1. 文本向量化概述
随着计算机计算能力的大幅度提升,机器学习和深度学习都取得了长足的发展。NLP越来越多的通过应用机器学习和深度学习工具解决问题,例如通过深度学习模型从网络新闻报道中分析出关键词汇与舆论主题并构建关系图谱。在这种背景下,文本向量化成为NLP一个非常重要的工具,因为文本向量化可将文本空间映射到一个向量空间,从而使得文本可计算。文本分类和聚类是NLP得得基础内容。这几节主要介绍文本进阶处理的文本向量化得常用方法、文本相速度的计算方法及常见的文本分类和聚类算法。
本节先学习文本向量化。文本向量化是将文本表示成一系列能够表达文本语义的机读向量。在nlp中,文本向量化是一个重要环节,其产出的的向量质量将直接影响后续模型的表现。例如:在一个文本相似度比较的任务,可以去文本向量的余弦值作为文本相似度,也可以将文本向量输入神经网络中进行计算得到相似度,但是无论后续模型是怎样的,前期的文本向量表示都会影响整个相似度比较的准确性。
例如,图像领域天然有着高维度和局部相关性等特性,nlp领域也有着自身的特征。一是计算机任何计算的前提都是提前向量化,而文本难以直接被向量化;二是文本向量化应当尽可能的包含语言本身的信息,但是文本中存在多种语法规则及其他种类的特性,导致向量化比较困难;三是自然语言处理本身可以体现人类社会的深层次关系(如讽刺等词语),这种关系未向量化带来了挑战。
文本向量化按照向量化的粒度的不同可以将其分为以字节为单位、以句子为单位向量表达,根据不同的情景选择不同的向量表达方法和处理方式。目前对文本向量化的大部分研究都是通过以词为单位的向量化。随着深度学习技术的广泛应用,基于神经网络的文本向量化已经成为NLP领域的研究热点,尤其是以词为单位的向量化。 Word2Vec是目前以词为单位中最典型的生成词向量的工具,其特点是将所有的词向量化,这样词与词之间即可度量它们之间的关系、挖掘词之间的联系。也有一部分研究将句子作为文本处理的基本单元,于是就产生了Doc2Vec和Str2Vec等技术。
2. 文本离散表示
文本向量化主要分为文本离散表示和文本分布式表示。离散表示是一种基于规则和统计的向量化方法,常用的方法有词集模型和词袋(BOW)模型,两类模型都是基于词之间保持独立性、没有关联为前提,将所有文本中的词形成一个字典,然后根据字典统计词出现频数。但是两者中间也有不同,例如: 词集模型中的独热表示,只要单个文本中单词出现在字典中,就将其置为1,不管出现多少次。 BOW模型只要文本中一个词出现在字典中,就将其向量值加1,出现多少次就加多少次。 文本离散表示的特点是忽略文本信息中的语序信息和语境信息,仅将其反映为若干维度的独立概念。这类模型由于本身原因存在无法解决的问题,如主语和宾语的顺序问题,会导致无法理解诸如“我为你鼓掌”和“你为我鼓掌”两个语句之间的区别。
2.1 独热表示
独热表示是指用一个长的向量表示一个词,向量长度为词典的大小,每个向量只有一个维度为1,其余维度全部为0,为1的位置表示该词语在词典的位置。例如:有两句话‘小张喜欢看电影,小王也喜欢’和‘小张也喜欢看足球比赛’。首先对这两句话分词构成一个词典,词典的键是词语。值是ID,即{’小张’:1,‘喜欢’:2,‘也’:3,‘看’:4,’电影‘:5,‘足球’:6,’比赛‘:7,‘小王’:8},然后根据ID值对于每个词语进行向量化,用0和1代表这个词是否出现,如‘小张’和‘小王’的独热表示分别为[1,0,0,0,0,0,0,0]和[0,0,0,0,0,0,0,1]。
独热表示词向量构造起来简单,但通常不是一个好的选择,他有明显的缺点,具体如下:
1. 维数过高:随着语料的增加,维数会越来越大,导致维数灾难。
2. 矩阵稀疏:one-hot表示的每一个词向量只有1维是有数值的,其他维度上的数值都为0。
3. 不能保留语义: one-hot表示的结果不能保留词语在句子中的位置信息。
2.2 BOW模型
BOW模型就是用一个向量表示一句话或一个文档。 BOW模型忽略文档的词语顺序、语法、句法等要素,将文档看作是若干个词汇的集合,文档中每个词都是独立的。
BOW模型每个维度上的数值代表ID对应的词在句子里出现的频次。上例中两句话的BOW模型向量化向量化分别表示为[1,2,1,1,1,0,0,1]和[0,1,1,1,0,1,1,0].
