第一个项目:13万字,带源代码和详细步骤
目录
第一个项目:13万字,带源代码和详细步骤
1. 项目介绍
2. 核心技术
3. 日志系统介绍
3.1 为什么需要⽇志系统
3.2 ⽇志系统技术实现
3.2.1 同步写⽇志
3.2.2 异步写⽇志
4.知识点和单词补充
4.1单词补充
4.2知识点补充
4.2.1完美转发forward
4.2.3 override
4.2.4 虚函数和纯虚函数
4.2.5智能指针中的reset
4.2.6继承和多态中,函数返回类型是父类的,返回子类的类型
4.2.7继承和多态中,函数返回类型是父类的,怎么样才可以返回子类的类型
4.2.8 stat(文件存不存在)
4.2.9 文件路径查找
4.3.0 c++线程
4.3.1 using的用法
4.3.2 ostream将数据写入
4.3.3 using和智能指针一起控制类对象
4.3.4使用 strftime 格式化时间
4.3.5 stringstream
4.3.6 终止一个程序的执行abort
4.3.7 cout.write
4.3.8 ofstream中的接口
4.3.9 stringstream
4.4.0 enum clss
4.4.1 atomic原子操作的库
4.4.2 unique_lock
4.4.3 智能指针中get接口
4.4.4 copy
4.2.5 ifstream的成员函数
4.2.6 seekg
4.2.7 condition_variable(多线程)
4.2.8 回调函数和智能指针
4.2.9 c++中的线程
4.3.0 线程的接口
4.3.1 bind绑定
5. 相关技术知识补充
5.1 不定参函数
不定参宏函数
打印文件名和行号
宏函数
编辑
c语言中不定参函数的使用,不定参数据的访问
模拟一个printf
C++风格不定参函数
5.2 设计模式
六⼤原则:
单例模式
• 饿汉模式:
懒汉模式
编辑
⼯⼚模式
抽象工厂模式(开闭原则没有遵循)
建造者模式:
代理模式
6. 日志系统框架设计
6.1模块划分
6.2 模块关系图
7. 代码设计
7.1 实⽤类(常用)设计
7.2 日志等级类设计
7.3 日志消息类设计
7.4 日志输出格式化类设计
7.5日志落地类的设计
7.6 日志器类(Logger)设计(建造者模式)
7.7 双缓冲区异步任务处理器(AsyncLooper)设计(实现异步日志缓冲区)
7.8 异步⽇志器(AsyncLogger)设计
7.9 单例日志器管理类设计(单例模式)
7.10日志宏&全局接口设计 (代理模式)
8.目前为止代码基本完成
buffer.hpp
format.hpp
level.hpp
ljwlog.h
logger.hpp
loop.hpp
makefile
message.hpp
sink.hpp
test.cc
util.hpp
1. 项目介绍
本项目主要实现⼀个日志系统,其主要⽀持以下功能:
• ⽀持多级别日志消息
• ⽀持同步日志和异步日志
• ⽀持可靠写⼊日志到控制台、⽂件以及滚动⽂件中
• ⽀持多线程程序并发写日志
• ⽀持扩展不同的日志落地⽬标地
2. 核心技术
• 类层次设计(继承和多态的应⽤)
• C++11(多线程、auto、智能指针、右值引⽤等)
• 双缓冲区
• ⽣产消费模型
• 多线程
• 设计模式(单例、⼯⼚、代理、建造者等)
本项⽬不依赖其他任何第三⽅库,只需要安装好CentOS/Ubuntu+vscode/vim(vscode写)环境即可开发。
3. 日志系统介绍
3.1 为什么需要⽇志系统
• ⽣产环境的产品为了保证其稳定性及安全性是不允许开发⼈员附加调试器去排查问题,可以借助日志系统来打印⼀些日志帮助开发⼈员解决问题
• 上线客户端的产品出现bug无法复现并解决,可以借助⽇志系统打印⽇志并上传到服务端帮助开发⼈员进⾏分析
• 对于⼀些⾼频操作(如定时器、⼼跳包)在少量调试次数下可能⽆法触发我们想要的⾏为,通过断点的暂停⽅式,我们不得不重复操作⼏⼗次、上百次甚⾄更多,导致排查问题效率是⾮常低下,可以借助打印⽇志的⽅式查问题
• 在分布式、多线程/多进程代码中,出现bug⽐较难以定位,可以借助⽇志系统打印log帮助定位 bug
• 帮助⾸次接触项⽬代码的新开发⼈员理解代码的运⾏流程
3.2 ⽇志系统技术实现
⽇志系统的技术实现主要包括三种类型:
• 利⽤printf、std::cout等输出函数将⽇志信息打印到控制台
• 对于⼤型商业化项目,为了⽅便排查问题,我们⼀般会将日志输出到⽂件或者是数据库系统⽅便查询和分析日志,主要分为同步⽇志和异步⽇志⽅式
◦ 同步写日志
◦ 异步写日志
3.2.1 同步写⽇志
同步⽇志是指当输出⽇志时,必须等待⽇志输出语句执⾏完毕后,才能执⾏后⾯的业务逻辑语句,⽇志输出语句与程序的业务逻辑语句将在同⼀个线程运⾏。每次调⽤⼀次打印⽇志API就对应⼀次系统调 ⽤write写⽇志⽂件。

在⾼并发场景下,随着⽇志数量不断增加,同步⽇志系统容易产⽣系统瓶颈:
• ⼀⽅⾯,⼤量的⽇志打印陷⼊等量的write系统调⽤,有⼀定系统开销.
• 另⼀⽅⾯,使得打印⽇志的进程附带了⼤量同步的磁盘IO,影响程序性能.
3.2.2 异步写⽇志
异步⽇志是指在进⾏⽇志输出时,⽇志输出语句与业务逻辑语句并不是在同⼀个线程中运⾏,⽽是有专⻔的线程⽤于进⾏⽇志输出操作。业务线程只需要将⽇志放到⼀个内存缓冲区中不⽤等待即可继续执⾏后续业务逻辑(作为⽇志的⽣产者),⽽⽇志的落地操作交给单独的⽇志线程去完成(作为⽇志的消费者),这是⼀个典型的⽣产-消费模型。

这样做的好处是即使⽇志没有真的地完成输出也不会影响程序的主业务,可以提⾼程序的性能:
• 主线程调⽤⽇志打印接口成为⾮阻塞操作
• 同步的磁盘IO从主线程中剥离出来交给单独的线程完成
4.知识点和单词补充
4.1单词补充
单例模式:Singleton pattern
实例:instance
工厂:factory
指针:pointer(ptr的由来)(智能指针shared_ptr等等)
建造者:Builder
主板:Motherboard(_board)
显示器:Display(_display)
操作系统:Operating System(_os)
参数:paramater
指挥者:director
建造(组建):construct
房东:landlord
中介:intermediary
实用类:Utility class(util)
存在:exist
文件:file
路径:path
目录:directory
格式:format
项:item
模式:pattern
格式化程序:Formatter
有效载荷:payload
下沉(落地):sink
基础:base
限制:limit
同步:synchronization
异步:asynchronous
序列化:serialization
同步:synchronization
异步:asynchronous
缓冲:buffer
默认的:default
阈值:threshold
增量:increment
循环:loop
消费者:consumer
生产者:producer
日志记录器:logger
管理者:manager
根,根源:root
整体的全局的:global
4.2知识点补充
4.2.1完美转发forward
在C++中,完美转发(Perfect Forwarding)是一种用于在函数模板中保持参数原有类型的技巧,包括它们的const和volatile修饰符以及引用属性。这在编写模板代码时非常有用,特别是在创建工厂函数或者封装其他函数调用时。
以下是对完美转发的一些总结:
基本概念
-
转发:将函数的参数原封不动地传递给另一个函数。
-
完美转发:在转发过程中保持参数的左值或右值属性。
关键字和操作符
-
std::forward<T>(u):条件性转发,如果u是左值,则返回左值引用;如果u是右值,则返回右值引用。 -
T&&:通用引用,在模板参数中用来捕获任意类型的参数。
完美转发的实现
在函数模板中,通常结合使用T&&和std::forward来实现完美转发:
template<typename T>
void func(T&& arg) {someOtherFunc(std::forward<T>(arg));
}
这里,T&&是一个通用引用,可以绑定到任何类型的参数上,std::forward<T>(arg)则确保了参数的左右值属性在转发时得以保持。
注意事项
-
通用引用:只有当
T&&是模板参数时,它才是通用引用。否则,它可能是一个右值引用。 -
引用折叠:当将一个引用类型绑定到另一个引用类型上时,会发生引用折叠,例如,
T& &会折叠成T&,而T&& &会折叠成T&。 -
转发时的const保持:如果参数是const的,完美转发也会保持const属性。
完美转发的用途
-
在模板库中,如工厂模式、函数适配器等,允许用户以最有效率的方式传递参数。
-
在函数重载和模板特化中,确保参数的值类别不变。
示例
#include <iostream>
#include <utility> // for std::forwardvoid print(int& x) {std::cout << "lvalue: " << x << std::endl;
}void print(int&& x) {std::cout << "rvalue: " << x << std::endl;
}template<typename T>
void wrapper(T&& arg) {print(std::forward<T>(arg));
}int main() {int a = 5;wrapper(a); // 转发为左值wrapper(5); // 转发为右值return 0;
}
在这个例子中,wrapper函数模板使用完美转发来保持参数arg的值类别,并将它传递给print函数。
总结
完美转发是C++11中引入的一个高级特性,它使得模板代码更加灵活和高效。理解并正确使用完美转发,对于编写可重用和高效的C++模板代码至关重要。
4.2.2 shared_ptr和make_shared
在C++中,shared_ptr是一种智能指针,它提供了对动态分配的对象的共享所有权。make_shared是一个标准库函数模板,用于创建一个shared_ptr对象,同时管理动态分配的对象。以下是shared_ptr和make_shared之间的关系:
shared_ptr:
-
shared_ptr是一个模板类,定义在<memory>头文件中。 -
它用于管理动态分配的对象,通过引用计数机制来确保对象在不再被需要时自动被销毁。
-
当最后一个
shared_ptr被销毁或重置时,它所管理的对象会被自动删除(调用delete)。
make_shared:
-
make_shared是一个模板函数,同样定义在<memory>头文件中。 -
它用于创建一个
shared_ptr对象,并分配和管理一个动态对象。 -
make_shared通常比直接使用new和shared_ptr的构造函数更高效,因为它可以一次性分配共享的控制块和对象内存,减少了内存分配的次数。
shared_ptr和make_shared的关系:
-
内存分配:
-
使用
new和shared_ptr的构造函数时,内存分配分为两步:首先分配对象内存,然后分配共享的控制块(用于引用计数和弱引用计数)。 -
使用
make_shared时,内存分配通常是一步完成的,即同时分配对象内存和控制块内存,这减少了内存分配的开销。
-
-
异常安全性:
-
make_shared提供了更强的异常安全性保证。在构造对象和控制块时,如果抛出异常,不会产生内存泄漏,因为内存分配是原子操作。
-
-
性能:
-
make_shared可能比直接使用shared_ptr的构造函数更快,因为它减少了内存分配的次数。 -
make_shared返回的shared_ptr可以直接使用,无需额外的步骤。
-
-
使用方式:
-
使用
make_shared时,不需要显式指定对象类型,它会根据传递的参数自动推导。
-
示例:
以下是使用shared_ptr和make_shared的例子:
#include <memory>
#include <iostream>class MyClass {
public:MyClass() { std::cout << "MyClass constructed\n"; }~MyClass() { std::cout << "MyClass destroyed\n"; }
};int main() {// 使用 make_shared 创建 shared_ptrstd::shared_ptr<MyClass> ptr1 = std::make_shared<MyClass>();// 直接使用 shared_ptr 构造函数std::shared_ptr<MyClass> ptr2(new MyClass());return 0;
}
在这个例子中,ptr1和ptr2都是shared_ptr,但ptr1是通过make_shared创建的,而ptr2是通过new和shared_ptr的构造函数创建的。
结论:
make_shared是创建shared_ptr对象的首选方式,因为它更高效且提供更好的异常安全性。然而,在某些情况下,例如需要自定义删除器或者初始化对象时,可能需要直接使用shared_ptr的构造函数。
4.2.3 override
在C++中,override关键字用于明确表示派生类中的函数意在重写基类中的虚函数。这是C++11标准中引入的一个特性,旨在提高代码的可读性和可维护性。
下面是使用override关键字的一个简单示例:
class Base {
public:virtual void doSomething() {// 基类的实现}
};class Derived : public Base {
public:void doSomething() override { // 使用override关键字// 派生类的实现,重写基类的虚函数}
};
在这个例子中,Derived类中的doSomething函数使用了override关键字,这表明它重写了Base类中的doSomething虚函数。如果基类中不存在这样的虚函数,或者签名不匹配,编译器将会报错。
使用override关键字的几个好处:
-
明确性:清楚地表明函数的意图是重写基类中的虚函数。
-
安全性:如果基类中的虚函数签名改变了,而派生类没有更新,编译器将会报错,因为不再满足重写的条件。
-
维护性:有助于其他开发者理解代码,特别是在大型项目中。
需要注意的是,override关键字不会改变函数的任何行为,它仅仅是一个指示器,告诉编译器这个函数应该重写基类中的某个虚函数。
4.2.4 虚函数和纯虚函数
在 C++ 中,虚函数和纯虚函数是实现多态性的重要机制,尤其是在面向对象编程中。它们的主要区别在于它们的定义和用途。下面将详细介绍这两者的区别及其用法。
1. 虚函数(Virtual Function)
虚函数是基类中声明为 virtual 的成员函数,允许在派生类中重写(override)。虚函数的主要目的是实现运行时多态性。
特点:
-
在基类中使用
virtual关键字声明。 -
可以在派生类中被重写。
-
可以有实现(即可以在基类中定义函数体)。
-
通过基类指针或引用调用时,会根据对象的实际类型调用相应的函数。
示例:
#include <iostream>class Base {
public:virtual void show() { // 虚函数std::cout << "Base class show function called." << std::endl;}
};class Derived : public Base {
public:void show() override { // 重写虚函数std::cout << "Derived class show function called." << std::endl;}
};int main() {Base* b; // 基类指针Derived d; // 派生类对象b = &d; // 指向派生类对象b->show(); // 调用派生类的 show(),输出 "Derived class show function called."return 0;
}
2. 纯虚函数(Pure Virtual Function)
纯虚函数是没有实现的虚函数,通常用于定义接口。它在基类中声明为 virtual,并在函数声明后加上 = 0。包含纯虚函数的类称为抽象类,不能实例化。
特点:
-
在基类中声明为
virtual,并且在声明后加上= 0。 -
不可以在基类中有实现(没有函数体)。
-
派生类必须重写纯虚函数才能实例化。
-
用于定义接口,强制派生类实现特定功能。
示例:
#include <iostream>class AbstractBase {
public:virtual void show() = 0; // 纯虚函数
};class ConcreteDerived : public AbstractBase {
public:void show() override { // 重写纯虚函数std::cout << "ConcreteDerived class show function called." << std::endl;}
};int main() {// AbstractBase ab; // 错误:不能实例化抽象类ConcreteDerived cd; // 可以实例化派生类AbstractBase* ab = &cd; // 基类指针指向派生类对象ab->show(); // 调用派生类的 show(),输出 "ConcreteDerived class show function called."return 0;
}
3. 总结
| 特性 | 虚函数 | 纯虚函数 |
|---|---|---|
| 定义 | 使用 | 使用 |
| 实现 | 可以有实现 | 没有实现 |
| 抽象类 | 不一定是抽象类 | 是抽象类 |
| 实例化 | 可以实例化包含虚函数的类 | 不能实例化包含纯虚函数的类 |
| 派生类要求 | 可选重写 | 必须重写 |
用法区别
-
虚函数用于需要在基类中提供默认实现的情况,允许派生类选择性地重写。
-
纯虚函数用于定义接口,强制派生类实现特定的功能,确保派生类提供具体的实现。
通过理解虚函数和纯虚函数的区别及其用法,你可以更好地利用 C++ 的面向对象特性,设计出灵活和可扩展的程序。
4.2.5智能指针中的reset
在 C++ 中,reset 通常与智能指针(如 std::unique_ptr 和 std::shared_ptr)有关,用于管理动态分配的内存。下面将详细介绍 reset 的用法及其总结。
1. std::unique_ptr 的 reset
std::unique_ptr 是 C++11 引入的一种智能指针,确保对动态分配内存的独占拥有权。当 unique_ptr 被销毁时,它会自动释放指向的内存。reset 方法用于更改 unique_ptr 所管理的对象。
用法:
-
释放当前管理的对象:调用
reset会释放当前指针所管理的内存。 -
管理新对象:可以将
reset用于分配新的对象。
示例:
#include <iostream>
#include <memory>int main() {std::unique_ptr<int> ptr(new int(10)); // 创建一个 unique_ptr 管理的对象std::cout << "Value: " << *ptr << std::endl; // 输出值ptr.reset(new int(20)); // 释放原来的对象并管理新的对象std::cout << "New Value: " << *ptr << std::endl; // 输出新的值ptr.reset(); // 释放当前对象// 现在 ptr 是 nullptr,不能再解引用return 0;
}
std::shared_ptr 也是一种智能指针,允许多个指针共享同一个对象。它会自动管理引用计数,当最后一个指向该对象的 shared_ptr 被销毁时,内存才会被释放。
用法:
-
释放当前管理的对象:调用
reset会减少引用计数,并可能释放内存。 -
管理新对象:可以将
reset用于指向新的对象。
示例:
#include <iostream>
#include <memory>int main() {std::shared_ptr<int> sptr(new int(30)); // 创建一个 shared_ptr 管理的对象std::cout << "Value: " << *sptr << std::endl; // 输出值sptr.reset(new int(40)); // 释放原来的对象并管理新的对象std::cout << "New Value: " << *sptr << std::endl; // 输出新的值sptr.reset(); // 释放当前对象// 现在 sptr 是 nullptr,不能再解引用return 0;
}
3. 总结
-
功能:
-
reset方法用于更改智能指针所管理的对象,无论是std::unique_ptr还是std::shared_ptr。 -
当调用
reset时,当前指针管理的对象会被销毁(如果存在),并且指针会被更新为新的对象。
-
-
适用场景:
-
用于动态分配内存的智能指针,使得内存管理更安全,避免内存泄漏。
-
特别适合在资源管理和生命周期控制上需要精细管理的场景。
-
-
注意事项:
-
确保在使用
reset之前,指针不应为nullptr,否则会导致解引用错误。 -
使用
reset时,确保理解对象的所有权转移,特别是在shared_ptr中,确保引用计数的管理。
-
通过使用智能指针及其 reset 方法,C++ 程序员能够更安全地管理动态分配的内存,减少内存泄漏的风险。
4.2.6继承和多态中,函数返回类型是父类的,返回子类的类型
在 C++ 中,函数返回类型为父类的确可以返回子类的对象,这是面向对象编程中的多态性的一部分。具体来说,当一个函数声明的返回类型是父类时,你可以返回一个子类的实例。这种行为称为向上转型(upcasting),允许你通过父类的指针或引用来操作子类对象。
示例代码
#include <iostream>
using namespace std;// 基类
class Animal {
public:virtual void sound() { // 使用虚函数实现多态cout << "Animal sound" << endl;}
};// 派生类
class Dog : public Animal {
public:void sound() override { // 重写基类的方法cout << "Bark" << endl;}
};// 返回类型为父类指针的函数
Animal* getAnimal() {return new Dog(); // 返回子类的实例
}int main() {Animal* animal = getAnimal(); // 获取子类对象animal->sound(); // 输出: Barkdelete animal; // 释放动态分配的内存return 0;
}
解释
-
基类和派生类:
-
Animal是基类,其中定义了一个虚函数sound()。 -
Dog是从Animal派生出的子类,重写了sound()方法。
-
-
返回类型为父类指针:
-
getAnimal()函数的返回类型是Animal*,它返回的是一个Dog的实例。 -
这里的关键点是,尽管返回类型是
Animal*,但实际返回的是Dog类的对象。
-
-
多态性:
-
在
main()函数中,通过父类指针animal调用sound()方法时,实际执行的是Dog类中的sound()方法,这展示了运行时多态性。 -
这使得程序可以在不修改代码的情况下扩展新的子类,只需实现适当的函数重写即可。
-
小结
因此,在 C++ 中,函数返回类型为父类是可以返回子类的对象的,这种特性支持多态性,使得代码更灵活且易于扩展。
4.2.7继承和多态中,函数返回类型是父类的,怎么样才可以返回子类的类型
在 C++ 中,如果一个函数的返回类型是父类,你可以通过返回一个子类的实例来实现多态性。为了成功返回子类的类型,你需要确保以下几点:
1. 使用指针或引用
确保函数返回的是父类的指针或引用,以便能够指向任何子类的对象。这是实现多态性的关键。
2. 使用虚函数
在基类中使用 virtual 关键字来声明函数,以便在子类中重写该函数。这可以确保调用该函数时执行的是子类的实现,而不是基类的实现。
示例代码
下面是一个示例,展示如何在 C++ 中实现这一点:
#include <iostream>
using namespace std;// 基类
class Animal {
public:virtual void sound() { // 声明虚函数cout << "Animal sound" << endl;}virtual ~Animal() {} // 虚析构函数
};// 派生类
class Dog : public Animal {
public:void sound() override { // 重写基类的虚函数cout << "Bark" << endl;}
};// 另一个派生类
class Cat : public Animal {
public:void sound() override { // 重写基类的虚函数cout << "Meow" << endl;}
};// 返回类型为父类指针的函数
Animal* getAnimal(const string& type) {if (type == "dog") {return new Dog(); // 返回子类 Dog 的实例} else if (type == "cat") {return new Cat(); // 返回子类 Cat 的实例}return nullptr; // 如果没有匹配类型,返回 nullptr
}int main() {Animal* animal1 = getAnimal("dog"); // 获取 Dog 对象animal1->sound(); // 输出: Barkdelete animal1; // 释放内存Animal* animal2 = getAnimal("cat"); // 获取 Cat 对象animal2->sound(); // 输出: Meowdelete animal2; // 释放内存return 0;
}
解释
-
基类和派生类:
-
Animal是基类,其中定义了一个虚函数sound()。 -
Dog和Cat是从Animal派生的类,它们重写了sound()方法。
-
-
返回父类指针:
-
getAnimal(const string& type)函数根据传入的参数返回不同子类的对象。返回类型是Animal*,这样可以指向Dog或Cat的实例。
-
-
多态性:
-
在
main()函数中,通过父类指针animal1和animal2调用sound()方法,实际执行的是子类Dog和Cat中的sound()方法。
-
-
内存管理:
-
使用
new动态分配内存时,确保在使用完对象后调用delete来释放内存,以避免内存泄漏。
-
小结
要返回子类的类型,确保函数返回的是父类的指针或引用,并在子类中重写虚函数。这样可以利用多态性,实现灵活的对象管理和动态行为。
4.2.8 stat(文件存不存在)
在 C++ 中,stat 函数用于获取文件的状态信息,例如文件的大小、类型、权限和时间戳等。它通常用于 POSIX 兼容的系统,如 Linux 和 macOS,包含在 <sys/stat.h> 头文件中。
stat 函数的原型
int stat(const char *path, struct stat *buf);
-
**
path**:要查询状态的文件的路径。 -
**
buf**:指向stat结构的指针,用于存放文件状态信息。
如果成功,stat 返回 0;如果失败,返回 -1 并设置 errno。
struct stat 结构
struct stat 结构包含有关文件的各种信息,定义如下:
struct stat {dev_t st_dev; // 文件所在设备的 IDino_t st_ino; // 文件的 inode numbermode_t st_mode; // 文件类型和权限nlink_t st_nlink; // 硬链接数量uid_t st_uid; // 文件所有者的用户 IDgid_t st_gid; // 文件所有者的组 IDdev_t st_rdev; // 特殊文件的设备 IDoff_t st_size; // 文件大小(字节数)time_t st_atime; // 最近访问时间time_t st_mtime; // 最近修改时间time_t st_ctime; // 最近状态改变时间
};
示例代码
以下是一个简单的示例,展示如何使用 stat 函数获取文件状态信息:
#include <iostream>
#include <sys/stat.h>
#include <unistd.h>
#include <ctime>int main() {const char *filePath = "example.txt"; // 要检查的文件路径struct stat fileInfo; // 用于存储文件状态信息// 获取文件状态if (stat(filePath, &fileInfo) == -1) {std::cerr << "Error getting file status." << std::endl;return 1;}// 输出文件信息std::cout << "File Size: " << fileInfo.st_size << " bytes" << std::endl;std::cout << "File Permissions: " << std::oct << (fileInfo.st_mode & 0777) << std::dec << std::endl;std::cout << "Last Modified: " << ctime(&fileInfo.st_mtime); // 打印最后修改时间std::cout << "Last Accessed: " << ctime(&fileInfo.st_atime); // 打印最后访问时间// 判断文件类型if (S_ISREG(fileInfo.st_mode)) {std::cout << "File Type: Regular file" << std::endl;} else if (S_ISDIR(fileInfo.st_mode)) {std::cout << "File Type: Directory" << std::endl;} else if (S_ISCHR(fileInfo.st_mode)) {std::cout << "File Type: Character device" << std::endl;} else if (S_ISBLK(fileInfo.st_mode)) {std::cout << "File Type: Block device" << std::endl;} else if (S_ISFIFO(fileInfo.st_mode)) {std::cout << "File Type: FIFO" << std::endl;} else if (S_ISLNK(fileInfo.st_mode)) {std::cout << "File Type: Symbolic link" << std::endl;} else if (S_ISSOCK(fileInfo.st_mode)) {std::cout << "File Type: Socket" << std::endl;}return 0;
}
解释
-
包含头文件:引入
sys/stat.h以使用stat和struct stat,并引入其他相关头文件。 -
定义文件路径:指定要获取信息的文件的路径。
-
调用
stat函数:获取文件的状态信息并存储在fileInfo中。若失败,输出错误信息并返回。 -
输出文件信息:
-
打印文件大小(字节数)。
-
打印文件权限(以八进制格式)。
-
打印最后修改时间和最后访问时间(使用
ctime转换为可读格式)。
-
-
判断文件类型:使用
S_IS*宏判断文件类型,输出相应的信息。
注意事项
-
路径有效性:确保提供的文件路径是有效的,否则
stat会返回错误。 -
文件权限:文件的权限可以通过
st_mode字段获取,使用按位与运算符可以提取特定权限。 -
类型判断:可以使用
S_ISREG,S_ISDIR,S_ISCHR,S_ISBLK,S_ISFIFO,S_ISLNK,S_ISSOCK等宏来判断文件类型。
总结
stat 函数是一个强大的工具,用于获取文件的各种状态信息,适用于文件管理和分析。在开发中,理解和使用 stat 函数是非常重要的。
4.2.9 文件路径查找
size_t pos = pathname.find_last_of("/\\"); 的作用是查找字符串 pathname 中最后一个出现的 / 或 \ 字符的位置,并将该位置的索引赋值给 pos。
例子:

