循环神经网络
RNN是针对序列数据而生的神经网络结构,核心在于循环使用网络层参数,避免时间步增大带来的参数激增,并引入**隐藏状态(Hidden State)**用于记录历史信息,有效的处理数据的前后关联性。
隐藏状态
隐藏状态 (HiddenState)用于记录历史信息,有效处理数据的前后关联性激活函数采用Tanh,将输出值域限制在[-1,1],防止数值呈指数级变化
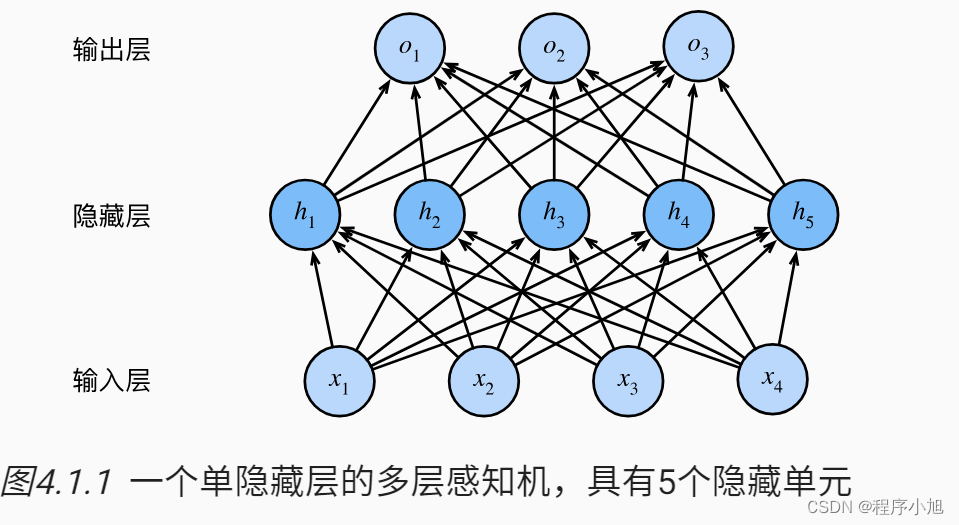
无隐藏状态
无状态的网络模型即之前应用过的多层感知机模型。
H = ϕ ( X W x h + b h ) O = H W h q + b q \begin{aligned} \boldsymbol{H} & =\phi\left(\boldsymbol{X} \boldsymbol{W}_{x h}+\boldsymbol{b}_{h}\right) \\ \boldsymbol{O} & =\boldsymbol{H} \boldsymbol{W}_{h q}+\boldsymbol{b}_{q} \end{aligned} HO=ϕ(XWxh+bh)=HWhq+bq
用Softmax回归来计算输出类别的概率分布。
有隐藏状态
有了隐状态后,情况就完全不同了。假设我们在时间步t有小批量输入Xt∈ R。换言之,对于n个序列样本
的小批量,Xt的每一行对应于来自该序列的时间步t处的一个样本。接下来,用Ht∈ Rn×h 表示时间步t的隐藏变量。与多层感知机不同的是,我们在这里保存了前一个时间步的隐藏变量Ht-1,并引入了一个新的权重参数Whh∈Rh×h,来描述如何在当前时间步中使用前一个时间步的隐藏变量。具体地说,当前时间步隐藏变量由当前时间步的输入与前一个时间步的隐藏变量一起计算得出:

H t = ϕ ( X t W x h + H t − 1 W h h + b h ) O t = H t W h q + b q \begin{aligned} \boldsymbol{H}_{t} & =\phi\left(\boldsymbol{X}_{t} \boldsymbol{W}_{x h}+\boldsymbol{H}_{t-1} \boldsymbol{W}_{h h}+\boldsymbol{b}_{h}\right) \\ \boldsymbol{O}_{t} & =\boldsymbol{H}_{t} \boldsymbol{W}_{h q}+\boldsymbol{b}_{q} \end{aligned} HtOt=ϕ(XtWxh+Ht−1Whh+bh)=HtWhq+bq
展示了循环神经网络在三个相邻时间步的计算逻辑。 在任意时间步t,隐状态的计算可以被视为:
1. 拼接当前时间步t的输入Xt和前一时间步t-1的隐状态Ht-1
2. 将拼接的结果送入带有激活函数Φ的全连接层。全连接层的输出是当前时间步t的隐状态Ht
循环神经网络文本举例
RNN特性:
- 循环神经网络的隐藏状态可以捕捉截至当前时间步的序列的历史信息
- 循环神经网络模型参数的数量不随时间步的增加而增长(本质上是三个权重矩阵w反复的进行使用)
RNN构建语言模型,实现文本生成。假设文本序列:想 要 有 直 升 机


衡量标准—困惑度(Perplexity)
讨论如何度量语言模型的质量, 这将在后续部分中用于评估基于循环神经网络的模型。 一个好的语言模型能够用高度准确的词元来预测我们接下来会看到什么。
如果想要压缩文本,我们可以根据当前词元集预测的下一个词元。 一个更好的语言模型应该能让我们更准确地预测下一个词元。 因此,它应该允许我们在压缩序列时花费更少的比特。 所以我们可以通过一个序列中所有的
n个词元的交叉熵损失的平均值来衡量:
1 n ∑ t = 1 n − log P ( x t ∣ x t − 1 , … , x 1 ) \frac{1}{n} \sum_{t=1}^{n}-\log P\left(x_{t} \mid x_{t-1}, \ldots, x_{1}\right) n1t=1∑n−logP(xt∣xt−1,…,x1)
其中P由语言模型给出,Xt是在时间步t从该序列中观察到的实际词元。这使得不同长度的文档的性能具有了可比性。由于历史原因,自然语言处理的科学家更喜欢使用一个叫做**困惑度(perplexity)**的量。简而言之,它是之前公式的指数:
exp ( − 1 n ∑ t = 1 n log P ( x t ∣ x t − 1 , … , x 1 ) ) \exp \left(-\frac{1}{n} \sum_{t=1}^{n} \log P\left(x_{t} \mid x_{t-1}, \ldots, x_{1}\right)\right) exp(−n1t=1∑nlogP(xt∣xt−1,…,x1))
困惑度的最好的理解是“下一个词元的实际选择数的调和平均数.
通过时间反向传播(BPTT)
循环神经网络的梯度分析
在这个简化模型中,我们将时间步t的隐状态表示为ht,输入表示为Xt,输出表示为0t。输入和隐状态可以拼接后与隐藏层中的一个权重变量相乘。因此,我们分别使用wh和w0。来表示隐藏层和输出层的权重。每个时间步的隐状态和输出可以写为:
h t = f ( x t , h t − 1 , w h ) , o t = g ( h t , w o ) , \begin{aligned} h_{t} & =f\left(x_{t}, h_{t-1}, w_{h}\right), \\ o_{t} & =g\left(h_{t}, w_{o}\right), \end{aligned} htot=f(xt,ht−1,wh),=g(ht,wo),
然后通过一个目标函数在所有T个时间步内 评估输出ot和对应的标签y之间的差异:
L ( x 1 , … , x T , y 1 , … , y T , w h , w o ) = 1 T ∑ t = 1 T l ( y t , o t ) L\left(x_{1}, \ldots, x_{T}, y_{1}, \ldots, y_{T}, w_{h}, w_{o}\right)=\frac{1}{T} \sum_{t=1}^{T} l\left(y_{t}, o_{t}\right) L(x1,…,xT,y1,…,yT,wh,wo)=T1t=1∑Tl(yt,ot)
∂ L ∂ w h = 1 T ∑ t = 1 T ∂ l ( y t , o t ) ∂ w h = 1 T ∑ t = 1 T ∂ l ( y t , o t ) ∂ o t ∂ g ( h t , w o ) ∂ h t ∂ h t ∂ w h . \begin{aligned} \frac{\partial L}{\partial w_{h}} & =\frac{1}{T} \sum_{t=1}^{T} \frac{\partial l\left(y_{t}, o_{t}\right)}{\partial w_{h}} \\ & =\frac{1}{T} \sum_{t=1}^{T} \frac{\partial l\left(y_{t}, o_{t}\right)}{\partial o_{t}} \frac{\partial g\left(h_{t}, w_{o}\right)}{\partial h_{t}} \frac{\partial h_{t}}{\partial w_{h}} . \end{aligned} ∂wh∂L=T1t=1∑T∂wh∂l(yt,ot)=T1t=1∑T∂ot∂l(yt,ot)∂ht∂g(ht,wo)∂wh∂ht.
