成了关键驱动、虚拟化环境的安装后,我们可以来完成最重要的 CUDA 工具套件的安装,我们熟悉的 CUDA、加速库、编译器、算子库、通讯库、性能相关工具都在这个安装包中提供。
访问官方 CUDA Toolkit 下载页面,完成安装包的下载,开始安装。
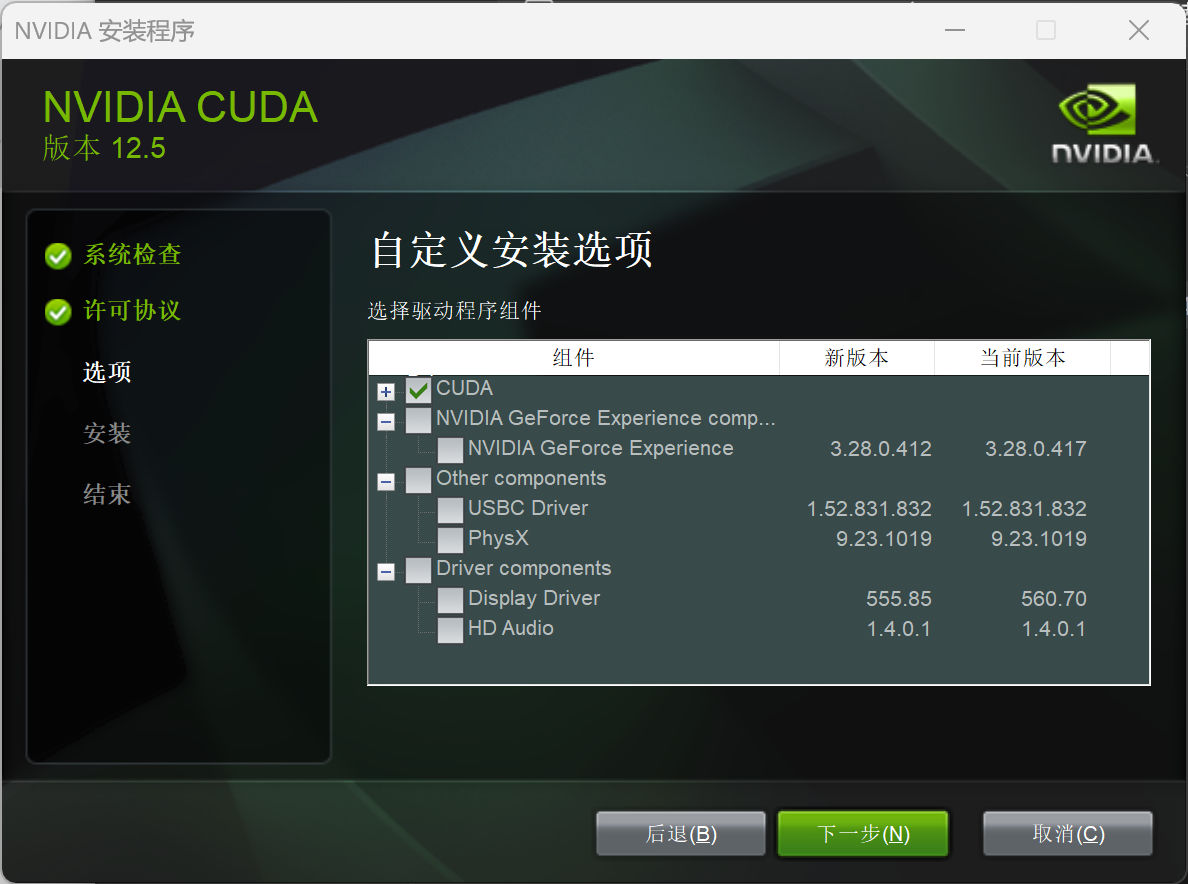
在安装的过程中,个人建议勾选掉其他在上一步中已经安装了的,更新的内容。
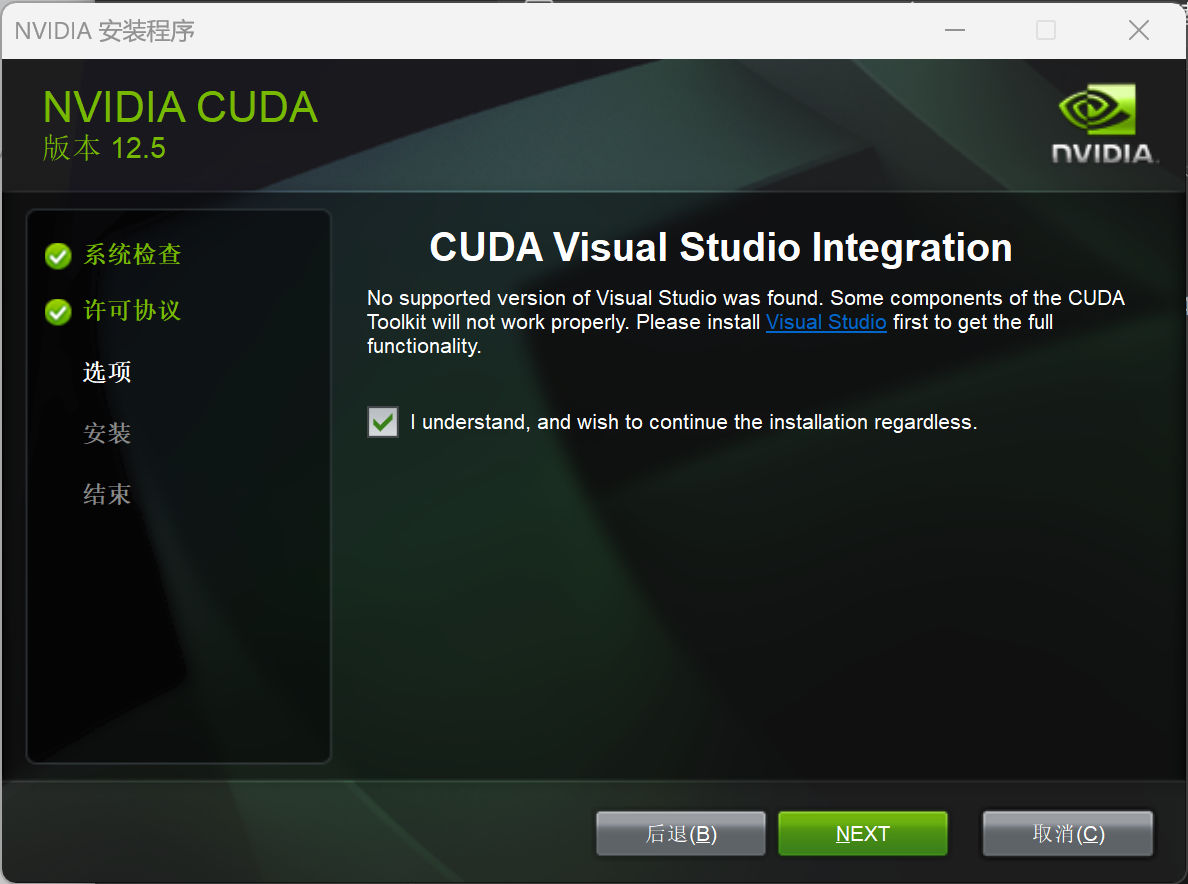
和安装 Docker 时一样,如果你之前安装了 VSCode ,可以选择安装 CUDA 的 VSCode 插件。
好了,差不多配置到这里,基础的系统环境就好了。
设备和基础环境验证
为了验证基础环境是否能够正常运行,我们可以通过下载 Nvidia 官方提供的 Docker 镜像,然后在容器内调用 Nvidia 系统管理接口,来确认是否可以在容器中访问到显卡。
