目录
1. PD架构
2. 路由功能
2. TSO
2.1 TSO 概念
2.2 TSO分配过程
2.3 TSO时间窗口
3. 调度
3.1 信息收集
3.2 生成调度(operator)
3.3 执行调度
4. Label 与高可用
4.1 Label 的配置
5. 小结
1. PD架构
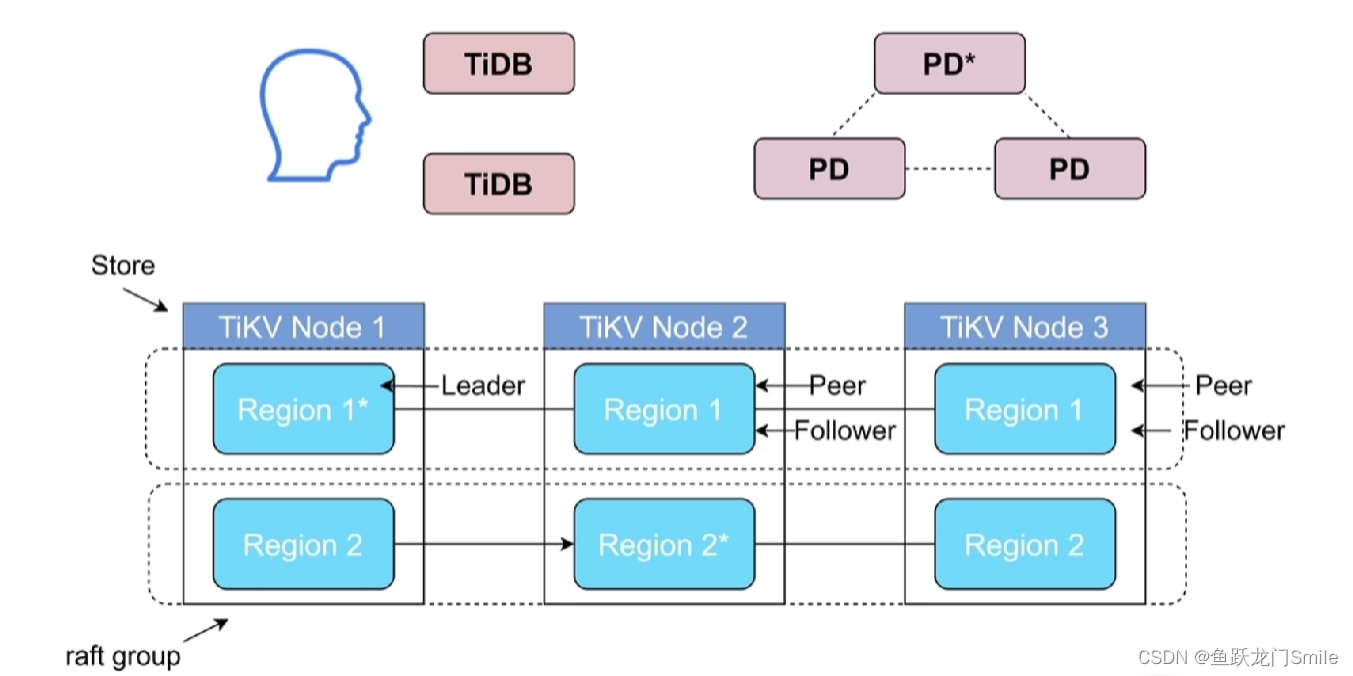
PD是整个TiDB的总控,相当于集群的大脑
PD集成了etcd,支持故障转移,无需担心单点故障
PD通过etcd raft,保证数据强一致性
一个TiKV Node(一个TiKV实例)就是一个store
一个Region的一个副本叫一个peer,一个Region包含多个peer
一个Region的多个副本构成raft group
多个raft group构成multi raft
PD主要功能
- 整个集群 TiKV 的元数据存储
- 分配全局 ID 和事务 ID(table id、index id)
- 生成全局时间戳 TSO
- 收集集群信息进行调度
- 提供 label,支持高可用
- 提供 TiDB Dashboard
2. 路由功能
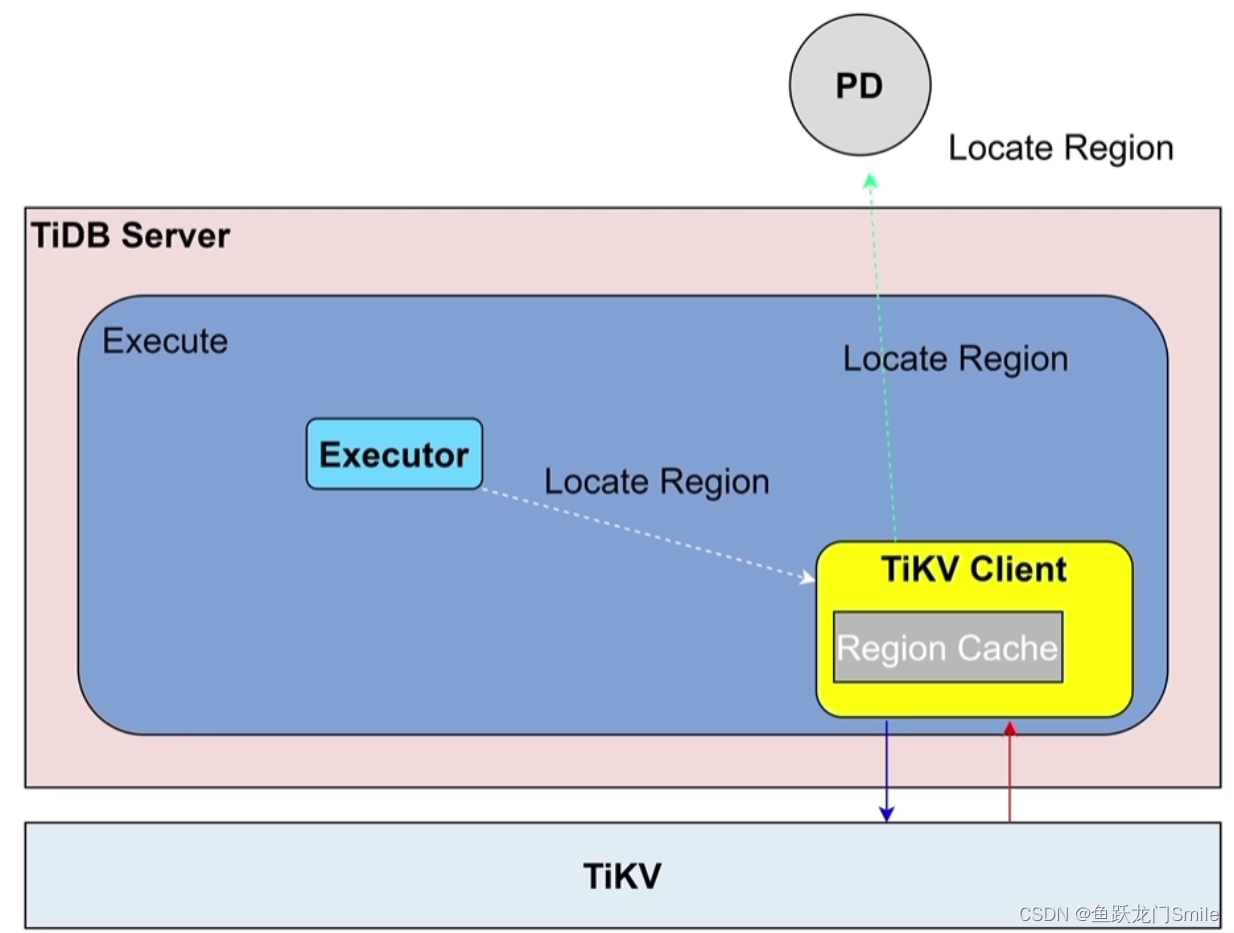
执行sql时,想要读取的数据的Leader在哪个TiKV,需要问PD
执行计划传到executor,然后把请求发给TiKv Client,然后去PD上找在哪个TIKV上的Region取数据,然后PD告诉TiKV Client去哪个TiKV上去数据,就发送请求到TiKV把数据读出来,如果每次都用Key这样去读数据网络压力就会大,那么将读取出来的位置(在哪个TiKV)缓存到TiKV Client(Region Cache)中,比如Key=100缓存到Region Cache中,下一次就不用去PD中找Key=100在哪个region,直接在Region Cache读取,如果要读Leader发生了改变,比如从TIKV node1变到TiKVnode 2去了,TIKV node1会说我不是Leader了,要到TiKV node 2去读取,这叫back off,back off越多,读取延迟越高。
2. TSO
2.1 TSO 概念
TSO(int64) = physical time(unix物理时间,精确到毫秒) logical time(逻辑时间,能把1ms分成262144个TSO)
2.2 TSO分配过程
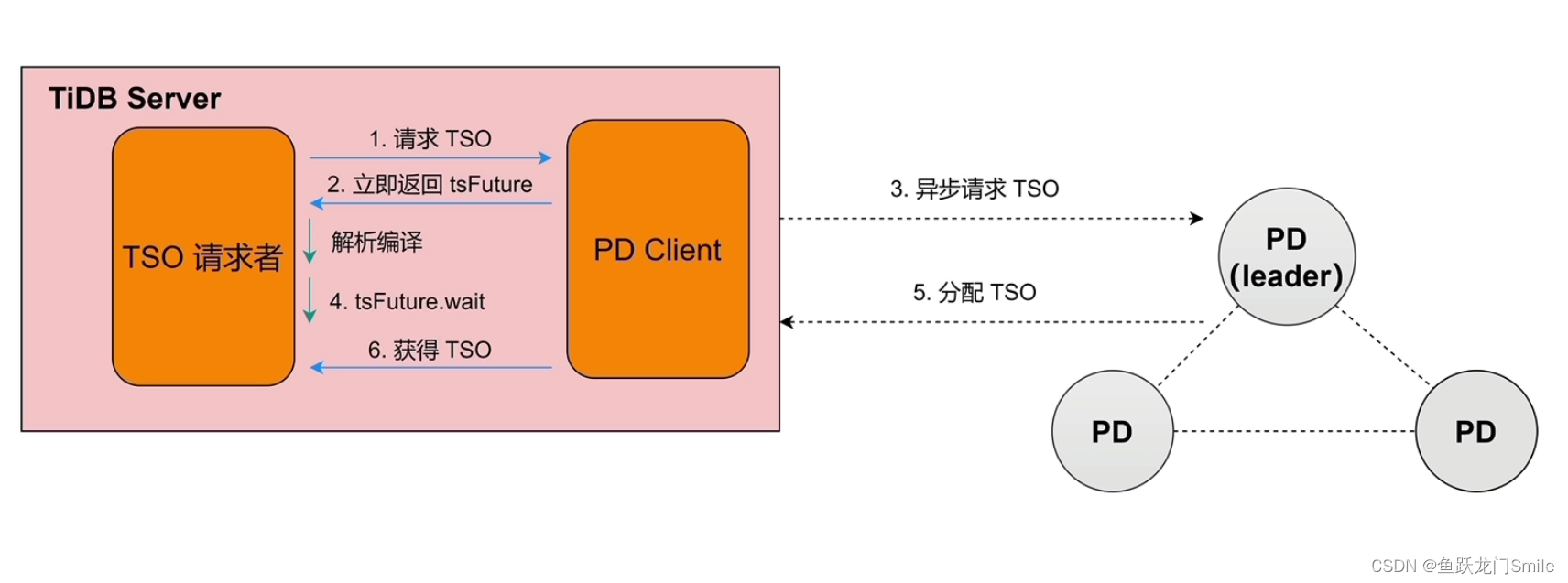
- 发送请求TSO给PD Client
- PD Client立即返回一个对象tsFuture(内存中的一个对象,标识了什么时刻请求了一个TSO)给TSO请求者,TSO请求者可以接着做解析编译生成执行计划
- 异步到PD Leader节点请求TSO,在PD Leader节点排队分配TSO,做完之后把TSO传回给PD Client
- 在请求的TSO来之前,如果解析编译完成了,tsFuture会调用tsFuture.wait方法等待TSO到来,如果PD Client在解析编译完成前就拿到了TSO则会时不时去看有没有调用tsFuture.wait方法,有的话就给TSO
- PD Client拿到TSO后,看见tsFuture.wait已经在等了,就立即把TSO给出来,这样一条sql语句既解析编译好了也拿到了TSO就可以开始执行了
每条sql每次都去请求PD拿TSO会造成性能下降,批处理可以解决,比如1ms内有100个会话去请求TSO,这时候PD Client就会把这100个会话的sql请求变成一个批处理请求。PD会有一个批处理的限定时间段,比如5ms所有的会话为一个批处理,如果这个5ms之内只有一条sql,也会去PD请求。
2.3 TSO时间窗口
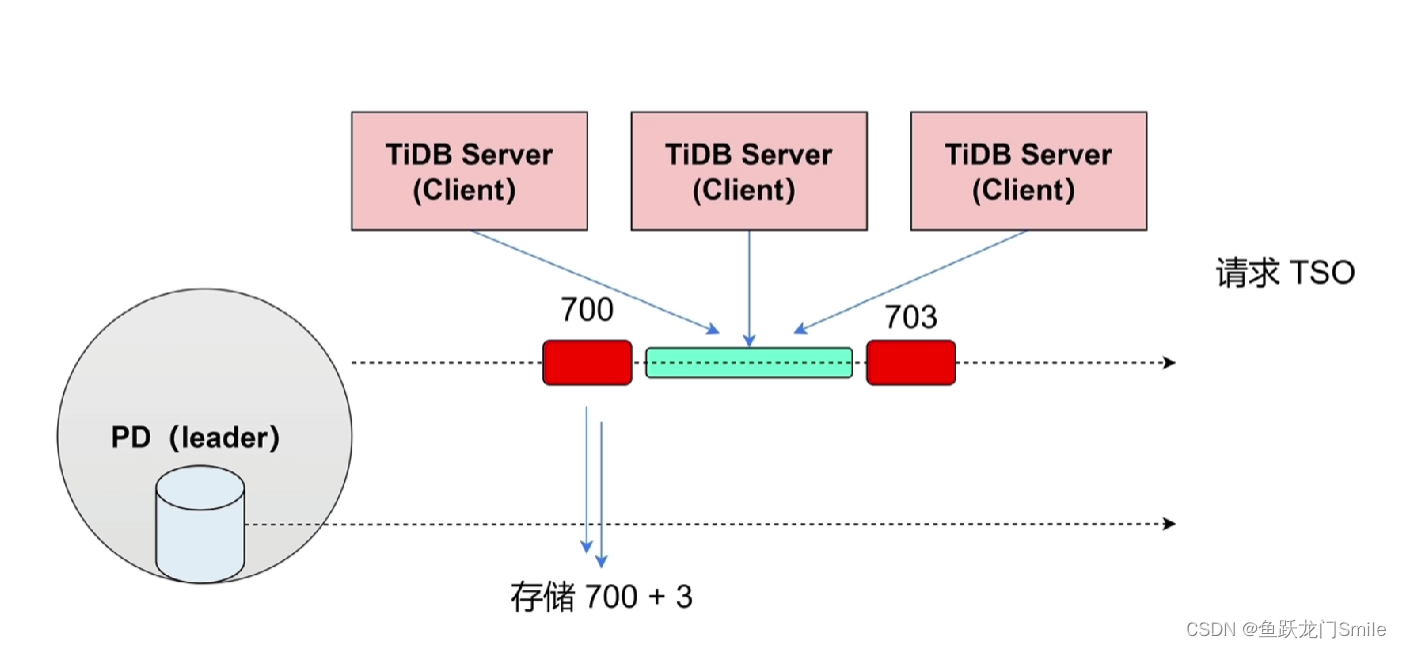
PD生成的TSO会存在PD的持久化存储中,会产生IO,会话sql越多,PD的IO压力越大。
为了解决IO压力大的问题,PD会先分配一段TSO在缓存中,比如分配3秒钟700~703在缓存中,此时持久化存储中TSO的开始时间是存的703,TiDB Server就到缓存中排队获取TSO,3秒都获取完了,再分配3秒706,所以时间窗口就是将一段TSO先分配到缓存供TiDB Server获取,减少PD IO压力。