4.3.0 c++线程
在 C++ 中,std::this_thread 和 std::thread 是与线程相关的两个重要组件,分别提供线程操作和线程管理的功能。以下是对它们及其接口的详细介绍。
1. std::thread
std::thread 是 C++11 中引入的类,用于创建和管理线程。
1.1. 构造函数
-
**
std::thread::thread()**:默认构造函数,创建一个未关联的线程。 -
**
template<class Function, class... Args> explicit thread(Function&& f, Args&&... args)**:创建一个新线程,执行函数f,并将参数args传递给它。
1.2. 成员函数
-
**
void join()**:等待线程完成执行,阻塞当前线程,直到被调用的线程执行结束。 -
**
void detach()**:分离线程,使其在后台独立运行,不再与主线程关联。 -
**
bool joinable() const**:检查线程是否可加入。如果线程已结束或被分离,返回false。 -
**
std::thread::~thread()**:析构函数。若线程仍在运行且未分离,会调用std::terminate()。
示例
#include <iostream>
#include <thread>void threadFunction(int id) {std::cout << "Thread " << id << " is running." << std::endl;
}int main() {std::thread t1(threadFunction, 1); // 创建线程 t1std::thread t2(threadFunction, 2); // 创建线程 t2t1.join(); // 等待线程 t1 完成t2.join(); // 等待线程 t2 完成return 0;
}
2. std::this_thread
std::this_thread 提供了与当前线程相关的操作,如获取线程 ID、休眠等。
2.1. 成员函数
-
**
static void sleep_for(const std::chrono::duration& rel_time)**:使当前线程休眠指定的时间段。 -
**
static void sleep_until(const std::chrono::time_point<Clock, Duration>& abs_time)**:使当前线程休眠直到指定的时间点。 -
**
static std::thread::id get_id()**:获取当前线程的 ID。 -
**
static bool yield()**:提示调度程序当前线程希望让出 CPU 控制权。
示例
#include <iostream>
#include <thread>
#include <chrono>void threadFunction(int id) {std::cout << "Thread " << id << " is running." << std::endl;std::this_thread::sleep_for(std::chrono::seconds(1)); // 休眠 1 秒
}int main() {std::thread t(threadFunction, 1);std::cout << "Current thread ID: " << std::this_thread::get_id() << std::endl;t.join(); // 等待线程完成return 0;
}
3. 总结
-
std::thread是用于创建和管理线程的类,提供了创建、等待和分离线程的功能。 -
std::this_thread提供了与当前线程相关的操作,如休眠和获取线程 ID。 -
使用
std::thread和std::this_thread,可以有效地实现多线程编程,确保线程的创建、管理和同步。
4. 常用功能示例
使用 sleep_for
#include <iostream>
#include <thread>void threadFunction() {std::cout << "Thread is going to sleep." << std::endl;std::this_thread::sleep_for(std::chrono::seconds(2)); // 休眠 2 秒std::cout << "Thread has woken up." << std::endl;
}int main() {std::thread t(threadFunction);t.join();return 0;
}
使用 yield
#include <iostream>
#include <thread>void threadFunction(int id) {std::cout << "Thread " << id << " is running." << std::endl;std::this_thread::yield(); // 提示调度程序让出 CPU
}int main() {std::thread t1(threadFunction, 1);std::thread t2(threadFunction, 2);t1.join();t2.join();return 0;
}
通过 std::thread 和 std::this_thread 的组合,C++ 程序员可以灵活地实现多线程应用,充分利用多核处理器的优势。
4.3.1 using的用法
在 C++ 中,using 关键字不仅用于简化类型名称和引入命名空间,还可以在与回调函数结合使用时,提供更清晰的语法。回调函数是一种通过函数指针或函数对象传递的函数,以便在特定事件发生时被调用。以下是对 using 的用法以及如何实现回调函数的详细说明。
1. using 关键字的用法
在回调函数的上下文中,using 主要用于定义函数指针类型或类型别名,使得代码更简洁和易于理解。
示例:使用 using 定义函数指针类型
#include <iostream>// 定义一个函数指针类型
using Callback = void(*)(int);void callbackFunction(int value) {std::cout << "Callback called with value: " << value << std::endl;
}// 函数接受回调函数
void performAction(Callback cb, int value) {cb(value); // 调用回调函数
}int main() {performAction(callbackFunction, 42); // 传递回调函数return 0;
}
2. 使用函数对象(可调用对象)
除了使用函数指针,C++ 还支持使用函数对象(如 std::function)作为回调函数。这种方式提供了更大的灵活性和可读性。
示例:使用 std::function 作为回调
#include <iostream>
#include <functional> // 引入 std::function// 使用 std::function 定义回调类型
using Callback = std::function<void(int)>;void performAction(Callback cb, int value) {cb(value); // 调用回调函数
}int main() {// 使用 lambda 表达式作为回调函数performAction([](int value) {std::cout << "Lambda callback called with value: " << value << std::endl;}, 100);// 使用普通函数作为回调performAction(callbackFunction, 200);return 0;
}
3. 使用类中的回调
回调函数也可以是类中的成员函数,这时需要使用 std::bind 或 lambda 表达式来绑定对象。
示例:使用类成员函数作为回调
#include <iostream>
#include <functional>class MyClass {
public:void memberFunction(int value) {std::cout << "Member function called with value: " << value << std::endl;}
};using Callback = std::function<void(int)>;void performAction(Callback cb, int value) {cb(value); // 调用回调函数
}int main() {MyClass obj;// 使用 std::bind 绑定成员函数Callback cb = std::bind(&MyClass::memberFunction, &obj, std::placeholders::_1);performAction(cb, 300); // 传递绑定的回调函数return 0;
}
总结
-
using关键字 在 C++ 中可用于简化函数指针或可调用对象的类型定义,特别在回调函数的上下文中,可以使代码更加清晰易懂。 -
回调函数 可以通过函数指针、函数对象(如
std::function)或 lambda 表达式实现。 -
C++ 的灵活性允许使用类成员函数作为回调,这时可以利用
std::bind或 lambda 进行绑定。
4.3.2 ostream将数据写入
在 C++ 中,将 std::ostream 作为参数传递的主要目的是为了实现灵活的输出,允许函数将输出结果写入不同的输出流(如控制台、文件等)。以下是 std::ostream 作为参数的用法,包括函数定义、调用及示例。
1. 函数定义
可以将 std::ostream 的引用或指针作为函数参数,以便在函数内部进行输出操作。
示例:使用 std::ostream 引用作为参数
#include <iostream>
#include <string>// 定义一个接受 ostream 引用的函数
void printMessage(std::ostream& os, const std::string& message) {os << message << std::endl; // 将消息写入输出流
}int main() {printMessage(std::cout, "Hello, World!"); // 输出到控制台std::ofstream outFile("output.txt"); // 创建文件输出流if (outFile.is_open()) {printMessage(outFile, "Writing to a file!"); // 输出到文件outFile.close(); // 关闭文件流} else {std::cerr << "Unable to open file!" << std::endl; // 输出错误信息}return 0;
}
2. 通过 std::ostream 实现灵活的日志记录
通过将 std::ostream 作为参数,可以实现灵活的日志记录功能,支持不同的输出目标。
示例:日志记录函数
#include <iostream>
#include <fstream>
#include <string>void logMessage(std::ostream& os, const std::string& level, const std::string& message) {os << "[" << level << "] " << message << std::endl; // 输出日志
}int main() {logMessage(std::cout, "INFO", "Application started."); // 输出信息到控制台std::ofstream logFile("log.txt"); // 创建文件输出流if (logFile.is_open()) {logMessage(logFile, "ERROR", "An error occurred!"); // 输出错误日志到文件logFile.close(); // 关闭文件流} else {std::cerr << "Unable to open log file!" << std::endl; // 输出错误信息}return 0;
}
3. 使用 std::ostream 的指针
虽然使用引用更为常见,但也可以使用指针作为参数。
示例:使用 std::ostream 指针
#include <iostream>
#include <fstream>void outputToStream(std::ostream* os, const std::string& message) {if (os) { // 检查指针是否有效*os << message << std::endl; // 将消息写入输出流}
}int main() {outputToStream(&std::cout, "Hello from pointer!"); // 输出到控制台std::ofstream outFile("output.txt");if (outFile.is_open()) {outputToStream(&outFile, "Writing to file via pointer!"); // 输出到文件outFile.close();} else {std::cerr << "Unable to open file!" << std::endl;}return 0;
}
e.close(); } else { std::cerr << "Unable to open file!" << std::endl; } return 0; }
4. 总结
-
std::ostream作为参数使得函数具有更高的灵活性,可以输出到不同的流(如控制台、文件等)。 -
可以使用引用或指针来传递
std::ostream,通常推荐使用引用。 -
通过这种方式,可以实现通用的输出函数,简化代码和提高可重用性。
这种方法在需要动态选择输出目标(例如调试、日志记录等)时特别有用,能够使代码更加模块化和清晰。
4.3.3 using和智能指针一起控制类对象
在 C++ 中,结合 using 和智能指针可以有效地管理类对象的生命周期和内存。这种方法不仅简化了代码,还提高了安全性,避免了内存泄漏。以下是如何使用 using 和智能指针控制类对象的几种常见方式。
1. 使用 using 定义智能指针类型别名
通过 using 定义智能指针类型别名,可以使代码更加简洁,并且便于管理和使用。
示例:定义智能指针类型别名
#include <iostream>
#include <memory>class MyClass {
public:void display() const {std::cout << "MyClass instance." << std::endl;}
};class Container {
public:using MyClassPtr = std::unique_ptr<MyClass>; // 定义智能指针类型别名void createInstance() {instance = MyClassPtr(new MyClass()); // 使用类型别名创建对象}void showInstance() const {if (instance) {instance->display(); // 调用成员函数} else {std::cout << "Instance not created." << std::endl;}}private:MyClassPtr instance; // 使用智能指针作为成员变量
};int main() {Container container;container.showInstance(); // 输出: Instance not created.container.createInstance();container.showInstance(); // 输出: MyClass instance.return 0;
}
在需要多个对象共享同一个类实例时,可以使用 std::shared_ptr 结合 using。
#include <iostream>
#include <memory>class MyClass {
public:MyClass(int id) : id(id) {}void display() const {std::cout << "MyClass instance with ID: " << id << std::endl;}private:int id;
};class Manager {
public:using MyClassPtr = std::shared_ptr<MyClass>; // 定义智能指针类型别名void createInstance(int id) {instance = MyClassPtr(new MyClass(id)); // 创建实例并使用智能指针管理}void showInstance() const {if (instance) {instance->display(); // 调用成员函数} else {std::cout << "No instance created." << std::endl;}}private:MyClassPtr instance; // 使用智能指针作为成员变量
};int main() {Manager manager;manager.showInstance(); // 输出: No instance created.manager.createInstance(1);manager.showInstance(); // 输出: MyClass instance with ID: 1{Manager anotherManager;anotherManager.createInstance(2);anotherManager.showInstance(); // 输出: MyClass instance with ID: 2} // anotherManager 作用域结束,智能指针会自动释放内存manager.showInstance(); // 输出: MyClass instance with ID: 1return 0;
}
3. 结合 using、智能指针与工厂模式
使用工厂模式结合 using 和智能指针可以使对象的创建和管理更加灵活。
示例:使用工厂模式和智能指针创建对象
#include <iostream>
#include <memory>class MyClass {
public:MyClass(int value) : value(value) {}void display() const {std::cout << "MyClass value: " << value << std::endl;}private:int value;
};class MyClassFactory {
public:using MyClassPtr = std::unique_ptr<MyClass>; // 定义智能指针类型别名static MyClassPtr create(int value) {return MyClassPtr(new MyClass(value)); // 返回智能指针}
};int main() {auto obj = MyClassFactory::create(42); // 使用工厂创建对象obj->display(); // 输出: MyClass value: 42return 0;
}
总结
-
使用
using定义类型别名:可以简化智能指针的使用,增强代码的可读性。 -
选择合适的智能指针:根据需求选择
std::unique_ptr或std::shared_ptr,以便在对象的生命周期和共享上进行合理管理。 -
结合工厂模式:通过工厂方法创建和返回智能指针,能够有效地管理对象的生命周期,避免内存泄漏。
通过结合 using 和智能指针,您可以更灵活地控制类对象,同时提高代码的安全性和可读性。
4.3.4使用 strftime 格式化时间
以下示例演示如何将当前时间戳转换为 std::tm 结构,并使用 strftime 格式化为可读的时间字符串。
#include <iostream>
#include <ctime>
#include <iomanip>int main() {// 获取当前时间戳std::time_t timestamp = std::time(nullptr); // 获取当前时间戳// 将时间戳转换为 std::tm 结构std::tm timeinfo;
#ifdef _WIN32localtime_s(&timeinfo, ×tamp); // 在 Windows 上使用 localtime_s
#elselocaltime_r(×tamp, &timeinfo); // 在 Linux/Unix 上使用 localtime_r
#endif// 定义输出字符串的缓冲区char buffer[100];// 使用 strftime 格式化时间strftime(buffer, sizeof(buffer), "%Y-%m-%d %H:%M:%S", &timeinfo);// 输出格式化的当前时间std::cout << "当前时间: " << buffer << std::endl;return 0;
}
代码解析
-
获取当前时间戳:
-
使用
std::time(nullptr)获取当前的 Unix 时间戳。
-
-
转换为
std::tm结构:-
在 Windows 上,使用
localtime_s进行线程安全的转换;在其他平台,使用localtime_r。
-
-
定义输出缓冲区:
-
使用字符数组
buffer存储格式化后的时间字符串。
-
-
格式化时间:
-
使用
strftime将std::tm结构格式化为字符串。格式字符串"%Y-%m-%d %H:%M:%S"指定输出的格式。
-
-
输出结果:
-
使用
std::cout输出格式化后的时间字符串。
-
常用格式化标志
在 strftime 中使用的格式化标志包括:
-
%Y:四位年份 -
%m:月份(01-12) -
%d:日(01-31) -
%H:小时(00-23) -
%M:分钟(00-59) -
%S:秒(00-59)
4.3.5 stringstream
在 C++ 中,std::stringstream 是一个非常有用的类,它允许你在内存中处理字符串输入和输出。通过 stringstream,你可以方便地将不同类型的数据格式化为字符串,也可以从字符串中提取数据。这种方式类似于使用 std::cin 和 std::cout,但是是在字符串上操作。
基本用法
以下是 std::stringstream 的一些常见用法示例,包括创建 stringstream 对象、写入数据和从中读取数据。
示例代码
#include <iostream>
#include <sstream> // 包含 stringstream 的头文件
#include <string>int main() {// 创建一个 stringstream 对象std::stringstream ss;// 向 stringstream 中写入数据ss << "Hello, World! ";ss << 42; // 写入整数ss << " is the answer.";// 获取 stringstream 中的字符串std::string result = ss.str(); // 转换为字符串std::cout << "写入后的字符串: " << result << std::endl;// 清空 stringstreamss.str(""); // 清空内容ss.clear(); // 清空状态标志// 向 stringstream 中写入新的数据ss << "The value of pi is approximately: ";ss << 3.14159;// 从 stringstream 中读取数据std::string piString;double piValue;ss >> piString >> piValue; // 读取字符串和浮点数// 输出读取到的数据std::cout << piString << " " << piValue << std::endl;return 0;
}
代码解析
-
包含头文件:
-
#include <sstream>用于引入std::stringstream的定义。
-
-
创建
stringstream对象:-
使用
std::stringstream ss;创建一个stringstream实例。
-
-
写入数据:
-
使用
<<操作符将字符串和其他类型的数据写入stringstream对象。
-
-
获取字符串:
-
使用
ss.str()方法将stringstream中的内容转换为std::string。
-
-
**清空
stringstream**:-
使用
ss.str("")清空内容,使用ss.clear()清空状态标志,以便重新使用。
-
-
读取数据:
-
使用
>>操作符从stringstream中读取数据。可以读取不同类型的数据(如字符串和浮点数)。
-
-
输出结果:
-
使用
std::cout输出最终的结果。
-
常见应用场景
-
数据格式化:可以将不同类型的数据格式化为一个字符串,比如将数值、日期等转换为字符串形式。
-
解析字符串:可以将格式化的字符串解析为不同类型的数据,例如从字符串中提取整数、浮点数等。
-
构建字符串:通过串联多个数据片段来构建一个完整的字符串。
注意事项
-
使用
stringstream时要注意清空状态和内容,以防止后续操作受到影响。 -
在处理输入输出时,
stringstream提供了更大的灵活性,尤其是当需要处理复杂格式时。
4.3.6 终止一个程序的执行abort
在 C++ 中,如果你想要终止一个程序的执行,可以使用 abort() 函数,这个函数会引发一个异常并终止程序的运行。使用方式如下:
#include <cstdlib> // 包含 abort 函数int main() {// 某些条件下需要中止程序if (/* 某些条件 */) {abort(); // 终止程序}// 其他代码return 0;
}
4.3.7 cout.write
用到了cout.write,从data位置开始,写入len长度的数据
std::cout.write 是 C++ 标准库中 iostream 类的一部分,它允许你将一个字符序列直接写入到输出流中。与使用插入运算符 << 不同,write 方法不会格式化数据,而是将原始字节序列输出到流中。
cout.write 方法介绍
write 方法是 std::ostream 类的一个成员函数,其原型如下:
basic_ostream<charT, traits>& write(const charT* s, streamsize n);charT 是字符类型,对于 std::cout 来说,它是 char。
traits 是字符类型的特征类,通常不需要显式指定。
s 是指向要写入的字符序列的指针。
n 是要写入的字符数。
write 方法返回对调用它的 std::ostream 对象的引用,这使得你可以连续调用多个输出操作。
cout.write 方法使用
下面是如何使用 std::cout.write 方法的一些示例:
示例 1:写入一个 C 风格字符串的一部分
#include <iostream>int main() {const char* str = "Hello, World!";std::cout.write(str, 5); // 写入 "Hello"std::cout << std::endl; // 添加换行return 0;
}在这个例子中,我们只写入字符串的前5个字符。
示例 2:写入一个 std::string 对象
#include <iostream>
#include <string>
int main() {std::string str = "Hello, World!";std::cout.write(str.c_str(), str.size()); // 写入整个字符串std::cout << std::endl; // 添加换行return 0;
}这里,我们使用 c_str() 方法获取 std::string 的 C 风格字符串,并写入整个字符串。
示例 3:连续写入
#include <iostream>int main() {const char* str1 = "Hello, ";const char* str2 = "World!";std::cout.write(str1, 7) << " "; // 写入 "Hello, " 然后添加一个空格std::cout.write(str2, 6); // 写入 "World!"std::cout << std::endl; // 添加换行return 0;
}在这个例子中,我们使用 write 方法的返回值来连续调用输出操作。
注意事项
write 方法不会在写入后添加任何额外的字符,比如换行符或字符串结束符 \0。
如果 n 指定的字符数超过了 s 指向的字符串的实际长度,write 方法将写入尽可能多的字符,但不会导致未定义行为。
如果 n 为 0,write 方法不会执行任何操作。
使用 write 方法时,需要确保不会超出缓冲区的界限,以避免未定义行为。
4.3.8 ofstream中的接口
std::ofstream 接口和成员函数的参数介绍
std::ofstream 是 C++ 中用于处理文件输出的类,提供了多种接口和成员函数。以下是主要接口、成员函数及其参数的详细介绍。
构造函数
-
std::ofstream()-
参数:无
-
描述:创建一个
std::ofstream对象,但不打开任何文件。
-
-
std::ofstream(const char* filename)-
参数:
const char* filename- 要打开的文件名的 C 风格字符串。 -
描述:创建并打开指定名称的文件。
-
-
std::ofstream(const std::string& filename)-
参数:
const std::string& filename- 要打开的文件名的字符串对象。 -
描述:创建并打开指定名称的文件。
-
成员函数
-
void open(const char* filename)-
参数:
const char* filename- 要打开的文件名。 -
描述:打开指定的文件。如果文件已存在,默认情况下会清空文件内容。
-
-
void open(const std::string& filename)-
参数:
const std::string& filename- 要打开的文件名。 -
描述:打开指定的文件,功能与上面的重载相同。
-
-
bool is_open() const-
参数:无
-
描述:检查流是否成功打开,返回
true表示成功,false表示失败。
-
-
std::ofstream& operator<<(const T& value)-
参数:
const T& value- 要写入的数据,可以是任意类型(如整数、浮点数、字符串等)。 -
描述:重载插入运算符,用于将数据写入文件。
-
-
void write(const char* s, std::streamsize n)-
参数:
-
const char* s- 指向要写入的字符数组的指针。 -
std::streamsize n- 要写入的字符数量。
-
-
描述:将指定数量的字符写入文件。
-
-
void put(char c)-
参数:
char c- 要写入的单个字符。 -
描述:写入一个字符到文件。
-
-
void close()-
参数:无
-
描述:关闭打开的文件,释放相关资源。
-
-
void flush()-
参数:无
-
描述:刷新输出缓冲区,确保所有数据都写入文件。
-
-
状态检查:
-
**
bool good() const**:检查流的状态是否良好。 -
**
bool eof() const**:检查是否到达文件末尾。 -
**
bool fail() const**:检查流是否处于失败状态。 -
**
bool bad() const**:检查流是否处于错误状态。
-
open() 的详细用法
open() 成员函数用于打开一个文件。可以使用两种重载形式:
-
void open(const char* filename)-
参数:
const char* filename- 要打开的文件名。 -
使用示例:
cpp
std::ofstream outFile; outFile.open("example.txt");
-
-
void open(const std::string& filename)-
参数:
const std::string& filename- 要打开的文件名。 -
使用示例:
cpp
std::ofstream outFile; outFile.open(std::string("example.txt"));
-
在调用 open() 之后,可以使用 is_open() 检查文件是否成功打开。打开文件时,可以同时指定打开模式,如下所示:
打开模式总结
打开模式用于指定打开文件时的行为,可以使用逻辑或(|)运算符组合多种模式。以下是常用的打开模式:
-
std::ios::out-
描述:以输出模式打开文件(默认模式)。
-
效果:如果文件已存在,内容会被清空(除非使用
std::ios::app)。
-
-
std::ios::app-
描述:以追加模式打开文件。
-
效果:写入的数据会被添加到文件末尾,原有内容不被覆盖。
-
-
std::ios::trunc-
描述:以截断模式打开文件。
-
效果:如果文件已经存在,内容会被清空。
-
-
std::ios::binary-
描述:以二进制模式打开文件。
-
效果:适用于处理二进制数据,避免文本模式下的换行符转换等。
-
示例代码
以下示例展示了如何使用 std::ofstream 和 open() 方法:
#include <iostream>
#include <fstream>int main() {// 创建 ofstream 对象std::ofstream outFile;// 打开文件并指定打开模式outFile.open("example.txt", std::ios::out | std::ios::app); // 以追加模式打开文件// 检查文件是否成功打开if (!outFile.is_open()) {std::cerr << "无法打开文件!" << std::endl;return 1; // 返回错误代码}// 写入数据outFile << "Hello, World!" << std::endl; // 使用 << 运算符写入outFile.write("This is a binary data test.", 30); // 使用 write() 写入字符数组// 关闭文件outFile.close();return 0;
}
总结
std::ofstream提供了多种接口和成员函数,使得文件写入操作简单易用。open()方法允许通过指定文件名和打开模式来打开文件,确保满足不同的需求。- 各种打开模式(如
std::ios::app和std::ios::trunc等)使用户能够灵活控制文件的读写行为。
4.3.9 stringstream
std::stringstream 是 C++ 标准库中用于字符串输入输出的流类,属于 sstream 头文件。它允许程序员以流的方式读写字符串,使得字符串的处理更加灵活和方便。下面是 std::stringstream 的接口介绍以及相关总结。
1. 接口介绍
1.1 构造函数
-
std::stringstream():默认构造函数,创建一个空的stringstream对象。 -
std::stringstream(const std::string& str):使用给定字符串初始化stringstream。 -
std::stringstream(std::ios_base::openmode mode):以指定模式打开流。
1.2 成员函数
-
写入数据
-
template<typename T> std::stringstream& operator<<(const T& val):将数据写入字符串流。
-
-
读取数据
-
template<typename T> std::stringstream& operator>>(T& val):从字符串流中读取数据。
-
-
获取和设置内容
-
std::string str() const:获取当前字符串流的内容。 -
void str(const std::string& s):设置字符串流的内容为给定字符串。
-
-
流状态管理
-
void clear():清除流的状态标志。 -
bool eof() const:检查流是否到达文件末尾。 -
bool fail() const:检查流是否出现错误。 -
bool good() const:检查流的状态是否良好。 -
bool bad() const:检查流是否处于坏状态。
-
-
格式设置
-
std::streamsize precision(std::streamsize n):设置或获取浮点数的精度。 -
std::ios_base& setf(std::ios_base::fmtflags flags):设置格式标志。
-
1.3 其他功能
-
清空内容
-
void clear():清除流的状态,但不清空内容。 -
void str(const std::string& s):设置流的内容,可以用来清空内容。
-
2. 示例代码
以下是使用 std::stringstream 的一些基本操作示例:
#include <iostream>
#include <sstream>
#include <string>int main() {// 创建 stringstream 对象std::stringstream ss;// 写入数据ss << "Hello, " << "world! " << 42;// 获取当前字符串内容std::string result = ss.str();std::cout << "String content: " << result << std::endl;// 清空 stringstream 内容ss.str(""); // 清空内容,流的状态保持不变// 从字符串中读取数据ss.str("123 456 789");int a, b, c;ss >> a >> b >> c; // 读取整数std::cout << "Read values: " << a << ", " << b << ", " << c << std::endl;return 0;
}
3. 总结
-
功能:
std::stringstream提供了将不同数据类型与字符串之间转换的能力,方便进行格式化输出和解析输入。 -
灵活性:可以在流中读写多种数据类型,适合处理复杂字符串操作。
-
性能:由于使用内存中的字符串而非磁盘 I/O,性能较好,尤其适用于需要频繁字符串操作的场景。
-
易用性:接口简单易用,代码可读性高,适合调试和记录日志信息。
4. 使用场景
-
格式化输出:将多个变量格式化为字符串进行输出。
-
解析输入:从字符串中提取数据,特别是在处理用户输入或文件读取时。
-
调试:在调试过程中,可以将复杂的状态信息写入
stringstream,方便查看。
通过 std::stringstream,开发者可以更灵活地处理字符串数据,提升代码的清晰度和维护性。
4.4.0 enum clss
在C++中,enum class 是一种强类型枚举,提供了更好的类型安全性和命名空间管理。与传统的枚举不同,enum class 不会隐式转换为整数类型,这有助于防止错误并增强代码的可读性。
定义和使用 enum class
以下是enum class的基本定义和使用示例:
#include <iostream>// 定义一个强类型枚举
enum class Color {RED,GREEN,BLUE
};enum class Direction {NORTH,SOUTH,EAST,WEST
};int main() {// 使用强类型枚举Color myColor = Color::RED;Direction myDirection = Direction::NORTH;// 打印枚举值的整数值std::cout << "Color value: " << static_cast<int>(myColor) << std::endl; // 输出:Color value: 0std::cout << "Direction value: " << static_cast<int>(myDirection) << std::endl; // 输出:Direction value: 0return 0;
}
enum class 的特点
-
类型安全:
-
enum class不允许隐式转换为整数,必须使用static_cast进行显式转换。 -
不同的
enum class类型之间的值不能直接比较。
-
-
命名空间:
-
enum class的枚举值具有作用域,因此可以使用相同的名称定义不同的枚举。例如,可以同时有Color::RED和Direction::RED。
-
-
增强的可读性:
-
enum class提高了代码的可读性,因为枚举值使用类名作为前缀,清楚地表明了它们的来源。
-
示例
下面是一个完整的示例,演示了如何定义和使用 enum class:
#include <iostream>enum class Color {RED,GREEN,BLUE
};enum class Fruit {APPLE,ORANGE,BANANA
};void printColor(Color color) {switch (color) {case Color::RED:std::cout << "Color is Red" << std::endl;break;case Color::GREEN:std::cout << "Color is Green" << std::endl;break;case Color::BLUE:std::cout << "Color is Blue" << std::endl;break;}
}int main() {Color myColor = Color::GREEN;printColor(myColor);// Error: cannot implicitly convert enum class to int// int value = myColor; // This will cause a compilation errorreturn 0;
}
在这个示例中,我们定义了两个强类型枚举 Color 和 Fruit,并使用 switch 语句来打印颜色。尝试将 myColor 直接赋值给整数将导致编译错误,这体现了 enum class 的类型安全性。
4.4.1 atomic原子操作的库
在C++中,atomic 是一个提供原子操作的库,主要用于多线程编程。原子操作是不可分割的操作,即在执行过程中不会被其他线程中断。这有助于避免数据竞争和确保数据的一致性。
1. 头文件和基本概念
要使用 atomic,需要包含头文件 <atomic>。原子类型提供了一种高效的方式来在多线程环境中共享数据。
2. 原子类型
C++标准库提供了一些原子类型,如 std::atomic 和 std::atomic<T>,其中 T 是基本数据类型,如 int、bool 等。常用的原子类型包括:
-
std::atomic<int> -
std::atomic<bool> -
std::atomic<float> -
std::atomic<double> -
std::atomic<指针类型>
3. 常用操作
std::atomic 提供了多种原子操作,包括:
-
加载和存储:使用
load()和store()方法。 -
交换:使用
exchange()方法。 -
增量和减量:使用
fetch_add()和fetch_sub()方法。 -
比较和交换:使用
compare_exchange_strong()和compare_exchange_weak()方法。
4. 示例代码
以下是一个使用 std::atomic 的简单示例:
#include <iostream>
#include <atomic>
#include <thread>
#include <vector>std::atomic<int> counter(0); // 原子计数器void increment() {for (int i = 0; i < 1000; ++i) {counter++; // 原子递增}
}int main() {const int numThreads = 10;std::vector<std::thread> threads;// 创建多个线程for (int i = 0; i < numThreads; ++i) {threads.emplace_back(increment);}// 等待所有线程完成for (auto& t : threads) {t.join();}std::cout << "Final counter value: " << counter.load() << std::endl; // 输出:Final counter value: 10000return 0;
}
5. 注意事项
-
性能:原子操作通常比锁(mutex)更轻量级,但在某些情况下,锁可能表现得更好。选择使用原子操作还是锁取决于具体的应用场景。
-
数据竞争:使用原子类型可以防止数据竞争,但仍需注意其他共享资源的访问。
-
内存序:原子操作的内存序可能会影响程序的行为,
std::memory_order提供了多种内存序选项,如memory_order_seq_cst、memory_order_acquire、memory_order_release等。
6. 总结
std::atomic 提供了一种有效的方法来处理多线程编程中的数据共享问题。通过使用原子操作,可以避免数据竞争,确保数据的一致性。合理使用 atomic 类型和原子操作是实现线程安全代码的重要一步。
4.4.2 unique_lock
std::unique_lock 是 C++ 标准库中用于管理互斥锁的一个智能指针类型,提供了一种方便和安全的方式来控制互斥锁的生命周期。它主要用于多线程编程中的资源管理,以确保线程安全。
1. 基本概念
-
std::unique_lock是一个 RAII(资源获取即初始化)类型,意味着它在构造时锁定互斥量,在析构时自动释放锁。这样可以防止锁泄漏和确保资源的正确管理。
2. 特点
-
互斥量的独占性:
std::unique_lock是独占锁,不能被复制。每个unique_lock实例只能管理一个互斥量。 -
可移动性:
std::unique_lock支持移动语义,可以通过移动构造和移动赋值来转移锁的所有权。 -
灵活的锁管理:可以在需要时手动锁定和解锁互斥量,允许更灵活的控制。
3. 构造和使用
使用 std::unique_lock 时,通常配合 std::mutex 使用。以下是一些常见的操作:
-
构造:通过构造函数传入一个互斥量的引用,锁定该互斥量。
-
解锁:调用
unlock()方法手动解锁。 -
重新锁定:调用
lock()方法可以重新锁定互斥量。
4. 示例代码
以下是一个使用 std::unique_lock 的示例:
#include <iostream>
#include <thread>
#include <mutex>std::mutex mtx; // 定义一个互斥量
int sharedData = 0; // 共享数据void increment() {std::unique_lock<std::mutex> lock(mtx); // 锁定互斥量for (int i = 0; i < 1000; ++i) {++sharedData; // 访问共享数据}// lock 在这里自动释放,互斥量被解锁
}int main() {const int numThreads = 10;std::thread threads[numThreads];// 创建多个线程for (int i = 0; i < numThreads; ++i) {threads[i] = std::thread(increment);}// 等待所有线程完成for (auto& t : threads) {t.join();}std::cout << "Final shared data value: " << sharedData << std::endl; // 输出共享数据的最终值return 0;
}
5. 其他功能
-
延迟锁定:可以在构造时不立即锁定互斥量,稍后通过调用
lock()来手动锁定。 -
条件变量支持:与条件变量配合使用时,可以通过
std::unique_lock来管理互斥量和条件变量的状态。 -
