一. 搭建flask环境
概念
- flask:一个轻量级 Web 应用框架,被设计为简单、灵活,能够快速启动一个 Web 项目。
- CNN:深度学习模型,用于处理具有网格状拓扑结构的数据,如图像(2D网格)和视频(3D网格)。
- PyTorch:开源的机器学习库,应用于如计算机视觉和自然语言处理等领域的深度学习。
flask环境搭建操作步骤:
- pycharm终端创建新的虚拟环境:python -m venv virtualName 。
- 激活虚拟环境。
- 在虚拟环境中安装flask。
- 运行第一个前端网页。
步骤4代码:
from flask import Flask
app = Flask(__name__)@app.route('/')
def hello_world():return "<h1>hello world!</h1>"if __name__ == '__main__':app.run(debug=True)
二. 训练水果模型
水果识别CNN训练操作步骤:
- 准备数据集(kaggle官网可下载)。
- 安装pyrorch。
- 使用pytorch的nn模型定义参数。
- 训练模型。
- 得到训练好的pth模型。
步骤3代码:
import torch
from torch import nn# 水果分类模型参数配置class NumberNet(nn.Module):def __init__(self, device, classes=10):super().__init__()if device is None:device = torch.device("cpu")if torch.cuda.is_available():device = torch.device("cuda:0")self.cnn = nn.Sequential(nn.Conv2d(3, 16, 3), # 100x100 -> 98x98nn.ReLU(),nn.MaxPool2d(2, 2), # 98x98 -> 49x49nn.Conv2d(16, 32, 3, padding=1), # 49x49 -> 49x49nn.ReLU(),nn.MaxPool2d(2, 2), # 49x49 -> 24x24nn.Conv2d(32, 64, 3, padding=1), # 24x24 -> 24x24nn.ReLU(),nn.MaxPool2d(2, 2), # 24x24 -> 12x12nn.Flatten(),nn.Dropout(),nn.Linear(64 * 12 * 12, 1024), # 调整线性层的输入特征数量nn.ReLU(),nn.Dropout(),nn.Linear(1024, classes),nn.LogSoftmax(dim=-1))def forward(self, X):return self.cnn(X)
步骤4代码:
import torch
from torch import nn
from NumberNet import NumberNet
from torchvision import transforms
from torchvision.datasets import ImageFolder
from torch.utils.data import random_split# 水果分类训练
# 数据集配置
# 假设 NumberNet 模型期望的输入是 3 通道彩色图像
transform = transforms.Compose([transforms.ToTensor(), # 这将把 PIL 图像或 NumPy 数组转换为张量,并且范围从 [0, 255] 标准化到 [0.0, 1.0]# transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 可选:标准化
])# 加载项目目录下的水果文件夹
img_dataset = ImageFolder("../fruits", transform=transform)
len_dataset = len(img_dataset)
train_size = int(len_dataset * 0.8)
valid_size = len_dataset - train_size
train_dataset, valid_dataset = random_split(img_dataset, [train_size, valid_size])# 数据加载器
train_dataloader = torch.utils.data.DataLoader(train_dataset, batch_size=1000, shuffle=True)
valid_dataloader = torch.utils.data.DataLoader(valid_dataset, batch_size=1000)
# batch_total 应该是 dataloader 的总批次数量,这里计算方式不正确
batch_total = len(train_dataloader) # 应该直接使用 len(dataloader)# 使用conda或者cpu开始训练
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
epochs = 10
model = NumberNet(device)
criterion = nn.CrossEntropyLoss()
