本文重点介绍了微信云数据库的一些使用技巧和系统限制。
 这篇文章任务是什么?
这篇文章任务是什么?
 掌握更多的云数据库函数使用技巧
掌握更多的云数据库函数使用技巧
前言
本篇文章在作为上一篇文章《小白变大神,8月做个todolist送自己》续篇,进一步介绍更多的云数据库工具函数,首次阅读的读者先看到文末,查阅历史文章教程,边看教程边看代码。
github代码库:sdjl/WxMpCloudBooster,获取代码:
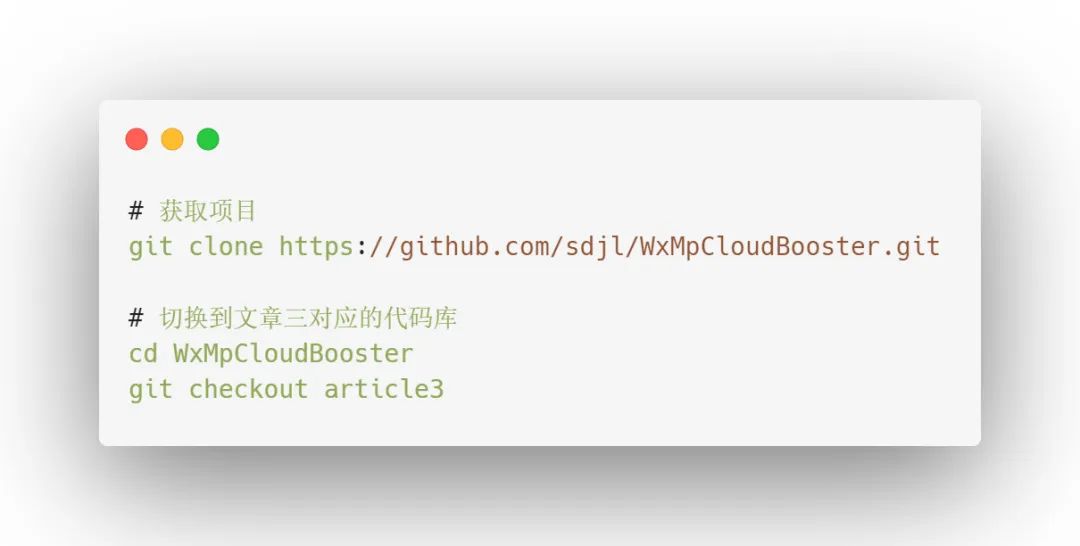
注意:建议 checkout 到 article3,否则拿到的代码可能和本文中不一致
一、云数据库的限制
1. 前端限制
- get请求每次最多读取200条数据,初始默认读取20次,单次返回数据总大小不能超过1M。
- 聚合请求最多读取10000条数据,单次返回数据总大小不能超过5M。
- add写入数据操作,单次写入数据不可以超过512KB。
- update更新数据操作,单次更新数据不可以超过512KB。
2. 云端限制
get请求默认每次最多读取100条数据,可通过修改limit参数后可以超过100条,上限未知,单次返回数据总大小不能超过50M。
聚合请求读取数据条数的上限未知,单次返回数据总大小不能超过50M。
add写入数据操作,单次写入数据不可以超过5M。
update更新数据操作,单次更新数据不可以超过5M。
addDocList函数实际使用了add操作,因此addDocList函数的单次写入数据不可以超过5M。
注意:以上除“get函数前端20条、云端100条”的限制外,其他限制是我自己测试总结的,微信官方文档中并没有说明,未来微信官方可能会调整这些限制。
3. 如何知道文档的大小?
请参考以下工具函数:

