❝自胜者强
大家好,我是柒八九。一个专注于前端开发技术/Rust及AI应用知识分享的Coder
❝此篇文章所涉及到的技术有
WebAssemblyRustAI模型(自训练模型) onnx OCR( 自适应灰度化处理/对比度增强/自适应二值化)tesseract Vite+React/Vue(下面的内容,在各种前端框架中都用)
因为,行文字数所限,有些概念可能会一带而过亦或者提供对应的学习资料。请大家酌情观看。
前言
❝中秋已经过了,国庆还会远吗?!
最近,我们用两篇文章讲述了,我在开发过程中如何使用Rust来处理一些之前在前端不好处理的需求。
-
Rust 赋能前端:PDF 分页/关键词标注/转图片/抽取文本/抽取图片/翻转...:在里面介绍如何在前端环境中( React/Vue)中使用Mupdf,用于执行各种PDF的操作。 -
Rust 赋能前端: 视频抽帧:在里面介绍如何在前端环境中( React/Vue)中对视频资源进行抽帧处理。
而今天我们基于之前的内容,也就是Rust 赋能前端: 视频抽帧做更近一步的处理。
之前,我们将一个视频资源解析成了一组图片资源。

然后,我们需要对每个图片资源中的文本进行关键词标注,通俗点来讲就是先对图片做OCR[1]处理,然后基于识别出的文本信息,比对关键词信息,如果OCR识别出的信息中存在关键词那么就对这些信息做标注。
效果展示
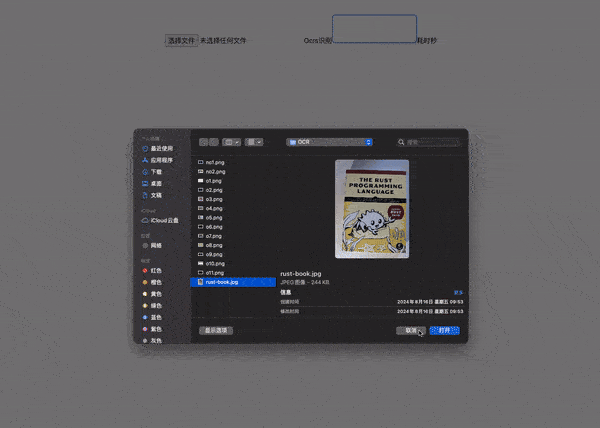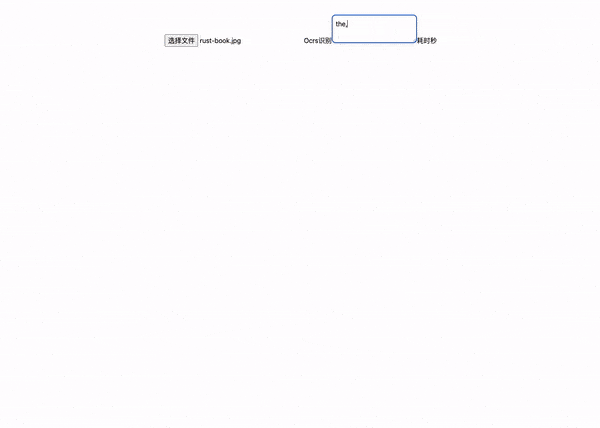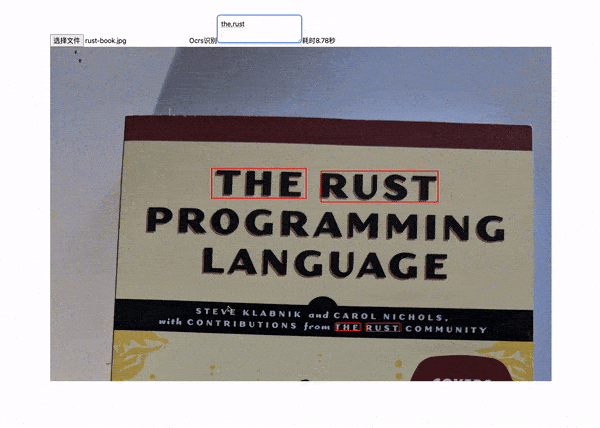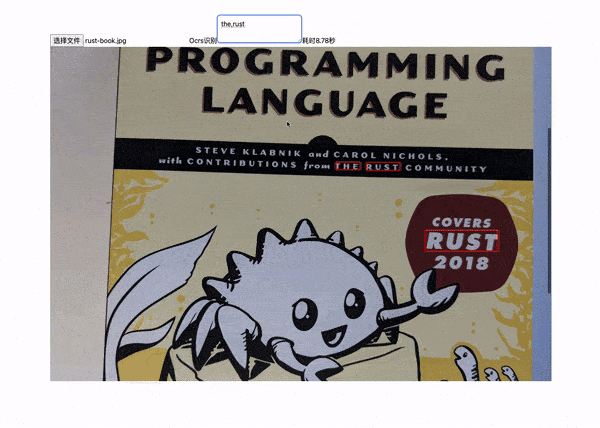
从上面的gif中我们可以看到,我们在textarea中输入关键字信息(the/rust),然后在等待(7-8秒)后,就会将图片中的关键字信息进行标注处理了。
然后,我们还能识别非常规排版的文字信息。 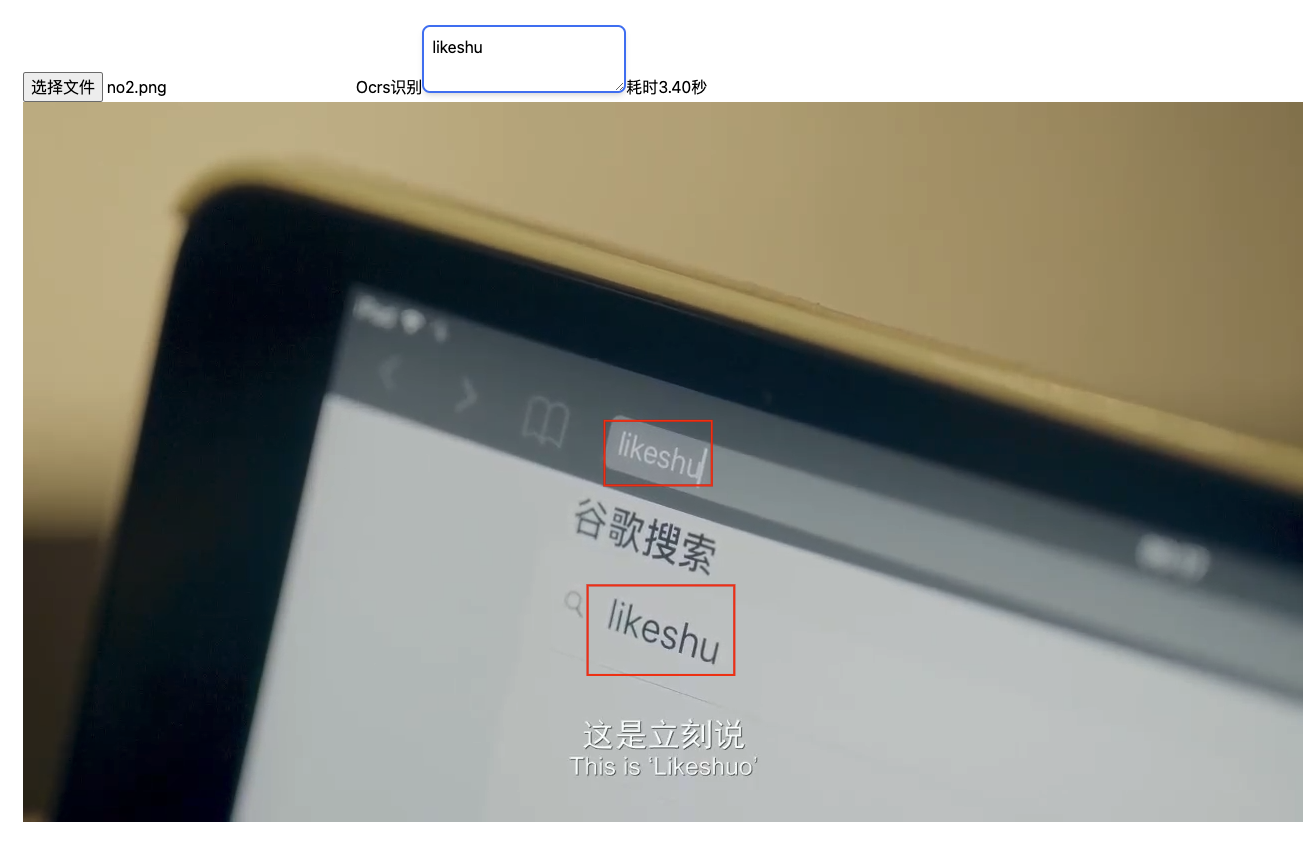 上图中,
上图中,likeshu不是一个正常的排版,而是有一定的倾斜度,但是我们还是可以识别出来。
好了,天不早了,干点正事哇。

我们能所学到的知识点
❝
项目初始化 技术选择的初衷 Rust+WebAssembly+AI模型实现OCR前端项目中引入编译好的 WebAssembly
1. 项目初始化
还是一样的套路,我们还是基于f_cli_f[2]来构建的前端Vite+React+TS项目。
当我们通过yarn/npm安装好对应的包时。我们就可以在pages新建一个Ocr的目录。
-
构建一个 index.tsx用于存放主要的代码逻辑 -
构建一个 models用于存放 模型文件
├── index.tsx
├── models
├── detection.rten
└── recognition.rten
随后,我们在src目录下构建一个wasm目录来存放在前端项目中要用到的各种wasm。针对这个例子,我们构建一个ocr的目录,用于存放Rust编译后的文件。
2. 技术选择的初衷
❝不以解决问题为目的技术尝试都是耍流氓
这就不得不提一下,我们的应用场景了,我们业务主要是处理英文文本资源或者更宽泛的说,主要是处理拉丁语系的文本。也就是我们不需要考虑中文/韩文/日文等语言。
正如标题所说,我们如果要在前端执行OCR,我们一般选择tesseract[3],也就是tesseract.js[4]。
其实,刚开始呢,我们也是选用tesseract.js,但是呢在执行过程中发现,有些图片资源或者场景,它的识别度不尽人意。

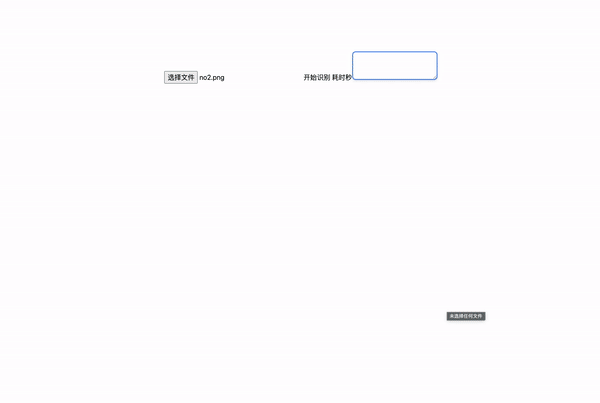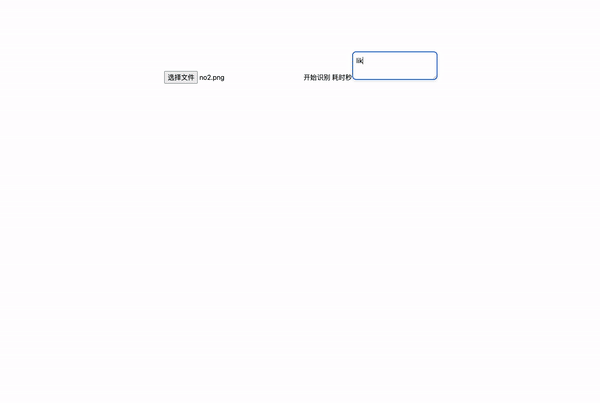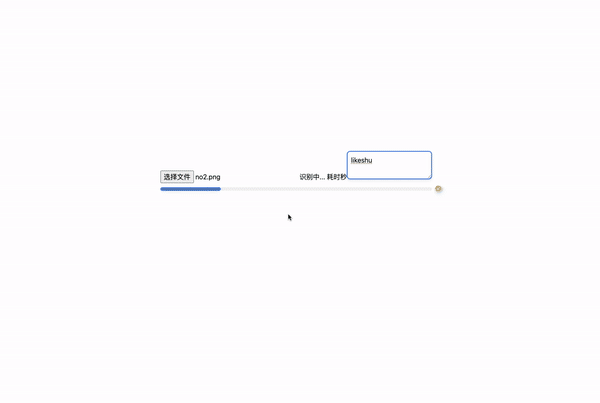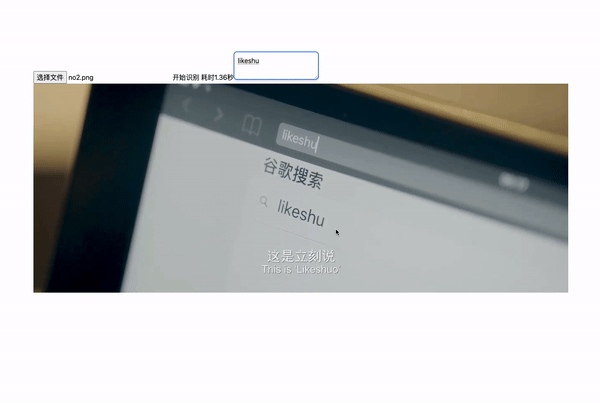
❝由于我们对识别精度有一定的要求,像上面这种情况就达不到我们业务需求,所以我们就需要另辟蹊径。
使用tesseract实现OCR
❝虽然,