∂ h t ∂ w h = ∂ f ( x t , h t − 1 , w h ) ∂ w h + ∂ f ( x t , h t − 1 , w h ) ∂ h t − 1 ∂ h t − 1 ∂ w h . \frac{\partial h_{t}}{\partial w_{h}}=\frac{\partial f\left(x_{t}, h_{t-1}, w_{h}\right)}{\partial w_{h}}+\frac{\partial f\left(x_{t}, h_{t-1}, w_{h}\right)}{\partial h_{t-1}} \frac{\partial h_{t-1}}{\partial w_{h}} . ∂wh∂ht=∂wh∂f(xt,ht−1,wh)+∂ht−1∂f(xt,ht−1,wh)∂wh∂ht−1.
∂ h t ∂ w h = ∂ f ( x t , h t − 1 , w h ) ∂ w h + ∑ i = 1 t − 1 ( ∏ j = i + 1 t ∂ f ( x j , h j − 1 , w h ) ∂ h j − 1 ) ∂ f ( x i , h i − 1 , w h ) ∂ w h . \frac{\partial h_{t}}{\partial w_{h}}=\frac{\partial f\left(x_{t}, h_{t-1}, w_{h}\right)}{\partial w_{h}}+\sum_{i=1}^{t-1}\left(\prod_{j=i+1}^{t} \frac{\partial f\left(x_{j}, h_{j-1}, w_{h}\right)}{\partial h_{j-1}}\right) \frac{\partial f\left(x_{i}, h_{i-1}, w_{h}\right)}{\partial w_{h}} . ∂wh∂ht=∂wh∂f(xt,ht−1,wh)+i=1∑t−1(j=i+1∏t∂hj−1∂f(xj,hj−1,wh))∂wh∂f(xi,hi−1,wh).
虽然我们可以使用链式法则递归地计算, 但当t很大时这个链就会变得很长。 我们需要想想办法来处理这一问题.
时间反向传播的细节
L = 1 T ∑ t = 1 T l ( o t , y t ) L=\frac{1}{T} \sum_{t=1}^{T} l\left(\mathbf{o}_{t}, y_{t}\right) L=T1t=1∑Tl(ot,yt)
首先引出用来举例的计算图模型。

忽略偏置b结合RNN的计算规则得出一下的式子
h t = W h x x t + W h h h t − 1 o t = W q h h t \begin{array}{l} \mathbf{h}_{t}=\mathbf{W}_{h x} \mathbf{x}_{t}+\mathbf{W}_{h h} \mathbf{h}_{t-1} \\ \mathbf{o}_{t}=\mathbf{W}_{q h} \mathbf{h}_{t} \end{array} ht=Whxxt+Whhht−1ot=Wqhht
模型参数是 Whh Whx和Wqh通常,训练该模型需要对这些参数进行梯度计
∂ L / ∂ W h x 、 ∂ L / ∂ W h h 和 ∂ L / ∂ W q h \partial L / \partial \mathbf{W}_{h x} \text { 、 } \partial L / \partial \mathbf{W}_{h h} \text { 和 } \partial L / \partial \mathbf{W}_{q h} ∂L/∂Whx 、 ∂L/∂Whh 和 ∂L/∂Wqh
对Ot(O1,O2,O3)求一次偏导得到:
∂ L ∂ o t = ∂ l ( o t , y t ) T ⋅ ∂ o t ∈ R q . \frac{\partial L}{\partial \mathbf{o}_{t}}=\frac{\partial l\left(\mathbf{o}_{t}, y_{t}\right)}{T \cdot \partial \mathbf{o}_{t}} \in \mathbb{R}^{q} . ∂ot∂L=T⋅∂ot∂l(ot,yt)∈Rq.