自定义析构行为:可以通过自定义析构函数来实现特定的清理逻辑。
6. 总结
std::unique_lock 是一种强大而灵活的工具,用于管理互斥锁的生命周期和状态。它提供了 RAII 的便利,确保在作用域结束时自动释放锁,从而避免死锁和资源泄漏。合理使用 std::unique_lock 能够简化多线程编程中的锁管理,提高代码的可读性和安全性。
4.4.3 智能指针中get接口
智能指针中的 get() 接口总结与介绍
智能指针是 C++11 引入的一项重要特性,用于自动管理动态分配内存(堆内存)的生命周期,减少内存泄漏和悬挂指针的问题。智能指针是一种封装了原始指针的类,通常实现 RAII(资源获取即初始化)机制,通过智能指针的生命周期来控制对象的释放。
在智能指针中,get() 是一个常见的成员函数,它返回底层原始指针的指针(裸指针)。了解 get() 接口的使用,可以帮助开发者在某些需要原始指针的场景中使用智能指针,而不会丧失智能指针提供的内存管理功能。
1. 智能指针类型
在 C++11 标准中,主要有三种类型的智能指针,它们分别为:
-
**
std::unique_ptr**:独占所有权的智能指针,每次只能有一个unique_ptr拥有资源。 -
**
std::shared_ptr**:共享所有权的智能指针,多个shared_ptr可以共享对资源的所有权。 -
**
std::weak_ptr**:一种不控制资源生命周期的智能指针,通常与shared_ptr一起使用,避免循环引用。
2. get() 函数
get() 函数是智能指针的一个成员函数,它返回指向智能指针管理对象的原始指针。此函数非常有用,因为它允许开发者在需要原始指针的情况下,仍然能够保持智能指针对内存的自动管理功能。
返回值
-
std::unique_ptr::get():返回一个指向其管理对象的原始指针。 -
std::shared_ptr::get():返回一个指向共享对象的原始指针。
3. 使用场景
get() 函数通常用于以下几种场景:
-
与 C 函数库兼容:许多 C 函数库(例如一些处理原始指针的 C API)需要原始指针作为参数。通过
get(),我们可以将智能指针中的原始指针传递给这些库函数。 -
访问底层指针:如果你只需要访问底层对象,且不打算修改智能指针的管理行为,可以使用
get()获取原始指针。 -
避免复制或移动:当需要一个原始指针传递给某些 API 或者用于某些优化时,可以避免不必要的复制或移动。
4. get() 函数的使用示例
下面的示例代码展示了如何使用 get() 函数:
#include <iostream>
#include <memory>class MyClass {
public:MyClass(int x) : x(x) {std::cout << "MyClass constructed with " << x << std::endl;}void print() {std::cout << "MyClass x = " << x << std::endl;}private:int x;
};int main() {// 创建一个智能指针std::unique_ptr<MyClass> uniquePtr = std::make_unique<MyClass>(42);// 获取原始指针MyClass* rawPtr = uniquePtr.get();// 使用原始指针rawPtr->print();// 使用智能指针仍然会管理资源的释放return 0;
}
5. get() 在不同智能指针中的应用
5.1 std::unique_ptr 的 get() 函数
std::unique_ptr 是一种独占所有权的智能指针,其生命周期管理对象的内存。get() 返回的原始指针可以直接访问对象,但你需要确保在使用原始指针时,智能指针不会失去所有权,否则将导致未定义行为。
std::unique_ptr<int> p = std::make_unique<int>(10);
int* rawPtr = p.get(); // 获取原始指针
std::cout << *rawPtr << std::endl; // 输出 10
std::shared_ptr 允许多个智能指针共享同一个对象,get() 返回的原始指针也允许访问共享的对象。在使用 get() 获取原始指针时,需要注意,shared_ptr 会在引用计数为 0 时自动删除对象,因此原始指针的使用应小心,避免访问已经被删除的对象。
std::shared_ptr<int> p1 = std::make_shared<int>(20);
int* rawPtr = p1.get(); // 获取原始指针
std::cout << *rawPtr << std::endl; // 输出 20
5.3 std::weak_ptr 和 get()
std::weak_ptr 并不直接管理对象的生命周期,而是提供对 shared_ptr 管理的对象的“弱引用”。如果 shared_ptr 被销毁,weak_ptr 不会阻止对象的释放。调用 weak_ptr::get() 会返回一个原始指针,但这个指针可能会是 nullptr,因此在使用时要确保 shared_ptr 仍然有效。
std::shared_ptr<int> p1 = std::make_shared<int>(30);
std::weak_ptr<int> weakPtr = p1;
int* rawPtr = weakPtr.lock().get(); // 使用 lock() 获取一个 shared_ptrif (rawPtr) {std::cout << *rawPtr << std::endl; // 输出 30
} else {std::cout << "Object no longer exists" << std::endl;
}
6. 注意事项
-
悬挂指针问题:使用
get()获取的原始指针并没有延长智能指针的生命周期。如果智能指针在get()后被销毁,原始指针将变成悬挂指针,可能导致未定义行为。务必确保智能指针在原始指针使用期间是有效的。 -
避免直接使用原始指针:虽然
get()提供了一个访问底层对象的方法,但直接使用原始指针可能绕过智能指针的自动内存管理功能。为了避免内存泄漏和悬挂指针,应该尽量避免在智能指针的管理下直接使用裸指针。 -
性能考虑:使用
get()获取原始指针不会涉及性能损失,因为它只是返回内部持有的裸指针。然而,在可能的情况下,应该尽量避免手动管理裸指针的生命周期,而是利用智能指针提供的内存管理。
7. 总结
get() 函数是 C++ 中智能指针的重要功能之一,允许开发者在需要时获取底层的原始指针。它使得智能指针能够与传统的 C 风格代码兼容,尤其是在需要传递裸指针到 C 函数库的场景中。然而,开发者在使用 get() 时应该小心,以避免悬挂指针和内存管理错误。总体来说,尽量保持智能指针的封装性,避免直接操作裸指针,才能充分利用智能指针的内存管理优势。
智能指针的 get() 函数是一种便捷的工具,但它的使用应该是慎重的,确保对象的生命周期在整个使用过程中得到妥善管理。
4.4.4 copy
在C++中,copy函数是算法头文件<algorithm>中提供的一个标准库函数,用于将一个容器或数组中的元素复制到另一个容器或数组中。以下是copy函数的基本用法:
函数原型
template <class InputIterator, class OutputIterator>
OutputIterator copy(InputIterator first, InputIterator last, OutputIterator result);
参数说明
-
first:指向输入序列开始位置的迭代器。 -
last:指向输入序列结束位置的后一个位置的迭代器。 -
result:指向输出序列开始位置的迭代器。
返回值
copy函数返回一个指向输出序列最后一个被复制元素的下一个位置的迭代器。
用法示例
复制数组到另一个数组
#include <algorithm> // copy函数的头文件
#include <iostream>int main() {int arr1[] = {1, 2, 3, 4, 5};int arr2[5]; // 确保arr2足够大,能够存放arr1的所有元素// 使用copy函数复制arr1到arr2std::copy(arr1, arr1 + 5, arr2);// 输出arr2的内容,验证复制是否成功for (int i = 0; i < 5; ++i) {std::cout << arr2[i] << " ";}std::cout << std::endl;return 0;
}
复制容器到另一个容器
#include <algorithm> // copy函数的头文件
#include <vector>
#include <iostream>int main() {std::vector<int> vec1 = {1, 2, 3, 4, 5};std::vector<int> vec2(5); // 确保vec2有足够的空间来存放vec1的所有元素// 使用copy函数复制vec1到vec2std::copy(vec1.begin(), vec1.end(), vec2.begin());// 输出vec2的内容,验证复制是否成功for (int elem : vec2) {std::cout << elem << " ";}std::cout << std::endl;return 0;
}
在使用copy函数时,请确保目标容器或数组有足够的空间来存放源序列中的所有元素,以避免越界访问。
此外,copy函数可以与其它标准库函数结合使用,例如与std::back_inserter结合来将元素复制到容器的末尾:
#include <algorithm> // copy函数的头文件
#include <vector>
#include <iterator> // std::back_inserter的头文件int main() {std::vector<int> vec1 = {1, 2, 3, 4, 5};std::vector<int> vec2;// 使用copy和back_inserter将vec1复制到vec2的末尾std::copy(vec1.begin(), vec1.end(), std::back_inserter(vec2));// 输出vec2的内容for (int elem : vec2) {std::cout << elem << " ";}std::cout << std::endl;return 0;
}
在这个例子中,std::back_inserter创建了一个插入迭代器,它能够在每次复制操作时自动扩展目标容器的容量。
4.2.5 ifstream的成员函数
在C++中,ifstream是输入文件流类,用于从文件中读取数据。它是std::basic_ifstream类的实例,专门用于处理字符类型为char的文件。以下是ifstream的一些常用成员函数及其用途的总结:
构造函数和析构函数
-
ifstream(): 默认构造函数。 -
ifstream(const char* filename, ios_base::openmode mode = ios_base::in): 构造函数,打开名为filename的文件。 -
~ifstream(): 析构函数,关闭文件流。
打开和关闭文件
-
open(const char* filename, ios_base::openmode mode = ios_base::in): 打开名为filename的文件。 -
close(): 关闭文件流。
文件状态检查
-
is_open(): 检查文件流是否成功打开。 -
operator!(): 检查文件流是否处于错误状态。 -
operator bool(): 返回文件流是否成功打开。
读写操作
-
get(): 从文件中读取一个字符。 -
getline(char* s, streamsize n): 从文件中读取一行,最多读取n-1个字符到字符串s中,并在末尾添加空字符。 -
read(char* s, streamsize n): 从文件中读取最多n个字符到s指向的字符数组中。 -
putback(char c): 将字符c放回输入流中。 -
unget(): 将最后一个读取的字符放回输入流中。
定位操作
-
seekg(streampos pos): 将读取位置设置为绝对位置pos。 -
seekg(streamoff off, ios_base::seekdir way): 将读取位置设置为相对于way指定的位置的偏移量off。 -
tellg(): 返回当前读取位置。
状态标志操作
-
clear(ios_base::iostate state = ios_base::goodbit): 清除错误标志,并设置流状态为state。 -
rdstate(): 返回当前的流状态。 -
setstate(ios_base::iostate state): 设置给定的流状态标志。
杂项操作
-
swap(ifstream& other): 交换两个文件流的内容。 -
rdbuf(): 返回与文件流关联的streambuf对象。
示例
以下是一个简单的示例,展示如何使用ifstream打开文件,读取内容,并检查状态:
#include <fstream>
#include <iostream>
#include <string>int main() {std::ifstream file("example.txt");if (!file.is_open()) {std::cerr << "Failed to open file." << std::endl;return 1;}std::string line;while (std::getline(file, line)) {std::cout << line << std::endl;}if (file.bad()) {std::cerr << "I/O error while reading." << std::endl;} else if (file.eof()) {std::cout << "Reached end of file." << std::endl;} else if (file.fail()) {std::cerr << "Non-integer data encountered." << std::endl;}file.close();return 0;
}
在使用ifstream时,应当注意文件打开失败时返回的错误处理,以及文件读取结束后的状态检查。此外,使用完文件流后,应当调用close()函数来关闭文件流。
4.2.6 seekg
在 C++ 中,ifstream 是一个用于读取文件的输入流类。seekg 是 ifstream 类的一个成员函数,用于设置文件的读取位置(即文件指针的位置)。这个函数对于随机访问文件中的数据尤其有用。以下是 seekg 的详细介绍及示例。
seekg 函数的基本用法
seekg 函数有几种重载形式,可以用于在文件中移动读取位置。它的基本原型如下:
std::ifstream& seekg(std::streampos pos); // 使用绝对位置
std::ifstream& seekg(std::streamoff off, std::ios_base::seekdir way); // 使用相对位置
-
std::streampos: 表示一个绝对的位置。 -
std::streamoff: 表示相对的位置,可以是正值或负值。 -
std::ios_base::seekdir: 用于指定偏移量的参考点,通常有三个选项:-
std::ios::beg: 文件的开头。 -
std::ios::cur: 当前的位置。 -
std::ios::end: 文件的末尾。
-
1. 使用绝对位置
当使用绝对位置时,可以直接指定想要读取的位置。
#include <iostream>
#include <fstream>int main() {std::ifstream file("example.txt");if (!file) {std::cerr << "Cannot open the file!" << std::endl;return 1;}file.seekg(5); // 将读取位置移动到第6个字节(从0开始计数)char ch;file.get(ch); // 读取一个字符std::cout << "Character at position 5: " << ch << std::endl;file.close();return 0;
}
2. 使用相对位置
使用相对位置时,可以指定相对于某个参考点的偏移量。这对于在文件中进行多次跳转非常有用。
#include <iostream>
#include <fstream>int main() {std::ifstream file("example.txt");if (!file) {std::cerr << "Cannot open the file!" << std::endl;return 1;}file.seekg(0); // 将读取位置移动到文件开头char ch;// 读取文件的前5个字符for (int i = 0; i < 5; ++i) {file.get(ch);std::cout << ch; // 输出前5个字符}std::cout << std::endl;// 移动到文件的第三个字符file.seekg(2, std::ios::beg); // 从文件开头开始的第3个字符file.get(ch);std::cout << "Character at position 2: " << ch << std::endl;// 移动到文件的倒数第二个字符file.seekg(-2, std::ios::end); // 从文件末尾开始file.get(ch);std::cout << "Character at second to last position: " << ch << std::endl;file.close();return 0;
}
3. 注意事项
-
在调用
seekg之前,确保文件已经打开,并且其状态正常,否则可能会引发错误。 -
在设置读取位置后,如果你希望读取数据,确保文件没有到达文件末尾。
-
调用
seekg后,文件的状态(如失败或结束)可能会改变,因此在读取之前应检查文件流的状态。
4. 结束
seekg 是 ifstream 类中一个非常有用的函数,能够为文件的随机访问提供灵活性。通过了解和实践 seekg 的用法,你可以更高效地处理文件操作,特别是在需要在大文件中定位特定数据时。
4.2.7 condition_variable(多线程)
std::condition_variable 是 C++11 引入的同步原语,用于在多线程编程中协调线程间的执行顺序,允许一个线程在某个条件满足之前进行等待,直到另一个线程通知它条件已经满足。通常与 std::mutex 或 std::unique_lock 配合使用,确保线程之间的同步和数据的一致性。
基本功能
condition_variable 主要提供两个操作:
-
wait:使当前线程等待,直到条件变量被通知。
-
notify_one:通知至少一个等待的线程。
-
notify_all:通知所有等待的线程。
头文件
#include <condition_variable>
#include <mutex>
使用示例
以下是一个使用 std::condition_variable 的简单示例:
#include <iostream>
#include <thread>
#include <condition_variable>
#include <mutex>std::mutex mtx;
std::condition_variable cv;
bool ready = false; // 控制线程执行顺序的条件变量// 工作线程
void print_id(int id) {std::unique_lock<std::mutex> lck(mtx);while (!ready) { // 如果条件不满足,等待通知cv.wait(lck);}// 条件满足,执行任务std::cout << "Thread " << id << " is running.\n";
}void go() {std::unique_lock<std::mutex> lck(mtx);ready = true; // 改变条件为truecv.notify_all(); // 通知所有等待的线程
}int main() {std::thread threads[10];for (int i = 0; i < 10; ++i) {threads[i] = std::thread(print_id, i);}std::cout << "Ready to go! Signaling threads to start...\n";go(); // 改变条件变量并通知for (auto& th : threads) {th.join(); // 等待所有线程执行完毕}return 0;
}
关键点
-
wait:
cv.wait(lck)会让当前线程在条件变量上等待,直到另一个线程调用notify_one()或notify_all()通知它。wait操作会自动释放mtx,并在等待时阻塞线程。当线程被唤醒时,它会重新获取mtx锁,确保数据一致性。 -
notify_one:通知至少一个等待的线程。如果有多个线程在等待,
notify_one()只会唤醒一个线程,其他线程仍然会保持等待状态。 -
notify_all:通知所有等待的线程,所有被唤醒的线程都会重新获取锁并继续执行。
注意事项
-
避免虚假唤醒:
wait被唤醒时,不意味着条件一定成立,因此通常会在wait外加一个循环,确保在被唤醒后条件仍然符合要求。while (!ready) { cv.wait(lck); // wait会自动释放锁,阻塞直到被通知 } -
**互斥量 (mutex)**:
std::condition_variable必须与std::mutex或std::unique_lock一起使用,来确保对共享数据的访问是同步的。
总结
std::condition_variable 是一个强大的工具,常用于线程间的协调和同步,特别是在生产者消费者问题等场景中非常有用。
4.2.8 回调函数和智能指针
在 C++ 中,回调函数和智能指针是两个重要的概念,它们在实现灵活、可维护和安全的程序时常常配合使用。下面分别解释这两个概念,并探讨它们如何结合使用。
1. 回调函数(Callback Functions)
回调函数是通过函数指针传递给其他函数的函数。这个被传递的函数会在特定的条件下由调用方执行。回调通常用于异步编程、事件驱动编程以及库设计中,以便通知调用者发生了某个事件。
回调函数的基本使用示例:
#include <iostream>// 定义回调函数类型
typedef void (*Callback)(int);void process_data(int value, Callback callback) {std::cout << "Processing value: " << value << std::endl;callback(value); // 调用回调函数
}void print_result(int value) {std::cout << "Callback called with value: " << value << std::endl;
}int main() {process_data(42, print_result); // 传递回调函数return 0;
}
在上面的代码中,process_data 函数接受一个整数值和一个回调函数 callback,并在处理数据后调用回调函数。
2. 智能指针(Smart Pointers)
智能指针是 C++ 标准库提供的一种自动管理动态内存的工具,它们通过 RAII(资源获取即初始化)模式来管理对象的生命周期。常见的智能指针有:
-
std::unique_ptr:独占所有权,不能复制,只能转移所有权。 -
std::shared_ptr:共享所有权,多个指针可以指向同一个对象,引用计数会跟踪指向该对象的指针数量。 -
std::weak_ptr:与std::shared_ptr配合使用,防止循环引用。
智能指针示例:
#include <iostream>
#include <memory>void print_message(std::shared_ptr<std::string> msg) {std::cout << *msg << std::endl;
}int main() {auto msg = std::make_shared<std::string>("Hello, smart pointers!");print_message(msg);return 0;
}
在这个示例中,std::shared_ptr 被用来管理字符串对象的生命周期,确保对象在不再使用时被自动销毁。
3. 回调函数与智能指针的结合
在一些复杂的场景中,回调函数和智能指针可能会一起使用。比如,当你在回调函数中传递智能指针时,可以确保对象在回调期间被正确管理,避免手动内存管理错误(如内存泄漏或悬空指针)。
回调函数与智能指针结合的示例:
#include <iostream>
#include <memory>// 定义回调函数类型,接收一个智能指针作为参数
typedef void (*Callback)(std::shared_ptr<std::string>);void process_data(std::shared_ptr<std::string> msg, Callback callback) {std::cout << "Processing data..." << std::endl;callback(msg); // 调用回调函数
}void print_message(std::shared_ptr<std::string> msg) {std::cout << *msg << std::endl;
}int main() {auto msg = std::make_shared<std::string>("Using smart pointers with callback!");process_data(msg, print_message);return 0;
}
关键点:
-
回调函数传递智能指针:
在回调函数中传递std::shared_ptr或std::unique_ptr可以确保对象的生命周期由智能指针管理,而不需要显式地手动管理内存。 -
std::shared_ptr在回调中使用:
使用std::shared_ptr作为回调函数的参数可以确保多个地方(比如多个回调)对同一对象的引用是安全的,并且在不需要的时候自动销毁对象。 -
防止悬空指针和内存泄漏:
当回调函数在异步或多线程环境中使用时,智能指针提供了内存管理的自动化,避免了手动管理内存带来的错误,比如悬空指针、内存泄漏等问题。
4. 需要注意的问题
-
循环引用问题:如果两个或更多的智能指针之间相互引用(例如
std::shared_ptr引用std::shared_ptr),可能会导致引用计数永远不为零,从而导致内存泄漏。在这种情况下,可以使用std::weak_ptr来打破循环引用。 -
线程安全:如果回调函数在多线程中使用,确保智能指针在多个线程中共享时是线程安全的。
std::shared_ptr是线程安全的,只要没有同时修改相同的对象。
总结
回调函数和智能指针是 C++ 中非常重要的两种工具,回调函数提供了一种灵活的机制来响应事件或条件变化,而智能指针则提供了自动管理内存的能力,减少了内存管理错误。它们的结合可以帮助编写更加安全、可维护的代码,尤其在复杂的事件驱动或异步编程中非常有用。
4.2.9 c++中的线程
C++中的线程总结和用法介绍
在 C++ 中,线程(std::thread)是实现并发编程的核心工具之一,提供了通过多核处理器提高程序执行效率的能力。C++11 引入了标准库中的多线程支持,std::thread 类成为了创建和管理线程的主要方式。以下是对 C++ 中线程的总结和常用用法介绍。
1. 创建线程
要在 C++ 中创建线程,可以使用 std::thread 类。std::thread 提供了通过函数、成员函数、函数对象或 Lambda 表达式创建线程的方式。
1.1 通过函数创建线程
#include <iostream>
#include <thread>void print_hello() {std::cout << "Hello from thread!" << std::endl;
}int main() {std::thread t(print_hello); // 创建线程t.join(); // 等待线程结束return 0;
}
-
std::thread的构造函数接收一个可调用对象(如普通函数、Lambda、函数对象等)并在新线程中执行它。 -
join()用于等待线程完成。另一种选择是调用detach(),将线程分离,允许它在后台执行,但不能再与主线程同步。
1.2 通过 Lambda 表达式创建线程
#include <iostream>
#include <thread>int main() {std::thread t([](){std::cout << "Hello from thread using Lambda!" << std::endl;});t.join();return 0;
}
2. 线程管理
-
**
join()**:等待线程完成。如果一个线程调用了join(),主线程会等待该线程完成执行,然后继续执行。join()在主线程调用后,确保线程的正确执行顺序。 -
**
detach()**:将线程与当前线程分离,线程开始独立执行,不需要等待它完成。使用detach()后,线程将变为“守护线程”,无法再通过join()获取线程的结束状态。
#include <iostream>
#include <thread>void print_message() {std::this_thread::sleep_for(std::chrono::seconds(1));std::cout << "Message from detached thread!" << std::endl;
}int main() {std::thread t(print_message);t.detach(); // 分离线程std::cout << "Main thread continues..." << std::endl;std::this_thread::sleep_for(std::chrono::seconds(2)); // 给分离线程一些时间return 0;
}
3. 线程参数传递
可以向线程传递参数,传递的参数会被拷贝到新线程中。可以通过标准的函数调用方式传递多个参数。
#include <iostream>
#include <thread>void print_sum(int a, int b) {std::cout << "Sum: " << a + b << std::endl;
}int main() {std::thread t(print_sum, 5, 7); // 向线程传递参数t.join();return 0;
}
4. 线程同步与互斥
多个线程访问共享资源时,可能会导致竞态条件(race conditions),从而引发未定义的行为。C++ 提供了多种同步机制来避免这种情况。
4.1 使用 std::mutex 锁定共享资源
std::mutex 提供了一种机制,确保同一时刻只有一个线程可以访问某一共享资源。通常与 std::lock_guard 或 std::unique_lock 一起使用来管理锁。
#include <iostream>
#include <thread>
#include <mutex>std::mutex mtx;void print_numbers(int id) {std::lock_guard<std::mutex> lock(mtx); // 锁定mutexstd::cout << "Thread " << id << " is running." << std::endl;
}int main() {std::thread t1(print_numbers, 1);std::thread t2(print_numbers, 2);t1.join();t2.join();return 0;
}
-
std::lock_guard是一种自动加锁和解锁的机制,构造时加锁,析构时解锁。这样即使发生异常也能确保锁被释放。
4.2 使用 std::unique_lock
std::unique_lock 提供了比 std::lock_guard 更灵活的功能,可以延迟加锁、提前解锁等。
#include <iostream>
#include <thread>
#include <mutex>std::mutex mtx;void print_numbers(int id) {std::unique_lock<std::mutex> lock(mtx);std::cout << "Thread " << id << " is running." << std::endl;// 也可以在这里手动释放锁
}int main() {std::thread t1(print_numbers, 1);std::thread t2(print_numbers, 2);t1.join();t2.join();return 0;
}
5. 条件变量与线程通信
有时线程需要等待某个条件成立才能继续执行。C++ 提供了 std::condition_variable 来实现线程之间的通信。
5.1 使用 std::condition_variable
#include <iostream>
#include <thread>
#include <mutex>
#include <condition_variable>std::mutex mtx;
std::condition_variable cv;
bool ready = false;void print_id(int id) {std::unique_lock<std::mutex> lck(mtx);while (!ready) cv.wait(lck);std::cout << "Thread " << id << " is running." << std::endl;
}void go() {std::unique_lock<std::mutex> lck(mtx);ready = true;cv.notify_all(); // 通知所有等待的线程
}int main() {std::thread threads[10];for (int i = 0; i < 10; ++i) {threads[i] = std::thread(print_id, i);}std::cout << "Ready to go!" << std::endl;go();for (auto& th : threads) {th.join();}return 0;
}
6. 线程池
虽然 C++ 标准库没有提供直接的线程池实现,但可以通过使用 std::thread 和 std::queue 等配合实现一个简单的线程池。线程池是通过预创建多个线程来处理任务的方式,避免每次都创建新线程,提高性能。
7. 线程安全注意事项
-
避免死锁:多个线程同时锁定多个互斥量时,可能导致死锁。可以使用
std::lock来避免死锁。 -
避免共享数据竞争:在多个线程同时访问共享数据时,必须使用互斥量(如
std::mutex)来保护数据,避免数据竞争。
8. 总结
C++ 提供了强大的线程功能,通过 std::thread、std::mutex、std::condition_variable 等工具,可以方便地实现并发编程。在使用线程时需要注意:
-
正确管理线程生命周期,避免资源泄漏。
-
使用同步机制来防止竞态条件。
-
适时使用线程池等技术来提高效率。
4.3.0 线程的接口
在C++中,线程的相关接口主要是通过 <thread> 头文件中的 std::thread 类提供的。下面是C++线程接口的总结:
1. std::thread 类
std::thread 是C++11引入的标准库类,用于创建和管理线程。它提供了如下功能:
创建线程
线程可以通过构造 std::thread 对象来创建,构造函数接受可调用对象(如函数指针、Lambda表达式或成员函数)及其参数。
#include <iostream>
#include <thread>void task() {std::cout << "Thread is running." << std::endl;
}int main() {std::thread t(task); // 创建线程t.join(); // 等待线程结束return 0;
}
线程的控制:
-
join(): 等待线程执行完毕并退出,调用者会阻塞直到线程结束。如果一个线程在join()前被销毁,则会抛出异常。 -
detach(): 使线程与主线程分离,线程会在后台执行,不能再通过join()来等待它。
std::thread t(task);
t.detach(); // 不再控制线程,线程在后台运行
2. 线程的同步(C++11起)
线程同步是避免多个线程同时访问共享数据时发生数据竞争的一种手段。常用的同步机制包括:
std::mutex
std::mutex 用于保护共享资源的访问,避免多个线程同时访问同一资源。
#include <iostream>
#include <thread>
#include <mutex>std::mutex mtx; // 全局互斥锁void print_hello() {mtx.lock();std::cout << "Hello from thread" << std::endl;mtx.unlock();
}int main() {std::thread t1(print_hello);std::thread t2(print_hello);t1.join();t2.join();return 0;
}
std::lock_guard
std::lock_guard 是一种RAII风格的锁,它会在作用域结束时自动释放锁,避免了手动解锁的麻烦。
void print_hello() {std::lock_guard<std::mutex> guard(mtx);std::cout << "Hello from thread" << std::endl;
}
std::unique_lock
std::unique_lock 提供更大的灵活性,支持延迟锁定、提前解锁等功能。
std::unique_lock<std::mutex> lock(mtx);
// 线程可以在此作用域内安全地访问共享资源
3. 条件变量
std::condition_variable 允许线程在某个条件成立时才继续执行,用于实现线程间的等待和通知机制。
std::condition_variable 的基本用法:
#include <iostream>
#include <thread>
#include <mutex>
#include <condition_variable>std::mutex mtx;
std::condition_variable cv;
bool ready = false;void print_id(int id) {std::unique_lock<std::mutex> lck(mtx);while (!ready) cv.wait(lck);std::cout << "Thread " << id << '\n';
}void go() {std::unique_lock<std::mutex> lck(mtx);ready = true;cv.notify_all(); // 通知所有等待的线程
}int main() {std::thread threads[10];for (int i = 0; i < 10; ++i)threads[i] = std::thread(print_id, i);std::cout << "10 threads ready to race...\n";go(); // 启动所有线程for (auto& th : threads) th.join();return 0;
}
4. std::async 和 std::future
std::async 用于启动异步任务,它返回一个 std::future 对象,可以用来获取线程的返回值或等待线程完成。
#include <iostream>
#include <future>int find_the_answer() {std::this_thread::sleep_for(std::chrono::seconds(2));return 42;
}int main() {std::future<int> the_answer = std::async(std::launch::async, find_the_answer);std::cout << "The answer is: " << the_answer.get() << std::endl; // 阻塞直到任务完成return 0;
}
5. std::this_thread
std::this_thread 提供与当前线程相关的功能:
-
std::this_thread::sleep_for():使当前线程休眠一段时间。 -
std::this_thread::sleep_until():使当前线程休眠直到指定的时间。 -
std::this_thread::get_id():获取当前线程的ID。 -
std::this_thread::yield():使当前线程让出CPU时间片,给其他线程运行。
#include <iostream>
#include <thread>
#include <chrono>void task() {std::cout << "Thread started, sleeping for 1 second..." << std::endl;std::this_thread::sleep_for(std::chrono::seconds(1));std::cout << "Thread resumed!" << std::endl;
}int main() {std::thread t(task);t.join();return 0;
}
6. std::thread::hardware_concurrency
std::thread::hardware_concurrency() 可以返回当前系统支持的并行线程数,通常是CPU的核心数。
#include <iostream>
#include <thread>int main() {unsigned int num_threads = std::thread::hardware_concurrency();std::cout << "Number of hardware threads: " << num_threads << std::endl;return 0;
}
总结
C++的线程接口通过 std::thread 提供了基本的线程管理能力,并通过 std::mutex、std::condition_variable、std::future 等提供了线程同步和通信的功能。通过这些接口,C++支持多线程并行计算,允许开发者在高效、线程安全的环境中编程。
4.3.1 bind绑定
在C++中,bind 是一个非常有用的工具,它主要来自于 C++11 标准中的 <functional> 头文件。它的主要功能是将函数或可调用对象与其部分参数绑定在一起,生成一个新的可调用对象。这可以增强代码的灵活性和可读性。
std::bind 的基本用法
-
引入头文件:
在使用std::bind之前,需要包含<functional>头文件#include <functional> -
基本语法:
#include <iostream> #include <functional>void func(int a, int b) {std::cout << "a: " << a << ", b: " << b << std::endl; }int main() {auto boundFunc = std::bind(func, 10, std::placeholders::_1);boundFunc(20); // 输出: a: 10, b: 20return 0; }在上面的例子中,
func是一个接受两个整数的函数。我们使用std::bind将第一个参数绑定为 10,并使用std::placeholders::_1占位符指定第二个参数。
std::placeholders
在使用 std::bind 时,如果你想为函数的某些参数保留可变性,可以使用 std::placeholders。这些占位符允许你定义绑定函数时的参数位置。
-
_1,_2,_3, ... 代表可绑定函数的参数的位置。
具体示例
-
绑定多个参数:
#include <iostream> #include <functional>void add(int a, int b, int c) {std::cout << "Result: " << a + b + c << std::endl; }int main() {auto boundAdd = std::bind(add, 1, 2, std::placeholders::_1);boundAdd(3); // 输出: Result: 6return 0; } -
不同顺序的参数绑定:
#include <iostream> #include <functional>void concat(std::string a, std::string b, std::string c) {std::cout << a + b + c << std::endl; }int main() {auto boundConcat = std::bind(concat, "Hello, ", std::placeholders::_1, "!");boundConcat("World"); // 输出: Hello, World!return 0; }
结合 STL 容器使用
std::bind 常常与标准库算法(如 std::for_each)结合使用,来应用用户定义的函数。
#include <iostream>
#include <vector>
#include <algorithm>
#include <functional>void print(int x) {std::cout << x << " ";
}int main() {std::vector<int> numbers = {1, 2, 3, 4, 5};// 使用 std::bind 来绑定 print 函数auto boundPrint = std::bind(print, std::placeholders::_1);std::for_each(numbers.begin(), numbers.end(), boundPrint);return 0; // 输出: 1 2 3 4 5
}
注意事项
-
性能开销:虽然
std::bind非常灵活,但在某些情况下,它的性能可能略逊色于直接使用 lambda 表达式。对于简单的参数绑定,使用 lambda 可能更高效。 -
类型安全性:
std::bind的类型是在编译时确定的,这可能导致一些类型不匹配的错误在编译时被捕获。 -
语义明确性:有些程序员认为使用 lambda 表达式的可读性和明确性可能优于使用
std::bind。
总结
std::bind 是 C++ 中非常有用的工具,适合用于将函数与部分参数绑定在一起。通过占位符的使用,你可以灵活地组装你的函数调用,从而提高代码的复用性和可读性。然而,根据具体情况,选择使用 std::bind 还是 lambda 表达式应根据性能和可读性需求做出权衡。
5. 相关技术知识补充
5.1 不定参函数
- 在初学C语⾔的时候,我们都⽤过printf函数进⾏打印。其中printf函数就是⼀个不定参函数,在函数内部可以根据格式化字符串中格式化字符分别获取不同的参数进⾏数据的格式化。
- ⽽这种不定参函数在实际的使⽤中也⾮常多⻅,在这⾥简单做⼀介绍:
不定参宏函数
打印文件名和行号
#include<stdio.h>int main()
{printf("[%s-%d]%s和%s---\n",__FILE__,__LINE__,"文件名","和行数");return 0;
}
宏函数
#include<stdio.h>#define LOG(fmt, ...) printf("[%s-%d]" fmt, __FILE__, __LINE__, __VA_ARGS__);int main()
{// printf("[%s-%d]%s和%s---\n",__FILE__,__LINE__,"文件名","和行数");LOG("%s和%s---\n","文件名","和行数");return 0;
}
直接打印一个会有问题,不带参数会出错