tesseract在某种场景上不满足我们的业务需求,但是如果大家在平时开发中也用到类似的OCR识别,并且精度要求不是很高,它还是一种很好的解决方案。
所以,我们用一个小节来讲讲如何使用tesseract做OCR
我们在Ocr的目录下,新建一个ocrServeice.ts文件。
图像预处理
const preprocessImage = (image: File): Promise<string> => {
return new Promise((resolve, reject) => {
const canvas = document.createElement('canvas');
const ctx = canvas.getContext('2d');
const img = new Image();
img.src = typeof image === 'string' ? image : URL.createObjectURL(image);
img.onload = () => {
// 设置canvas大小与图片一致
canvas.width = img.width;
canvas.height = img.height;
// 绘制图片到canvas
ctx?.drawImage(img, 0, 0);
let imageData = ctx?.getImageData(0, 0, canvas.width, canvas.height);
const data = imageData?.data;
if (data) {
// 1. 自适应灰度化处理
imageData = adaptiveGrayscale(imageData);
// 2. 对比度增强
imageData = enhanceContrast(imageData, 1.5);
// 3. 自适应二值化
imageData = adaptiveBinarize(imageData);
// 3. 将处理后的图像数据重新绘制到Canvas上
ctx.putImageData(imageData, 0, 0);
}
resolve(canvas.toDataURL());
};
img.onerror = reject;
});
};
在处理图片资源时,我们用到了自适应灰度化/对比度增强/自适应二值化的简单版本。
自适应灰度化/对比度增强/自适应二值化
// 灰度化算法:加权灰度化
const adaptiveGrayscale = (imageData: ImageData): ImageData => {
const data = imageData.data;
for (let i = 0; i < data.length; i += 4) {
// 使用加权公式,更符合人眼感知的亮度
const gray = 0.3 * data[i] + 0.5 * data[i + 1] + 0.2 * data[i + 2];
data[i] = data[i + 1] = data[i + 2] = gray;
}
return imageData;
};
// 对比度增强
const enhanceContrast = (imageData: ImageData, factor: number = 1.2): ImageData => {
const data = imageData.data;
for (let i = 0; i < data.length; i += 4) {
data[i] = Math.min(255, data[i] * factor); // 对R通道增强对比度
data[i + 1] = Math.min(255, data[i + 1] * factor); // 对G通道增强对比度
data[i + 2] = Math.min(255, data[i + 2] * factor); // 对B通道增强对比度
}
return imageData;
};
// 二值化处理
const adaptiveBinarize = (imageData: ImageData, threshold: number = 128): ImageData => {
const data = imageData.data;
