系列文章目录
参考博客
参考博客
参考博客
文章目录
- 系列文章目录
- 前言
- 一、NVIDIA驱动
- 1、驱动下载
- 2、驱动安装
- 1.删除旧驱动
- 2.禁用nouveau驱动和关闭x-window
- 3.安装NVIDIA驱动
- 二、cuda与cudnn下载安装
- 1、cuda下载安装
- 2、cudnn下载安装
- 3、验证版本
- 三、Docker下载安装
- 清理旧的Docker
- 1.查看是否已安装了docker,是否有容器和镜像:
- 2.清空所有容器和镜像:
- 3.卸载当前的Docker。
- 4.检查验证
- 安装最新Docker
- 1.更新系统软件包
- 2.安装依赖包【用于通过HTTPS来获取仓库】
- 3.添加Docker官方GPG密钥
- 4.验证
- 5.添加Docker阿里稳定版软件源
- 6.再次更新软件包
- 7.安装默认最新版
- 8.测试,安装好后默认启动
- 问题1:拉取镜像时提示超时
- 9.Docker常用命令
- 四、安装nvidia-container-toolkit工具
- 1、基础配置
- 2、更新密钥与仓库
- 3、更新软件包列表
- 4、安装NVIDIA容器工具包
- 5、查看版本
- 6、配置 Docker 使用 NVIDIA nvidia-container-toolkit工具
- 五、安装多容器协作Docker-Compose
- 1、Docker Compose安装
- 2、Docker Compose 常用指令
- 六、调用vLLM和OpenWebUI
- 1、拉取vLLM镜像
- 2、拉取OpenWebUI镜像
- 3、下载模型
- 4、docker-compose.yml 文件
- 总结
前言
ollama框架适合个人使用,但是如果是企业使用的话,需要考虑高并发环境,这时候就需要考虑vLLM框架了。
Ollama
- 部署简单,支持跨平台(含 macOS)
- 资源占用低,适合低配设备
- 交互式对话友好,内置 CLI 界面
- 高并发能力弱(仅支持 4 请求并发)
- 模型精度因量化可能下降
- 企业级扩展性有限
vLLM - 吞吐量高,支持千级并发请求
- 分布式部署和多 GPU 优化
- 保留原始模型精度,支持复杂参数调整
- 依赖 NVIDIA GPU 和高显存
- 配置复杂,需技术背景
- 无内置交互界面,需 API 开发
选择 Ollama 的场景:
个人开发者快速验证模型效果(如测试生成文案或代码)
低配置硬件环境(如 16GB 内存的笔记本或树莓派)
需要交互式对话原型开发(如本地 ChatGPT 风格应用)
选择 vLLM 的场景:
企业级 API 服务(如智能客服需 SLA 99.9% 保障)
高并发文档处理(如法律合同批量分析)
多 GPU 服务器集群(如 8 卡 H100 运行 70B 模型)
硬件:
四卡NVIDIA 2080TI 服务器
GPU架构:Turing
一、NVIDIA驱动
1、驱动下载
NVIDIA最新驱动下载

NVIDIA驱动的历史版本下载
太新的NVIDIA驱动即使说明自身能够支持和兼容某某显卡,但是在实际安装中,安装太新的驱动会导致图形化界面打不开或者循环登录问题,所以在实际安装中不要太过于追求最新的驱动,它没有想象中那么兼容。
另外不知道为什么直接打开的NVIDIA驱动下载页面加载不了旧驱动,需要去专门的Unix 驱动程序网站才能找到。

2、驱动安装
Ctrl+Alt+F1或者Ctrl+Alt+F3进入tty文本模式,Ctrl+Alt+F7或者Ctrl+Alt+F1返回图形化界面。
1.删除旧驱动
打开终端,先删除旧的驱动:
sudo apt-get purge nvidia*
sudo nvidia-uninstall
卸载过程中,可能会询问你:
if you plan to no longer use the NVIDIA driver, you should make sure that no X screens are configured to use the NVIDIA X driver in your X configuration file.
