一、解决方案架构
| 项目/产品 | 类型 | 介绍 |
| 云原生一站式机器学习/深度学习/大模型AI平台 | AI训练开发平台 | 云原生一站式机器学习/深度学习/大模型AI平台,支持sso登录,多租户,大数据平台对接,notebook在线开发,拖拉拽任务流pipeline编排,多机多卡分布式训练,超参搜索,推理服务VGPU,边缘计算,serverless,标注平台,自动化标注,数据集管理,大模型微调,vllm大模型推理,llmops,私有知识库,AI模型应用商店,支持模型一键开发/推理/微调,支持国产cpu/gpu/npu芯片,支持RDMA,支持pytorch/tf/mxnet/deepspeed/paddle/colossalai/horovod/spark/ray/volcano分布式,私有化部署。 |
| 华为云HCCDA-AI认证 | 每位学生一次考试认证 | 面向AI初学者,培训与认证AI基础理论及基于华为云EI服务的AI应用开发能力。包括理论学习、实验学习和理论考试和实验考试,考试通过后发放HCCDA-AI认证。 根据实际学生人数安排。 |
| AI/数据挖掘实战课程 | 数据挖掘与深度学习体系化实战课程 | AI课程: 数据挖掘与深度学习体系化实战课程,一共16章的内容,共96课时。 交付物 课程设计与实训材料:每个课程一套详细的课程大纲、教案、实训指导书和代码文档,真实项目案例和实战项目。每个课程包含2课时的导学视频。 交付形式 所有课程材料、技术指南和实验说明均以PDF、word、PPT等通用格式提供,部分提供在线访问权限,确保学生可以随时查阅最新资料。 |
| AI训练服务器 | 学校自备 | 考虑到现在大部分学校已经有自有的本地AI训练服务器或云服务器,所以本方案暂未给出AI训练服务器,如有需求可另行给出。 |
1.1 来自产业的实战项目
课程中的实战项目全部是基于产业的商业化项目,经过角色拆解、任务拆解、代码拆解、部署流程拆解等过程,讲其标准化为教师可以带领学生完成的实训内容,真正帮助学生接触产业前沿技术和工作内容,提升就业竞争力。
1.2 创新的AI训练实训平台
云原生一站式机器学习/深度学习/大模型AI平台可以大大提高带领学生完成AI实训和项目开发的效率,区别于市场上现有的实训平台,完整的平台包含:
- 1、机器的标准化
- 2、分布式存储(单机可忽略)、k8s集群、监控体系(prometheus/efk/zipkin)
- 3、基础能力(tf/pytorch/mxnet/valcano/ray等分布式,nni/katib超参搜索)
- 4、平台web部分(oa/权限/项目组、在线构建镜像、在线开发、pipeline拖拉拽、超参搜索、推理服务管理等)
二、云原生一站式机器学习/深度学习/大模型AI平台
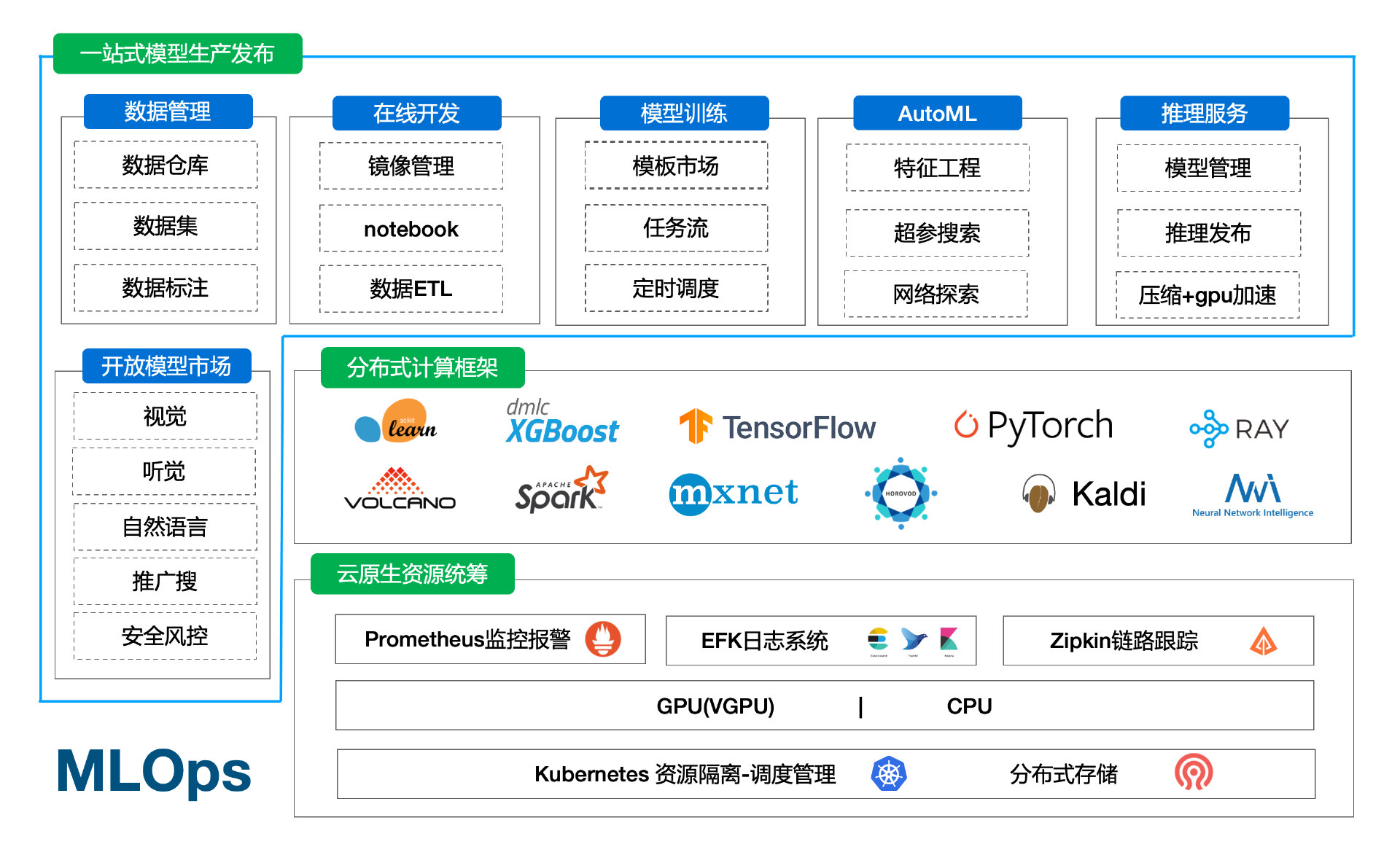
3.1 功能介绍
算力/存储/用户管理
算力:
- 云原生统筹平台cpu/gpu等算力
- 支持划分多资源组,支持多k8s集群,多地部署
- 支持T4/V100/A100/昇腾/dcu/VGPU等异构GPU/NPU环境
- 支持边缘集群模式,支持边缘节点上开发/训练/推理
- 支持鲲鹏芯片arm64架构,RDMA
存储:
- 自带分布式存储,支持多机分布式下文件处理
- 支持外部存储挂载,支持项目组挂载绑定
- 支持个人存储空间/组空间等多种形式
- 平台内存储空间不需要迁移
用户权限:
- 支持sso登录,对接公司账号体系
- 支持项目组划分,支持配置相应项目组用户的权限
- 管理平台用户的基本信息,组织架构,rbac权限体系
多集群管控
cube支持多集群调度,可同时管控多个训练或推理集群。在单个集群内,不仅能做到一个项目组内对在线开发、训练、推理的隔离,还可以做到一个k8s集群下多个项目组算力的隔离。另外在不同项目组下的算力间具有动态均衡的能力,能够在多项目间共享公共算力池和私有化算力池,做到成本最低化。
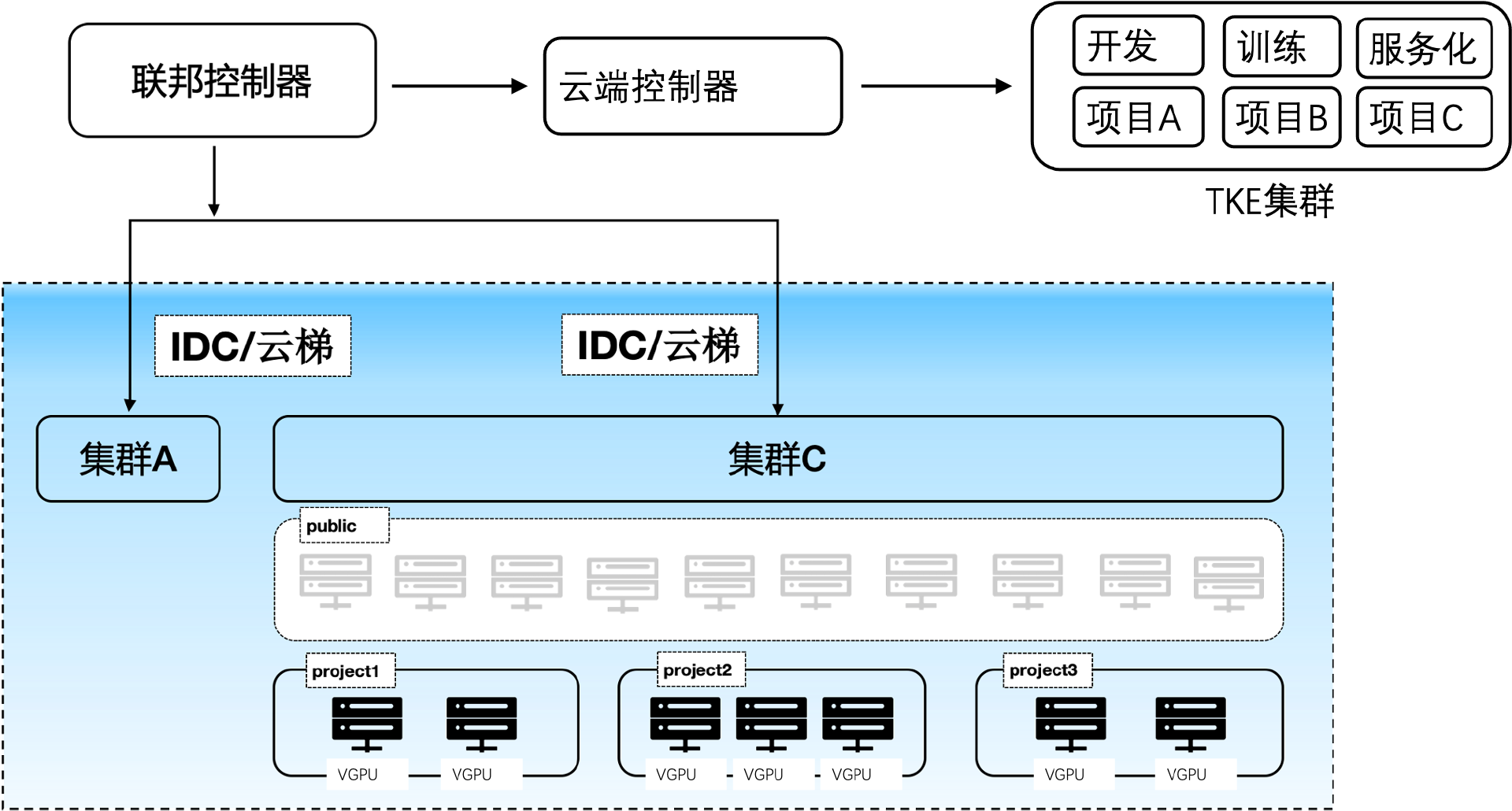
分布式存储
自动为用户挂载用户的个人目录,同一个用户在平台任何地方启动的容器,其用户个人子目录均为/mnt/$username。可以将pvc/hostpath/memory/configmap等挂载成容器目录。同时可以在项目组中配置项目组的默认挂载,进而实现一个项目组共享同一个目录等功能。

