DiffIR论文阅读笔记
2026/3/13 2:45:32
来源:https://blog.csdn.net/weixin_44326452/article/details/139287341
浏览:
次
关键词:DiffIR论文阅读笔记
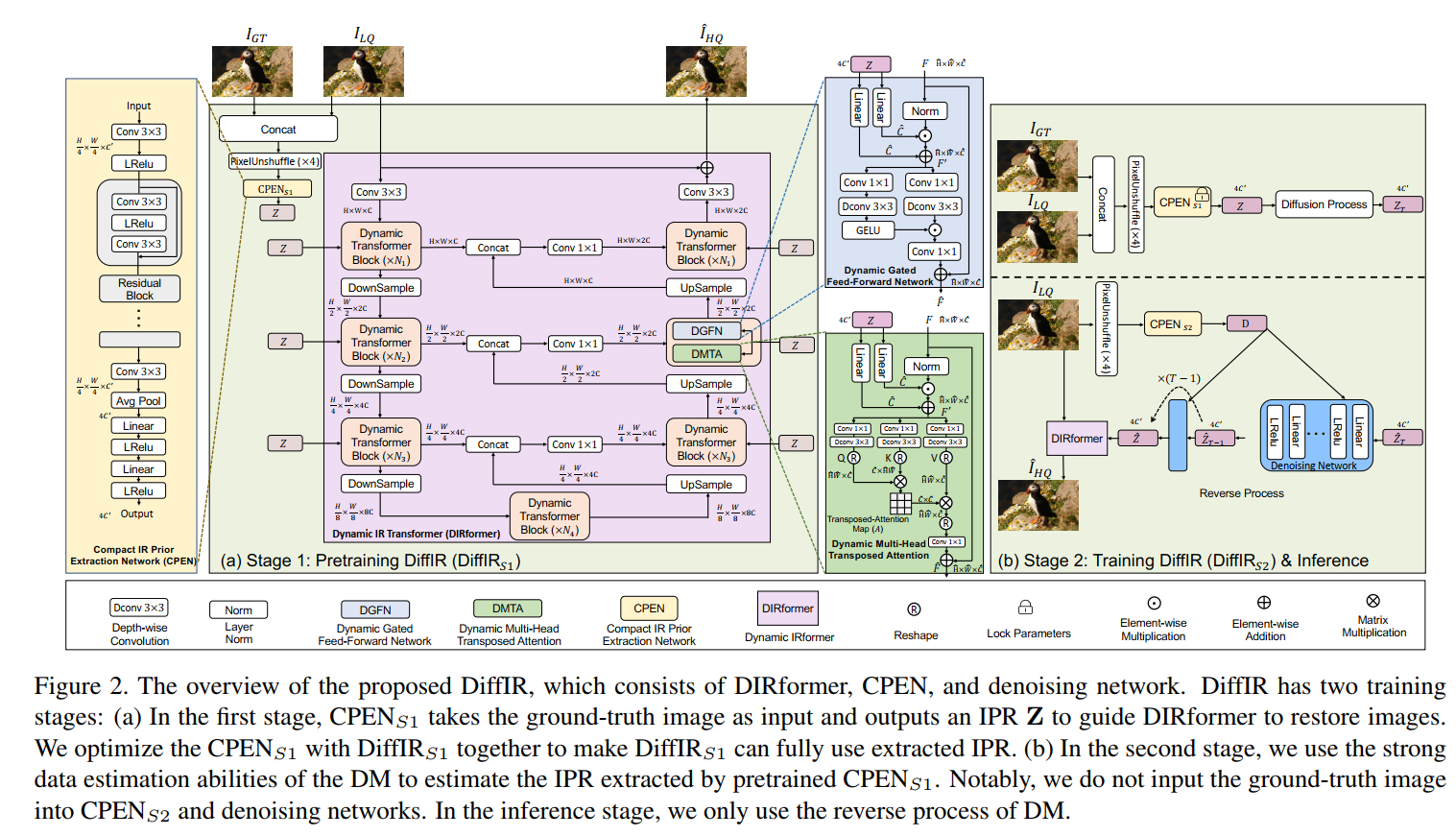
ICCV2023的一篇用diffusion模型做Image Restoration的论文,一作是清华的教授,还在NIPS2023上一作发表了Hierarchical Integration Diffusion Model for Realistic Image Deblurring,作者里甚至有Luc Van Gool大佬。 模型分三个部分,一个是CPEN用来提取IPR,一个是DIRformer,用来完成restoration任务,一个是denoising network,用diffusion的方式来预测IPR。分两阶段训练,第一阶段先train CPEN和DIRformer,第二阶段再train denoising network。如此看来其实思想和stable diffusion很像,就是不在图像域上diffusion,这样size太大而且step太多,而是在特征域上diffusion,本文就是在IPR上diffusion
方法的细节上图都有。首先CPEN是一个从输入和GT的concatenate中提取一维向量,用这个一维向量参与到用于restoration的transformer中的channel-wise调制过程。第一阶段是这个restoration network和这个CPEN的联合训练,损失是restoration结果和GT之间的L1损失。这里引进GT是为了这个向量能提取得更好一点,从而使得整个过程的PSNR更高一点。 但实际应用中我们不可能有GT来作为输入,所以第二阶段我们需要train一个diffusion model来从LQ图片中预测z。这里diffusion还是老一套,认为一阶段train好的CPEN提取的z是x0,然后加噪到xt,reverse的过程就是从xt去噪预测x0的过程。diffusion模型的输入由3部分组成,首先当然是上一步的Zt,然后是t,接着是作为条件输入的D,这个D是用一个新的CPEN从LQ中提取的,称为CPEN2,他和第一阶段的CPEN在网络结构上是一样的(除了输入层)。这个很好理解,如果没有D作为条件,那不就相当于要diffusion模型从噪声预测一个z出来,那这个z当然和input无关,所以需要额外添加一个D作为条件,这也是很多用diffusion做restoration的思路。第二阶段需要混合训练CPEN2,denoising network和restoration network,损失函数是restoration结果 和GT之间的L1损失,以及diffusion预测的IPR和第一阶段的CPEN预测的IPR之间的L1损失。 感觉这个工作怪怪的,restoraion一般比较关注的去噪没有做,居然做了inpainting。选的三个任务是超分,inpainting和deblurring这三个任务。此外,这个IPR向量仅仅是通道调制,在我看来更多可能影响风格信息,用diffusion模型来预测这个IPR向量真的有必要吗?对这个工作实际效果持怀疑态度,到时候跑代码看一下。
版权声明:
本网仅为发布的内容提供存储空间,不对发表、转载的内容提供任何形式的保证。凡本网注明“来源:XXX网络”的作品,均转载自其它媒体,著作权归作者所有,商业转载请联系作者获得授权,非商业转载请注明出处。
我们尊重并感谢每一位作者,均已注明文章来源和作者。如因作品内容、版权或其它问题,请及时与我们联系,联系邮箱:809451989@qq.com ,投稿邮箱:809451989@qq.com