Scala学习
scala介绍
Scala 是 Scalable Language 的简写,是一门多范式的编程语言
Scala是把函数式编程思想和面向对象编程思想结合的一种编程语言。
大数据计算引擎Spark由Scala编写
scala特点
多范式:
- 面向对象
- 函数式编程
兼容JAVA:
- 类库调用
- 互操作
语法简洁:
- 代码行短
- 类型推断
- 抽象控制
静态类型化:
- 可检验
- 安全重构
支持并发控制:
- 强计算能力
- 自定义其他控制结构
scala :OO(面向对象)+FP(函数式编程)
在面向对象编程中,我们把对象传来传去,那在函数式编程中,我们要做的是把函数传来传去,而这个,说成术语,叫做高阶函数
在函数式编程中,函数是基本单位,,他几乎被用作一切,包括最简单的计算,甚至连变量都被计算所取代。在函数式编程中,变量只是一个名称,而不是一个存储单元,这是函数式编程与传统的命令式编程最典型的不同之处。
scala和java编译之后的class文件一样
安装使用scala
在idea中使用scala
1.在idea中增加scala插件支持scala的使用
2.安装scala
①直接下载(scala官网下载)
②添加依赖下载
<dependency><groupId>org.scala-lang</groupId><artifactId>scala-library</artifactId><version>2.12.10</version></dependency><dependency><groupId>org.scala-lang</groupId><artifactId>scala-compiler</artifactId><version>2.12.10</version></dependency><dependency><groupId>org.scala-lang</groupId><artifactId>scala-reflect</artifactId><version>2.12.10</version></dependency>
scala和java的编译插件
<build><plugins><!-- Java Compiler --><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><version>3.1</version><configuration><source>1.8</source><target>1.8</target></configuration></plugin><!-- Scala Compiler --><plugin><groupId>org.scala-tools</groupId><artifactId>maven-scala-plugin</artifactId><version>2.15.2</version><executions><execution><goals><goal>compile</goal><goal>testCompile</goal></goals></execution></executions></plugin></plugins></build>
使用scala
/*** 写scala可运行文件的注意事项* 1、如果一个scala文件要运行,class要改成object* 2、如果是class,就仅单纯代表一个类,如果是object代表的是单例对象* 3、scala语法中,一句话结束不需要加分号* 4、scala文件中,可以无缝使用java中的类和方法*/
object HelloWorld {def main(args: Array[String]): Unit = {println("hello world")System.out.println("hhh") // java语法同样可以运行}
}
scala语法
1.变量与常量
变量:
在程序的运行过程中,其值可以发生改变的量,在scala中定义一个变量,需要使用一个关键词:var
注意:
1、变量一旦定义,它的类型就确定,可以不用手动指定类型,根据赋的值自动推断出类型
2、也可以手动的指定变量的数据类型,完整的写法:var 变量名:数据类型 = 值
scala中的数据类型和java的数据类型对应关系:
| java: | scala: |
|---|---|
| byte | Byte |
| short | Short |
| int | Int |
| long | Long |
| float | Float |
| double | Double |
| boolean | Boolean |
| char | Char |
常量:
在程序的运行过程中,其值不能发生改变的量
在scala中定义一个常量,需要使用一个关键词:val
定义一个变量a1,并赋值100var a1 = 100 // 自动推断出类型println(a1)println(a1.getClass) // 获取变量的类型
// a1 = "你好" :stringprintln(a1)a1 = 200 //可以改变值println(a1)//定义一个整数类型的变量a2,并赋值11var a2: Int = 11 //给类型println(a2)println(a2.getClass)println("=" * 50) // * 其实是一个函数,底层是通过StringBuilder链接字符的//定义一个整数常量a3,赋值300val a3: Int = 300println(a3)
2.字符串的使用
字符串:由若干个字符组成的序列
//正常使用双引号构建字符串var s1: String = "我是大帅哥!"println(s1)//使用三个一对双引号构建长字符串var sql1: String ="""|select|*|from|students|where age>18|""".stripMarginprintln(sql1)
String类和java是共同的一个字符串类,String类中的功能在scala中正常使用
// string类中的方法可以使用
var s3 = "hello,world,java,hadoop,scala"
// 数组
val arr1: Array[String] = s3.split(",")
// val arr1: Array[String] = s3 split "," 另一种写法 只有一个参数去掉符号
println(arr1) // 打印的是地址值
//scala中的数组和java中的数组一样,也是有索引的,也是从0开始的 注意是()不是java中的[]println(arr1(0))println(arr1(1))println(arr1(2))println(arr1(3))println(arr1(4))
在scala中字符串是如何做拼接的?