可以在调用addDoc或updateDoc之前,先把整个文档传入getKLen函数,然后把文档大小保存到某个变量中,如:
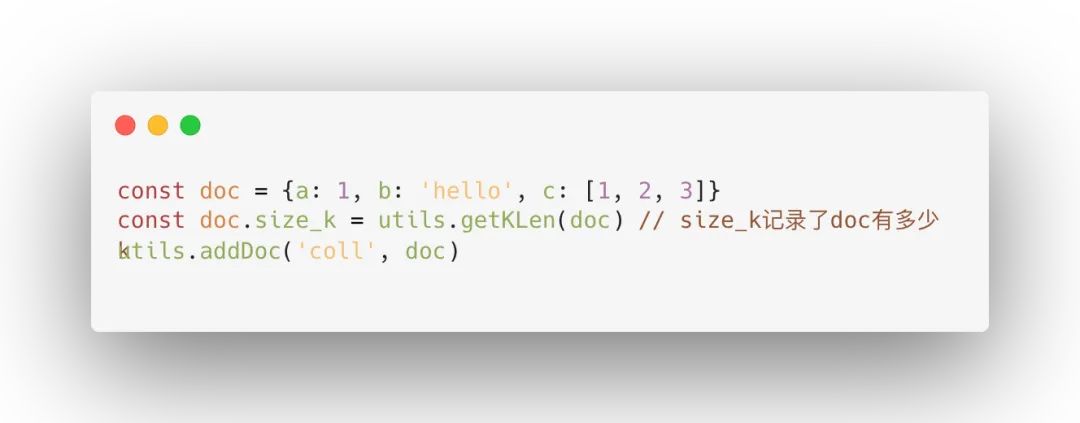
通过查看size_k的值,如果size_k=10,表示这个文档大小为10K左右
二、云函数版本
在云函数中操作数据库时,不需要考虑权限问题,代码默认拥有所有操作权限
在WxMpCloudBooster代码库中,为云函数提供了一个专门的文件for_cloud/utils/utils.js。可以把for_cloud/utils目录放在云函数的根目录下,复制后目录结构如下:

然后使用下面的代码导入云函数的utils模块:
1. 支持使用addDocList批量插入函数

假设有一个doc_list,里面包含了10000个订单数据,可以这样插入:
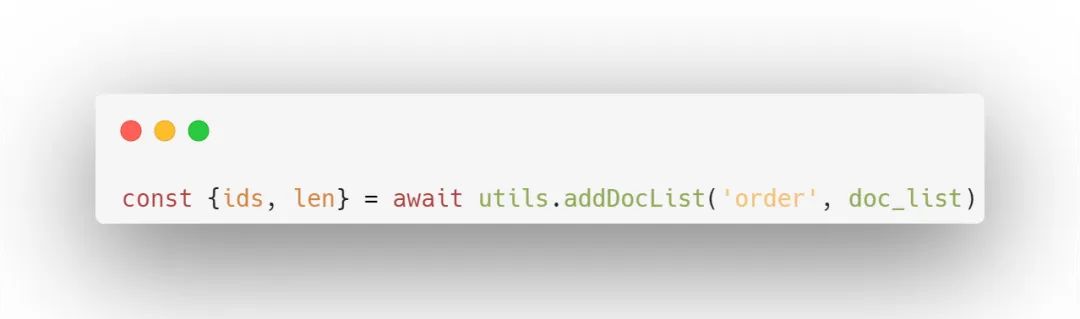
在返回的结果中,ids是插入的文档的ID列表,len是实际插入的文档数量。且使用addDocList,无论插入多少条数据,都只消耗1次调用次数。
如果前端有批量插入需求,可以在前端把doc_list传给云函数,然后在云函数中调用addDocList函数。
2. 巧用addDocList函数批量更新不同值
实际开发中面临给两种不同的数据更新不同的值的问题:
1.给多个数据的同个字段更新不同的值,如需要给每个订单添加created字段,表示该订单的下单时间,但是每个订单的下单时间是不同的。
2.给多个数据的不同字段更新不同的值,如有些订单需要添加created字段,但有些订单需要添加updated字段,且每个订单的更新值也都不同。
使用addDocList函数,实现批量更新不同数据的需求,且仅消耗3次调用次数,同时数据的_id字段不会改变。,步骤如下:
1.在云函数中新建一个数据库事务(可选)
2.读取所有需要更新的数据,并修改数据
3.使用removeMatch或removeAll函数删除所有需要更的数据
4.使用addDocList函数插入修改后的数据
5.提交数据库事务(可选)
在微信云数据库中,无法通过使用事务减少数据库调用次数,无论是否使用,调用次数的计算方式不变。
3. 使用开发者工具导入批量更新不同值
可以按照下面这个步骤批量手动更新数据:
1.在开发者工具中导出数据;
2.使用python、js或其他语言修改数据,并输出一个新的json文件;
3.在开发者工具中导入新的json文件。
如果需要通过程序自动化实现,可使用云数据库的HTTP API(消耗调用次数)。
4. 其他函数
for_cloud/utils/utils.js文件中的部分函数与前端版本一致。