for (let i = 0; i < data.length; i += 4) {
const gray = data[i]; // 因为之前已经灰度化了,所以 R=G=B
const value = gray >= threshold ? 255 : 0; // 根据阈值进行二值化
data[i] = data[i + 1] = data[i + 2] = value;
}
return imageData;
};
使用Tesseract处理图片
export const performOCRWithKeywords = async (image: File, keywords: string[],setProgress:(number)=>void):Promise<KeywordMatch[]> => {
try {
// 先进行图像预处理
const preprocessedImage = await preprocessImage(image);
const result = await Tesseract.recognize(
preprocessedImage,
'eng', // 自定义语言包,英文
{
logger: m => {
console.log(m);
if (m.status === 'recognizing text') {
setProgress(Math.floor(m.progress*100));
}
},
}
);
const { text, words } = result.data;
const matches = [];
words.forEach((word) => {
if (keywords.includes(word.text)) {
matches.push({
keyword: word.text,
position: word.bbox, // 获取关键词的位置信息
});
}
});
return new Promise((resolve) => resolve(matches));
} catch (err) {
console.error('OCR failed:', err);
throw err;
}
};
题外话
上面代码中我们使用了tesseract.js在前端实现ocr识别。如果仔细翻看文档的化,就会看到如下的描述。

也就是tesseract.js封装了tesseract的webassembly版本。
当我们翻看tesseract.js源码,也能印证上面的信息。
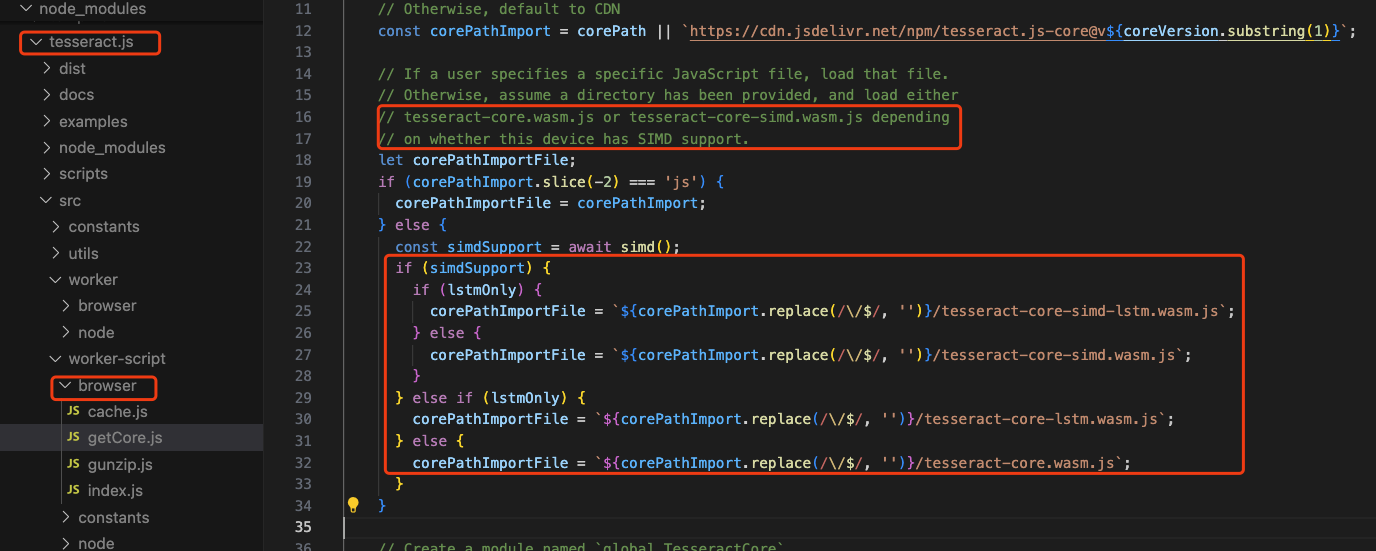
其中,有一个概念叫做SIMD[5]也是一种WebAssembly的优化方案。这个我们后期有机会,单写一篇。
❝
WebAssembly无处不在
3. Rust+WebAssembly+AI模型实现OCR
既然,常规方式不满足我们的要求,那么我们就需要看看其他语言是否有成熟的解决方案,然后将其编译成WebAssembly在浏览器环境中使用。
功夫不负有心人。
还真让我们找到了。那就是ocrs[6]。
啥是ocrs
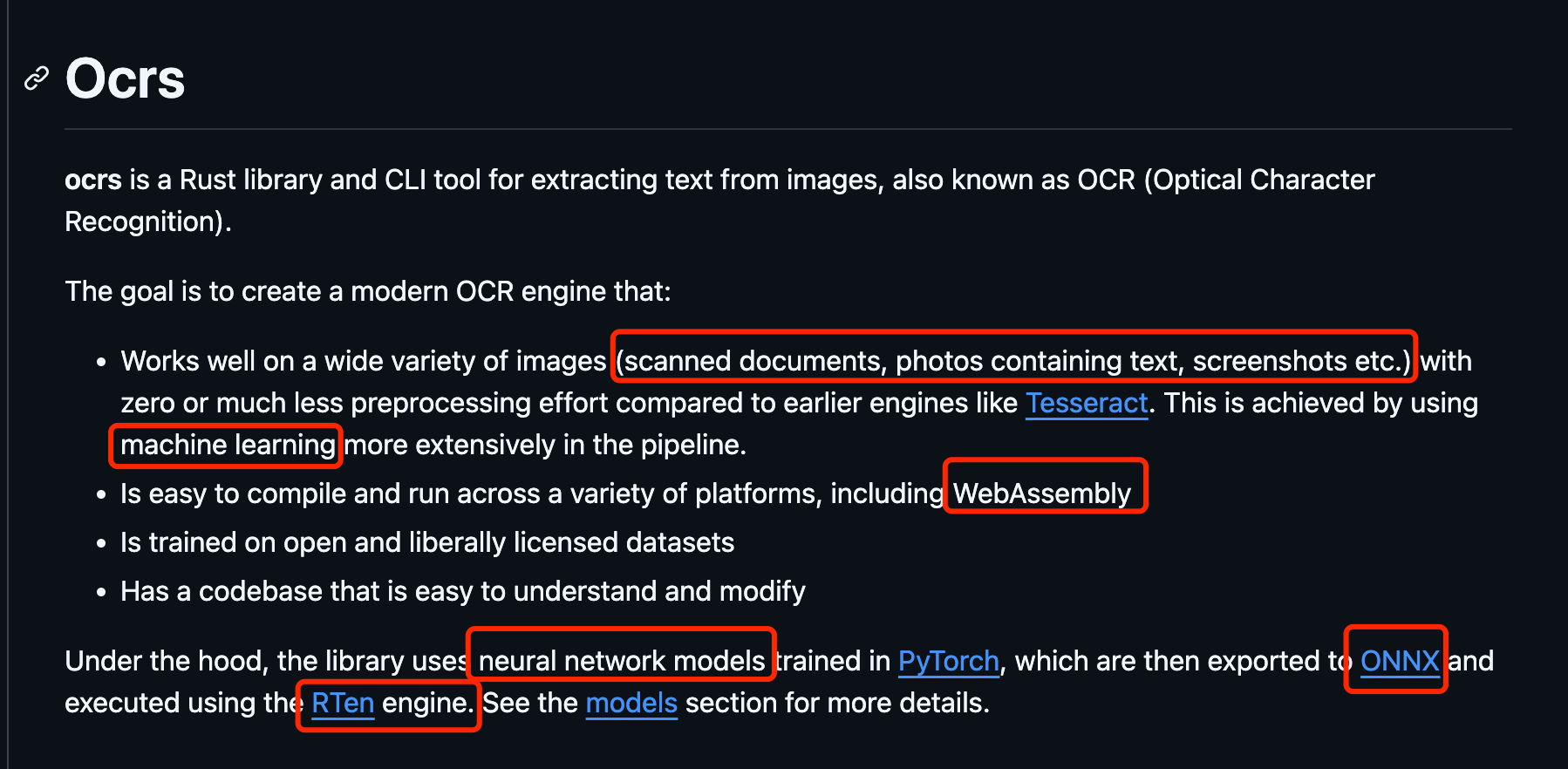
这是其官网的介绍说明。就像图片中标注的那样,它有几点让人动容的点。
-
它可以很好地处理各种图像(扫描文档、包含文本的照片、屏幕截图等) -
机器学习/模型训练 -
易于编译并运行在各种平台上,包括 WebAssembly
ocrs模型
我们可以在ocrs模型[7]找到相关介绍。
OCRS 引擎将文本检测和识别分为三个阶段
-
文本检测:这是一种 语义分割模型,它将灰度输入图像中的每个像素分类为``文本/非文本`。然后,消费者对文本像素集群进行后处理,以获得单词的定向边界框。 -
布局分析:这是一个 图形模型,它将单词边界框作为输入节点,并对每个节点与附近节点的关系进行分类(例如,行的开始 / 中间 / 结束) -
文本识别:这是一个 CRNN 模型,它将文本行的灰度图像作为输入并返回一系列字符。
所有模型均可导出至 ONNX 以供下游使用。
❝开放神经网络交换 (
ONNX)是一个开放的生态系统,它使 AI 开发人员能够随着项目的发展选择合适的工具。ONNX为 AI 模型(包括深度学习和传统机器学习)提供了一种开源格式。它定义了一个可扩展的计算图模型,以及内置运算符和标准数据类型的定义。