- 1、使用+号拼接 这种拼接方式比较消耗性能
- 2、使用StringBuilder
- 3、前提:有一组序列,使用scala特有的函数 mkString
- 4、使用scala特有的字符串传递方式 s"${变量}" 底层就是使用StringBuilder方式拼接的
var q1: String = "hello"var q2: String = "world"var q3: String = "java"var res1: String = q1 + "|" + q2 + "|" + q3println(res1)// hello|world|javaval sb: StringBuilder = new StringBuilder()sb.append(q1).append("-").append(q2).append("-").append(q3)println(sb) //hello-world-javaval res3: String = arr1.mkString("&") // 数组方法println(res3) //hello&world&java&hadoop&scalaval res4: String = s"${q1.toUpperCase}#${q2}#${q3}" //可以使用string的方法println(res4) //HELLO#world#java
3.运算符
/** 运算符* */
var x: Int = 3
var y: Int =4
println(x+y)
println(x-y)
println(x*y)
println(x/y)
println(x * 1.0/ y) // 整除
println(x%y)
4.条件语句
条件语句:
选择语句: if
循环语句:for while
选择语句: if
val sc = new Scanner(System.in)print("请输入年龄:")val age : Int = sc.nextInt()if(age>18){println("成年了")}else{println("未成年")}
循环语句
// for 循环遍历数组//创建一个数组//数组:在内存中一块连续固定大小的空间,有索引可以检索数据,查询快,增删慢val arr1: Array[Int] = Array(1, 2, 3, 4, 5)
// 遍历数组// java的方法在这里行不通
// for(var i:Int = 0;i<arr1.length;i+=1){
// println(arr1(i))
// }/*** 注意:* 1、在scala语言中,没有++或者--的语法 i+=1 i= i+1* 2、在scala语言中,不存在和java一样的普通for循环* 3、scala中的for循环写法不太一样*/for (i <- arr1){println(i)}
// while循环遍历数组var i :Int = 0while (i<arr1.length){println(arr1(i))i +=1}
需求:在控制台中输出10行hello world
// while 循环实现var i:Int = 1while (i<=10){println("hello world")i+=1}
// 使用for循环,指定循环的次数// 10次 包含10for(e<-1 to 10){println("hello world")}// 9次 不包含10for(e<-1 until 10){println("hello world")}
5.控制流程语句
注意:在scala中没有break或者continue关键字
for (e <-1 to 5){if(e == 2){
// continue 用不了}println(e)}
// break
import scala.util.control.Breaks._ // scala中大部情况下,表示所有或者默认值或者占位符的时候,使用的是下划线for (e <-1 to 5){if(e == 2){break // 底层实现是一个函数,抛出一个异常,终止程序运行}println(e)}
println("我是大帅哥")
//Exception in thread "main" scala.util.control.BreakControl
//后续代码不会执行
// break之后不停 继续运行 使用breakablebreakable{for (e <-1 to 5){if(e == 2){break // 底层实现是一个函数,抛出一个异常,终止程序运行}println(e)}}println("我是大帅哥")
// 1 我是大帅哥 遇到break 继续运行
6.IO流
读文件
/** 对比java与scala* */// 读取一个文件内容// java的方式读取val br = new BufferedReader(new FileReader("D:\\pypro\\Bigdt30\\scala\\data\\test.text"))var line : String = br.readLine()while(line != null){println(line)line = br.readLine()}// scala中的读取文件的方式// Source.fromFil 底层是使用了字节输入流读取数据FileInputStreamval bs: BufferedSource = Source.fromFile("D:\\\\pypro\\\\Bigdt30\\\\scala\\\\data\\\\test.text")
// val lineIterator: Iterator[String] = bs.getLines()
// while (lineIterator.hasNext){
// val s: String = lineIterator.next()
// println(s)
// }
// for (e <- lineIterator) {
// println(e)
// }
// 简写for (e <- bs.getLines()) {println(e)}
写文件
// java写文件val bw = new BufferedWriter(new FileWriter("scala/data/test1.text"))bw.write("哈哈哈哈哈")bw.newLine()bw.write("呵呵呵")bw.flush()// 纯scala中没有写文件的方式
7.异常
与java中的很像
/*** scala中的异常和java的很像*/try {// println(10/2) //除0异常// val arr1: Array[Int] = Array(1, 2, 3, 4, 5)// println(arr1(5)) // 数组越界异常// val br: BufferedReader = new BufferedReader(new FileReader("scala/data/words888.txt")) // 文件找不到异常/*** 也可以手动的抛出异常*/val sc = new Scanner(System.in)print("输入除数:")val cs: Int = sc.nextInt()if(cs!=0){println(10/cs)}else{throw new ArithmeticException("您输入的除数是0") // 抛出异常}}catch{//类似于sql语句中case whencase e:ArithmeticException=>// println("除0异常")e.printStackTrace()case e:ArrayIndexOutOfBoundsException=>println("数组越界异常")
// case e:Exception=> 不确认的异常
// println("出现异常")case _ => // 任意一个异常println("出现异常")}finally {//今后finally中的处理大部分情况下都与释放资源有关println("这是finally代码块")}println("hello world")
8.函数和方法
在不同的地方定义,称呼不一样
- 函数:在object中定义的叫做函数
- 方法:在class中定义的叫做方法
def main(args: Array[String]): Unit = {}
- def: 定义函数或者方法的关键字
- main: 是函数或者方法的名字,符合标识符的命名规则
- args: 函数形参的名字
- Array[String]: 参数的数据类型,是一个元素为字符串的数组
- =: 后面跟着函数体
- Unit: 等同于java中的void 表示无返回值的意思
def main(args: Array[String]): Unit = {//调用函数val res1: Int = add(3, 4)println(res1)//在main函数内也可以创建函数 java中不行 但是要调用这个函数必须在定义后面def plus(x: Int, y: Int): Int = {return x + y}// 证明:scala中的函数可以嵌套定义,函数中可以再定义函数//调用必须在定义之后val res2: Int = plus(10, 20)println(res2)}
//需求1:定义一个求两个数之和的函数,返回结果
// 在main函数之外def add(a1: Int, b1: Int): Int = { return a1 + b1}
object Demo5Function {def main(args: Array[String]): Unit = {val res3: Int = add2(11, 22) // 报错println(res3)val d1 = new Demo1() //创建对象调用函数val res4: Int = d1.add2(11, 22)println(res4)}
}
// 函数或者方法必须定义在class或者object中
def add2(a1: Int, b1: Int): Int = {return a1 + b1
}class Demo1{//这里叫方法,将来调用时需要创建该类的对象才可以调用def add2(a1: Int, b1: Int): Int = {return a1 + b1}
}
object Demo5Function {def main(args: Array[String]): Unit = {// 调用形式 //object中的函数可以使用类名调用,类似于静态一样val res5: Int = Demo5Function.add(100, 200)println(res5)
//调用形式2:object中的函数调用时,可以省略类名val res6: Int = add(200, 300)println(res6)// 调用形式3val res7: Int = fun1("1000")println(res7)//如果方法调用的函数只有一个参数的时候,可以将.和小括号用空格代替调用val res8: Int = Demo5Function fun1 "1000" // "=" * 50 -> "=".*(50)println(res8)//如果定义的时候,没有小括号,调用的时候,就不需要加小括号show}def fun1(s:String): Int = {return s.toInt//定义格式1:如果函数有返回值,且最后一句话作为返回值的话,return关键字可以不写def add3(a1: Int, b1: Int): Int = {a1 + b1}//定义格式2:如果函数体中只有一句实现,那么大括号也可以不写def add4(a1: Int, b1: Int): Int = a1 + b1//定义格式3:如果函数没有参数的时候,小括号省略不写def show= println("好好学习,天天向上!")}
}
函数的递归
/*** scala中的函数也可以递归* 方法定义时,调用自身的现象** 条件:要有出口,不然就是死递归*/def main(args: Array[String]): Unit = {//求阶乘 5!val res1: Int = jieCheng(5)println(s"5的阶乘是$res1")println(s"5的阶乘是${Demo6Function jieCheng 5}") // 简写}def jieCheng(number: Int): Int = {if (number == 1) {1} else {number * jieCheng(number - 1)}}
9.类(面向对象)
val s1: Student = new Student() //好好学习,天天向上!