假设此时TiDB Server最新一次请求获取的TSO是704,刚好Leader PD宕机了,缓存里面的703~706都丢了 ,选出的新Leader PD会从706开始分配706~709到缓存中,704~706的都丢了,会产生一个小的断层,这是TSO的高可用性。
3. 调度
总流程

3.1 信息收集
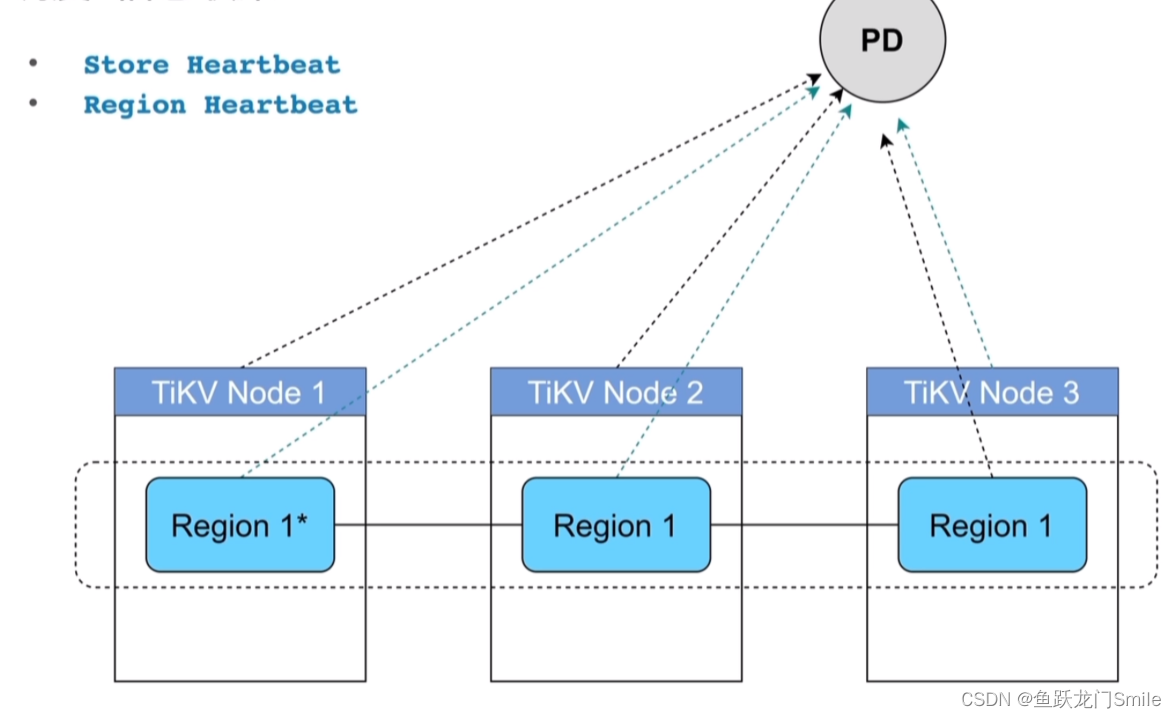
TiKV节点会周期性的去向PD报心跳,有两种心跳信息
- store hearbeat:当前的容量、剩余空间、读写流量
- region hearbeat:副本的分布状态、region读写流量
3.2 生成调度(operator)
- Balance
- Leader(主要是读写,是不是均衡分布在所有的TIKV上)
- Region(主要是存储压力,不要让某一个TiKV过多存储Region)
- Hot Region(打散热点Leader region,让其分布在多个节点)
- 集群拓扑
- 缩容
- 故障恢复