模型下载
使用ocrs时,它已经为我们提供了已经训练好的模型了。我们可以在huggingface[8]中进行下载。
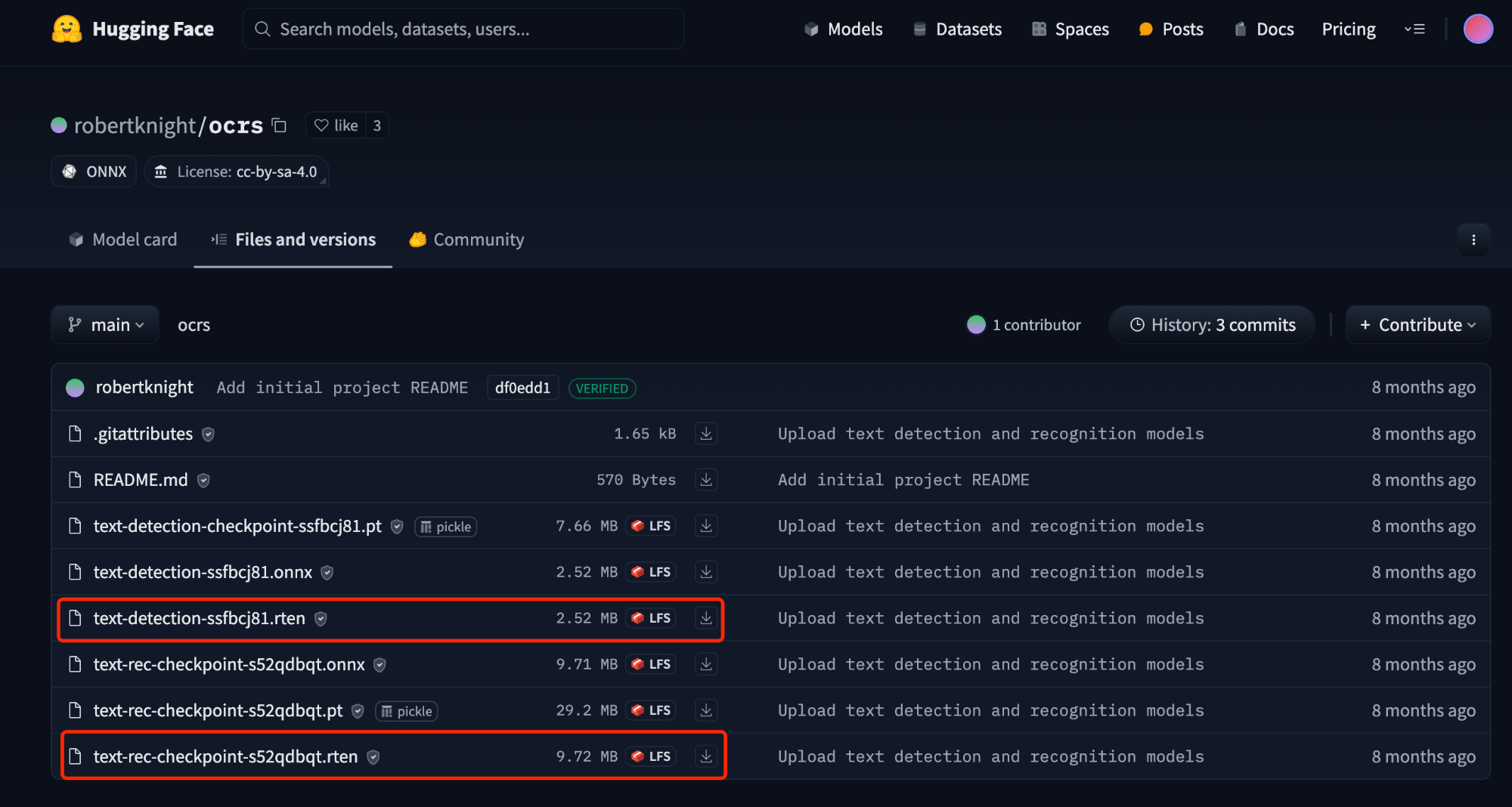
下载完的模型,我们可以将其放置到之前项目中models文件下。(文件名称也修改一下)
❝由于
huggingface在国内环境不稳定,如果大家在下载过程中遇到问题,可以直接私聊,找我要资源。
亦或者我们可以通过下面的链接进行模型下载
-
text-detection.rten地址 [9] -
text-recognition.rten地址 [10]
当然,我们也可以训练自己的模型[11]。由于篇幅有限,这里就不展开说明了。
新建Rust项目
由于ocrs提供了三种方式可供使用。
-
在rust环境通过cargo add 添加到其他库中 -
ocr_cli 下载到本地,在cli中使用 -
编译成WebAssembly在 JS环境中使用
我们今天的主要目标就是把ocrs编译成WebAssembly在浏览器中使用。
但是呢,我们还是要新建一个Rust项目,因为在实际应用过程中,我们发现它之前的代码还有改进空间亦或者说是我们还可以对其功能进行丰富。
话不多说,直接开干。
使用cargo new --lib ocr_project构建一个新的Rust项目。
然后我们Caro.toml中新添如下内容。
[package]
name = "ocr_project"
version = "0.1.0"
edition = "2021"
[dependencies]
anyhow = "1.0.80"
rayon = "1.10.0"
rten = { version = "0.12.0" }
rten-imageproc = { version = "0.12.0" }
rten-tensor = { version = "0.12.0" }
thiserror = "1.0.59"
[target.'cfg(target_arch = "wasm32")'.dependencies]
wasm-bindgen = "0.2.92"
[dev-dependencies]
fastrand = "2.1.0"
image = { version = "0.25.1", default-features = false, features = ["png", "jpeg", "webp"] }
lexopt = "0.3.0"
[lib]
crate-type = ["lib", "cdylib"]
[features]
avx512 = ["rten/avx512"]
在src的文件内容呢,还是和ocrs中的一致,我们直接cv即可。在终端使用tree看目录结构如下
├── Cargo.toml
├── README.md
└── src
├── detection.rs
├── errors.rs
├── geom_util.rs
├── layout_analysis
│ └── empty_rects.rs
├── layout_analysis.rs
├── lib.rs
├── log.rs
├── preprocess.rs
├── recognition.rs
├── test_util.rs
├── text_items.rs
└── wasm_api.rs
之前不是说,我们需要对其代码做一次内容新增吗。让其能够满足我们的业务需求。
修改wasm_api.rs内容
在wasm_api.rs中有一个OcrEngine结构体。它是主要为图片识别抛出很多方法。
#[wasm_bindgen]
impl OcrEngine {
/// 使用 `init` 提供的模型和其他设置构建一个新的 `OcrEngine`。
///
/// 要检测图像中的文本,`init` 必须设置检测模型。
/// 要识别文本,`init` 必须设置识别模型。
#[wasm_bindgen(constructor)]
pub fn new(init: OcrEngineInit) -> Result<OcrEngine, String> {
// 省去代码
}
/// 准备 OCR 引擎分析的图像。
///
/// 图像是一个按行优先排列的像素数组。支持的通道组合为 RGB 和 RGBA。
/// 通道数由 `data` 的长度推断。
#[wasm_bindgen(js_name = loadImage)]
pub fn load_image(&self, width: u32, height: u32, data: &[u8]) -> Result<Image, String> {
// 省去代码
}
/// 检测图像中的文本。
///
/// 返回找到的文本行列表。这些可以传递给 `recognizeText` 识别字符。
#[wasm_bindgen(js_name = detectText)]
pub fn detect_text(&self, image: &Image) -> Result<Vec<DetectedLine>, String> {
// 省去代码
}
#[wasm_bindgen(js_name = recognizeText)]
pub fn recognize_text(
&self,
image: &Image,
lines: Vec<DetectedLine>
) -> Result<Vec<TextLine>, String> {
// 省去代码
}
#[wasm_bindgen(js_name = getText)]
pub fn get_text(&self, image: &Image) -> Result<String, String> {
// 省去代码
}
#[wasm_bindgen(js_name = getTextLines)]
pub fn get_text_lines(&self, image: &Image) -> Result<Vec<TextLine>, String> {
// 省去代码
}
#[wasm_bindgen(js_name = getWords)]
pub fn get_words(&self, image: &Image) -> Result<Vec<RotatedRect>, String> {
// 省去代码
}
}
从上面结构中,我们可以看出OcrEngine导出了很多方法。例如getWords/getTextLines/getText/recognizeText/loadImage。
乍一看去,确实为我们提供了图片识别的功能。但是呢,如果真正的在前端使用过程中,发现它只是基于图片做了文本识别。我们现在想把基于关键字比对并且返回对应的位置信息的操作也糅合到里面。
这就需要我们基于上面的内容做一次内容的新增。
pub fn find_keyword_position(
&self,
image: &Image,
keywords: Vec<String>
) -> Result<Vec<TextWord>, String> {
// 检测图像中的单词
let words = self.engine.detect_words(&image.input).map_err(|e| e.to_string())?;
// 找到图像中的文本行
let lines = self.engine.find_text_lines(&image.input, &words);
// 识别文本行
let text_lines = self.engine
.recognize_text(&image.input, &lines)
.map_err(|e| e.to_string())?;
// 存储匹配的关键词及其位置信息
let mut key_words_position = Vec::new();
for line in text_lines {
if let Some(line) = line {
let matched_words: Vec<TextWord> = line
.words()
.filter(|w| {
let word_text = w.to_string().to_lowercase();
keywords.iter().any(|k| word_text.to_lowercase().contains(k))
})
.map(|w| TextWord {