/*** 可以在scala程序定义类* 类:构造方法 成员方法 成员变量** 构造方法:* 1、在scala中构造方法的编写和在java中不太一样,类所拥有的大括号中都是构造代码块的内容* 2、默认情况下,每一个类都应该提供一个无参的构造方法* 3、构造方法可以有许多*/
//这就是一个构造方法
class Student{println("好好学习,天天向上!") //理解为代码块 java中不行
}
// 带参构造
def main(args: Array[String]): Unit = {// val s1: Student = new Student("jack",18)val s2: Student = new Student("jack", 18, "男")println(s2) // 打印的是地址 需要tostring方法//如果调用的是一个类的无参构造方法,new的时候小括号可以不用写val s3: Student2 = new Student2s3.fun1()//也可以使用多态的方式创建对象
// val s4:Student2=new Student2 父类引用指向子类对象// s4.fun1() 调用方法时 运行看左,编译看右 此时父类中没有此方法 报错val s4:Object = new Student("mike", 19, "男")println(s4.toString)// 考虑这种做法
}
class Student(name: String, age: Int) {/*** 定义成员变量*/val _name: String = nameval _age: Int = agevar _gender: String = _ // 这个下划线,就表示将来会赋予默认值/*** 构造方法也可以写多个*/def this(name: String, age: Int, gender: String) {this(name: String, age: Int)_gender = gender}/*** 也可以重写方法*/override def toString: String = {"姓名:" + _name + ", 年龄:" + _age + ", 性别:" + _gender}
}class Student2{def fun1()={println("牛逼666")}
}
与java创建类时一样,定义成员变量,构造方法,getset方法,重写tostring方法 非常麻烦
// caseclass
/*** scala提供了一个非常好用的功能:样例类* 减少用户创建类所编写代码量,只需要定义成员变量即可,自动扩充成员变量,构造方法,重写toString方法*/
object Demo8CaseClass {def main(args: Array[String]): Unit = {val t1 = new Teacher("jack", 22, "打胶")println(t1)println(t1.name)println(t1.age)println(t1.like)t1.like = "敲代码" println(t1)// 改变了}
}/*** 样例类中的成员变量,编译后默认是被jvm添加了final关键字,用户是改变不了的* 对于scala来说,默认是被val修饰的* 如果将来想要被改变,定义的时候需要使用var进行修饰*/
case class Teacher(name:String,age:Int,var like:String)
Apply
def main(args: Array[String]): Unit = {val b1: Book = new Book()b1.apply() // 当作是一个普通的方法}
class Book{def apply(): Unit = {println("hhh")}
}
def main(args: Array[String]): Unit = {Book() // 理解为伴生对象 可以直接调用object中的功能}
object Book{def apply(): Unit = {println("hhh")}
}
def main(args: Array[String]): Unit = {val b1: Book = Book("中华上下五千年", 999)println(b1)}// object Book 是 object Book 的伴生对象 名字相同
object Book {def apply(name:String,price:Int): Book = {new Book(name,price)}
}
class Book(name: String, price: Int) {val _name: String = nameval _price: Int = priceoverride def toString: String = "书名:" + _name + ", 价格:" + _price
}
10.函数式编程
面向对象与函数式编程的区别:
- 面向对象编程:将对象当作参数一样传来传去
- 1、对象可以当作方法参数传递
- 2、对象也可以当作方法的返回值返回
- 当看到类,抽象类,接口的时候,今后无论是参数类型还是返回值类型,都需要提供对应的实现类对象
// 是一个参数为字符串类型,返回值是整数类型的函数def fun1(s: String): Int = {s.toInt + 1000}val res1: Int = fun1("1000")println(res1)
- 面向函数式编程:将函数当作参数一样传来传去
- 1、函数A当作函数B的参数进行传递
- 2、函数A当作函数B的返回值返回
- 在scala中,将函数也当作一个对象,对象就有类型
- 函数在scala也有类型的说法
- 参数类型=>返回值类型
//定义变量的方式,定义一个函数//将函数当作对象,赋值给类型是函数类型的变量,将来可以直接通过变量调用函数val fun2: String => Int = fun1val res2: Int = fun2("2000")println(res2) // 3000
函数A作为函数B的参数定义
- 本质上是将函数A的处理逻辑主体传给了函数B,在函数B中使用这个处理逻辑
// f: String => Int 相当于函数A// fun3 相当于函数B//定义 函数主体def fun3(f: String => Int): Int = {val a1: Int = f("1000")a1 + 3000}
// 定义一个函数def show1(s:String): Int = {s.toInt}//调用val res1: Int = fun3(show1) // show1->fprintln(res1) // 4000def show2(s: String): Int = {s.toInt+11111}val res2: Int = fun3(show2)println(res2)// 15111
//定义一个函数fun1, 函数的参数列表中,既有正常的类型参数,也有函数类型的参数def fun1(s: String, f: String => Int): Int = {val a1: Int = f(s)a1 + 1000}def show1(s: String): Int = {s.toInt}def show2(s: String): Int = {s.toInt + 1111}// ..... val res1: Int = fun1("2000", show2) // 可以传不同的函数 很麻烦 使用lambda简写println(res1)//使用lambda表达式改写函数作为参数传递的调用形式 直接把函数逻辑写在后面fun1("2000", (s: String) => s.toInt)fun1("2000", (s: String) => s.toInt+1000)//在scala中,数据类型可以自动类型推断fun1("2000", s => s.toInt+1000)//如果当作参数的函数的参数只在函数主体使用了一次,那么可以使用_代替fun1("2000", _.toInt+1000)
应用:遍历数组
def main(args: Array[String]): Unit = {val arr1: Array[Int] = Array(11, 22, 33, 44, 55)// 遍历 太麻烦 使用foreach函数// for (e <- arr1) {// println(e)// }// def fun1(i: Int): Unit = {
// println(i*2)
// }//def foreach[U](f: A => U): Unit//foreach函数需要一个参数和数组元素一样类型的类型,返回值是Unit的函数//foreach函数的主要作用是将调用该方法的序列中的元素,依次取出传递给后面的函数进行处理arr1.foreach(fun1)// scala自带的一个函数// def println(x: Any) = Console.println(x)// Any可以接收任意的数据类型元素arr1.foreach(println)}
函数当作返回值返回
/*** fun1: 参数是String类型,返回值是一个函数(参数是String类型,返回值是Int)*/
// 定义返回值是函数的函数方式1:def fun1(s1: String): String => Int = {def show(s: String): Int = { // 要返回的函数s.toInt + s1.toInt}show}// 调用函数的返回值是函数的方式1:val resFun1: String => Int = fun1("1") // 把函数作为对象赋给一个变量 show-> resFun1val res1: Int = resFun1("1000")println(res1)// //调用方式2:// val res2: Int = fun1("1")("1000")// println(res2)
- 什么是函数柯里化?