- Region merge(drop、delete、truncate等操作后,region较空,可以将空的regio进行合并)
3.3 执行调度
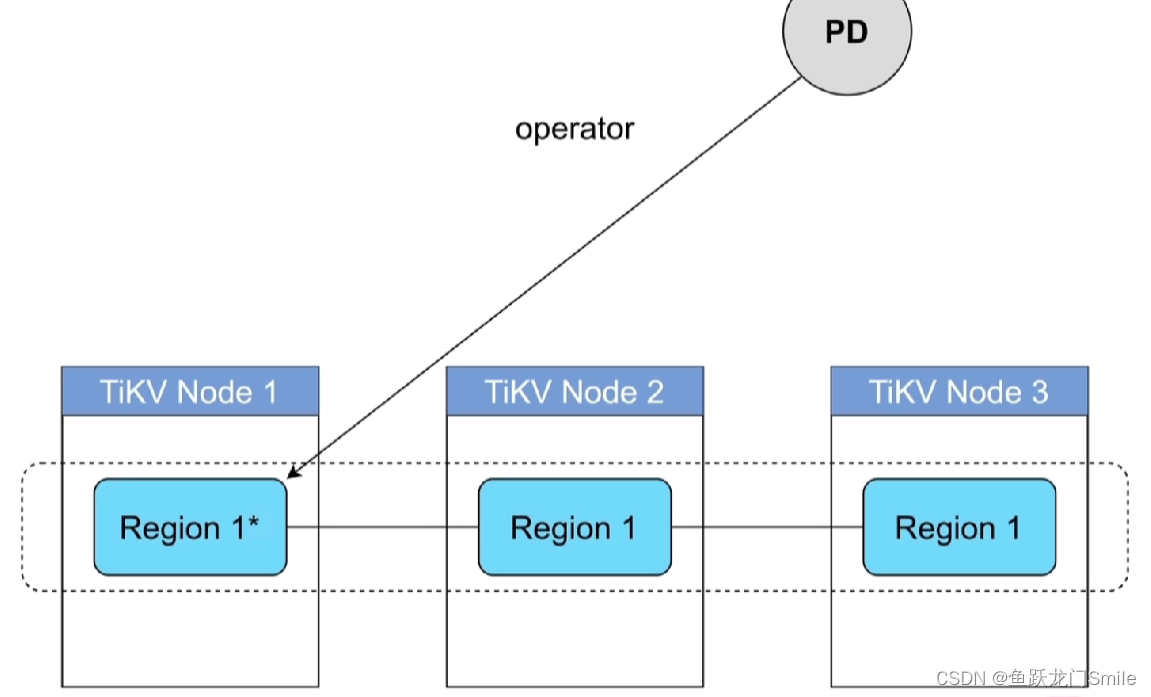
PD直接将operator发送给想要改动的region(有一个等待队列,从这个队列中按照设定的速度将operator发送给region) ,region接到operator后做相应的调整(分裂、合并,调到其他节点等等)。
4. Label 与高可用
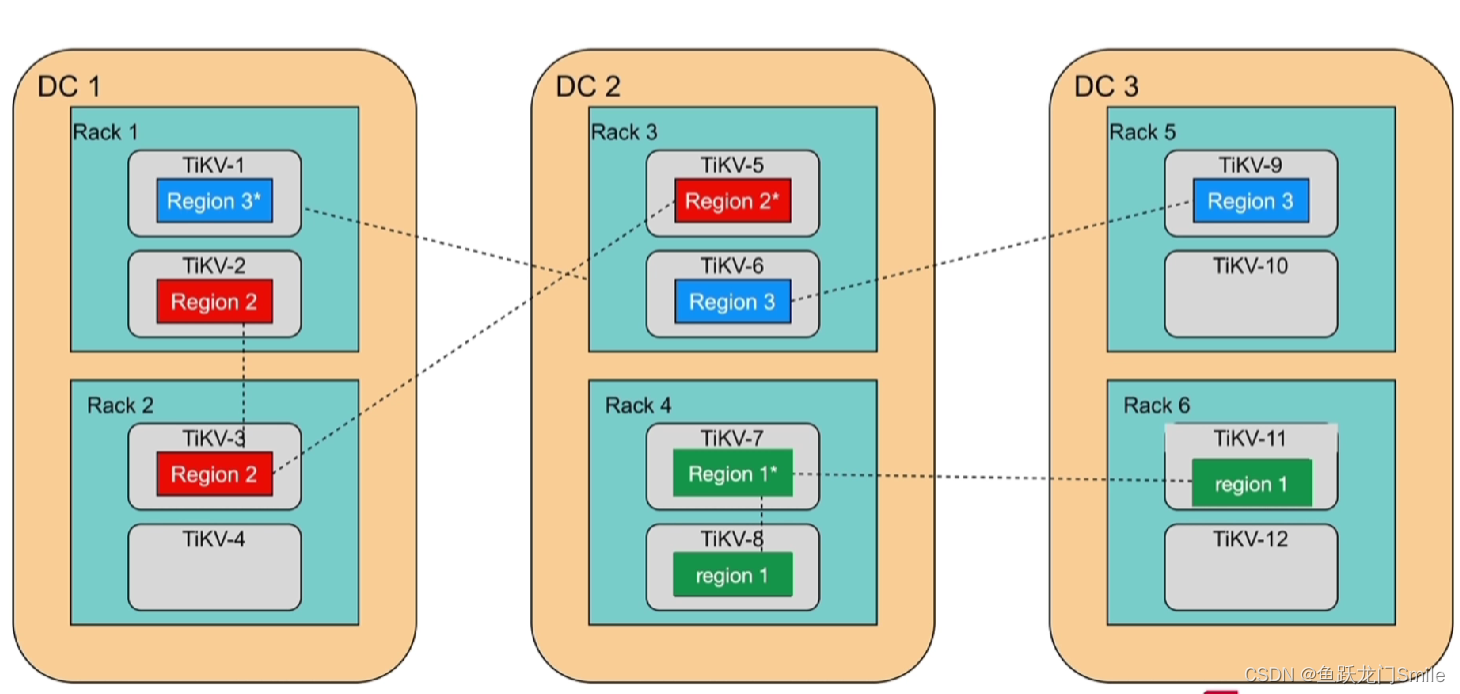
DC1、DC2、DC3是3个独立的数据中心,Rack是机柜,Rack中是TiKV服务器。
如果rack4或者DC2出问题了,Region1就可能不可用了(多数派不可用),如果DC1出问题了,Region2可能也不可用了,不管是坏一个机柜或者是坏一个数据中心都不影响Region3
