目录
1.urllib库
1.1.request模块
1.1.1、urllib.request.urlopen() 函数
1.1.2.urllib.request.urlretrieve() 函数
1.2. error模块
1.3. parse 模块
2. BeautifulSoup4库
2.1.对象种类
2.2.对象属性
2.2.1.子节点
2.2.2.父节点
2.2.3.兄弟节点
2.2.4.回退和前进
2.3.对象方法
2.3.1.find_all()
2.3.2.find()
2.3.3.CSS选择器查找
2.3.4.修改内容
2.4.输出
2.4.1.格式化输出
2.4.2.压缩输出
2.4.3.文本输出
3.re标准库
大概会用到以下这些模块
| 分类 | 库名 | 主要用途 |
|---|---|---|
| 网络请求 | requests | 同步HTTP请求 |
aiohttp | 异步HTTP请求 | |
| 动态渲染 | selenium | 浏览器自动化 |
playwright | 高性能无头浏览器控制 | |
| 数据解析 | BeautifulSoup4 | HTML/XML解析 |
lxml | XPath/CSS选择器解析 | |
re | 字符串正则匹配(文本清洗/数据提取) | |
| 爬虫框架 | scrapy | 全功能爬虫框架 |
| 反反爬 | fake-useragent | 随机生成请求头 |
1.urllib库
Python3 中将 Python2 中的 urllib 和 urllib2 两个库整合为一个 urllib 库,所以现在一般说的都是 Python3 中的 urllib 库,它是python3内置标准库,不需要额外安装。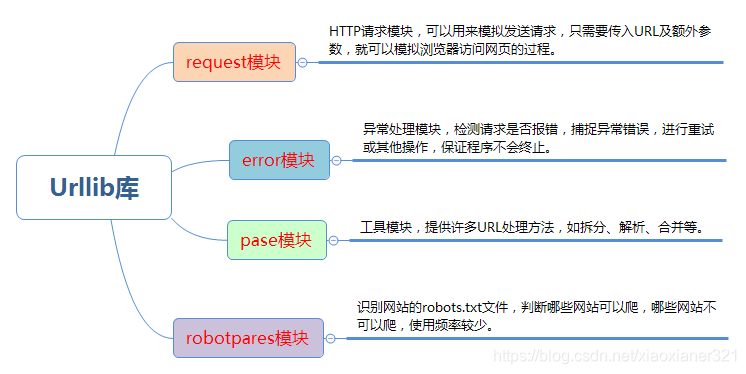
1.1.request模块
request模块提供了最基本的构造 HTTP 请求的方法,利用它可以模拟浏览器的一个请求发起过程,同时它还带有处理authenticaton(授权验证),redirections(重定向),cookies(浏览器Cookies)以及其它内容。
1.1.1、urllib.request.urlopen() 函数
语法:
urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None)参数说明:
url:请求的 url,也可以是request对象
data:请求的 data,如果设置了这个值,那么将变成 post 请求,如果要传递一个字典,则应该用urllib.parse模块的urlencode()函数编码;
timeout:设置网站的访问超时时间句柄对象;
cafile和capath:用于 HTTPS 请求中,设置 CA 证书及其路径;
cadefault:忽略*cadefault*参数;
context:如果指定了*context*,则它必须是一个ssl.SSLContext实例。urlopen() 返回对象HTTPResponse提供的方法和属性:1)read()、readline()、readlines()、fileno()、close():对 HTTPResponse 类型数据进行操作;
2)info():返回 HTTPMessage 对象,表示远程服务器 返回的头信息 ;
3)getcode():返回 HTTP 状态码 geturl():返回请求的 url;
4)getheaders():响应的头部信息;
5)status:返回状态码;
6)reason:返回状态的详细信息.案例一:使用urlopen()函数抓取百度
import urllib.request
url = "http://www.baidu.com/"
res = urllib.request.urlopen(url) # get方式请求
print(res) # 返回HTTPResponse对象<http.client.HTTPResponse object at 0x00000000026D3D00>
# 读取响应体
bys = res.read() # 调用read()方法得到的是bytes对象。
print(bys) # <!DOCTYPE html><!--STATUS OK-->\n\n\n <html><head><meta...
print(bys.decode("utf-8")) # 获取字符串内容,需要指定解码方式,这部分我们放到html文件中就是百度的主页# 获取HTTP协议版本号(10 是 HTTP/1.0, 11 是 HTTP/1.1)
print(res.version) # 11# 获取响应码
print(res.getcode()) # 200
print(res.status) # 200# 获取响应描述字符串
print(res.reason) # OK# 获取实际请求的页面url(防止重定向用)
print(res.geturl()) # http://www.baidu.com/# 获取响应头信息,返回字符串
print(res.info()) # Bdpagetype: 1 Bdqid: 0x803fb2b9000fdebb...
# 获取响应头信息,返回二元元组列表
print(res.getheaders()) # [('Bdpagetype', '1'), ('Bdqid', '0x803fb2b9000fdebb'),...]
print(res.getheaders()[0]) # ('Bdpagetype', '1')
# 获取特定响应头信息
print(res.getheader(name="Content-Type")) # text/html;charset=utf-8案例二:get请求
我们在http://httpbin.org/网站,发送一个get测试请求:
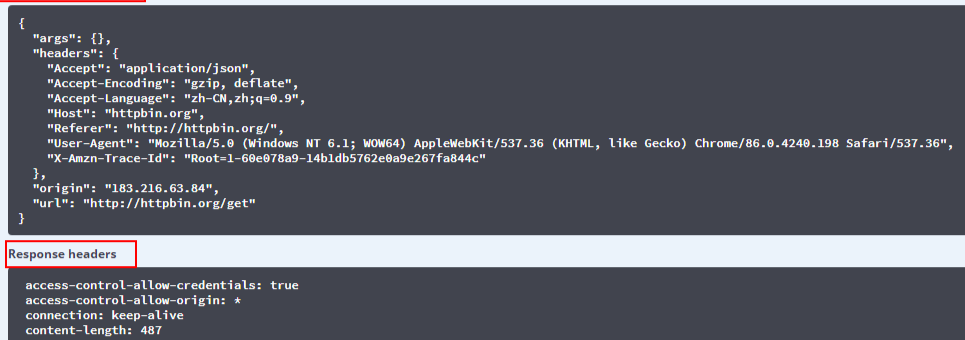
然后我们在使用python模拟浏览器发送一个get请求:
import urllib.request
# 请求的URL
url = "http://httpbin.org/get"
# 模拟浏览器打开网页(get请求)
res = urllib.request.urlopen(url)
print(res.read().decode("utf-8")) 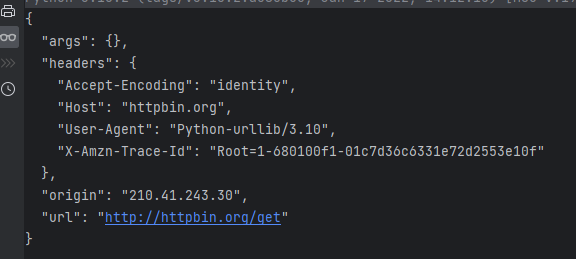
通过上面的案例,不难发现使用urllib发送的请求,比较不同的地方是:"User-Agent",使用urllib发送的会有一个默认的Headers:User-Agent: Python-urllib/3.8。所以遇到一些验证User-Agent的网站时,有可能会直接拒绝爬虫,因此我们需要自定义Headers把自己伪装的像一个浏览器一样。
案例三: 伪装Headers
我去爬取豆瓣网时:
import urllib.requesturl = "http://douban.com"
resp = urllib.request.urlopen(url)
print(resp.read().decode('utf-8'))返回错误:反爬虫
raise HTTPError(req.full_url, code, msg, hdrs, fp)
urllib.error.HTTPError: HTTP Error 418: HTTP 418 客户端错误响应代码表示服务器拒绝。
自定义Headers:
import urllib.requesturl = "http://douban.com"
# 自定义headers
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36'
}
req = urllib.request.Request(url, headers=headers)
# urlopen(也可以是request对象)
print(urllib.request.urlopen(req).read().decode('utf-8')) # 获取字符串内容,需要指定解码方式1.1.2.urllib.request.urlretrieve() 函数
urlretrieve()函数的作用是直接将远程的网页数据htlm下载到本地
# 语法:
urlretrieve(url, filename=None, reporthook=None, data=None)
# 参数说明
url:传入的网址
filename:指定了保存本地路径(如果参数未指定,urllib会生成一个临时文件保存数据)
reporthook:是一个回调函数,当连接上服务器、以及相应的数据块传输完毕时会触发该回调,我们可以利用这个回调函数来显示当前的下载进度
data:指 post 到服务器的数据,该方法返回一个包含两个元素的(filename, headers)元组,filename 表示保存到本地的路径,header表示服务器的响应头
import urllib.requesturl = "http://www.hao6v.com/"
filename = "C:\\pythonProject\\python爬虫\\gyp.html"def callback(blocknum, blocksize, totalsize):"""@blocknum:目前为此传递的数据块数量@blocksize:每个数据块的大小,单位是byte,字节@totalsize:远程文件的大小"""if totalsize == 0:percent = 0else:percent = blocknum * blocksize / totalsizeif percent > 1.0:percent = 1.0percent = percent * 100print("download : %.2f%%" % (percent))local_filename, headers = urllib.request.urlretrieve(url, filename, callback)
1.2. error模块
urllib.error 模块为 urllib.request 所引发的异常定义了异常类,基础异常类是 URLError。
| 状态码 | 分类 | 定义 |
|---|---|---|
| 1xx | 信息响应 | |
| 100 | Continue | 服务器已接收请求头,客户端应继续发送请求体 |
| 101 | Switching Protocols | 协议切换(如HTTP→WebSocket) |
| 2xx | 成功响应 | |
| 200 | OK | 请求成功,响应内容取决于请求方法(GET/POST等) |
| 201 | Created | 资源创建成功(常用于POST/PUT) |
| 204 | No Content | 无返回内容,但响应头可能含元信息 |
| 3xx | 重定向 | |
| 301 | Moved Permanently | 资源永久重定向到新URI |
| 302 | Found | 资源临时重定向(早期规范语义不明确,建议用307/308替代) |
| 304 | Not Modified | 资源未修改(缓存相关) |
| 4xx | 客户端错误 | |
| 400 | Bad Request | 请求语法错误 |
| 403 | Forbidden | 服务器拒绝执行(无权限) |
| 404 | Not Found | 资源不存在 |
| 408 | Request Timeout | 请求超时 |
| 5xx | 服务器错误 | |
| 500 | Internal Server Error | 服务器内部错误(无具体信息) |
| 503 | Service Unavailable | 服务不可用(临时过载或维护) |
| 504 | Gateway Timeout | 网关超时(上游服务器未响应) |
import urllib.request,urllib.errortry:url = "http://www.baidus.com"resp = urllib.request.urlopen(url)print(resp.read().decode('utf-8'))
