基于TensorFlow/Keras的深度学习案例
- 实现基于MNIST数据集的TensorFlow/Keras深度学习案例
- 0. 什么是深度学习?
- 1. TensorFlow简介
- 2. Keras简介
- 3. 安装TensorFlow前的注意事项
- 4. 安装Anaconda3及搭建TensorFlow环境
- 1) 下载安装Anaconda Navigator
- 2) 创建最新版Python 3.12.X适用的TensorFlow虚拟环境
- 3) 激活TensorFlow虚拟环境
- 4) 安装TensorFlow
- A. 从阿里云的pip源安装TensorFlow:
- B. 从清华大学镜像网站安装:
- 5) 验证TensorFlow版本
- 5. 认识并下载MNIST数据集
- 1) MNIST数据集简介
- 2) MNIST数据集的功能
- 3) 对于MNIST数据集的典型工作流程
- 4) 下载MNIST数据集
- 6. TensorFlow/Keras项目案例
- 1) 深度学习案例一
- 2) 深度学习案例二
实现基于MNIST数据集的TensorFlow/Keras深度学习案例
[Deep Learning] Implement A Deep Learning Project Based-on MNIST Dataset on TensorFlow and Keras
By Jackson@ML
0. 什么是深度学习?
深度学习是机器学习的一个子集,它使用多层神经网络(称为深度神经网络)来模拟人脑的复杂决策能力。某种形式的深度学习为当今生活中的大多数人工智能 (AI) 应用程序提供支持。
深度学习和机器学习之间的主要区别在于底层神经网络架构。“非深度”的传统机器学习模型使用具有一个或两个计算层的简单神经网络,而深度学习模型则采用三层或更多层(但通常为数百或数千层)来训练模型。
– IBM官网
监督学习模型需要结构化的、标记的输入数据才能完成准确的输出,而深度学习模型可以使用无监督学习。通过无监督学习,深度学习模型可以提取所需的特征、特征和关系,以便由原始的非结构化数据中提取进行准确的输出。此外,这些模型甚至还可以评估和优化输出以提高其精度。
深度学习是数据科学的一个方面,它推动了许多应用程序和服务,这些应用程序和服务可以提高自动化水平,无需人工干预即可执行分析和物理任务。这使得许多每天日常的产品和服务成为可能,例如数字助理、支持语音的电视遥控器、信用卡欺诈检测、自动驾驶汽车和生成式人工智能等。
1. TensorFlow简介
TensorFlow 是一个用于快速数值计算的开源库。TensorFlow (TF) 由 Google Brain 开发,是用于深度学习模型量产的最知名的库。
2015年11月9日,TensorFlow被Google(谷歌)公司所创立,之后由谷歌持续维护至今,并在 Apache 2.0 开源许可下发布。尽管该 API 名义上用于 Python 编程语言,但仍然可以访问底层 C++ API。
与Theano等其他用于深度学习的数值库不同,TensorFlow被设计用于研发和生产系统,尤其是谷歌搜索中的RankBrain和一些有趣的DeepDream项目。
它可以在单个 CPU 系统和 GPU 上运行,也可以在移动设备和数百台机器的大规模分布式系统上运行。
TensorFlow(简称TF)因其知名度而拥有非常庞大的社区。但是,TensorFlow 的学习曲线很陡峭。为了更好地进行深度学习试验,经由Keras 不断积累,则是个不错的选择;它是建立在 TensorFlow 之上的高级 API。与 TF 相比,它显得用户友好且更易于使用,并且用户可以更快地熟悉它,因为它更“pythonic”,也就是更加Python化,具有更多Python的特点。
那么,为什么不单独使用Keras呢?当然可以。但是,如果想更好地控制模型网络,获得更好的调试,或者开发新的网络并在未来进行一些深度学习研究,那么 TensorFlow 就是您的最佳选择。
在本文的简短介绍中,将引导和帮助您搭建 TensorFlow 深度学习环境。Keras API 包含在 TensorFlow 中,但您也可以单独下载和使用它。
2. Keras简介
Keras是一个基于Python的深度学习框架,可以方便地定义和训练几乎所有类型的深度学习模型。
Keras源于宽松的MIT许可证发布,因此,用户可以在商业项目中免费使用它,并且,它兼容所有版本的Python(从Python 2.7到Python 3.7及以上版本)。

Keras是一个模型级(model-level)的库,为开发深度学习提供了高层次的构建模块,它依赖一个专用的、高度优化的张量库,即后端引擎(backend engine)。
目前Keras有几个后端实现,其中,TensorFlow后端就是最流行的深度学习平台。
因此,本文项目案例,除了使用TensorFlow之外,还需要安装和导入Keras.
3. 安装TensorFlow前的注意事项
安装前的一些注意事项包括:是否使用 GPU?
图形处理单元 (GPU) 是一种微处理芯片,旨在处理计算环境中的图形,并且可以具有比中央处理器 (CPU) 多得多的内核。更多的 GPU 内核允许更好地计算多个并行进程。如果您可以访问 GPU,您如何使用它?
- 在用户计算机上,如果您使用 pip 安装了 TensorFlow,则最新版本将支持 GPU。对于 1.15 及更早版本,CPU 和 GPU 包是分开的。
以下分别是支持CPU和GPU的安装命令:
pip install tensorflow (for CPU)
pip install tensorflow-gpu (for GPU)
- 但是,这并不那么简单,因为您还需要安装一些NVIDIA®软件要求。建议遵循 TensorFlow 的安装说明来了解 GPU 支持。
4. 安装Anaconda3及搭建TensorFlow环境
1) 下载安装Anaconda Navigator
笔者之前发布过关于Anaconda3安装指南 - 《2024最新版Anaconda Navigator安装使用指南》,以下是访问链接,敬请关注。
https://blog.csdn.net/jackson_lingua/article/details/139386602?spm=1001.2014.3001.5501
2) 创建最新版Python 3.12.X适用的TensorFlow虚拟环境
由于Anaconda Navigator已经安装完毕,因此,我们使用Anaconda的命令行终端来操作创建基于最新版Python 3.12.x的TensorFlow虚拟化环境。
conda create -n tensorflowenv python==3.12
执行结果如下图所示:
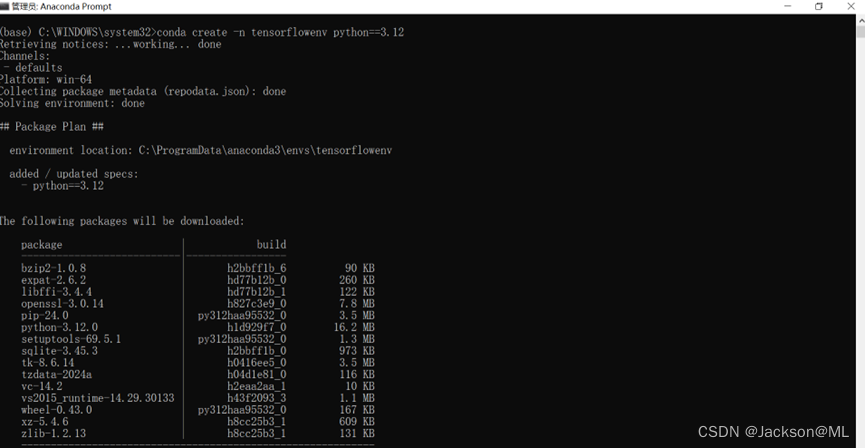
注: Anaconda Navigator安装过程中,可能要求用户选择默认配置,即选择内置的Python 3.11安装包,如果选择并完成安装,则上述命令中的Python版本,可以修改为python==3.11.