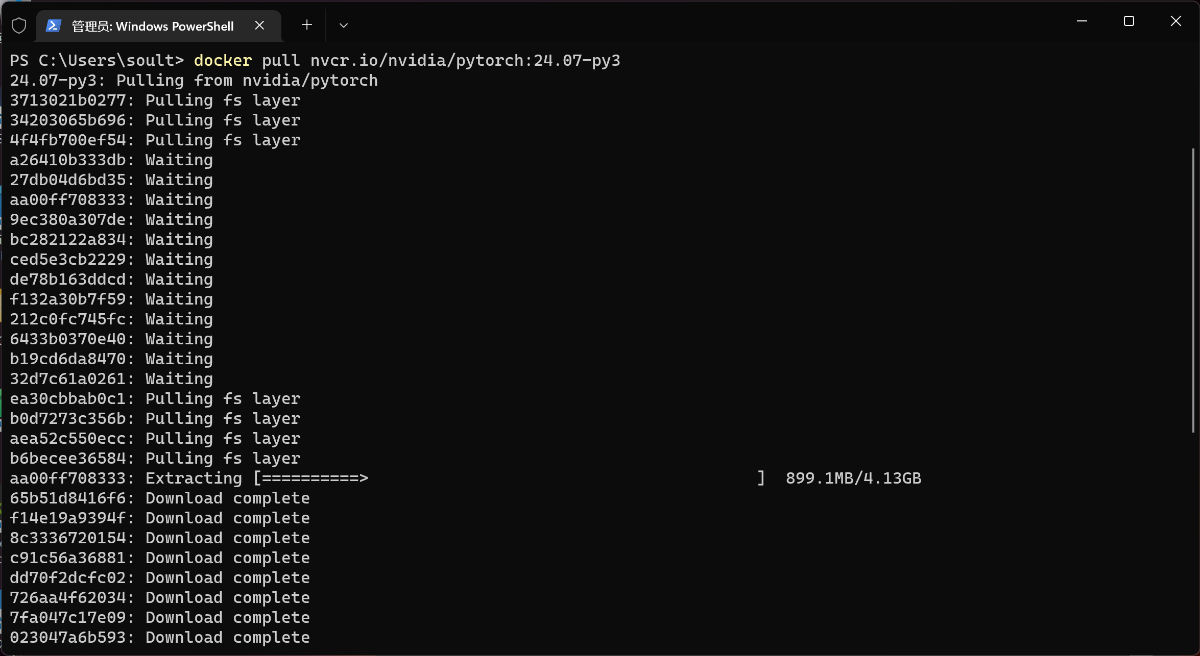
Nvidia 官方,每个月都会提供新版本的 PyTorch 环境。我们可以使用这个环境,来作为日常的开发环境,或者作为刚刚提到的基础环境验证使用。
docker pull nvcr.io/nvidia/pytorch:24.07-py3
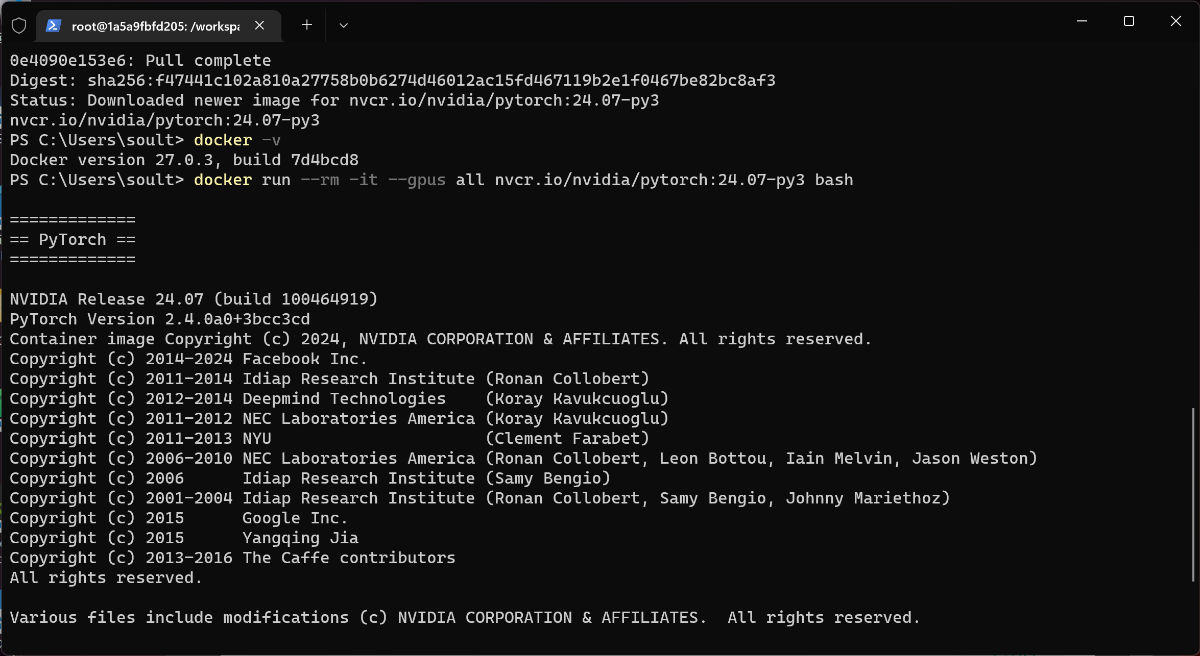
使用下面的命令,我们可以创建一个干净的容器环境,并进入这个容器环境的交互命令行环境中,--gpus all 参数,会在启动容器的时候,将显卡资源传入 Docker 容器中。
docker run --rm -it --gpus all nvcr.io/nvidia/pytorch:24.07-py bash
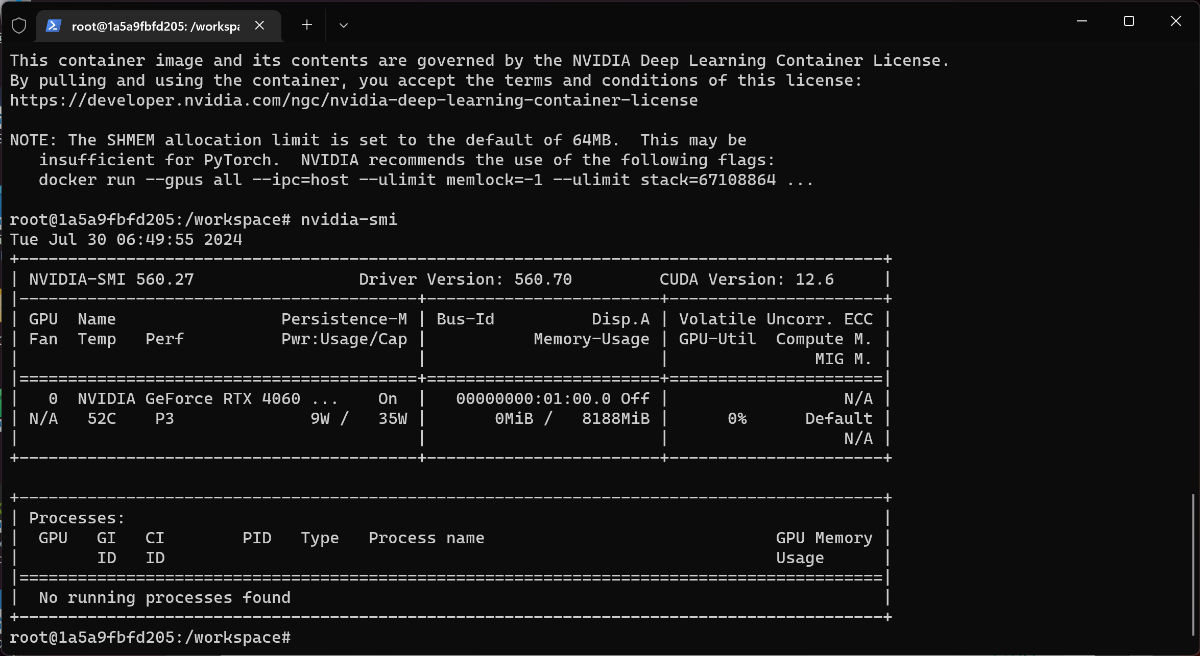
接下来,执行 nvidia-smi 就能够看到我们熟悉的 Nvidia 显卡的运行状态了。如果能够看到类似上图中的结果,说明我们的基础环境配置一切正常。