如果元数据存在某个Region中,刚好这个Region不可用了,那么整个数据库就不可用了,PD节点只能保证同一个TiKV节点上不能有同时有一个Region的两个peer,不能保证其他分布,PD是通过Label来知道哪一个TiKV在哪一个DC和在哪一个Rack,Label是为了让PD感知集群的拓扑结构。
4.1 Label 的配置
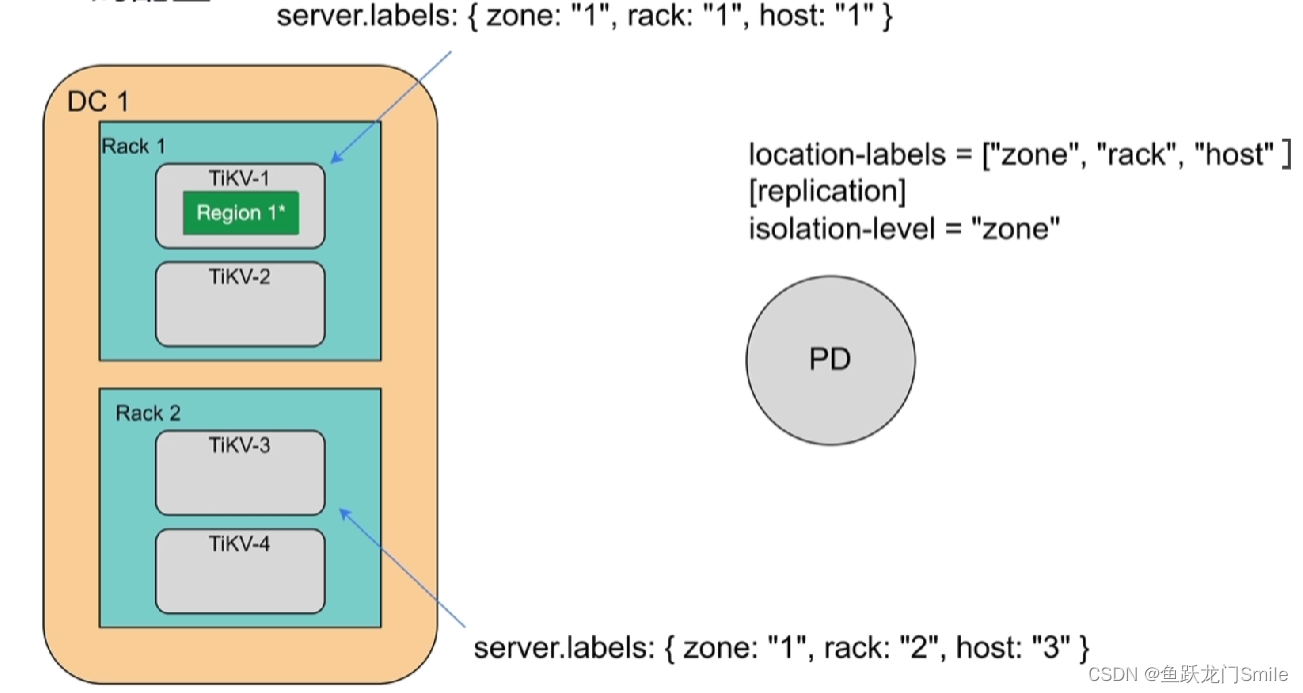
TiKV设置标签
server.labels: { zone: "1", rack: "2", host: "3" }
zone代表DC,rack代表Rack(机柜),host代表服务器(不同场景代表可能一样,有可能zone也代表机柜)
在PD这儿设置隔离级别参数
location-labels = ["zone", "rack", "host" ]
[replication]
isolation-level = "zone"(Region相同的副本在zone的这一层隔离)
5. 小结
- PD 的架构与原理
- TSO 的分配
- 调度的原理与实现
- label 与高可用的关系
来自TiDB官方资料