- 1、本身是一个数学界的一个名词,本意是原来一次传递多个参数,现在被改成了可以分开传递的形式,这种做法叫做柯里化
- 2、在scala中体现柯里化,指的是函数的返回值也是一个函数,将来调用时参数可以分开传递。
- 3、提高了程序的灵活性和代码复用性
- 4、在scala中也可以通过偏函数实现参数分开传递的功能
//定义方式2(是方式1的简化写法):/*** 方式2这种将参数分开定义,今后调用时可以分开传递,这种做法,在scala中叫做函数柯里化**/def fun1(s1: String)(s: String): Int = {s.toInt + s1.toInt}
//函数柯里化:val resFun1: String => Int = fun1("1")val r1: Int = resFun1("11")println(r1)val r2: Int = resFun1("12")println(r2)val r3: Int = resFun1("13")println(r3)
// 调用方法和方式一相同
def function1(s1: String, s2: String): Int = { // 返回值类型不是函数s1.toInt + s2.toInt}/*** 偏函数 * 分开传递*/val f1: String => Int = function1("1", _) // 加_得到一个函数val res1: Int = f1("1000")val res2: Int = f1("2000")val res3: Int = f1("3000")println(s"res1:$res1,res2:$res2,res3:$res3")
11.集合
java中的ArrayList
def main(args: Array[String]): Unit = {val list1: util.ArrayList[Int] = new util.ArrayList[Int]() // 创建ArrayListlist1.add(11)list1.add(22)list1.add(33)list1.add(44)//scala中的for循环,只能遍历scala中的序列,无法遍历java的序列// for (e <- list1) { 无法使用// }// 使用while循环遍历var i = 0while (i < list1.size()) {println(list1.get(i))i += 1}
scala的集合:
- List: 元素有序,且可以发生重复,长度固定的
- Set: 元素无序,且唯一,长度固定的
- Map: 元素是键值对的形式,键是唯一的
- Tuple: 元组,长度是固定的,每个元素的数据类型可以不一样
// list//创建了一个空集合val list1: List[Nothing] = List()val list2: List[Int] = List(34, 11, 22, 11, 33, 44, 55, 22, 75, 987, 1, 12, 34, 66)
// 1.获取List集合的长度println(list2.size)println(list2.length)
//2.通过索引下标获取元素println(list2(0))println(list2(1))
//3.scala推荐获取第一个元素的方式是调用head函数 最后一个元素调用lastprintln(list2.head)println(list2.last)
//4.根据指定的分隔符拼接元素println(list2.mkString("|"))
//5.反转val resList1: List[Int] = list2.reverseprintln(s"list2:$list2")println(s"resList1:$resList1")
//6.去重val resList2: List[Int] = list2.distinct //返回一个新的集合println(s"list2:$list2")println(s"resList2:$resList2")
//7.去掉第一个元素 tailval resList3: List[Int] = list2.tail // 除去第一个,其余的元素返回一个新的集合println(s"list2:$list2")println(s"resList3:$resList3")
//8.取数(前几个)val resList4: List[Int] = list2.take(5) // 从左向右取元素,取若干个println(s"list2:$list2")println(s"resList4:$resList4")
//9.取数(靠右边的)val resList5: List[Int] = list2.takeRight(5) //取右边的几个,组成新的集合println(s"list2:$list2")println(s"resList5:$resList5")
//10.从第一个判断取数据,直到不符合条件停止val resList6: List[Int] = list2.takeWhile((e: Int) => e % 2 == 0)println(s"list2:$list2")println(s"resList6:$resList6")
//11.求和val res1: Int = list2.sum // 元素必须是数值println(s"集合中的元素和为:$res1")
//12.最值val res2: Int = list2.maxprintln(s"集合中的元素最大值为:$res2")
//13.遍历集合for (e <- list2) {println(e)}//list的高阶函数//foreach: 将集合中的元素依次取出传入到后面的函数中
// 注意:没有返回值的,要么就输出,要么就其他方式处理掉了//def foreach[U](f: A => U)list2.foreach((e: Int) => println(e))
// 简写list2.foreach(println)
//需求1:使用foreach求出集合中偶数的和var ouSum = 0var jiSum = 0list2.foreach((e: Int) => {if (e % 2 == 0) {ouSum += e} else {jiSum += e}})println(s"集合中偶数之和为:$ouSum")println(s"集合中奇数之和为:$jiSum")// map: 依次处理每一个元素,得到一个新的结果,返回到一个新的集合中val list3: List[Int] = List(1, 2, 3, 4, 5, 6, 7, 8, 9)//需求2:将集合中的每一个元素*2val resList7: List[Int] = list3.map((e: Int) => e * 2)println(s"list3:$list3")println(s"resList7:$resList7")//filter: 保留符合条件的元素val list4: List[Int] = List(4, 7, 9, 10, 12, 11, 14, 9, 7)val resList8: List[Int] = list4.filter((e: Int) => e % 2 == 0)println(s"list4:$list4")println(s"resList8:$resList8")// sortBy: 排序
// sortWith: 两个数之间的关系排序val resList9: List[Int] = list4.sortBy((e: Int) => -e)println(s"list4:$list4")println(s"resList9:$resList9")val resList10: List[Int] = list4.sortWith((x: Int, y: Int) => x > y)println(s"list4:$list4")println(s"resList10:$resList10")//flatMap: 扁平化val list5: List[String] = List("hello|world|java", "hello|hadoop|flink", "scala|spark|hadoop")val resTmp1: List[String] = list5.flatMap((e: String) => e.split("\\|"))resTmp1.foreach(println)// groupBy: 分组val list6: List[String] = List("hello", "world", "java", "hadoop", "flink", "java", "hadoop", "flink", "flink", "java", "hadoop", "flink", "java", "hadoop", "hello", "world", "java", "hadoop", "hello", "world", "java", "hadoop")val map: Map[String, List[String]] = list6.groupBy((e: String) => e) // 按照元素分组for (e <- map) {println(e)}
// set
//set集合:scala中的Set集合也是不可变的,除了排序相关的函数以外,List集合有的高阶函数,Set集合也有 无序
// 创建两个set集合val set1: Set[Int] = Set(1, 4, 3, 6, 5)val set2: Set[Int] = Set(3, 6, 5, 7, 8)
// 求交集// val resSet1: Set[Int] = set1.&(set2)
// val resSet1: Set[Int] = set1 & set2val resSet1: Set[Int] = set1.intersect(set2)println(s"set1: ${set1}")println(s"set2: ${set2}")println(s"交集: ${resSet1}") //(5,6,3)//求并集// val resSet2: Set[Int] = set1.|(set2)val resSet2: Set[Int] = set1 | set2println(s"set1: ${set1}")println(s"set2: ${set2}")println(s"并集: ${resSet2}")//求差集// val resSet3: Set[Int] = set1.&~(set2)val resSet3: Set[Int] = set1 &~ set2println(s"set1: ${set1}")println(s"set2: ${set2}")println(s"差集: ${resSet3}")//set集合和list集合相互转换 toset tolistval list1: List[Int] = List(11, 22, 33, 44, 55, 11, 22, 44, 88, 33, 44, 99, 11, 22, 55)//List->Setval resSet4: Set[Int] = list1.toSetprintln(s"list1:${list1}")println(s"resSet4:${resSet4}")println("=" * 50)//Set->Listval list2: List[Int] = resSet4.toList.sortBy((e:Int)=>e)println(s"list1:${list1}")println(s"resSet4:${resSet4}")println(s"list2:${list2}")
//mutable/*** 通过观察api发现,不可变的集合是属于scala.collection.immutable包下的* 如果将来想要使用可变的集合,就要去scala.collection.mutable包下寻找*/
//创建一个可变的List集合val listBuffer1: ListBuffer[Int] = new ListBuffer[Int]
// 向集合中添加元素listBuffer1.+=(11)listBuffer1.+=(22)listBuffer1.+=(33)listBuffer1.+=(11)listBuffer1.+=(55)listBuffer1.+=(22)listBuffer1.+=(33)listBuffer1.+=(66)listBuffer1.+=(33)println(listBuffer1)
//使用函数获取元素 同list集合 list集合的功能可变集合都能调用 println(listBuffer1(2))println(listBuffer1.head)println(listBuffer1.last)
// 删除元素listBuffer1.-=(33) //从左向右找元素,只会删除第一次找到的
//批量添加元素listBuffer1.+=(100,220,300,400)
// 直接添加一个集合进去val list1: List[Int] = List(99, 88, 77)listBuffer1.++=(list1)// 可变的set集合 功能同set集合val hashSet1: mutable.HashSet[Int] = new mutable.HashSet[Int]()val set1: hashSet1.type = hashSet1.+=(1, 2, 3, 4, 5, 7, 1, 2, 3, 1, 6, 5)println(set1)
// Tuple
//大小,值是固定的,根据创建的类来定,每个元素的数据类型可以是不一样,最高可以创建存储22个元素的元组
// 不可变 保护信息
// 创建一个5元组val t1: (Int, String, String, Int, String) = Tuple5(1001, "jack", "男", 17, "学习")
// case class Student1(id: Int, name: String, age: Int, like: String)val s2: Student1 = new Student1(1002, "mike", 18, "看剧")val t2: (Int, Student1) = Tuple2(1002, s2)println(t2._2.name)
//map
//创建Map集合 元素是键值对形式
//键是唯一的,键一样的时候,值会被覆盖
val map1: Map[Int, String] = Map((1001, "张三"), (1002, "李四"), (1003, "王五"), (1001, "赵六"), 1005 -> "老刘")println(map1)
//可以根据键获取值// println(map1(1006)) // 小括号获取值,键不存在报错// println(map1.get(1006)) // get函数获取,键不存在,返回Noneprintln(map1.getOrElse(1006, 0)) //根据键获取值,若键不存在,返回提供的默认值,默认值的类型可以是任意数据类型val keys: Iterable[Int] = map1.keys // 获取所有的键,组成一个迭代器for (e <- keys) {println(e)}val values: Iterable[String] = map1.values // 获取所有的值,组成一个迭代器for (e <- values) {println(e)}
// 遍历map//遍历Map集合第一种方式,先获取所有的键,根据键获取每个值val keys2: Iterable[Int] = map1.keys // 获取所有的键,组成一个迭代器for (e <- keys2) {val v: Any = map1.getOrElse(e, 0)println(s"键:${e}, 值:${v}")}//遍历Map集合第二种方式for (kv <- map1) { // 直接遍历map集合,得到每一个键值对组成的元组println(s"键:${kv._1}, 值:${kv._2}")}//遍历Map集合第三种方式map1.foreach((kv: (Int, String)) => println(s"键:${kv._1}, 值:${kv._2}"))
集合的应用案例
WordCount:
def main(args: Array[String]): Unit = {//1、读取数据文件,将每一行数据封装成集合的元素val lineList: List[String] = Source.fromFile("scala/data/words.txt").getLines().toListprintln(lineList)//2、将每一行数据按照|切分,并且进行扁平化val wordsList: List[String] = lineList.flatMap((line: String) => line.split("\\|"))println(wordsList)//3、根据元素进行分组val wordKV: Map[String, List[String]] = wordsList.groupBy((e: String) => e)println(wordKV)/*** List((world,8), (java,11),...)*/val wordCount: Map[String, Int] = wordKV.map((kv: (String, List[String])) => {val word: String = kv._1val count: Int = kv._2.size(word, count)})println("="*50)val resultList: List[(String, Int)] = wordCount.toListresultList.foreach(println)println("="*50)// /**
// * 使用链式调用的方式简写
// */
// Source.fromFile("scala/data/words.txt")
// .getLines()
// .toList
// .flatMap((line:String)=>line.split("\\|"))
// .groupBy((e:String)=>e)
// .map((kv: (String, List[String])) => {
// val word: String = kv._1
// val count: Int = kv._2.size
// (word, count)
// })
// .toList
// .foreach(println)
}
}
12.JDBC