BOW模型与one-hot表示相比存在的缺点如下。
1. 维数高和稀疏性:不能保留词语在句子中的位置信息,如“我为你鼓掌”和“你为我鼓掌”向量化结果依然没有区别。
2. 不能保留语义:当语料增加时,维数也会增大,一个文本里不出现的词就会增多,导致矩阵稀疏。
2.3 TF-IDF表示
TF-IDF表示是用一个向量表示一个句话或一个文档,它的表示过程如下。 首先TF-IDF是在BOW的基础上对词出现的频次赋予TF-IDF权值。 其次对BOW模型进行修正,进而表示该词在文档集合中的重要程度。
3 文本分布式表示
文本分布式表示将每个词个根据上下文从高维空间映射到一个低纬度、稠密的向量上。分布式表示的思想是词的语义是通过上下文信息确定的,即相同语境出现的词,其语义也相近。 分布式表示的优点是考虑到了词之间存在的相似关系,减小了词向量的维度。常用的方法有基于矩阵的分布表示、基于聚类的分布表示和基于神经网络的分布表示。
分布式表示与one-hot表示对比,在形式上,one-hot表示的词向量是一种稀疏词向量,其长度就是字典长度,而分布式表示是一种固定长度的稠密词向量;在功能上,分布式的最大特点是相关或相似的词在语义上距离更近。
3.1 WordVec模型
Word2Vec模型是简单化的神经网络模型。随着深度学习技术的广泛应用,基于神经网络的文本向量化成为了nlp领域的研究热点。Word2Vec可以在百万数量级的词典和上亿的数据集上进行高效地训练;该工具得到的训练结果可以很好地度量词与词之间的相似性。
WordVec模型的输入是独热向量,根据输入和输出的模式不同,分为连续词袋模型(Continuous Bag-of-Words,CBOW)和跳字模型(Skip-Gram)。CBOW模型的训练输入是模一个特定词上下文对应的独热向量,而输出是这个特定词的概率分布。跳字模型和CBOW模型的思路相反。输入是特定词的独热向量,而输出是这个特定词的上下文的概率分布。CBOW对小模型语料库比较合适,而跳字模型在大型语料库中表现更好。
WordVec模型特点是,当模型训练好后,并不会使用训练好的模型处理新的任务,真正需要的是模型通过训练数据所学得的参数,如隐藏层的权重矩阵。
3.1.1 CBOW模型
CBOW模型根据上下文的词语预测目标词出现的概率。CBOW模型的神经网络包含输入层、隐藏层和输入层。输入层的输入的是某一个特定词上下文的one-hot向量。 输出层的输出是在给定上下文的条件下特定词的概率分布。 其模型结构如图所示。

3.1.1.1 CBOW模型的网络结构
假设某个特定词的上下文含C个词,词汇表中词汇量的大小为V,每个词都用one-hot向量表示,神经网络相邻层的神经元是全连接的。其网络结构如下。
输入层的含有C个单元,每个单元含V个神经元,用于输入V维one-hot向量。 隐藏层的神经元个数为 N ,在输入层中,每个单元到隐藏层连接权重值共享一个维的权重矩阵 W。输出层含有V个神经元,隐藏层到输出层连接权重为
维权重矩阵
![]() 。 输出层神经元的输出值表示词汇表中每个词的概率分布,通过softmax函数计算每个词出现的概率。
。 输出层神经元的输出值表示词汇表中每个词的概率分布,通过softmax函数计算每个词出现的概率。
3.1.1.2 CBOW模型的数字形式
CBOW模型的简单形式:
假定预测目标值只有一个词,模型是在只有一个上下文的情况下预测一个目标词。 此时CBOW模型的结构如下图所示。

模型的输入为一个V维one-hot词向量,输出也是一个V维向量。 它包含了V个词的概率,每一个概率代表输入一个词的条件下输出词的概率。
CBOW模型的一般形式:
假设给定了一个输入x(one-hot向量),则隐藏层输出表达式可表示为![]() 。输出层每个神经元的输入表达式为
。输出层每个神经元的输入表达式为![]() 。其中
。其中![]() 是矩阵
是矩阵![]() 的第j列向量。 词汇表中的词用字母w表示,
的第j列向量。 词汇表中的词用字母w表示,表示实际输入的词,
表示目标词,词汇表中第j个词用
表示,条件概率p(
=
|
)表示输入词为
,目标词为
的概率。 当输入词为
,词汇表中每个词为目标词的概率式如下。

3.1.1.3 CBOW模型的损失函数
CBOW模型输出的真实目标词的概率记为p( |
,
,⋯,
),训练的目的就是使这个概率最大,其表达式如下。

其中表示真实目标词在词汇表中的下标。在求解过程中,要求目标函数的最小值,因此,损失函数的表达式定义如下。
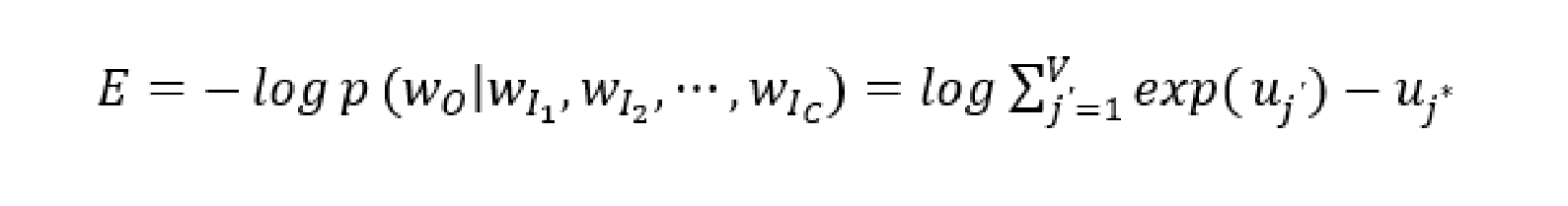
3.1.1.4 CBOW模型学习步骤
假设词向量空间维度为V,上下文词的个数为C,词汇表中的所有词都转化为one-hot向量,CBOW模型的学习步骤如下。
初始化权重矩阵W(V×N矩阵,N为人为设定的隐藏层单元的数量),输入层的所有one-hot向量分别乘以共享的权重矩阵W,得到隐藏层的输入向量。
隐藏层的输入向量求平均作为隐藏层的输出。
隐藏层的输出向量乘以权重矩阵(N×V矩阵),得到输出层的输入向量。
输入向量通过激活函数处理得到输出层的概率分布。
计算损失函数。
更新权重矩阵。
3.1.2 Skip-Gram模型
Skip-Gram模型与CBOW模型相反,是根据目标词预测其上下文。其结构图如图所示。

3.1.2.1 Skip-Gram模型的结构
假设词汇表中词汇量的大小为V,隐藏层的大小为N,相邻层的神经元是全连接的,Skip-Gram模型的结构组成如下。
输入层含有V个神经元,输入是一个V维one-hot向量。 输入层到隐藏层连接权重是一个V×N维的权重矩阵W。 输出层含有C个单元,每个单元含有V个神经元,隐藏层到输出层每个单元连接权重共享一个N×V维权重矩阵W^。 输出层每个单元使用softmax函数计算得到上下文的概率分布。
3.1.2.2 Skip-Gram模型的数字形式
假设给定一个输入x,则隐藏层的输出为一个N维向量,表达式为ℎ=W。 输出层有C×V个输出神经元,每个神经元节点的净输入则表示为
,其中
为输出层第c个单元的第j个神经元的净输入,
是矩阵
的第j列向量。 由于每个输出单元共享相同的
,所以每个单元的第j个神经元的净输入相同,即
=
. 最终可得输出层第c个单元,第j个神经元的输出表达式如下。
![]()
3.1.2.3 Skip-Gram模型的损失函数
模型训练的目标是,给定一个特定词,使得输出的C个单元为实际的C个上下文的概率最大,即最大化条件概率,其表达式如下。
![]()
Skip-Gram模型的损失函数定义式如下。其中,是第c个单元上的词在词汇表中的索引。

3.2 Doc2Vec模型
Word2Vec模型获取一段文本的向量,是先对文本分词,提取文本的关键词,用Word2Vec获取这些关键词的词向量,然后计算这些关键词向量的平均值,然而,这种方法只保留了句子或文本中词的信息,缺丢失了文本中的主题信息。为此,有研究者在Word2vec的基础上提出了文本向量化Doc2Vec模型。
Doc2Vec模型与Word2Vec模型类似,只是在Word2Vec模型输入层增添了一个与词向量同维度的段落向量,可以将这个段落向量看作是另一个词向量。 Doc2Vec存在如下两种模型。 分布式记忆模型(Distributed Memory,DM),对应Word2Vec模型里的CBOW。 分布式词袋模型(Distributed Bag of Words,DBOW),对应Word2Vec模型中的Skip-gram模型。
3.2.1 DM模型
DM模型与CBOW模型类似,在给定上下文的前提下,试图预测目标词出现的概率,只不过DM模型的输入不仅包括上下文而且还包括相应的段落。假设词汇表中词汇量的大小为 VV,每个词都用one-hot向量表示,神经网络相邻层的神经元是全连接的
DM模型的网络结构如下。
- 输入层含1个段落单元, C个上下文单元,每个单元有 d 个神经元,用于输入 d 维one-hot向量。
- 隐藏层的神经元个数为 h,段落单元到隐藏层链接权重为
维矩阵 V×h,每个上下文单元到隐藏层连接权重值共享一个 C×h 维的权重矩阵
。
- 输出层含有 V 个神经元,隐藏层到输出层连接权重为
维权矩阵 h×V。
- 通过softmax函数计算输出层的神经元输出值。
DM模型增加了一个与词向量长度相等的段落向量即Paragraph ID,从输入到输出的计算过程如下,结构如图所示。