如果你不放心,还可以在容器环境中,输入 python 进入 Python 交互命令行环境,然后输入下面的代码,来查看 CUDA 是否能够被容器中的程序调用:
# python>>> import torch
>>> print(torch.cuda.is_available())
True
为设备扩展 4090 移动显卡
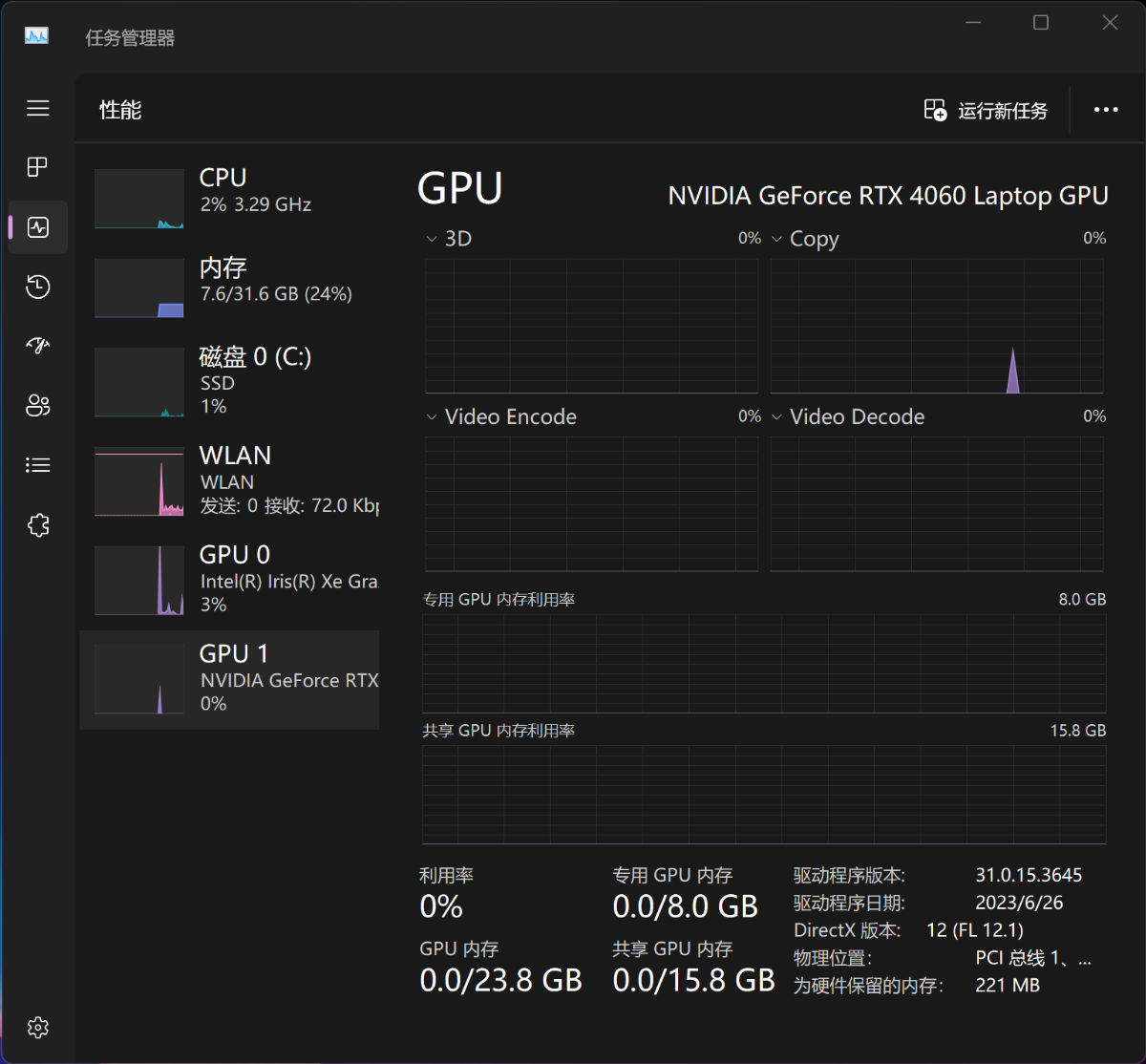
在系统管理器中,我们当前能够看到设备内置的 4060 显卡的运行状况,和显存状况。
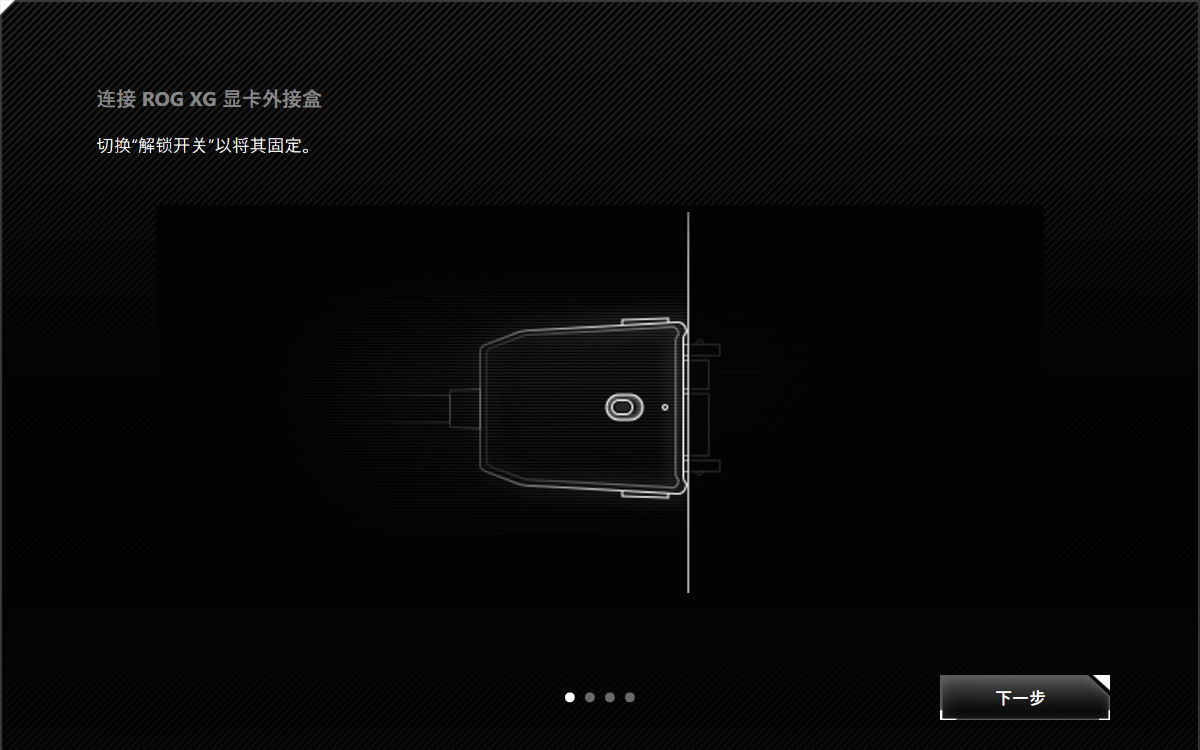
当我们把设备和显卡坞对接到一起后,系统会弹出一个提醒,告诉我们应该锁定显卡坞上的开关。切记,如果我们要拔掉显卡坞,务必在系统托盘中找到 “XG Mobile” 图标,点击安全移除扩展坞。直接拔出正在运行的显卡坞,可能会烧毁相关设备或接口,造成不必要的麻烦。
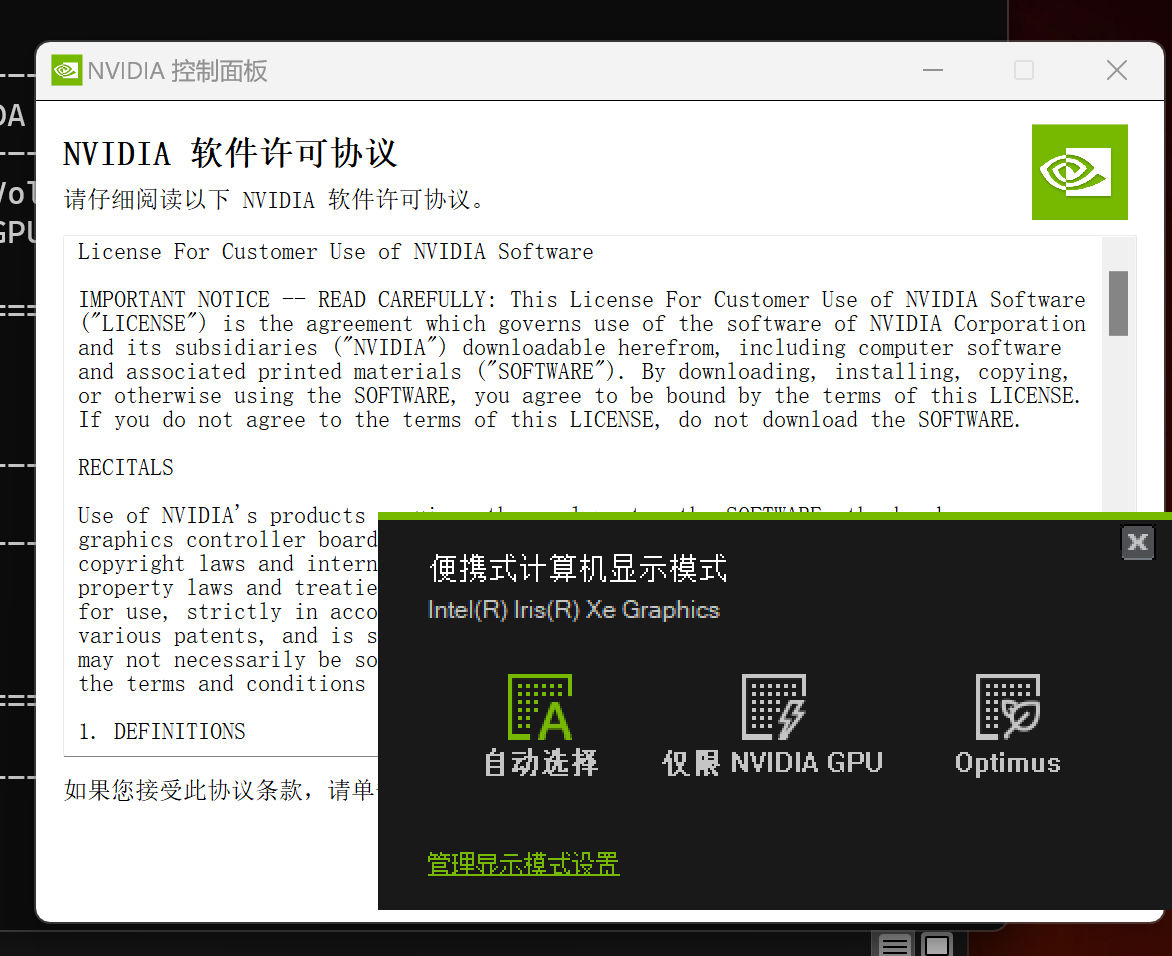
与此同时,Nvidia 相关的程序,也会提醒我们可以切换显卡设备。如果我们选择切换设备,系统可能会重新启动。
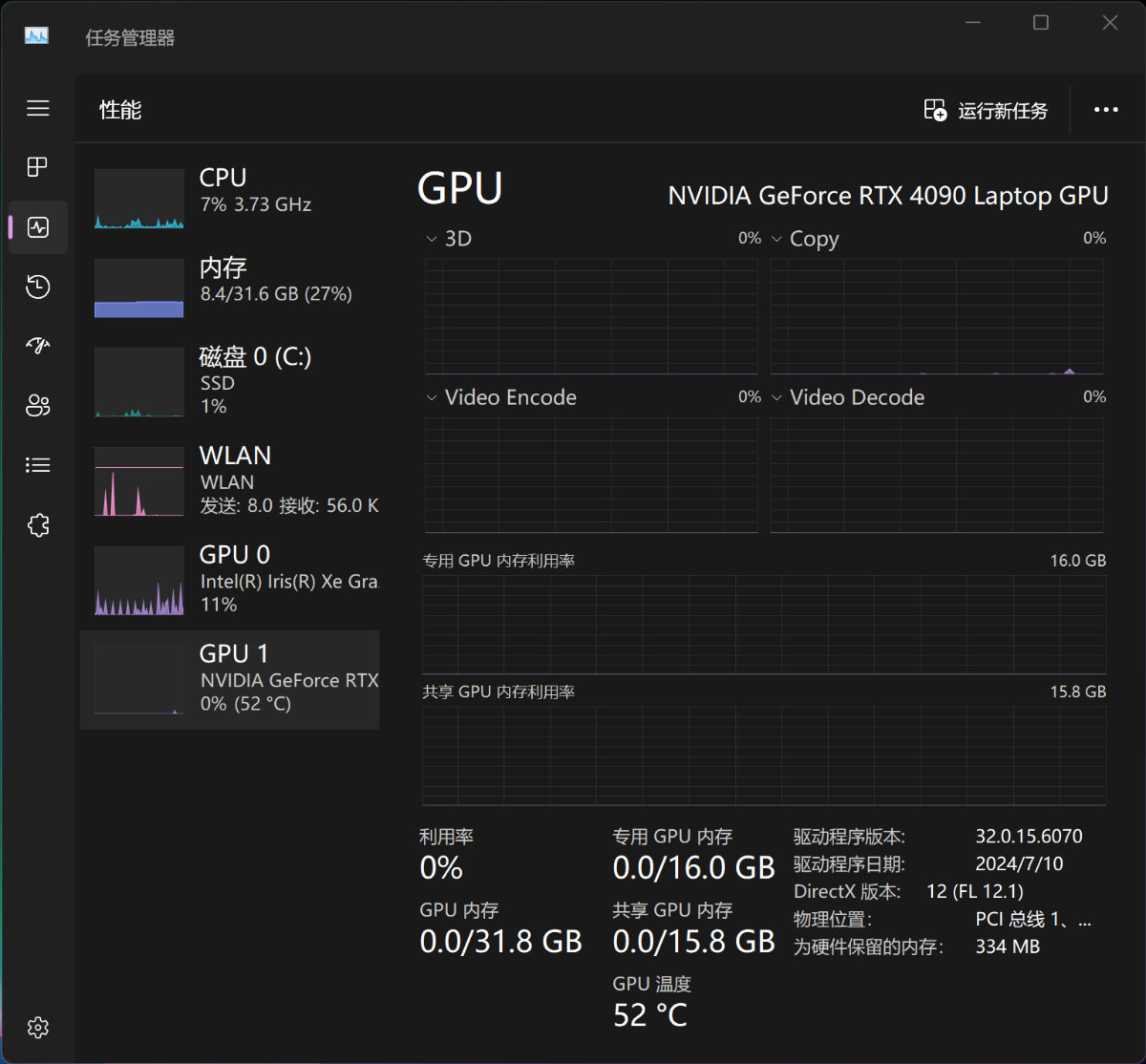
重启之后,在设备管理器中,我们能够看到扩展坞的 16G 显存已经被正常识别了。
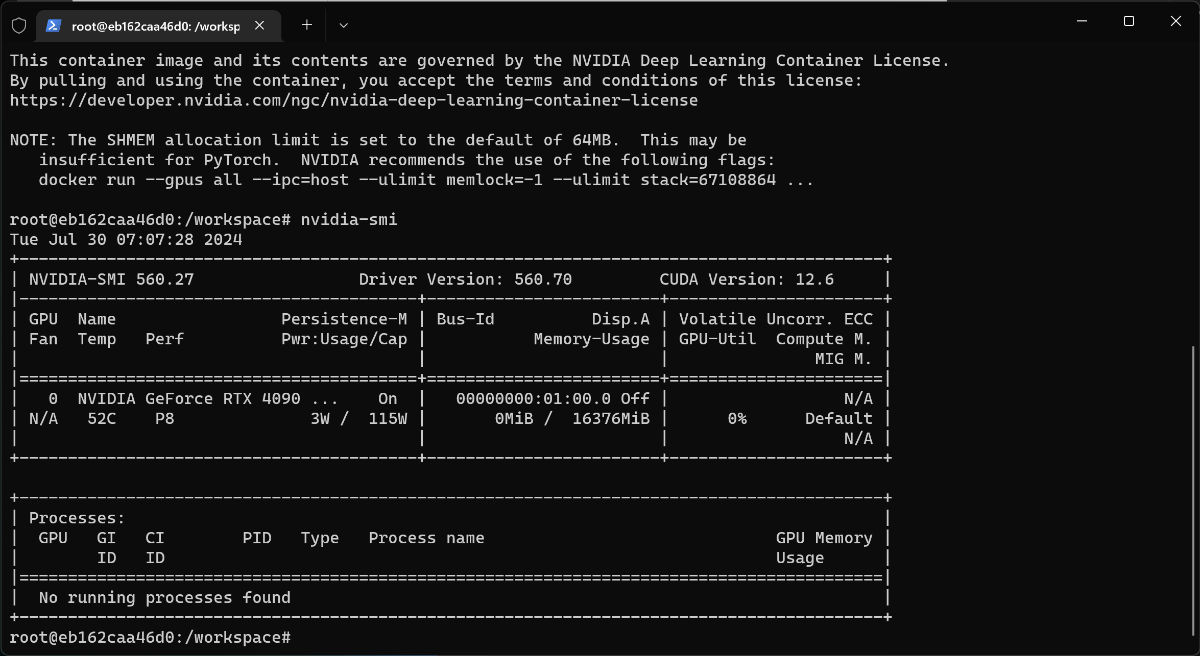
使用上文中提到的方法,我们能够在容器中看到显卡资源已经被替换为了 4090 啦。
接下来,让我们使用这块 4090 做一个简单的模型运行的验证。
使用 Stable Diffusion XL LCM-LoRA 模型应用验证外接显卡
昨天的那篇文章中,我们聊过了《算能端侧 AI 盒子 Stable Diffusion 一秒一张图:AirBox BM1684X》,文章里使用的 SD 和 LCM 来进行图片生成。文章发布后,有同学在评论区提到,能否跑个 SDXL 和 LCM 的例子。
在昨天那台小设备上跑 SDXL 估计很难 1s 一张,但是今天使用 4090 移动版,跑个 1s+ 一张图,还是有可能的,哪怕项目没有经过太多的工程优化。
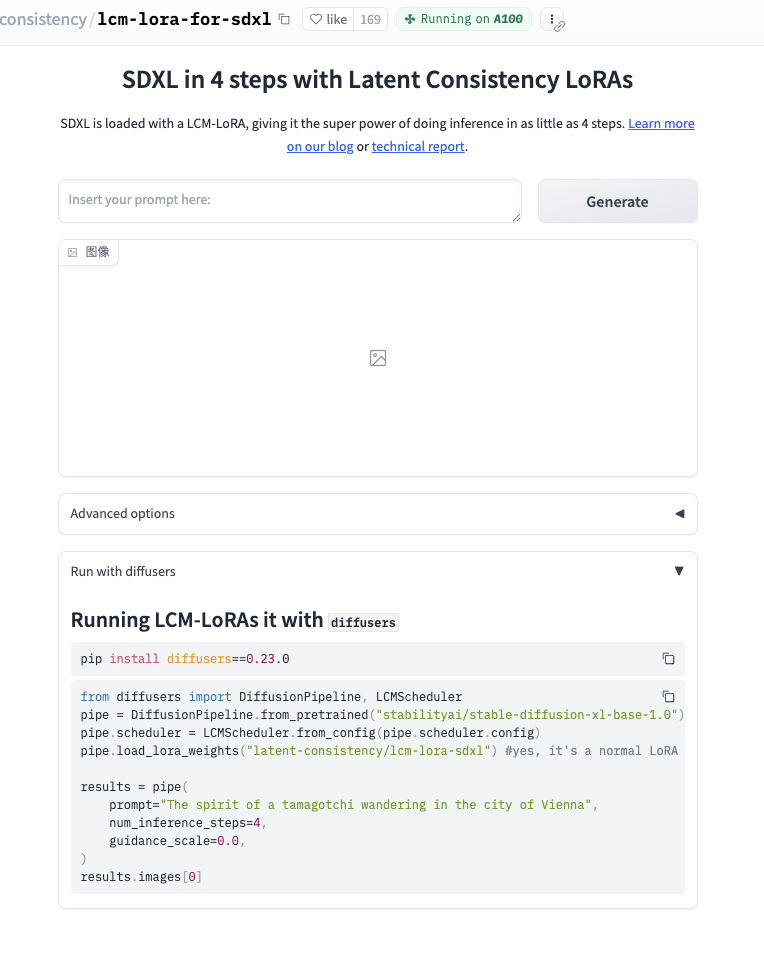
为了省事,我直接选择了一个 HuggingFace 空间上的项目,latent-consistency/lcm-lora-for-sdxl。使用 Docker 将项目正在运行中的镜像完整的拖到本地执行,然后替换云端的 A100 为本地的 4090 移动版:
# 下载空间对应的镜像文件
docker pull registry.hf.space/latent-consistency-lcm-lora-for-sdxl:latest# 使用本地资源运行镜像
docker run -it -p 7860:7860 --platform=linux/amd64 --gpus all -e HF_TOKEN="这里替换为你的 Token" -e SAFETY_CHECKER="True" -e HF_HOME="/data/.huggingface" registry.hf.space/latent-consistency-lcm-lora-for-sdxl:latest python app.py
需要注意的时候,想要运行这个镜像,你需要在 HuggingFace 上创建一个个人 Token,并替换命令行中对应的内容。
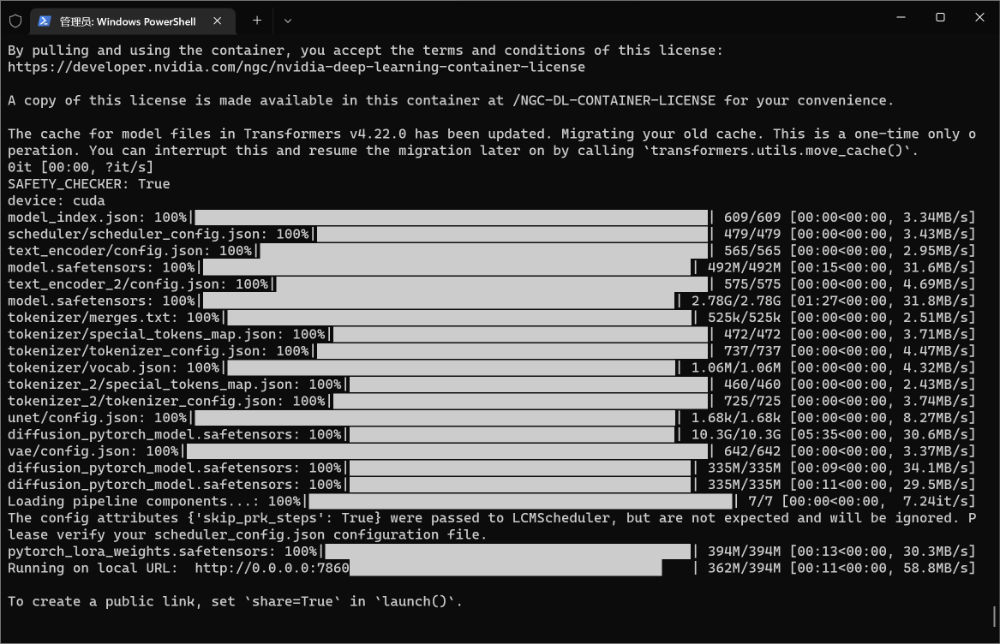
命令执行完毕,Docker 会自动下载基础镜像,并创建一个容器,在容器中执行 Python 程序,从 HuggingFace 上自动获取必要的模型程序。稍等片刻,程序执行完毕,我们就能够看到熟悉的访问地址提示了。
在浏览器中访问 http://localhost:7860,就能够在本地对这个模型应用进行验证啦。
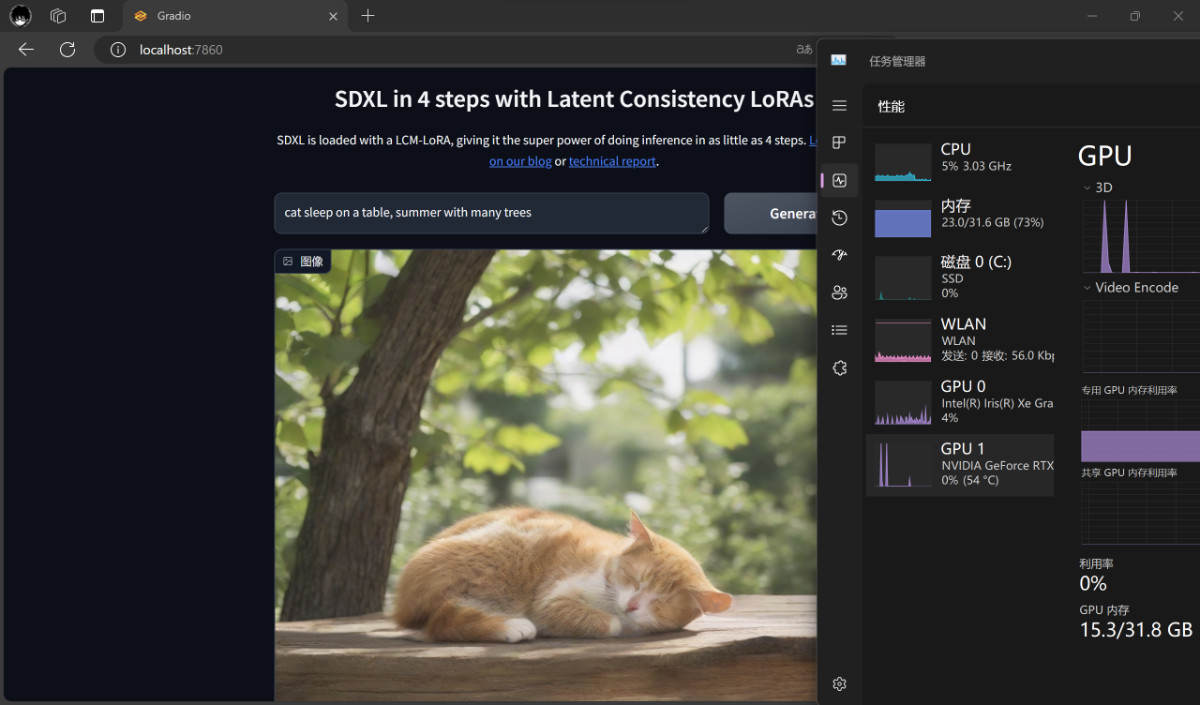
随便在输入框里输入点什么,然后点击“生成”,大概 1 秒钟多点的时间,就能够得到一张看起来还凑合的图片啦。(当然,因为使用的是扩展坞,第一次启动的时候,需要传输模型到显卡中,大概会有几十秒时间做预热。)
其他:Windows 的 Copilot 功能
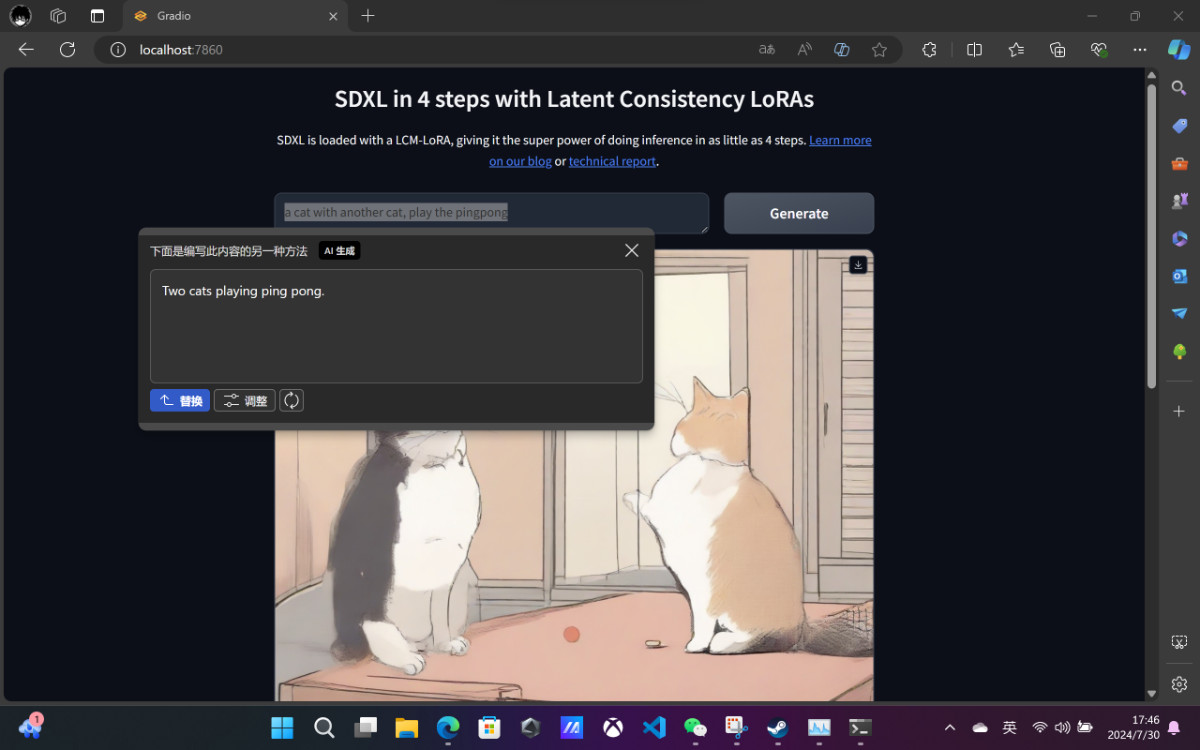
在我生成的过程中,偶尔会触发出来 Windows 的 Copilot 功能,能够对我随便写的 Prompt 进行改写优化。
个人体验,排除掉云端响应速度比较慢这个缺点,还是挺好用的,希望后续这个功能能够被本地的 NPU 或者其他的算力支持,缩短一些这个交互的使用时间吧。
最后
好了,这篇文章,我们就先聊到这里啦。

有了相对大的端侧计算设备,接下来其实有两个方向值得折腾,一个明显是折腾更多的端侧模型。另外一个,你猜得到吗?
–EOF
我们有一个小小的折腾群,里面聚集了一些喜欢折腾、彼此坦诚相待的小伙伴。
我们在里面会一起聊聊软硬件、HomeLab、编程上、生活里以及职场中的一些问题,偶尔也在群里不定期的分享一些技术资料。
关于交友的标准,请参考下面的文章:
致新朋友:为生活投票,不断寻找更好的朋友
当然,通过下面这篇文章添加好友时,请备注实名和公司或学校、注明来源和目的,珍惜彼此的时间 😄
关于折腾群入群的那些事
本文使用「署名 4.0 国际 (CC BY 4.0)」许可协议,欢迎转载、或重新修改使用,但需要注明来源。 署名 4.0 国际 (CC BY 4.0)
本文作者: 苏洋
创建时间: 2024年07月30日
统计字数: 8823字
阅读时间: 18分钟阅读
本文链接: https://soulteary.com/2024/07/30/portable-mobile-workstation-edge-ai-device-notes-rog-flow-x13-and-4090-docking-station.html