import java.sql.{Connection, DriverManager, PreparedStatement, ResultSet}/*** jdbc的链接步骤* 1、注册驱动* 2、创建数据库链接对象* 3、创建数据操作对象* 4、执行sql语句* 5、如果第4步是查询的话,分析查询结果* 6、释放资源*/object Demo20JDBC {def main(args: Array[String]): Unit = {//1、注册驱动Class.forName("com.mysql.jdbc.Driver")//2、创建数据库链接对象//jdbc:数据库名://host:port/数据库?xxx=xxx&xxx=xxxval conn: Connection = DriverManager.getConnection("jdbc:mysql://master:3306/Y1?useUnicode=true&characterEncoding=UTF-8&useSSL=false", "root", "123456")//3、创建数据操作对象val preparedStatement: PreparedStatement = conn.prepareStatement("select id,name,age,gender,clazz from student where clazz=?")//4、执行sql语句// 防止sql注入
// preparedStatement.setInt(1,23)preparedStatement.setString(1, "理科二班")val resultSet: ResultSet = preparedStatement.executeQuery()//5、如果第4步是查询的话,分析查询结果while (resultSet.next()){val id: Int = resultSet.getInt("id")val name: String = resultSet.getString("name")val age: Int = resultSet.getInt("age")val gender: String = resultSet.getString("gender")val clazz: String = resultSet.getString("clazz")println(s"学号:$id, 姓名:$name, 年龄:$age, 性别:$gender, 班级:$clazz")}//6、释放资源conn.close()}
}
13.JSON
导入依赖
<!-- https://mvnrepository.com/artifact/com.alibaba/fastjson --><dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId> <version>2.0.49</version></dependency>
import scala.io.Source
import com.alibaba.fastjson.{JSON, JSONArray, JSONObject}
def main(args: Array[String]): Unit = {val lineList: List[String] = Source.fromFile("scala/data/stu.json").getLines().toList// 拼起来val jsonStr: String = lineList.mkString("\r\n")//使用fastjson包中的JSON类,将一个字符串转成json对象//转成json对象之后,可以通过键获取值//parseObject 将整体转成一个json格式数据val jsonObj1: JSONObject = JSON.parseObject(jsonStr)// 键获取值val s1: String = jsonObj1.getString("student_list")//parseArray将一个"[{},{}]"变成一个元素是json对象的数组val jSONArray: JSONArray = JSON.parseArray(s1)// 遍历数组var i = 0while (i < jSONArray.size()) {val obj1: JSONObject = jSONArray.getJSONObject(i)val name: String = obj1.getString("name")val like: String = obj1.getString("like")println(s"${name}的爱好是${like}")i += 1}}
14.scala,java集合的转换
def main(args: Array[String]): Unit = {//创建一个java中的集合val array1: util.ArrayList[Int] = new util.ArrayList[Int]()array1.add(11)array1.add(22)array1.add(33)array1.add(66)array1.add(55)array1.add(44)println(array1)/*** 将java中的集合转成scala中的集合** java中的集合本来是没有转换scala的功能,需要导入隐式转换* scala中的导包,可以在任意地方**/import scala.collection.JavaConverters._val list1: List[Int] = array1.asScala.toListprintln(list1)/*** scala中的集合转java的集合*/val list2: util.List[Int] = list1.asJavaprintln(list2)}
}
15.模式匹配
模式匹配,可以帮助我们开发的时候,减少代码量,让逻辑看起来更加清晰,以及可以避免一些异常
语法:
表达式 match {
case 值|[变量名:类型]|元组|数组|对象=>
匹配成功执行的语句
case xxx=>
xxx
_ xxx=>
xxx
}
*模式匹配中,如果没有对应的匹配,那么就报错!!!
/*** 可以匹配变量值*/var i: Int = 100i match {case 20 => println("该值是20")case 50 => println("该值是50")// case 100=>println("该值是100")case _ => println("其他值")} // 其他值/**
// * 匹配数据类型
// */var flag1: Any = trueflag1 match {case _: Int => println("是Int类型")case _: Boolean => println("是boolean类型")}/**
// * 匹配元组
// */val t1: (Int, String, Int) = Tuple3(1001, "张三", 18)t1 match {case (a1: Int, b1: String, c1: Int) =>println(s"学号:$a1, 姓名:$b1, 年龄:$c1")}//
// /**
// * 匹配数组
// */val array: Array[Any] = Array(1001, "李四", "男", 18, "理科一班")array match {case Array(id: Int, name: String, gender: String, age: Int, clazz: String) =>println(s"学号:$id, 姓名:$name, 性别:$gender, 年龄:$age, 班级:$clazz")}模式匹配的应用:
/*** 模式匹配的应用1:避免异常**/val map1: Map[Int, String] = Map((1001, "张三"), (1002, "李四"))// val res1: Option[String] = map1.get(1001) // Some("张三")
// .get 方法获取值// println(res1.get)// val res1: Option[String] = map1.get(1003)// println(res1.get)val sc: Scanner = new Scanner(System.in)println("请输入要查询的键:")val key: Int = sc.nextInt()map1.get(key) match {case Some(a: Any) => println(s"${key}键对应的值为$a")case None => println(s"${key}键不存在!")}// 输入1001 输出 1001键对应的值为张三// 输入1003 输出 1003键不存在/*** 模式匹配的应用2:简化代码*students.txt 部分数据:* 1500100066,惠耘涛,22,男,文科三班* 1500100067,广浦泽,22,男,文科五班* 1500100068,宣南蓉,23,女,理科一班*/val stuList: List[String] = Source.fromFile("scala/data/students.txt").getLines().toListval stuArrayList: List[Array[String]] = stuList.map((line: String) => line.split(","))// 不用模式匹配stuArrayList.map((e:Array[String])=>{val id: String = e(0)val name: String = e(1)val age: String = e(2)val gender: String = e(3)val clazz: String = e(4)(id, name, gender, age, clazz)}).foreach(println)// 使用模式匹配stuArrayList.map{case Array(id: String, name: String, gender: String, age: String, clazz: String)=>(id, name, gender, age, clazz)}.foreach(println)
16.隐式转换
scala中的隐式转换:
1、scala中的隐式转换,本质上就是将一个类型转换成另一个类型去使用另一个类型中的功能
2、scala中的隐式转换分为3种:隐式转换函数,隐式转换类,隐式转换变量
3、隐式转换函数,在使用隐式转换函数返回值类型的功能的时候,可以自动的将参数的类型转成返回值类型进行使用
4、隐式转换类,可以自动的将构造方法的参数类型转成类的类型,将来可以直接使用构造方法中的类型调用类中的方法
5、隐式转换变量,配合函数定义中的隐式转换参数使用,
将来调用函数的时候,可以不用传入隐式转换参数的值,自动使用对应类型的隐式转换变量
当然,也可以手动传入具体的值给隐式转换参数。
// 隐式转换函数
// 将一个A类型将来会自动地转换成另一个B类型,类型可以式基本数据类型,也可以是引用数据类型var i:String = "100"//显式转换val res1: Int = i.toInt// 定义一个函数def fun1(s: Int): Int = {return s + 1000}//调用函数println(fun1(100))println(fun1(200))println(fun1("300".toInt))// 定义隐式转换函数
//需求:调用fun1函数,就只传字符串,不会报错//在需要返回值类型的功能的时候,自动地根据已有隐式转换函数将参数的类型转成返回值的类型
// 参数类型和返回值类型相同时,尽管函数体不一样,也是重复的隐式函数implicit def implicitFun1(s: String): Int = {return Integer.parseInt(s)}//调用函数println(fun1(100))println(fun1(200))println(fun1("300")) // 不报错,有结果
// 读文件时的隐式转换 将字符串自动转换为BufferedSource类
object Demo11 {implicit def implicitFun3(s: String): BufferedSource = Source.fromFile(s)implicit def implicitFun1(s: String): Int = Integer.parseInt(s)
}
import com.shujia.jichu.Demo11._val stuList: List[String] = "scala/data/students.txt".getLines().toListval scoreList: List[String] = "scala/data/scores.txt".getLines().toListprintln("1000" + 500) // 1000500 // 优先使用字符串自身的+拼接功能,做字符串拼接println("1000" - 500) // 500 // 字符串中没有-减法功能,自动使用隐式转换中的函数,将字符串转成数字做减法println("2000" - 500) // 1500 // 字符串中没有-减法功能,自动使用隐式转换中的函数,将字符串转成数字做减法/*** 隐式转换类*/def main(args: Array[String]): Unit = {// 正常做法// 创建对象,使用函数val demo1 = new Demo12("scala/data/students.txt")val stuList: List[String] = demo1.show1()// 定义隐式转换类之后 字符串自动转换为对象val stuList: List[String] = "scala/data/students.txt".show1()}
// 定义一个隐式转换类 读取文件信息//`implicit' modifier cannot be used for top-level objects 不能写在object外面//implicit class Demo12(path: String) {//implicit使用的地方,不能超过object作用域implicit class Demo12(path: String) {def show1(): List[String] = {Source.fromFile(path).getLines().toList}
/*** 隐式转换变量*/def main(args: Array[String]): Unit = {// 之前没有定义过读取文件编码,是因为 def fromFile(name: String)(implicit codec: Codec): BufferedSource 存在隐式转换参数codec 默认utf-8 可以手动修改Source.fromFile("scala/data/students.txt")(Codec("GBK")).getLines().toList//定义一个隐式转换参数def fun1(a1: Int)(implicit a2: Int): Int = a1 + a2//定义一个隐式转换变量implicit var i1: Int = 1000
// a2可以不用传,寻找Int类型的变量,直接使用默认值val res1: Int = fun1(100)println(res1) //1100}
scala进阶应用:
阶段一
基于学生、分数、科目数据使用Scala语言完成下面的练习
中括号为最终要求输出的格式
题目较为基础
1.统计班级人数 [班级,人数]
2.统计学生的总分 [学号,学生姓名,学生年龄,总分]
阶段二
数据同阶段二一样
题目难度偏大
1、统计年级排名前十学生各科的分数 [学号, 姓名,班级,科目,分数]
2、统计总分大于年级平均分的学生 [学号,姓名,班级,总分]
3、统计每科都及格的学生 [学号,姓名,班级,科目,分数]
4、统计每个班级的前三名 [学号,姓名,班级,分数]
5、统计偏科最严重的前100名学生 [学号,姓名,班级,科目,分数]
数据准备:
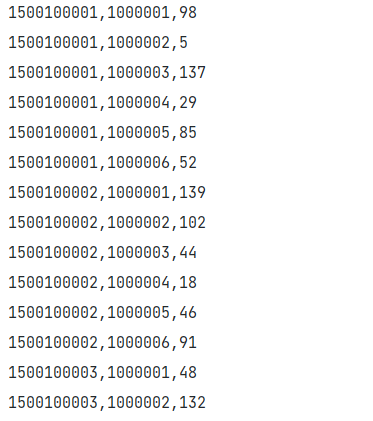
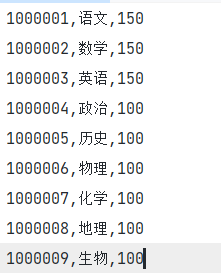
部分数据截图:
students.txt

score.txt
subject.txt
import scala.collection.immutable
import scala.io.Sourceobject HomeWork {//定义一些变量,样例类,为后续的开发做准备/*** 定义一些样例类 类似于java的封装*/private case class Student(id: String, name: String, age: Int, gender: String, clazz: String)private case class Score(id: String, subject_id: String, score: Int)private case class Subject(subject_id: String, subject_name: String, subject_score: Int)/*** 定义三个存储三个不同对象的List集合*/private var stuList: List[Student] = _private var scoreList: List[Score] = _private var subjectList: List[Subject] = _/*** 定义一些map集合* stuInfoMap (stu.id, stu.name + "," + stu.clazz)* subNameMap (subject.subject_id, subject.subject_name)* subScoreMap (subject.subject_id, subject.subject_score)*/private var stuInfoMap: Map[String, String] = _private var subNameMap: Map[String, String] = _private var subScoreMap: Map[String, Int] = _//初始化变量private def loadData(): Unit = {//读取学生数据stuList = "scala/data/students.txt".load().map {case Array(id: String, name: String, age: String, gender: String, clazz: String) =>Student(id, name, age.toInt, gender, clazz)}//读取成绩数据scoreList = "scala/data/score.txt".load().map {case Array(id: String, subject_id: String, score: String) =>Score(id, subject_id, score.toInt)}//读取科目数据subjectList = "scala/data/subject.txt".load().map {case Array(subject_id: String, subject_name: String, subject_score: String) =>Subject(subject_id, subject_name, subject_score.toInt)}//处理三个map集合//stuInfoMap 存储了学生的学号为键,姓名和班级作为值stuInfoMap = stuList.map((stu: Student) => (stu.id, stu.name + "," + stu.clazz)).toMapsubNameMap = subjectList.map((sub: Subject) => (sub.subject_id, sub.subject_name)).toMapsubScoreMap = subjectList.map((sub: Subject) => (sub.subject_id, sub.subject_score)).toMap}/*** 根据学号集合打印【学号,姓名,班级,科目,分数】*/private def printStudentInfoWithId(ids: List[String]): Unit = {// 从总的学生成绩信息中过滤出来scoreList.filter((sco: Score) => ids.contains(sco.id)).map {case Score(id: String, subject_id: String, score: Int) => {//根据学号,查找姓名和班级 stuInfoMapval nameWithClazz: String = stuInfoMap.getOrElse(id, "查无此人")//根据科目编号,查找科目的名字 subNameMapval subject_name: String = subNameMap.getOrElse(subject_id, "无此科目")s"[$id,$nameWithClazz,$subject_name,$score]"}}.foreach(println)}/*** 统计班级人数 [班级,人数]*/private def xuQiu1(): Unit = {stuList.groupBy((stu: Student) => stu.clazz).map((kv: (String, List[Student])) => {s"[${kv._1},${kv._2.size}]"}).foreach(println)}/*** 统计学生的总分 [学号,学生姓名,学生年龄,总分]*/private def xuQiu2(): Unit = {val stringToInt: Map[String, Int] = scoreList.groupBy((sco: Score) => sco.id).map((kv: (String, List[Score])) => {(kv._1, kv._2.map(_.score).sum)})val ids: List[String] = stringToInt.map {case (id: String, _: Int) => id}.toListstuList.filter((stu: Student) => ids.contains(stu.id)).map((stu: Student) => {val sumScore: Int = stringToInt.getOrElse(stu.id, 0)s"[${stu.id},${stu.name},${stu.age},$sumScore]"}).foreach(println)}/*** 统计年级排名前十学生各科的分数 [学号,姓名,班级,科目,分数]*/private def xuQiu3(): Unit = {val ids: List[String] = scoreList.groupBy((s: Score) => s.id) // 按照学号进行分组.map((kv: (String, List[Score])) => {(kv._1, kv._2.map(_.score).sum) // 求每个学生的总分}).toList.sortBy(-_._2).take(10).map(_._1)printStudentInfoWithId(ids) // 学号,姓名,班级,科目,分数}/*** 统计总分大于年级平均分的学生 [学号,姓名,班级,总分]*/private def xuQiu4(): Unit = {//先计算年级平均分 372val avgScore: Int = scoreList.map(_.score).sum / stuList.size// println(avgScore)//计算每个人总分进行过滤scoreList.groupBy((s: Score) => s.id) // 按照学号进行分组.map((kv: (String, List[Score])) => {(kv._1, kv._2.map(_.score).sum) // 求每个学生的总分}).filter(_._2 > avgScore).map((t: (String, Int)) => {//根据stuInfoMap获取学生的姓名和班级val nameWithClazz: String = stuInfoMap.getOrElse(t._1, "查无此人")s"[${t._1},$nameWithClazz,${t._2}]"}).foreach(println)}/*** 统计每科都及格的学生 [学号,姓名,班级,科目,分数]*/private def xuQiu5(): Unit = {//1500100001,1000001,98val ids: List[String] = scoreList.filter((sco: Score) => sco.score >= subScoreMap.getOrElse(sco.subject_id, 0) * 0.6).groupBy(_.id) // 根据学号分组,过滤6门考试都及格的学生.filter(_._2.size == 6).keys.toListprintStudentInfoWithId(ids)}/*** 统计每个班级的前三名 [学号,姓名,班级,分数]*/private def xuQiu6(): Unit = {val ids: List[String] = scoreList.groupBy((s: Score) => s.id) // 按照学号进行分组.map((kv: (String, List[Score])) => {val nameWithClazz: String = stuInfoMap.getOrElse(kv._1, "查无此人")val infos: Array[String] = nameWithClazz.split(",")val name: String = infos(0)val clazz: String = infos(1)(kv._1, name, clazz, kv._2.map(_.score).sum) // 求每个学生的总分}).groupBy(_._3) // 根据班级进行分组.flatMap((kv: (String, Iterable[(String, String, String, Int)])) => {kv._2.toList.sortBy(-_._4).take(3)}).map(_._1).toList// 从总的学生成绩信息中过滤出来scoreList.filter((sco: Score) => ids.contains(sco.id)).map {case Score(id: String, subject_id: String, score: Int) => {//根据学号,查找姓名和班级 stuInfoMapval nameWithClazz: String = stuInfoMap.getOrElse(id, "查无此人")s"[$id,$nameWithClazz,$score]"}}.foreach(println)}/*** 统计偏科最严重的前100名学生 [学号,姓名,班级,科目,分数]** 方差* (每个人的各科分数-6门考试的平均分)^2 / 科目数**/private def xuQiu7(): Unit = {//归一化val ids: List[String] = scoreList.map {case Score(id: String, subject_id: String, score: Int) =>(id: String, subject_id: String, score * 100 / subScoreMap.getOrElse(subject_id, 0))}.groupBy(_._1) //根据学号进行分组.map((kv: (String, List[(String, String, Int)])) => {val id: String = kv._1val scoreList: List[(String, String, Int)] = kv._2//每个人的平均分val avgScore: Int = scoreList.map(_._3).sum / scoreList.size//求方差val fangCha: Double = scoreList.map((t3: (String, String, Int)) => Math.pow(t3._3 - avgScore, 2)).sum / scoreList.size(id, fangCha)}).toList.sortBy(-_._2).take(100).map(_._1)printStudentInfoWithId(ids)}def main(args: Array[String]): Unit = {loadData()// xuQiu1()// xuQiu2()// xuQiu3()// xuQiu4()// xuQiu5()// xuQiu6()xuQiu7()}//定义一个隐式转换类//将来可以直接通过文件路径获取一个封装了行数据的集合implicit class Load(path: String) {def load(): List[Array[String]] = {Source.fromFile(path).getLines().toList.map((line: String) => line.split(","))}}}