提示你是否保留xorg.conf文件,选择NO维持当前配置,继续。
2.禁用nouveau驱动和关闭x-window
禁用自带的 nouveau 驱动
创建一个文件通过命令
sudo vim /etc/modprobe.d/blacklist-nouveau.conf
并添加如下内容:
blacklist nouveau
options nouveau modeset=0
再更新一下
sudo update-initramfs -u
修改后需要重启系统。
确认下Nouveau是否已经禁用,使用命令,没有输出表明已禁用:
lsmod | grep nouveau
在tty环境下,结束x-window的服务,否则驱动将无法正常安装:
先查看使用的显示管理器是什么:
cat /etc/X11/default-display-manager
systemctl status display-manager
若输出结果为 /usr/sbin/gdm3,则当前显示管理器是 gdm3
若输出结果为 /usr/sbin/lightdm,则当前显示管理器是 lightdm
停止使用:
sudo service gdm3 stop
或者
sudo service lightdm stop
3.安装NVIDIA驱动
在驱动文件所在的文件夹中,进入命令行
输入修改权限命令,确定文件可读写:
sudo chmod 777 NVIDIA*.run
调用run驱动文件进行安装,注意后面跟着的的参数,很重要:
sudo ./NVIDIA-Linux-x86_64-***.**.run --no-opengl-files –-no-x-check --no-nouveau-check
–no-opengl-files:表示只安装驱动文件,不安装OpenGL文件,避免NVIDIA驱动中的opengl文件覆盖系统原生的opengl文件。这个参数不可省略,否则会导致登陆界面死循环,英语一般称为”login loop”或者”stuck in login”。
–no-x-check:表示安装驱动时不检查X服务,非必需。
–no-nouveau-check:表示安装驱动时不检查nouveau,非必需。
-Z, --disable-nouveau:禁用nouveau。此参数非必需,因为之前已经手动禁用了nouveau。
-A:查看更多高级选项。
安装过程中一些选项:
ERROR:An NVIDIA kernel module “nvidia-drm” appear to aiready be loaded in your kernel…
提示你nvidia的drm模块还在加载使用,无法正常安装新驱动,选择OK,退出安装界面,使用以下命令查看NVIDIA模块状态:
lsmod | grep nvidia
如果有输出(例如 nvidia、nvidia_drm、 nvidia_modeset 等),表示模块已加载。
若无输出,则可能未加载或未正确安装驱动。
按依赖顺序卸载模块(从最上层到底层):
sudo modprobe -r nvidia_drm # 卸载 nvidia-drm
sudo modprobe -r nvidia_modeset # 卸载依赖的 modeset 模块
sudo modprobe -r nvidia # 卸载核心 NVIDIA 驱动模块
完成后,重新调用run驱动文件进行安装。
The distribution-provided pre-install script failed! Are you sure you want to continue?
提示你将会进行一些脚本安装,选择 continue installation 继续。
Would you like to register the kernel module souces with DKMS? This will allow DKMS to automatically build a new module, if you kernel changes later
提示你是否升级DKMS内核,选择 No 继续。
Unable to find a suitable destination to install 32-bit…
提示你没找到能放置32位兼容库的位置,因为这是64位的环境,所以不用安装32位的库,选择 OK 继续。
The initramfs will likely need to be rebuilt due to the following condition(s):
- Nouveau is present in the initramfs.
提示你是否要重新构建初始内存磁盘,选择rebuilt initramfs继续。
Would you like to run the nvidia-xconfigutility to automatically update your x configuration so that the NVIDIA x driver will be used when you restart x? Any pre-existing x confile will bked up.e backed up.