两个 ## 告诉编译器,一旦不定参为空,则取消前面的逗号
#include<stdio.h>#define LOG(fmt, ...) printf("[%s-%d]" fmt, __FILE__, __LINE__, ##__VA_ARGS__);int main()
{// printf("[%s-%d]%s和%s---\n",__FILE__,__LINE__,"文件名","和行数");LOG("%s和%s---\n","文件名","和行数");LOG("ljw\n");return 0;
}
c语言中不定参函数的使用,不定参数据的访问
都是宏

不定参的访问

获得不定参的第一个的地址

void printNum(int count, ...)
{va_list ap;va_start(ap, count);for(int i = 0; i < count; i++){int num = va_arg(ap, int);printf("param[%d]:%d\n", i, num);}va_end(ap);
}

#include<stdio.h>
#include <stdarg.h>
#define LOG(fmt, ...) printf("[%s-%d]" fmt, __FILE__, __LINE__, ##__VA_ARGS__);void printNum(int count, ...)
{va_list ap;va_start(ap, count);for(int i = 0; i < count; i++){int num = va_arg(ap, int);printf("param[%d]:%d\n", i, num);}va_end(ap);
}int main()
{// printf("[%s-%d]%s和%s---\n",__FILE__,__LINE__,"文件名","和行数");LOG("%s和%s---\n","文件名","和行数");LOG("ljw\n");printNum(3, 1,2,3);printNum(2, 1,2);return 0;
}模拟一个printf
用到了vasprintf
必须在最上面_GUN_SOURCE


free头文件




C++风格不定参函数
sizeof求不定参的数量和完美转发(传进来的是左值就是左,右就是右)

#include<iostream>
using namespace std;template<typename T, typename ...Args>
void xprintf(T& v,Args &&...args)
{cout<<v;if((sizeof ...args) >0){xprintf(forward<Args>(args)...);}else{cout<< endl;}
}int main()
{xprintf("%s\n","你好");return 0;
}测试

改错
typename ...Args不定参的参数包类型
#include<iostream>
using namespace std;void xprintf()
{cout<< endl;
}
template<typename T, typename ...Args>
void xprintf(T& v,Args &&...args)
{cout<<v;if((sizeof ...(args)) >0){xprintf(forward<Args>(args)...);}else{xprintf();}
}
int main()
{xprintf("你好");return 0;
}

5.2 设计模式
设计模式是前辈们对代码开发经验的总结,是解决特定问题的⼀系列套路。它不是语法规定,⽽是⼀ 套⽤来提⾼代码可复⽤性、可维护性、可读性、稳健性以及安全性的解决⽅案。
六⼤原则:
• 单⼀职责原则(Single Responsibility Principle);
◦ 类的职责应该单⼀,⼀个⽅法只做⼀件事。职责划分清晰了,每次改动到最⼩单位的⽅法或类。
◦ 使⽤建议:两个完全不⼀样的功能不应该放⼀个类中,⼀个类中应该是⼀组相关性很⾼的函数、数据的封装
◦ ⽤例:⽹络聊天:⽹络通信&聊天,应该分割成为⽹络通信类&聊天类
• 开闭原则(Open Closed Principle);
◦ 对扩展开放,对修改封闭
◦ 使⽤建议:对软件实体的改动,最好⽤扩展⽽⾮修改的⽅式。
◦ ⽤例:超时卖货:商品价格---不是修改商品的原来价格,⽽是新增促销价格。
• ⾥⽒替换原则(Liskov Substitution Principle);
◦ 通俗点讲,就是只要⽗类能出现的地⽅,⼦类就可以出现,⽽且替换为⼦类也不会产⽣任何错 误或异常。
◦ 在继承类时,务必重写⽗类中所有的⽅法,尤其需要注意⽗类的protected⽅法,⼦类尽量不要 暴露⾃⼰的public⽅法供外界调⽤。
◦ 使⽤建议:⼦类必须完全实现⽗类的⽅法,孩⼦类可以有⾃⼰的个性。覆盖或实现⽗类的⽅法 时,输⼊参数可以被放⼤,输出可以缩⼩
◦ ⽤例:跑步运动员类-会跑步,⼦类⻓跑运动员-会跑步且擅⻓⻓跑,⼦类短跑运动员-会跑步且 擅⻓短跑
• 依赖倒置原则(Dependence Inversion Principle);
◦ ⾼层模块不应该依赖低层模块,两者都应该依赖其抽象.不可分割的原⼦逻辑就是低层模式,原 ⼦逻辑组装成的就是⾼层模块。
◦ 模块间依赖通过抽象(接⼝)发⽣,具体类之间不直接依赖
◦ 使⽤建议:每个类都尽量有抽象类,任何类都不应该从具体类派⽣。尽量不要重写基类的⽅ 法。结合⾥⽒替换原则使⽤。
◦ ⽤例:奔驰⻋司机类--只能开奔驰;司机类--给什么⻋,就开什么⻋;开⻋的⼈:司机--依 赖于抽象
• 迪⽶特法则(Law of Demeter),⼜叫“最少知道法则”;
◦ 尽量减少对象之间的交互,从⽽减⼩类之间的耦合。⼀个对象应该对其他对象有最少的了解。 对类的低耦合提出了明确的要求:
▪ 只和直接的朋友交流,朋友之间也是有距离的。⾃⼰的就是⾃⼰的(如果⼀个⽅法放在本类 中,既不增加类间关系,也对本类不产⽣负⾯影响,那就放置在本类中)。
◦ ⽤例:⽼师让班⻓点名--⽼师给班⻓⼀个名单,班⻓完成点名勾选,返回结果,⽽不是班⻓点 名,⽼师勾选
• 接⼝隔离原则(Interface Segregation Principle);
◦ 客⼾端不应该依赖它不需要的接⼝,类间的依赖关系应该建⽴在最⼩的接⼝上
◦ 使⽤建议:接⼝设计尽量精简单⼀,但是不要对外暴露没有实际意义的接⼝。
◦ ⽤例:修改密码,不应该提供修改用户信息接⼝,⽽就是单⼀的最⼩修改密码接⼝,更不要暴露数据库操作
从整体上来理解六⼤设计原则,可以简要的概括为⼀句话,⽤抽象构建框架,⽤实现扩展细节,具体到每⼀条设计原则,则对应⼀条注意事项:
• 单⼀职责原则告诉我们实现类要职责单⼀;
• ⾥⽒替换原则告诉我们不要破坏继承体系;
• 依赖倒置原则告诉我们要⾯向接⼝编程;
• 接⼝隔离原则告诉我们在设计接⼝的时候要精简单⼀;
• 迪⽶特法则告诉我们要降低耦合;
• 开闭原则是总纲,告诉我们要对扩展开放,对修改关闭。
单例模式
⼀个类只能创建⼀个对象,即单例模式,该设计模式可以保证系统中该类只有⼀个实例,并提供⼀个访问它的全局访问点,该实例被所有程序模块共享。⽐如在某个服务器程序中,该服务器的配置信息存放在⼀个⽂件中,这些配置数据由⼀个单例对象统⼀读取,然后服务进程中的其他对象再通过这个单例对象获取这些配置信息,这种⽅式简化了在复杂环境下的配置管理。
单例模式有两种实现模式:饿汉模式和懒汉模式
• 饿汉模式:
程序启动时就会创建⼀个唯⼀的实例对象。因为单例对象已经确定,所以⽐较适⽤于多线程环境中,多线程获取单例对象不需要加锁,可以有效的避免资源竞争,提⾼性能。
实现:

![]()
在类内只是一个声明
在类外实例化 (启动时就会创建⼀个唯⼀的实例对象)

测试的:没有调用(开始就创建了)
class Singleton
{
private:static Singleton _slt;Singleton(int data = 1) :_data(data){cout<< _data << endl;}~Singleton() {}Singleton(const Singleton& slt) = delete;
public:static Singleton &getInstance(){return _slt;}
private:int _data;
};
Singleton Singleton::_slt;int main()
{//Singleton::getInstance();return 0;
}就是说不管你将来用不用,程序启动时就创建一个唯一的实例对象。
// 饿汉模式
// 优点:简单
// 缺点:可能会导致进程启动慢(都不知道是在初始化还是系统挂了),且如果有多个单例类对象实例启动顺序不确定。

第一步:构造函数私有(不能随意创建)

把map<string,string>设为私有

创建static变量

类外声明

2、提供获取单例对象的接口函数
创建对象
问题(需要防止拷贝)
然后就会出现一个问题,没有绝对防死可以拷贝构造对象
Singleton copy(Singleton::GetInstance());
第三步防拷贝


添加数据并打印


饿汉模式:一开始(main函数之前)就创建单例对象
静态的在main之前就创建了1、如果单例对象初始化内容很多,影响启动速度2、如果两个单例类,互相有依赖关系。 假设有A B两个单例类,要求A先创建,B再创建,B的初始化创建依赖A
class Singleton
{
public:// 2、提供获取单例对象的接口函数static Singleton& GetInstance()//instance是实例的意思{return _sinst;}//覆盖型的Addvoid Add(const pair<string, string>& kv){_dict[kv.first] = kv.second;}void Print(){for (auto& e : _dict){cout << e.first << ":" << e.second << endl;}cout << endl;}private:// 1、构造函数私有Singleton(){// ...}// 3、防拷贝Singleton(const Singleton& s) = delete;Singleton& operator=(const Singleton& s) = delete;//使map全局只有唯一实例map<string, string> _dict;// ...//可以创建自己类型的对象,也不会套娃,因为静态的在静态区//静态的在main之前就创建了static Singleton _sinst;
};Singleton Singleton::_sinst;int main()
{//保证创建的都是一个对象//三个地址都一样,说明三个创建的是同一个cout << &Singleton::GetInstance() << endl;cout << &Singleton::GetInstance() << endl;cout << &Singleton::GetInstance() << endl;Singleton copy(Singleton::GetInstance());//添加数据Singleton::GetInstance().Add({ "1111","2222" });Singleton::GetInstance().Print();return 0;
}如果这个单例对象在多线程高并发环境下频繁使用,性能要求较高,那么显然使用饿汉模式来避 免资源竞争,提高响应速度更好。
懒汉模式
- 1、如果单例对象初始化内容很多,影响启动速度
- 2、如果两个单例类,互相有依赖关系。
- 假设有A B两个单例类,要求A先创建,B再创建,B的初始化创建依赖A,就没法用饿汉了,然后就有了下面的懒汉
懒汉模式:第⼀次使⽤要使⽤单例对象的时候创建实例对象。如果单例对象构造特别耗时或者耗费济源(加载插件、加载⽹络资源等),可以选择懒汉模式,在第⼀次使⽤的时候才创建对象。
◦ 这⾥介绍的是《Effective C++》⼀书作者Scott Meyers提出的⼀种更加优雅简便的单例模式 Meyers'Singleton in C++。
◦ C++11 Static local variables 特性以确保C++11起,静态变量将能够在满⾜thread-safe的前提 下唯⼀地被构造和析构
懒汉
优点:第一次使用实例对象时,创建对象。进程启动无负载。多个单例实例启动顺序自由控制。
缺点:复杂
懒汉用的static指针,main之前创建一个指针不耽误时间
顺序可以随便控制
单例一般不用智能指针,所以需要显示释放
特殊场景:1、中途需要显示释放 2、程序结束时,需要做一些特殊动作(如持久化)
改进






//懒汉用的static指针,main之前创建一个指针不耽误时间
//顺序可以随便控制
//单例一般不用智能指针,所以需要显示释放
// 特殊场景:1、中途需要显示释放 2、程序结束时,需要做一些特殊动作(如持久化)namespace lazy
{class Singleton{public://改进::2// 2、提供获取单例对象的接口函数static Singleton& GetInstance(){if (_psinst == nullptr){// 第一次调用GetInstance的时候创建单例对象_psinst = new Singleton;}return *_psinst;}//改进::3// 一般单例不用释放。// 特殊场景:1、中途需要显示释放 2、程序结束时,需要做一些特殊动作(如持久化)static void DelInstance(){if (_psinst){delete _psinst;_psinst = nullptr;}}void Add(const pair<string, string>& kv){_dict[kv.first] = kv.second;}void Print(){for (auto& e : _dict){cout << e.first << ":" << e.second << endl;}cout << endl;}//改进::5,因为一个单例显示释放一次多个就要多次delete太麻烦//所以有了GC//用智能指针又没办法显示释放class GC{public:~GC(){lazy::Singleton::DelInstance();}};private:// 1、构造函数私有Singleton(){// ...}//程序结束后,把东西写入文件中(可持久化)~Singleton(){cout << "~Singleton()" << endl;//改进::4// map数据写到文件中,可持久化FILE* fin = fopen("map.txt", "w");for (auto& e : _dict){fputs(e.first.c_str(), fin);fputs(":", fin);fputs(e.second.c_str(), fin);fputs("\n", fin);}}// 3、防拷贝Singleton(const Singleton& s) = delete;Singleton& operator=(const Singleton& s) = delete;map<string, string> _dict;// ...//改进::这里弄一个指针static Singleton* _psinst;//改进::5static GC _gc;};//类外定义Singleton* Singleton::_psinst = nullptr;//改进::5Singleton::GC Singleton::_gc;
}
int main()
{//Singleton s1;//Singleton s2;cout << &lazy::Singleton::GetInstance() << endl;cout << &lazy::Singleton::GetInstance() << endl;cout << &lazy::Singleton::GetInstance() << endl;//Singleton copy(Singleton::GetInstance());lazy::Singleton::GetInstance().Add({ "xxx", "111" });lazy::Singleton::GetInstance().Add({ "yyy", "222" });lazy::Singleton::GetInstance().Add({ "zzz", "333" });lazy::Singleton::GetInstance().Add({ "abc", "333" });lazy::Singleton::GetInstance().Print();//lazy::Singleton::DelInstance();lazy::Singleton::GetInstance().Add({ "abc", "444" });lazy::Singleton::GetInstance().Print();//lazy::Singleton::DelInstance();return 0;
} C++11之后才支持的
C++11之后才支持的


测试:没调用时

加调用(用的时候创建)


⼯⼚模式
⼯⼚模式是⼀种创建型设计模式,它提供了⼀种创建对象的最佳⽅式。在⼯⼚模式中,我们创建对象时不会对上层暴露创建逻辑,⽽是通过使⽤⼀个共同结构来指向新创建的对象,以此实现创建-使⽤的分离。
⼯⼚模式可以分为:
• 简单⼯⼚模式:简单⼯⼚模式实现由⼀个⼯⼚对象通过类型决定创建出来指定产品类的实例。假设有个⼯⼚能⽣产出⽔果,当客⼾需要产品的时候明确告知⼯⼚⽣产哪类⽔果,⼯⼚需要接收⽤⼾提供的类别信息,当新增产品的时候,⼯⼚内部去添加新产品的⽣产⽅式
简单⼯⼚模式:通过参数控制可以⽣产任何产品
优点:
简单粗暴,直观易懂。使⽤⼀个⼯⼚⽣产同⼀等级结构下的任意产品
缺点:
1. 所有东西⽣产在⼀起,产品太多会导致代码量庞⼤
2. 开闭原则遵循(开放拓展,关闭修改)的不是太好,要新增产品就必须修改⼯⼚⽅法。
建立一个水果工厂
先先一个纯虚数

苹果和香蕉来继承
class Apple :public Fruit
{
public:void name() override{cout << "我是一个苹果\n";}
};
class Banana :public Fruit
{
public:void name() override{cout << "我是一个香蕉\n";}
};在创建一个工厂(用智能指针进行管理)创造接口设置为静态,全局可以调用
class FruitFactory
{
public:static shared_ptr<Fruit> create(const string &name){if (name == "苹果"){//返回Apple一个匿名对象return make_shared<Apple>();}if (name == "香蕉"){return make_shared<Banana>();}}
};调用
int main()
{shared_ptr<Fruit> fruit = FruitFactory::create("苹果");fruit->name();fruit = FruitFactory::create("香蕉");fruit->name();return 0;
}
这个模式的结构和管理产品对象的⽅式⼗分简单,但是它的扩展性⾮常差,当我们需要新增产品的时候,就需要去修改⼯⼚类新增⼀个类型的产品创建逻辑,违背了开闭原则。
改进一下 (改进了开闭原则)
• ⼯⼚⽅法模式:在简单⼯⼚模式下新增多个⼯⼚,多个产品,每个产品对应⼀个⼯⼚。假设现在有A、B两种产品,则开两个⼯⼚,⼯⼚A负责⽣产产品A,⼯⼚B负责⽣产产品B,⽤户只知道产品的⼯⼚名,⽽不知道具体的产品信息,⼯⼚不需要再接收客户的产品类别,⽽只负责⽣产产品。
把工厂抽象化
class FruitFactory
{
public:virtual shared_ptr<Fruit> create() = 0;
};苹果香蕉工厂
class AppleFactory :public FruitFactory
{
public:shared_ptr<Fruit> create() override{return make_shared<Apple>();}
};
class BananaFactory :public FruitFactory
{
public:shared_ptr<Fruit> create() override{return make_shared<Banana>();}
};再这样调用就会出错

正确做法
(扩展一下虚函数和纯虚函数的区别,这里的ff1等价于ff)

(扩展一下reset)
⼯⼚⽅法模式每次增加⼀个产品时,都需要增加⼀个具体产品类和⼯⼚类,这会使得系统中类的个数成倍增加,在⼀定程度上增加了系统的耦合度
抽象工厂模式(开闭原则没有遵循)
抽象⼯⼚模式:⼯⼚⽅法模式通过引⼊⼯⼚等级结构,解决了简单⼯⼚模式中⼯⼚类职责太重的问题,但由于⼯⼚⽅法模式中的每个⼯⼚只⽣产⼀类产品,可能会导致系统中存在⼤量的⼯⼚类,势 必会增加系统的开销。此时,我们可以考虑将⼀些相关的产品组成⼀个产品族(位于不同产品等级结构中功能相关联的产品组成的家族),由同⼀个⼯⼚来统⼀⽣产,这就是抽象⼯⼚模式的基本思想。
设计两个产品,水果和动物
class Fruit
{
public:virtual void name() = 0;
};
class Apple :public Fruit
{
public:void name() override{cout << "我是一个苹果\n";}
};
class Banana :public Fruit
{
public:void name() override{cout << "我是一个香蕉\n";}
};class Animal
{
public:virtual void name() = 0;
};
class Lamp :public Animal
{
public:void name() override{cout << "我是一个山羊\n";}
};
class Dog :public Animal
{
public:void name() override{cout << "我是一个土狗\n";}
};再定一个抽象工厂
class Factory
{
public:virtual shared_ptr<Fruit> getFruit(const string& name) = 0;virtual shared_ptr<Animal> getAnimal(const string& name) = 0;
};水果工厂
class FruitFactory : public Factory
{
public:shared_ptr<Animal> getAnimal(const string& name){//返回一个空return shared_ptr<Animal>();}shared_ptr<Fruit> getFruit(const string& name){if (name == "苹果"){return make_shared<Apple>();}if (name == "香蕉"){return make_shared<Banana>();}}
};动物工厂
class AnimalFactory : public Factory
{
public:shared_ptr<Fruit> getFruit(const string& name){//返回一个空return shared_ptr<Fruit>();}shared_ptr<Animal> getAnimal(const string& name){if (name == "土狗"){return make_shared<Dog>();}if (name == "山羊"){return make_shared<Lamp>();}}
};再弄一个工厂的生产者,生产不同的工厂,在通过不同的工厂生产各种不同品类的产品
class FactoryProducer
{
public:static shared_ptr<Factory> create(const string& name){if (name == "水果"){return make_shared<FruitFactory>();}if (name == "动物"){return make_shared<AnimalFactory>();}}
};main中

抽象⼯⼚模式适⽤于⽣产多个⼯⼚系列产品衍⽣的设计模式,增加新的产品等级结构复杂,需要对原有系统进⾏较⼤的修改,甚⾄需要修改抽象层代码,违背了“开闭原则”。
建造者模式:
建造者模式是⼀种创建型设计模式,使⽤多个简单的对象⼀步⼀步构建成⼀个复杂的对象,能够将⼀个复杂的对象的构建与它的表⽰分离,提供⼀种创建对象的最佳⽅式。主要⽤于解决对象的构建过于复杂的问题。
建造者模式主要基于五个核⼼类实现:
• 抽象产品类:
• 具体产品类:⼀个具体的产品对象类
• 抽象Builder类:创建⼀个产品对象所需的各个部件的抽象接⼝
• 具体产品的Builder类:实现抽象接⼝,构建各个部件
• 指挥者Director类:统⼀组建过程,提供给调⽤者使⽤,通过指挥者来构造产品

主板,显示器和操作系统
一个电脑类
/*抽象电脑类*/
class Computer
{
public:
protected:string _board;string _display;string _os;
};操作系统是不确定的,组装的时候因为不同的电脑是不同的操作系统
记得加上virtual,和=0,它是纯虚函数
class Computer
{
public:Computer(){}void setBoard(const string &board){_board = board;}void setDisplay(const string& display){_display = display;}virtual void setOS() = 0;
protected:string _board;string _display;string _os;
};电脑参数:
void showParamater(){string param = "Computer Paramaters:\n";param += "\tBoard:" + _board + "\n";param += "\tDisplay:" + _display + "\n";param += "\tOs:" + _os + "\n";cout << param << endl;} 具体产品类(苹果笔记本)
具体产品类(苹果笔记本)
![]()
/*具体产品类*/

class MacBook :public Computer
{
public:void setOS() override{_os = "Mac OS x13";}
};抽象建造者类
![]() /*抽象建造者类:包含创建⼀个产品对象的各个部件的抽象接⼝*/
/*抽象建造者类:包含创建⼀个产品对象的各个部件的抽象接⼝*/
class Builder
{
public:virtual void buildBoard(const string& board) = 0;virtual void buildDisplay(const string& display) = 0;//系统这里不用写参数virtual void buildOs() = 0;virtual shared_ptr<Computer> build() = 0;
};进行派生建造
![]()
class MacBookBuilder :public Builder
{
public:MacBookBuilder():_computer(new MacBook()){}
private:shared_ptr<Computer> _computer;
};构造零件
构造主板......................
最后在返回对象
/*具体产品的具体建造者类:实现抽象接⼝,构建和组装各个部件*/
class MacBookBuilder :public Builder
{
public:MacBookBuilder():_computer(new MacBook()){}void buildBoard(const string& board){_computer->setBoard(board);}virtual void buildDisplay(const string& display){_computer->setDisplay(display);}virtual void buildOs(){_computer->setOS();}shared_ptr<Computer> build(){return _computer;}
private:shared_ptr<Computer> _computer;
};指挥者类
![]()
/*指挥者类,提供给调⽤者使⽤,通过指挥者来构造复杂产品*/
class Director
{
public:Director(Builder* builder):_builder(builder){}void construct(const string& board, const string& display){_builder->buildBoard(board);_builder->buildDisplay(board);_builder->buildOs();}
private:shared_ptr<Builder> _builder;
};具体main中使用
int main()
{Builder* builder = new MacBookBuilder();unique_ptr<Director> director(new Director(builder));director->construct("华硕主板", "三星显示器");shared_ptr<Computer> compter = builder->build();compter->showParamater();return 0;
}
思路:
思路:先抽象一个笔记本的类,它有很多个零部件去进行设置,但是安装呢,我们派生出具体的苹果笔记本电脑,然后有了具体的苹果笔记本电脑,我们接下来呢,出现了我们的建造者,建造者呢,它需要建造出我们的每一个零件零件,然后最终去建造一个电脑,但是呢有了零部件,就能建造出电脑吗,那也不一定,因为建造电脑的时候呢,有可能各个零部件,建造的顺序它是有要求的,所以呢我们接下来就有了一个指挥者类,指挥者类呢,在构造的时候呢,构造一个对象的时候,在它里面定义了各个参数所需要的各项信息,以及他们的顺序,等各个零部件都安装好后,最终呢再通过建造者,建造出我们的苹果笔记本电脑,主要用于建造复杂对象的建造过程
代理模式
代理模式指代理控制对其他对象的访问,也就是代理对象控制对原对象的引⽤。在某些情况下,⼀个对象不适合或者不能直接被引⽤访问,⽽代理对象可以在客⼾端和⽬标对象之间起到中介的作⽤。
代理模式的结构包括⼀个是真正的你要访问的对象(⽬标类)、⼀个是代理对象。⽬标对象与代理对象实 现同⼀个接⼝,先访问代理类再通过代理类访问⽬标对象。代理模式分为静态代理、动态代理:
• 静态代理指的是,在编译时就已经确定好了代理类和被代理类的关系。也就是说,在编译时就已经 确定了代理类要代理的是哪个被代理类。
• 动态代理指的是,在运⾏时才动态⽣成代理类,并将其与被代理类绑定。这意味着,在运⾏时才能 确定代理类要代理的是哪个被代理类。
以租房为例,房东将房⼦租出去,但是要租房⼦出去,需要发布招租启⽰,带⼈看房,负责维修,这 些⼯作中有些操作并⾮房东能完成,因此房东为了图省事,将房⼦委托给中介进⾏租赁。代理模式实现:

房子类
class RentHouse
{
public:virtual void rentHouse() = 0;
};/*房东类:将房⼦租出去*/
class Landlord : public RentHouse
{
public:void rentHouse(){cout << "把房子租出去\n";}
};/*中介代理类:对租房⼦进⾏功能加强,实现租房以外的其他功能*/
发布招租(中介类)
中介代理了房东,再进行租房子的操作
class intermediary : public RentHouse
{
public:void rentHouse(){std::cout << "发布招租启⽰\n";std::cout << "带⼈看房\n";_landlord.rentHouse();std::cout << "负责租后维修\n";}
private:Landlord _landlord;
};main中使用
int main()
{intermediary intermediary;intermediary.rentHouse();return 0;
}
6. 日志系统框架设计
本项⽬实现的是⼀个多⽇志器⽇志系统,主要实现的功能是让程序员能够轻松的将程序运⾏⽇志信息落地到指定的位置,且⽀持同步与异步两种⽅式的⽇志落地⽅式。
项⽬的框架设计将项⽬分为以下⼏个模块来实现。
6.1模块划分
• ⽇志等级模块:对输出⽇志的等级进⾏划分,以便于控制⽇志的输出,并提供等级枚举转字符串功能。
◦ OFF:关闭
◦ DEBUG:调试,调试时的关键信息输出
◦ INFO:提⽰,普通的提⽰型⽇志信息
◦ WARN:警告,不影响运⾏,但是需要注意⼀下的⽇志
◦ ERROR:错误,程序运⾏出现错误的⽇志
◦ FATAL:致命,⼀般是代码异常导致程序⽆法继续推进运⾏的⽇志
• ⽇志消息模块:中间存储⽇志输出所需的各项要素信息
◦ 时间:描述本条⽇志的输出时间。
◦ 线程ID:描述本条⽇志是哪个线程输出的。
◦ ⽇志等级:描述本条⽇志的等级。
◦ ⽇志数据:本条⽇志的有效载荷数据。
◦ ⽇志⽂件名:描述本条⽇志在哪个源码⽂件中输出的。
◦ ⽇志⾏号:描述本条⽇志在源码⽂件的哪⼀⾏输出的。
• ⽇志消息格式化模块:设置⽇志输出格式,并提供对⽇志消息进⾏格式化功能。
◦ 系统的默认⽇志输出格式:%d{%H:%M:%S}%T[%t]%T[%p]%T[%c]%T%f:%l%T%m%n
◦ ->13:26:32 [2343223321] [FATAL] [root] main.c:76 套接字创建失败\n
◦ %d{%H:%M:%S}:表⽰⽇期时间,花括号中的内容表⽰⽇期时间的格式。
◦ %T:表⽰制表符缩进。
◦ %t:表⽰线程ID
◦ %p:表⽰⽇志级别
◦ %c:表⽰⽇志器名称,不同的开发组可以创建⾃⼰的⽇志器进⾏⽇志输出,⼩组之间互不影响。
◦ %f:表⽰⽇志输出时的源代码⽂件名。
◦ %l:表⽰⽇志输出时的源代码⾏号。
◦ %m:表⽰给与的⽇志有效载荷数据
◦ %n:表⽰换⾏
◦ 设计思想:设计不同的⼦类,不同的⼦类从⽇志消息中取出不同的数据进⾏处理。
• ⽇志消息落地模块:决定了⽇志的落地⽅向,可以是标准输出,也可以是⽇志⽂件,也可以滚动⽂件输出....
◦ 标准输出:表⽰将⽇志进⾏标准输出的打印。
◦ ⽇志⽂件输出:表⽰将⽇志写⼊指定的⽂件末尾。
◦ 滚动⽂件输出:当前以⽂件⼤⼩进⾏控制,当⼀个⽇志⽂件⼤⼩达到指定⼤⼩,则切换下⼀个⽂件进⾏输出
◦ 后期,也可以扩展远程⽇志输出,创建客⼾端,将⽇志消息发送给远程的⽇志分析服务器。
◦ 设计思想:设计不同的⼦类,不同的⼦类控制不同的⽇志落地⽅向。
• ⽇志器模块:
◦ 此模块是对以上⼏个模块的整合模块,⽤⼾通过⽇志器进⾏⽇志的输出,有效降低⽤户的使⽤难度。
◦ 包含有:⽇志消息落地模块对象,⽇志消息格式化模块对象,⽇志输出等级
• ⽇志器管理模块:
◦ 为了降低项⽬开发的⽇志耦合,不同的项⽬组可以有⾃⼰的⽇志器来控制输出格式以及落地⽅ 向,因此本项⽬是⼀个多⽇志器的⽇志系统。
◦ 管理模块就是对创建的所有⽇志器进⾏统⼀管理。并提供⼀个默认⽇志器提供标准输出的⽇志输出。
• 异步线程模块:
◦ 实现对⽇志的异步输出功能,⽤户只需要将输出⽇志任务放⼊任务池,异步线程负责⽇志的落 地输出功能,以此提供更加⾼效的⾮阻塞⽇志输出。
6.2 模块关系图

7. 代码设计
7.1 实⽤类(常用)设计
提前完成⼀些零碎的功能接⼝,以便于项⽬中会⽤到。
• 获取系统时间
• 判断⽂件是否存在
• 获取⽂件的所在⽬录路径
• 创建⽬录

写成静态的好处就是,不用实例化对象了,直接通过类名再加上作用于限定符就可以直接访问这个getTime这个接口了
namespace ljwlog
{//实用类的设计区域namespace util{class Date{public:static time_t now(){return time(nullptr);}};}
}判断文件是否存在(接口先写出来)
namespace ljwlog
{//实用类的设计区域namespace util{class File{public:static bool exists(const string& pathname); //路径文件是否存在static string path(const string& pathname); //路径static void createDirectory(const string& pathname);//创建目录};}
}如何判断它是否存在呢
用stat

static bool exists(const string& pathname)//路径文件是否存在{struct stat st;if (stat(pathname.c_str(), &st) < 0){return false;}return true;}获取文件的所在路径
static string path(const string& pathname)//路径
{// ./a.txtsize_t pos = pathname.find_last_of("/\\");if (pos == string::npos){return ".";}return pathname.substr(0, pos + 1);
}创建目录
mkdir创建目录

0777权限全部给了
在遍历这个路径的时候,如果找不到则直接进行创建,创建完毕 就跳出循环了 查找不到/的时候,也就是最后这个路径下实际对应的那个目录
否则这里不跳出,则会继续向下执行,跳不出
static void createDirectory(const string & pathname) // 创建目录
{// ./abc/bcd/cdesize_t pos = 0, idx = 0;while (idx < pathname.size()){pos = pathname.find_first_of("/\\", idx);if (pos == string::npos){mkdir(pathname.c_str(), 0777);return;}string parent_dir = pathname.substr(0, pos + 1);if (exists(parent_dir) == true){idx = pos + 1;continue;}mkdir(parent_dir.c_str(), 0777);idx = pos + 1;}
}总代码:
#pragma once
#include <iostream>
#include <ctime>
#include <string>
#include <sys/stat.h>
#include <sys/types.h>
using namespace std;
namespace ljwlog
{// 实用类的设计区域namespace util{class Date{public:static time_t now(){return time(nullptr);}};class File{public:static bool exists(const string &pathname) // 路径文件是否存在{struct stat st;if (stat(pathname.c_str(), &st) < 0){return false;}return true;}static string path(const string &pathname) // 路径{// ./a.txtsize_t pos = pathname.find_last_of("/\\");if (pos == string::npos){return ".";}return pathname.substr(0, pos + 1);}static void createDirectory(const string &pathname) // 创建目录{// ./abc/bcd/cdesize_t pos = 0, idx = 0;while (idx < pathname.size()){pos = pathname.find_first_of("/\\", idx);if (pos == string::npos){mkdir(pathname.c_str(), 0777);return ;}string parent_dir = pathname.substr(0, pos + 1);if(exists(parent_dir) == true){idx = pos + 1;continue;}mkdir(parent_dir.c_str(),0777);idx = pos + 1;}}};}
}
测试:
int main()
{ string pathname = "./abc/bcd/a.txt";ljwlog::util::File::createDirectory(pathname);return 0;
}
7.2 日志等级类设计
⽇志等级总共分为7个等级,分别为:
• OFF关闭所有⽇志输出
• DRBUG进⾏debug时候打印⽇志的等级
• INFO打印⼀些⽤户提⽰信息
• WARN打印警告信息
• ERROR打印错误信息
• FATAL打印致命信息-导致程序崩溃的信息
![]()
定义枚举类,枚举出日志等级
提供转换接口:将枚举转换为对应字符串
/*
• OFF关闭所有⽇志输出• DRBUG进⾏debug时候打印⽇志的等级• INFO打印⼀些⽤⼾提⽰信息• WARN打印警告信息• ERROR打印错误信息• FATAL打印致命信息-导致程序崩溃的信息
*/
#pragma oncenamespace ljwlog
{class LogLevel{public:enum class value{UNKNOW = 0,DEBUG,INFO,WARN,ERROR,FATAL,OFF};static const char* toString(LogLevel::value level){switch(level){case LogLevel::value::DEBUG: return "DEBUG";case LogLevel::value::INFO: return "INFO";case LogLevel::value::WARN: return "WARN";case LogLevel::value::ERROR: return "ERROR";case LogLevel::value::FATAL: return "FATAL";case LogLevel::value::OFF: return "OFF";}return "UNKNOW";}};
}测试:
int main()
{ cout<< ljwlog::LogLevel::toString(ljwlog::LogLevel::value::DEBUG) <<endl;cout<< ljwlog::LogLevel::toString(ljwlog::LogLevel::value::ERROR) <<endl;cout<< ljwlog::LogLevel::toString(ljwlog::LogLevel::value::FATAL) <<endl;cout<< ljwlog::LogLevel::toString(ljwlog::LogLevel::value::INFO) <<endl;cout<< ljwlog::LogLevel::toString(ljwlog::LogLevel::value::OFF) <<endl;cout<< ljwlog::LogLevel::toString(ljwlog::LogLevel::value::WARN) <<endl;return 0;
}
7.3 日志消息类设计
⽇志消息类主要是封装⼀条完整的⽇志消息所需的内容,其中包括⽇志等级、对应的logger name、打印⽇志源⽂件的位置信息(包括⽂件名和⾏号)、线程ID、时间戳信息、具体的⽇志信息等内容。
![]()
namespace ljwlog
{struct LogMsg{using ptr = std::shared_ptr<LogMsg>;size_t _line;//行号size_t _ctime;//时间std::thread::id _tid;//线程IDstd::string _name;//日志器名称std::string _file;//文件名std::string _payload;//日志消息LogLevel::value _level;//日志等级};
}构造
namespace ljwlog
{struct LogMsg{LogMsg(LogLevel::value level, size_t line,const string &file,const string &logger,const string msg):_ctime(util::Date::now()),_level(level),_line(line),_tid(this_thread::get_id()),_file(file),_logger(logger),_payload(msg){}size_t _ctime;//日志产生的时间戳LogLevel::value _level;//日志等级size_t _line;//行号thread::id _tid;//线程IDstring _file;//源码文件名string _logger;//日志器名称string _payload;//有效消息数据};}7.4 日志输出格式化类设计
![]()
⽇志格式化(Formatter)类主要负责格式化⽇志消息。其主要包含以下内容
• pattern成员:保存⽇志输出的格式字符串。
◦ %d⽇期
◦ %T缩进
◦ %t线程id
◦ %p⽇志级别
◦ %c⽇志器名称
◦ %f⽂件名
◦ %l⾏号
◦ %m⽇志消息
◦ %n换⾏
• std::vector items成员:⽤于按序保存格式化字符串对应的⼦格式化对象。 FormatItem类主要负责⽇志消息⼦项的获取及格式化。其包含以下⼦类
• MsgFormatItem:表⽰要从LogMsg中取出有效⽇志数据
• LevelFormatItem:表⽰要从LogMsg中取出⽇志等级
• LoggerFormatItem:表⽰要从LogMsg中取出⽇志器名称
• ThreadFormatItem:表⽰要从LogMsg中取出线程ID
• TimeFormatItem:表⽰要从LogMsg中取出时间戳并按照指定格式进⾏格式化
• FileFormatItem:表⽰要从LogMsg中取出源码所在⽂件名
• LineFormatItem:表⽰要从LogMsg中取出源码所在⾏号
• TabFormatItem:表⽰⼀个制表符缩进
• NLineFormatItem:表⽰⼀个换⾏
• OtherFormatItem:表⽰⾮格式化的原始字符串
⽰例:"[%d{%H:%M:%S}]%m%n"
![]()





抽象格式化子项基类
#pragma once
#include<memory>
#include<iostream>
#include"message.hpp"
using namespace std;
namespace ljwlog
{//抽象格式化子项基类class FormatItem{public:using ptr = shared_ptr<FormatItem>;virtual void format(ostream &out, LogMsg &msg) = 0;};
}
![]()
// 派生格式化子项类--消息,等级,时间,文件名,行号,线程ID,日志器名,制表符,换行,其他class MsgFormatItem : public FormatItem{public:void format(ostream &out, LogMsg &msg) override{out << msg._payload;}};![]()
class LevelFormatItem : public FormatItem{public:void format(ostream &out, LogMsg &msg) override{out<< LogLevel::toString(msg._level);}};![]()
//日志器名称class LoggerFormatItem : public FormatItem{public:void format(ostream &out, LogMsg &msg) override{out << msg._logger;}};![]()
class ThreadFormatItem : public FormatItem{public:void format(ostream &out, LogMsg &msg) override{out << msg._tid;}};
将时间戳转换为时分秒
localtime_r这里就把时间放进了t中,再strftime弄成字符串,再放进out里
class TimeFormatItem : public FormatItem{public:TimeFormatItem(const string &fmt = "%H:%M:%S"): _time_fmt(fmt){} void format(ostream &out, LogMsg &msg) override{struct tm t;localtime_r(&msg._ctime, &t);char tmp[32] = "0";strftime(tmp, 31, _time_fmt.c_str(), &t);out << tmp;}private:string _time_fmt; //%H:%M:%S};![]()
class FileFormatItem : public FormatItem{public:void format(ostream &out, LogMsg &msg) override{out << msg._file;}};![]()
class LineFormatItem : public FormatItem{public:void format(ostream &out, LogMsg &msg) override{out << msg._line;}};![]()
//制表符缩进class TabFormatItem : public FormatItem{public:void format(ostream &out, LogMsg &msg) override{out << "\t";}};![]()
class NLineFormatItem : public FormatItem{public:void format(ostream &out,LogMsg &msg) override{out << "\n";}};![]()
class OtherFormatItem : public FormatItem{private:std::string _str;public:OtherFormatItem(const string &str):_str(str){}void format(ostream &out,LogMsg &msg) override{out << _str;}};格式化程序的接口
class Formatter{public://模式Formatter(const string &pattern = "[%d{%H:%M:%S}][%t][%c][%f:%l][%p]%T%M%N"):_pattern(pattern){assert(parsePattern());}//对msg记性格式化void format(ostream &out, LogMsg &msg){}string format(LogMsg &msg);//对格式化规则字符串进行解析bool parsePattern();private://根据不同的格式化字符创建不同的格式化子项对象FormatItem::ptr createItem(const string &key, const string &val);private:string _pattern;vector<FormatItem::ptr> _items;};接口实现
class Formatter{public:using ptr = shared_ptr<Formatter>;// 模式Formatter(const string &pattern = "[%d{%H:%M:%S}][%t][%c][%f:%l][%p]%T%M%N") : _pattern(pattern){assert(parsePattern());}// 对msg记性格式化void format(ostream &out, LogMsg &msg){for (auto &item : _items){item->format(out, msg);}}string format(LogMsg &msg){stringstream ss;format(ss, msg);return ss.str();}// 对格式化规则字符串进行解析bool parsePattern(){// 1.对格式化规则字符串进行解析// ab%%cde[%d{%H%M%S}][%p]%T%m%nvector<pair<string, string>> fmt_order;size_t pos = 0;string key, val;while (pos < _pattern.size()){// 1.处理原始字符串--判断是否是%,不是就是原始字符,然后继续返回找%if (_pattern[pos] != '%'){val.push_back(_pattern[pos++]);continue;}// 能到这说明pos位置就是%字符,%%处理称为一个原始%字符if (pos + 1 < _pattern.size() && _pattern[pos + 1] == '%'){val.push_back('%');pos += 2;continue;}// 能走到这里,代表%后面是个格式化字符,代表原始字符处理完毕fmt_order.push_back(make_pair("", val));val.clear();// 格式化字符的处理pos += 1;key = _pattern[pos];pos += 1;if (_pattern[pos] == '{'){pos += 1; // 这时候pos指向子规则的起始位置while (pos < _pattern.size() && _pattern[pos] != '}'){val.push_back(_pattern[pos++]);}// 走到了末尾跳出了循环,则代表没有遇到},则说明格式是错误的if (pos == _pattern.size()){cout << "子规则{}匹配错误!\n";return false; // 没有找到}}}}}private:// 根据不同的格式化字符创建不同的格式化子项对象FormatItem::ptr createItem(const string &key, const string &val){/*%d ⽇期%t 线程id%c ⽇志器名称%f ⽂件名%l ⾏号%p ⽇志级别%T 缩进%m ⽇志消息%n 换⾏*/// 只有第一个需要参数if (key == "d")return make_shared<TimeFormatItem>(val);if (key == "t")return make_shared<ThreadFormatItem>();if (key == "c")return make_shared<LoggerFormatItem>();if (key == "f")return make_shared<FileFormatItem>();if (key == "l")return make_shared<LineFormatItem>();if (key == "p")return make_shared<LevelFormatItem>();if (key == "T")return make_shared<TabFormatItem>();if (key == "m")return make_shared<MsgFormatItem>();if (key == "n")return make_shared<NLineFormatItem>();return make_shared<OtherFormatItem>(val);}private:string _pattern;vector<FormatItem::ptr> _items;};
}

// 对格式化规则字符串进行解析bool parsePattern(){// 1.对格式化规则字符串进行解析// ab%%cde[%d{%H%M%S}][%p]%T%m%nvector<pair<string, string>> fmt_order;size_t pos = 0;string key, val;while (pos < _pattern.size()){// 1.处理原始字符串--判断是否是%,不是就是原始字符,然后继续返回找%if (_pattern[pos] != '%'){val.push_back(_pattern[pos++]);continue;}// 能到这说明pos位置就是%字符,%%处理称为一个原始%字符if (pos + 1 < _pattern.size() && _pattern[pos + 1] == '%'){val.push_back('%');pos += 2;continue;}// 能走到这里,代表%后面是个格式化字符,代表原始字符处理完毕fmt_order.push_back(make_pair("", val));val.clear();// 格式化字符的处理pos += 1;key = _pattern[pos];pos += 1;if (_pattern[pos] == '{'){pos += 1; // 这时候pos指向子规则的起始位置while (pos < _pattern.size() && _pattern[pos] != '}'){val.push_back(_pattern[pos++]);}// 走到了末尾跳出了循环,则代表没有遇到},则说明格式是错误的if (pos == _pattern.size()){cout << "子规则{}匹配错误!\n";return false; // 没有找到}}}}}完善一下:%c如果是开头,不判断是否为空,可能就会插入一个空" "


测试:
int main()
{ ljwlog::LogMsg msg(ljwlog::LogLevel::value::INFO, 53, "main.c", "root", "格式化功能测试");ljwlog::Formatter fmt;string str = fmt.format(msg);cout<< str << endl;return 0;
}调用思路图

再进行边缘测试


花括号不匹配测试

会直接断言

测试其他特殊字符,没有给出特殊的响应


修改,程序异常退出


7.5日志落地类的设计
⽇志落地类主要负责落地⽇志消息到⽬的地。
它主要包括以下内容:
- Formatter日志格式化器:主要是负责格式化日志消息,
- mutex互斥锁:保证多线程日志落地过程中的线程安全,避免出现交叉输出的情况。
这个类支持可扩展,其成员函数log设置为纯虚函数,当我们需要增加一个log输出目标,可以增加一个类继承自该类并重写log方法实现具体的落地日志逻辑。
⽬前实现了三个不同⽅向上的⽇志落地:
- 标准输出:StdoutSink
- 固定文件:FileSink
- 滚动文件:RollSink(日志文件滚动的条件有两个:文件大小(BySize)和时间)
- 滚动文件:RollSink(日志文件滚动的条件有两个:文件大小和时间(ByTime))
滚动日志文件输出的必要性:
- 由于机器磁盘空间有限,我们不可能一直无限地向一个文件中增加数据
- 如果一个日志文件体积太大,一方面是不好打开,另一方面是即时打开了由于包含数据巨大,也 不利于查找我们需要的信息
- 所以实际开发中会对单个日志文件的大小也会做一些控制,即当大小超过某个大小时(如1GB), 我们就重新创建一个新的日志文件来滚动写日志。对于那些过期的日志,大部分企业内部都有专门的运维人员去定时清理过期的日志,或者设置系统定时任务,定时清理过期日志。
日志文件滚动的条件有两个:文件大小和时间。我们可以选择:
- 日志文件在大于1GB的时候会更换新的⽂件
- 每天定点滚动⼀个日志文件
本项目基于文件大小的判断滚动生成新的文件

![]()
日志落地模块的实现
1.抽象落地基类
2.派生子类(根据不同的落地方向进行派生)
3.使用工厂模式进行创建与表示的分离
![]()
这样抽象后,里面的都是通过指针或者引用访问的,所以定义一个指针指针

![]()
![]()
//落地方向:标准输出class StdoutSink : public Logsink{public://将日志消息写入到标准输出void log(const char* data, size_t len) override;};接口实现:
// 落地方向:标准输出class StdoutSink : public Logsink{public:// 将日志消息写入到标准输出void log(const char *data, size_t len) override{cout.write(data, len);}};![]()
//落地方向:指定文件class FileSink : public Logsink{public://构造时传入文件名,并打开文件,将操作句柄管理起来FileSink(const string &pathname);//将日志消息写入到标准输出void log(const char* data, size_t len) override;private:string _pathname;ofstream _ofs;//标准输出};因为每次打开文件都很麻烦,所以呢也要管理文件的操作句柄
在 C++ 中,管理文件的操作句柄通常指的是使用文件流(file streams)来读取或写入文件。文件流是 C++ 标准库中的类,用于处理文件 I/O。以下是三个主要的文件流类,它们分别用于不同类型的文件操作:
- std::ifstream - 用于从文件读取数据。
- std::ofstream - 用于向文件写入数据。
- std::fstream - 用于读写文件
接口实现:
传的路径,但不一定就可以打开文件
用到了(util中File的创建文件)
// 落地方向:指定文件class FileSink : public Logsink{public:// 构造时传入文件名,并打开文件,将操作句柄管理起来FileSink(const string &pathname):_pathname(pathname){//1.创建日志文件所在的目录util::File::createDirectory(util::File::path(pathname));//2.创建并打开日志文件,app是可追加方式_ofs.open(_pathname, ios::binary | ios::app);//确保在读取文件时,处理好文件打开失败、读取错误等异常情况,以避免程序崩溃或数据损坏assert(_ofs.is_open());}// 将日志消息写入到标准输出void log(const char *data, size_t len) override{_ofs.write(data, len);assert(_ofs.good());}private:string _pathname;ofstream _ofs; // 标准输出};![]()
// 落地方向:滚动文件(以大小进行滚动)class RollBySizeSink : public Logsink{public:// 构造时传入文件名,并打开文件,将操作句柄管理起来RollBySizeSink(const string &basename, size_t max_size);// 将日志消息写入到标准输出--写入前判断文件大小,超过了最大大小就要切换文件void log(const char *data, size_t len) override;private:void createNewFile();//进行大小判断,超过指定大小则创建新文件private://通过基础文件名 + 扩展文件名(以时间生成)组成一个实际的当前输出文件名string _basename;ofstream _ofs; // 标准输出size_t _max_fsize;//记录最大大小,当前文件超过了这个大小就要切换文件size_t _cur_fsize;//记录当前文件已经写入的数据大小};接口实现
// 落地方向:滚动文件(以大小进行滚动)class RollBySizeSink : public LogSink{public:// 构造时传入文件名,并打开文件,将操作句柄管理起来RollBySizeSink(const string &basename, size_t max_size) :_basename(basename), _max_fsize(max_size), _cur_fsize(0), _name_count(0){string pathname = createNewFile();// 1.创建日志文件所在的目录util::File::createDirectory(util::File::path(pathname));// 2.创建并打开日志文件,app是可追加方式_ofs.open(pathname, ios::binary | ios::app);// 确保在读取文件时,处理好文件打开失败、读取错误等异常情况,以避免程序崩溃或数据损坏assert(_ofs.is_open());}//将日志消息写入到标准输出--写入前判断文件大小,超过了最大大小就要切换文件void log(const char* data, size_t len){if(_ofs.is_open() == false || _cur_fsize >= _max_fsize){//关闭原来的文件_ofs.close();string pathname = createNewFile();_ofs.open(pathname, ios::binary | ios::app);assert(_ofs.is_open());//新的文件,里面的内容要清零_cur_fsize = 0;}_ofs.write(data, len);assert(_ofs.good());_cur_fsize += len;}private://进行大小判断,超过指定大小则创建新文件string createNewFile(){//获取系统时间,以时间来构造文件名扩展名time_t t = util::Date::now();struct tm it;localtime_r(&t, &it);stringstream filename;filename << _basename;//文件目录filename << it.tm_year + 1900;filename << it.tm_mon + 1;filename << it.tm_mday;filename << it.tm_hour;filename << it.tm_min;filename << it.tm_sec;filename << "-";filename << _name_count++;//计数器++,方便打印看数filename << ".log";return filename.str();}private:// 通过基础文件名 + 扩展文件名(以时间生成)组成一个实际的当前输出文件名string _basename; // ./log/base- --> ./logs/base-200290912.logofstream _ofs; // 标准输出size_t _max_fsize; // 记录最大大小,当前文件超过了这个大小就要切换文件size_t _cur_fsize; // 记录当前文件已经写入的数据大小size_t _name_count;//计数器,弄一个计数器,要不然1秒就运行完了,名字又是用时间区分的,所以为了区分文件名加一个计数器};
创建工厂,要具备扩展性
上面的派生类需要的参数不同 (用到了不定参类型)
class SinkFactory{public:template<class SinkType, class ...Args>static LogSink::ptr create(Args && ...args){return make_shared<SinkType>(forward<Args>(args)...); }};测试前两个:
int main()
{ ljwlog::LogMsg msg(ljwlog::LogLevel::value::INFO, 53, "main.c", "root", "格式化功能测试");ljwlog::Formatter fmt("abc%%c[%d{%H:%M:%S}][%t][%c][%f:%l][%p]%T%m%n");string str = fmt.format(msg);//cout<< str << endl;ljwlog::LogSink::ptr stdout_lsp = ljwlog::SinkFactory::create<ljwlog::StdoutSink>();ljwlog::LogSink::ptr file_lsp = ljwlog::SinkFactory::create<ljwlog::FileSink>("./logfile/test.log");//ljwlog::LogSink::ptr roll_lsp = ljwlog::SinkFactory::create<ljwlog::RollBySizeSink>("./logfile/test.log", 10*1024*1024);stdout_lsp->log(str.c_str(), str.size());file_lsp->log(str.c_str(), str.size());return 0;
}
滚动的测试要循环
int main()
{ ljwlog::LogMsg msg(ljwlog::LogLevel::value::INFO, 53, "main.c", "root", "格式化功能测试");ljwlog::Formatter fmt("abc%%c[%d{%H:%M:%S}][%t][%c][%f:%l][%p]%T%m%n");string str = fmt.format(msg);// cout<< str << endl;ljwlog::LogSink::ptr stdout_lsp = ljwlog::SinkFactory::create<ljwlog::StdoutSink>();//ljwlog::LogSink::ptr file_lsp = ljwlog::SinkFactory::create<ljwlog::FileSink>("./logfile/test.log");ljwlog::LogSink::ptr roll_lsp = ljwlog::SinkFactory::create<ljwlog::RollBySizeSink>("./logfile/test.log", 1024*1024);stdout_lsp->log(str.c_str(), str.size());//打印//file_lsp->log(str.c_str(), str.size());//打印size_t cursize = 0;size_t count = 0;while(cursize <= 1024*1024*10){string tmp = str + to_string(count++);roll_lsp->log(tmp.c_str(), tmp.size());//打印cursize += tmp.size();}return 0;
}
![]()
- 扩展一个以时间作为入职文件滚动切换类型的日志落地模块
- 以前的滚动文件时以大小来滚动的,1M切换一个文件
- 现在扩展一个用时间滚动一个文件
- 时间间隔多少秒就切换一个文件
- 以秒为单位,分,时,天
- 扩展一个以时间作为入职文件滚动切换类型的日志落地模块
- 以时间进行文件滚动,实际上是以时间段进行滚动
- 实现思想:以当前系统时间,取模时间段大小,可以得到当前时间段是第几个时间段
- 每次以当前系统时间取模,判断与当前文件的时间段是否一致,不一致代表不是同一个时间段
创建一个时间间隔枚举类
enum class TimeGap //Gap是间隔的意思
{GAP_SECOND, //间隔多久切换一个文件GAP_MINUTE,GAP_HOUR,GAP_DAY,
}; // 落地方向:滚动文件(以时间间隔进行滚动)class RollByTimeSink : public ljwlog::LogSink{public:// 构造时传入文件名,并打开文件,将操作句柄管理起来RollByTimeSink(const string &basename, TimeGap gap_type) : _basename(basename){switch (gap_type){case TimeGap::GAP_SECOND: _gap_size = 1; break; //间隔一秒切换一个文件case TimeGap::GAP_MINUTE: _gap_size = 60; break;case TimeGap::GAP_HOUR: _gap_size = 3600; break;case TimeGap::GAP_DAY: _gap_size = 3600 * 24; break;}//获取当前是第几个时间段//当_gap_size为1的时候,任何数取模1都是0_cur_gap = _gap_size ==1 ? ljwlog::util::Date::now() : ljwlog::util::Date::now() % _gap_size;string filename = createNewFile();ljwlog::util::File::createDirectory(ljwlog::util::File::path(filename));_ofs.open(filename, ios::binary | ios::app);assert(_ofs.is_open());}// 将日志消息写入标准输出,判断当前时间是否是当前文件的时间段,不是则切换文件void log(const char *data, size_t len){time_t cur = ljwlog::util::Date::now();if(cur % _gap_size != _cur_gap){_ofs.close();string filename = createNewFile();_ofs.open(filename, ios::binary | ios::app);assert(_ofs.is_open());}_ofs.write(data, len);assert(_ofs.good());}string createNewFile(){// 获取系统时间,以时间来构造文件名扩展名time_t t = ljwlog::util::Date::now();struct tm it;localtime_r(&t, &it);stringstream filename;filename << _basename; // 文件目录filename << it.tm_year + 1900;filename << it.tm_mon + 1;filename << it.tm_mday;filename << it.tm_hour;filename << it.tm_min;filename << it.tm_sec;filename << ".log";return filename.str();}private:string _basename;ofstream _ofs;size_t _cur_gap; // 当前时第几个时间段size_t _gap_size; // 时间段的大小};思路:
log里时间间隔到了就会创建新的文件进行写入
//将日志消息写入到标准输出--写入前判断文件大小,超过了最大大小就要切换文件void log(const char* data, size_t len){if(_ofs.is_open() == false || _cur_fsize >= _max_fsize){//关闭原来的文件_ofs.close();string pathname = createNewFile();_ofs.open(pathname, ios::binary | ios::app);assert(_ofs.is_open());//新的文件,里面的内容要清零_cur_fsize = 0;}_ofs.write(data, len);assert(_ofs.good());_cur_fsize += len;}测试:(以每一秒为间隔)
int main()
{ljwlog::LogMsg msg(ljwlog::LogLevel::value::INFO, 53, "main.c", "root", "格式化功能测试");ljwlog::Formatter fmt("abc%%c[%d{%H:%M:%S}][%t][%c][%f:%l][%p]%T%m%n");string str = fmt.format(msg);// cout<< str << endl;ljwlog::LogSink::ptr time_lsp = ljwlog::SinkFactory::create<ljwlog::RollByTimeSink>("./logfile/roll--", ljwlog::TimeGap::GAP_SECOND);time_t old = ljwlog::util::Date::now();//写入数据5秒while(ljwlog::util::Date::now() < old + 5){time_lsp->log(str.c_str(), str.size());usleep(100);//慢一点}return 0;
}
7.6 日志器类(Logger)设计(建造者模式)
- 日志器主要是用来和前端交互, 当我们需要使用日志系统打印log的时候,只需要创建Logger对象,调用该对象debug、 info、 warn error- fatal等方法输出自己想打印的日志即可,支持解析可变参数列表和输出格式, 即可以做到像使用printf函数一样打印日志。
- 当前日志系统支持同步日志&异步日志两种模式,两个不同的日志器唯一不同的地方在于他们在日志的落地方式上有所不同:
- 同步日志器:直接对日志消息进行输出。
- 异步日志器:将日志消息放入缓冲区,由异步线程进行输出。
- 因此日志器类在设计的时候先设计出一个Logger基类,在Logger基类的基础上,继承出SyncLogger同步日志器和AsyncLogger异步日志器。
- 且因为日志器模块是对前边多个模块的整合,想要创建一个日志器,需要设置日志器名称,设置日志输出等级,设置日志器类型,设置日志输出格式,设置落地方向,且落地方向有可能存在多个,整个日志器的创建过程较为复杂,为了保持良好的代码风格,编写出优雅的代码,因此日志器的创建这里采用了建造者模式来进行创建。

一个放进磁盘一个放进内存


代码实现
![]()
基本接口
class Logger{public:using ptr = shared_ptr<Logger>;Logger(const string &logger_name, LogLevel::value level, Formatter::ptr &formatter,vector<LogSink::ptr> &sinks):_logger_name(logger_name),_limit_level(level),_formater(formatter),_sinks(sinks.begin(), sinks.end()){}//完成构造日志消息对象过程并进行格式化,得到格式化后的日志消息字符串--然后进行落地输出void debug(const string& file, size_t line, const string& fmt, ...){//通过传入的参数构造出一个日志消息对象,进行日志的格式化,最终落地//1.判断当前的日志是否达到了输出等级if(LogLevel::value::DEBUG < _limit_level) { return ;}//2.对fmt格式化字符和不定参进行字符串组织,得到的日志消息的字符串va_list ap;va_start(ap, fmt);char* res;//属于动态申请int ret = vasprintf(&res, fmt.c_str(), ap);if(ret == -1){cout<< "vasprintf faild!!!!!\n";return ;}va_end(ap);//将ap指针置空//序列化serialization(LogLevel::value::DEBUG, file, line, res);free(res);}void info(const string& file, size_t line, const string& fmt, ...){//通过传入的参数构造出一个日志消息对象,进行日志的格式化,最终落地//1.判断当前的日志是否达到了输出等级if(LogLevel::value::INFO < _limit_level) { return ;}//2.对fmt格式化字符和不定参进行字符串组织,得到的日志消息的字符串va_list ap;va_start(ap, fmt);char* res;//属于动态申请int ret = vasprintf(&res, fmt.c_str(), ap);if(ret == -1){cout<< "vasprintf faild!!!!!\n";return ;}va_end(ap);//将ap指针置空//序列化serialization(LogLevel::value::INFO, file, line, res);free(res); }void warn(const string& file, size_t line, const string& fmt, ...){//通过传入的参数构造出一个日志消息对象,进行日志的格式化,最终落地//1.判断当前的日志是否达到了输出等级if(LogLevel::value::WARN < _limit_level) { return ;}//2.对fmt格式化字符和不定参进行字符串组织,得到的日志消息的字符串va_list ap;va_start(ap, fmt);char* res;//属于动态申请int ret = vasprintf(&res, fmt.c_str(), ap);if(ret == -1){cout<< "vasprintf faild!!!!!\n";return ;}va_end(ap);//将ap指针置空//序列化serialization(LogLevel::value::WARN, file, line, res);free(res); }void error(const string& file, size_t line, const string& fmt, ...){//通过传入的参数构造出一个日志消息对象,进行日志的格式化,最终落地//1.判断当前的日志是否达到了输出等级if(LogLevel::value::ERROR < _limit_level) { return ;}//2.对fmt格式化字符和不定参进行字符串组织,得到的日志消息的字符串va_list ap;va_start(ap, fmt);char* res;//属于动态申请int ret = vasprintf(&res, fmt.c_str(), ap);if(ret == -1){cout<< "vasprintf faild!!!!!\n";return ;}va_end(ap);//将ap指针置空//序列化serialization(LogLevel::value::ERROR, file, line, res);free(res); }void fatal(const string& file, size_t line, const string& fmt, ...){//通过传入的参数构造出一个日志消息对象,进行日志的格式化,最终落地//1.判断当前的日志是否达到了输出等级if(LogLevel::value::FATAL < _limit_level) { return ;}//2.对fmt格式化字符和不定参进行字符串组织,得到的日志消息的字符串va_list ap;va_start(ap, fmt);char* res;//属于动态申请int ret = vasprintf(&res, fmt.c_str(), ap);if(ret == -1){cout<< "vasprintf faild!!!!!\n";return ;}va_end(ap);//将ap指针置空//序列化serialization(LogLevel::value::FATAL, file, line, res);free(res); }protected://对日志序列化,为了方便使用,这样直接复制,serialization直接输入INFO就可以了void serialization(LogLevel::value level, const string &file, size_t line, char*str){//3.构造LogMsg对象LogMsg msg(LogLevel::value::DEBUG, line, file, _logger_name, str);//4.通过格式化工具对LogMsg进行格式化,得到格式化后的日志字符串stringstream ss;_formater->format(ss, msg);//5.进行日志落地log(ss.str().c_str(), ss.str().size());}private://抽象接口完成实际的落地输出--不同的日志器会有不同的实际落地方式//同步落地和异步落地,然后各自继承virtual void log(const char* data, size_t len) = 0;private:mutex _mutex;//互斥锁string _logger_name;atomic<LogLevel::value> _limit_level;//等级限制Formatter::ptr _formater;//格式化vector<LogSink::ptr> _sinks;//日志落地方向};//同步class SyncLogger : public Logger{protected:void log(const char* data, size_t len) override;};
思路:

解释一下父类调用子类的log

用户构造这些零部件太麻烦了,使用建造者模式解决(存在的意义:一个对象的建造过于复杂,输入参数过多,建造者模式,先把各个零部件建造好,再拿零部件去构造出复杂对象)

日志这里可以不需要指挥者,因为顺序可以不一样,直接用建造者建造
思路:
//使用建造者模式来建造日志器,而不要让用户直接去构造日志器,简化用户的使用复杂度
//1.抽象一个日志器建造者类
//1.1设置日志器类型
//1.2将不同类型的日志器的创建放到同一个日志器建造者类中完成
//2.派生出具体的建造者类---局部日志器的建造者 & 全局日志器建造者(后边添加了全局单例管理之后,将日志器添加全局管理
enum class LoggerType{LOGGER_SYNC,LOGGER_ASTNC};//使用建造者模式来建造日志器,而不要让用户直接去构造日志器,简化用户的使用复杂度//1.抽象一个日志器建造者类//1.1设置日志器类型//1.2将不同类型的日志器的创建放到同一个日志器建造者类中完成class LoggerBuilder{public:LoggerBuilder():_logger_type(LoggerType::LOGGER_SYNC),//默认同步日志器_limit_level(LogLevel::value::DEBUG) //默认限制输出等级{}void buildLoggerType(LoggerType type) {_logger_type = type;}void buildLoggerName(const string &name) {_logger_name = name;}void buildLoggerLevel(LogLevel::value level) {_limit_level = level;}void buildFormatter(const string &pattern) {_formatter = make_shared<Formatter>(pattern);}template<class SinkType, class ...Args>void buildSink(Args &&...args){LogSink::ptr psink = SinkFactory::create<SinkType>(forward<Args>(args)...);_sinks.push_back(psink);}virtual Logger::ptr build() = 0;protected:LoggerType _logger_type;string _logger_name;atomic<LogLevel::value> _limit_level;Formatter::ptr _formatter;vector<LogSink::ptr> _sinks;};//2.派生出具体的建造者类---局部日志器的建造者 & 全局日志器建造者(后边添加了全局单例管理之后,将日志器添加全局管理class LocalLoggerBuilder : public LoggerBuilder{public:Logger::ptr build() override{assert(_logger_name.empty() == false);//必须有日志器名称if(_formatter.get() == nullptr){_formatter = make_shared<Formatter>();}if(_sinks.empty()){buildSink<StdoutSink>();}if(_logger_type == LoggerType::LOGGER_ASTNC){}return make_shared<SyncLogger>(_logger_name, _limit_level, _formatter, _sinks);}};测试:
int main()
{unique_ptr<ljwlog::LoggerBuilder> builder(new ljwlog::LocalLoggerBuilder());builder->buildLoggerName("sync_logger");builder->buildLoggerLevel(ljwlog::LogLevel::value::WARN);builder->buildFormatter("%m%n");builder->buildLoggerType(ljwlog::LoggerType::LOGGER_SYNC);builder->buildSink<ljwlog::FileSink>("./logfile/test.log");builder->buildSink<ljwlog::StdoutSink>();ljwlog::Logger::ptr logger = builder->build();logger->debug(__FILE__, __LINE__, "%s", "测试日志");logger->info(__FILE__, __LINE__, "%s", "测试日志");logger->warn(__FILE__, __LINE__, "%s", "测试日志");logger->error(__FILE__, __LINE__, "%s", "测试日志");logger->fatal(__FILE__, __LINE__, "%s", "测试日志");size_t cursize = 0; size_t count = 0;while (cursize <= 1024 * 1024 * 10){logger->fatal(__FILE__, __LINE__, "测试日志--%d", count++);cursize += 20;}return 0;
}
思路:

7.7 双缓冲区异步任务处理器(AsyncLooper)设计(实现异步日志缓冲区)
![]()
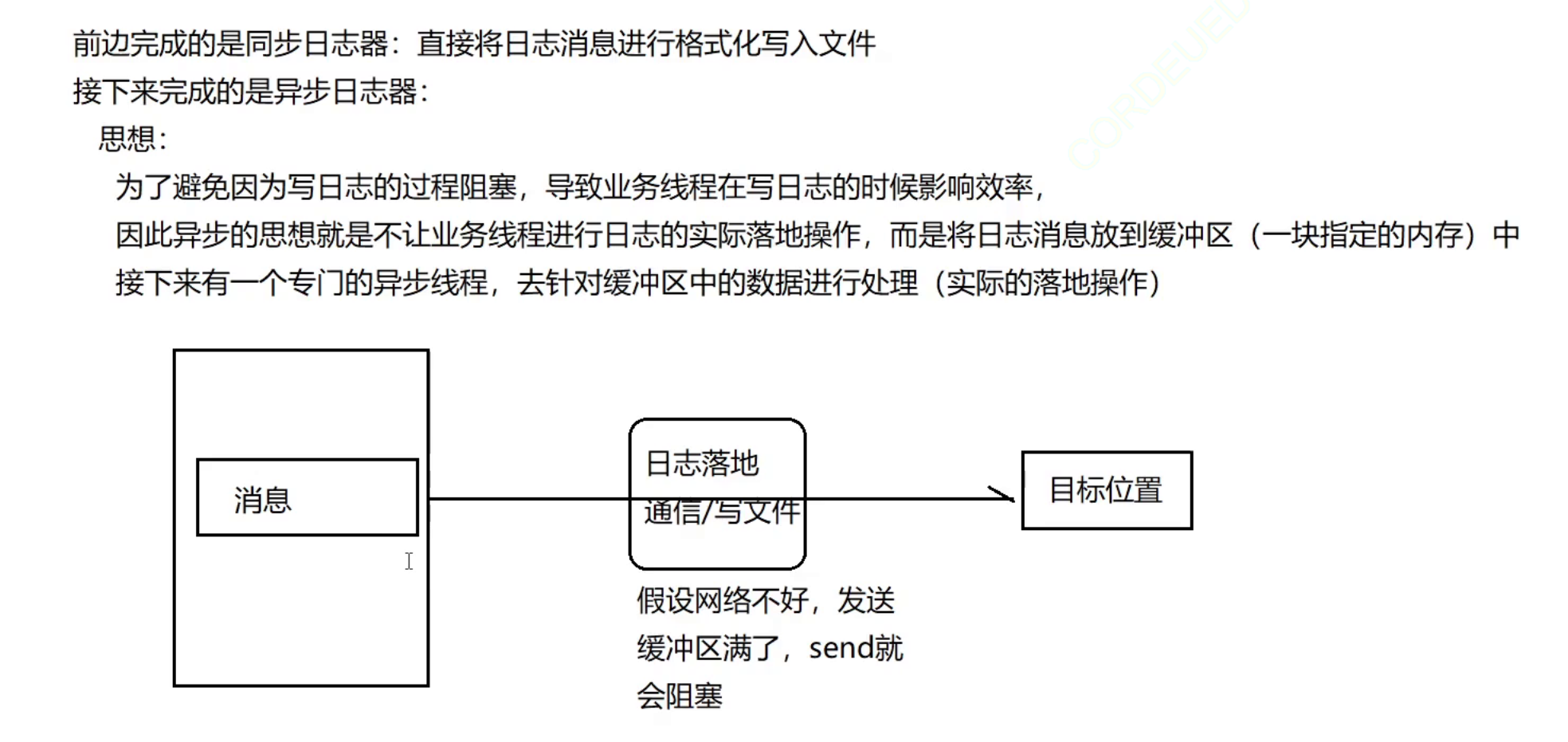



生产者和消费者的锁冲突缓解了,生产者和生产者的还存在
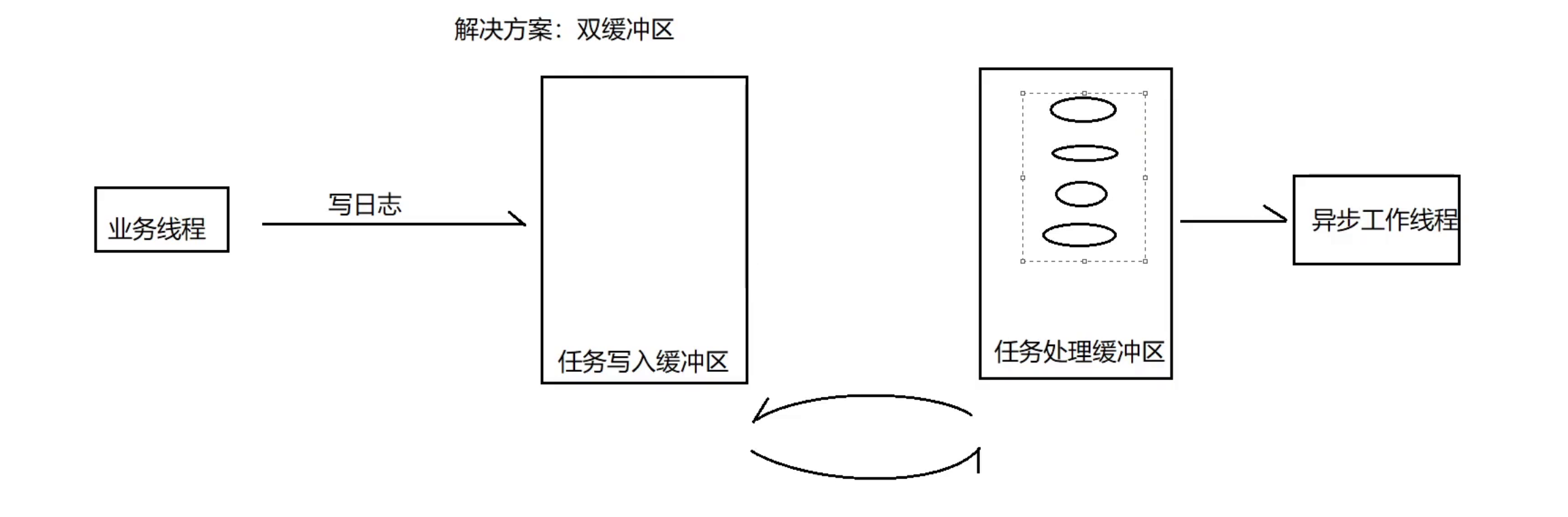
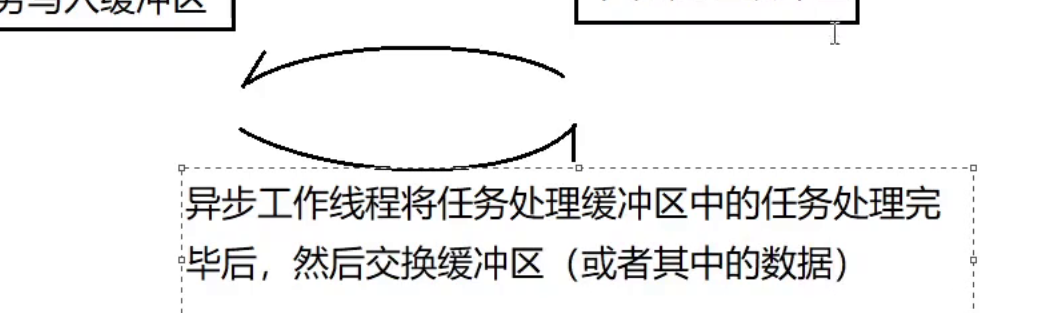

- 设计思想:异步处理线程+数据池
- 使用者将需要完成的任务添加到任务池中,由异步线程来完成任务的实际执行操作。
- 任务池的设计思想:双缓冲区阻塞数据池
- 优势:避免了空间的频繁申请释放,且尽可能的减少了生产者与消费者之间锁冲突的概率,提高了任务处理效率。
- 在任务池的设计中,有很多备选方案,比如循环队列等等,但是不管是哪一种都会涉及到锁冲突的情况,因为在生产者与消费者模型中,任何两个角色之间都具有互关系,因此每一次的任务添加与取出都有可能涉及锁的冲突,而双缓冲区不同,双缓冲区是处理器将一个缓冲区中的任务全部处理完毕后,然后交换两个缓冲区,重新对新的缓冲区中的任务进行处理,虽然同时多线程写入也会冲突,但是冲突并不会像每次只处理一条的时候频繁(减少了生产者与消费者之间的锁冲突),且不涉及到空的频繁申请释放所带来的消耗

写日志的时候会有构造数据会降低效率,所以并不是一条一条数据放进缓冲区里,而是直接把这条格式化好的日志字符串放进缓冲区,而不是放message

不能用string是因为默认以\0结束字符串



代码实现 /* 实现异步日志缓冲区 */
大致规模
//这是100M#define DEFAULT_BUFFER_SIZE (1024*1024*100)//创建一个缓冲区bufferclass Buffer{public:Buffer();//向缓冲区中写入数据void push(const char *data, size_t len);//返回可读数据的起始地址const char* begin();//返回可读数据的长度size_t readAbleSize();//对读写指针进行向后偏移操作void moveReader(size_t len);//重置读写位置,初始化缓冲区void reset();//对Buffer进行交换操作void swap(const Buffer &buffer);//判断缓冲区是否为空,为空就不交换void empty();private://对读写指针进行向后偏移操作void moveWriter(size_t len);private:vector<char> _buffer;size_t _reader_idx;//当前可读数据的指针--本质是下标size_t _writer_idx;//当前可写数据的指针};接口的实现
//这是100M#define DEFAULT_BUFFER_SIZE (1024*1024*100)#define THRESHOLD_BUFFER_SIZE (80*1024*100) //阈值#define INCREMENT_BUFFER_SIZE (10*1024*100) //增量//创建一个缓冲区bufferclass Buffer{public://提前开好空间,vector不用析构了Buffer(): _buffer(DEFAULT_BUFFER_SIZE), _reader_idx(0), _writer_idx(0) {}//向缓冲区中写入数据void push(const char *data, size_t len){//缓冲区剩余空间不够的情况:1.扩容。2.阻塞/返回false//1.固定大小,则直接返回if(len > writeAbleSize()) return ;//2.动态空间,用于极限性能测试--扩容ensureEnoughSize(len);//1.将数据拷贝进缓冲区copy(data, data+len, &_buffer[_writer_idx]);//2.将当前写入位置向后偏移moveWriter(len);}size_t writeAbleSize()//可写的大小(范围){//对于扩容思路来说,不存在可写空间大小,因为总是可写//因此这个接口仅仅针对固定大小缓冲区提供return (_buffer.size() - _writer_idx);}//返回可读数据的起始地址const char* begin(){return &_buffer[_reader_idx];}//返回可读数据的长度size_t readAbleSize(){//因为当前实现的缓冲区设计思想是双缓冲区,处理完后就交换,所以不存在空间循环使用的return (_writer_idx - _reader_idx);}//对读写指针进行向后偏移操作void moveReader(size_t len){assert(len <= readAbleSize());_reader_idx += len;}//重置读写位置,初始化缓冲区void reset(){_writer_idx = 0;//缓冲区所有空间都是空闲的_reader_idx = 0;//与_writer_idx相等表示没有数据可读}//对Buffer进行交换操作void swap(Buffer &buffer){_buffer.swap(buffer._buffer);std::swap(_reader_idx, buffer._reader_idx);//标注好是std里的还是自己ljwlog里的std::swap(_writer_idx, buffer._writer_idx);}//判断缓冲区是否为空,为空就不交换bool empty(){return (_reader_idx == _writer_idx);}private://对空间进行扩容void ensureEnoughSize(size_t len){if(len < writeAbleSize()) return ;//不需要扩容size_t new_size = 0;if(_buffer.size() < THRESHOLD_BUFFER_SIZE){new_size = _buffer.size()*2;//小于阈值则翻倍增长}else{new_size = _buffer.size() + INCREMENT_BUFFER_SIZE;//否则线性增长}_buffer.resize(new_size);}private://对读写指针进行向后偏移操作void moveWriter(size_t len){assert((len + _writer_idx) <= _buffer.size());_writer_idx += len;}private:vector<char> _buffer;size_t _reader_idx;//当前可读数据的指针--本质是下标size_t _writer_idx;//当前可写数据的指针};测试:
要先确保有logfile这个目录并且目录里有test.log,test.log里放了
![]()
![]()
思路

int main()
{//读取文件数据,一点一点的写入缓冲区,最终将缓冲区数据写入文件,判断生成的新文件与源文件是否一致ifstream ifs("./logfile/test.log", ios::binary);if(ifs.is_open() == false) { cout<< "open faild\n"; return -1;}ifs.seekg(0, ios::end);//读写位置跳转到文件末尾size_t fsize = ifs.tellg();//获取当前读写位置相对于起始位置的偏移量ifs.seekg(0, ios::beg);//重新跳转到起始位置string body;body.resize(fsize);ifs.read(&body[0], fsize);if(ifs.good() == false) {cout<< "read error\n"; return -1;}ifs.close();cout<< fsize << endl;ljwlog::Buffer buffer;for(int i = 0; i < body.size(); i++){buffer.push(&body[i], 1);}cout<< buffer.readAbleSize() <<endl;ofstream ofs("./logfile/tmp.log", ios::binary);//逐字节写入的错误原因是因为readAbleSize是逐渐变小的,i++双向靠近size_t rsize = buffer.readAbleSize();//逐字节写入for(int i = 0; i < rsize; i++){ofs.write(buffer.begin(), 1);//每次写入一个字节if(ofs.good() == false) {cout<< "write error!\n"; return -1;}buffer.moveReader(1);}ofs.close();return 0;
}


7.8 异步⽇志器(AsyncLogger)设计
异步⽇志器类继承⾃⽇志器类,并在同步⽇志器类上拓展了异步消息处理器。当我们需要异步输出⽇志的时候,需要创建异步⽇志器和消息处理器,调⽤异步⽇志器的log、error、info、fatal等函数输出不同级别⽇志。
• log函数为重写Logger类的函数,主要实现将⽇志数据加⼊异步队列缓冲区中
• realLog函数主要由异步线程进⾏调⽤(是为异步消息处理器设置的回调函数),完成⽇志的实际落地⼯作。



![]()
/*实现异步工作器*/
#pragma once
#include"buffer.hpp"
#include<thread>
#include<mutex>
#include<functional>
#include<memory>
#include<atomic>
#include<condition_variable>
using namespace std;namespace ljwlog
{using Functor = function<void(Buffer &)>;enum class AsyncType{ASYNC_SAFE,//安全状态,表示缓冲区满了则阻塞,避免资源耗尽的风险ASUNC_UNSAFE//不考虑资源耗尽的问题,无线扩容,常用于测试};class AsyncLooper{public:using ptr = shared_ptr<AsyncLooper>;AsyncLooper(const Functor &cb, AsyncType loop_type = AsyncType::ASYNC_SAFE):_looper_type(loop_type),_stop(false),_thread(thread(&AsyncLooper::threadEntry, this)),_callBack(cb){}~AsyncLooper(){stop();}void stop(){_stop = true;//将退出标志设置为true_cond_con.notify_all();//唤醒所有的工作线程_thread.join();//等待工作线程的退出}void push(const char* data, size_t len){ //1.无限扩容-非安全; 2.固定大小--生产缓冲区中数据满了就阻塞unique_lock<mutex> lock(_mutex);//条件变量为空值,若缓冲区剩余空间大小大于数据长度,则可以添加数据if(_looper_type == AsyncType::ASYNC_SAFE){_cond_pro.wait(lock, [&](){return _pro_buf.writeAbleSize() >= len;});}//如果我是安全工作器(满了就阻塞),不安全满了就扩容可能会出现溢出 非安全的就注释掉下面这句//条件变量空置,若缓冲区剩余空间大小大于数据长度,则可以添加数据//_cond_pro.wait(lock, [&](){ return _pro_buf.writeAbleSize() >= len;});//能够走下来代表满足了条件,可以向缓冲区添加数据_pro_buf.push(data, len);//唤醒消费者对缓冲区中的数据进行处理_cond_con.notify_one();}private://线程入口函数--对消费者缓冲区中的数据进行处理,处理完毕后,初始化缓冲区,交换缓冲区void threadEntry(){while(!_stop){//1.判断生产缓冲区有没有数据,有则交换,无则阻塞//用{}设置一个生命周期,交换完数据就可以解锁了,生产者就可以往生产缓冲区里放入数据了//为互斥锁设置一个生命周期,当缓冲区交换完毕后就解锁(并不对数据的处理过程加锁保护){unique_lock<mutex> lock(_mutex);//若当前是退出前被唤醒,或者有数据被唤醒,则返回真,继续向下运行,否则重新陷入休眠_cond_con.wait(lock, [&](){return _stop || !_pro_buf.empty();});_con_buf.swap(_pro_buf);//2.交换完就可以唤醒生产者了// 不是安全状态就不需要唤醒了,因为无线扩容不阻塞,没啥好唤醒的if(_looper_type == AsyncType::ASUNC_UNSAFE){_cond_pro.notify_all();} }//3.被唤醒后,对消费缓冲区进行数据处理_callBack(_con_buf);//4.初始化消费者缓冲区_con_buf.reset();}}private:Functor _callBack;private:AsyncType _looper_type;atomic<bool> _stop;//工作停止标志Buffer _pro_buf;//生产缓冲区Buffer _con_buf;//消费缓冲区mutex _mutex;condition_variable _cond_pro;//生产者条件变量condition_variable _cond_con;//消费者条件变量thread _thread;//异步工作器对应的工作线程};
}以后looper.hpp处理安全还是不安全了,buffer只管往缓冲区写入就好了,解耦合了
在logger.hhp的更改

//从loop.hpp里拓展的异步class AsyncLogger : public Logger{public:AsyncLogger(const string &logger_name, LogLevel::value level,Formatter::ptr &formatter,vector<LogSink::ptr>&sinks,AsyncType looper_type):Logger(logger_name, level, formatter, sinks),//bind绑定,因为只需要传进去一个参数,//绑定一下只需要传进去一个参数就可以了(buf)_looper(make_shared<AsyncLooper>(bind(&AsyncLogger::realLog, this, placeholders::_1), looper_type)){}void log(const char* data, size_t len);//将数据写入缓冲区//设计一个实际落地函数(将缓冲区中的数据落地)void realLog(Buffer &buf){if(_sinks.empty()) return ;for(auto &sink : _sinks){sink->log(buf.begin(), buf.readAbleSize());}}private:AsyncLooper::ptr _looper;};


异步工作器测试:
#include "format.hpp"
#include "level.hpp"
#include "util.hpp"
#include "message.hpp"
#include "sink.hpp"
#include "logger.hpp"
#include "buffer.hpp"
#include "loop.hpp"
#include<unistd.h>int main()
{//异步日志器的测试unique_ptr<ljwlog::LoggerBuilder> builder(new ljwlog::LocalLoggerBuilder());builder->buildLoggerName("async_logger");builder->buildLoggerLevel(ljwlog::LogLevel::value::WARN);builder->buildFormatter("%m%n");builder->buildLoggerType(ljwlog::LoggerType::LOGGER_ASTNC);//异步builder->buildSink<ljwlog::FileSink>("./logfile/async.log");builder->buildSink<ljwlog::StdoutSink>();ljwlog::Logger::ptr logger = builder->build();logger->debug(__FILE__, __LINE__, "%s", "测试日志");logger->info(__FILE__, __LINE__, "%s", "测试日志");logger->warn(__FILE__, __LINE__, "%s", "测试日志");logger->error(__FILE__, __LINE__, "%s", "测试日志");logger->fatal(__FILE__, __LINE__, "%s", "测试日志");size_t cursize = 0; size_t count = 0;while (cursize <= 1024 * 1024 * 10){logger->fatal(__FILE__, __LINE__, "测试日志--%d", count++);cursize += 20;}return 0;
}
启动一个非安全的异步


这里换成1

思路:
7.9 单例日志器管理类设计(单例模式)
日志的输出,我们希望能够在任意位置都可以进行,但是当我们创建了一个日志器之后,就会受到日志器所在作用域的访问属性限制。因此,为了突破访问区域的限制,我们创建一个日志器管理类,且这个类是一个单例类,这样的话,我们就可以在任意位置来通过管理器单例获取到指定的日志器来进行日志输出了。基于单例日志器管理器的设计思想,我们对于日志器建造者类进行继承,继承出一个全局日志器建造者类,实现一个日志器在创建完毕后,直接将其添加到单例的日志器管理器中,以便于能够在任何位置通过日志器名称能够获取到指定的日志器进行日志输出。


单例模式

![]()
加一个函数

//设计用懒汉方式的单例模式class LoggerManager{public:static LoggerManager& getInstance(){//最简单的懒汉单例,C++11才支持,这里是线程安全的static LoggerManager eton;return eton;}void addLogger(Logger::ptr &logger)//完成日志器的添加 {//存在添加不存在不添加if(hasLogger(logger->name())){return;}unique_lock<mutex> lock(_mutex);_loggers.insert(make_pair(logger->name(), logger));//完成日志器的添加 }bool hasLogger(const string &name){unique_lock<mutex> lock(_mutex);auto it = _loggers.find(name);if(it == _loggers.end()){return false;}return true;}Logger::ptr getLogger(const string &name){unique_lock<mutex> lock(_mutex);auto it = _loggers.find(name);if(it == _loggers.end()){return Logger::ptr();//传一个空的日志}//存在就返回存在的日志器return it->second;}Logger::ptr rootLogger(){return _root_logger;}private://构造私有LoggerManager(){unique_ptr<ljwlog::LoggerBuilder> builder(new ljwlog::LocalLoggerBuilder());builder->buildLoggerName("root");_root_logger = builder->build();_loggers.insert(make_pair("root", _root_logger));}private:mutex _mutex;Logger::ptr _root_logger;//默认日志器//用哈希表unordered_map<string, Logger::ptr> _loggers;};局部日志器哪里创建哪里使用
![]()


//设计一个全局日志器的建造者--在局部的基础上增加了一个功能:将日志器添加到单例对象中class GlobalLoggerBuilder : public LoggerBuilder{public:Logger::ptr build() override{assert(_logger_name.empty() == false);//必须有日志器名称if(_formatter.get() == nullptr){_formatter = make_shared<Formatter>();}if(_sinks.empty()){buildSink<StdoutSink>();}Logger::ptr logger;//异步的返回if(_logger_type == LoggerType::LOGGER_ASTNC){logger = make_shared<AsyncLogger>(_logger_name, _limit_level, _formatter, _sinks, _looper_type);}else{logger = make_shared<SyncLogger>(_logger_name, _limit_level, _formatter, _sinks);}//返回之前添加到单例对象里LoggerManager::getInstance().addLogger(logger);return logger;}};测试:
void test_log()
{ljwlog::Logger::ptr logger = ljwlog::LoggerManager::getInstance().getLogger("async_logger");logger->debug(__FILE__, __LINE__, "%s", "测试日志");logger->info(__FILE__, __LINE__, "%s", "测试日志");logger->warn(__FILE__, __LINE__, "%s", "测试日志");logger->error(__FILE__, __LINE__, "%s", "测试日志");logger->fatal(__FILE__, __LINE__, "%s", "测试日志");size_t count = 0;while (count <= 500000){logger->fatal(__FILE__, __LINE__, "测试日志--%d", count++);}
}int main()
{unique_ptr<ljwlog::LoggerBuilder> builder(new ljwlog::GlobalLoggerBuilder());builder->buildLoggerName("async_logger");builder->buildLoggerLevel(ljwlog::LogLevel::value::WARN);builder->buildFormatter("[%c][%f:%l]%m%n");builder->buildLoggerType(ljwlog::LoggerType::LOGGER_ASTNC);//异步builder->buildEnableUnSafeAsync();//启动一个非安全的异步//注意:启动之后要把loop.hpp中的while(!_stop)改成while(1)builder->buildSink<ljwlog::FileSink>("./logfile/async.log");builder->buildSink<ljwlog::StdoutSink>();builder->build();test_log();return 0;
}
7.10日志宏&全局接口设计 (代理模式)
提供全局的日志器获取接口
使用代理模式通过全局函数或宏函数来代理Logger类的log、debug、info warnerror、fatal等接
口,以便于控制源码文件名称和行号的输出控制,简化用户操作。
当仅需标准输出日志的时候可以通过主日志器来打印日志。 且操作时只需要通过宏函数直接进行输出即可。

![]()
#pragma once#include"logger.hpp"
#include<unistd.h>
namespace ljwlog
{ //1.提供获取指定日志器的全局接口(避免用户自己作单例对象)Logger::ptr getLogger(const string &name){return ljwlog::LoggerManager::getInstance().getLogger(name);}Logger::ptr rootLogger(const string &name){return ljwlog::LoggerManager::getInstance().rootLogger();}//2.使用宏函数对日志器的接口进行代理(代理模式)//这个宏的功能就是 ,用户在传的时候只需要传两个参数,最终编译的时候进行预处理的时候呢,//就会将debug(fmt, ...)替换成debug(__FILE。。。。),,自动会传入文件名和行号#define debug(fmt, ...) debug(__FILE__, __LINE__, fmt, ##__VA_ARGS__)#define info(fmt, ...) info(__FILE__, __LINE__, fmt, ##__VA_ARGS__)#define warn(fmt, ...) warn(__FILE__, __LINE__, fmt, ##__VA_ARGS__)#define error(fmt, ...) error(__FILE__, __LINE__, fmt, ##__VA_ARGS__)#define fatal(fmt, ...) fatal(__FILE__, __LINE__, fmt, ##__VA_ARGS__)//3.提供宏函数,直接通过默认日志器进行日志的标准输出打印(不用获取日志器了)#define DEBUG(fmt, ...) ljwlog::rootLogger()->debug(fmt, ##__VA_ARGS__)#define INFO(fmt, ...) ljwlog::rootLogger()->info(fmt, ##__VA_ARGS__)#define WARN(fmt, ...) ljwlog::rootLogger()->warn(fmt, ##__VA_ARGS__)#define ERROR(fmt, ...) ljwlog::rootLogger()->error(fmt, ##__VA_ARGS__)#define FATAL(fmt, ...) ljwlog::rootLogger()->fatal(fmt, ##__VA_ARGS__)
}测试1:
void test_log11()
{ljwlog::Logger::ptr logger = ljwlog::LoggerManager::getInstance().getLogger("async_logger");logger->debug("%s", "测试日志");logger->info("%s", "测试日志");logger->warn("%s", "测试日志");logger->error("%s", "测试日志");logger->fatal("%s", "测试日志");size_t count = 0;while (count <= 500000){logger->fatal("测试日志--%d", count++);}}int main()
{unique_ptr<ljwlog::LoggerBuilder> builder(new ljwlog::GlobalLoggerBuilder());builder->buildLoggerName("async_logger");builder->buildLoggerLevel(ljwlog::LogLevel::value::WARN);builder->buildFormatter("[%c][%f:%l]%m%n");builder->buildLoggerType(ljwlog::LoggerType::LOGGER_ASTNC);//异步builder->buildEnableUnSafeAsync();//启动一个非安全的异步//注意:启动之后要把loop.hpp中 //的while(!_stop)改成while(1)builder->buildSink<ljwlog::FileSink>("./logfile/async.log");builder->buildSink<ljwlog::StdoutSink>();builder->build();test_log11();return 0;
}

测试2:
void test_log11()
{ljwlog::Logger::ptr logger = ljwlog::LoggerManager::getInstance().getLogger("async_logger");DEBUG("%s", "测试日志");INFO("%s", "测试日志");WARN("%s", "测试日志");ERROR("%s", "测试日志");FATAL("%s", "测试日志");size_t count = 0;while (count <= 500000){FATAL("测试日志--%d", count++);}
}int main()
{unique_ptr<ljwlog::LoggerBuilder> builder(new ljwlog::GlobalLoggerBuilder());builder->buildLoggerName("async_logger");builder->buildLoggerLevel(ljwlog::LogLevel::value::WARN);builder->buildFormatter("[%c][%f:%l]%m%n");builder->buildLoggerType(ljwlog::LoggerType::LOGGER_ASTNC);//异步builder->buildEnableUnSafeAsync();//启动一个非安全的异步//注意:启动之后要把loop.hpp中的 //while(!_stop)改成while(1)builder->buildSink<ljwlog::FileSink>("./logfile/async.log");builder->buildSink<ljwlog::StdoutSink>();builder->build();test_log11();return 0;
}

测试3:
void test_log11()
{ljwlog::Logger::ptr logger = ljwlog::LoggerManager::getInstance().getLogger("async_logger");logger->debug("%s", "测试日志");logger->info("%s", "测试日志");logger->warn("%s", "测试日志");logger->error("%s", "测试日志");logger->fatal("%s", "测试日志");DEBUG("%s", "测试日志");INFO("%s", "测试日志");WARN("%s", "测试日志");ERROR("%s", "测试日志");FATAL("%s", "测试日志");
}int main()
{unique_ptr<ljwlog::LoggerBuilder> builder(new ljwlog::GlobalLoggerBuilder());builder->buildLoggerName("async_logger");builder->buildLoggerLevel(ljwlog::LogLevel::value::WARN);builder->buildFormatter("[%c][%f:%l]%m%n");builder->buildLoggerType(ljwlog::LoggerType::LOGGER_ASTNC);//异步builder->buildEnableUnSafeAsync();//启动一个非安全的异步//注意:启动之后要把loop.hpp中的 //while(!_stop)改成while(1)builder->buildSink<ljwlog::FileSink>("./logfile/async.log");builder->buildSink<ljwlog::StdoutSink>();builder->build();test_log11();return 0;
}打印现象是不同的





测试4:
void test_log11()
{DEBUG("%s", "测试日志");INFO("%s", "测试日志");WARN("%s", "测试日志");ERROR("%s", "测试日志");FATAL("%s", "测试日志");
}int main()
{test_log11();
}
8.目前为止代码基本完成

buffer.hpp
#pragma once
#include<vector>
#include<assert.h>
#include "util.hpp"
#include <algorithm> // copy函数的头文件
using namespace std;
/* 实现异步日志缓冲区 */namespace ljwlog
{//这是100M#define DEFAULT_BUFFER_SIZE (1024*1024*100)#define THRESHOLD_BUFFER_SIZE (80*1024*100) //阈值#define INCREMENT_BUFFER_SIZE (10*1024*100) //增量//创建一个缓冲区bufferclass Buffer{public://提前开好空间,vector不用析构了Buffer(): _buffer(DEFAULT_BUFFER_SIZE), _reader_idx(0), _writer_idx(0) {}//向缓冲区中写入数据void push(const char *data, size_t len){//1.考虑空间不够则扩容ensureEnoughSize(len);//缓冲区剩余空间不够的情况:1.扩容。2.阻塞/返回false//1.固定大小,则直接返回 //if(len > writeAbleSize()) return ; //2.动态空间,用于极限性能测试--扩容//ensureEnoughSize(len);//1.将数据拷贝进缓冲区copy(data, data+len, &_buffer[_writer_idx]);//2.将当前写入位置向后偏移moveWriter(len);}size_t writeAbleSize()//可写的大小(范围){//对于扩容思路来说,不存在可写空间大小,因为总是可写//因此这个接口仅仅针对固定大小缓冲区提供return (_buffer.size() - _writer_idx);}//返回可读数据的起始地址const char* begin(){return &_buffer[_reader_idx];}//返回可读数据的长度size_t readAbleSize(){//因为当前实现的缓冲区设计思想是双缓冲区,处理完后就交换,所以不存在空间循环使用的return (_writer_idx - _reader_idx);}//对读写指针进行向后偏移操作void moveReader(size_t len){assert(len <= readAbleSize());_reader_idx += len;}//重置读写位置,初始化缓冲区void reset(){_writer_idx = 0;//缓冲区所有空间都是空闲的_reader_idx = 0;//与_writer_idx相等表示没有数据可读}//对Buffer进行交换操作void swap(Buffer &buffer){_buffer.swap(buffer._buffer);std::swap(_reader_idx, buffer._reader_idx);//标注好是std里的还是自己ljwlog里的std::swap(_writer_idx, buffer._writer_idx);}//判断缓冲区是否为空,为空就不交换bool empty(){return (_reader_idx == _writer_idx);}private://对空间进行扩容void ensureEnoughSize(size_t len){if(len <= writeAbleSize()) return ;//不需要扩容size_t new_size = 0;if(_buffer.size() < THRESHOLD_BUFFER_SIZE){new_size = _buffer.size()*2 + len;//小于阈值则翻倍增长(确保增长空间后大于等于len)}else{new_size = _buffer.size() + INCREMENT_BUFFER_SIZE + len;//否则线性增长}_buffer.resize(new_size);}private://对读写指针进行向后偏移操作void moveWriter(size_t len){assert((len + _writer_idx) <= _buffer.size());_writer_idx += len;}private:vector<char> _buffer;size_t _reader_idx;//当前可读数据的指针--本质是下标size_t _writer_idx;//当前可写数据的指针};
}format.hpp
#pragma once#include "message.hpp"
#include "level.hpp"
#include "util.hpp"
#include <memory>
#include <iostream>
#include <ctime>
#include <assert.h>
#include <string>
#include <vector>
#include <sstream>
using namespace std;
namespace ljwlog
{// 抽象格式化子项基类class FormatItem{public:using ptr = shared_ptr<FormatItem>;virtual void format(ostream &out, LogMsg &msg) = 0;};// 派生格式化子项类--消息,等级,时间,文件名,行号,线程ID,日志器名,制表符,换行,其他class MsgFormatItem : public FormatItem{public:void format(ostream &out, LogMsg &msg) override{out << msg._payload;}};class LevelFormatItem : public FormatItem{public:void format(ostream &out, LogMsg &msg) override{out << LogLevel::toString(msg._level);}};class TimeFormatItem : public FormatItem{public:TimeFormatItem(const string &fmt = "%H:%M:%S"): _time_fmt(fmt){} void format(ostream &out, LogMsg &msg) override{struct tm t;localtime_r(&msg._ctime, &t);char tmp[32] = "0";strftime(tmp, 31, _time_fmt.c_str(), &t);out << tmp;}private:string _time_fmt; //%H:%M:%S};class FileFormatItem : public FormatItem{public:void format(ostream &out, LogMsg &msg) override{out << msg._file;}};//日志器名称class LoggerFormatItem : public FormatItem{public:void format(ostream &out, LogMsg &msg) override{out << msg._logger;}};class LineFormatItem : public FormatItem{public:void format(ostream &out, LogMsg &msg) override{out << msg._line;}};//制表符缩进class TabFormatItem : public FormatItem{public:void format(ostream &out, LogMsg &msg) override{out << "\t";}};class NLineFormatItem : public FormatItem{public:void format(ostream &out,LogMsg &msg) override{out << "\n";}};class OtherFormatItem : public FormatItem{private:std::string _str;public:OtherFormatItem(const string &str):_str(str){}void format(ostream &out,LogMsg &msg) override{out << _str;}};class ThreadFormatItem : public FormatItem{public:void format(ostream &out, LogMsg &msg) override{out << msg._tid;}};/*%d ⽇期%T 缩进%t 线程id%p ⽇志级别%c ⽇志器名称%f ⽂件名%l ⾏号%m ⽇志消息%n 换⾏*/class Formatter{public:using ptr = shared_ptr<Formatter>;// 模式 %b%%cde[%d{%H%M%S}][%p]%T%m%n//[%d{%H:%M:%S}][%t][%c][%f:%l][%p]%T%M%NFormatter(const string &pattern = "[%d{%H:%M:%S}][%t][%p][%c][%f:%l]%m%n") : _pattern(pattern){assert(parsePattern());}// 对msg进行格式化void format(ostream &out, LogMsg &msg){for (auto &item : _items){item->format(out, msg);}}string format(LogMsg &msg){stringstream ss;format(ss, msg);return ss.str();}private:// 对格式化规则字符串进行解析bool parsePattern(){// 1.对格式化规则字符串进行解析// %cab%%cde[%d{%H%M%S}][%p]%T%m%nstd::cout << "pattern: " << _pattern << std::endl;vector<pair<string, string>> fmt_order;size_t pos = 0;string key, val;while (pos < _pattern.size()){// 1.处理原始字符串--判断是否是%,不是就是原始字符,然后继续返回找%if (_pattern[pos] != '%'){val.push_back(_pattern[pos++]);continue;}// 能到这说明pos位置就是%字符,%%处理称为一个原始%字符if (pos + 1 < _pattern.size() && _pattern[pos + 1] == '%'){val.push_back('%');pos += 2;continue;}// 能走到这里,代表%后面是个格式化字符,代表原始字符处理完毕if (val.empty() == false){fmt_order.push_back(make_pair("", val));val.clear();}//这时候pos指向的是%位置,是格式化字符的处理pos += 1;//这一步之后,pos指向格式化字符位置if(pos == _pattern.size()){cout<< "%之后,没有对应的格式化字符\n";return false;}key = _pattern[pos];pos += 1;//这时候pos指向格式化字符后的位置if (pos < _pattern.size() && _pattern[pos] == '{'){pos += 1; // 这时候pos指向子规则的起始位置while (pos < _pattern.size() && _pattern[pos] != '}'){val.push_back(_pattern[pos++]);}// 走到了末尾跳出了循环,则代表没有遇到},则说明格式是错误的if (pos == _pattern.size()){cout << "子规则{}匹配错误!\n";return false; // 没有找到}}pos += 1;//因为这时候pos指向的是}位置,向后走一步,走到了一次处理的新位置。}fmt_order.push_back(make_pair(key, val));key.clear();val.clear();}//2.根据解析得到的数据初始化格式化子项数组成员 for(auto &it : fmt_order){_items.push_back(createItem(it.first, it.second));}return true;}private:// 根据不同的格式化字符创建不同的格式化子项对象FormatItem::ptr createItem(const string &key, const string &val){/*%d ⽇期%t 线程id%c ⽇志器名称%f ⽂件名%l ⾏号%p ⽇志级别%T 缩进%m ⽇志消息%n 换⾏*/// 只有第一个需要参数if (key == "d")return make_shared<TimeFormatItem>(val);if (key == "t")return make_shared<ThreadFormatItem>();if (key == "c")return make_shared<LoggerFormatItem>();if (key == "f")return make_shared<FileFormatItem>();if (key == "l")return make_shared<LineFormatItem>();if (key == "p")return make_shared<LevelFormatItem>();if (key == "T")return make_shared<TabFormatItem>();if (key == "m")return make_shared<MsgFormatItem>();if (key == "n")return make_shared<NLineFormatItem>();if(key == "")return make_shared<OtherFormatItem>(val);cout<< "没有对应的格式化字符:%" << key << endl;abort();}private:string _pattern;vector<FormatItem::ptr> _items;};
}
level.hpp
/*
• OFF关闭所有⽇志输出• DRBUG进⾏debug时候打印⽇志的等级• INFO打印⼀些⽤⼾提⽰信息• WARN打印警告信息• ERROR打印错误信息• FATAL打印致命信息-导致程序崩溃的信息
*/
#pragma once
namespace ljwlog
{class LogLevel{public:enum class value{UNKNOW = 0,DEBUG,INFO,WARN,ERROR,FATAL,OFF};static const char* toString(LogLevel::value level){switch(level){case LogLevel::value::DEBUG: return "DEBUG";case LogLevel::value::INFO: return "INFO";case LogLevel::value::WARN: return "WARN";case LogLevel::value::ERROR: return "ERROR";case LogLevel::value::FATAL: return "FATAL";case LogLevel::value::OFF: return "OFF";}return "UNKNOW";}};
}
ljwlog.h
#pragma once#include"logger.hpp"
#include<unistd.h>
namespace ljwlog
{ //1.提供获取指定日志器的全局接口(避免用户自己作单例对象)Logger::ptr getLogger(const string &name){return ljwlog::LoggerManager::getInstance().getLogger(name);}Logger::ptr rootLogger(){return ljwlog::LoggerManager::getInstance().rootLogger();}//2.使用宏函数对日志器的接口进行代理(代理模式)//这个宏的功能就是 ,用户在传的时候只需要传两个参数,最终编译的时候进行预处理的时候呢,//就会将debug(fmt, ...)替换成debug(__FILE。。。。),,自动会传入文件名和行号#define debug(fmt, ...) debug(__FILE__, __LINE__, fmt, ##__VA_ARGS__)#define info(fmt, ...) info(__FILE__, __LINE__, fmt, ##__VA_ARGS__)#define warn(fmt, ...) warn(__FILE__, __LINE__, fmt, ##__VA_ARGS__)#define error(fmt, ...) error(__FILE__, __LINE__, fmt, ##__VA_ARGS__)#define fatal(fmt, ...) fatal(__FILE__, __LINE__, fmt, ##__VA_ARGS__)//3.提供宏函数,直接通过默认日志器进行日志的标准输出打印(不用获取日志器了)#define DEBUG(fmt, ...) ljwlog::rootLogger()->debug(fmt, ##__VA_ARGS__)#define INFO(fmt, ...) ljwlog::rootLogger()->info(fmt, ##__VA_ARGS__)#define WARN(fmt, ...) ljwlog::rootLogger()->warn(fmt, ##__VA_ARGS__)#define ERROR(fmt, ...) ljwlog::rootLogger()->error(fmt, ##__VA_ARGS__)#define FATAL(fmt, ...) ljwlog::rootLogger()->fatal(fmt, ##__VA_ARGS__)
}logger.hpp
#pragma once
#include "util.hpp"
#include "level.hpp"
#include "format.hpp"
#include "sink.hpp"
#include "loop.hpp"
#include<string>
#include<atomic>
#include<thread>
#include<vector>
#include<mutex>
#include <stdarg.h>
#include <functional>
#include<unordered_map>
#include <assert.h>
using namespace std;
namespace ljwlog
{class Logger{public:using ptr = shared_ptr<Logger>;Logger(const string &logger_name, LogLevel::value level, Formatter::ptr formatter,vector<LogSink::ptr> &sinks):_logger_name(logger_name),_limit_level(level),_formater(formatter),_sinks(sinks.begin(), sinks.end()){}const string &name() {return _logger_name;}//完成构造日志消息对象过程并进行格式化,得到格式化后的日志消息字符串--然后进行落地输出void debug(const string& file, size_t line, const string& fmt, ...){//通过传入的参数构造出一个日志消息对象,进行日志的格式化,最终落地//1.判断当前的日志是否达到了输出等级if(LogLevel::value::DEBUG < _limit_level) { return ;}//2.对fmt格式化字符和不定参进行字符串组织,得到的日志消息的字符串va_list ap;va_start(ap, fmt);char* res;//属于动态申请int ret = vasprintf(&res, fmt.c_str(), ap);if(ret == -1){cout<< "vasprintf faild!!!!!\n";return ;}va_end(ap);//将ap指针置空//序列化serialization(LogLevel::value::DEBUG, file, line, res);free(res);}void info(const string& file, size_t line, const string& fmt, ...){//通过传入的参数构造出一个日志消息对象,进行日志的格式化,最终落地//1.判断当前的日志是否达到了输出等级if(LogLevel::value::INFO < _limit_level) { return ;}//2.对fmt格式化字符和不定参进行字符串组织,得到的日志消息的字符串va_list ap;va_start(ap, fmt);char* res;//属于动态申请int ret = vasprintf(&res, fmt.c_str(), ap);if(ret == -1){cout<< "vasprintf faild!!!!!\n";return ;}va_end(ap);//将ap指针置空//序列化serialization(LogLevel::value::INFO, file, line, res);free(res); }void warn(const string& file, size_t line, const string& fmt, ...){//通过传入的参数构造出一个日志消息对象,进行日志的格式化,最终落地//1.判断当前的日志是否达到了输出等级if(LogLevel::value::WARN < _limit_level) { return ;}//2.对fmt格式化字符和不定参进行字符串组织,得到的日志消息的字符串va_list ap;va_start(ap, fmt);char* res;//属于动态申请int ret = vasprintf(&res, fmt.c_str(), ap);if(ret == -1){cout<< "vasprintf faild!!!!!\n";return ;}va_end(ap);//将ap指针置空//序列化serialization(LogLevel::value::WARN, file, line, res);free(res); }void error(const string& file, size_t line, const string& fmt, ...){//通过传入的参数构造出一个日志消息对象,进行日志的格式化,最终落地//1.判断当前的日志是否达到了输出等级if(LogLevel::value::ERROR < _limit_level) { return ;}//2.对fmt格式化字符和不定参进行字符串组织,得到的日志消息的字符串va_list ap;va_start(ap, fmt);char* res;//属于动态申请int ret = vasprintf(&res, fmt.c_str(), ap);if(ret == -1){cout<< "vasprintf faild!!!!!\n";return ;}va_end(ap);//将ap指针置空//序列化serialization(LogLevel::value::ERROR, file, line, res);free(res); }void fatal(const string& file, size_t line, const string& fmt, ...){//通过传入的参数构造出一个日志消息对象,进行日志的格式化,最终落地//1.判断当前的日志是否达到了输出等级if(LogLevel::value::FATAL < _limit_level) { return ;}//2.对fmt格式化字符和不定参进行字符串组织,得到的日志消息的字符串va_list ap;va_start(ap, fmt);char* res;//属于动态申请int ret = vasprintf(&res, fmt.c_str(), ap);if(ret == -1){cout<< "vasprintf faild!!!!!\n";return ;}va_end(ap);//将ap指针置空//序列化serialization(LogLevel::value::FATAL, file, line, res);free(res); }protected://对日志序列化,为了方便使用,这样直接复制,serialization直接输入INFO就可以了void serialization(LogLevel::value level, const string &file, size_t line, char*str){//3.构造LogMsg对象LogMsg msg(level, line, file, _logger_name, str);//4.通过格式化工具对LogMsg进行格式化,得到格式化后的日志字符串stringstream ss;_formater->format(ss, msg);//5.进行日志落地log(ss.str().c_str(), ss.str().size());}private://抽象接口完成实际的落地输出--不同的日志器会有不同的实际落地方式//同步落地和异步落地,然后各自继承virtual void log(const char* data, size_t len) = 0;protected:mutex _mutex;//互斥锁string _logger_name;atomic<LogLevel::value> _limit_level;//等级限制Formatter::ptr _formater;//格式化vector<LogSink::ptr> _sinks;//日志落地方向};//同步class SyncLogger : public Logger{public:SyncLogger(const string &logger_name,LogLevel::value level,Formatter::ptr &formatter,vector<LogSink::ptr> &sinks):Logger(logger_name, level, formatter, sinks){}protected://同步日志器,是将日志直接通过落地模块句柄进行日志落地void log(const char* data, size_t len) override{unique_lock<mutex> lock(_mutex);if(_sinks.empty()) return ;for(auto &sink : _sinks){sink->log(data, len);}}};//从loop.hpp里拓展的异步class AsyncLogger : public Logger{public:AsyncLogger(const string &logger_name, LogLevel::value level,Formatter::ptr &formatter,vector<LogSink::ptr>&sinks,AsyncType looper_type):Logger(logger_name, level, formatter, sinks),//bind绑定,因为只需要传进去一个参数,//绑定一下只需要传进去一个参数就可以了(buf)_looper(make_shared<AsyncLooper>(bind(&AsyncLogger::realLog, this, placeholders::_1), looper_type)){}void log(const char* data, size_t len)//将数据写入缓冲区{_looper->push(data, len);}//设计一个实际落地函数(将缓冲区中的数据落地)void realLog(Buffer &buf){if(_sinks.empty()) return ;for(auto &sink : _sinks){sink->log(buf.begin(), buf.readAbleSize());}}private:AsyncLooper::ptr _looper;};enum class LoggerType{LOGGER_SYNC,//同步LOGGER_ASTNC//异步};//使用建造者模式来建造日志器,而不要让用户直接去构造日志器,简化用户的使用复杂度//1.抽象一个日志器建造者类//1.1设置日志器类型//1.2将不同类型的日志器的创建放到同一个日志器建造者类中完成class LoggerBuilder{public:LoggerBuilder():_logger_type(LoggerType::LOGGER_SYNC),//默认同步日志器_limit_level(LogLevel::value::DEBUG), //默认限制输出等级_looper_type(AsyncType::ASYNC_SAFE) //安不安全处理,扩不扩容,极限测试,异步的{}void buildLoggerType(LoggerType type) {_logger_type = type;}void buildEnableUnSafeAsync(){_looper_type = AsyncType::ASUNC_UNSAFE;}//异步的void buildLoggerName(const string &name) {_logger_name = name;}void buildLoggerLevel(LogLevel::value level) {_limit_level = level;}void buildFormatter(const string &pattern) {_formatter = make_shared<Formatter>(pattern);}template<class SinkType, class ...Args>void buildSink(Args &&...args){LogSink::ptr psink = SinkFactory::create<SinkType>(forward<Args>(args)...);_sinks.push_back(psink);}virtual Logger::ptr build() = 0;protected:LoggerType _logger_type;AsyncType _looper_type;string _logger_name;atomic<LogLevel::value> _limit_level;Formatter::ptr _formatter;vector<LogSink::ptr> _sinks;};//2.派生出具体的建造者类---局部日志器的建造者 & 全局日志器建造者(后边添加了全局单例管理之后,将日志器添加全局管理class LocalLoggerBuilder : public LoggerBuilder{public:Logger::ptr build() override{assert(_logger_name.empty() == false);//必须有日志器名称if(_formatter.get() == nullptr){_formatter = make_shared<Formatter>();}if(_sinks.empty()){buildSink<StdoutSink>();}//异步的返回if(_logger_type == LoggerType::LOGGER_ASTNC){return make_shared<AsyncLogger>(_logger_name, _limit_level, _formatter, _sinks, _looper_type);}return make_shared<SyncLogger>(_logger_name, _limit_level, _formatter, _sinks);}};//设计用懒汉方式的单例模式class LoggerManager{public:static LoggerManager& getInstance(){//最简单的懒汉单例,C++11才支持,这里是线程安全的static LoggerManager eton;return eton;}void addLogger(Logger::ptr &logger)//完成日志器的添加 {//存在添加不存在不添加if(hasLogger(logger->name())){return;}unique_lock<mutex> lock(_mutex);_loggers.insert(make_pair(logger->name(), logger));//完成日志器的添加 }bool hasLogger(const string &name){unique_lock<mutex> lock(_mutex);auto it = _loggers.find(name);if(it == _loggers.end()){return false;}return true;}Logger::ptr getLogger(const string &name){unique_lock<mutex> lock(_mutex);std::cout << name << std::endl;auto it = _loggers.find(name);if(it == _loggers.end()){return Logger::ptr();//传一个空的日志}//存在就返回存在的日志器return it->second;}Logger::ptr rootLogger(){return _root_logger;}private://构造私有LoggerManager(){//这里只能使用本地的建造者unique_ptr<ljwlog::LoggerBuilder> builder(new ljwlog::LocalLoggerBuilder());builder->buildLoggerName("root");_root_logger = builder->build();_loggers.insert(make_pair("root", _root_logger));}private:mutex _mutex;Logger::ptr _root_logger;//默认日志器//用哈希表unordered_map<string, Logger::ptr> _loggers;};//设计一个全局日志器的建造者--在局部的基础上增加了一个功能:将日志器添加到单例对象中class GlobalLoggerBuilder : public LoggerBuilder{public:Logger::ptr build() override{assert(_logger_name.empty() == false);//必须有日志器名称if(_formatter.get() == nullptr){_formatter = make_shared<Formatter>();}if(_sinks.empty()){buildSink<StdoutSink>();}Logger::ptr logger;//异步的返回if(_logger_type == LoggerType::LOGGER_ASTNC){logger = make_shared<AsyncLogger>(_logger_name, _limit_level, _formatter, _sinks, _looper_type);}else{logger = make_shared<SyncLogger>(_logger_name, _limit_level, _formatter, _sinks);}//返回之前添加到单例对象里LoggerManager::getInstance().addLogger(logger);return logger;}};}loop.hpp
/*实现异步工作器*/
#pragma once
#include"buffer.hpp"
#include<thread>
#include<mutex>
#include<functional>
#include<memory>
#include<atomic>
#include<condition_variable>
using namespace std;namespace ljwlog
{using Functor = function<void(Buffer &)>;enum class AsyncType{ASYNC_SAFE,//安全状态,表示缓冲区满了则阻塞,避免资源耗尽的风险ASUNC_UNSAFE//不考虑资源耗尽的问题,无线扩容,常用于测试};class AsyncLooper{public:using ptr = shared_ptr<AsyncLooper>;AsyncLooper(const Functor &cb, AsyncType loop_type = AsyncType::ASYNC_SAFE):_looper_type(loop_type),_stop(false),_thread(thread(&AsyncLooper::threadEntry, this)),_callBack(cb){}~AsyncLooper(){stop();}void stop(){_stop = true;//将退出标志设置为true_cond_con.notify_all();//唤醒所有的工作线程_thread.join();//等待工作线程的退出}void push(const char* data, size_t len){ //1.无限扩容-非安全; 2.固定大小--生产缓冲区中数据满了就阻塞unique_lock<mutex> lock(_mutex);//条件变量为空值,若缓冲区剩余空间大小大于数据长度,则可以添加数据if(_looper_type == AsyncType::ASYNC_SAFE){_cond_pro.wait(lock, [&](){return _pro_buf.writeAbleSize() >= len;});}//如果我是安全工作器(满了就阻塞),不安全满了就扩容可能会出现溢出 非安全的就注释掉下面这句//条件变量空置,若缓冲区剩余空间大小大于数据长度,则可以添加数据//_cond_pro.wait(lock, [&](){ return _pro_buf.writeAbleSize() >= len;});//能够走下来代表满足了条件,可以向缓冲区添加数据_pro_buf.push(data, len);//唤醒消费者对缓冲区中的数据进行处理_cond_con.notify_one();}private://线程入口函数--对消费者缓冲区中的数据进行处理,处理完毕后,初始化缓冲区,交换缓冲区void threadEntry(){//while(!_stop)//非安全的改成1while(1){//用{}设置一个生命周期,交换完数据就可以解锁了,生产者就可以往生产缓冲区里放入数据了//为互斥锁设置一个生命周期,当缓冲区交换完毕后就解锁(并不对数据的处理过程加锁保护){//1.判断生产缓冲区有没有数据,有则交换,无则阻塞unique_lock<mutex> lock(_mutex);//退出标志被设置,且生产缓冲区已无数据,这时候再退出,否则有可能会造成生产缓冲区中有数据,但是没有被完全处理if(_stop && _pro_buf.empty()) break;//若当前是退出前被唤醒,或者有数据被唤醒,则返回真,继续向下运行,否则重新陷入休眠_cond_con.wait(lock, [&](){return _stop || !_pro_buf.empty();});_con_buf.swap(_pro_buf);//2.交换完就可以唤醒生产者了// 不是安全状态就不需要唤醒了,因为无线扩容不阻塞,没啥好唤醒的if(_looper_type == AsyncType::ASUNC_UNSAFE){_cond_pro.notify_all();} }//3.被唤醒后,对消费缓冲区进行数据处理_callBack(_con_buf);//4.初始化消费者缓冲区_con_buf.reset();}}private:Functor _callBack;private:AsyncType _looper_type;atomic<bool> _stop;//工作停止标志Buffer _pro_buf;//生产缓冲区Buffer _con_buf;//消费缓冲区mutex _mutex;condition_variable _cond_pro;//生产者条件变量condition_variable _cond_con;//消费者条件变量thread _thread;//异步工作器对应的工作线程};
}makefile
test:test.ccg++ -o $@ $^ -lpthread -std=c++11 -g
.PHONY:clean
clean:rm -f testmessage.hpp
#pragma once
#include"level.hpp"
#include"util.hpp"
#include<iostream>
#include<memory>
#include<thread>
using namespace std;namespace ljwlog
{struct LogMsg{LogMsg(LogLevel::value level, size_t line,const string &file,const string &logger,const string msg):_ctime(util::Date::now()),_level(level),_line(line),_tid(this_thread::get_id()),_file(file),_logger(logger),_payload(msg){}time_t _ctime;//日志产生的时间戳LogLevel::value _level;//日志等级size_t _line;//行号thread::id _tid;//线程IDstring _file;//源码文件名string _logger;//日志器名称string _payload;//有效消息数据载荷};}
sink.hpp
#pragma once
#include "util.hpp"
#include <memory>
#include <string>
#include <fstream>
#include <iostream>
#include <cassert>
#include <sstream>
using namespace std;
namespace ljwlog
{class LogSink{public:using ptr = shared_ptr<LogSink>;virtual ~LogSink() {}virtual void log(const char *data, size_t len) = 0;};// 落地方向:标准输出class StdoutSink : public LogSink{public:// 将日志消息写入到标准输出void log(const char *data, size_t len) override{cout.write(data, len);}};// 落地方向:指定文件class FileSink : public LogSink{public:// 构造时传入文件名,并打开文件,将操作句柄管理起来FileSink(const string &pathname) : _pathname(pathname){// 1.创建日志文件所在的目录util::File::createDirectory(util::File::path(pathname));// 2.创建并打开日志文件,app是可追加方式_ofs.open(_pathname, ios::binary | ios::app);// 确保在读取文件时,处理好文件打开失败、读取错误等异常情况,以避免程序崩溃或数据损坏assert(_ofs.is_open());}// 将日志消息写入到标准输出void log(const char *data, size_t len) override{_ofs.write(data, len);assert(_ofs.good());}private:string _pathname;ofstream _ofs; // 标准输出};// 落地方向:滚动文件(以大小进行滚动)class RollBySizeSink : public LogSink{public:// 构造时传入文件名,并打开文件,将操作句柄管理起来RollBySizeSink(const string &basename, size_t max_size) :_basename(basename), _max_fsize(max_size), _cur_fsize(0), _name_count(0){string pathname = createNewFile();// 1.创建日志文件所在的目录util::File::createDirectory(util::File::path(pathname));// 2.创建并打开日志文件,app是可追加方式_ofs.open(pathname, ios::binary | ios::app);// 确保在读取文件时,处理好文件打开失败、读取错误等异常情况,以避免程序崩溃或数据损坏assert(_ofs.is_open());}//将日志消息写入到标准输出--写入前判断文件大小,超过了最大大小就要切换文件void log(const char* data, size_t len){if(_ofs.is_open() == false || _cur_fsize >= _max_fsize){//关闭原来的文件_ofs.close();string pathname = createNewFile();_ofs.open(pathname, ios::binary | ios::app);assert(_ofs.is_open());//新的文件,里面的内容要清零_cur_fsize = 0;}_ofs.write(data, len);assert(_ofs.good());_cur_fsize += len;}private://进行大小判断,超过指定大小则创建新文件string createNewFile(){//获取系统时间,以时间来构造文件名扩展名time_t t = util::Date::now();struct tm it;localtime_r(&t, &it);stringstream filename;filename << _basename;//文件目录filename << it.tm_year + 1900;filename << it.tm_mon + 1;filename << it.tm_mday;filename << it.tm_hour;filename << it.tm_min;filename << it.tm_sec;filename << "-";filename << _name_count++;//计数器++,方便打印看数filename << ".log";return filename.str();}private:// 通过基础文件名 + 扩展文件名(以时间生成)组成一个实际的当前输出文件名string _basename; // ./log/base- --> ./logs/base-200290912.logofstream _ofs; // 标准输出size_t _max_fsize; // 记录最大大小,当前文件超过了这个大小就要切换文件size_t _cur_fsize; // 记录当前文件已经写入的数据大小size_t _name_count;//计数器,弄一个计数器,要不然1秒就运行完了,名字又是用时间区分的,所以为了区分文件名加一个计数器};enum class TimeGap //Gap是间隔的意思{GAP_SECOND, //间隔多久切换一个文件GAP_MINUTE,GAP_HOUR,GAP_DAY,};// 落地方向:滚动文件(以时间间隔进行滚动)class RollByTimeSink : public ljwlog::LogSink{public:// 构造时传入文件名,并打开文件,将操作句柄管理起来RollByTimeSink(const string &basename, TimeGap gap_type) : _basename(basename){switch (gap_type){case TimeGap::GAP_SECOND: _gap_size = 1; break; //间隔一秒切换一个文件case TimeGap::GAP_MINUTE: _gap_size = 60; break;case TimeGap::GAP_HOUR: _gap_size = 3600; break;case TimeGap::GAP_DAY: _gap_size = 3600 * 24; break;}//获取当前是第几个时间段//当_gap_size为1的时候,任何数取模1都是0_cur_gap = _gap_size ==1 ? ljwlog::util::Date::now() : ljwlog::util::Date::now() % _gap_size;string filename = createNewFile();ljwlog::util::File::createDirectory(ljwlog::util::File::path(filename));_ofs.open(filename, ios::binary | ios::app);assert(_ofs.is_open());}// 将日志消息写入标准输出,判断当前时间是否是当前文件的时间段,不是则切换文件void log(const char *data, size_t len){time_t cur = ljwlog::util::Date::now();if(cur % _gap_size != _cur_gap){_ofs.close();string filename = createNewFile();_ofs.open(filename, ios::binary | ios::app);assert(_ofs.is_open());}_ofs.write(data, len);assert(_ofs.good());}string createNewFile() // ./logfile/roll--20241030152451.log {// 获取系统时间,以时间来构造文件名扩展名time_t t = ljwlog::util::Date::now();struct tm it;localtime_r(&t, &it);stringstream filename;filename << _basename; // 文件目录filename << it.tm_year + 1900;filename << it.tm_mon + 1;filename << it.tm_mday;filename << it.tm_hour;filename << it.tm_min;filename << it.tm_sec;filename << ".log";return filename.str();}private:string _basename;ofstream _ofs;size_t _cur_gap; // 当前时第几个时间段size_t _gap_size; // 时间段的大小};class SinkFactory{public:template<class SinkType, class ...Args>static LogSink::ptr create(Args && ...args){return make_shared<SinkType>(forward<Args>(args)...); }};
}
test.cc
#include "format.hpp"
#include "level.hpp"
#include "util.hpp"
#include "message.hpp"
#include "sink.hpp"
#include "logger.hpp"
#include "buffer.hpp"
#include "loop.hpp"
#include "ljwlog.h"
#include<unistd.h>void test_log()
{ljwlog::Logger::ptr logger = ljwlog::LoggerManager::getInstance().getLogger("async_logger");logger->debug(__FILE__, __LINE__, "%s", "测试日志");logger->info(__FILE__, __LINE__, "%s", "测试日志");logger->warn(__FILE__, __LINE__, "%s", "测试日志");logger->error(__FILE__, __LINE__, "%s", "测试日志");logger->fatal(__FILE__, __LINE__, "%s", "测试日志");// size_t count = 0;// while (count <= 500000)// {// logger->fatal(__FILE__, __LINE__, "测试日志--%d", count++);// }
}
void test_log11()
{ljwlog::Logger::ptr logger = ljwlog::LoggerManager::getInstance().getLogger("async_logger");logger->debug("%s", "测试日志");logger->info("%s", "测试日志");logger->warn("%s", "测试日志");logger->error("%s", "测试日志");logger->fatal("%s", "测试日志");// size_t count = 0;// while (count <= 500000)// {// logger->fatal("测试日志--%d", count++);// }DEBUG("%s", "测试日志");INFO("%s", "测试日志");WARN("%s", "测试日志");ERROR("%s", "测试日志");FATAL("%s", "测试日志");// size_t count = 0;// while (count <= 500000)// {// FATAL("测试日志--%d", count++);// }
}int main()
{unique_ptr<ljwlog::LoggerBuilder> builder(new ljwlog::GlobalLoggerBuilder());builder->buildLoggerName("async_logger");builder->buildLoggerLevel(ljwlog::LogLevel::value::WARN);builder->buildFormatter("[%c][%f:%l]%m%n");builder->buildLoggerType(ljwlog::LoggerType::LOGGER_ASTNC);//异步builder->buildEnableUnSafeAsync();//启动一个非安全的异步//注意:启动之后要把loop.hpp中的while(!_stop)改成while(1)builder->buildSink<ljwlog::FileSink>("./logfile/async.log");builder->buildSink<ljwlog::StdoutSink>();builder->build();test_log11();//test_log();//异步日志器的测试// unique_ptr<ljwlog::LoggerBuilder> builder(new ljwlog::LocalLoggerBuilder());// builder->buildLoggerName("async_logger");// builder->buildLoggerLevel(ljwlog::LogLevel::value::WARN);// builder->buildFormatter("[%c]%m%n");// builder->buildLoggerType(ljwlog::LoggerType::LOGGER_ASTNC);//异步// //builder->buildEnableUnSafeAsync();//启动一个非安全的异步// builder->buildSink<ljwlog::FileSink>("./logfile/async.log");// builder->buildSink<ljwlog::StdoutSink>();// ljwlog::Logger::ptr logger = builder->build();// logger->debug(__FILE__, __LINE__, "%s", "测试日志");// logger->info(__FILE__, __LINE__, "%s", "测试日志");// logger->warn(__FILE__, __LINE__, "%s", "测试日志");// logger->error(__FILE__, __LINE__, "%s", "测试日志");// logger->fatal(__FILE__, __LINE__, "%s", "测试日志");//size_t cursize = 0; size_t count = 0;// while (cursize <= 1024 * 1024 * 10)// {// logger->fatal(__FILE__, __LINE__, "测试日志--%d", count++);// cursize += 20;// }//启动一个非安全的异步// size_t count = 0;// while(count < 500000)// {// logger->fatal(__FILE__, __LINE__, "测试日志--%d", count++);// }// //读取文件数据,一点一点的写入缓冲区,最终将缓冲区数据写入文件,判断生成的新文件与源文件是否一致// ifstream ifs("./logfile/test.log", ios::binary);// if(ifs.is_open() == false) { cout<< "open faild\n"; return -1;}// ifs.seekg(0, ios::end);//读写位置跳转到文件末尾// size_t fsize = ifs.tellg();//获取当前读写位置相对于起始位置的偏移量// ifs.seekg(0, ios::beg);//重新跳转到起始位置// string body;// body.resize(fsize);// ifs.read(&body[0], fsize);// if(ifs.good() == false) {cout<< "read error\n"; return -1;}// ifs.close();// cout<< fsize << endl;// ljwlog::Buffer buffer;// for(int i = 0; i < body.size(); i++)// {// buffer.push(&body[i], 1);// }// cout<< buffer.readAbleSize() <<endl;// ofstream ofs("./logfile/tmp.log", ios::binary);// //一次性写入// ofs.write(buffer.begin(), buffer.readAbleSize());// //逐字节写入的错误原因是因为readAbleSize是逐渐变小的,i++双向靠近// size_t rsize = buffer.readAbleSize();// //逐字节写入// // for(int i = 0; i < rsize; i++)// // {// // ofs.write(buffer.begin(), 1);//每次写入一个字节// // if(ofs.good() == false) {cout<< "write error!\n"; return -1;}// // buffer.moveReader(1);// // }// ofs.close();// unique_ptr<ljwlog::LoggerBuilder> builder(new ljwlog::LocalLoggerBuilder());// builder->buildLoggerName("sync_logger");// builder->buildLoggerLevel(ljwlog::LogLevel::value::WARN);// builder->buildFormatter("%m%n");// builder->buildLoggerType(ljwlog::LoggerType::LOGGER_SYNC);// builder->buildSink<ljwlog::FileSink>("./logfile/test.log");// builder->buildSink<ljwlog::StdoutSink>();// ljwlog::Logger::ptr logger = builder->build();// logger->debug(__FILE__, __LINE__, "%s", "测试日志");// logger->info(__FILE__, __LINE__, "%s", "测试日志");// logger->warn(__FILE__, __LINE__, "%s", "测试日志");// logger->error(__FILE__, __LINE__, "%s", "测试日志");// logger->fatal(__FILE__, __LINE__, "%s", "测试日志");// size_t cursize = 0; size_t count = 0;// while (cursize <= 1024 * 1024 * 10)// {// logger->fatal(__FILE__, __LINE__, "测试日志--%d", count++);// cursize += 20;// }// string logger_name = "sync_logger";// ljwlog::LogLevel::value limit = ljwlog::LogLevel::value::WARN;//大于限制才输出显示// ljwlog::Formatter::ptr fmt(new ljwlog::Formatter("[%d{%H:%M:%S}][%t][%c][%f:%l][%p]%T%m%n"));// ljwlog::LogSink::ptr stdout_lsp = ljwlog::SinkFactory::create<ljwlog::StdoutSink>();// ljwlog::LogSink::ptr file_lsp = ljwlog::SinkFactory::create<ljwlog::FileSink>("./logfile/test.log");// ljwlog::LogSink::ptr roll_lsp = ljwlog::SinkFactory::create<ljwlog::RollBySizeSink>("./logfile/roll--", 1024 * 1024);// vector<ljwlog::LogSink::ptr> sinks = {stdout_lsp, file_lsp, roll_lsp};// ljwlog::Logger::ptr logger(new ljwlog::SyncLogger(logger_name, limit, fmt, sinks));// logger->debug(__FILE__, __LINE__, "%s", "测试日志");// logger->info(__FILE__, __LINE__, "%s", "测试日志");// logger->warn(__FILE__, __LINE__, "%s", "测试日志");// logger->error(__FILE__, __LINE__, "%s", "测试日志");// logger->fatal(__FILE__, __LINE__, "%s", "测试日志");// size_t cursize = 0; size_t count = 0;// while (cursize <= 1024 * 1024 * 10)// {// logger->fatal(__FILE__, __LINE__, "测试日志--%d", count++);// cursize += 20;// }// ljwlog::LogMsg msg(ljwlog::LogLevel::value::INFO, 53, "main.c", "root", "格式化功能测试");// ljwlog::Formatter fmt("abc%%c[%d{%H:%M:%S}][%t][%c][%f:%l][%p]%T%m%n");// string str = fmt.format(msg);// // cout<< str << endl;// ljwlog::LogSink::ptr time_lsp = ljwlog::SinkFactory::create<ljwlog::RollByTimeSink>("./logfile/roll--", ljwlog::TimeGap::GAP_SECOND);// time_t old = ljwlog::util::Date::now();// //写入数据5秒// while(ljwlog::util::Date::now() < old + 5)// {// time_lsp->log(str.c_str(), str.size());// usleep(100);//慢一点// }// ljwlog::LogSink::ptr stdout_lsp = ljwlog::SinkFactory::create<ljwlog::StdoutSink>();// ljwlog::LogSink::ptr file_lsp = ljwlog::SinkFactory::create<ljwlog::FileSink>("./logfile/test.log");// ljwlog::LogSink::ptr roll_lsp = ljwlog::SinkFactory::create<ljwlog::RollBySizeSink>("./logfile/roll--", 1024 * 1024);//stdout_lsp->log(str.c_str(), str.size()); // 打印//file_lsp->log(str.c_str(), str.size()); // 打印// size_t cursize = 0;// size_t count = 0;// while (cursize <= 1024 * 1024 * 10)// {// string tmp = str + to_string(count++);// roll_lsp->log(tmp.c_str(), tmp.size()); // 打印// cursize += tmp.size();// }// cout<< ljwlog::Loglevel::toString(ljwlog::Loglevel::value::DEBUG) <<endl;// cout<< ljwlog::Loglevel::toString(ljwlog::Loglevel::value::ERROR) <<endl;// cout<< ljwlog::Loglevel::toString(ljwlog::Loglevel::value::FATAL) <<endl;// cout<< ljwlog::Loglevel::toString(ljwlog::Loglevel::value::INFO) <<endl;// cout<< ljwlog::Loglevel::toString(ljwlog::Loglevel::value::OFF) <<endl;// cout<< ljwlog::Loglevel::toString(ljwlog::Loglevel::value::WARN) <<endl;// cout<< ljwlog::util::Date::now()<<endl;// string pathname = "./abc/bcd/a.txt";// ljwlog::util::File::createDirectory(pathname);return 0;
}
util.hpp
#pragma once
#include <iostream>
#include <ctime>
#include <string>
#include <sys/stat.h>
#include <sys/types.h>
using namespace std;
namespace ljwlog
{// 实用类的设计区域namespace util{class Date{public:static time_t now(){return time(nullptr);}};class File{public:static bool exists(const string &pathname) // 路径文件是否存在{struct stat st;if (stat(pathname.c_str(), &st) < 0){return false;}return true;}static string path(const string &pathname) // 路径{// ./logfile/roll--size_t pos = pathname.find_last_of("/\\");if (pos == string::npos){return ".";}return pathname.substr(0, pos + 1);}static void createDirectory(const string &pathname) // 创建目录{// ./abc/bcd/cdesize_t pos = 0, idx = 0;while (idx < pathname.size()){pos = pathname.find_first_of("/\\", idx);if (pos == string::npos){mkdir(pathname.c_str(), 0777);return ;}string parent_dir = pathname.substr(0, pos + 1);if(exists(parent_dir) == true){idx = pos + 1;continue;}mkdir(parent_dir.c_str(),0777);idx = pos + 1;}}};}
}
9.整理整合