# except urllib.error.HTTPError as e:
# print("请检查url是否正确")
# URLError是urllib.request异常的超类
except urllib.error.URLError as e:if hasattr(e, "code"):print(e.code)if hasattr(e, "reason"):print(e.reason) 
1.3. parse 模块
| 功能分类 | 函数 | 核心作用 |
|---|---|---|
| URL解析 | urlparse(url) | 将URL拆分为6组件(协议/域名/路径等),保留参数分隔符;和& |
urlsplit(url) | 类似urlparse但不拆分参数分隔符,返回5组件 | |
urldefrag(url) | 分离URL中的片段标识(如#anchor) | |
| URL构建 | urlunparse(parts) | 将urlparse的6组件重组为完整URL |
urljoin(base, url) | 基于基URL合并相对路径(智能处理./和../) | |
| 查询参数处理 | urlencode(query_dict) | 将字典转为URL查询字符串(自动编码特殊字符) |
parse_qs(query_str) | 将查询字符串解析为字典(值类型为list) | |
parse_qsl(query_str) | 将查询字符串解析为键值对列表(保留原始顺序) |
2. BeautifulSoup4库
学了urllib标准库之后,我们已经能爬到些比较正常的网页源码(html文档)了,但这离结果还差一步——就是如何筛选我们想要的数据,这时候BeautifulSoup库就来了,BeautifulSoup目前最新版本为BeautifulSoup4。
用于解析HTML和XML文档的流行库,它能够从网页中提取数据并生成易于遍历的解析树。
(官网文档:Beautiful Soup 4.12.0 文档 — Beautiful Soup 4.12.0 documentation)
soup = BeautifulSoup("<html>Hello</html>", "html.parser")参数解析:
(1)markup
需要解析的HTML/XML文档内容(字符串或文件对象)。
(2)解析器选择(features 或第二参数)
| 解析器 | 安装方式 | 特点 | 示例 |
|---|---|---|---|
"html.parser" | Python内置 | 速度中等,无依赖 | BeautifulSoup(html, "html.parser") |
"lxml" | pip install lxml | 最快,支持复杂文档 | BeautifulSoup(html, "lxml") |
"html5lib" | pip install html5lib | 容错性最强,速度慢 | BeautifulSoup(html, "html5lib") |
from bs4 import BeautifulSoup # 导入BeautifulSoup4库# 未指定就使用html.parser这个python标准解析器 BeautifulSoup(markup, "html.parser") 未指定会产生警告 GuessedAtParserWarning: No parser was explicitly specified# BeautifulSoup 第一个参数接受:一个文件对象或字符串对象
soup1 = BeautifulSoup(markup=open("C:\\pythonProject\\python爬虫\\gyp.html"), features="html.parser")
soup2 = BeautifulSoup("<html>hello python</html>") # 得到文档的对象
print(type(soup2)) # <class 'bs4.BeautifulSoup'>
print(soup1) # <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" ....
print(soup2) # <html><head></head><body>hello python</body></html>2.1.对象种类
BeautifulSoup将复杂HTML文档转换成一个复杂的树形结构,每个节点都是Python对象,所有对象可以归纳为4种: Tag , NavigableString , BeautifulSoup , Comment 。
| 对象类型 | 关键属性/方法 | 功能描述 | 注意事项 |
|---|---|---|---|
| Tag 标签对象 | name(标签名)attributes(属性字典) | 表示HTML/XML文档中的标签节点,可获取标签名和属性(如class、id等) | 通过遍历或搜索文档树获取,支持嵌套操作(如tag.contents ) |
| NavigableString | tag.string | 提取标签对内的纯文本内容(仅限直接包含的字符串) | 若标签内含注释或其他子标签,需用.strings或.get_text()获取完整文本 |
| BeautifulSoup | 文档根对象 | 代表整个解析后的文档,可视为特殊的Tag对象(包含<html>顶层标签) | 初始化时需指定解析器(如lxml),支持全局搜索方法(如.find_all()) |
| Comment 对象 | 继承自NavigableString | 处理HTML注释内容(如<!-- comment -->),输出时自动去掉注释符号 | 需用type(tag.string)==bs4.Comment 判断,避免误将注释当作普通文本处理 |
from bs4 import BeautifulSoup# 导入BeautifulSoup4库
# python 标准解析器 未指定就使用这个 BeautifulSoup(markup, "html.parser")
soup2 = BeautifulSoup("<html>""<p class='boldest'>我是p标签<b>hello python</b></p>""<!--我是标签外部的内容注释-->""<p class='boldest2'><!--我p标签内的注释-->我是独立的p标签</p>""<a><!--我a标签内的注释-->我是链接</a>""<h1><!--这是一个h1标签的注释--></h1>""</html>","html5lib") # 得到文档的对象
# Tag 标签对象
print(type(soup2.p)) # 输出Tag对象<class 'bs4.element.Tag'>
print(soup2.p.name) # 输出Tag标签对象的名称
print(soup2.p.attrs) # 输出第一个p标签的属性信息:{'class': ['boldest']}
soup2.p['class'] = ['boldest', 'boldest1']
print(soup2.p.attrs) # {'class': ['boldest', 'boldest1']}# NavigableString 可以遍历的字符串对象
print(type(soup2.b.string)) # <class 'bs4.element.NavigableString'>
print(soup2.b.string) # hello python
print(soup2.a.string) # None 存在注释或者其他标签内容均无法获取
print(soup2.b.string.replace_with("hello world")) # replace_with()方法可替换标签中的内容
print(soup2.b.string) # hello world# BeautifulSoup 对象
print(type(soup2)) # <class 'bs4.BeautifulSoup'>
print(soup2) # <html><head></head><body><p class="boldest">我是p标签<b>hello python</b></p><!--我是标签外部的内容注释--><p><!--我p标签内的注释-->我是独立的p标签</p></body></html>
print(soup2.name) # [document]# Comment 注释及特殊字符串(是一个特殊类型的 NavigableString 对象)
print(type(soup2.h1.string)) # <class 'bs4.element.Comment'>
print(soup2.h1.string) # 这是一个h1标签的注释 (利用 .string 来输出它的内容,注释符被去除了,不是我们想要的)
print(soup2.h1.prettify()) # 会以特殊格式输出:<h1> <!--这是一个h1标签的注释--> </h1>2.2.对象属性
可以简单理解爬取到的内容是树状图:
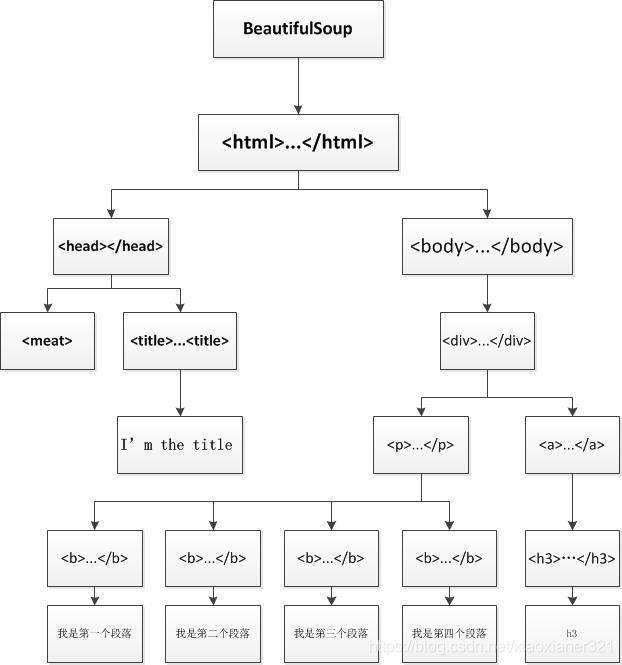
2.2.1.子节点
BeautifulSoup 对象常用属性总结
| 属性/方法 | 描述 | 使用场景与注意事项 |
|---|---|---|
| .tag | 获取标签名(如tag.name 返回'div') | 适用于快速识别标签类型,但需注意某些标签(如<br/>)可能无闭合标签。 |
| .contents | 返回标签的直接子节点列表(包括文本和标签节点) | 需注意列表可能包含换行符等空白文本节点,可通过过滤NavigableString类型处理。 |
| .children | 生成器形式返回直接子节点(性能优于.contents) | 适合遍历大量子节点时节省内存,但不可索引(需转为列表)。 |
| .descendants | 递归生成所有子孙节点(深度优先遍历) | 可用于爬取嵌套结构的完整内容(如表格内的所有文本),但需处理混合节点类型(注释、字符串等)。 |
| .string | 提取标签内唯一字符串子节点(无嵌套标签) | 若标签含多个子节点(如<p>Text<b>bold</b></p>),返回None,需改用.get_text()或.strings。 |
| .strings | 生成器形式返回标签内所有字符串(保留空白) | 需手动去除换行符和缩进(如' '.join(tag.strings).strip() )。 |
| .stripped_strings | 生成器形式返回标签内字符串(自动去除空白) | 适用于清洗文本(如新闻正文提取),但可能合并相邻空格(需根据需求调整)。 |
from bs4 import BeautifulSoupmarkup = '''<!DOCTYPE html>
<html><head><meta charset="UTF-8"><title>I’m the title</title></head><body><h1>HelloWorld</h1><div><div><p><b>我是一个段落...</b>我是第一段我是第二段<b>我是另一个段落</b>我是第一段</p><a>我是一个链接</a></div><div><p>picture</p><img src="example.png"/></div></div></body>
</html>'''
soup = BeautifulSoup(markup, "html5lib") # BeautifulSoup 对象
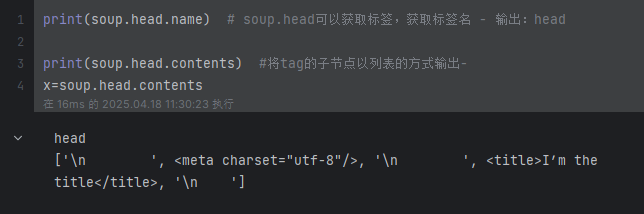
print(soup.head.name) # soup.head可以获取标签,获取标签名 - 输出:head
print(soup.head.contents) # 将tag的子节点以列表的方式输出--输出:['\n ', <meta charset="utf-8"/>, '\n ', <title>I’m the title</title>, '\n ']
print(soup.head.contents[1]) # <meta charset="utf-8"/>
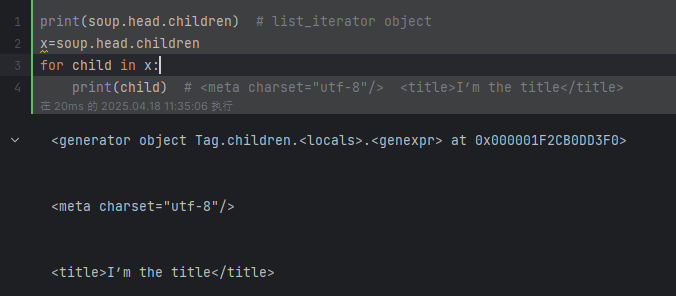
print(soup.head.children) # list_iterator object
for child in soup.head.children:print(child) # <meta charset="utf-8"/> <title>I’m the title</title>
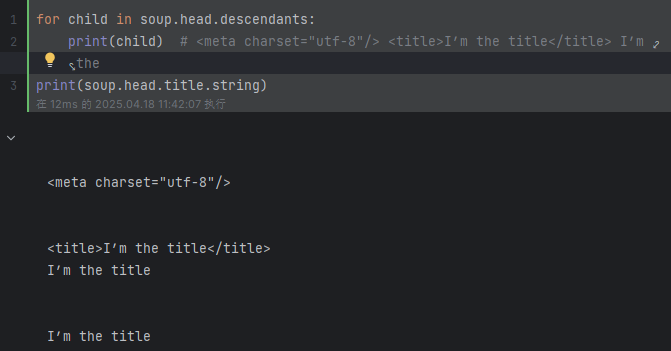
# 标签中的内容其实也是一个节点 使用contents和children无法直接获取间接节点中的内容,但是.descendants 属性可以
for child in soup.head.descendants:print(child) # <meta charset="utf-8"/> <title>I’m the title</title> I’m the title
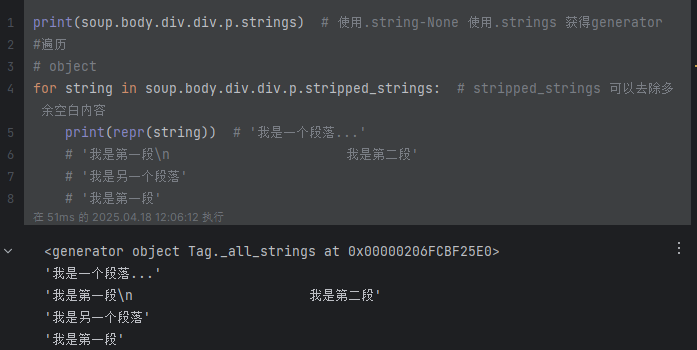
print(soup.head.title.string) # 输出:I’m the title 注:title中有其他节点或者注释都无法获取print(soup.body.div.div.p.strings) # 使用.string-None 使用.strings 获得generator object
for string in soup.body.div.div.p.stripped_strings: # stripped_strings 可以去除多余空白内容print(repr(string)) # '我是一个段落...'# '我是第一段\n 我是第二段'# '我是另一个段落'# '我是第一段'tag+contents:
children:
深度优先遍历:descendants
获取标签字符:string
2.2.2.父节点
| 属性 | 描述 |