adam = torch.optim.Adam(model.parameters(), lr=0.01)for epoch in range(epochs):losses = []for batch_num, (images, labels) in enumerate(train_dataloader, start=1): # 使用 enumerate 来获取批次编号adam.zero_grad()predict = model(images.to(device))loss = criterion(predict, labels.to(device))print(f"batch size: {batch_num} / {batch_total} -- loss: {loss.item():.4f} ")losses.append(loss.item())loss.backward()adam.step()acc_list = []with torch.no_grad():for images, labels in valid_dataloader:predict = model(images.to(device))result = torch.argmax(predict, dim=-1)acc = (result == labels.to(device)).float().mean() # 使用 torch 的函数来计算准确率acc_list.append(acc.item())total_acc = sum(acc_list) / len(acc_list)total_loss = sum(losses) / batch_totalprint(f"epoch: {epoch + 1} / {epochs} -- loss: {total_loss:.4f} -- acc: {total_acc:.4f} ")# 保存模型参数,而不是整个模型
torch.save(model, "../readyModel/model.pth")
三. 将训练好的模型嵌入flask后端
实现水果识别web操作步骤:
- 在虚拟化环境下创建.py后端启动文件,并且创建模型实例,同时将训练好的.pth文件放入代码对应的文件路径。
- 创建index.html文件,作为后续前端文件。
- 在前端代码和后端代码使用Jason进行路由。
- 启动项目,实现功能。
步骤1代码:
from flask import Flask, render_template, request, jsonify
import time
import torch
import cv2
import numpy as np
from FruitNet import FruitNet # 确保FruitNet定义是正确的app = Flask(__name__)# 定义设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# 创建模型实例
model = FruitNet(device=device, classes=5) # 确保类别数与训练时一致
model.to(device)# 加载训练好的权重
model.load_state_dict(torch.load("static/fruit_model.pth")) # 确保权重文件名为fruit_model.pth
model.eval() # 设置模型为评估模式def predict_image(image_data):# 通过cv2加载图片数据img = cv2.imdecode(np.frombuffer(image_data, np.uint8), cv2.IMREAD_COLOR)# 将图像从BGR转换为RGB格式(因为OpenCV默认加载的是BGR格式)img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)# 调整图片大小到100x100(与训练时的输入大小一致)img = cv2.resize(img, (100, 100))# 在第一个位置增加一个维度,形成batch大小为1img = np.expand_dims(img, 0)# 将numpy对象转化为pytorch的tensor对象img = torch.from_numpy(img)# 调整图像通道顺序img = torch.permute(img, [0, 3, 1, 2]) # 转换为 (batch_size, channels, height, width)# 测试最终的结果with torch.no_grad(): # 关闭梯度计算img = img.to(device).float() # 确保输入是float类型,并发送到指定设备predict = model(img)predicted_class = torch.argmax(predict, dim=-1).item()# 定义水果类别标签fruit_classes = ["Apple Golden 1", "Banana", "Pear Red", "Tomato Heart", "Watermelon"] # 根据你的数据集定义类别标签# 输出预测的水果种类predicted_fruit = fruit_classes[predicted_class]return predicted_fruit
步骤2代码:
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><title>水果识别</title><link rel="stylesheet" href="./static/css/index.css"><script src="./static/js/jquery-3.7.1.min.js"></script>
</head>
<body>