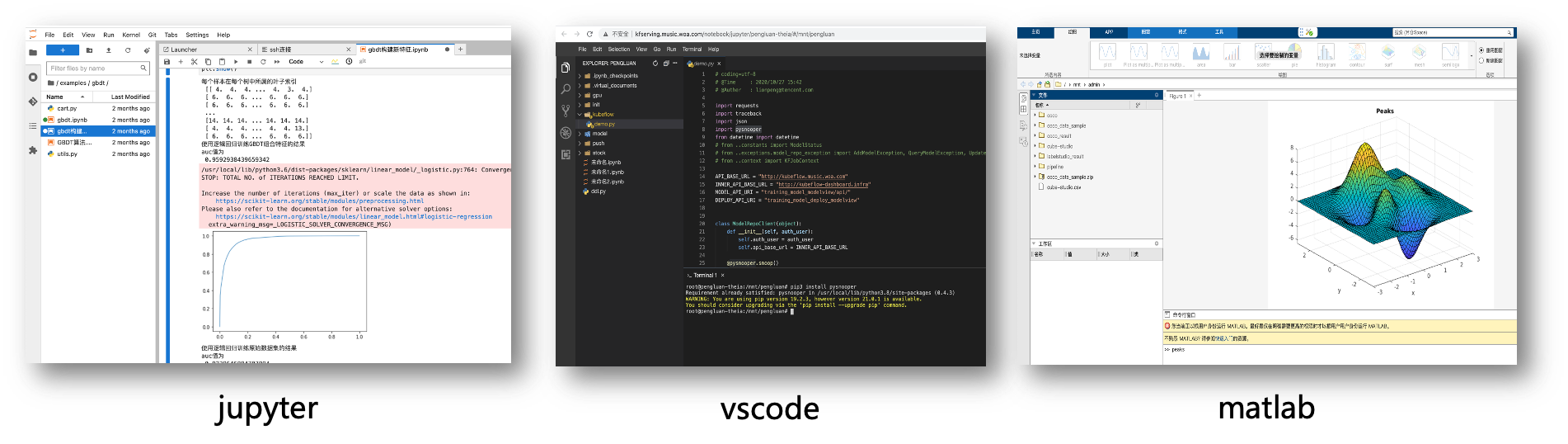
在线开发
- 系统多租户/多实例管理,在线交互开发调试,无需安装三方控件,只需浏览器就能完成开发。
- 支持vscode,jupyter,Matlab,Rstudio等多种在线IDE类型
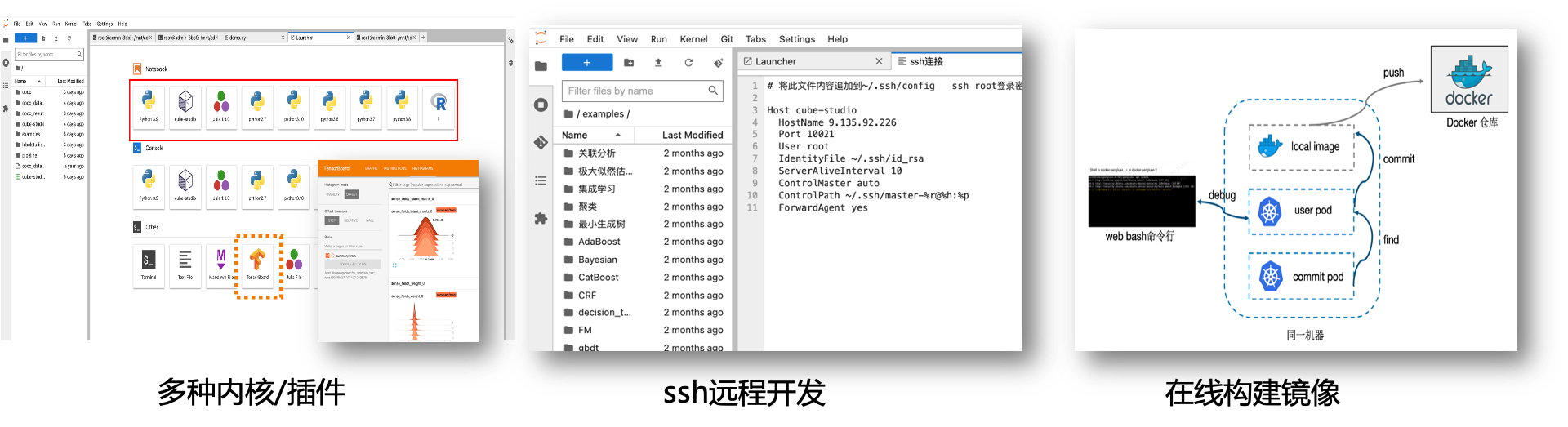
- Jupyter支持cube-studio sdk,Julia,R,python,pyspark多内核版本,
- 支持c++,java,conda等多种开发语言,以及tensorboard/git/gpu监控等多种插件
- 支持ssh remote与notebook互通,本地进行代码开发
- 在线镜像构建,通过Web Shell方式在浏览器中完成构建;并提供各种版本notebook,inference,gpu,python等基础镜像
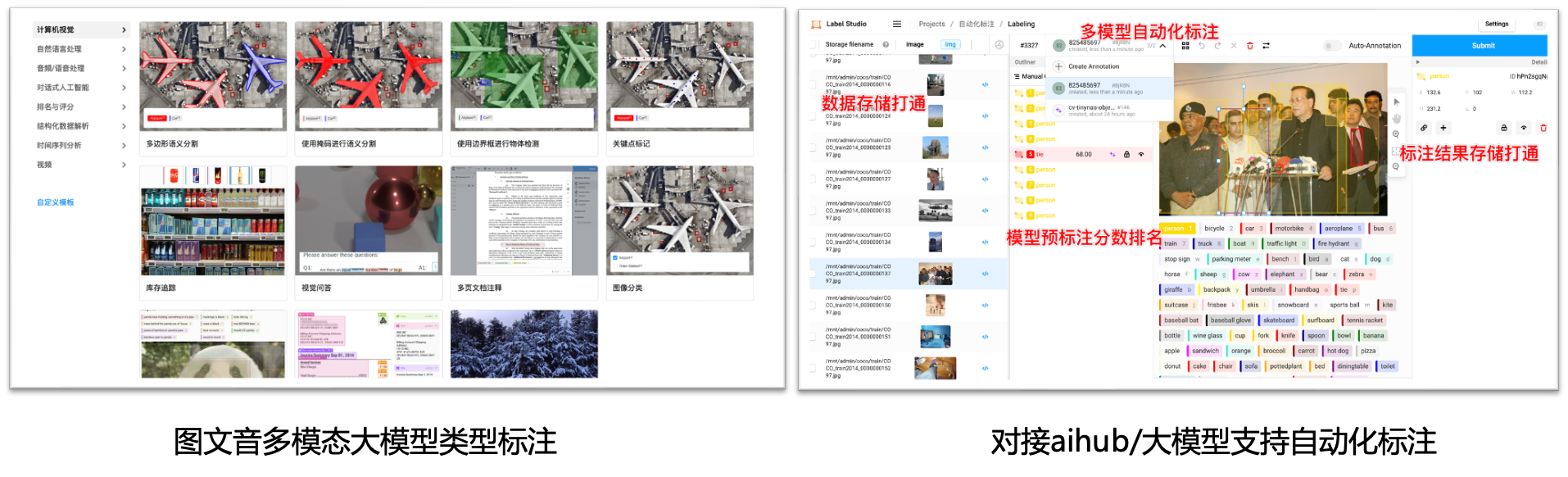
标注平台
- 支持图/文/音/多模态/大模型多种类型标注功能,用户管理,工作任务分发
- 对接aihub模型市场,支持自动化标注;对接数据集,支持标注数据导入;对接pipeline,支持标注结果自动化训练
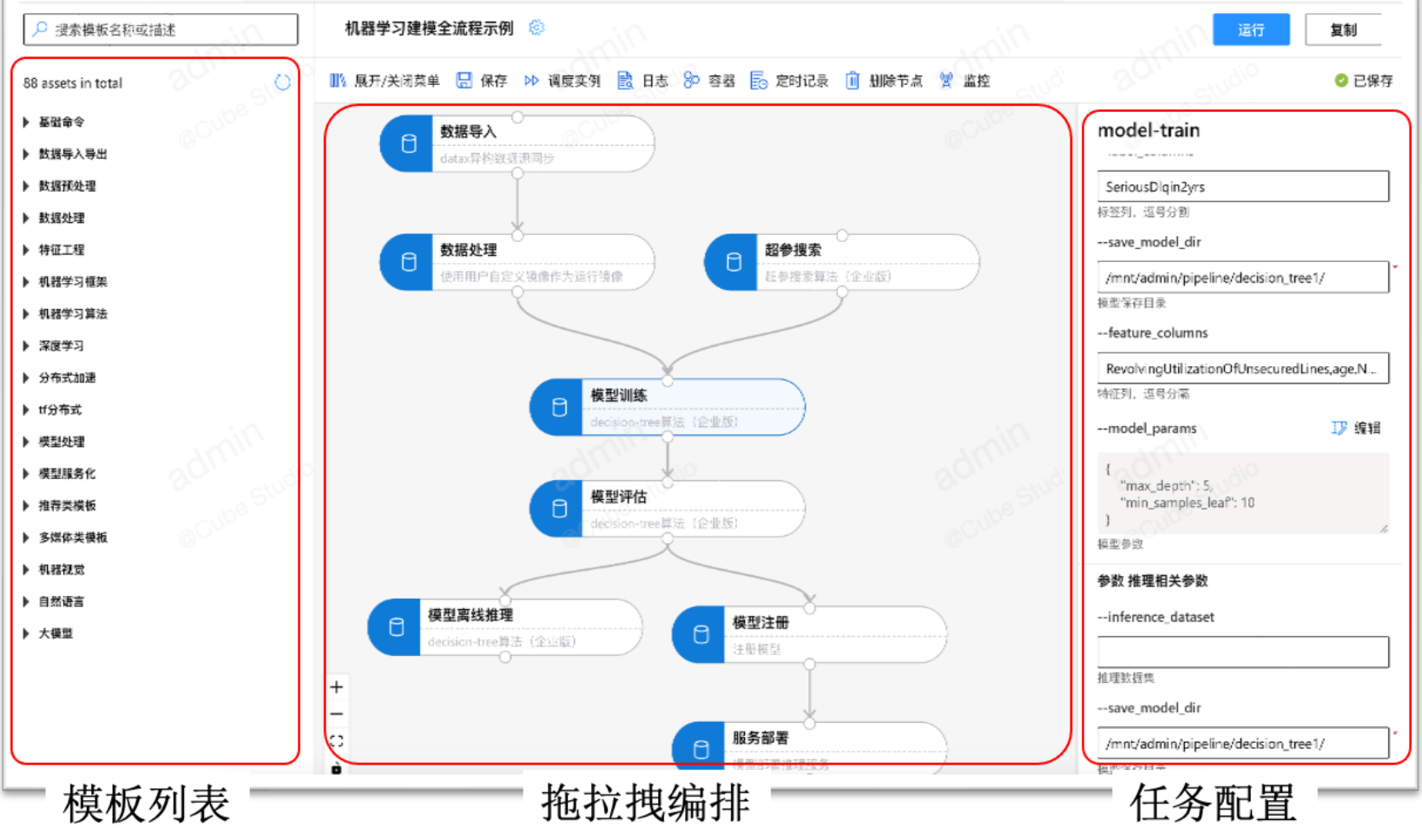
拖拉拽pipeline编排
1、Ml全流程
数据导入,数据预处理,超惨搜索,模型训练,模型评估,模型压缩,模型注册,服务上线,ml算法全流程
2、灵活开放
支持单任务调试、分布式任务日志聚合查看,pipeline调试跟踪,任务运行资源监控,以及定时调度功能(包含补录,忽略,重试,依赖,并发限制,过期淘汰等功能)
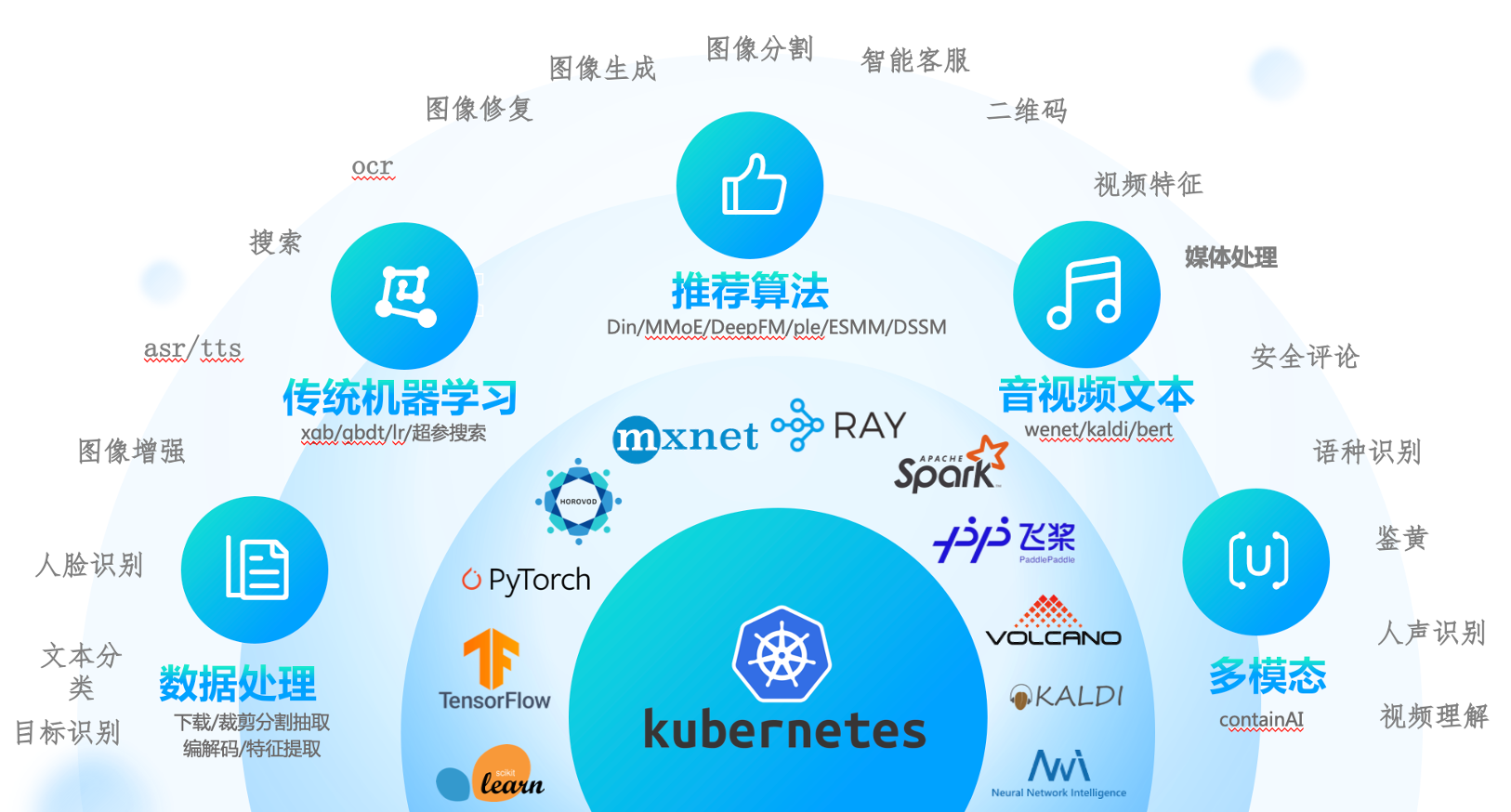
分布式框架
1、训练框架支持分布式(协议和策略)
2、代码识别分布式角色(有状态)
3、控制器部署分布式训练集群(operator)
4、配置分布式训练集群的部署(CRD)
多层次多类型算子
以k8s为核心,
1、支持tf分布式训练、pytorch分布式训练、spark分布式数据处理、ray分布式超参搜索、mpi分布式训练、horovod分布式训练、nni分布式超参搜索、mxnet分布式训练、volcano分布式数据处理、kaldi分布式语音训练等,
2、 以及在此衍生出来的分布式的数据下载,hdfs拉取,cos上传下载,视频采帧,音频抽取,分布式的训练,例如推荐场景的din算法,ComiRec算法,MMoE算法,DeepFM算法,youtube dnn算法,ple模型,ESMM模型,双塔模型,音视频的wenet,containAI等算法的分布式训练。
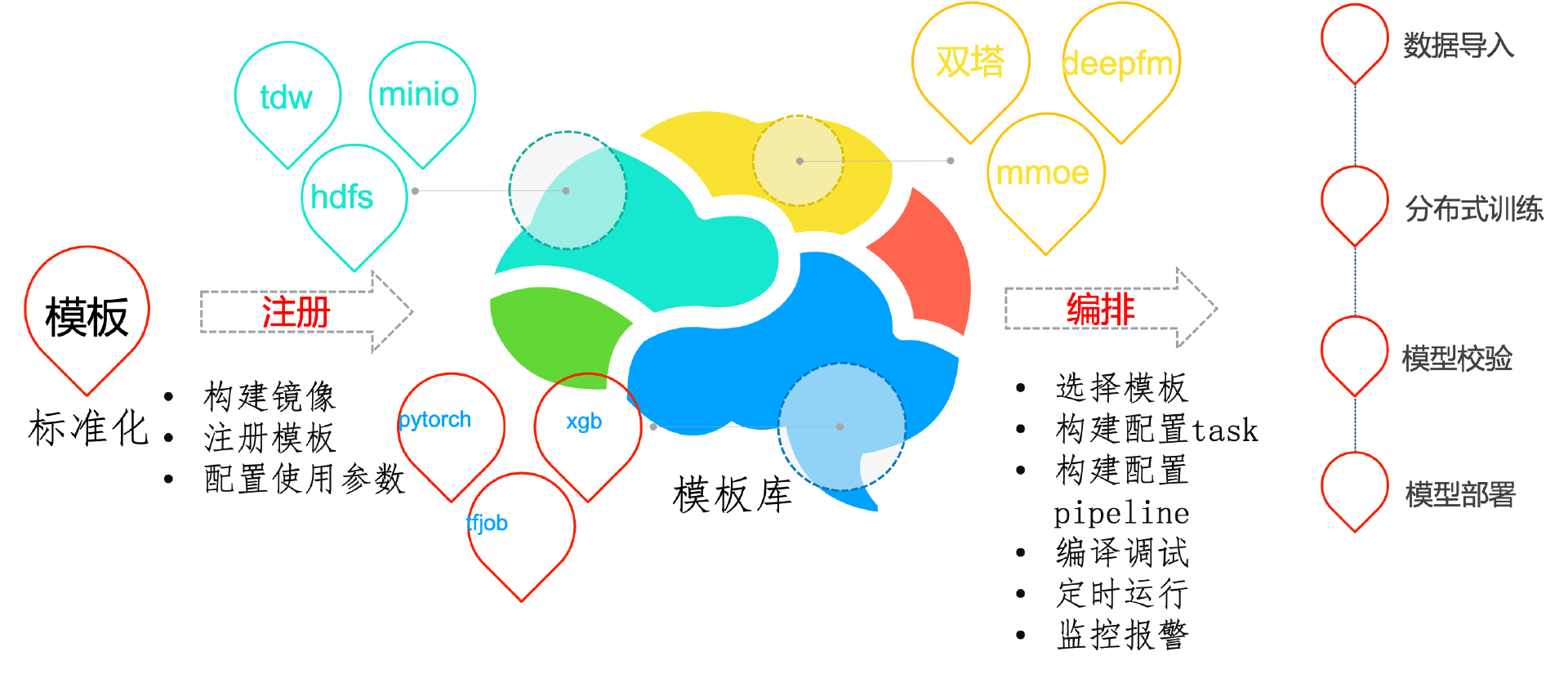
功能模板化
- 和非模板开发相比,使用模板建立应用成本会更低一些,无需开发平台。
- 迁移更加容易,通过模板标准化后,后续应用迁移迭代只需迁移配置模板,简化复杂的配置操作。
- 配置复用,通过简单的配置就可以复用这些能力,算法与工程分离避免重复开发。
为了避免重复开发,对pipeline中的task功能进行模板化开发。平台开发者或用户可自行开发模板镜像,将镜像注册到平台,这样其他用户就可以复用这些功能。平台自带模板在job-template目录下
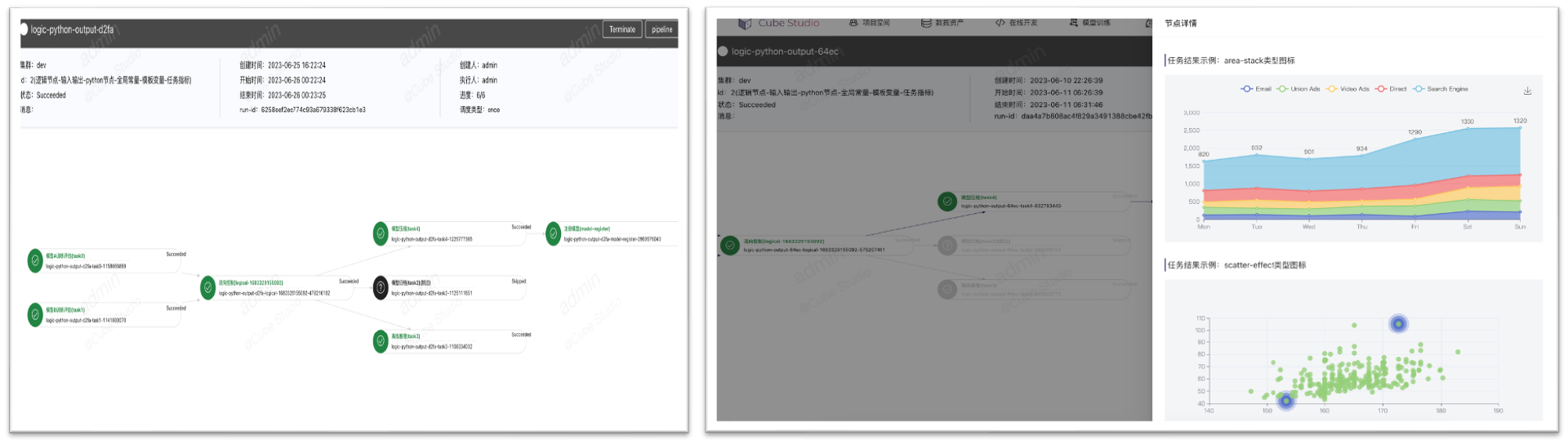
流水线调试
- Pipeline调试支持定时执行,支持,补录,并发限制,超时,实例依赖等。
- Pipeling运行,支持变量在任务间输入输出,全局变量,流向控制,模板变量,数据时间等
- Pipeling运行,支持任务结果可视化,图片、csv/json,echart源码可视化
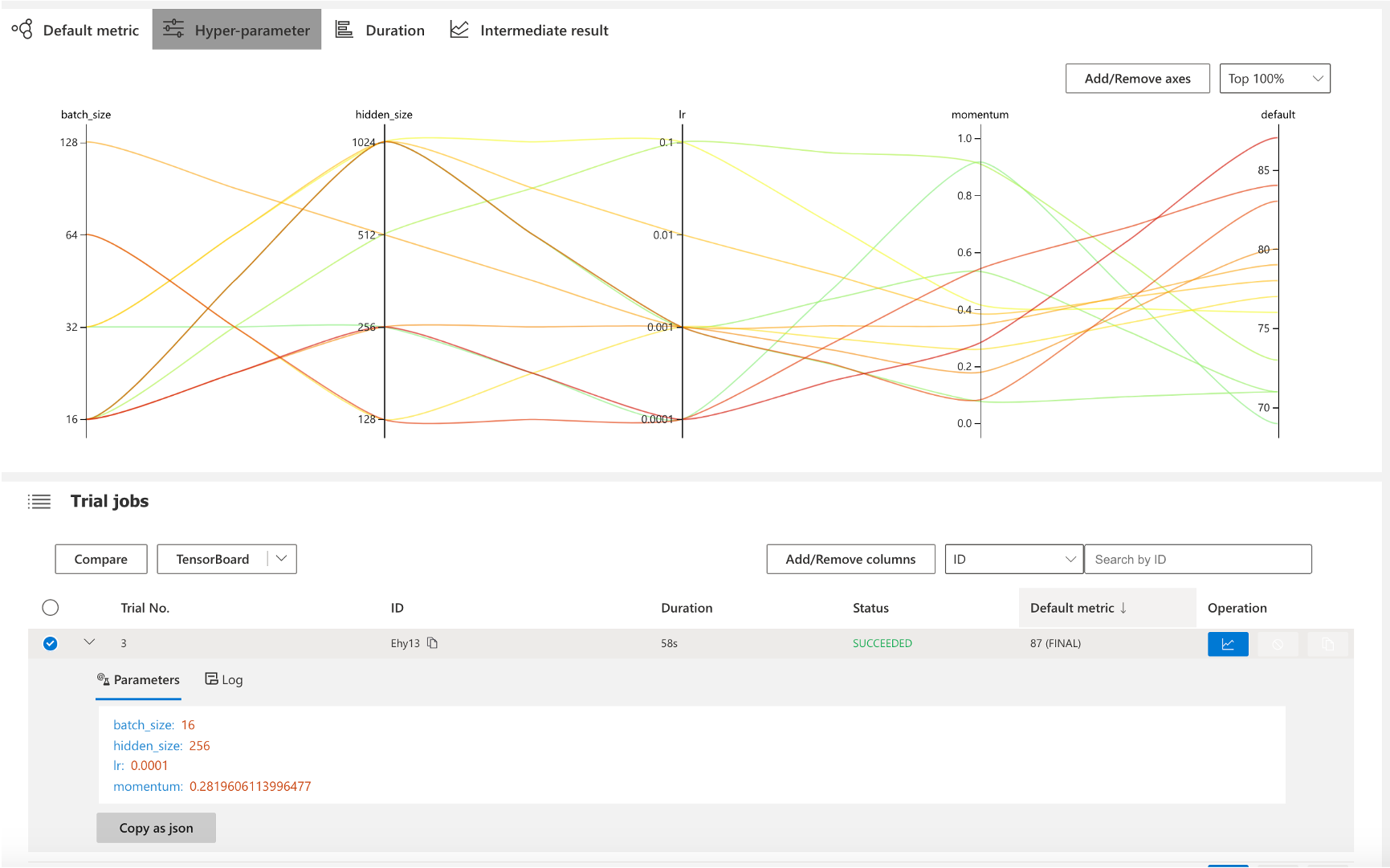
nni超参搜索
界面化呈现训练各组数据,通过图形界面进行直观呈现。 减少以往开发调参过程的枯燥感,让整个调参过程更加生动具有趣味性,完全无需丰富经验就能实现更精准的参数控制调节。
# 上报当前迭代目标值
nni.report_intermediate_result(test_acc)
# 上报最终目标值
nni.report_final_result(test_acc)
# 接收超参数为输入参数
parser.add_argument('--batch_size', type=int)