3) 激活TensorFlow虚拟环境
创建完毕虚拟环境后,打开Anaconda Prompt命令行窗口并“以管理员身份运行”,执行以下命令激活虚拟环境:
conda activate tensorflowenv
激活成功后,命令行变为:
(tensorflowenv) C:\WINDOWS\system32\
4) 安装TensorFlow
在pypi.org官网项目清单中,查到TensorFlow安装命令很简单:
pip install tensorflow
但由于实际搭建环境的时候,计算机可能附带有不同版本的Python,同时,海内外有很多后台服务器都可能在为tensorflow服务。
在国内搭建环境,为了加快下载安装速度,可以打开Anaconda Prompt(以管理员身份运行),继续在虚拟环境下,使用conda命令从以下两个镜像网站之一安装TensorFlow:
A. 从阿里云的pip源安装TensorFlow:
pip install tensorflow -i https://mirrors.aliyun.com/pypi/simple
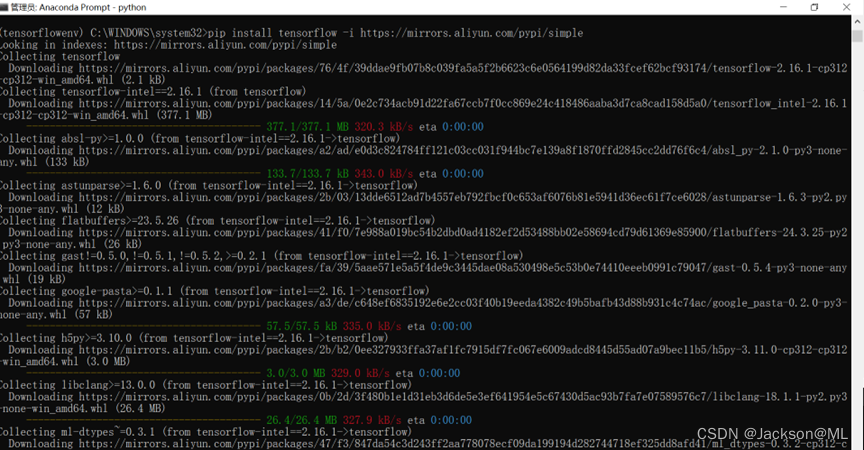
B. 从清华大学镜像网站安装:
https://pypi.tuna.tsinghua.edu.cn/simple/tensorflow/
点击该网页,选择适用于Windows系统的安装链接,再次使用pip来安装TensorFlow软件包。
5) 验证TensorFlow版本
仍然打开Anaconda Prompt 命令行窗口并且以管理员身份运行。
执行python命令,运行Python交互式解释器窗口。
C:\WINDOWS\system32\python
使用命令如下图,验证TensorFlow版本
>>> import tenforflow as tf
>>> print(tf.__version__)

可以看出,TensorFlow版本验证,是通过调用tf对象(即Tensor Flow的实例)的__version__来查看的。
查看的结果是,TensorFlow当前版本为 2.16.1,的确是最新的发行版本,于2024年3月9日发布。
5. 认识并下载MNIST数据集
1) MNIST数据集简介
MNIST数据库(修改后的国家标准与技术研究院数据库)是手写数字的大量集合。它有一个包含 60,000 个示例的训练集和一个包含10,000个示例的测试集。它是更大的NIST特殊数据库3(由美国人口普查局的员工编写的数字)和特殊数据库1(由高中生编写的数字)的子集,其中包含手写数字的单色图像。这些数字已标准化大小,并在固定大小的图像中居中。
NIST的原始黑白(双层)图像经过大小归一化,以适合20x20像素的框,同时保持其纵横比。生成的图像包含灰度,这是归一化算法使用的抗锯齿技术的结果。通过计算像素的质心,将图像置于 28x28 图像的中心,并平移图像,以便将该点定位在 28x28 场的中心。
– 来自于 https://paperswithcode.com/dataset/mnist
-
MNIST 数据集是 70,000 个手写数字 (0-9) 的集合,每个图像为 28×28 像素。以下是指定格式的数据集信息:
实例数:70,000 张图像
属性数量:784(28×28像素)
目标:列表示手写图像对应的数字 (0-9)
像素 1-784:每个像素值 (0-255) 表示图像中相应像素的灰度强度。
数据集分为两个主要子集:
训练集:由 60,000 张图像及其标签组成,通常用于训练机器学习模型。
测试集:包含 10,000 张图像及其相应的标签,用于评估训练模型的性能。
2) MNIST数据集的功能
MNIST 数据集目前代表了图像处理和机器学习中许多任务的主要输入,可以追溯到美国国家标准与技术研究院 (NIST)。NIST是一家专注于测量科学和标准的美国政府机构,负责管理各种数据集,包括两个与手写数字特别相关的数据集:
特殊数据库 1 (SD-1):由于作为美国人口普查局的雇员,工作场所中有相当多的人口是私人手写数据——它们都来自理想的来源。人口普查人员重复处理书面值,从而使他们的样本在算法训练中成功的机会很高。
特别数据库3(SD-3):该数据集包含由学生提供的高中生的数字化笔迹数字。然而,就真实性而言,这些信息看起来不如人口普查局提供的数字那么“官方”,但最棒的是它们适用于各种写作风格。
3) 对于MNIST数据集的典型工作流程
对于MNIST数据集的典型Keras工作流程如下:
- 1.定义训练数据:输入张量和目标张量;
- 2.定义层组成的网络(或模型),将输入映射到目标;
- 3.配置学习过程:选择损失函数、优化器和需要监控的指标;
- 4.调用模型的fit方法,在训练数据上迭代。
4) 下载MNIST数据集
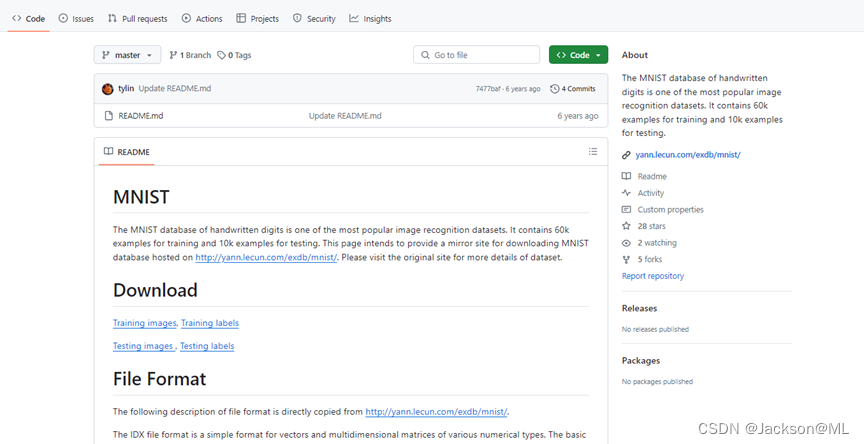