| .parent | 获取某个元素的父节点 |
| .parents | 可以递归得到元素的所有父辈节点 |
from bs4 import BeautifulSoupmarkup = '''<!DOCTYPE html>
<html><head><meta charset="UTF-8"><title>I’m the title</title></head><body><h1>HelloWorld</h1><div><div><p><b>我是一个段落...</b>我是第一段我是第二段<b>我是另一个段落</b>我是第一段</p><a>我是一个链接</a></div><div><p>picture</p><img src="example.png"/></div></div></body>
</html>'''
soup = BeautifulSoup(markup, "html5lib") # BeautifulSoup 对象title = soup.head.title
print(title.parent) # 输出父节点
# <head>
# <meta charset="utf-8"/>
# <title>I’m the title</title>
# </head>
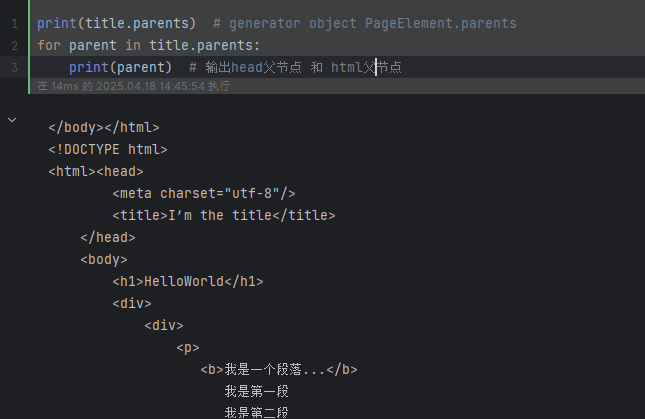
print(title.parents) # generator object PageElement.parents
for parent in title.parents:print(parent) # 输出head父节点 和 html父节点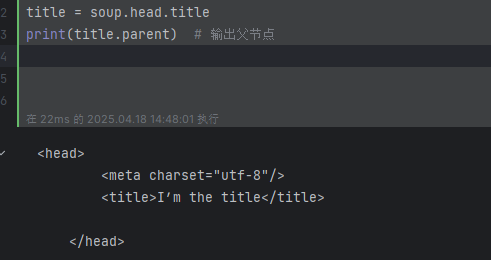
2.2.3.兄弟节点
| 属性 | 描述 |
| .next_sibling | 查询兄弟节点,表示下一个兄弟节点 |
| .previous_sibling | 查询兄弟节点,表示上一个兄弟节点 |
| .next_siblings | 对当前节点的兄弟节点迭代输出(下) |
| .previous_siblings | 对当前节点的兄弟节点迭代输出(上) |
from bs4 import BeautifulSoupmarkup = '''<!DOCTYPE html>
<html><head><meta charset="UTF-8"><title>I’m the title</title></head><body><div><p><b id=“b1”>我是第一个段落</b><b id=“b2”>我是第二个段落</b><b id=“b3”>我是第三个段落</b><b id=“b4”>我是第四个段落</b></p><a>我是一个链接</a></div></body>
</html>'''
soup = BeautifulSoup(markup, "html5lib") # BeautifulSoup 对象
p = soup.body.div.p.b
print(p) # <b id="“b1”">我是第一个段落</b>
print(p.next_sibling) # <b id="“b2”">我是第二个段落</b>
print(p.next_sibling.previous_sibling) # <b id="“b1”">我是第一个段落</b>
print(p.next_siblings) # generator object PageElement.next_siblings
for nsl in p.next_siblings:print(nsl) # <b id="“b2”">我是第二个段落</b># <b id="“b3”">我是第三个段落</b># <b id="“b4”">我是第四个段落</b>2.2.4.回退和前进
| 属性 | 描述 |
| .next_element | 解析下一个元素对象 |
| .previous_element | 解析上一个元素对象 |
| .next_elements | 迭代解析元素对象 |
| .previous_elements | 迭代解析元素对象 |
from bs4 import BeautifulSoupmarkup = '''<!DOCTYPE html>
<html><head><meta charset="UTF-8"><title>I’m the title</title></head><body><div><p><b id=“b1”>我是第一个段落</b><b id=“b2”>我是第二个段落</b><b id=“b3”>我是第三个段落</b><b id=“b4”>我是第四个段落</b></p><a>我是一个链接<h3>h3</h3></a></div></body>
</html>'''
soup = BeautifulSoup(markup, "html5lib") # BeautifulSoup 对象
p = soup.body.div.p.b
print(p) # <b id="“b1”">我是第一个段落</b>
print(p.next_element) # 我是第一个段落
print(p.next_element.next_element) # <b id="“b2”">我是第二个段落</b>
print(p.next_element.next_element.next_element) # 我是第二个段落
for element in soup.body.div.a.next_element: # 对:我是一个链接 字符串的遍历print(element)2.3.对象方法
这里的搜索文档,其实就是按照某种条件去搜索过滤文档,过滤的规则,往往会使用搜索的API,或者我们也可以自定义正则/过滤器,去搜索文档
2.3.1.find_all()
find_all( name , attrs , recursive , string , **kwargs ) | 参数/属性 | 类型 | 作用 | 示例 |
|---|---|---|---|
name | 字符串/正则/列表/函数 | 指定标签名称(如 'div') | soup.find_all('p') 查找所有 <p> 标签 |
attrs | 字典 | 通过属性筛选(如 class、id) | soup.find_all(attrs={'class': 'header'}) 匹配 class="header" 的标签 |
recursive | 布尔值(默认 True) | 是否递归搜索子标签。False 时仅搜索直接子节点 | soup.find_all('div', recursive=False) 仅查顶层 <div> |
string | 字符串/正则/函数 | 直接搜索标签内的文本内容(非标签本身) | soup.find_all(string='Hello') 查找文本为 "Hello" 的节点 |