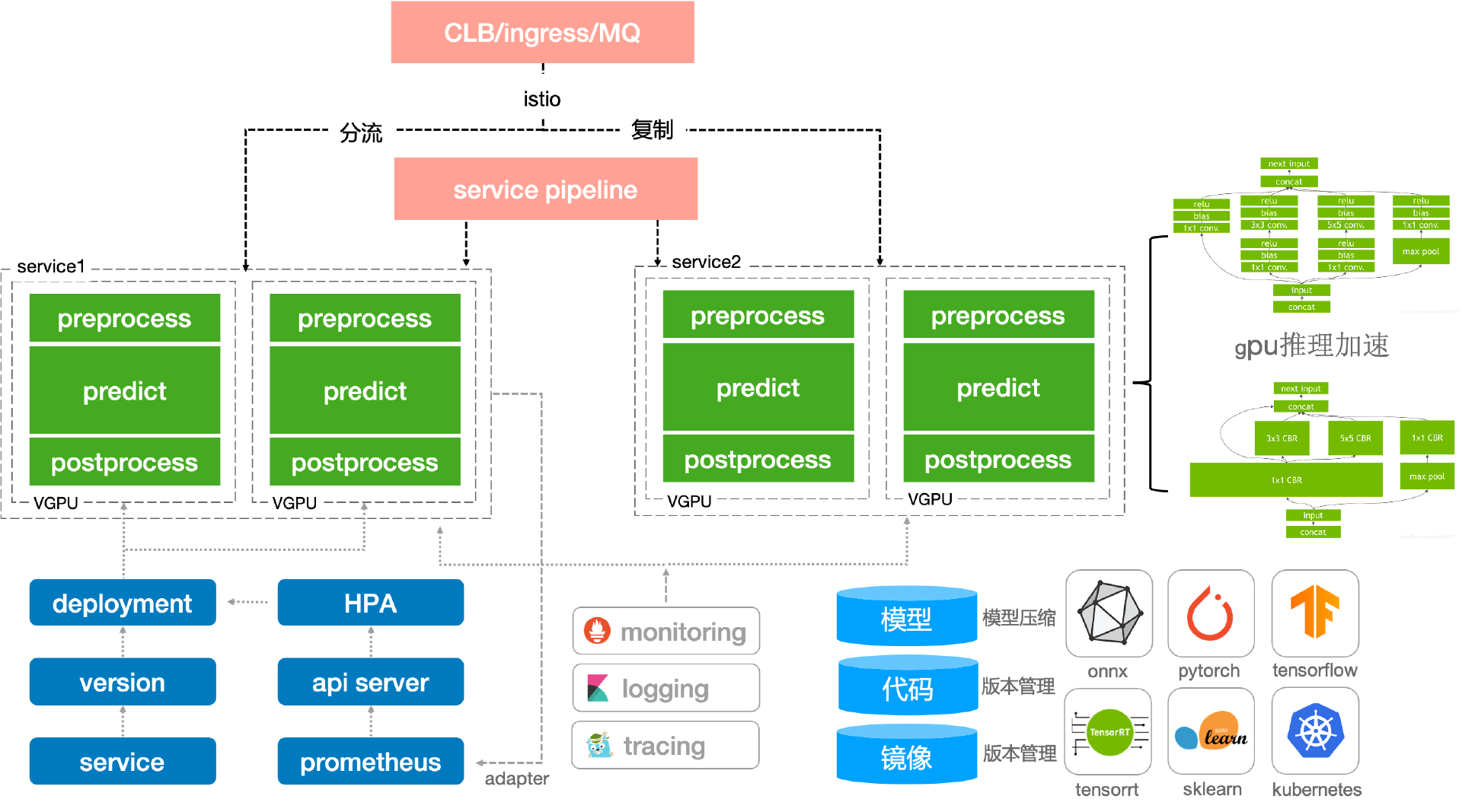
推理服务
0代码发布推理服务从底层到上层,包含服务网格,serverless,pipeline,http框架,模型计算。
- 服务网格阶段:主要工作是代理流量的中转和管控,例如分流,镜像,限流,黑白名单之类的。
- serverless阶段:主要为服务的智能化运维,例如服务的激活,伸缩容,版本管理,蓝绿发布。
- pipeline阶段:主要为请求在各数据处理/推理之间的流动。推理的前后置处理逻辑等。
- http/grpc框架:主要为处理客户端的请求,准备推理样本,推理后作出响应。
- 模型计算:模型在cpu/gpu上对输入样本做前向计算。
主要功能:
- 支持模型管理注册,灰度发布,版本回退,模型指标可视化,以及在piepline中进行模型注册
- 推理服务支持多集群,多资源组,异构gpu环境,平台资源统筹监控,VGPU,服务流量分流,复制,sidecar
- 支持0代码的模型发布,gpu推理加速,支持训练推理混部,服务优先级,自定义指标弹性伸缩。
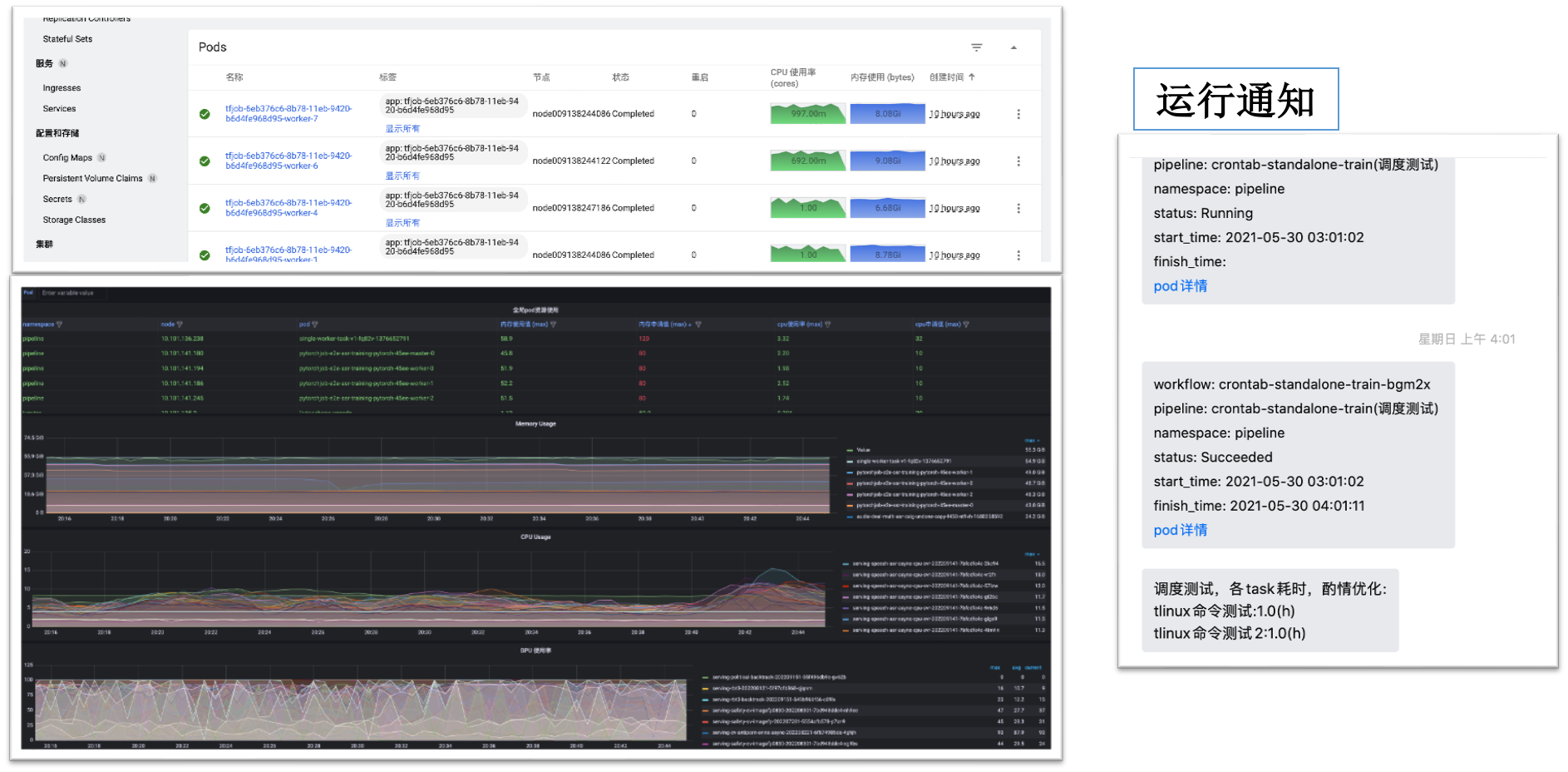
监控和推送
监控:cube-studio集成prometheus生态,可以监控包括主机,进程,服务流量,gpu等相关负载,并配套grafana进行可视化
推送:cube-studio开放推送接口,可自定义推送给企业oa系统
AIHub
- 系统自带通用模型数量400+,覆盖绝大数行业场景,根据需求可以不断扩充。
- 模型开源、按需定制,方便快速集成,满足用户业务增长及二次开发升级。
- 模型标准化开发管理,大幅降低使用门槛,开发周期时长平均下降30%以上。
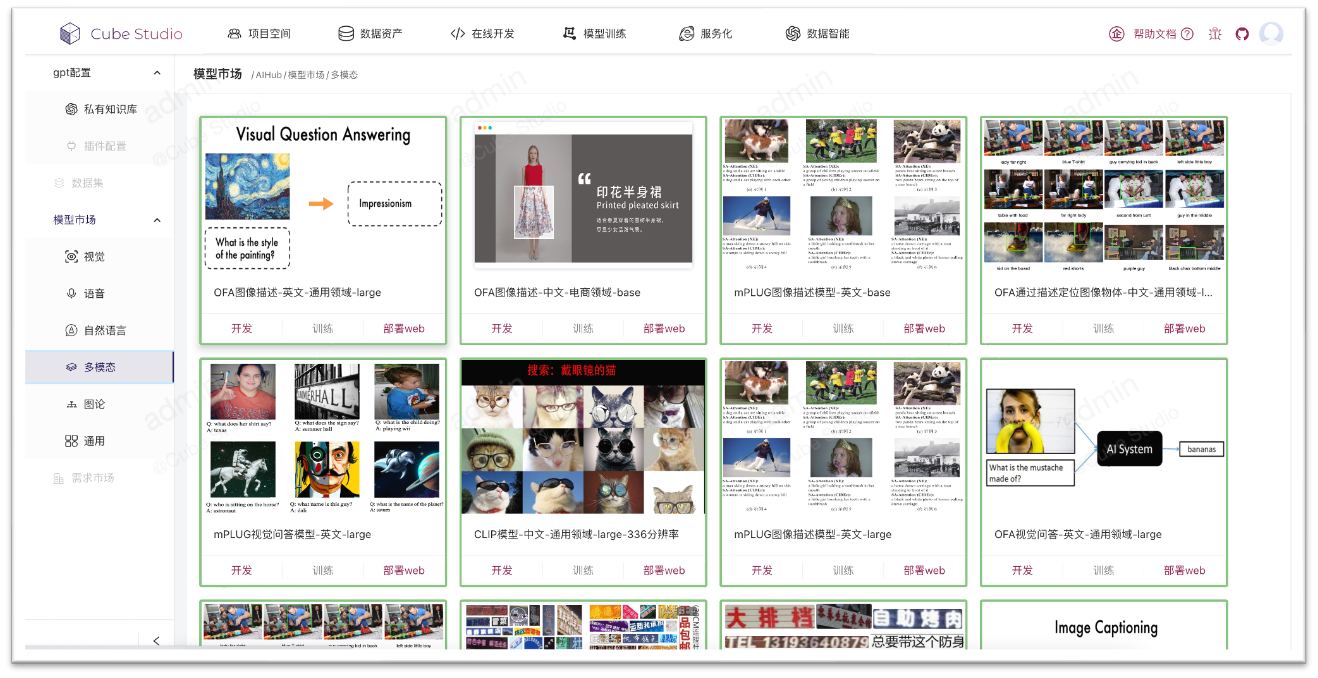
- AIHub模型可一键部署为WEB端应用,手机端/PC端皆可,实时查看模型应用效果
- 点击模型开发即可进入notebook进行模型代码的二次开发,实现一键开发
- 点击训练即可加入自己的数据进行一键微调,使模型更贴合自身场景
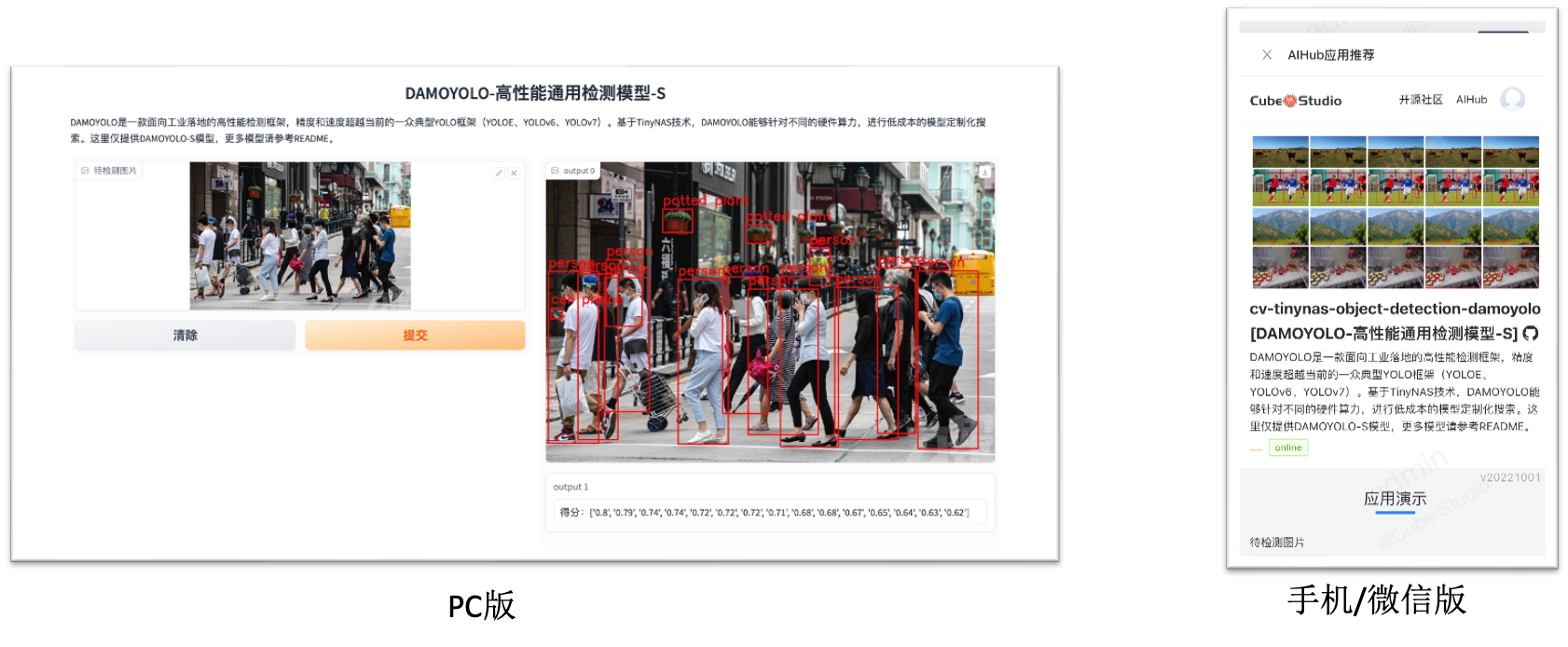
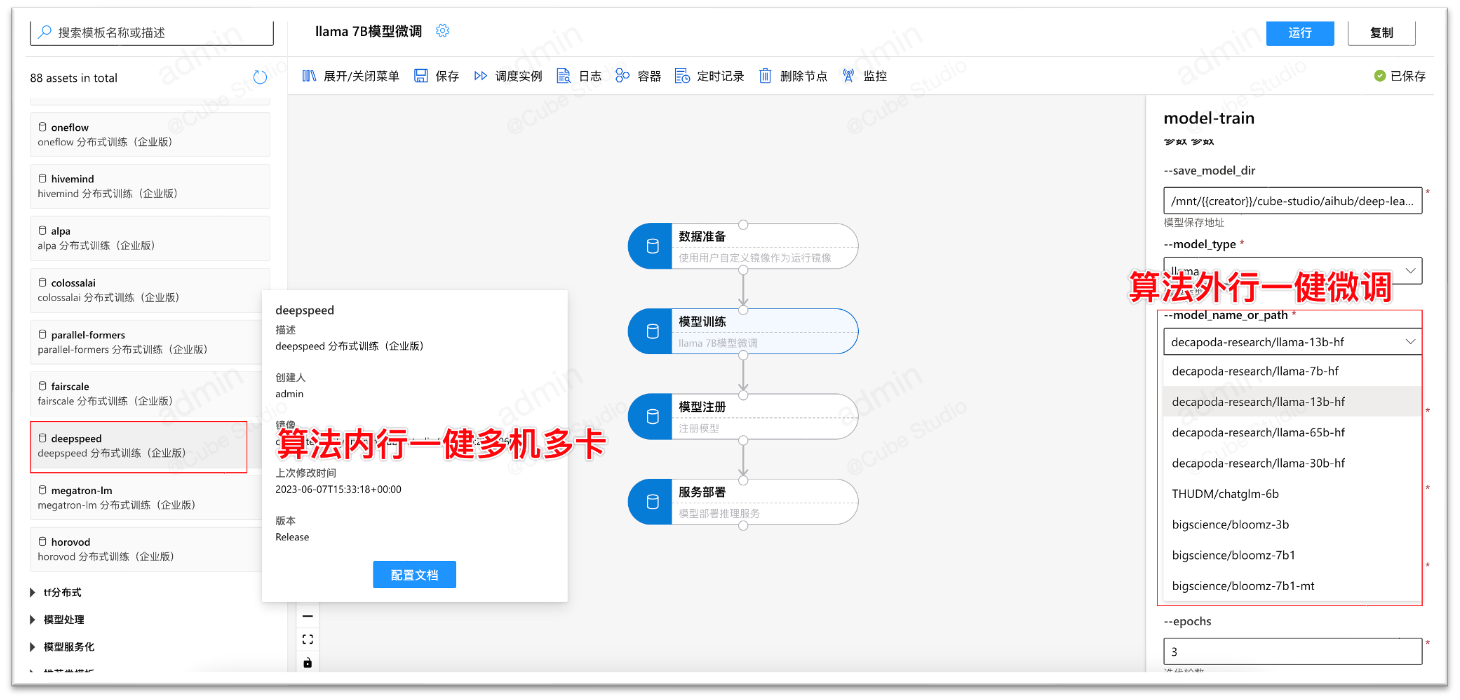
GPT训练微调
- cube-studio支持deepspeed/colossalai等分布式加速框架,可一键实现大模型多机多卡分布式训练
- AIHub包含gpt/AIGC大模型,可一键转为微调pipeline,修改为自己的数据后,便可以微调并部署
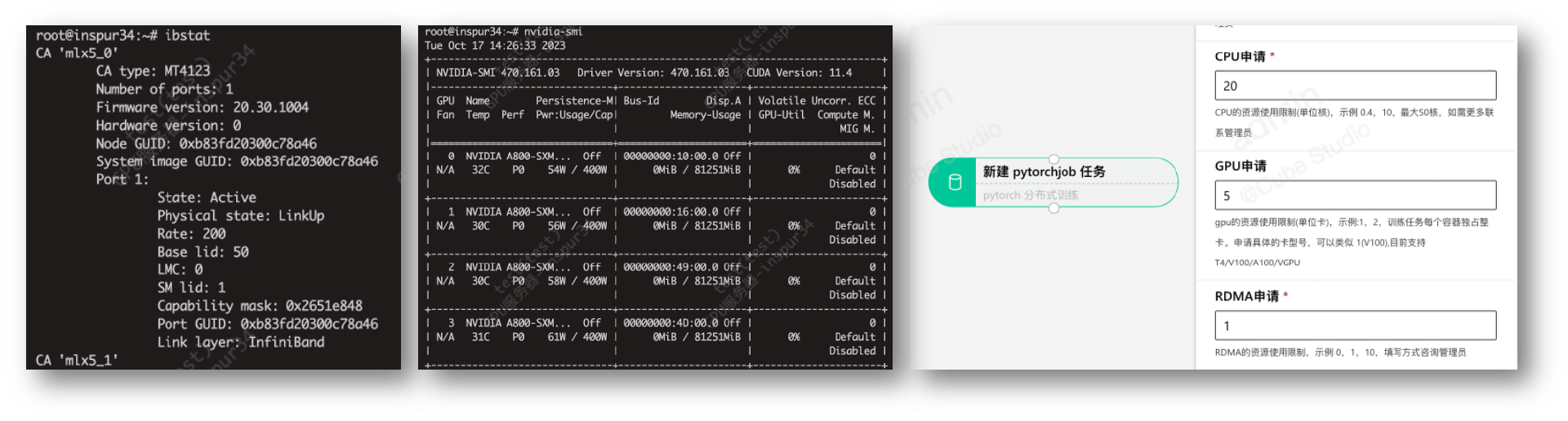
GPT-RDMA
rdma插件部署后,k8s机器可用资源
capacity:cpu: '128'memory: 1056469320Kinvidia.com/gpu: '8'rdma/hca: '500'
代码分布式训练中使用IB设备
export NCCL_IB_HCA=mlx5 export MLP_WORKER_GPU=$GPU_NUM export MLP_WORKER_NUM=$WORLD_SIZE export MLP_ROLE_INDEX=$RANK export MLP_WORKER_0_HOST=$MASTER_ADDR export MLP_WORKER_0_PORT=$MASTER_PORT
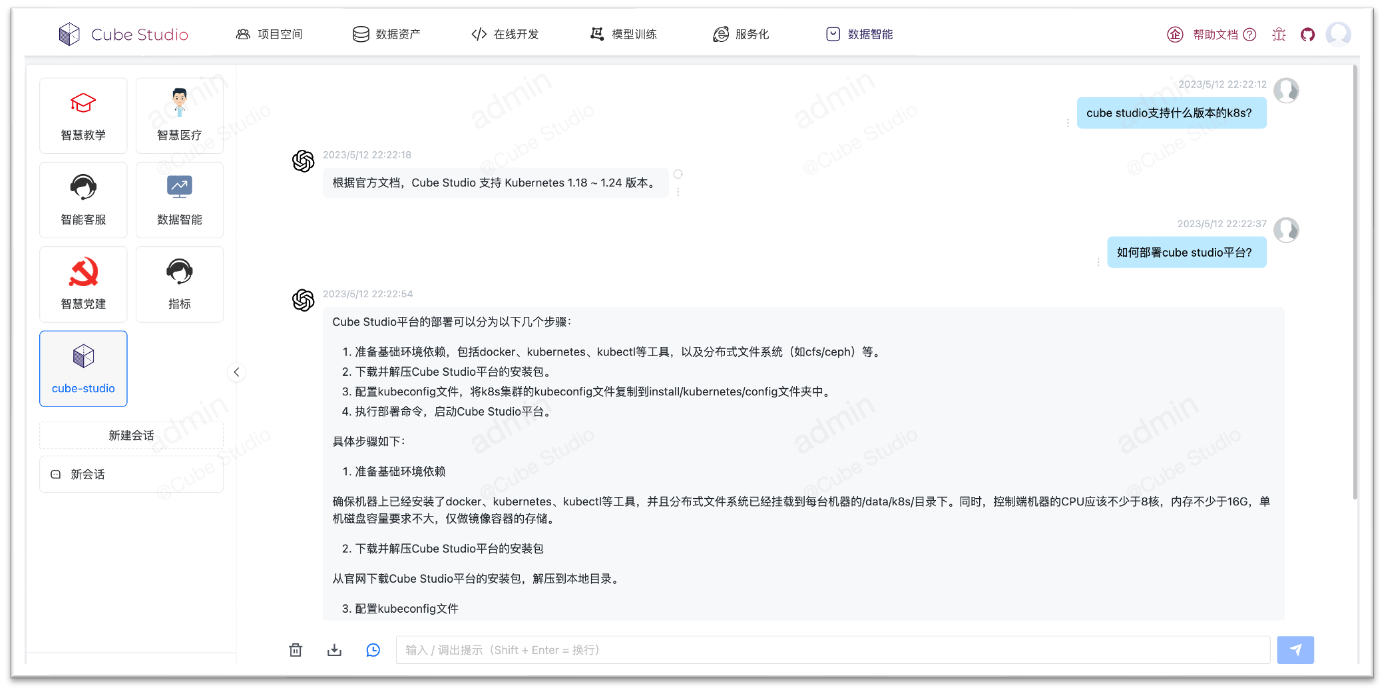
gpt私有知识库
- 数据智能模块可配置专业领域智能对话,快速敏捷使用llm
- 可为某个聊天场景配置私有知识库文件,支持主题分割,语义embedding,意图识别,概要提取,多路召回,排序,多种功能融合
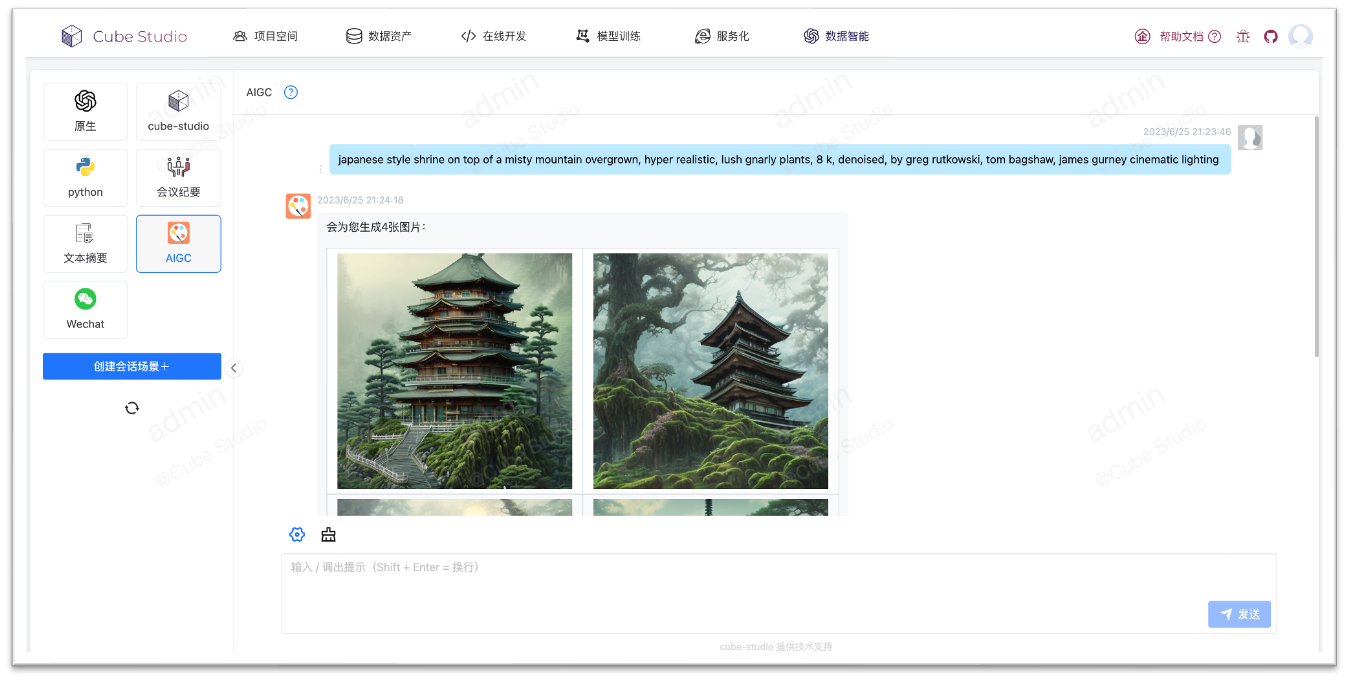
gpt智能聊天
- 可以将智能会话与AIHub相结合,例如下面AIGC模型与聊天会话
- 可使用Autogpt方式串联所有aihub模型,进行图文音智能化处理
- 智能会话与公共直接打通,可在微信公众号中进行图文音对话
数据平台对接
为了加速AI算法平台的使用,cube-studio支持对接公司原有数据中台,包括数据计算引擎sqllab,元数据管理,指标管理,维表管理,数据ETL,数据集管理

三种方式部署
针对企业需求,根据不同场景对计算实时性的不同需求,可以提供三种建设模式
模式一:私有化部署——对数据安全要求高、预算充足、自己有开发能力
模式二:边缘集群部署——算力分散,多个子网环境的场景,或边缘设备场景
模式三:serverless集群——成本有限,按需申请算力的场景
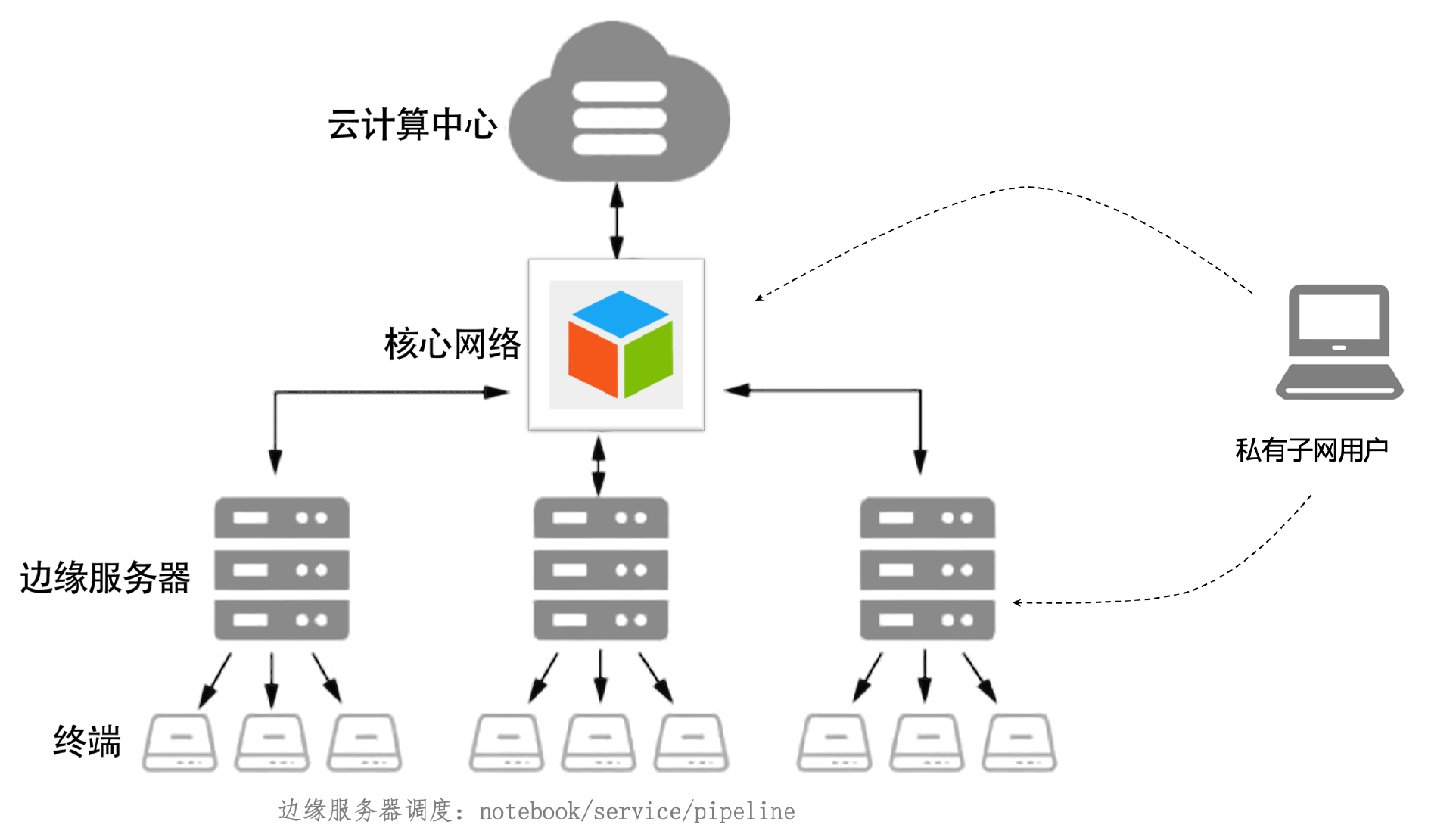
边缘计算
通过边缘集群的形式,在中心节点部署平台,并将边缘节点加入调度,每个私有网用户,通过项目组,将notebook,pipeline,service部署在边缘节点
- 1、避免数据到中心节点的带宽传输
- 2、避免中心节点的算力成本,充分利用边缘节点算力
- 3、避免边缘节点的运维成本
三、AI实战项目课程
以下是为CS/AI专业本科生/高职设计的AI课程大纲,课程为《数据挖掘与深度学习深度实战课程》。课程16章,96课时。
导学
- 数据挖掘技术在商业领域的常见应用
- 数据挖掘工程师岗位介绍与岗位职责
- 数据挖掘工程师需求现状与发展前景
- 高价值数据挖掘工程师的能力模型与成长路径
- 课程整体的设计逻辑、内容安排及项目简介
- 建议的学习方法、学习路线及课程收获
第一部分:数据获取和数据理解
1、 数据化分析问题思维
- 信度与效度思维、平衡思维、分类思维、矩阵思维
- 管道/漏斗思维、相关思维、远近度思维、逻辑树思维
- 时间序列思维、队列分析思维、循环/闭环思维、测试/对比思维
- 指数化思维、极端化思维、反向思维
2、 数据探索和EDA
- 变量确定
- 单变量分析
- 双变量分析
- 处理缺失值
- 处理离群值
- 变量转换
3、数据获取与存储
- Spark的入门
- RDD原理
- DataSet和DataFrame
- SQL语法的使用
- ClickHouse和MPP查询
- 数据仓库中的ODS\DWD\DWS\ADS
4、 爬虫与正则
- 数据来源和数据获取技术
- 爬虫以及爬虫中需要注意的事项
- 正则表达式的使用
项目:供应链金融的数据处理实战
项目描述:移动互联网红利期已经过去,产业互联网是未来的发展主战场,供应链金融是产业互联网最重要的环节,是未来各行各业最重要的经济形式。供应链金融可以更好地满足部分中小企业的资金需求,有利于整个产业链的协同发展。本部分以供应链金融为例,具体讲解数据处理流程以及风险控制建模方法。
项目中涉及到的模块有:
- 采购阶段预付款融资中的数据处理
- 生产阶段库存融资中的数据处理
- 销售阶段应收账款融资中的数据处理
- 供应链金融的风险控制建模
- 定义问题及分析
- 所需要的数据描述
- 采集数据、处理数据
- 模型的构建
难度:业务知识适中;技术知识:容易、重要
数据:农产品供应链各环节企业为期1年的股票收盘价数据
学习效果:掌握如何进行未知领域的业务分析,面对全新问题学会如何定义问题、数据收集、数据存储和处理。
学员作业:实现供应链金融数据处理和分析,包括:
- 编写爬虫程序,自行爬取指定的数据源
- 对爬取到的数据做数据处理
- 进行业务建模
第二部分:数据清洗与特征选择
1、 数据预处理
- Spark MLlib的数据类型
- 无量纲化:归一化、标准化、区间缩放法
- 对定量特征二值化,对定性特征哑编码,缺失值计算,数据变换
2、 Pandas基本用法
3、 one-hot编码和embedding的异与同
4、 降维方法(PCA、LDA)
5、 特征选择方法
- 方差选择法
- 相关系数法
- 卡方检验
- 互信息法
项目:基于供应链金融数据的清洗与特征选择
项目描述:本项目沿用第一部分的数据,并对于供应链金融数据进行预处理和特征选择。
项目中涉及到的模块有:
- 对业务数据进行预处理(如归一化等操作)
- 把原始数据转换成有效的特征
- 对数据进行降维操作
- 对数据进行特征选择
学习效果:
1、掌握如何进行未知领域的业务分析,面对全新问题如何进行问题定义,数据收集、数据存储和处理。
2、掌握数据处理的基本方法,包含如何进行数据预处理、特征表达、数据降维以及特征选择。
学员作业:供应链金融的数据处理,需要完成的内容包括:
- 用获取到的供应链金融数据进行数据加工处理
- 基于处理好的数据完成建模。
第三部分:数据的可视化分析
1、Matplotlib的基本用法
- 坐标、2D绘图、散点图、条形图、
- 直方图、饼图、箱型图、泡泡图、等高线
2、描述统计学中的可视化
- Seaborn的可视化(scatter、pairplot、swarmplot)
- 五数概括法和boxplot、violinplot