打开Chrome浏览器,在必应搜索引擎(https://cn.bing.com)中,搜索关键字,可以找到MNIST数据集在Github的链接:https://github.com/cvdfoundation/mnist
点击进入该页面,看到需要下载的共有四个链接,分别是:
- Training images,
- Training labels,
- Testing images,
- Testing labels
如下图图所示。
点击各个链接,很快,数据集文件就下载到Windows中;从“下载”文件夹里,可以看到这四个gz结尾的文件,如下图所示:

6. TensorFlow/Keras项目案例
完成了上述步骤的准备工作,并分别验证各个第三方库安装正确后,就可以导入并使用TensorFlow库了。
在虚拟环境下,标准导入命令为:
import tensorflow
以下举两个例子,分别来看如何使用TensorFlow/Keras实现对MNIST数据集的深度学习过程。
1) 深度学习案例一
示例代码如下:
# Import libraries and framework
from tensorflow import keras
from keras import datasets
import matplotlib.pyplot as plt
import numpy as np
import gzip# To load FashionMNIST dataset,there are two ways below
# 1.Online downloading mode
(x_train,y_train),(x_test,y_test)= datasets.fashion_mnist.load_data()
# 2.Local dataset reading mode(download and save datasets into a path)
# def load_data(path,files):
# paths = [path+ each for each in files ]
# with gzip.open(paths[0], 'rb') as lbpath:
# train_labels = np.frombuffer(lbpath.read(), np.uint8, offset=8)
# with gzip.open(paths[1], 'rb') as impath:
# train_images = np.frombuffer(impath.read(), np.uint8, offset=16).reshape(len(train_labels),28,28)
# with gzip.open(paths[2], 'rb') as lbpath:
# test_labels = np.frombuffer(lbpath.read(), np.uint8, offset=8)
# with gzip.open(paths[3], 'rb') as impath:
# test_images = np.frombuffer(impath.read(), np.uint8, offset=16).reshape(len(test_labels), 28, 28)
# return (train_labels,train_images), (test_labels,test_images)# Define a path to dedicated dataset
path = './dataset/FashionMNIST/'files = ['train-labels-idx1-ubyte.gz','train-images-idx3-ubyte.gz', 't10k-labels-idx1-ubyte.gz', 't10k-images-idx3-ubyte.gz']# Call local saved dataset to extract training data and testing data
# (y_train, x_train), (y_test, x_test) = load_data(path, files)# print out the shape of training and testing set
print(x_train.shape,y_train.shape)
print(x_test.shape,y_test.shape)
# training set and testing set
x_train = x_train.reshape(-1, 28, 28, 1)
x_test = x_test.reshape(-1, 28, 28, 1)
# combine the training and testing dataset
x_train = x_train / 255.0
x_test = x_test / 255.0# Build a LeNet-5 model