提示你是否需要更新xorg.conf文件,选择NO维持当前配置,继续。
安装完成后,重新启动X-Window,进入图形化界面:
sudo service gdm3 start
或
sudo service lightdm start
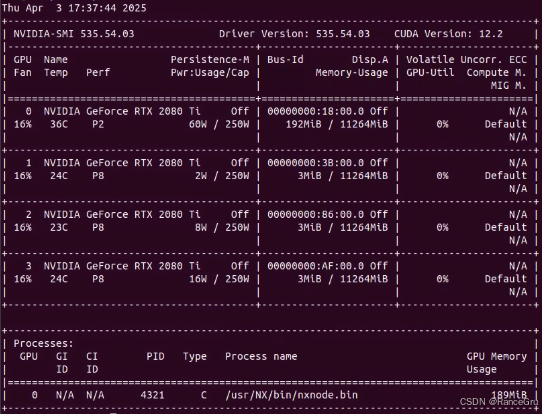
运行以下代码,查看驱动是否存在:
nvidia-smi
二、cuda与cudnn下载安装
1、cuda下载安装
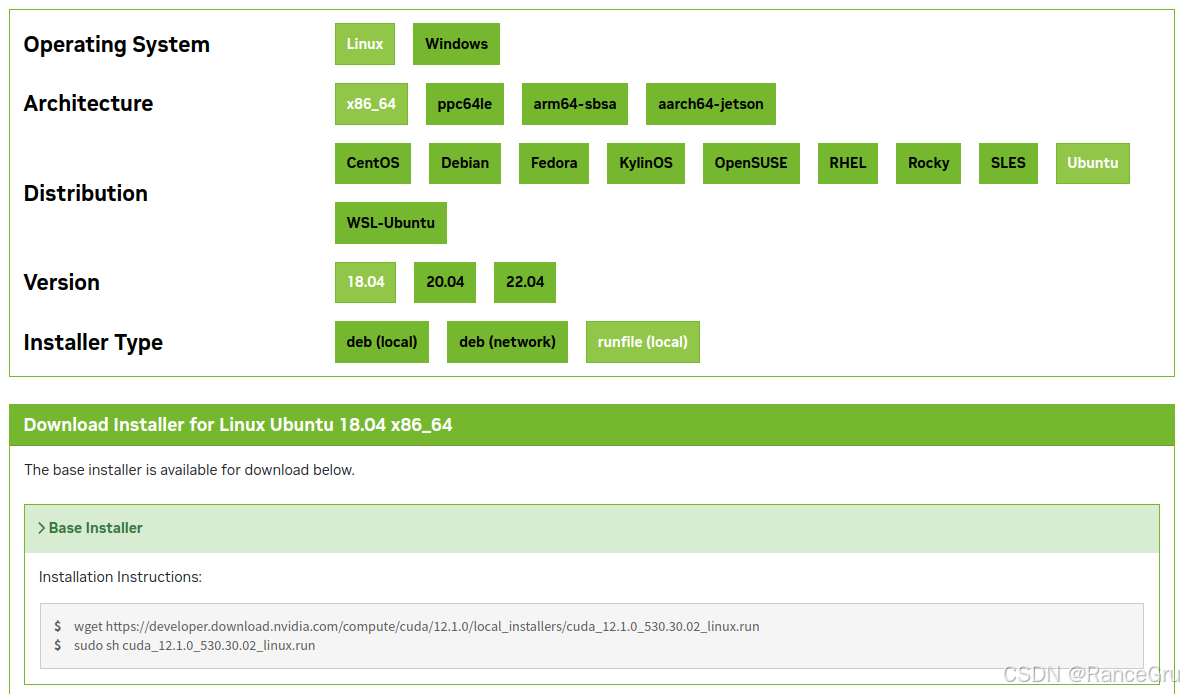
cuda历史版本下载
根据提供的命令进行下载:
wget https://developer.download.nvidia.com/compute/cuda/12.1.0/local_installers/cuda_12.1.0_530.30.02_linux.run
前提已经安装了NVIDIA驱动。
进入cuda的run文件所在的文件夹,打开命令行。
根据提供的命令进行安装:
sudo sh cuda_12.1.0_530.30.02_linux.run
输入accept,同意条款,继续。

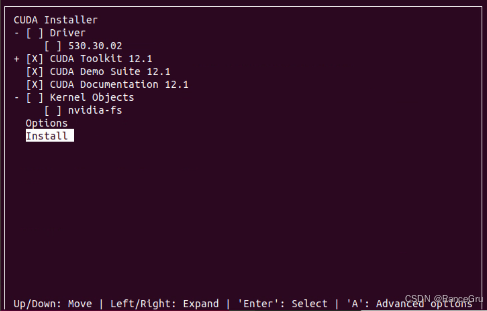
由于已经安装了NVIDIA驱动,所以不要勾选Driver。
那么上下箭头移动到Driver,按enter回车键,将"[]"中的X去掉,即是不选择.然后移动到Install继续安装。
等待一段时间后提示以下画面表示coda安装成功。

2、cudnn下载安装
cudnn历史版本下载
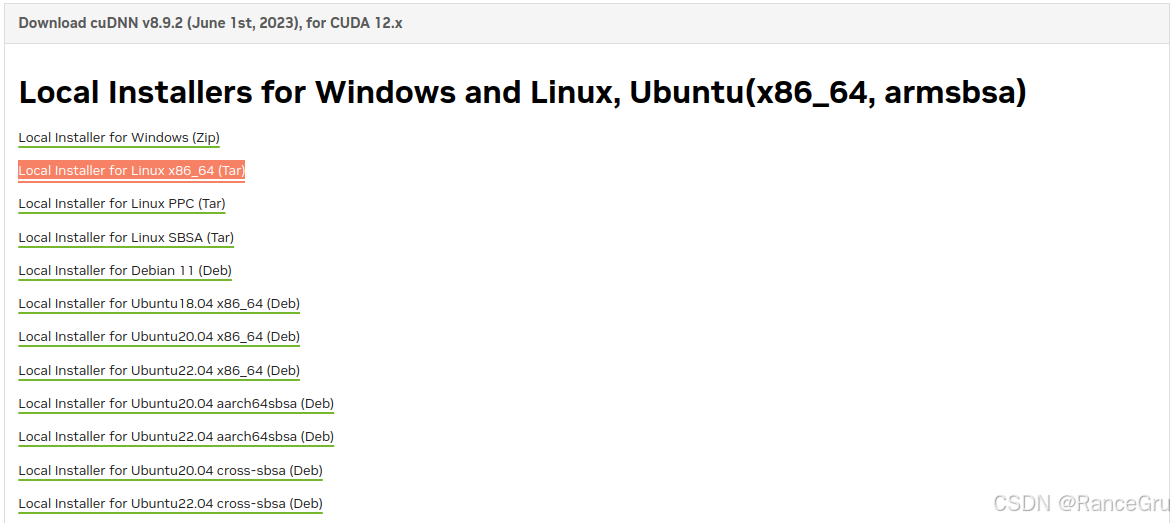
直接解压cudnn,进入对应文件夹,打开命令行,把cudnn对应的文件拷贝到cuda相应的文件夹下即可:
sudo cp include/cudnn* /usr/local/cuda-12.1/include
sudo cp lib64/libcudnn* /usr/local/cuda-12.1/lib64
sudo chmod a+r /usr/local/cuda-12.1/include/cudnn.h /usr/local/cuda-12.1/lib64/libcudnn*
3、验证版本
# 删除目前的软链接
sudo rm -rf /usr/local/cuda
# 生成新的软链接
sudo ln -s /usr/local/cuda-12.1 /usr/local/cuda
# 查看当前cuda的版本,
nvcc --version
cat /usr/local/cuda/version.txt
#查看cudnn版本
cat /usr/local/cuda/include/cudnn_version.h | grep CUDNN_MAJOR -A 2


三、Docker下载安装
清理旧的Docker
1.查看是否已安装了docker,是否有容器和镜像:
# 查看是否有Docker及其版本
sudo docker --version# 检查容器
sudo docker ps -a# 检查镜像
sudo docker images
2.清空所有容器和镜像:
sudo docker rm -f $(sudo docker ps -aq) && sudo docker rmi -f $(sudo docker images -aq)
3.卸载当前的Docker。
运行以下命令移除 Docker 核心组件:
sudo apt-get purge docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
sudo apt-get remove docker docker-engine docker.io containerd runc删除 Docker 相关数据及配置
删除 Docker 工作目录
默认数据存储位置(镜像、容器、卷等):
sudo rm -rf /var/lib/docker
sudo rm -rf /var/lib/containerd
删除配置文件
sudo rm -rf /etc/docker
移除 Docker 用户组
sudo groupdel docker
4.检查验证
which docker
docker --version
安装最新Docker
需要连接国外网络
1.更新系统软件包
sudo apt update
2.安装依赖包【用于通过HTTPS来获取仓库】