- 相关性分析
- 直方图上的kde(核概率密度估计)
3、SHAP VALUES
4、词云可视化
项目:基于微博数据的舆情分析
项目说明:舆情对于经济、社会、文化都是至关重要的。舆情是对于了解行情、产品和公司来说最直接的一手信息来源。在这个项目中,我们将对于微博数据进行分析。通过此项目,可以掌握如何把多维分析结果可视化出来,并转化为有指导意义的数据价值。
项目中涉及到的模块有:
- 挖掘出特定人群的兴趣点
- 分词、去掉停用词、提取关键词
- 计算单词之间的相似度
- 对于数据结果的可视化
难度:简单、重要
数据:微博文本数据
学习效果:掌握各种数据可视化方式,并可以用可视化的方式查看数据分布、趋势变化,从而发现数据之间的关联和规律,挖掘数据的价值
学员作业:基于微博数据的可视化分析,需要完成的部分包括:
- 文本预处理
- 实现词云可视化
第四部分:因果推断
1、因果推断的基本概念
- 辛普森悖论、变量关系图
- 因果关系估计偏差来源
- 常见因果关系估计方法概览
2、因果推断的技术路线及发展方向
- 断点回归
- 工具变量
- 倾向匹配得分
- 探索性实验
3、反事实推断dml
- 价格需求弹性计算
项目:基于因果推断的营销产品定价策略
项目描述:在营销场景中,我们需要对产品进行定价,这需要建立起需求数量随商品价格变动而变动的弹性,因为混杂因素(季节性、产品质量等)会干扰,我们用dml方法进行因果推断,可以通过正则化挑拣重要控制变量,用非参数推断解决非线性问题。
项目中涉及到的模块有:
- OLS回归
- Poisson回归
- 多元岭回归
- dml
- 稳健型评估
数据:零售业中的营销数据
学习效果:学会用因果推断的方式简化业务模型,也就是如何通过因果关系,去考虑解决我们的目标问题需要的因果关系。
学员作业:独立实现一遍dml
第五部分:经典的数据挖掘算法
1、逻辑回归及ffm
- 逻辑回归介绍
- ffm介绍
- 广告ctr预测
2、决策树与随机森林到底是什么
- 决策树与随机森林
- 泰坦尼克号乘客是否获救
3、贝叶斯模型及在心脏病预测的使用
- 多项式模型
- 高斯模型
- 伯努利模型
4、隐马尔可夫模型及pagerank,tf-idf
- 隐马尔科夫模型
- PageRank
- tf-idf
5、knn最近邻
- 手写数字识别
- 约会网站的配对效果
6、Boosting算法
- Boosting的核心思想
- adaboost在人脸检测中的应用
7、Apriori算法
- Apriori算法介绍
- 实现超市购物记录分析
8、聚类
- K-MEANS聚类
- DBSCAN笑脸聚类
- 层次聚类
- 谱聚类
9、文本聚类
- LDA模型
案例说明:用常用的业务场景讲述经典的数据挖掘算法,以及在Spark MLlib的实现方式
学习效果:掌握算法原理及适合的应用场景,通过具有现实含义的案例讲解算法的具体实现。这一章的内容在面试中会经常被问到,因此要掌握每种算法的优劣以及实现中会踩到的坑。
作业:根据课程内容,独立实现一种算法的整个过程,并理解模型结果背后的业务含义。
第六部分:深度学习(Deep Learning)
1、感知机、神经元、梯度下降推理过程
2、前馈神经网络、循环网络、对称连接网络的基本概念
3、卷积神经网络CNN实现图像识别
4、循环神经网络(RNNs)
- RNN介绍
- 分析电子病历
- 预测患者病情发展
5、word2vec的原理及Spark中的具体实现
- Word2Vec介绍
- 文本聚类
项目:基于电子病例文本数据的疾病预测
项目说明:电子病历用于预测患者病情发展是医疗发展必须解决的一个难题,如何利用数据驱动的医疗保健,来提供最好的和最个性化的护理,正成为医疗行业革命成功的主要趋势之一,电子病历是推动这一数据驱动的医疗革命成功的主要载体,这个部分会学习利用深度学习的方法(如基于词嵌入模型)实现对电子病历信息的表示,利用长短期记忆(LSTM)网络模型特性,解决对电子病历信息时间上的无规律性和疾病信息长期依赖,实现对疾病风险的预测。
项目中涉及到的模块有:
- RNNs
- LSTMs
- 词向量
- 疾病风险的预测
数据:中医骨科电子病历数据集
学习效果:深度学习基本入门,了解深度学习的基本概念,了解cnn、lstm等常见的神经网络模型,了解word2vec的原理及应用场景。
学员作业:在本次作业中我们会提供一份视频数据,这些视频都已经打上的特定的标签,学员将根据标签信息完成对于视频的聚类。 (使用数据:视频数据)