计算目标函数关于输出层中参数Wqh的梯度
∂ L ∂ W q h = ∑ t = 1 T prod ( ∂ L ∂ o t , ∂ o t ∂ W q h ) = ∑ t = 1 T ∂ L ∂ o t h t ⊤ , \frac{\partial L}{\partial \mathbf{W}_{q h}}=\sum_{t=1}^{T} \operatorname{prod}\left(\frac{\partial L}{\partial \mathbf{o}_{t}}, \frac{\partial \mathbf{o}_{t}}{\partial \mathbf{W}_{q h}}\right)=\sum_{t=1}^{T} \frac{\partial L}{\partial \mathbf{o}_{t}} \mathbf{h}_{t}^{\top}, ∂Wqh∂L=t=1∑Tprod(∂ot∂L,∂Wqh∂ot)=t=1∑T∂ot∂Lht⊤,
接下来对ht进行求导结合RNN循环的性质来进行计算
∂ L ∂ h t = prod ( ∂ L ∂ h t + 1 , ∂ h t + 1 ∂ h t ) + prod ( ∂ L ∂ o t , ∂ o t ∂ h t ) = W h h ⊤ ∂ L ∂ h t + 1 + W q h ⊤ ∂ L ∂ o t \frac{\partial L}{\partial \mathbf{h}_{t}}=\operatorname{prod}\left(\frac{\partial L}{\partial \mathbf{h}_{t+1}}, \frac{\partial \mathbf{h}_{t+1}}{\partial \mathbf{h}_{t}}\right)+\operatorname{prod}\left(\frac{\partial L}{\partial \mathbf{o}_{t}}, \frac{\partial \mathbf{o}_{t}}{\partial \mathbf{h}_{t}}\right)=\mathbf{W}_{h h}^{\top} \frac{\partial L}{\partial \mathbf{h}_{t+1}}+\mathbf{W}_{q h}^{\top} \frac{\partial L}{\partial \mathbf{o}_{t}} ∂ht∂L=prod(∂ht+1∂L,∂ht∂ht+1)+prod(∂ot∂L,∂ht∂ot)=Whh⊤∂ht+1∂L+Wqh⊤∂ot∂L
由于通过时间反向传播是反向传播在循环神经网络中的应用方式, 所以训练循环神经网络交替使用前向传播和通过时间反向传播。 通过时间反向传播依次计算并存储上述梯度。 具体而言,存储的中间值会被重复使用,以避免重复计算
∂ L ∂ W h x = ∑ t = 1 T prod ( ∂ L ∂ h t , ∂ h t ∂ W h x ) = ∑ t = 1 T ∂ L ∂ h t x t ⊤ ∂ L ∂ W h h = ∑ t = 1 T prod ( ∂ L ∂ h t , ∂ h t ∂ W h h ) = ∑ t = 1 T ∂ L ∂ h t h t − 1 ⊤ \begin{aligned} \frac{\partial L}{\partial \mathbf{W}_{h x}} & =\sum_{t=1}^{T} \operatorname{prod}\left(\frac{\partial L}{\partial \mathbf{h}_{t}}, \frac{\partial \mathbf{h}_{t}}{\partial \mathbf{W}_{h x}}\right)=\sum_{t=1}^{T} \frac{\partial L}{\partial \mathbf{h}_{t}} \mathbf{x}_{t}^{\top} \\ \frac{\partial L}{\partial \mathbf{W}_{h h}} & =\sum_{t=1}^{T} \operatorname{prod}\left(\frac{\partial L}{\partial \mathbf{h}_{t}}, \frac{\partial \mathbf{h}_{t}}{\partial \mathbf{W}_{h h}}\right)=\sum_{t=1}^{T} \frac{\partial L}{\partial \mathbf{h}_{t}} \mathbf{h}_{t-1}^{\top} \end{aligned} ∂Whx∂L∂Whh∂L=t=1∑Tprod(∂ht∂L,∂Whx∂ht)=t=1∑T∂ht∂Lxt⊤=t=1∑Tprod(∂ht∂L,∂Whh∂ht)=t=1∑T∂ht∂Lht−1⊤