sudo apt install apt-transport-https ca-certificates curl software-properties-common
3.添加Docker官方GPG密钥
sudo -i
curl -fsSL https://mirrors.aliyun.com/docker-ce/linux/ubuntu/gpg | gpg --dearmor -o /etc/apt/trusted.gpg.d/docker-ce.gpg
4.验证
sudo apt-key fingerprint 0EBFCD88
0EBFCD88 是公钥的指纹。执行这个命令后,系统会显示与该指纹相关的公钥信息。
5.添加Docker阿里稳定版软件源
echo "deb [arch=amd64 signed-by=/usr/share/keyrings/docker-archive-keyring.gpg] https://mirrors.aliyun.com/docker-ce/linux/ubuntu $(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
或
sudo add-apt-repository "deb [arch=amd64] https://mirrors.aliyun.com/docker-ce/linux/ubuntu $(lsb_release -cs) stable"
6.再次更新软件包
sudo apt update
7.安装默认最新版
sudo apt install docker-ce docker-ce-cli containerd.io
8.测试,安装好后默认启动
sudo docker run hello-world
问题1:拉取镜像时提示超时
Unable to find image ‘hello-world:latest’ locally docker: Error response from daemon: Get “https://registry-1.docker.io/v2/”: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers). See ‘docker run --help’.
遇到连接超时的问题,这通常是因为默认的 Docker 镜像源访问速度较慢或不稳定所导致的。为了加速 Docker 镜像的下载和提升稳定性,解决这个问题的一种有效方法就是更换镜像源,配置加速地址:
创建docker目录
sudo mkdir -p /etc/docker
目录下创建一个json文件,并写入可用网址
sudo tee /etc/docker/daemon.json <<-'EOF'
{"registry-mirrors": ["https://do.nark.eu.org","https://dc.j8.work","https://docker.m.daocloud.io","https://dockerproxy.com","https://docker.mirrors.ustc.edu.cn","https://docker.nju.edu.cn"]
}
EOF
初始化
sudo systemctl daemon-reload
sudo systemctl restart docker
sudo systemctl status docker
sudo docker info
重新测试:
sudo docker run hello-world
如果输出“Hello from Docker!”则表示Docker已经成功安装。
9.Docker常用命令
#开机自启
sudo systemctl enable docker# 启动
sudo systemctl enable docker
或者
sudo systemctl start docker
或者
sudo service docker start#运行状态
sudo systemctl status docker
sudo service docker status#停止
sudo systemctl stop docker
sudo service docker stop#重启
sudo systemctl restart docker
sudo service docker restart#查看docker中运行的容器sudo docker ps#查看docker中所有的容器
sudo docker ps -a#启动一个已停止的容器:
docker start <容器ID>#停止一个已启动的容器
docker stop <容器ID>#重启一个已启动的容器
docker restart <容器ID>#查看容器内的标准输出
docker logs <容器ID>#获取镜像:例如获取ubuntu镜像
sudo docker pull ubuntu#获取最新镜像
sudo docker pull ubuntu latest#移除容器
docker rm -f <容器ID>
#显示镜像的历史记录
docker history#导出容器
docker export <容器ID> > <文件名>.tar#导入容器
cat docker/<文件名>.tar | docker 导入 - 测试/<容器名>:v1
例如:cat docker/ubuntu.tar | docker import - test/ubuntu:v1#查看镜像
sudo docker image ls
或
sudo docker images#删除镜像
sudo docker rmi image#批量删除所有镜像
sudo docker rmi `docker images -q#查看Docker网络
sudo docker network ls#删除指定的Docker网络,例如:test (注意:删除网络后连接到该网络的容器都会断开网络)
docker network rm test#进入Docker容器
docker exec -it <容器名或id> /bin/bash#创建新的镜像
docker commit < OPTIONS > container <REPOSITORY[:TAG]>
例如:docker commit test_id_or_name my-test-image:latest (这将基于test的id或name容器创建一个新镜像my-test-image,标签为latest)#配置容器随docker一起自动启动
docker run -restart=always#如果容器已经启动,可以使用一下命令
docker update -restart=always <CONTAINER ID>#如果已经配置容器随docker一起启动,现在想配置容器不跟随启动
docker update --restart=no <CONTAINER ID>#批量关闭自启
docker update --restart=no $(docker ps -a -q)四、安装nvidia-container-toolkit工具
需要连接国外网络
1、基础配置
升级更新
sudo apt-get update
安装curl库
sudo apt-get install -y curl
2、更新密钥与仓库
配置添加官方密钥和仓库:
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
完成后会生成两个文件,分别是密钥和仓库,检查一下是否正常,不要是空文件:
/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg
/etc/apt/sources.list.d/nvidia-container-toolkit.list
3、更新软件包列表
sudo apt-get update”不遵循本地机器的代理设置,通过使用-E选项,可以保留当前用户的环境变量,使得执行的命令可以继承当前用户的环境设置。
sudo -E apt-get update
4、安装NVIDIA容器工具包
安装NVIDIA容器工具包:
sudo -E apt-get install -y nvidia-container-toolkit
5、查看版本
启动Docker服务后,可以使用以下命令来查看nvidia-container-toolkit的版本:
nvidia-container-cli --version
# 或者
nvidia-container-runtime --version
6、配置 Docker 使用 NVIDIA nvidia-container-toolkit工具
编辑 Docker 配置文件 /etc/docker/daemon.json,添加以下内容:
{ "registry-mirrors": ["https://xxx.com"],"runtimes": {"nvidia": {"path": "nvidia-container-runtime","runtimeArgs": []}},"default-runtime": "nvidia"
