
相关阅读:
-
ViT:3 Compact Architecture
-
MobileLLM:“苗条”的模型比较好!
大家也许会很好奇为什么在ViT章节插入了NVIDIA Llama-3.1-Minitron 4B,ViT因为应用场景的特殊性所以都寄希望于高效率的模型,因此各种针对大参数模型的提炼和优化技术层出不穷。而NVIDIA Llama-3.1-Minitron则复现了这些系列的教科书实验。对于一些基本的术语,可以移步ViT 1温习一下。


Llama-3.1-Minitron 4B
LLMs例如Llama 3.1 405B和NVIDIA Nemotron-4 340B在许多具有挑战性的任务中表现出色,包括编码、推理和数学。但是部署它们需要大量资源。所以在可以预见的未来,开发小型且高效的语言模型成为热门,毕竟好用且部署成本要低很多。
NVIDIA近日的研究表明,结构化权重修剪与知识蒸馏相结合,形成了一种有效且高效的策略,可以从较大的兄弟模型中提炼较小的语言模型。NVIDIA Minitron 8B和4B就是通过修剪和蒸馏NVIDIA Nemotron系列中较大的15B而得到的。
的确修剪和蒸馏这些大模型的提炼方法与从头开始训练相比,MMLU分数提高了16%。每个额外的模型需要的训练令牌更少,最多减少40倍,与从头开始训练所有模型相比,训练一个疗程可节省高达1.8倍的计算成本。当然最重要的是性能也不能拉胯,性能与Mistral 7B、Gemma 7B和Llama-3 8B相当,最高可达 15T。
NVIDIA的本次研究提出了一套实用且有效的结构化压缩最佳实践,将LLMs深度、宽度、注意力和MLP修剪与基于知识蒸馏的方法相结合。最后将它们应用于Llama 3.1 8B模型以获得Llama-3.1-Minitron 4B。
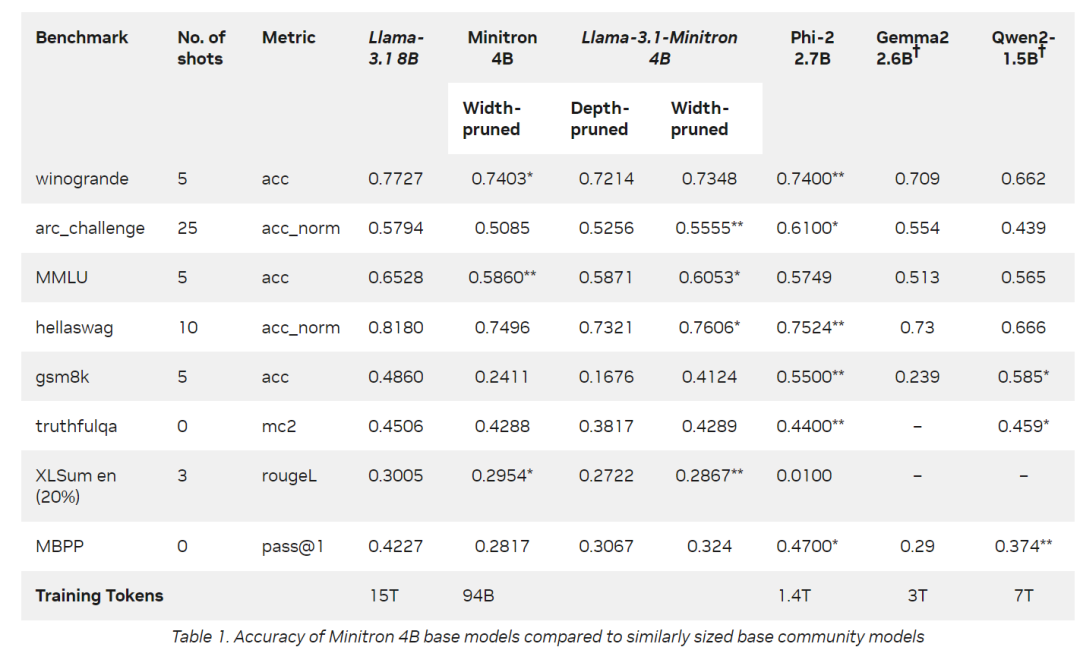
Llama-3.1-Minitron 4B与类似大小的最先进的开源模型相比表现出色,包括 Minitron 4B、Phi-2 2.7B、Gemma2 2.6B和Qwen2-1.5B,Llama-3.1-Minitron 4B即将发布到HuggingFace。
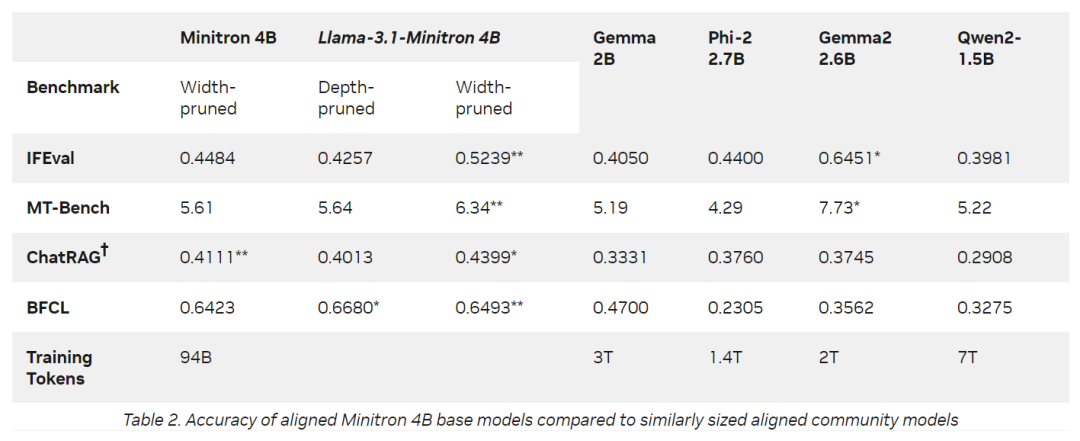