<div class="main"><div><!-- 显示上传的图片 --><div class="upload-img"><img id="upload-img" src="" alt="请上传图片"/></div><!-- 表单用于上传图片 --><form id="upload-btn" action="/upload" method="post" enctype="multipart/form-data"><input style="margin-left: 120px" type="file" name="the_file" id="selectImg"> <br/><input type="submit" value="识别该水果"></form></div><!-- 显示识别结果 --><div class="result"><h2 id="result-show"></h2></div>
</div><script>// 将文件转为 Base64 用于图片预览function convertToBase64(file, callback) {const reader = new FileReader();reader.onload = function(e) {callback(e.target.result);};reader.readAsDataURL(file);}$(function(){// 处理图片选择后的显示$("#selectImg").change(function(ev){const file = $(this)[0].files[0];if (file) {convertToBase64(file, function(base64Img){$("#upload-img").attr("src", base64Img); // 更新图片预览});}});// 处理表单提交$('#upload-btn').submit(function(ev){ev.preventDefault(); // 阻止默认表单提交var formData = new FormData(this); // 获取表单数据$.ajax({url: '/upload', // 请求的后端地址type: 'POST',data: formData,contentType: false,processData: false,success: function(response){console.log('文件上传成功');console.log(response);// 更新识别结果$('#result-show').text('识别结果:' + response.result); // 显示识别结果},error: function(error){console.error('文件上传失败');console.error(error);}});});});
</script>
</body>
</html>
步骤3代码:
<script>// 将文件转为 Base64 用于图片预览function convertToBase64(file, callback) {const reader = new FileReader();reader.onload = function(e) {callback(e.target.result);};reader.readAsDataURL(file);}$(function(){// 处理图片选择后的显示$("#selectImg").change(function(ev){const file = $(this)[0].files[0];if (file) {convertToBase64(file, function(base64Img){$("#upload-img").attr("src", base64Img); // 更新图片预览});}});// 处理表单提交$('#upload-btn').submit(function(ev){ev.preventDefault(); // 阻止默认表单提交var formData = new FormData(this); // 获取表单数据$.ajax({url: '/upload', // 请求的后端地址type: 'POST',data: formData,contentType: false,processData: false,success: function(response){console.log('文件上传成功');console.log(response);// 更新识别结果$('#result-show').text('识别结果:' + response.result); // 显示识别结果},error: function(error){console.error('文件上传失败');console.error(error);}});});});
</script>
@app.route("/")
def home():return render_template("index.html")@app.route('/upload', methods=['POST'])
def upload_file():if request.method == 'POST':f = request.files['the_file']# 保存图片到静态目录timestamp = time.strftime("%Y%m%d%H%M%S")file_path = f'./static/uploads/{timestamp}.png'f.save(file_path)# 读取保存后的图片数据并预测with open(file_path, 'rb') as image_file:image_data = image_file.read()predicted_fruit = predict_image(image_data)# 返回JSON数据return jsonify({'file_id': timestamp,'result': predicted_fruit,'img_path': f'/static/uploads/{timestamp}.png'})
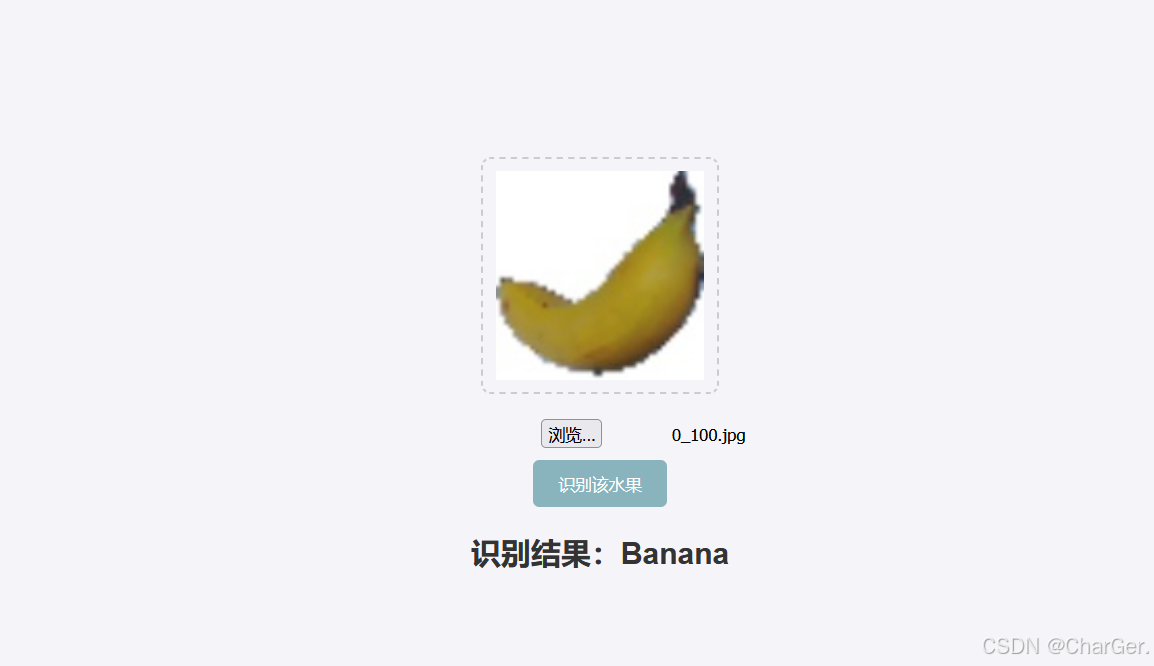
步骤4实现效果: