1. Context Parallel并行原理介绍
megatron中的context并行(简称CP)与sequence并行(简称SP)不同点在于,SP只针对Layernorm和Dropout输出的activation在sequence维度上进行切分,CP则是对所有的input输入和所有的输出activation在sequence维度上进行切分,可以看成是增强版的SP。除了Attention模块以外,其他的模块(Layernorm、Dropout)由于没有多token的处理,在CP并行时都不用任何修改。
为什么Attention模块是个例外? 因为Attention计算过程中每个token的Q(query)要跟同一个sequence中其他token的K(key)和V(value)一起进行计算,存在计算上的依赖,所以通过CP并行后,在计算Attention前要通过allgather通信拿到所有token的KV向量,在反向计算时对应需要通过reduce_scatter分发gradient梯度。
为了减少显存占用,在前向时每个gpu只用保存一部分KV块,反向时通过allgather通信拿到所有的KV数据。KV的通信发生在相邻TP通信组相同位置的rank之间。allgather和reduce_scatter在ring拓扑架构实现时,底层会通过send和recv来进行实现。
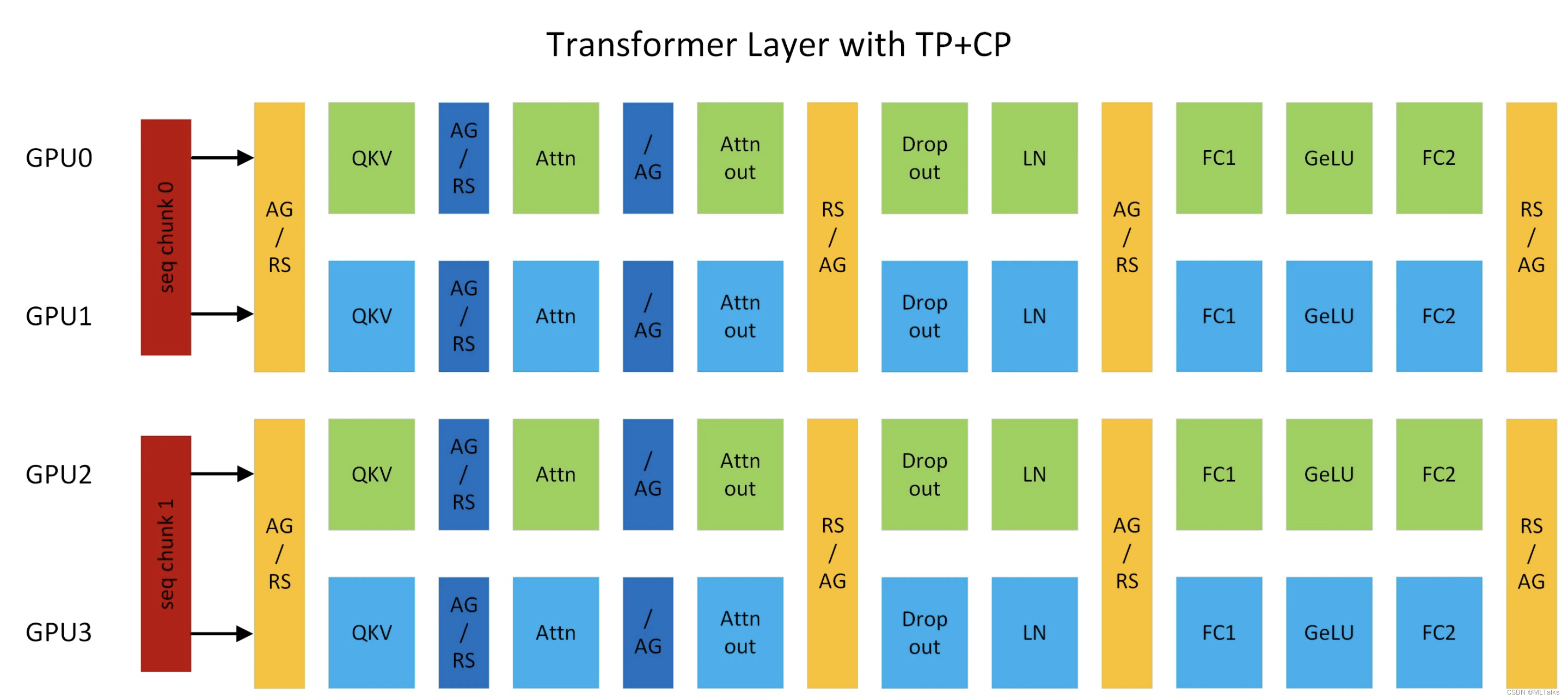
以上图TP2-CP2的transformer网络为例,在Attention前的是CP的通信算子,其他都是TP的通信算子。AG表示allgather, RS表示reduce_scatter, AG/RS表示前向allgather反向reduce_scatter, RS/AG表示前向reduce_scatter反向allgather。
这里TP2对应为[GPU0, GPU1], [GPU2, GPU3], CP2对应为TP组相同位置的rank号,也就是[GPU0, GPU2], [GPU1, GPU3]。CP并行与Ring Attention类似,但是提供了新的OSS与FlashAttention版本,也去除了low-triangle causal masking的冗余计算。
LLM经常由于sequence长度过长导致显存OOM,这时之前的一种方式是通过重计算的方式保存中间的activation产出,全量重计算的劣势会带来30%的计算代价;另外一种方式是扩大TP(tensor parallel)的大小,扩大TP的劣势在于会对tensor切的更小,从而导致linear fc的计算时间变少,从而与通信很难进行计算的掩盖。
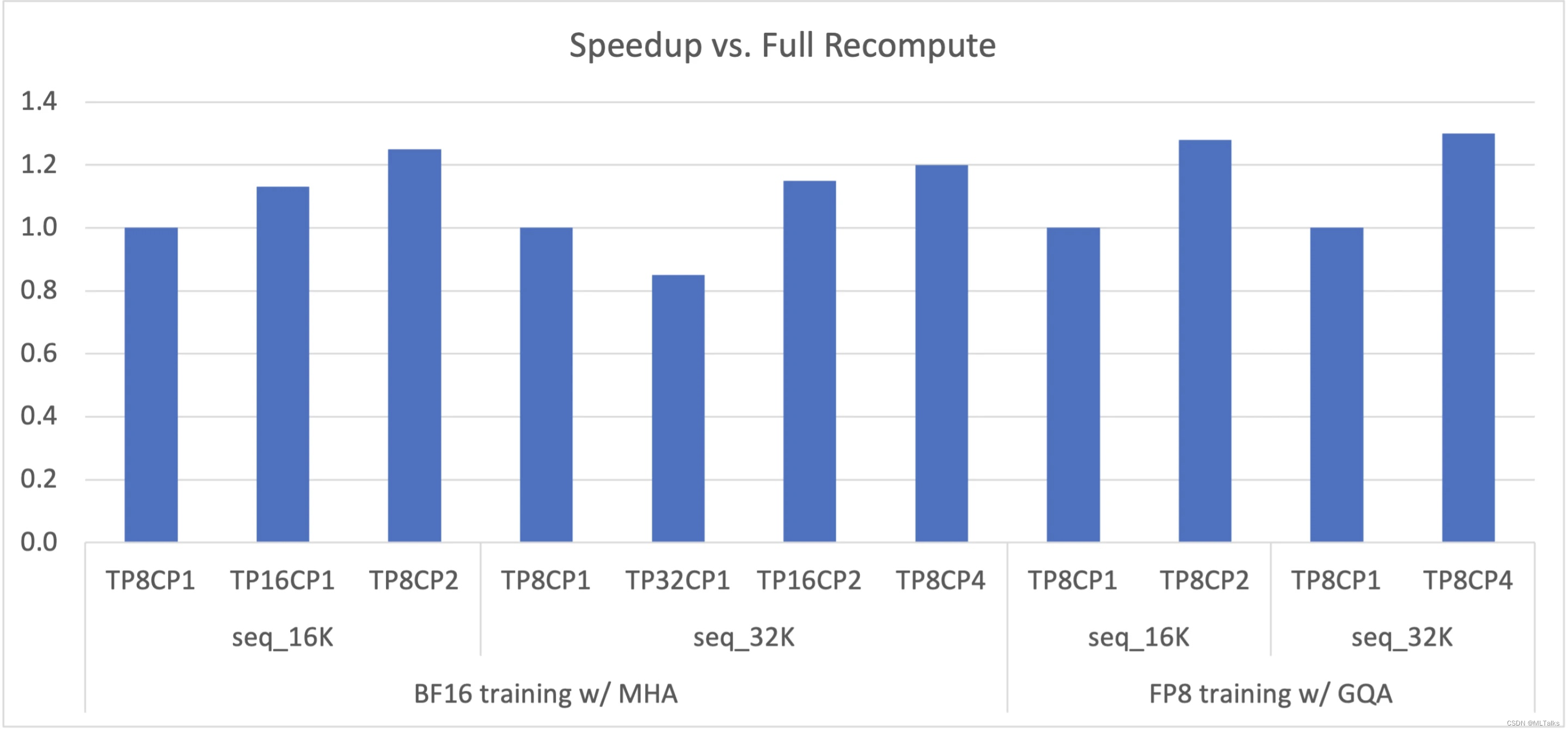
通过CP可以更好解决OOM的问题,每个GPU只用处理一部分的sequence, 同时减少CP倍的通信和计算,但保持TP不变,同时activation也会减少CP倍。CP优化的性能参考如下图,在Megatron中(Megatron-Core>=0.5.0 && Transformer Engine >=1.1)通过指定--context-parallel-size可以进行使用。 t o t a l _ g p u _ c o u n t = T P × C P × P P × D P total\_gpu\_count = TP \times CP \times PP \times DP total_gpu_count=TP×CP×PP×DP。
2. 源码
以Megatron-Core 0.5.0为例进行介绍
- 首先在
megatron/arguments.py中定义了--context-parallel-size参数, 同时也要求了world_size能要整除TP*PP*CP。
group.add_argument('--context-parallel-size', type=int, default=1,help='Degree of context parallelism.')....model_parallel_size = args.pipeline_model_parallel_size * \args.tensor_model_parallel_sizeassert args.world_size % (model_parallel_size * args.context_parallel_size) == 0, \'world size ({}) is not divisible by tensor parallel size ({}) times ' \'pipeline parallel size ({}) times context parallel size ({})'.format(args.world_size, args.tensor_model_parallel_size,args.pipeline_model_parallel_size, args.context_parallel_size)args.data_parallel_size = args.world_size // (model_parallel_size * args.context_parallel_size)
- 在
megatron/core/parallel_state.py中初始化通信组时会初始化相关CP通信组, 以TP-PP-DP-CP=8-1-1-2为例,TP通信组为[0,1,2,3,4,5,6,7],[8,9,10,11,12,13,14,15], CP通信组为[0,8],[1,9],[2,10],[3,11],[4,12],[5,13],[6,14],[7,15]。
def initialize_model_parallel(...):...for i in range(pipeline_model_parallel_size):for j in range(data_parallel_size):start_rank = (i * num_pipeline_model_parallel_groups+ j * tensor_model_parallel_size * context_parallel_size)end_rank = (i * num_pipeline_model_parallel_groups+ (j + 1) * tensor_model_parallel_size * context_parallel_size)for k in range(tensor_model_parallel_size):ranks = range(start_rank + k, end_rank, tensor_model_parallel_size)group = torch.distributed.new_group(ranks, pg_options=get_nccl_options('cp', nccl_comm_cfgs))if rank in ranks:_CONTEXT_PARALLEL_GROUP = group_CONTEXT_PARALLEL_GLOBAL_RANKS = ranks
- 在
megatron/core/transformer/custom_layers/transformer_engine.py中TEDotProductAttention会初始化相关CP通信组相关参数,TEDotProductAttention继承自te.pytorch.DotProductAttention,在前向中直接调用父类的的forward函数。
class TEDotProductAttention(te.pytorch.DotProductAttention):def __init__(...):...if te_version >= packaging.version.Version("1.0.0"):if getattr(TEDotProductAttention, "cp_stream") is None:TEDotProductAttention.cp_stream = torch.cuda.Stream()extra_kwargs["cp_group"] = get_context_parallel_group(check_initialized=False)extra_kwargs["cp_global_ranks"] = get_context_parallel_global_ranks(check_initialized=False)extra_kwargs["cp_stream"] = TEDotProductAttention.cp_stream...def forward(...):...core_attn_out = super().forward(query,key,value,attention_mask,attn_mask_type=attn_mask_type.name,**packed_seq_kwargs,)...
- Transformer Engine中
DotProductAttention定义在transformer_engine/pytorch/attention.py中,CP相关参数通过attn_kwargs进行传入。接下来会调用FlashAttention的前反向。
class DotProductAttention(torch.nn.Module):def __init__(...):...if self.use_flash_attention:self.flash_attention = FlashAttention(norm_factor,attention_type=attention_type,layer_number=layer_number,deterministic=self.deterministic,**attn_kwargs)...class FlashAttention(torch.nn.Module):def forward(...):...if context_parallel:with self.attention_dropout_ctx():output = attn_forward_func_with_cp(self.training, query_layer, key_layer, value_layer,cu_seqlens_q, cu_seqlens_kv, max_seqlen_q, max_seqlen_kv,self.attention_dropout if self.training else 0.0,cp_group, cp_global_ranks, cp_stream,softmax_scale=1.0/self.norm_factor,qkv_format="bshd" if qkv_format=="sbhd" else qkv_format,attn_mask_type=attn_mask_type,deterministic=self.deterministic)
- 在FlashAttention中会通过函数
attn_forward_func_with_cp进行调用,最终Attn前的all_gather通信是在AttnFuncWithCP中通过send、recv通信来实现的, 执行完通信就执行对应的flash_attention算子的调用。
def attn_forward_func_with_cp(...):out = AttnFuncWithCP.apply(is_training, q, k, v, cu_seqlens_q, cu_seqlens_k, max_seqlen_q, max_seqlen_k,dropout_p, cp_group, cp_global_ranks, cp_stream, softmax_scale, qkv_format,attn_mask_type, attn_bias_type, attn_bias, deterministic, use_fused_attention)return outclass AttnFuncWithCP(torch.autograd.Function):def forward(...):for i in range(cp_size+1):if i < cp_size:with torch.cuda.stream(flash_attn_streams[i%2]):# wait until KV is receivedfor req in send_recv_reqs[(i+1)%2]:req.wait()if i < (cp_size-1):p2p_comm_buffers[i+1] = torch.empty_like(p2p_comm_buffers[i])send_recv_reqs[i%2] = flash_attn_p2p_communicate(rank,p2p_comm_buffers[i],send_dst,p2p_comm_buffers[i+1],recv_src,cp_group,batch_p2p_comm)...fused_attn_fwd(is_training, max_seqlen_q, max_seqlen_k, cu_seqlens_q,cu_seqlens_k, q_inputs[i%2], kv_inputs[i%2][0],kv_inputs[i%2][1], TE_DType[q.dtype],tex.NVTE_Fused_Attn_Backend.NVTE_F16_arbitrary_seqlen,attn_scale=softmax_scale, dropout=dropout_p,qkv_layout=qkv_layout, attn_mask_type="causal",attn_bias_type=attn_bias_type, attn_bias=attn_bias_inputs[i%2],)
3. 参考
- Context parallelism overview