Nvidia进一步优化了Llama-3.1-Minitron 4B模型,以使用其TensorRT-LLM工具包进行部署,从而增强了其推理性能。例如,与原始的Llama 3.1 8B模型相比,该模型在各种情况下的FP8精度吞吐量增加到2.7倍。在 Llama-3.1-Minitron 4B上执行的额外优化使该模型非常强大和高效,易于应用于许多领域。

经验总结
具体的过程如下:从15B模型开始评估每个组件(层、神经元、头部和嵌入通道)的重要性,然后对模型进行排序和修剪到目标大小的8B模型。之后使用模型蒸馏执行了轻度二次训练,原始模型作为老师,修剪后的模型作为学生。训练后8B模型作为修剪和提炼为较小的4B模型的起点。
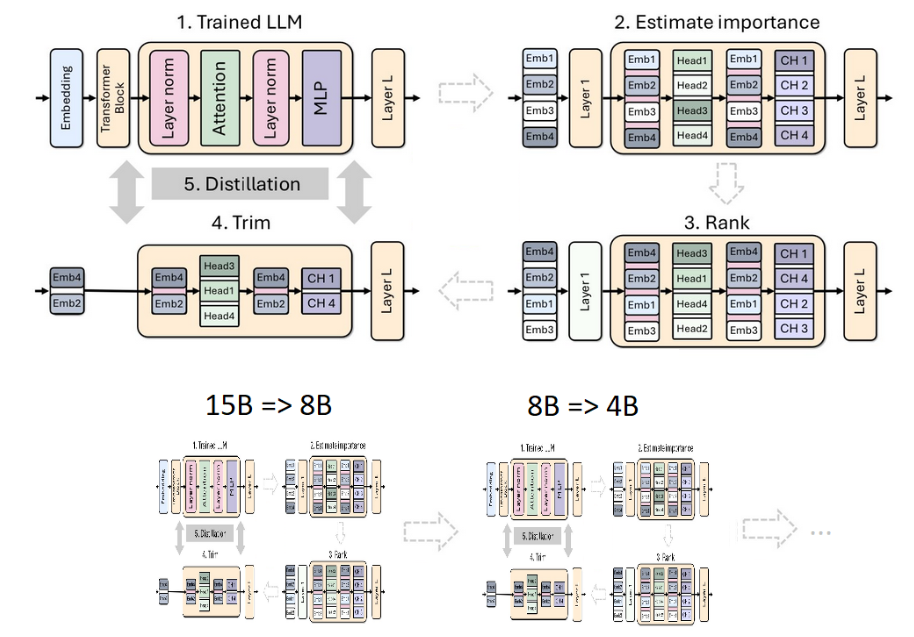
要修剪模型,首先要了解模型哪些部分是重要的,这点至关重要。这里使用一种纯粹基于激活的重要性估计策略。这种策略使用1024个样本数据集通过并行的前向传播来评估所有这个神经网络中组件的重要性(depth, neuron, head, and embedding channel)。研究指出可以迭代地交替使用修剪和重要性评估方法,然而实证研究表明,使用单次重要性估计就足够了,迭代多次并没有带来想象中的收益。
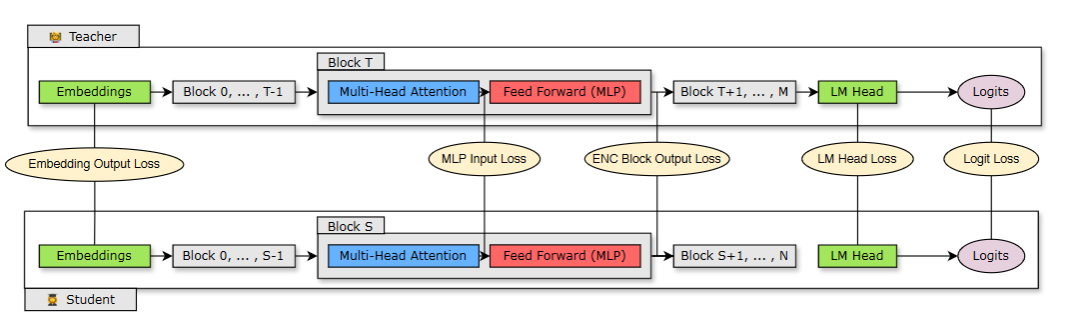
上图显示使用学生模型(修剪模型)的蒸馏过程,该模型具有N层,是从具有M层的教师模型(原始未修剪模型)中蒸馏出来的。学生通过最小化映射在学生块S和教师块T上的Embedding Loss、Logit Loss等Loss组合学习和训练。
基于通过剪枝和知识蒸馏的消融研究<就是拿掉一个组件,看看缺失的情况对于整体的影响力>,本次研究将学习成果总结出一些压缩的最佳实践:
-
要训练一个家族的LLMs,首先挑选最大号的模型然后进行修剪和迭代蒸馏以获得较小的LLMs
-
如果使用的大模型是使用多阶段训练策略进行训练的,则最好选择最后阶段的模型。
-
当源模型最接近目标期望大小的模型时候可以修剪
-
最好进行宽度修剪而不是深度修剪,这对于≤ 15B效果很棒
-
针对神经网络中各个组件的重要性评估,一次就够了
-
使用蒸馏损失进行再训练,当深度显著减少时使用Logit+Embedding +中间状态进行蒸馏,当深度没有显著减少时,仅使用Logit蒸馏。