第七部分:知识图谱(Knowledge Graph)
1、搭建知识图谱并存入Neo4j图数据库
- 命名实体识别
- 实体消歧
- 关系抽取
- 事件抽取
- 知识表示
2、APCNNs深度学习模型和知识图谱的融合
- APCNN模型介绍
- 从文本中识别实体
- 关系抽取
- 结果的排序
- 评估指标与效果验证
项目:基于知识图谱的电影推荐
项目说明:传统推荐主要考虑用户序列偏好,却忽视了细致的用户偏好,如用户具体喜欢某个物品的哪个属性等;而知识图谱提供了实体与实体之间更深层次、更长范围的关联,增强了推荐算法的挖掘能力,一定程度上提高了推荐的准确性和多样性,也有效地弥补交互信息的稀疏或缺失(冷启动)。
我们在这个部分会重点学习知识图谱的构建和使用过程,包含命名实体识别、实体消歧、关系抽取、事件抽取、知识表示。我们会拓展到深度学习与知识图谱的结合APCNNs模型,用深度学习的方式进行语料的选取和范围、关系抽取、结果生成与检测。学习完这一部分,学员对知识图谱有了一个比较全面的理解,不仅对于知识图谱的构建和使用有了场景化的理解,而且理解工业界对于知识图谱的应用范围以及知识图谱的优势。
项目中涉及到的模块有:
- 知识图谱的构建和使用
- 命名实体识别
- 实体消歧
- 关系抽取
- 事件抽取
数据源:电影推荐数据集(20M)
学习效果:系统掌握识图谱的搭建过程和技术实现路线。
学员作业:基于Neo4j的知识图谱搭建,需要完成:
- Neo4j的安装
- 节点和关系数据的整理
- 数据的导入以及图谱的可视化
第八部分:用户获取-营销案例分析
1、 营销中的用户获取介绍
- 用户获取的重要性
- 用于用户获取的经典方法
2、商品销量预测案例剖析
- 时序数据的处理
- ambari模型
- transformer模型
- 基于模型的销量预测
3、 日志数据分析案例剖析
- 日志采集和存储
- 漏斗模型
- 点击分析模型
- AAARR模型的数据表示
4、基于CRM的精准营销案例剖析
- CRM介绍
- 智能线索挖掘
- 精准营销
项目:智能用户获取实战
项目说明:用户获取是互联网甚至传统行业最关注的问题,我们通过处理淘宝的5458位用户的访问日志搭建漏斗模型、查看用户的转化路径,并可视化为桑基图,同时通过对流量日志的分析,讲解精准营销的思路,以及AAARR模型在数据挖掘上的技术技巧。目的是用最少的钱获得最多的用户,找到获客成本最低的渠道或方法,并不断加大该方向的投入,提升产出效率。
项目中涉及到的模块有:
- 销量预测
- 流量数据处理
- 精准营销
- AAARR
难度:适中,重要
数据源:淘宝用户行为数据集
学习效果:掌握时序模型,掌握流量数据处理的基本流程与技术,掌握精准营销的技术手段,了解aaarr模型。
学员作业:基于淘宝用户行为数据,实现漏斗模型并分析用户行为。
第九部分:用户运营-营销案例分析
1、用户画像的构建
- 用户画像介绍
- 标签体系的搭建
- 标签的存储
- 用户属性挖掘:特征、行为、需求
2、用户分群与RFM模型
- 用户分群的重要性
- 用户群体聚类
- 用户价值评分
- RFM模型
3、经典推荐算法
- 协同过滤
- Wide & Deep Learning
- A/B Testing
4、对不同用户群体的品类定位和诊断
- GDAD
- 产品特点定位
- 竞争考量定位
- 目标市场定位
- 消费情感定位
5、门店铺货分析
- 门店客群分析
- 标签匹配
- 缺货预警
6、pylift库的使用
- pylift库介绍
- 营销增益模型
项目:基于点击率数据的用户运营分析
项目说明:用户运营的主要目的是提升用户的复购,复看,复x率。学习该项目,可以掌握如何提升用户的活跃度和转化率,给企业提升营收。如何利用用户画像、用户分群、推荐算法和试探性实验来挖掘用户特征的价值,以及营销增益模型来进行点击率预测,即预测用户看到商品后点击的概率。
项目中涉及到的模块有:
- 搭建用户画像
- 用户分群
- 推荐算法
- 试探性实验
- 营销增益
难度:适中,重要
学习效果:重点掌握用户运营过程中的各种技术手段
数据源:用户画像比赛数据
学员作业:pylift库实现营销增益模型
第十部分:用户流失/用户召回-营销案例分析
1、 用户行为路径分析(AIPL)
- 关键路径
- 扩散路径
- 收敛路径
- 端点路径
2、 用户留存分析模型
- Cohort分析
- 渠道同期群分析方法
- 产品功能留存矩阵
- 友盟的留存分析案例
3、 间隔分析模型与FP-TREE 算法
4、 归因模型
- 最终互动模型
- 首次互动模型
- 线性归因模型
- 时间衰减归因模型
- 自定义
项目标题:基于行为数据的用户召回实战
项目说明:召回是让用户在产品生命周期中形成一个闭环,将已经流失的用户召回到平台中,让用户生命周期进行一定的延长。在本项目的学习中,我们需要对用户行为路径进行分析,对用户的留存进行分析。并根据FP-TREE 算法计算路径之间的频繁项,最后进行流失的归因。
项目中涉及到的模块有:
- 行为路径分析
- 留存分析
- FP-TREE算法
- 流失归因
难度:适中,重要
学习效果:重点掌握用户运营过程中的各种技术手段
数据源:用户行为数据集
学习效果:学习和掌握用户召回方面数据建模的整个过程。
学员作业:基于FP-TREE 算法进行对用户召回分析
第十一部分:金融业的数据挖掘
1、 金融智能风控体系
- 风险策略引擎
- 风险算法平台
- 信审系统
- 额度系统
- 案调系统
- 催收体系
- 监管服务体系
2、 基于两阶段模型的lgd估计
- lgd(违约损失率模型)的算法实现
- 判别模型和回归预测
3、 基于两阶段法做金融指数基金设计
- 资产选择(运用图神经网络)
- 资产配置
4、 经典的量化交易算法及实现
- 加权平均价格算法(VMAP)
- 时间加权平均价格(TWAP)
- 成交量加权平均价格算法(VWAP)
- 成交量固定百分比算法(VP)
- 执行落差交易策略(IS)
- Step算法、Sniffers算法
- 盘口策略、W&P策略、Hidden策略、Guerrilla游击队策略等
项目:违约损失率模型实战
项目说明:在金融行业中违规损失率模型是风控中比较重要的模型,它可以反应信用卡的风险情况。我们采用信用卡数据,学习如何进行数据清洗,用EDA对数据进行变量分析,然后用Multivariate Logistic Regression对数据进行分类(低风险和高风险两个类别),最后建立信用卡的风险策略。
项目中涉及到的模块有:
- 数据预处理和变量分析
- MLR
- 信用卡风险策略
数据源:信用卡模型的数据集
学习效果:学习和掌握金融业的风控和量化数据挖掘应用场景及基本的模型算法
第十二部分:物联网
1、物联网介绍
- 物联网发展现状
- 物联网的四层架构模型
2、物联网中的核心环节
- 设备数据采集
- 边缘计算
- MIST计算
3、联邦学习
- 数据的隐私问题
- fate整体架构
- 如何进行多方计算
- 联邦学习在医疗智能诊断上的应用
- IBM沃森实现原理
项目:整体物联网系统搭建演示
项目说明:物联网是指物与物、物与人的泛在连接,实现对物品和过程的智能化感知、识别和管理。这里我们会搭建一个物联网的简易demo,讲解物联网中如何实现数据采集、边缘计算、MIST 计算和联邦学习、数据隐私的技术方案。
项目中涉及到的模块有:
- 物联网数据层埃及
- 边缘计算
- MIST计算、联邦计算
- 数据隐私
学习效果:了解物联网的技术架构和物联网在各行业的应用,以及联邦学习的概念和技术架构。
第十三部分:工业互联网中的模型
1、工业互联网数据的分析流程
- 工厂业务流程
- ERP(经营情况分析)
- MES(计划准确率)
- WMS(存货周转率)
2、设备故障预测案例
- 物联网设备数据处理
- 时序模型
- lstm对故障分类判断
3、刀具寿命检测案例
- 刀具寿命的传统数据模型
- Taylor 模型
- Archard 模型
- Colding 模型
4、工场中的智能排产案例
- APS排产系统简介
- 最优经济批量计算
- 调度最优化问题
5、产品质量检测案例
- 小样本检测算法
- 质量检测中的图像识别
6、物流优化案例
- 旅行商问题
- 配送路线问题
- 多回路运输问题
- 最近邻点法
- 节约里程法
- 扫描算法
项目:工业互联网中的设备故障预测实战
项目说明:工业互联网是是第四次工业革命的重要基石,是国家进行产业升级的重要举措。通过讲解利用IoT 数据如何预测设备故障,根据目前设备的运行参数对于设备的健康状态进行分类,并且预估部件或系统的剩余寿命或正常工作的时间长度。
项目中涉及到的模块有:
- IoT数据搜集和分析
- 设备故障预测
- 时序模型
数据源:IoT数据集
学习效果:通过本部分的学习,学员能了解目前数据挖掘在工业制造领域的应用场景,也能了解工业的数字化转型的现状和机遇。