**kwargs | 关键字参数 | 简化属性筛选语法(等效于 attrs) | soup.find_all(class_='header') 匹配 class="header" |
| 返回值 | ResultSet(类列表) | 返回所有匹配的标签或文本节点的集合,若无结果则返回空列表 [] | results = soup.find_all('a') 获取所有 <a> 标签 |
from bs4 import BeautifulSoup
import remarkup = '''<!DOCTYPE html>
<html><head><meta charset="UTF-8"><title id="myTitle">I’m the title</title></head><body><div><p><b id=“b1” class="bcl1">我是第一个段落</b><b>我是第二个段落</b><b id=“b3”>我是第三个段落</b><b id=“b4”>我是第四个段落</b></p><a href="www.temp.com">我是一个链接<h3>h3</h3></a><div id="dv1">str</div></div></body>
</html>'''
# 语法:find_all( name , attrs , recursive , string , **kwargs )
soup = BeautifulSoup(markup, "html5lib") # BeautifulSoup 对象
# 第一个参数name,可以是一个标签名也可以是列表
print(soup.findAll('b')) # 返回包含b标签的列表 [<b id="“b1”">我是第一个段落</b>, <b id="“b2”">我是第二个段落</b>, <b id="“b3”">我是第三个段落</b>, <b id="“b4”">我是第四个段落</b>]
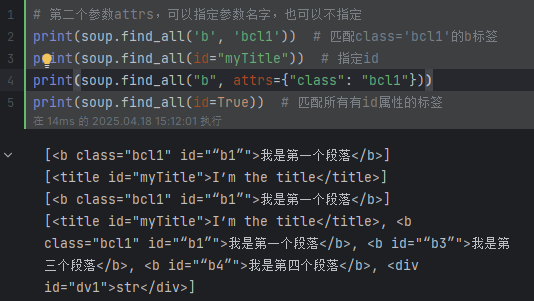
print(soup.findAll(['a', 'h3'])) # 按列表匹配多个 [<a href="www.temp.com">我是一个链接<h3>h3</h3></a>, <h3>h3</h3>]# 第二个参数attrs,可以指定参数名字,也可以不指定
print(soup.findAll('b', 'bcl1')) # 匹配class='bcl1'的b标签[<b class="bcl1" id="“b1”">我是第一个段落</b>]
print(soup.findAll(id="myTitle")) # 指定id [<title id="myTitle">I’m the title</title>]
print(soup.find_all("b", attrs={"class": "bcl1"})) # [<b class="bcl1" id="“b1”">我是第一个段落</b>]
print(soup.findAll(id=True)) # 匹配所有有id属性的标签# 第三个参数recursive 默认True 如果只想搜索tag的直接子节点,可以使用参数 recursive=False
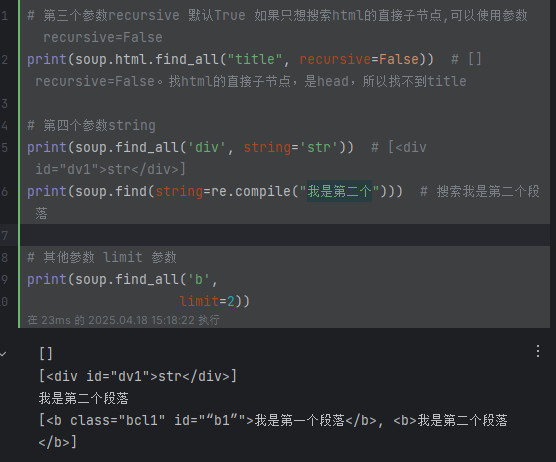
print(soup.html.find_all("title", recursive=False)) # [] recursive=False。找html的直接子节点,是head,所以找不到title# 第四个参数string
print(soup.findAll('div', string='str')) # [<div id="dv1">str</div>]
print(soup.find(string=re.compile("我是第二个"))) # 搜索我是第二个段落# 其他参数 limit 参数
print(soup.findAll('b', limit=2)) # 当搜索到的结果数量达到 limit 的限制时,就停止搜索返回结果,[<b class="bcl1" id="“b1”">我是第一个段落</b>, <b>我是第二个段落</b>]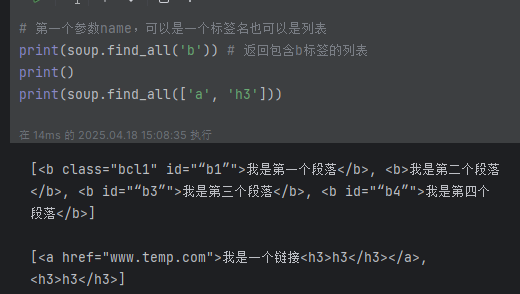
2.3.2.find()
find()与find_all() 的区别是 find_all() 方法的返回结果是值包含一个元素的列表,而 find() 方法直接返回结果(即找到了就不再找,只返第一个匹配的),find_all() 方法没有找到目标是返回空列表, find() 方法找不到目标时,返回 None。
soup = BeautifulSoup(markup, "html5lib") # BeautifulSoup 对象
# 第一个参数name,可以是一个标签名也可以是列表
print(soup.find('b')) # 返回<b class="bcl1" id="“b1”">我是第一个段落</b>,只要找到一个即返回# 第二个参数attrs,可以指定参数名字,也可以不指定
print(soup.find('b', 'bcl1')) # <b class="bcl1" id="“b1”">我是第一个段落</b>
print(soup.find(id="myTitle")) # <title id="myTitle">I’m the title</title>
print(soup.find("b", attrs={"class": "bcl1"})) # <b class="bcl1" id="“b1”">我是第一个段落</b>
print(soup.find(id=True)) # 匹配到第一个<title id="myTitle">I’m the title</title># 第三个参数recursive 默认True 如果只想搜索tag的直接子节点,可以使用参数 recursive=False
print(soup.html.find("title", recursive=False)) # None recursive=False。找html的直接子节点,是head,所以找不到title# 第四个参数string
print(soup.find('div', string='str')) # [<div id="dv1">str</div>]
print(soup.find(string=re.compile("我是第二个"))) # 我是第二个段落find汇总
| 方法分类 | 方法名 | 功能描述 |
|---|---|---|
| 父节点搜索 | find_parents() | 搜索当前节点所有符合条件的父辈节点(包括直接父节点和更上层祖先) |
find_parent() | 搜索当前节点第一个符合条件的直接父节点 | |
| 后续兄弟节点搜索 | find_next_siblings() | 返回当前节点后所有符合条件的兄弟节点(同层级) |
find_next_sibling() | 返回当前节点后第一个符合条件的兄弟节点 | |
| 前序兄弟节点搜索 | find_previous_siblings() | 返回当前节点前所有符合条件的兄弟节点(同层级) |
find_previous_sibling() | 返回当前节点前第一个符合条件的兄弟节点 | |
| 后续所有节点搜索 | find_all_next() | 返回文档中当前节点之后所有符合条件的节点(不限于兄弟节点,跨层级) |
find_next() | 返回文档中当前节点之后第一个符合条件的节点 | |
| 前序所有节点搜索 | find_all_previous() | 返回文档中当前节点之前所有符合条件的节点(不限于兄弟节点,跨层级) |
find_previous() | 返回文档中当前节点之前第一个符合条件的节点 |
2.3.3.CSS选择器查找
soup.select() 方法概述
- 作用:通过 CSS 选择器语法快速定位 HTML/XML 文档中的标签或节点。
- 返回值:返回一个
ResultSet(类似列表的对象),包含所有匹配的节点。若无匹配则返回空列表[]。 - 优势:语法简洁,支持复杂层级选择(比
find_all更灵活)。
参数解析
select('selector')
- 唯一参数:字符串类型的 CSS 选择器表达式。
- 支持的选择器类型:
选择器类型 示例 说明 标签选择器 'div'选择所有 <div>标签类选择器 '.header'选择 class="header"的标签ID 选择器 '#main'选择 id="main"的标签层级选择器 'div > p'选择 <div>直接子级的<p>属性选择器 '[href]'或'[data-id="1"]'按属性名或属性值筛选 组合选择器 'div.header, p#intro'多条件组合选择(逗号分隔)
- 支持的选择器类型:
from bs4 import BeautifulSoup
import remarkup = '''<!DOCTYPE html>
<html><head><meta charset="UTF-8"><title id="myTitle">I’m the title</title></head><body><div><p><b id=“b1” class="bcl1">我是第一个段落</b><b>我是第二个段落</b><b id=“b3”>我是第三个段落</b><b id=“b4”>我是第四个段落</b></p><a href="www.temp.com">我是一个链接<h3>h3</h3></a><div id="dv1">str</div></div></body>
</html>'''
soup = BeautifulSoup(markup, "html5lib") # BeautifulSoup 对象
print(soup.select("html head title")) # [<title id="myTitle">I’m the title</title>]
print(soup.select("body a")) # [<a href="www.temp.com">我是一个链接<h3>h3</h3></a>]
print(soup.select("#dv1")) # [<div id="dv1">str</div>]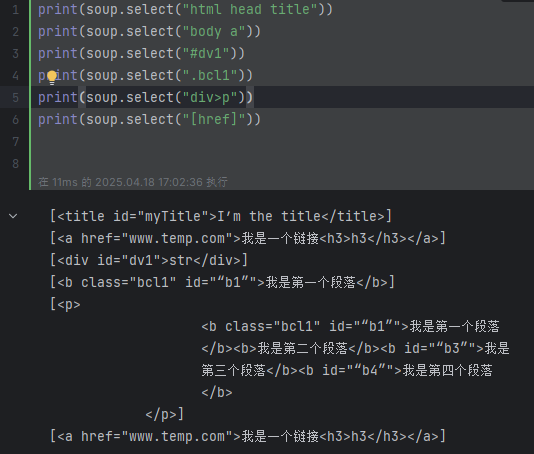
2.3.4.修改内容
修改tag的名称、属性、内容
from bs4 import BeautifulSoupsoup = BeautifulSoup('<b class="boldest">Extremely bold</b>', "html5lib")
tag = soup.b
tag.name = "blockquote"
print(tag) # <blockquote class="boldest">Extremely bold</blockquote>tag['class'] = 'veryBold'
tag['id'] = 1
tag.string = "replace"tag.append(" append")#添加内容del tag['id'] # 删除属性添加非标签内容:
from bs4 import BeautifulSoup, NavigableString, Commentsoup = BeautifulSoup('<div><b class="boldest">Extremely bold</b></div>', "html5lib")
tag = soup.div
new_string = NavigableString('NavigableString')
tag.append(new_string)
print(tag) # <div><b class="boldest">Extremely bold</b>NavigableString</div>new_comment = soup.new_string("Nice to see you.", Comment)
tag.append(new_comment)
print(tag) # <div><b class="boldest">Extremely bold</b>NavigableString<!--Nice to see you.--></div># 添加标签,推荐使用工厂方法new_tag
new_tag = soup.new_tag("a", href="http://www.example.com")
tag.append(new_tag)
print(tag) # <div><b class="boldest">Extremely bold</b>NavigableString<!--Nice to see you.--><a href="http://www.example.com"></a></div>把元素插入到指定的位置:
from bs4 import BeautifulSoupmarkup = '<a href="http://example.com/">I linked to <i>example.com</i></a>'
soup = BeautifulSoup(markup,"html5lib")
tag = soup.a
tag.insert(1, "but did not endorse ") # 和append的区别就是.contents属性获取不一致
print(tag) # <a href="http://example.com/">I linked to but did not endorse <i>example.com</i></a>
print(tag.contents) # ['I linked to ', 'but did not endorse ', <i>example.com</i>]将当前tag移除文档树,并作为方法结果返回:
from bs4 import BeautifulSoupmarkup = '<a href="http://example.com/">I linked to <i>example.com</i></a>'
soup = BeautifulSoup(markup, "html5lib")
a_tag = soup.a
print(a_tag)#<a href="http://example.com/">I linked to <i>example.com</i></a>
i_tag = soup.i.extract()print(a_tag) # <a href="http://example.com/">I linked to </a>
print(i_tag) # <i>example.com</i> 我们移除的内容| 方法 | 功能描述 | 示例代码 | 输出结果 | 关键区别 |
|---|---|---|---|---|
decompose() | 完全移除并销毁节点,不可恢复 | soup.i.decompose()print(a_tag) | <a href="...">I linked to </a> | 永久性删除,内存中不再存在 |
replace_with() | 用新节点/文本替换原节点,保留文档结构 | new_tag = soup.new_tag("b")new_tag.string = "example.net"soup.a.i.replace_with(new_tag) | <a href="...">I linked to <b>example.net</b></a> | 可灵活替换为任意节点类型(标签/文本/注释等) |
unwrap() | 移除当前标签,但保留其内容(解包操作) | a_tag.i.unwrap()print(a_tag) | <a href="...">I linked to example.com</a> | 仅去除标签外壳,内容提升到父层级 |
wrap() | 用新标签包裹指定内容(反向操作) | soup2.p.string.wrap(soup2.new_tag("b"))print(soup2.p) | <p><b>I wish I was bold.</b></p> | 常用于添加格式化标签(如加粗/高亮) |
2.4.输出
2.4.1.格式化输出
prettify() 方法将Beautiful Soup的文档树格式化后以Unicode编码输出,每个XML/HTML标签都独占一行。
from bs4 import BeautifulSoupmarkup = '<a href="http://example.com/">I linked to <i>example.com</i></a>'
soup = BeautifulSoup(markup, "html5lib")
print(soup) # <html><head></head><body><a href="http://example.com/">I linked to <i>example.com</i></a></body></html>
print(soup.prettify()) #<html># <head># </head># <body># <a href="http://example.com/"># I linked to# <i># example.com# </i># </a># </body># </html>2.4.2.压缩输出
果只想得到结果字符串,不重视格式,那么可以对一个 BeautifulSoup 对象或 Tag 对象使用Python的str() 方法。
2.4.3.文本输出
如果只想得到tag中包含的文本内容,那么可以调用 get_text() 方法。
from bs4 import BeautifulSoupmarkup = '<a href="http://example.com/">I linked to <i>example.com</i>点我</a>'
soup = BeautifulSoup(markup, "html5lib")
print(soup)
print(str(soup))
print(soup.get_text())
3.re标准库
BeautifulSoup库,重html文档中筛选我们想要的数据,但这些数据可能还有很多更细致的内容,比如,我们取到的是不是我们想要的链接、是不是我们需要提取的邮箱数据等等,为了更细致精确的提取数据,那么正则来了。
正则表达式(英语:Regular Expression,在代码中常简写为regex、regexp或RE),是计算机科学的一个概念。正则表达式使用单个字符串来描述、匹配一系列匹配某个句法规则的字符串。在其他语言中,我们也经常会接触到正则表达式。
| 方法/概念 | 代码示例 | 关键说明 |
|---|---|---|
| re.compile() | pat = re.compile('\d{2}') | 预编译正则模式,匹配连续2位数字 |
| search() | pat.search("12abc") | 在任意位置搜索首次匹配,成功返回Match对象 |
| match() | pat.match('1224abc') | 仅从字符串起始位置匹配,成功返回Match对象 |
| findall() | re.findall(r'apple',s)re.findall(r'apple',s,re.I) | 默认区分大小写,re.I标志忽略大小写 |
| sub()替换 | re.sub('a','A','abcdacdl') | 将所有小写a替换为大写A |
import re# 创建正则对象
pat = re.compile('\d{2}') #出现2次数字的
# search 在任意位置对给定的正则表达式模式搜索第一次出现的匹配情况
s = pat.search("12abc")
print(s.group()) # 12# match 从字符串起始部分对模式进行匹配
m = pat.match('1224abc')
print(m.group()) # 12# search 和 match 的区别 匹配的位置不也一样
s1 = re.search('foo', 'bfoo').group()
print(s1) # foo
try:m1 = re.match('foo','bfoo').group() # AttributeError
except:print('匹配失败') # 匹配失败# 原生字符串(\B 不是以py字母结尾的)
allList = ["py!", "py.", "python"]
for li in allList:# re.match(正则表达式,要匹配的字符串)if re.match(r'py\B', li):print(li) # python# findall()
s = "apple Apple APPLE"
print(re.findall(r'apple', s)) # ['apple']
print(re.findall(r'apple', s, re.I)) # ['apple', 'Apple', 'APPLE']# sub()查找并替换
print(re.sub('a', 'A', 'abcdacdl')) # AbcdAcdl