extend是扩展代码, example是功能样例代码
给使用者展示使用方法
把不安全的操作去掉最好,建议用安全的
test.cc里
#include "../logs/ljwlog.h"void test_log(const string& name)
{INFO("%s", "测试开始");ljwlog::Logger::ptr logger = ljwlog::LoggerManager::getInstance().getLogger(name);logger->debug("%s", "测试日志");logger->info("%s", "测试日志");logger->warn("%s", "测试日志");logger->error("%s", "测试日志");logger->fatal("%s", "测试日志");INFO("%s", "测试完成");
}int main()
{unique_ptr<ljwlog::LoggerBuilder> builder(new ljwlog::GlobalLoggerBuilder());builder->buildLoggerName("async_logger");builder->buildLoggerLevel(ljwlog::LogLevel::value::WARN);builder->buildFormatter("[%c][%f:%l]%m%n");builder->buildLoggerType(ljwlog::LoggerType::LOGGER_ASTNC);builder->buildSink<ljwlog::FileSink>("./logfile/async.log");builder->buildSink<ljwlog::StdoutSink>();builder->buildSink<ljwlog::RollBySizeSink>("./logfile/roll-async-by-size", 1024*1024);builder->build();test_log("async_logger");return 0;
}在创建一个扩展

把扩展的落地方向这一块放进去

#include"../logs/ljwlog.h"enum class TimeGap //Gap是间隔的意思
{GAP_SECOND, //间隔多久切换一个文件GAP_MINUTE,GAP_HOUR,GAP_DAY,
};
// 落地方向:滚动文件(以时间间隔进行滚动)
class RollByTimeSink : public ljwlog::LogSink
{
public:// 构造时传入文件名,并打开文件,将操作句柄管理起来RollByTimeSink(const string &basename, TimeGap gap_type) : _basename(basename){switch (gap_type){case TimeGap::GAP_SECOND: _gap_size = 1; break; //间隔一秒切换一个文件case TimeGap::GAP_MINUTE: _gap_size = 60; break;case TimeGap::GAP_HOUR: _gap_size = 3600; break;case TimeGap::GAP_DAY: _gap_size = 3600 * 24; break;}//获取当前是第几个时间段//当_gap_size为1的时候,任何数取模1都是0_cur_gap = _gap_size ==1 ? ljwlog::util::Date::now() : ljwlog::util::Date::now() % _gap_size;string filename = createNewFile();ljwlog::util::File::createDirectory(ljwlog::util::File::path(filename));_ofs.open(filename, ios::binary | ios::app);assert(_ofs.is_open());}// 将日志消息写入标准输出,判断当前时间是否是当前文件的时间段,不是则切换文件void log(const char *data, size_t len){time_t cur = ljwlog::util::Date::now();if(cur % _gap_size != _cur_gap){_ofs.close();string filename = createNewFile();_ofs.open(filename, ios::binary | ios::app);assert(_ofs.is_open());}_ofs.write(data, len);assert(_ofs.good());}string createNewFile() // ./logfile/roll--20241030152451.log {// 获取系统时间,以时间来构造文件名扩展名time_t t = ljwlog::util::Date::now();struct tm it;localtime_r(&t, &it);stringstream filename;filename << _basename; // 文件目录filename << it.tm_year + 1900;filename << it.tm_mon + 1;filename << it.tm_mday;filename << it.tm_hour;filename << it.tm_min;filename << it.tm_sec;filename << ".log";return filename.str();}
private:string _basename;ofstream _ofs;size_t _cur_gap; // 当前时第几个时间段size_t _gap_size; // 时间段的大小
};int main()
{unique_ptr<ljwlog::LoggerBuilder> builder(new ljwlog::GlobalLoggerBuilder());builder->buildLoggerName("async_logger");builder->buildLoggerLevel(ljwlog::LogLevel::value::WARN);builder->buildFormatter("[%c][%f:%l]%m%n");builder->buildLoggerType(ljwlog::LoggerType::LOGGER_ASTNC);builder->buildSink<RollByTimeSink>("./logfile/roll-async-by-size", TimeGap::GAP_SECOND);ljwlog::Logger::ptr logger = builder->build();size_t cur = ljwlog::util::Date::now();while(ljwlog::util::Date::now() < cur + 5)//5秒钟做测试,写五个日志文件,1秒一个{logger->fatal("这是一个测试日志(时间大小)");usleep(1000);}return 0;
}功能样例代码测试
![]()
#include "../logs/ljwlog.h"void test_log(const string& name)
{INFO("%s", "测试开始");ljwlog::Logger::ptr logger = ljwlog::LoggerManager::getInstance().getLogger(name);logger->debug("%s", "测试日志");logger->info("%s", "测试日志");logger->warn("%s", "测试日志");logger->error("%s", "测试日志");logger->fatal("%s", "测试日志");INFO("%s", "测试完成");
}int main()
{unique_ptr<ljwlog::LoggerBuilder> builder(new ljwlog::GlobalLoggerBuilder());builder->buildLoggerName("async_logger");builder->buildLoggerLevel(ljwlog::LogLevel::value::DEBUG);builder->buildFormatter("[%c][%f:%l]%m%n");builder->buildLoggerType(ljwlog::LoggerType::LOGGER_SYNC);builder->buildSink<ljwlog::FileSink>("./logfile/sync.log");builder->buildSink<ljwlog::StdoutSink>();builder->buildSink<ljwlog::RollBySizeSink>("./logfile/roll-sync-by-size", 1024*1024);builder->build();test_log("async_logger");return 0;
}

拓展样例代码测试
![]()
#include"../logs/ljwlog.h"enum class TimeGap //Gap是间隔的意思
{GAP_SECOND, //间隔多久切换一个文件GAP_MINUTE,GAP_HOUR,GAP_DAY,
};
// 落地方向:滚动文件(以时间间隔进行滚动)
class RollByTimeSink : public ljwlog::LogSink
{
public:// 构造时传入文件名,并打开文件,将操作句柄管理起来RollByTimeSink(const string &basename, TimeGap gap_type) : _basename(basename){switch (gap_type){case TimeGap::GAP_SECOND: _gap_size = 1; break; //间隔一秒切换一个文件case TimeGap::GAP_MINUTE: _gap_size = 60; break;case TimeGap::GAP_HOUR: _gap_size = 3600; break;case TimeGap::GAP_DAY: _gap_size = 3600 * 24; break;}//获取当前是第几个时间段//当_gap_size为1的时候,任何数取模1都是0_cur_gap = _gap_size ==1 ? ljwlog::util::Date::now() : ljwlog::util::Date::now() % _gap_size;string filename = createNewFile();ljwlog::util::File::createDirectory(ljwlog::util::File::path(filename));_ofs.open(filename, ios::binary | ios::app);assert(_ofs.is_open());}// 将日志消息写入标准输出,判断当前时间是否是当前文件的时间段,不是则切换文件void log(const char *data, size_t len){time_t cur = ljwlog::util::Date::now();if(cur % _gap_size != _cur_gap){_ofs.close();string filename = createNewFile();_ofs.open(filename, ios::binary | ios::app);assert(_ofs.is_open());}_ofs.write(data, len);assert(_ofs.good());}string createNewFile() // ./logfile/roll--20241030152451.log {// 获取系统时间,以时间来构造文件名扩展名time_t t = ljwlog::util::Date::now();struct tm it;localtime_r(&t, &it);stringstream filename;filename << _basename; // 文件目录filename << it.tm_year + 1900;filename << it.tm_mon + 1;filename << it.tm_mday;filename << it.tm_hour;filename << it.tm_min;filename << it.tm_sec;filename << ".log";return filename.str();}
private:string _basename;ofstream _ofs;size_t _cur_gap; // 当前时第几个时间段size_t _gap_size; // 时间段的大小
};int main()
{unique_ptr<ljwlog::LoggerBuilder> builder(new ljwlog::GlobalLoggerBuilder());builder->buildLoggerName("async_logger");builder->buildLoggerLevel(ljwlog::LogLevel::value::WARN);builder->buildFormatter("[%c][%f:%l]%m%n");builder->buildLoggerType(ljwlog::LoggerType::LOGGER_ASTNC);builder->buildSink<RollByTimeSink>("./logfile/roll-async-by-size", TimeGap::GAP_SECOND);ljwlog::Logger::ptr logger = builder->build();size_t cur = ljwlog::util::Date::now();while(ljwlog::util::Date::now() < cur + 5)//5秒钟做测试,写五个日志文件,1秒一个{logger->fatal("这是一个测试日志(时间大小)");usleep(1000);}return 0;
}
10.性能测试
下面对日志系统做一个性能测试,测试一下平均每秒能打印多少条日志消息到文件。
主要的测试方法是:每秒能打印日志数=打印日志条数/总的打印日志消耗时间
主要测试要素:同步/异步&单线程/多线程
- 100w+条指定长度的日志输出所耗时间
- 每秒可以输出多少条日志
- 每秒可以输出多少MB日志
测试环境:
- CPU:13th Gen Intel(R) Core(TM) i5-13500H 2.60 GHz
- RAM: 32.0 GB
- ROM: 1TB-SSD(固态硬盘)
- OS: Ubuntu Server 22.04 LTS 64bit(云服务器) (CPU - 2核 内存 - 2GB)
测试重要的三点
测试三要素:
1.测试环境
2.测试方法3.测试结果

创建一个目录bench



基本逻辑
#include"../logs/ljwlog.h"// 日志器名称 线程数量 日志数量 单条日志大小(日志长度)
void bench(const string& logger_name, size_t thr_count, size_t msg_count, size_t msg_len)
{//1.获取日志器//2.组织指定长度的日志消息//3.创建指定数量的线程//4.线程函数内部开始计时//5.开始循环写日志//6.线程函数内部结束计时//7.计算总耗时//8.进行输出打印
}
void sync_bench();//同步
void async_bench();//异步1.获取日志器
//1.获取日志器ljwlog::Logger::ptr logger = ljwlog::getLogger(logger_name);if(logger.get() == nullptr)//没找到就返回{return ;}2.组织指定长度的日志消息
string
string::string - C++ Reference (cplusplus.com)

//2.组织指定长度的日志消息string msg(msg_len - 1, 'A');//-1是为了追加一个换行方便查看3.创建指定数量的线程
4.线程函数内部开始计时
5.开始循环写日志
6.线程函数内部结束计时
7.计算总耗时:在多线程中,每个线程都会消耗时间,但是线程是并发处理的,因此耗时最高的那个线程就是总时间
8.进行输出打印
std::vector::emplace_back(构造并插入一个元素)
vector::emplace_back - C++ Reference (cplusplus.com)
代码示例:
#include"../logs/ljwlog.h"// 日志器名称 线程数量 日志数量 单条日志大小(日志长度)
void bench(const string& logger_name, size_t thr_count, size_t msg_count, size_t msg_len)
{//1.获取日志器ljwlog::Logger::ptr logger = ljwlog::getLogger(logger_name);if(logger.get() == nullptr)//没找到就返回{return ;}cout<< "测试日志:" << msg_count << "条,总大小:" << (msg_count + msg_len) / 1024 << "KB\n";//2.组织指定长度的日志消息string msg(msg_len - 1, 'A');//-1是为了追加一个换行方便查看//3.创建指定数量的线程vector<thread> threads;vector<double> cost_arry(thr_count);//总的耗时统计size_t msg_per_thr = msg_count / thr_count; //总日志数量/线程数量//就是每个线程要输出的日志数量 for(int i = 0; i < thr_count; i++){threads.emplace_back([&, i](){//4.线程函数内部开始计时auto start = chrono::high_resolution_clock::now();//5.开始循环写日志for(int j = 0; j < msg_per_thr; j++){logger->fatal("%s", msg.c_str());}//6.线程函数内部结束计时auto end = chrono::high_resolution_clock::now();chrono::duration<double> cost = end - start;cost_arry[i] = cost.count();//总的耗时统计//单个耗时打印 cout<< "线程" << i << ":" << "\t输出日志的数量:" << msg_per_thr << ",耗时:" << cost.count() << "s" << endl;});}for(int i = 0; i < thr_count; i++){threads[i].join();}//7.计算总耗时:在多线程中,每个线程都会消耗时间,但是线程是并发处理的,因此耗时最高的那个线程就是总时间double max_cost = cost_arry[0];for(int i =0; i < thr_count; i++){max_cost = cost_arry[i] > max_cost ? cost_arry[i] : max_cost;}size_t msg_per_sec = msg_count / max_cost;//每秒输出日志的数量size_t size_per_sec = (msg_count * msg_len) / (max_cost * 1024);//每秒输出日志的大小//8.进行输出打印cout<< "每秒输出日志的数量:" << msg_per_sec << "条\n";cout<< "每秒输出日志的大小:" << size_per_sec << "KB\n";
}
//单线程同步测试
void sync_bench()//同步
{unique_ptr<ljwlog::LoggerBuilder> builder(new ljwlog::GlobalLoggerBuilder());builder->buildLoggerName("sync_logger");builder->buildFormatter("%m%n");builder->buildLoggerType(ljwlog::LoggerType::LOGGER_SYNC);builder->buildSink<ljwlog::FileSink>("./logfile/sync.log");builder->build();bench("sync_logger", 1, 1000000, 100);
}
void async_bench();//异步int main()
{sync_bench();return 0;
}单线程同步测试
//单线程同步测试
void sync_bench()//同步
{unique_ptr<ljwlog::LoggerBuilder> builder(new ljwlog::GlobalLoggerBuilder());builder->buildLoggerName("sync_logger");builder->buildFormatter("%m%n");builder->buildLoggerType(ljwlog::LoggerType::LOGGER_SYNC);builder->buildSink<ljwlog::FileSink>("./logfile/sync.log");builder->build();bench("sync_logger", 1, 1000000, 100);
}
void async_bench();//异步int main()
{sync_bench();return 0;
}
多个线程同步测试
//多个线程同步测试
void sync_bench()//同步
{unique_ptr<ljwlog::LoggerBuilder> builder(new ljwlog::GlobalLoggerBuilder());builder->buildLoggerName("sync_logger");builder->buildFormatter("%m%n");builder->buildLoggerType(ljwlog::LoggerType::LOGGER_SYNC);builder->buildSink<ljwlog::FileSink>("./logfile/sync.log");builder->build();bench("sync_logger", 3, 1000000, 100);
}void async_bench();//异步int main()
{sync_bench();return 0;
}
同步写日志,多个线程反而慢了因为有锁冲突
异步测试单个线程安全模式
//异步测试单个线程
void async_bench()//异步
{unique_ptr<ljwlog::LoggerBuilder> builder(new ljwlog::GlobalLoggerBuilder());builder->buildLoggerName("async_logger");builder->buildFormatter("%m%n");builder->buildLoggerType(ljwlog::LoggerType::LOGGER_ASTNC);//builder->buildEnableUnSafeAsync();//开启非安全模式---主要是为了将实际落地时间排除在外builder->buildSink<ljwlog::FileSink>("./logfile/async.log");builder->build();bench("async_logger", 1, 1000000, 100);}int main()
{//sync_bench();async_bench();return 0;
}
异步测试单个线程非安全模式
//异步测试单个线程
void async_bench()//异步
{unique_ptr<ljwlog::LoggerBuilder> builder(new ljwlog::GlobalLoggerBuilder());builder->buildLoggerName("async_logger");builder->buildFormatter("%m%n");builder->buildLoggerType(ljwlog::LoggerType::LOGGER_ASTNC);builder->buildEnableUnSafeAsync();//开启非安全模式---主要是为了将实际落地时间排除在外builder->buildSink<ljwlog::FileSink>("./logfile/async.log");builder->build();bench("async_logger", 1, 1000000, 100);
}
异步测试多个线程非安全模式
void async_bench()//异步
{unique_ptr<ljwlog::LoggerBuilder> builder(new ljwlog::GlobalLoggerBuilder());builder->buildLoggerName("async_logger");builder->buildFormatter("%m%n");builder->buildLoggerType(ljwlog::LoggerType::LOGGER_ASTNC);builder->buildEnableUnSafeAsync();//开启非安全模式---主要是为了将实际落地时间排除在外builder->buildSink<ljwlog::FileSink>("./logfile/async.log");builder->build();bench("async_logger", 3, 1000000, 100);
}int main()
{//sync_bench();async_bench();return 0;
}
同步和异步差别
同步往磁盘写,考虑磁盘性能,异步往内存写,考虑cpu和内存性能,比磁盘高
结果情况
能够通过上边的测试看出来,一些情况:
在单线程情况下,异步效率看起来还没有同步高,这个我们得了解,现在的IO操作在用户态都会有缓冲区进行缓冲区, 因此我们当前测试用例看起来的同步其实大多时候也是在操作内存,只有在缓冲区满了才会涉及到阻塞写磁盘操作,而异步单线程效率看起来低,也有一个很重要的原因就是单线程同步操作中不存在锁冲突,而单线程异步日志操作存在大量的锁冲突,因此性能也会有一定的降低。
但是,我们也要看到限制同步日志效率的最大原因是磁盘性能,打日志的线程多少并无明显区别,线程多了反而会降低,因为增加了磁盘的读写争抢,而对于异步日志的限制,并非磁盘的性能,而是cpu的处理性能,打日志并不会因为落地而阻塞,因此在多线程打日志的情况下性能有了显著的提高。