model = keras.Sequential([keras.layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)),keras.layers.MaxPooling2D((2, 2)),keras.layers.Conv2D(64, (3, 3), activation='relu'),keras.layers.MaxPooling2D((2, 2)),keras.layers.Flatten(),keras.layers.Dense(512, activation='relu'),keras.layers.Dense(10, activation='softmax')
])
# print out network structure
model.summary()
# Complie a model
model.compile(loss='sparse_categorical_crossentropy',optimizer=keras.optimizers.Adam(lr=0.001),metrics=['accuracy'])# A model training test set
# Using the model training method - model.fit()
epochs = 5
batch_size = 128
# Visualize the training process
history = model.fit(x_train, y_train, batch_size=batch_size, epochs=5, shuffle=True,validation_data=(x_test, y_test))# Visualize the loss rate of process,save it as an image
plt.figure('loss')
plt.plot(np.arange(0,epochs),history.history['loss'] , 'r', label="Train_loss")
plt.plot(np.arange(0,epochs), history.history['val_loss'], 'b', label="Valid_loss")
plt.title("Loss")
plt.xlabel('epochs')
plt.ylabel('train/test loss')
plt.grid(True)
plt.legend()
# save the result as an image
plt.savefig('./loss.png')# a model training and visualization process
plt.figure('accuracy')
plt.plot(np.arange(0,epochs), history.history['accuracy'], 'r', label="Train_acc")
plt.plot(np.arange(0,epochs), history.history['val_accuracy'], 'b', label="Valid_acc")
plt.title("Acc")
plt.xlabel('epochs')
plt.ylabel('train/test acc')
plt.grid(True)
plt.legend()
# Set and save the result as an image
plt.savefig('./acc.png')
plt.show()
plt.close()
运行结果如下图所示:
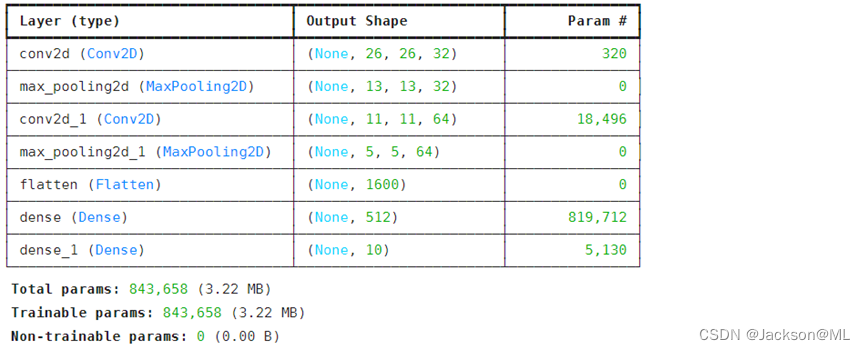
2) 深度学习案例二
以下代码示例,为加载 MNIST 数据集的Keras 示例,检索训练图像和标签,然后连续绘制四个图像及其相应的标签。每个图像都以灰度显示。
示例代码如下:
# Import libraries
from tensorflow.keras.datasets import mnist
import matplotlib.pyplot as plt
import numpy as np# Load the MNIST dataset
(X_train, y_train), (_, _) = mnist.load_data()# Print 4 images in a row
plt.figure(figsize=(10, 5))
for i in range(4):plt.subplot(1, 4, i+1)plt.imshow(X_train[i], cmap='gray')plt.title(f"Label: {y_train[i]}")plt.axis('off')
plt.tight_layout()
plt.show()
运行结果如下图所示:

以上就是运用TensorFlow/Keras进行深度学习的基础环境搭建及应用过程。
基于深度学习,后续还有更多案例,敬请关注, 并欢迎点赞收藏。
您的认可,我的动力!😊
继续你的创作。