Paragraph ID通过矩阵 Wp 映射成段落向量。段落向量和词向量的维数虽然一样,但是代表了两个不同的向量空间。每个段落或句子被映射到向量空间中,可以用矩阵 Wp 的一列表示。上下文通过矩阵 Wc 映射到向量空间,用矩阵 Wc的一列表示。将段落向量和词向量求平均或按顺序拼接后输入Softmax层。
3.2.2 DBOW模型
与Skip-gram模型只给定一个词语预测上下文概率分布类似,DBOW模型输入只有段落向量,DBOW模型通过一个段落向量预测段落中随机词的概率分布。其结构如图所示。

DBOW模型的训练方法忽略输入的上下文,让模型去预测段落中的随机一个词,在每次迭代的时候,从文本中采样得到一个窗口,再从这个窗口中随机采样一个词作为预测任务并让模型去预测,输入就是段落向量。
Doc2Vec模型主要包括以下两个步骤。 训练模型。在已知的训练数据中得到词向量 、各参数项和段落向量或句子向量 。 推断过程。对于新的段落,需要得到它的向量表达。 DM模型与CBOW模型相对应,可以根据上下文词向量和段落向量预测目标词的概率分布。DBOW模型与Skip-gram模型对应,只输入段落向量,预测从段落中随机抽取的词组概率分布。总而言之,Doc2vec是Word2Vec的升级,Doc2vec不仅提取文本的语义信息,而且提取了文本的语序信息。
4. Word2Vec词向量的训练
4.1 中文语料预处理
训练词向量需要有一个大量的语料库,本节使用维基百科的中文网页数据做为训练语料库。 预处理主要包含以下三个步骤。 将维基百科提供的xml格式的语料文件读入后存储为txt格式。 将繁体字转化为简体字。 利用jieba库对语料库中的句子进行分词。
4.2 词向量训练
当中文语料预处理完成后,使用gensim库训练词向量。 由于维基百科的语料数据较多,所以对它进行数据预处理和训练时需要等待较长的时间。在代码中设置判断语句,如果训练好的模型存在则不需要再训练。
4.3 代码实现
import re
import pandas as pd
import jieba
from gensim.models import Word2Vec
from gensim.models.word2vec import LineSentence# 读取CSV文件
data = pd.read_csv('news.txt', header=None)
data.columns = [ 'contents']# 数据预处理
data_dup = data.drop_duplicates(subset='contents')# 分词
data_cut = data_dup['contents'].astype('str').apply(lambda x: list(jieba.cut(x)))# 去停用词
stopword = pd.read_csv('stopword.txt', header=None, encoding='utf-8', engine='python', on_bad_lines='skip')
stopword_set = set(stopword[0] + ['']) # 直接使用集合提高查找效率# 去除停用词和空白字符
data_qustop = data_cut.apply(lambda x: [i for i in x if i not in stopword_set and i not in ['\u3000', '\xa0']])# 保存处理后的数据到CSV
data_qustop.to_csv('data_qustop.csv', index=False)def get_word2vec_trainwords(data_qustop):with open('word2vec_train_words.txt', 'w', encoding='utf-8') as f:for text in data_qustop:f.write(' '.join(text) + '\n')print(f'已处理 {text.count(" ") + 1} 条数据')# 调用函数生成训练数据
get_word2vec_trainwords(data_qustop)# 使用word2vec模型训练词向量