第十四部分:基于图的数据挖掘
1、图数据介绍
- 图形数据格式
- 图数据库(存储)
- DFS图形数据遍历
2、 基于图结构的表示学习
- deepwalk
- node2vec
3、基于图特征的表示学习
- gcn
- gat
4、图学习模型在生物图上的应用
- 生物图介绍
- G-Meta
项目:基于Deepwalk进行对于维基百科数据的分类和可视化
项目说明:DeepWalk算法在wiki数据集上进行节点分类任务和可视化任务。 wiki数据集包含 2,405 个网页和17,981条网页之间的链接关系,以及每个网页的所属类别。主要包括两个步骤,第一步为随机游走采样节点序列,第二步为使用skip-gram model、word2vec学习表达向量。
项目中涉及到的模块有:
- DeepWalk算法
- skip-gram模型
- 词向量模型
- 表示学习
数据源:wiki的数据集
学习效果:了解图数据挖掘和遗传算法等优化算法。
第十五部分:最优化方法介绍
1、遗传算法与神经网络的结合应用
- 三相不平衡的应用
- 医生排班的应用
2、仿生优化算法快速实现迭代收敛
- 苍狼算法
- 鸽群优化算法
- 蚁群算法(tsp)
- 人工鱼群算法
- 人工免疫算法
3、隐私计算相关技术
- 同态加密
- 零知识证明
- 差分隐私(数据安全和区块链最重要的算法)
学习效果:了解遗传算法思想和隐私计算的相关技术
第十六部分:职业发展规划及毕业设计
1、 面试指导与行业经验分享
1.1 数据挖掘的二十问二十答(模拟真实面试场景)
1.2 行业经验:模拟数据科学家的一天
- 互联网电商和o2o数据科学家的主要工作是什么?
- 互联网医疗的数据科学家的主要工作
- 传统零售业的数据科学家的主要工作
- 传统制造业的数据科学家的主要工作
2、项目实操
(1)供应链金融里的风险控制
要求:可以自由选择一个行业进行建模,利用爬虫获取该行业的供应链上下游各环节的重要企业的财报数据和股票数据,对数据进行数据处理和分析,然后利用我们所讲解到的两阶段的违约损失率模型进行建模,最后得出每个企业的违规损失率的风险值。
(2)零售业营销集成化
要求:利用提供的流量日志数据,对数据进行数据处理,建立漏斗模型,进行用户的行为路径分析,搭建客户画像,建立用户客群,进行用户的RFM模型分析,最后学员选择一种方式进行推荐系统模型的搭建。
(3)文本聚类模型实现微博话题发现
要求:通过爬虫获取微博的历史数据,利用自然语言处理技术对数据进行分词、去停用词和提取关键词等操作,学员选择一种方式对处理好的文本数据进行文本聚类,可以是lda,也可以是word2vec,最后利用情感分析,判别出舆情中热门的话题。
3.2 课程配套
1)课程介绍
2)课程大纲
3)PPT课件
4)实验指导书
5)实验相关资料:实验案例提供实验环境和实验指导手册。
四、华为云HCCDA-AI认证


考前理论学习内容
| 章/节 | 时长(分钟) | 学习目标 |
| 人工智能概览 | 56 | 了解人工智能基本定义、发展历史、技术架构、落地挑战、发展趋势、华为全栈全场景AI解决方案 |
| 人工智能应用集成需求分析 | 31 | 了解人工智能应用开发需求分析过程 |
| 华为云EI-API服务介绍 | 124 | 掌握华为云EI-API服务的适用场景及API调用方法 |
| 华为云ModelArts服务介绍 | 29 | 熟悉华为云ModelArts服务的功能和使用方法 |
| 华为云HiLens服务介绍 | 31 | 熟悉华为云HiLens服务的功能和使用方法 |
| 人工智能应用集成产品测试 | 22 | 熟悉人工智能应用产品测试的理论及方法 |
| 发票验真综合应用开发 | 23 | 熟悉发票验真综合应用开发方法 |
| 考试大纲及考试样题 | 60 | 了解认证考试的考点和比例分布 |
考前在线实验
1、图像识别API服务调用
实验时长:60分钟
2、文字识别API服务调用
实验时长:60分钟
3、自然语言处理API服务调用
实验时长:30分钟
4、语音交互API服务调用
实验时长:60分钟
5、ModelArts服务应用-商超商品识别
实验时长:60分钟
6、chatglm2-6b-int4模型推理部署
实验时长:60分钟
7、发票验真综合应用开发
实验时长:60分钟
考试
考试分为理论考试和实验考试,都是在线完成,完成后获得华为云HCCDA-AI认证。