二、 获取文档函数使用技巧
1. getDoc函数

根据文档ID获取文档。如果有一个列表,建议使用docs函数一次读取多个文档并缓存到本地,以减少调用次数。utils.js中的所有数据库操作函数均会根据当前运行环境自动判断操作测试数据库还是正式数据库。若小程序不在本地运行,则会自动给集合名称添加p_前缀,表示访问生产环境的集合表。
2. *My*函数
当数据库权限设置为“自定义安全规则”且有“auth.openid == doc._openid”规则时,直接使用getDoc函数会拿不到数据,返回的doc总是等于null。此时需要设置mine为true,或者使用getMyDoc函数代替getDoc。utils中的数据库操作函数总是成对出现,如getDoc和getMyDoc,docs和myDocs等。
当需要读取用户自己的数据时,请使用对应的My函数,否则会有权限问题。
3. getOne函数
根据某个条件获取一个文档时,可使用getOne函数。

getOne支持排序,例如当你想要获取“最近一个订单数据”时,可以使用order_by对下单时间进行排序。
假设要获得最新已完成的订单,可以这样使用:

finished_time表示订单完成时间,-1表示降序。
4. getMyLastOne函数
获取当前用户的最新一个数据是常见需求,例如用户最近的一个评论,用户最近的一个订单等。getMyLastOne函数是getOne的一个封装,用于获取当前用户在指定集合中最新创建的文档:

如果用户订单表中有index字段,你可以这样获取当前用户的最新订单:
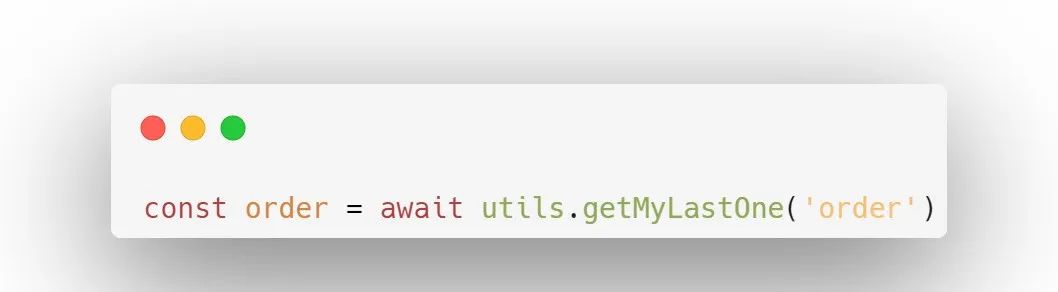
此函数会自动过滤掉其他用户的数据。本代码库中有引入index字段,用于记录文档的创建顺序,然后有些utils的函数是基于index字段的。
5. getMyUniqueOne函数
明确的知道某个表中一个用户只能有一个文档,例如在user_setting表中,使用getMyUniqueOne函数获取用户的唯一数据:
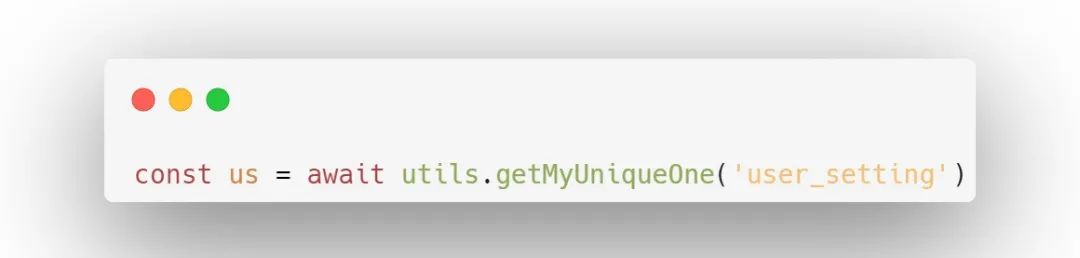
注意:user_setting表在设计上_openid应该是唯一索引。
三、获取所有文档函数使用技巧
1. allDocs参数
docs函数最多只能读取20个文档(受微信系统限制),在需要读取更多的文档,甚至需要读取所有文档的时候。需要使用aggregate实现了allDocs函数,用于读取集合中的所有文档。数据库的聚合操作(aggregate)没有单次读取20条的限制。

直接调用此函数,会返回集合中的所有数据,如:
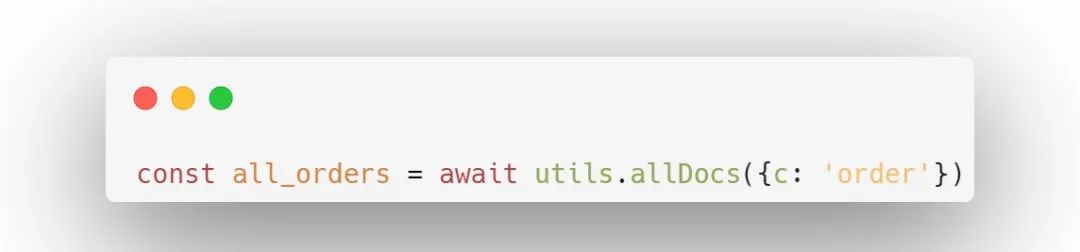
此函数实际上会分多次读取,每次读取page_size个文档(默认1000),直到读取完所有文档为止。如果实际上有3000个订单,那么此函数会读取3次,消耗3次。可以把page_size设置得更大一些,如3000,这样读取上面的3000个文档就只需要消耗1次调用。
但问题是,系统限制前端每次读取的数据总量不能超过5M,当单次读取超过5M时,就会报错。因此,如果单个文档较大,建议适当减小page_size的值(这可能会增加调用次数)。
如果确保表中所有数据加起来不会超过5MB,那么可以把page_size设置得大一些,如999999,这样就能实现仅消耗1次调用次数读取所有文档。
2. limit参数
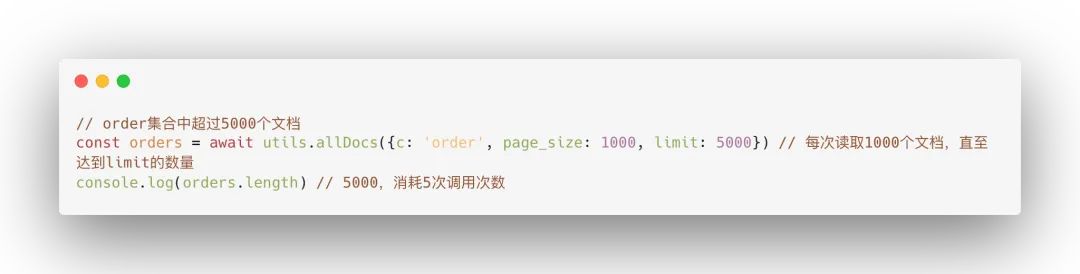
想要“较多数据”而非“全部数据”,可以使用limit参数,如获得500个最新的订单:

limit参数用于限制读取文档的数量,由于limit小于page_size,因此只会消耗1次调用次数。如page_size为1000,limit为5000,并且集合中文档数量超过5000个,那么以下的代码会读取5次,只返回5000个文档:
3. 单个文档超过1M的读取
无论是getDoc、getOne还是docs函数,它们都是普通查询(相对于聚合查询而言)。统限制单次读取的数据总量不能超过1M,如果文档大小在1M-5M之间,可以使用allDocs函数配合limit参数,如:

如果文档超过5M,可以配合only参数,分多次读取,每次仅读取部分字段,如:

3. allDocs函数的其他功能
allDocs函数内部使用了聚合查询aggregate,可以在官网https://developers.weixin.qq.com/miniprogram/dev/wxcloud/guide/database/aggregation/aggregation.html中了解更多。
sort参数用于排序,使用方法和docs中的order_by参数相同,但是在使用聚合查询时,用sort表示排序。
match参数与docs中的w参数相似,但是在使用聚合时,使用match命名,以区分普通查询。
allDocs函数还支持project功能,可以在官方文档https://developers.weixin.qq.com/minigame/dev/wxcloud/reference-sdk-api/database/aggregate/Aggregate.project.html中了解。
当同时使用project和sort时,函数内部会先执行project,然后再执行sort。
调用allDocs函数时用户可能需要等待几秒钟,此时可以设置show_loading参数为true,以显示系统默认的loading动画,函数会在数据读取完毕后自动关闭loading动画。
四、其他更新数据函数
1. updateMatch函数
updateDoc函数一次能更新一个文档。可以使用updateMatch函数批量更新多个文档。

若想把所有“未完成”订单的状态都改为“已完成”,可以这样使用:

只是删除某个字段,例如删除订单的重量字段weight,可以这样使用:

上面代码中的第二个参数表示仅修改有weight字段的数据,这是可选的。
updateMatch有一个限制,即更新时所有匹配的数据设置的值必须是相同的,假如想给所有订单设置一个created字段表示订单创建时间,但每个订单的创建时间是不同的,那么就不能使用updateMatch函数。微信云数据库的API不支持这种批量更新不同值的操作。
2. undefinedToRemove函数
在updateMatch的第三个参数中,设置weight为undefined,这样就会删除weight字段。但注意,如果使用微信默认API,当设置某字段为undefined时,系统会抛出异常,如图所示:
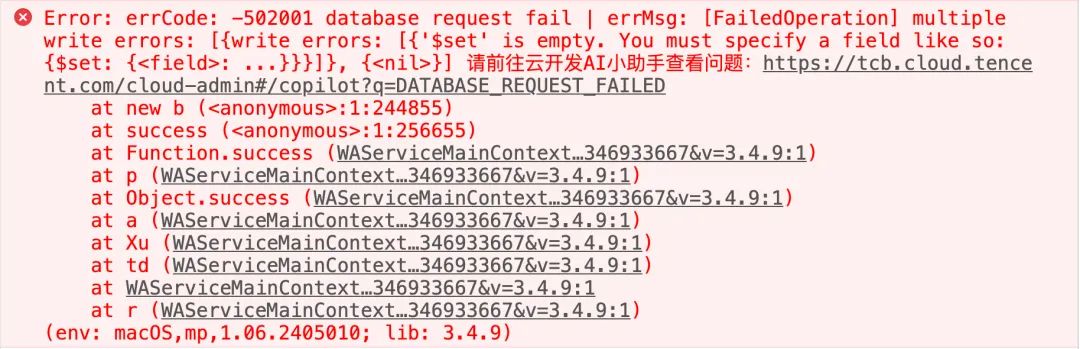
如果在实际开发中需要设置一个字段为undefined时,目标是删除这个字段。在utils.js中提供了undefinedToRemove函数,并且在updateMatch中默认使用了undefinedToRemove函数。

传给undefinedToRemove函数的参数,可以是一个对象,也可以是一个数组,函数会递归搜索所有值为undefined的属性,并替换为数据库删除命令开发者资源 / SDK 文档 / 数据库 / Command / 更新·字段操作符 / remove (qq.com)。
如要删除数据库中的a.b.c字段:

3. setDoc函数
updateDoc函数只会更新在第三个参数d中所指定的属性,对于没有明确指定的属性,updateDoc不会做任何更改。
如需要将整个文档替换成新对象,就可以使用setDoc函数。

如果setDoc指定的id不存在,则会创建一个新的文档。
提醒:如果能用updateDoc,就不要用setDoc,因为微信限制每次写入或更新的数据不能超过512KB,使用setDoc容易超过这个限制。
五、其他删除数据函数
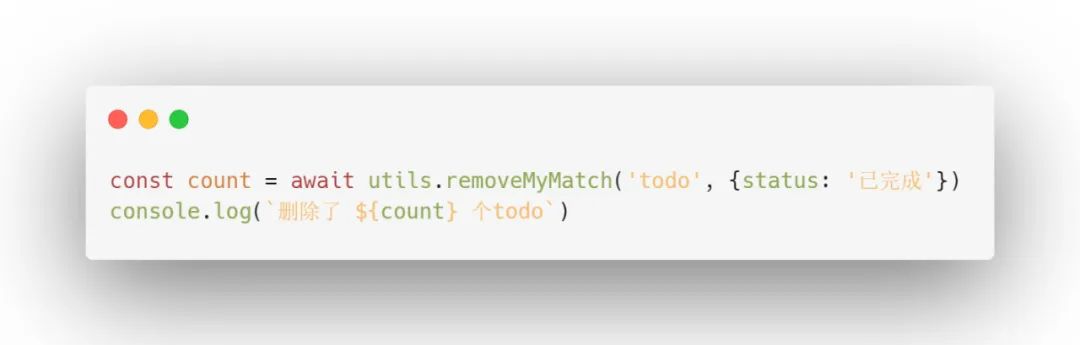
1. removeMatch函数
同样的,上篇文章中的removeDoc只能删除一个文档,若一次需要删除多个文档,可使用removeMatch函数。

例如删除当前用户所有已完成的todo:
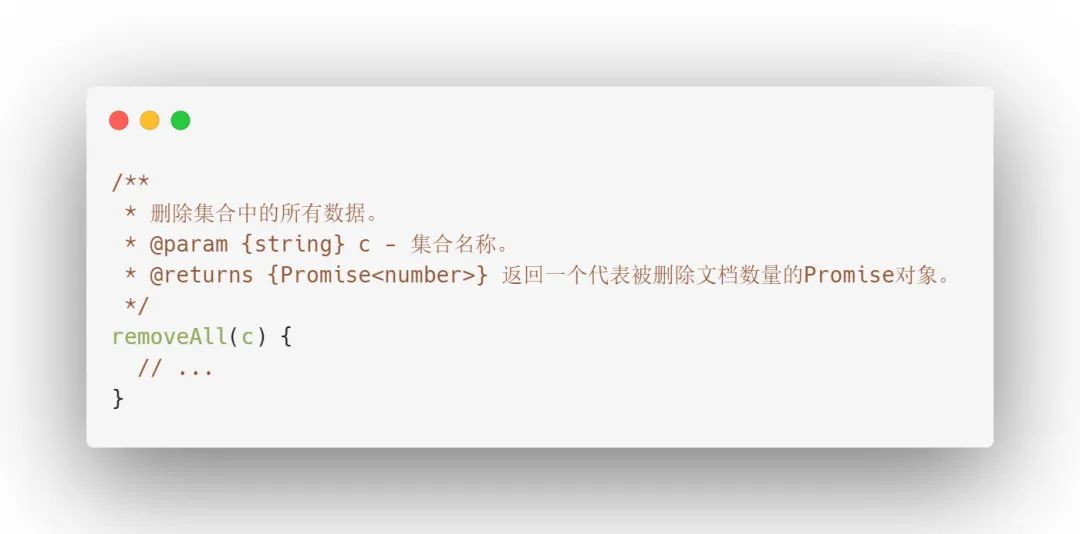
2. removeAll函数
开发阶段需要清空某个表中的所有数据时,可使用removeAll函数,只需要输入集合名称即可。
如果希望向用户提供一个“清空自己的数据”的功能,可以使用removeMyAll函数。
六、其他数据库操作函数
exists:根据文档ID或查询条件判断文档是否存在。
count:根据查询条件统计文档数量。
getMaxFeild: 获取某个字段的最大值。
getMinFeild: 获取某个字段的最小值。
以上函数的用法请查看代码库中的注释。
原创为腾讯云开发布道师 刘永辉