with open('word2vec_train_words.txt', 'r', encoding='utf-8') as news:model = Word2Vec(LineSentence(news), sg=0, vector_size=192, window=5, min_count=5, workers=9)# 打印特定词的词向量
print(model.wv['中国'])代码随需文件在顶部,注意将代码和文件放在同一目录下。
代码结果如下:
D:\ana\envs\nlp\python.exe D:\pythoncode\nlp\word.py
Building prefix dict from the default dictionary ...
Loading model from cache C:\Users\86130\AppData\Local\Temp\jieba.cache
Loading model cost 0.379 seconds.
Prefix dict has been built successfully.
已处理 1 条数据
已处理 1 条数据
已处理 1 条数据
已处理 1 条数据
已处理 2 条数据
已处理 1 条数据
已处理 1 条数据
已处理 1 条数据
[-7.0224394e-04 -3.1521432e-03 1.5586118e-03 -2.3781818e-042.4512981e-03 -1.1890735e-03 -2.1551263e-03 1.1864057e-034.3512415e-03 -2.6018780e-03 1.3899369e-03 -4.1617472e-03-3.5277847e-03 -2.4357748e-04 -4.5665246e-03 1.4528321e-038.3260174e-04 -1.2081731e-03 2.6061411e-03 5.0774929e-034.4032647e-03 -9.7928382e-04 1.0719541e-03 -2.0852548e-03-4.2923987e-03 3.2697686e-03 -1.0151988e-03 -3.4698160e-04-9.2256878e-04 -2.3623258e-03 2.1154738e-03 -2.2240523e-03-4.9888263e-03 4.6578725e-03 2.1693066e-03 4.8097577e-033.4601577e-03 1.5233004e-03 5.1062605e-03 -2.3045007e-03-3.5433911e-03 2.2017609e-03 1.9421875e-03 -2.9503182e-035.0545628e-03 -1.8532848e-03 4.9736495e-03 4.3475316e-04-3.3012796e-03 -1.0297485e-03 -3.8422160e-03 -1.5518349e-035.4255064e-04 4.9389000e-03 4.8728376e-03 -3.4353528e-031.8099746e-03 1.1851931e-03 -1.2965376e-03 -4.8068608e-035.3496164e-04 -4.2529721e-03 3.2917652e-03 -3.0208752e-032.8830413e-03 5.1217307e-03 -8.3333500e-05 2.3585900e-03-9.4239600e-04 3.8337298e-03 2.0521339e-03 -4.6928772e-03-1.2492208e-03 1.8899838e-03 -5.1858526e-05 -6.2566187e-04-5.4970756e-04 -8.7062578e-04 3.1507947e-04 2.1693204e-03-2.2149954e-03 -1.9966781e-03 -2.7508786e-05 1.4028947e-04-8.7919958e-05 -2.4924513e-03 2.2465636e-03 -1.1312080e-031.0955936e-03 3.4714738e-04 3.1092067e-03 -3.5637401e-03-3.5498489e-03 -2.3313842e-03 4.9144942e-03 -8.2910556e-04-4.9110637e-03 -2.8387582e-04 -2.3171473e-03 3.1250410e-03-4.9915030e-03 1.4890631e-03 -4.8191831e-03 6.5093796e-043.1245823e-03 3.8527853e-03 -3.9695124e-03 -3.1526163e-03-3.5616879e-03 -4.1241352e-03 -4.9474374e-03 -1.1070296e-03-4.3538152e-04 -3.7792716e-03 3.5349149e-03 5.8313523e-043.0358683e-03 7.6711801e-04 4.1112801e-04 -3.8375675e-03-1.1336760e-03 2.2505622e-03 -2.6486013e-03 5.8895285e-041.5017521e-03 -8.0018799e-04 5.1730704e-03 4.3487679e-031.2581596e-03 3.7074194e-03 3.0684571e-03 -2.9065714e-03-2.6855431e-03 -3.4730926e-03 -4.0504350e-03 4.3285042e-03-1.0324698e-03 -3.5702933e-03 -2.1637443e-03 2.6792325e-03-1.4943419e-03 -1.9529480e-03 8.4449229e-04 -1.4459863e-03-8.2518783e-04 5.5963109e-04 -1.5510129e-03 4.4371262e-032.0369452e-03 -5.1869079e-03 3.2602083e-03 -3.5178408e-034.0074624e-04 2.2938724e-03 -2.6580077e-03 -1.0993071e-034.2163953e-03 -2.2103086e-03 -3.9772191e-03 4.8218295e-03-1.1226548e-03 -2.4580378e-03 4.4639581e-03 2.2309057e-032.2525191e-03 4.8356839e-03 -4.4026463e-03 2.7371459e-031.0621622e-03 2.1813959e-03 8.8432309e-04 2.3250699e-032.3366094e-03 3.1794384e-03 -1.6677590e-03 -2.3831918e-03-2.2214402e-04 1.3196530e-03 -1.6995663e-03 3.1550613e-032.1636095e-03 4.0440583e-03 1.3381628e-03 4.2274389e-03-7.2250515e-04 4.2072539e-03 1.9359458e-03 -4.1913148e-03-2.0487576e-03 -1.2874367e-03 2.5484606e-03 -4.5424947e-04]进程已结束,退出代码为 0
5 Doc2Vec段落向量的训练
1. 数据预处理
定义一个类包含繁体字和简体字的转换操作和利用jieba库进行分词操作。 gensim库里的Doc2vec提供的LabeledSentence函数可以将文档标签(如类别)加入到文档向量的训练中,因此Doc2vec在训练时能够采用tags信息更好地辅助训练,相对于Word2Vec模型,这里的多了一个tags属性。
2.段落向量训练
当数据预处理完成后,使用gensim库训练段落向量。 Doc2Vec函数训练段落向量,第一个参数documents表示预处理后用于训练的语料;dm=0表示使用DBOW模型训练段落向量,dm=1则表示使用DM模型训练段落向量;参数size表示段落向量的维度,参数window、min_count、workers的含义与Word2Vec函数相同。