}
在更改配置后,重启 Docker 服务:
sudo systemctl restart docker
五、安装多容器协作Docker-Compose
需要连接国外网络
1、Docker Compose安装
# 安装最新版本docker-compose
sudo curl -L "https://github.com/docker/compose/releases/latest/download/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose# 加上许可权限
sudo chmod +x /usr/local/bin/docker-compose# 查看是否已成功安装
docker-compose --version# docker-compose是一个文件,如果要卸载只需要把文件删除即可
rm /usr/local/bin/docker-compose
2、Docker Compose 常用指令
docker-compose up:启动应用程序的所有服务。如果容器不存在,则会自动创建并启动。如果容器已经存在,则会重新启动。docker-compose down:停止并移除应用程序的所有服务。这将停止并删除所有相关的容器、网络和卷。docker-compose start:启动应用程序的所有服务。与docker-compose up不同的是,docker-compose start只会启动已经存在的容器,而不会重新创建。docker-compose stop:停止应用程序的所有服务。与docker-compose down不同的是,docker-compose stop只会停止容器,而不会删除它们。docker-compose restart:重启应用程序的所有服务。这将停止并重新启动所有容器。docker-compose ps:列出应用程序的所有服务及其状态。这将显示每个服务的容器ID、状态、端口映射等信息。docker-compose logs:查看应用程序的服务日志。这将显示所有服务的日志输出。docker-compose build:构建应用程序的服务镜像。这将根据定义的Dockerfile构建镜像。docker-compose exec:在运行的容器中执行命令。例如,docker-compose exec web ls将在名为web的容器中执行ls命令。docker-compose down --volumes:停止并移除应用程序的所有服务,并删除所有相关的容器、网络和卷。使用--volumes选项可以删除与服务关联的卷。
六、调用vLLM和OpenWebUI
1、拉取vLLM镜像
拉取vLLM镜像:
sudo docker pull vllm/vllm-openai:v0.7.2
建议使用指定版本,高版本的vllm运行后可能提示:
Compute Capability < 8.0
这个问题跟显卡架构有关,低于Ampere架构的GPU架构会触发。
查看vLLM镜像是否拉取成功:
sudo docker images

2、拉取OpenWebUI镜像
拉取OpenWebUI镜像:
sudo docker pull ghcr.io/open-webui/open-webui:main
查看OpenWebUI镜像是否拉取成功:
sudo docker images

3、下载模型
国外使用huggingface网站下载
国内使用modelscope网站下载
DeepSeek-R1-Distill-Qwen-32B-GPTQ-Int4模型地址
在下载前,请先通过如下命令安装ModelScope(需要python环境):
pip install modelscope
下载完整模型库到指定文件夹:
modelscope download --model tclf90/deepseek-r1-distill-qwen-32b-gptq-int4 --local_dir /home/xxx/models/
4、docker-compose.yml 文件
提供一份docker-compose.yml 文件参考:
services:vllm:container_name: vllmimage: vllm/vllm-openai:v0.7.2ports:- "8000:8000"volumes:- ./models:/modelscommand: ["--model", "/models/DeepSeek-R1-Distill-Qwen-32B-GPTQ-Int4","--served-model-name", "r1","--tensor-parallel-size", "4","--max-model-len", "8912","--max-num-seqs", "8","--dtype","auto","--gpu-memory-utilization", "0.80"]ipc: hostrestart: alwaysdeploy:resources:reservations:devices:- driver: nvidiacount: allcapabilities: [gpu]open-webui:image: ghcr.io/open-webui/open-webui:maincontainer_name: open-webuienvironment:ROOT_PATH: "/vllm"OPENAI_API_BASE_URL: "http://vllm:8000/v1"ports:- "3030:8080"volumes:- ./open-webui:/app/backend/datarestart: alwaysdepends_on:- vllm
参数解释:
1. vllm 服务: container_name: vllm: 容器的名称为 vllm。image: vllm/vllm-openai:v0.7.2: 使用 vllm 提供的官方镜像,版本为 v0.7.2。ports: - "8000:8000": 将容器的 8000 端口映射到宿主机的 8000 端口。volumes: - ./models:/models: 将宿主机的 ./models 目录挂载到容器的 /models 目录,用于存放模型文件。command: 运行容器时执行的命令,配置了以下参数:--model "/models/DeepSeek-R1-Distill-Qwen-32B-GPTQ-Int4": 使用指定路径下的模型。--served-model-name "r1": 模型的服务名称为 r1。--tensor-parallel-size "4": 张量并行大小为 4,优化 GPU 计算。--max-model-len "8912": 模型处理的最大长度为 8912 个 token。--max-num-seqs "8": 每次处理的最大序列数为 8。--dtype "auto": 数据类型自动选择。--gpu-memory-utilization "0.80": GPU 内存利用率设为 80%。ipc: host: 共享宿主机的 IPC 资源。restart: always: 容器退出后自动重启。deploy.resources.reservations.devices: 配置 GPU 设备,使用所有 NVIDIA GPU。2. open-webui 服务: image: ghcr.io/open-webui/open-webui:main: 使用 Open Web UI 的官方镜像。container_name: open-webui: 容器名称为 open-webui。environment: 设置环境变量:ROOT_PATH: "/vllm": 应用的根路径设为 /vllm。OPENAI_API_BASE_URL: "http://vllm:8000/v1": 指向 vllm 服务的 openai的API 端点。ports: - "3030:8080": 将容器的 8080 端口映射到宿主机的 3030 端口。volumes: - ./open-webui:/app/backend/data: 挂载宿主机的 ./open-webui 目录到容器的 /app/backend/data。restart: always: 容器退出后自动重启。depends_on: vllm: 启动此服务前,确保 vllm 服务已启动。
在 docker-compose.yml 所在目录下打开终端,执行:
docker-compose up -d
然后在浏览器访问:
http://localhost:3030
使用默认的管理员账号登录:
默认管理员账号:admin
默认管理员邮箱:admin@openwebui.com
默认密码:admin
总结
之前尝试过只依靠了一个Hugging Face的Transformers库去部署Meta-Llama-3.2_1B的模型和使用Ollama+OpenWebUI部署DeepSeek-R1-14B模型,体验感还是不错的,这次使用vLLM+OpenWebUI部署DeepSeek-R1-32B模型。