text: w.to_string(),
rect: RotatedRect {
rect: w.rotated_rect(),
},
})
.collect();
key_words_position.push(matched_words);
}
}
Ok(key_words_position.concat())
}
看代码,我们是利用了self.engine的detect_words/find_text_lines/recognize_text返回的数据信息,又做了一次信息加工。
而engine的初始化就是刚才的
/// 从给定的配置中构造一个新的引擎。
pub fn new(params: OcrEngineParams) -> anyhow::Result<OcrEngine> {
let detector = params.detection_model
.map(|model| TextDetector::from_model(model, Default::default()))
.transpose()?;
let recognizer = params.recognition_model.map(TextRecognizer::from_model).transpose()?;
Ok(OcrEngine {
detector,
recognizer,
debug: params.debug,
decode_method: params.decode_method,
})
}
OcrEngine真正定义位置
这里多说几句,OcrEngine是在lib.rs中定义的。
impl OcrEngine {
/// 从给定的配置中构造一个新的引擎。
pub fn new(params: OcrEngineParams) -> anyhow::Result<OcrEngine> {
let detector = params.detection_model
.map(|model| TextDetector::from_model(model, Default::default()))
.transpose()?;
let recognizer = params.recognition_model.map(TextRecognizer::from_model).transpose()?;
Ok(OcrEngine {
detector,
recognizer,
debug: params.debug,
decode_method: params.decode_method,
})
}
/// 预处理图像以便与引擎的其他方法一起使用。
pub fn prepare_input(&self, image: ImageSource) -> anyhow::Result<OcrInput> {
Ok(OcrInput {
image: prepare_image(image),
})
}
/// 在图像中检测文本单词。
///
/// 返回每个找到的单词的有向边界矩形的无序列表。
pub fn detect_words(&self, input: &OcrInput) -> anyhow::Result<Vec<RotatedRect>> {
if let Some(detector) = self.detector.as_ref() {
detector.detect_words(input.image.view(), self.debug)
} else {
Err(anyhow!("检测模型未加载"))
}
}
/// 在图像中检测文本像素。
///
/// 返回 (H, W) 张量,表示输入中每个像素属于文本单词的概率。
/// 这是一个底层 API,对调试非常有用。
/// 使用 [detect_words](OcrEngine::detect_words "detect_words") 获取返回单词有向边界矩形的高级 API。
pub fn detect_text_pixels(&self, input: &OcrInput) -> anyhow::Result<NdTensor<f32, 2>> {
if let Some(detector) = self.detector.as_ref() {
detector.detect_text_pixels(input.image.view(), self.debug)
} else {
Err(anyhow!("检测模型未加载"))
}
}
/// 执行布局分析,将单词分组为行并按阅读顺序排序。
///
/// `words` 是由 [OcrEngine::detect_words] 找到的文本单词矩形的无序列表。
/// 结果是按阅读顺序排列的行列表。每行是一个按阅读顺序排列的单词边界矩形序列。
pub fn find_text_lines(
&self,
_input: &OcrInput,
words: &[RotatedRect]
) -> Vec<Vec<RotatedRect>> {
find_text_lines(words)
}
/// 识别图像中的文本行。
///
/// `lines` 是由 [OcrEngine::find_text_lines] 生成的图像中文本行框的有序列表。
///
/// 输出是与输入图像区域对应的 [TextLine] 列表。
/// 如果在某一行中未找到文本,则该行的条目可能为 `None`。
pub fn recognize_text(
&self,
input: &OcrInput,
lines: &[Vec<RotatedRect>]
) -> anyhow::Result<Vec<Option<TextLine>>> {
if let Some(recognizer) = self.recognizer.as_ref() {
recognizer.recognize_text_lines(input.image.view(), lines, RecognitionOpt {
debug: self.debug,
decode_method: self.decode_method,
})
} else {
Err(anyhow!("识别模型未加载"))
}
}
/// 准备用于输入文本行识别模型的图像。
///
/// 这个方法帮助调试识别问题,通过公开 [OcrEngine::recognize_text] 在将图像输入识别模型之前所做的预处理。
/// 使用 [OcrEngine::recognize_text] 来识别文本。
///
/// `line` 是由 [RotatedRect] 组成的文本行。
///
/// 返回值范围在 [-0.5, 0.5] 的灰度 (H, W) 图像。
pub fn prepare_recognition_input(
&self,
input: &OcrInput,
line: &[RotatedRect]
) -> anyhow::Result<NdTensor<f32, 2>> {
let Some(recognizer) = self.recognizer.as_ref() else {
return Err(anyhow!("识别模型未加载"));
};
let line_image = recognizer.prepare_input(input.image.view(), line);
Ok(line_image)
}
/// 返回应用于文本检测模型输出的置信度阈值,用以确定像素是否为文本。
pub fn detection_threshold(&self) -> f32 {
self.detector
.as_ref()
.map(|detector| detector.threshold())
.unwrap_or(TextDetectorParams::default().text_threshold)
}
/// 便捷 API,将图像中的所有文本提取为单个字符串。
pub fn get_text(&self, input: &OcrInput) -> anyhow::Result<String> {
let word_rects = self.detect_words(input)?;
let line_rects = self.find_text_lines(input, &word_rects);
let text = self
.recognize_text(input, &line_rects)?
.into_iter()
.filter_map(|line| line.map(|l| l.to_string()))
.collect::<Vec<_>>()
.join("\n");
Ok(text)
}
}
这里就真正的用到的preprocess和模型相关的内容了。
由于这个篇幅也有点长,大家可以从源码中自行寻找。如果有需要到时候,出一篇解析文章。
编译成WebAssembly
我们可以使用如下代码对Rust项目进行编译。
RUSTFLAGS="-C target-feature=+simd128" cargo build --release --target wasm32-unknown-unknown --package ocr_project
wasm-bindgen target/wasm32-unknown-unknown/release/ocr_project.wasm --out-dir js/dist/ --target web --reference-types --weak-refs
具体解释如下:
-
RUSTFLAGS="-C target-feature=+simd128" cargo build --release --target wasm32-unknown-unknown --package ocr_project-
RUSTFLAGS="-C target-feature=+simd128": 这部分设置了 Rust 编译器的标志,-C target-feature=+simd128是指启用 SIMD (Single Instruction, Multiple Data) 128-bit 特性,这可以显著提高 WebAssembly 代码的并行处理能力,尤其是在处理图像、音频或其他需要大规模数据处理的场景下。 -
cargo build --release: 使用 Rust 的包管理工具cargo进行构建,并指定--release选项,这会在优化级别更高的模式下进行编译,从而生成高性能的可执行文件。 -
--target wasm32-unknown-unknown: 指定编译目标为wasm32-unknown-unknown,即生成 WebAssembly 二进制文件(.wasm)。 -
--package ocr_project: 指定要编译的 Rust 包名为ocr_project,这是一个执行光学字符识别(OCR)功能的项目。
-
-
wasm-bindgen target/wasm32-unknown-unknown/release/ocr_project.wasm --out-dir js/dist/ --target web --reference-types --weak-refs-
wasm-bindgen:wasm-bindgen是一个工具,用来将生成的.wasm文件和 JavaScript 绑定起来,便于在 JavaScript 环境中调用 WebAssembly 函数。 -
target/wasm32-unknown-unknown/release/ocr_project.wasm: 指定生成的.wasm文件的位置,即上一步生成的 WebAssembly 二进制文件。 -
--out-dir js/dist/: 指定输出目录为js/dist/,生成的 JavaScript 文件和优化后的.wasm文件将放在该目录下。 -
--target web: 表示为 Web 环境生成绑定文件,可以在浏览器中直接使用 WebAssembly。 -
--reference-types: 启用 WebAssembly 的引用类型(reference types),这可以允许 WebAssembly 和 JavaScript 之间更高效地传递复杂类型(如对象和数组)。 -
--weak-refs: 启用 WebAssembly 的弱引用特性,弱引用可以避免内存泄漏,因为它们不阻止垃圾回收。这在处理复杂的 JavaScript 和 WebAssembly 交互时非常有用。
-
对于,如何优化Rust打包问题,我们后续还有一篇相对完整的文章,这里也不在过多解释了。
通过上面的操作,我们就在js目录下有如下的文件资源。
└── dist
├── ocr_project.d.ts
├── ocr_project.js
├── ocr_project_bg.wasm
└── ocr_project_bg.wasm.d.ts
4. 前端项目中引入编译好的WebAssembly
之前在使用f_cli_f初始化前端项目时,我们就在src下构建了wasm/ocr。在上一步呢,我们已经在Rust项目中编译好了wasm的相关资源。
那么,我们直接将其CV到前端wasm/ocr目录下即可。
对了,之前我们不是下载了两个模型吗,别忘记把他们复制到pages/Ocr/models目录下。
现在我们就来构建我们前端逻辑。
话不多说,开干。
页面结构很简单
<div>
<input type="file" accept="image/*" onChange={handleImageChange} />
<button onClick={handleOcrProcessing}>Ocrs识别</button>
<textarea ref={textRef} />
{<span>耗时{time}秒</span>}
<div >
<canvas id="ocrCanvas" />
</div>
</div>
上面handleImageChange也很简单就是收集上传的图片资源。
const handleImageChange = async (event: React.ChangeEvent<HTMLInputElement>) => {
const file = event.target.files?.[0];
if (file) {
try {
const imageData = await loadImage(file);
setImageData(imageData);
setSelectedImage(file);
} catch (error) {
console.error('Error loading image:', error);
}
}
};
其中最核心的部分就是handleOcrProcessing
const handleOcrProcessing = async () => {
if (!imageData) return;
const textEle = textRef.current;
const textValue = textEle.value;
if (!textValue) return;
// 引入模型
const detectionModelPath = new URL('./models/detection.rten', import.meta.url);
const recognitionModelPath = new URL('./models/recognition.rten', import.meta.url);
const [_, detectionModel, recognitionModel] = await Promise.all([
initOcrLib(),
fetch(detectionModelPath).then(res => res.arrayBuffer()).then(data => new Uint8Array(data)),
fetch(recognitionModelPath).then(res => res.arrayBuffer()).then(data => new Uint8Array(data)),
]);
const ocrInit = new OcrEngineInit();
// 设置模型
ocrInit.setDetectionModel(detectionModel);
ocrInit.setRecognitionModel(recognitionModel);
//初始化ocr引擎
const ocrEngine = new OcrEngine(ocrInit);
// 预处理图片
const ocrInput = ocrEngine.loadImage(imageData.width, imageData.height, imageData.data);
// 文本识别
const words = detectAndRecognizeText(ocrEngine, ocrInput);
// 关键字查询
const keywords: string[] = textValue.split(',').map(keyword => keyword.toLowerCase());
try {
const matches = [];
words.forEach((word) => {
if (keywords.includes(word.text.toLowerCase())) {
matches.push({
keyword: word.text,
position: word.rect, // 获取关键词的位置信息
});
}
});
const reader = new FileReader();
// 将识别出的关键词绘制到图片上
reader.onload = (e) => {
if (e.target?.result) {
drawBoxesOnCanvas(e.target.result as string, matches, 'ocrCanvas');
}
};
reader.readAsDataURL(selectedImage);
} catch (error) {
console.error('OCR failed:', error);
}
setTime(logTimeDelta(t0));
};
TODO
上面的代码其实还有很多优化空间
-
利用webWorker对图片进行识别处理(tesseract就是这么干的) -
返回处理进度 -
如果有需要,可以自训练模型,处理中文等语言的识别 -
...
后记
分享是一种态度。
全文完,既然看到这里了,如果觉得不错,随手点个赞和“在看”吧。

OCR: https://en.wikipedia.org/wiki/Optical_character_recognition
[2]f_cli_f: https://www.npmjs.com/package/f_cli_f
[3]tesseract: https://tesseract-ocr.github.io/tessdoc/
[4]tesseract.js: https://github.com/naptha/tesseract.js#tesseractjs
[5]SIMD: https://ftp.cvut.cz/kernel/people/geoff/cell/ps3-linux-docs/CellProgrammingTutorial/BasicsOfSIMDProgramming.html
[6]ocrs: https://github.com/robertknight/ocrs
[7]ocrs模型: https://github.com/robertknight/ocrs-models
[8]huggingface: https://huggingface.co/robertknight/ocrs
[9]text-detection.rten地址: https://ocrs-models.s3-accelerate.amazonaws.com/text-detection.rten
[10]text-recognition.rten地址: https://ocrs-models.s3-accelerate.amazonaws.com/text-recognition.rten
[11]训练自己的模型: https://github.com/robertknight/ocrs-models/blob/main/docs/training.md
本文由 mdnice 多平台发布