启动 elasticsearch(脚本)、kibana(bat脚本) 和 elasticsearch-head-master(npm run start)
1、RESTful 风格
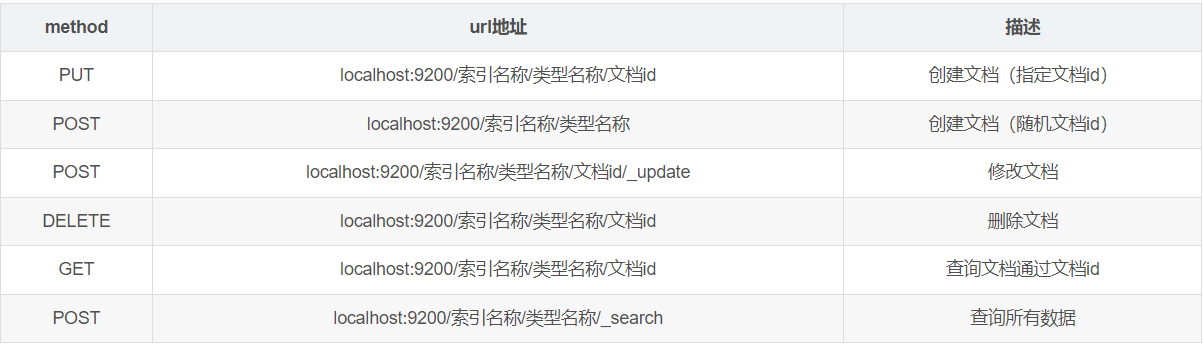
1.1、索引类基本操作
1.1.1、创建索引
PUT /索引名/类型名/文档id
{请求体}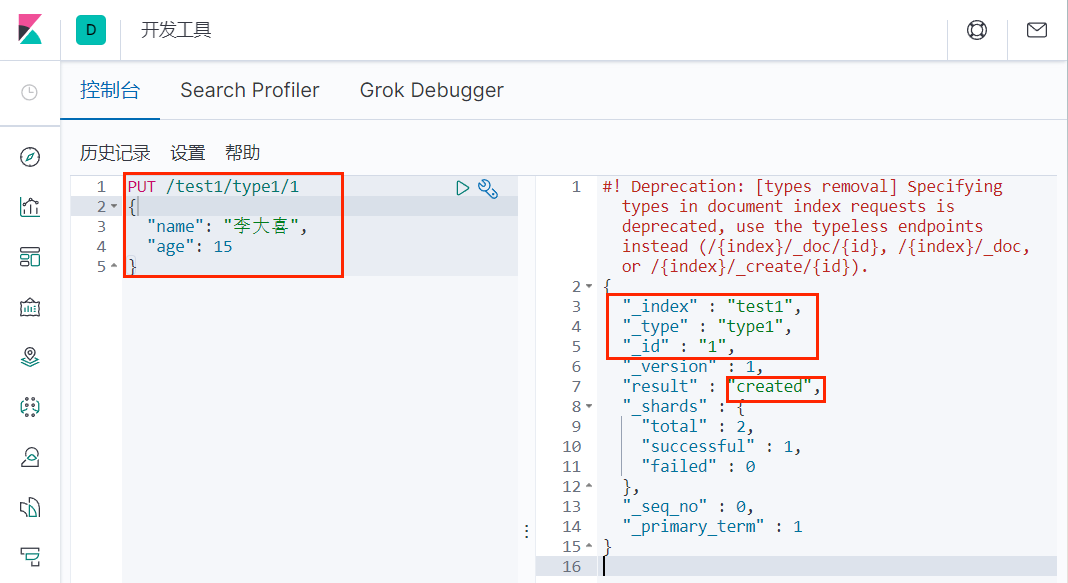
在 elasticsearch-head-master 查看:
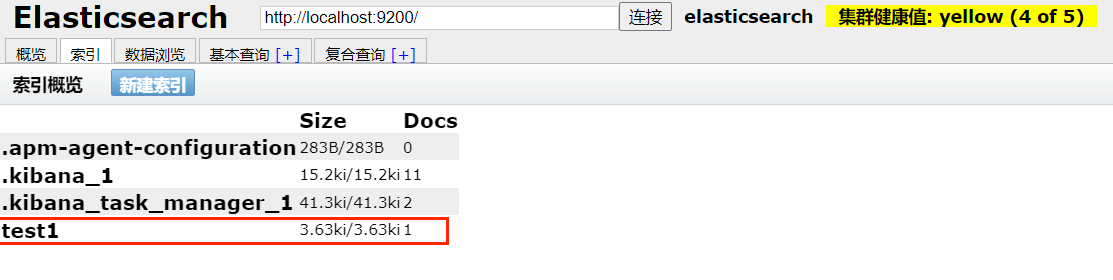
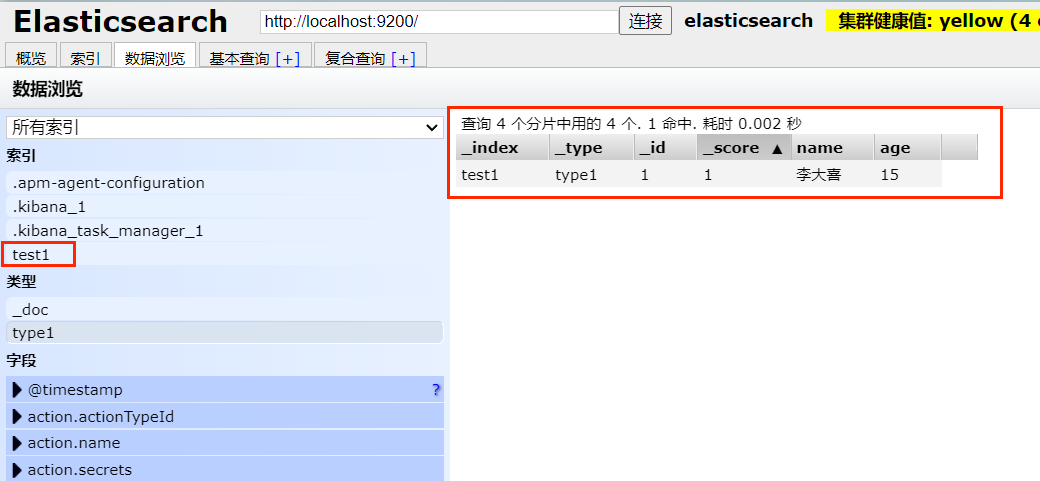
可以看到,索引 test1 被成功创建了 ,查看数据:
1.1.2、基本数据类型
- 字符串类型
text、keyword - 数值类型
long、integer、short、byte、double、float、half float、scaled float - 日期类型
date - 布尔值类型
boolean - 二进制类型
binary
创建索引的时候可以不指定索引规则(字段类型),es 会自动判断(只不过有时候可能判断错误)
1.1.3、创建索引时指定字段类型
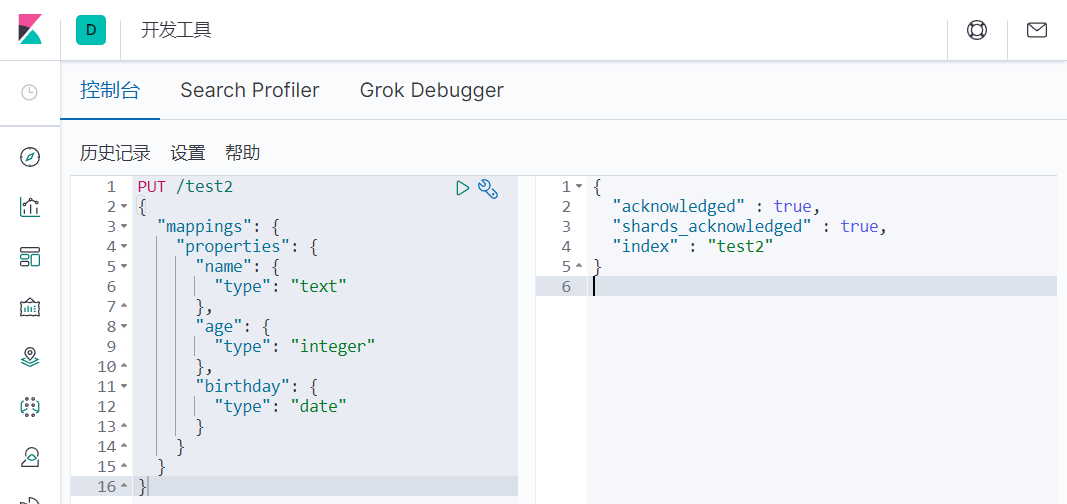
下面,我们创建一个索引,并指定索引规则:
1.1.4、获得索引规则信息
语法:
# 获得索引信息
GET 索引
# 获得文档信息
GET 索引/类型/文档id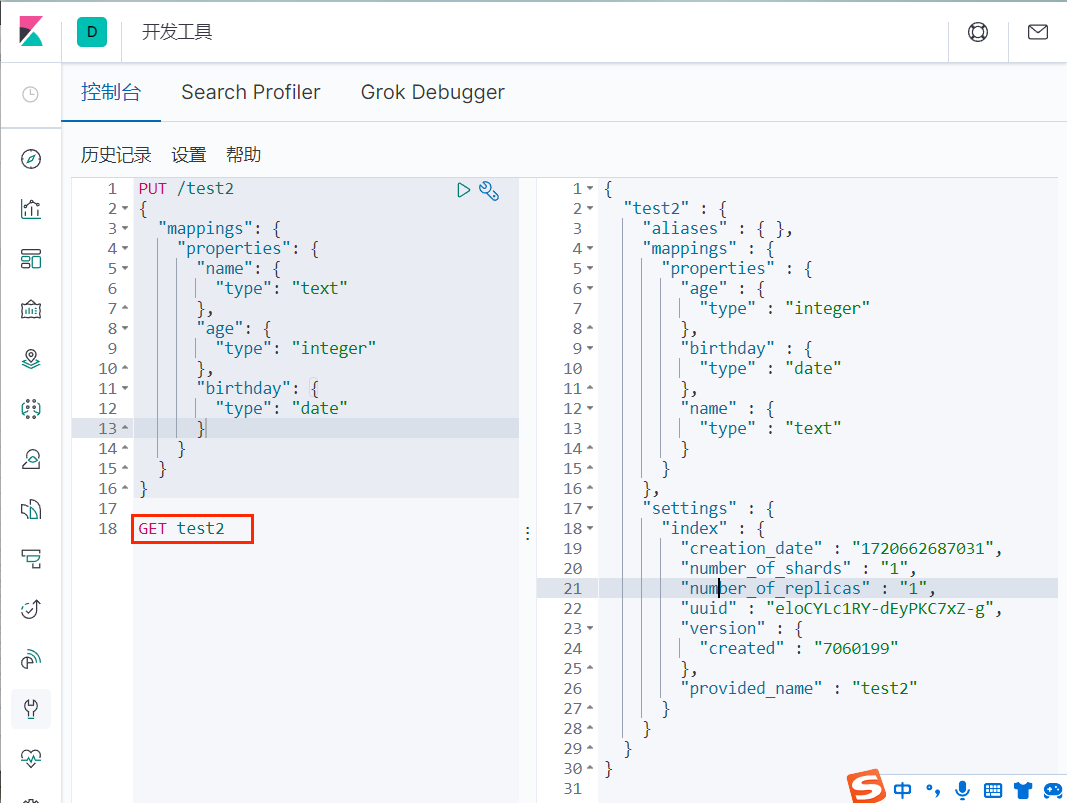
1.1.5、修改数据
1)使用 PUT 覆盖
修改 /test1/type1/1 中的 age 属性为 18:
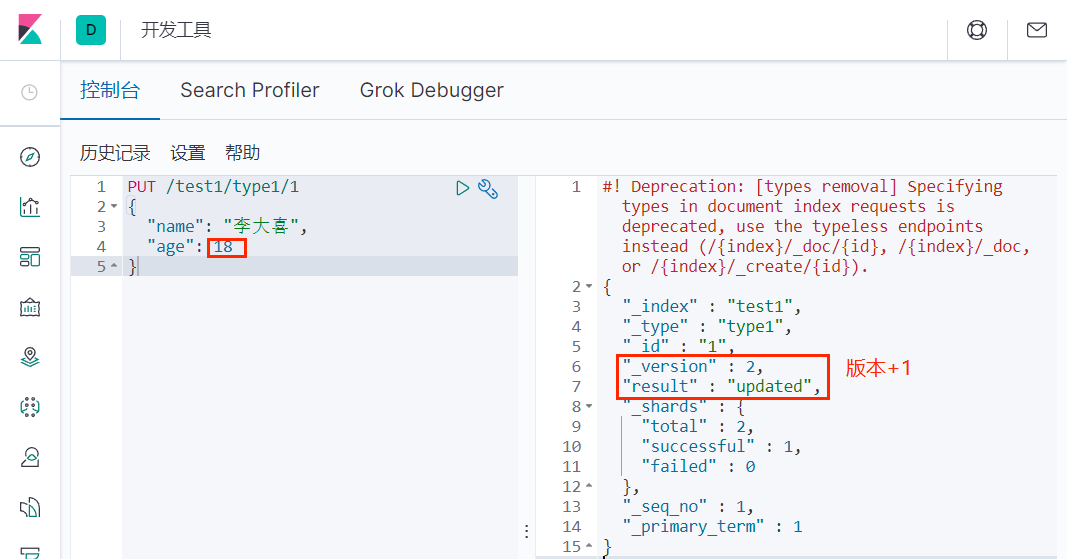
这种方法的一个缺点是,我们在覆盖的过程中可能会不小心漏掉一些字段,导致数据丢失。
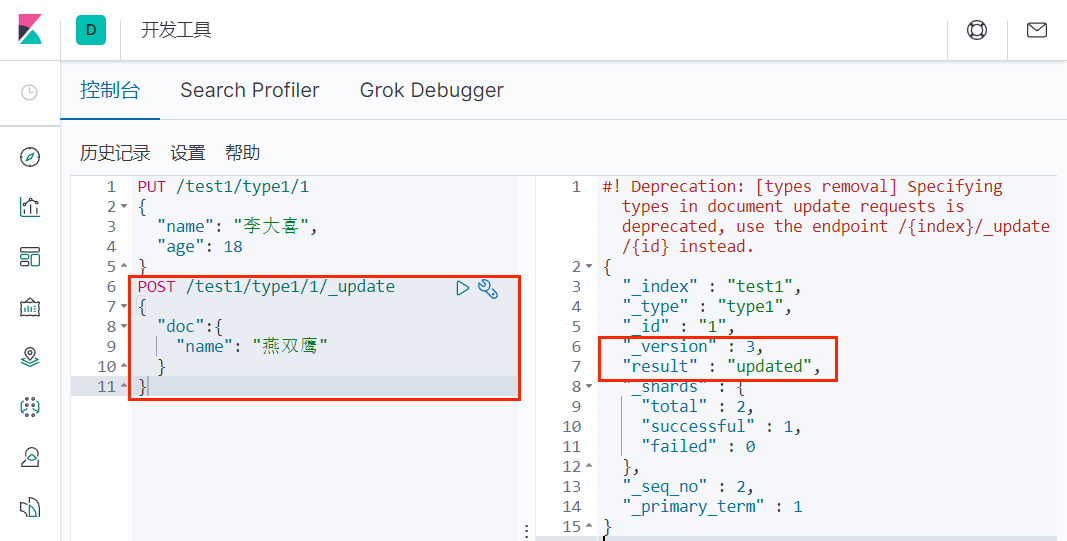
2)POST 更新文档
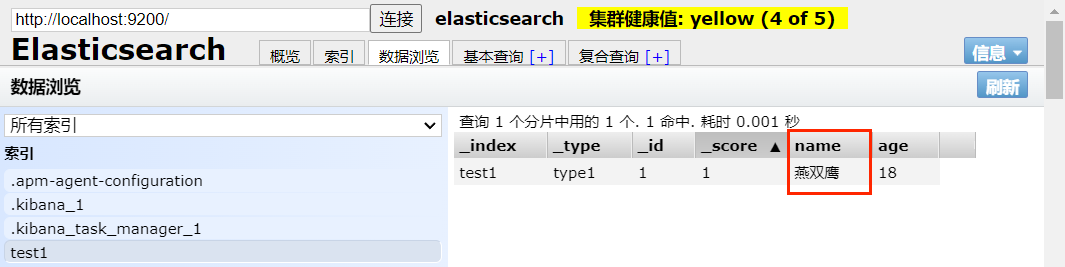
修改 /test1/type1/1 的 name 属性为 "燕双鹰"
1.1.6、删除索引
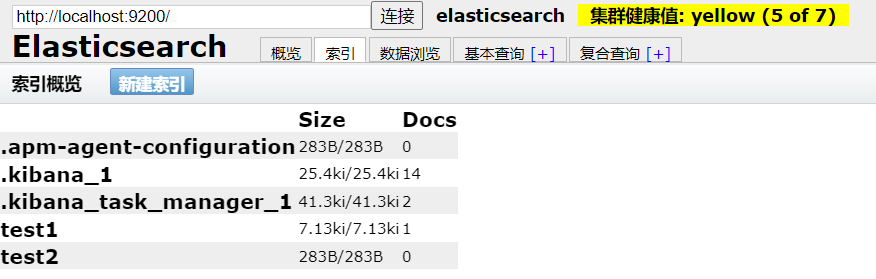
删除 test2 索引:
DELETE test2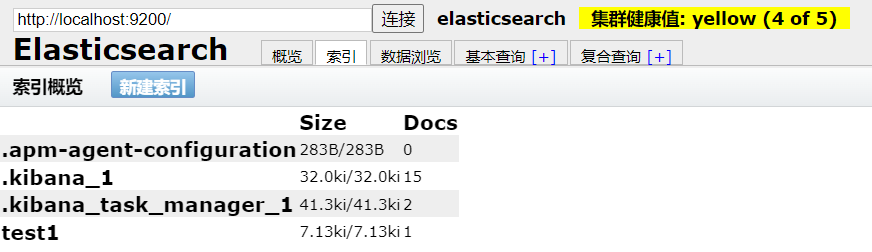
1.2、文档操作
1.2.1、基本操作
1、PUT 插入数据
PUT /lyh/user/1
{"name": "李大喜","age": 25,"desc": "只想做农民","tags": ["半人半鬼","神枪第一"]
}PUT /lyh/user/2
{"name": "谢永强","age": 20,"desc": "那啥,我去趟果园","tags": ["窝囊强","果园天尊"]
}
PUT /lyh/user/3
{"name": "曾泰","age": 45,"desc": "大人真乃神人也","tags": ["舔灵"]
}2、GET 查询数据
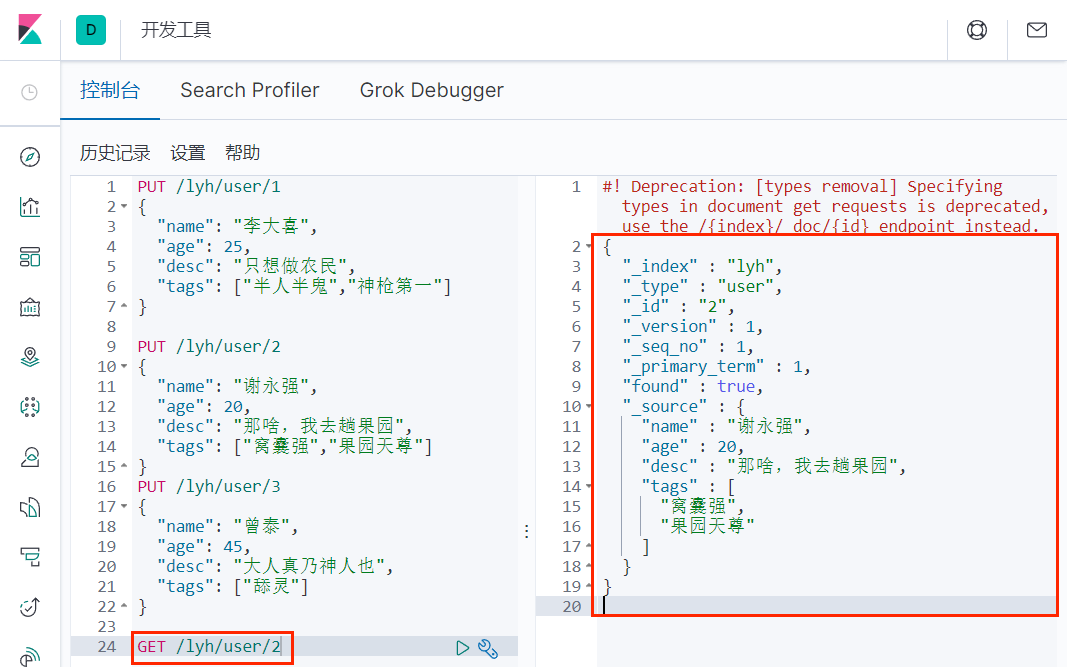
3、更新数据
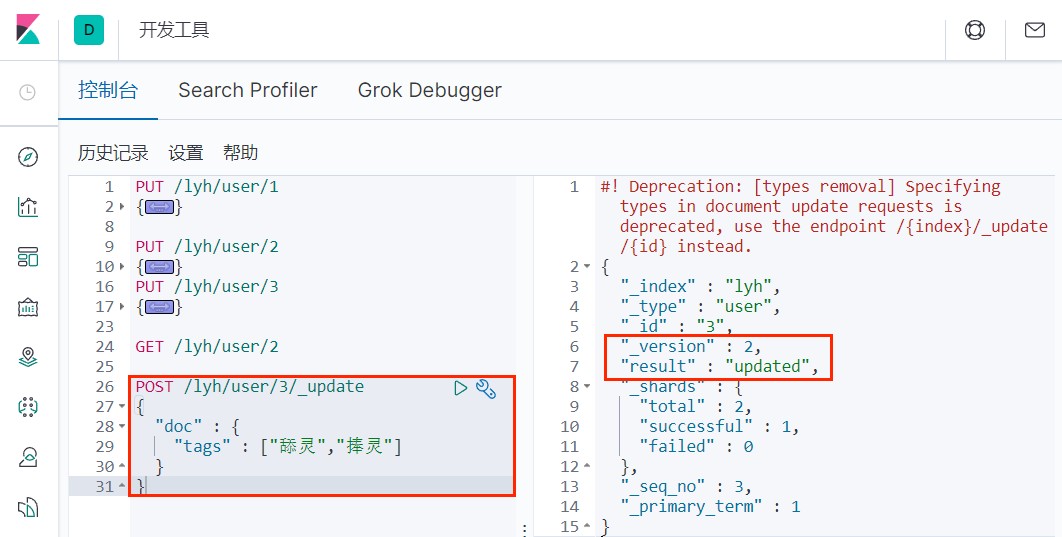
4、普通文档查询
GET /lyh/user/15、条件查询
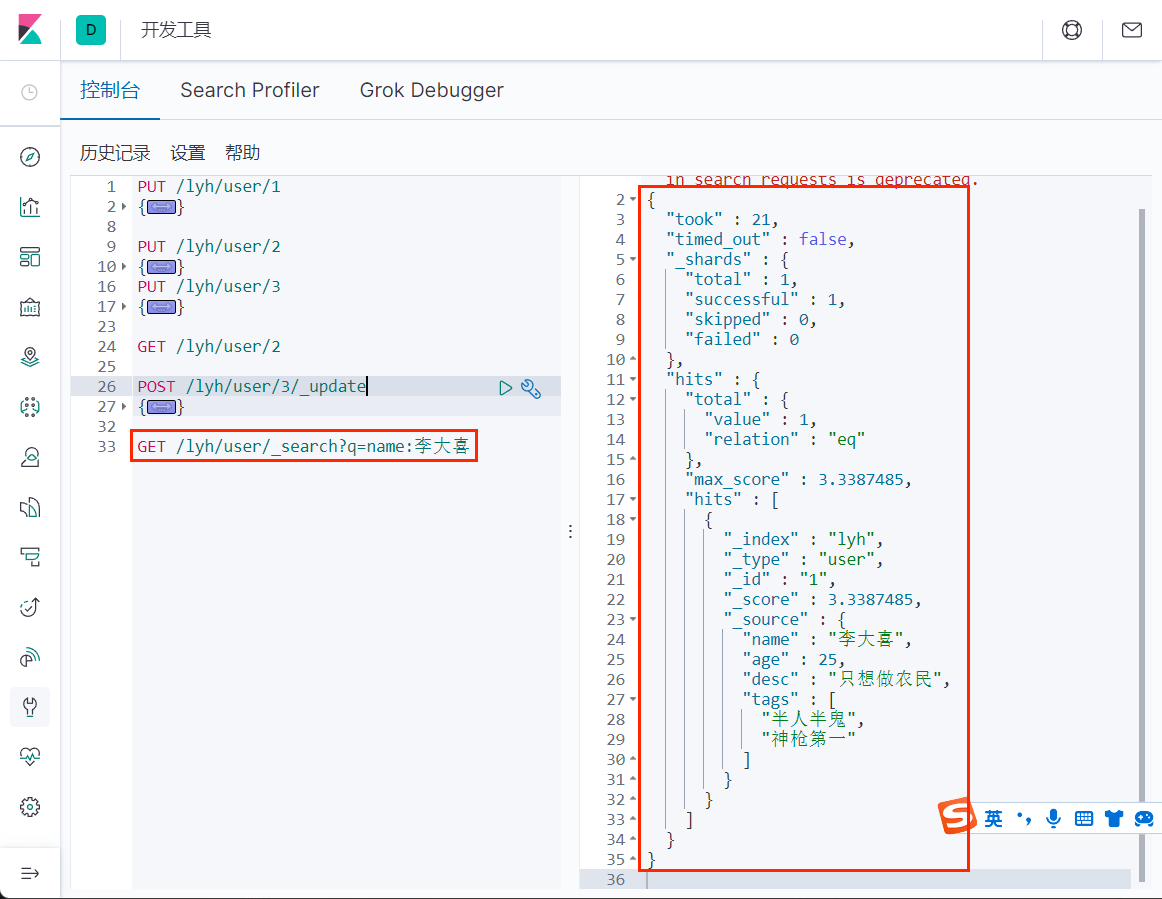
1.2.2、复杂查询
对比上面普通 GET 查询和条件查询可以看到,使用条件查询时返回的 JSON 中有一个 _score 字段,它代表的是匹配度,也就是权重,因为 es 返回的是权重最高的数据。
score(权重)
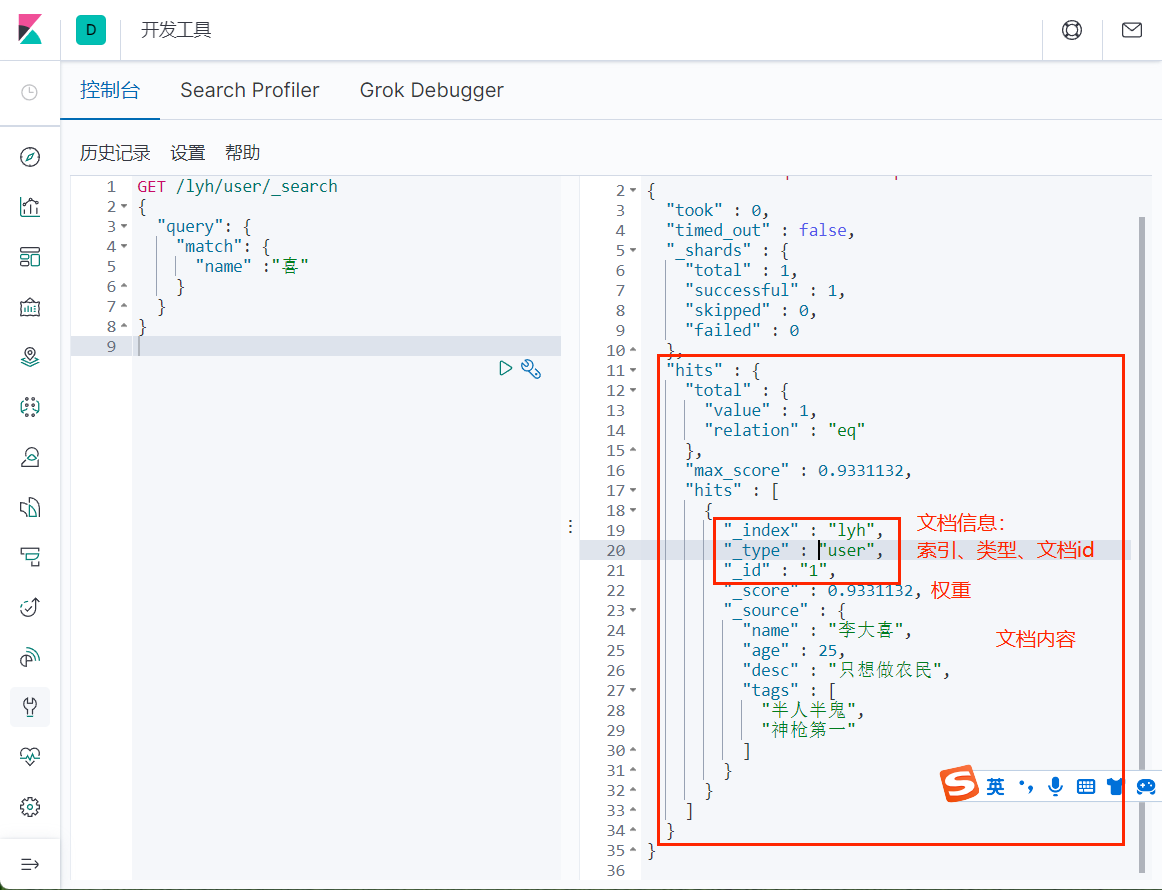
设置投影
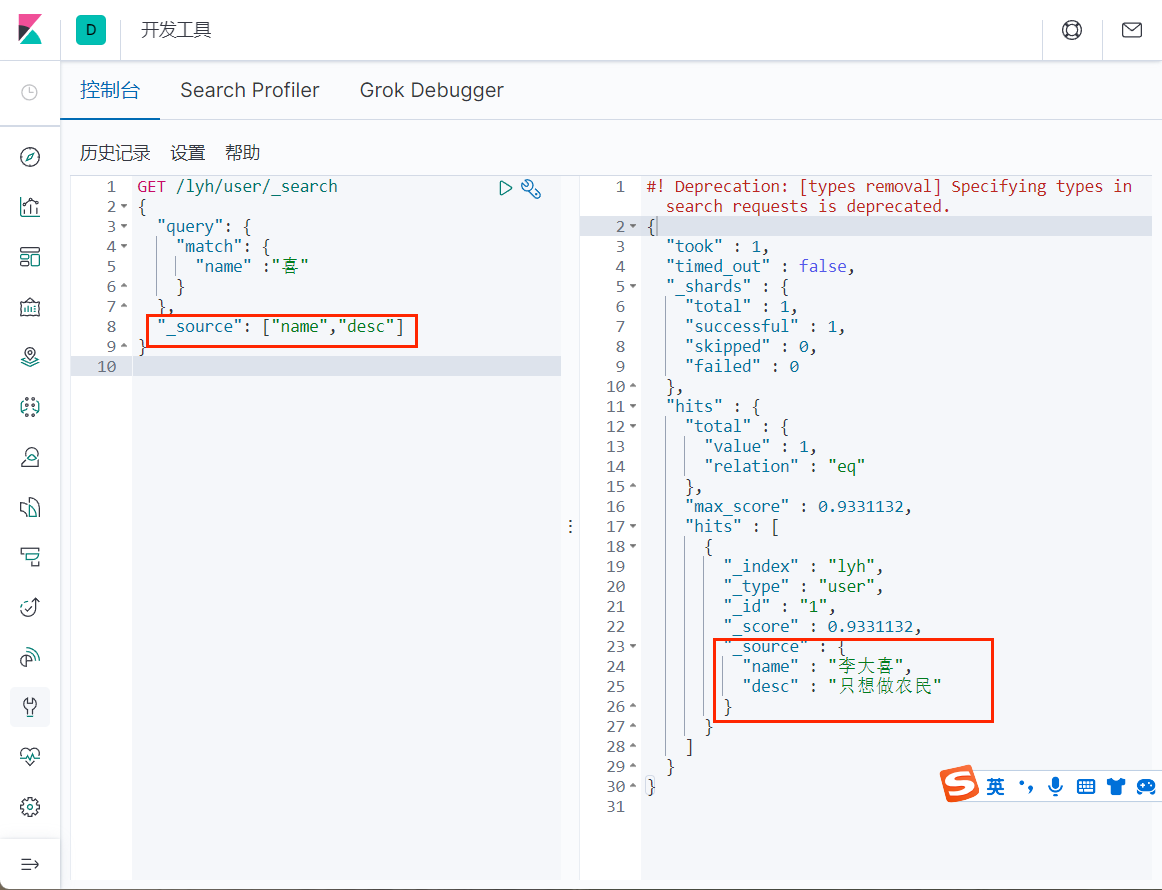
排序
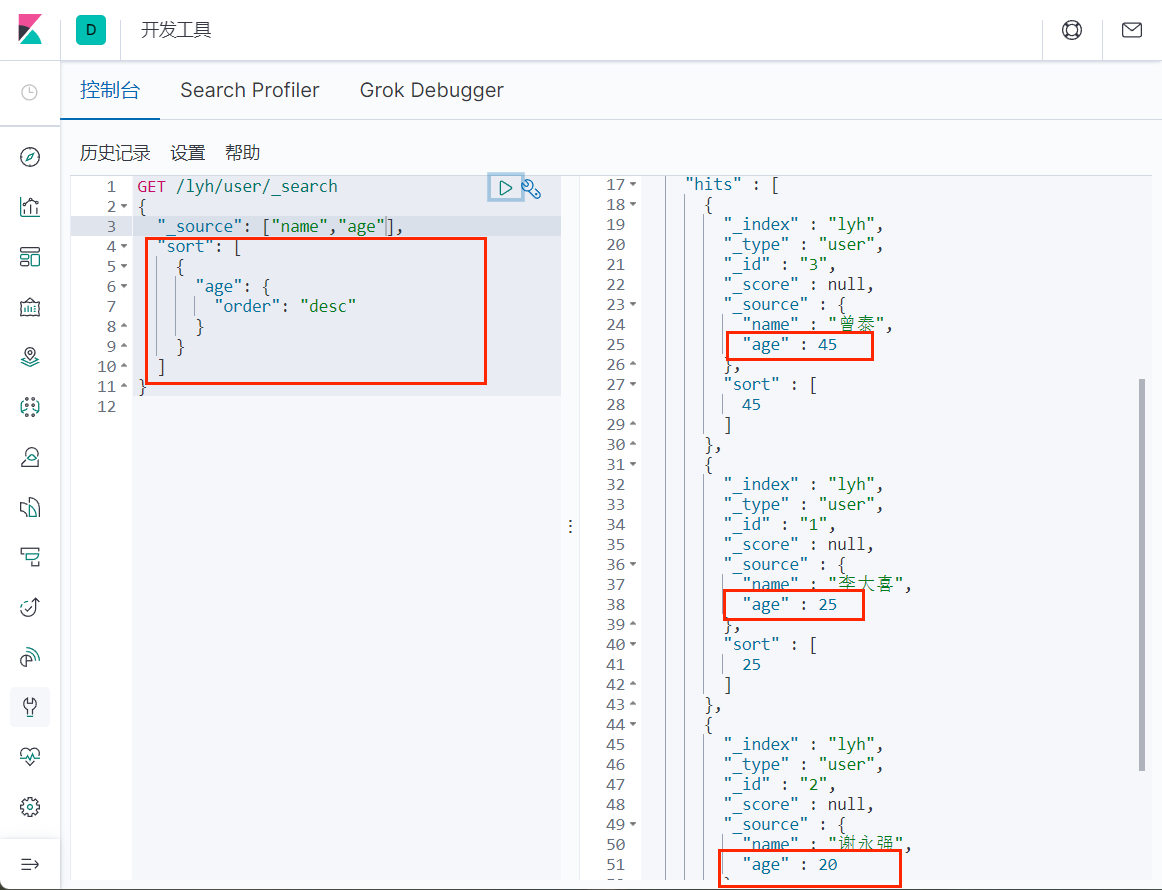
因为原本是按照权重排序的,但是这里使用了 age 作为排序字段,所以 _score 字段为 null
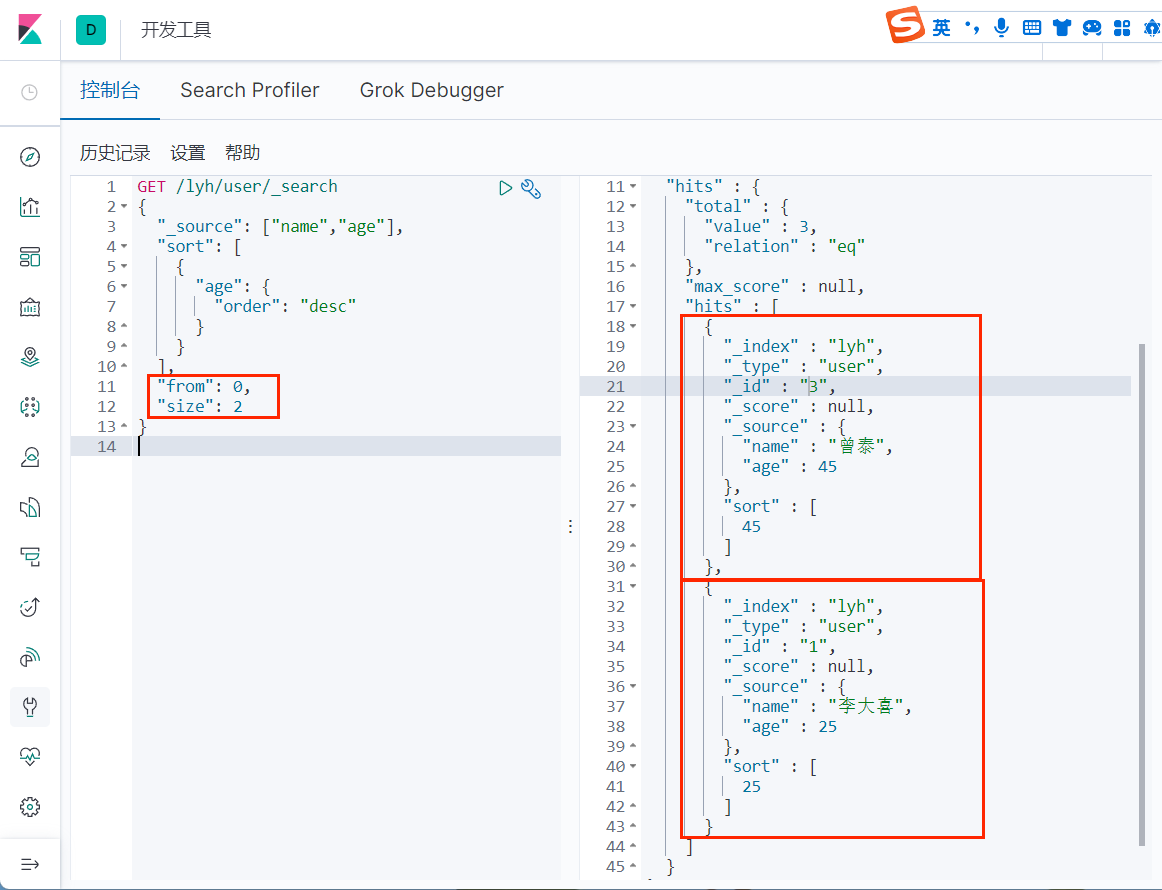
分页查询
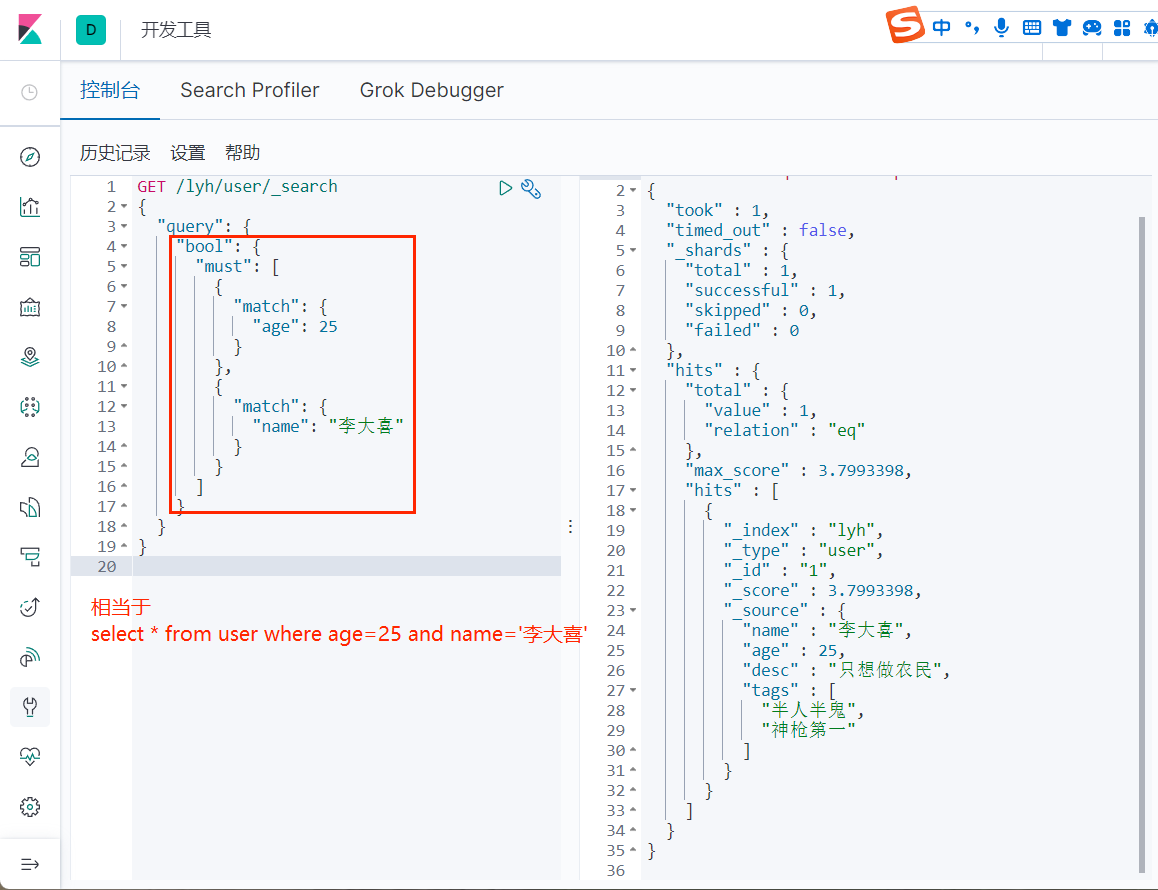
条件过滤查询(bool)
and (must)
or (should)
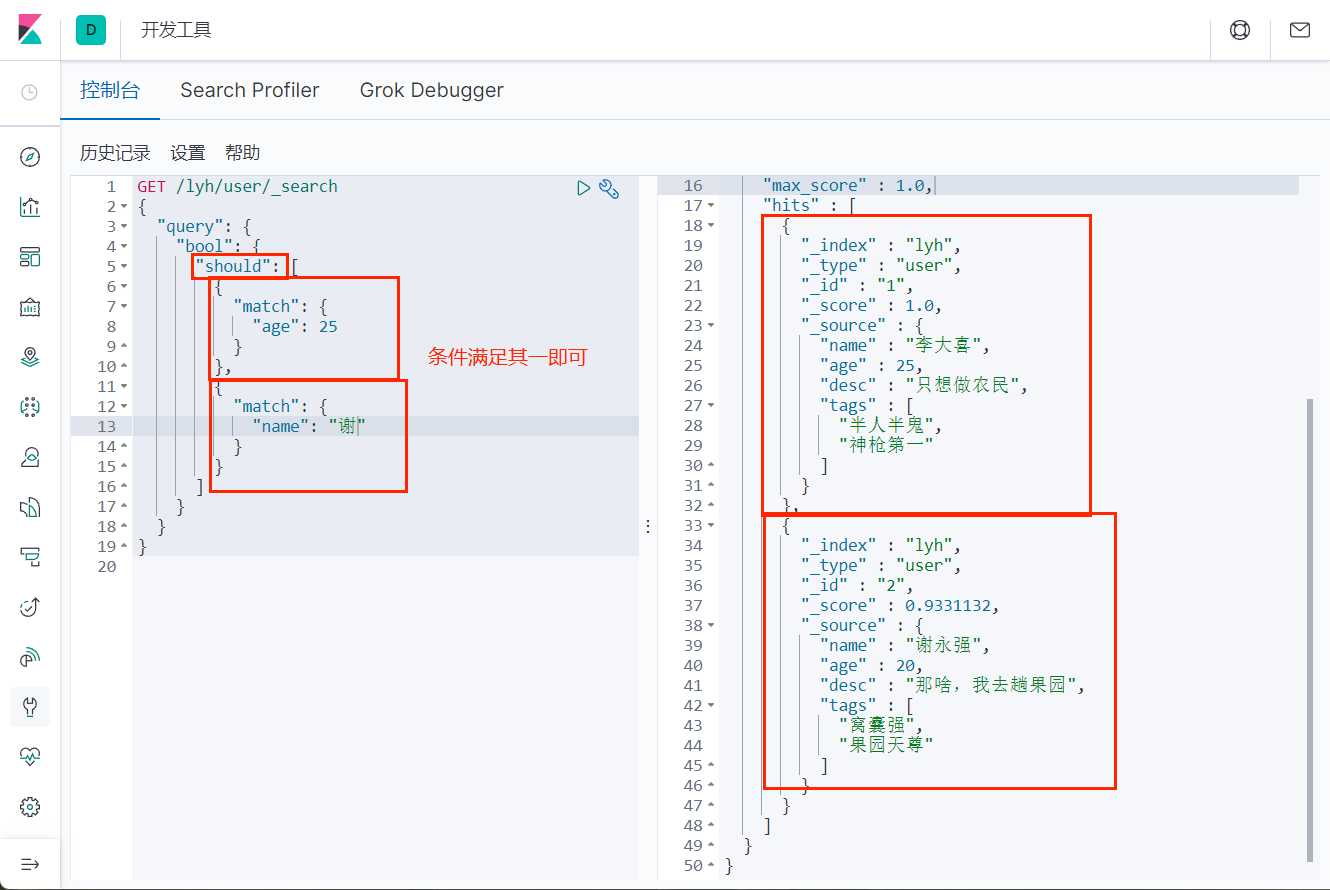
not(must_not)
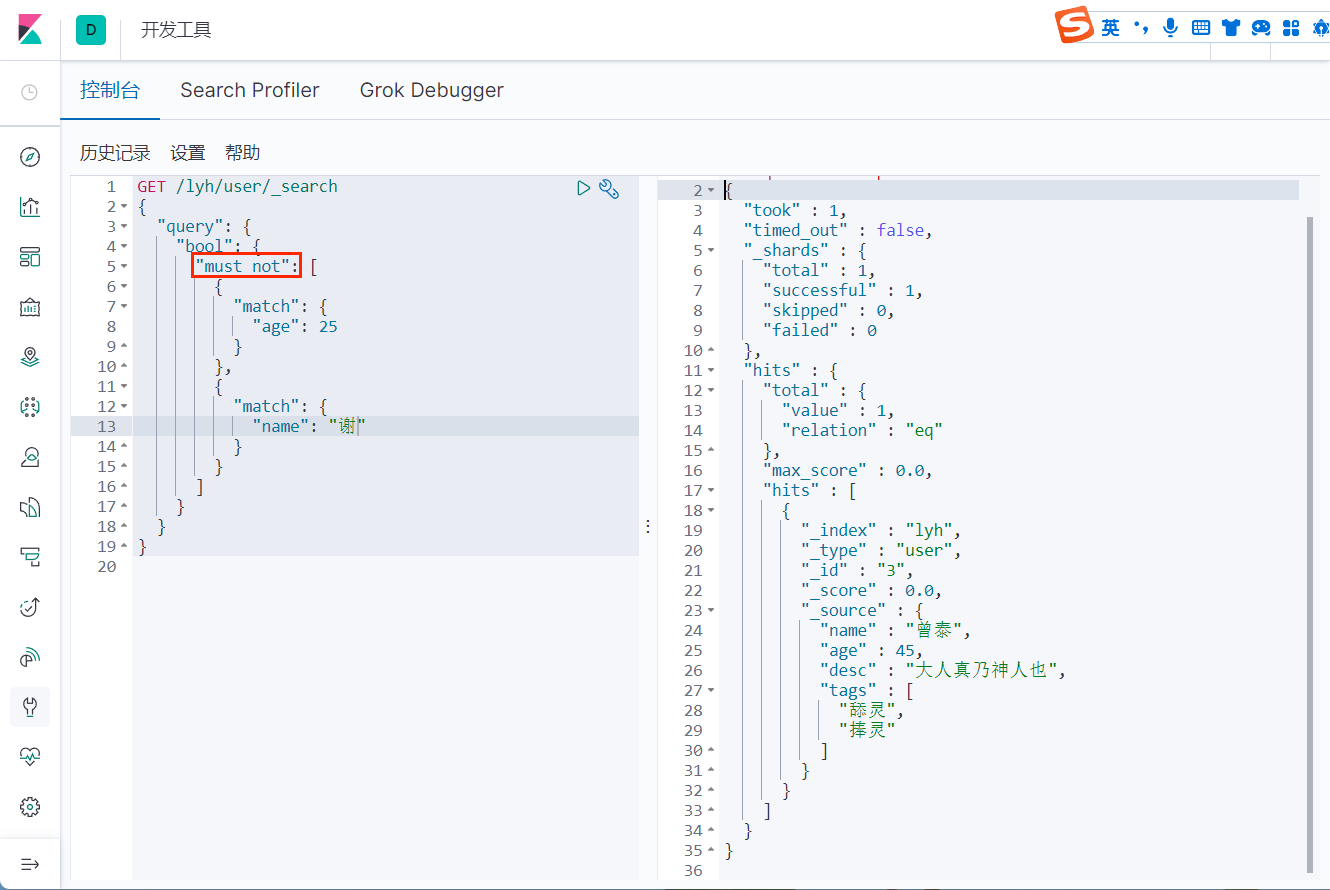
可以看到,这里过滤出了 age 不等于 25 的和姓名不是 "谢" (这里的 "谢" 指的是分词器分词后所包含的)的记录。
range(filter)
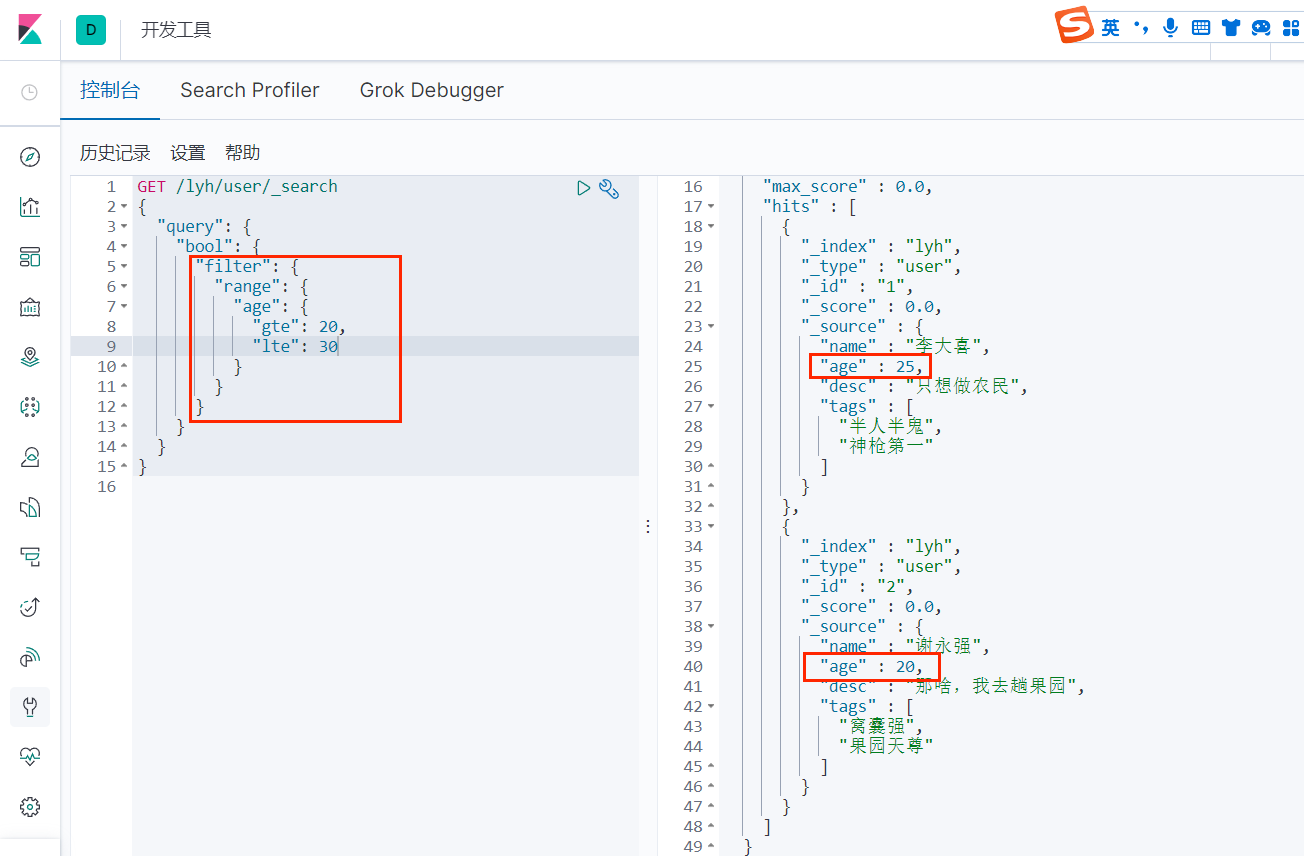
上面,我们过滤出了所有 age >= 20 并且 <= 30 的记录
匹配多个条件
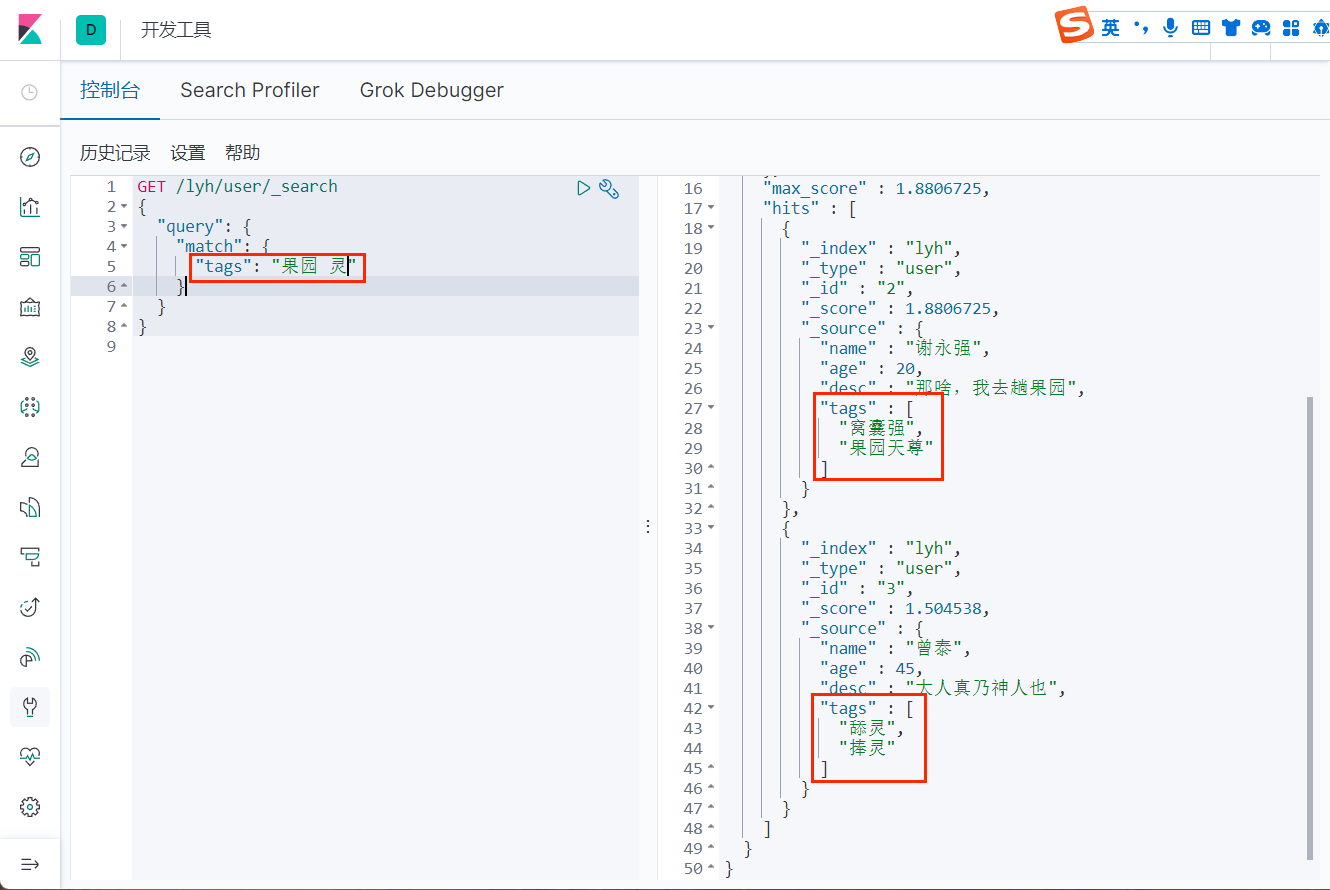
精确查询
term 查询是直接通过倒排索引进行精确查询的,区别于上面我们只用的 match:
- term 是精确查询
- match 会使用分词器
text 类型会被分词器解析,而 keyword 类型不会被分词器解析
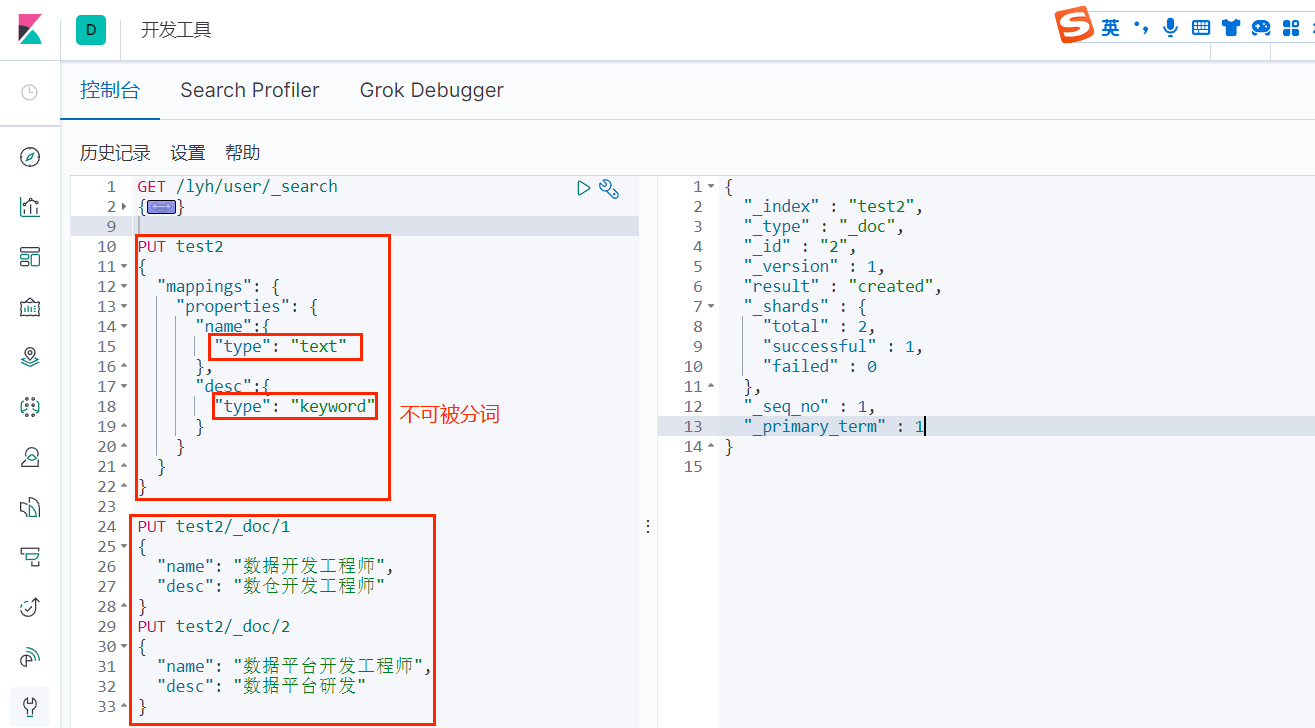
测试 keyword 分词:
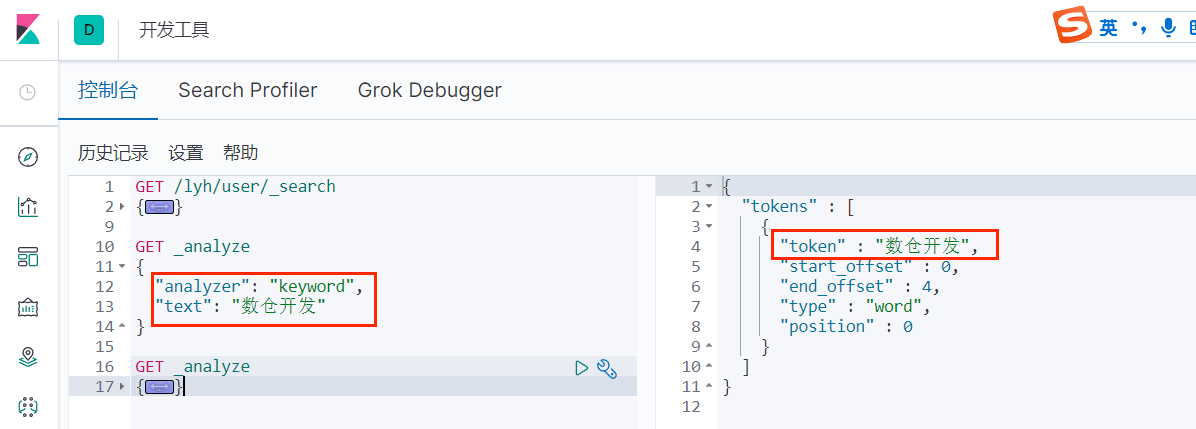
可以看到,使用 keyword 分词器不会把文本分开;
测试默认标准分词器
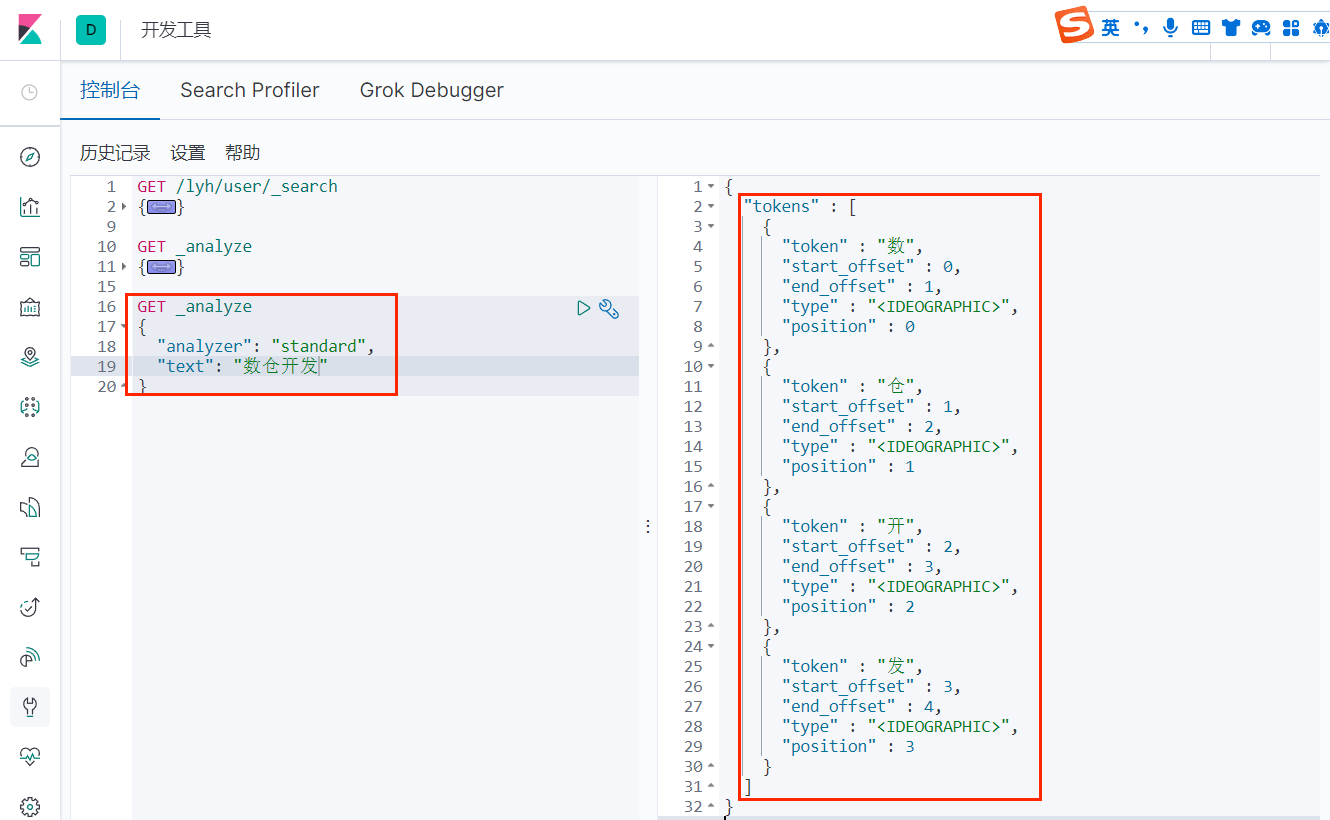
可以看到,使用默认标准的分词器是会把文本完全拆开的,这也是上面为什么我们可以模糊匹配的原因;
查询类型为 text 的 name 字段:
查询字段类型为 keyword 的 desc 字段:
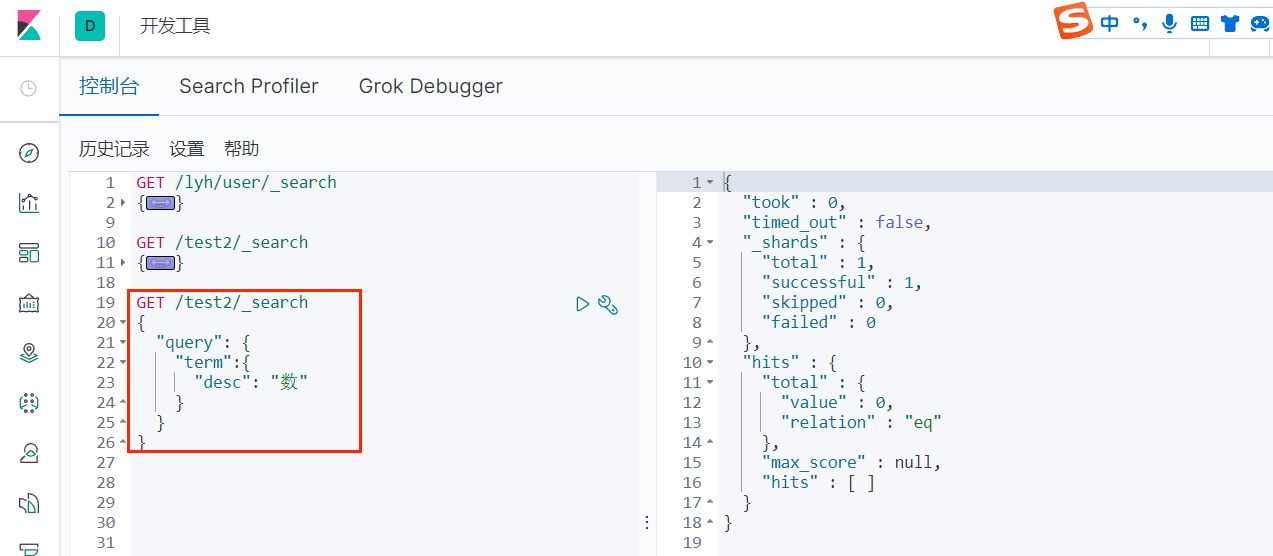
所以结论就是:keyword 类型的字段不会被分词器解析。
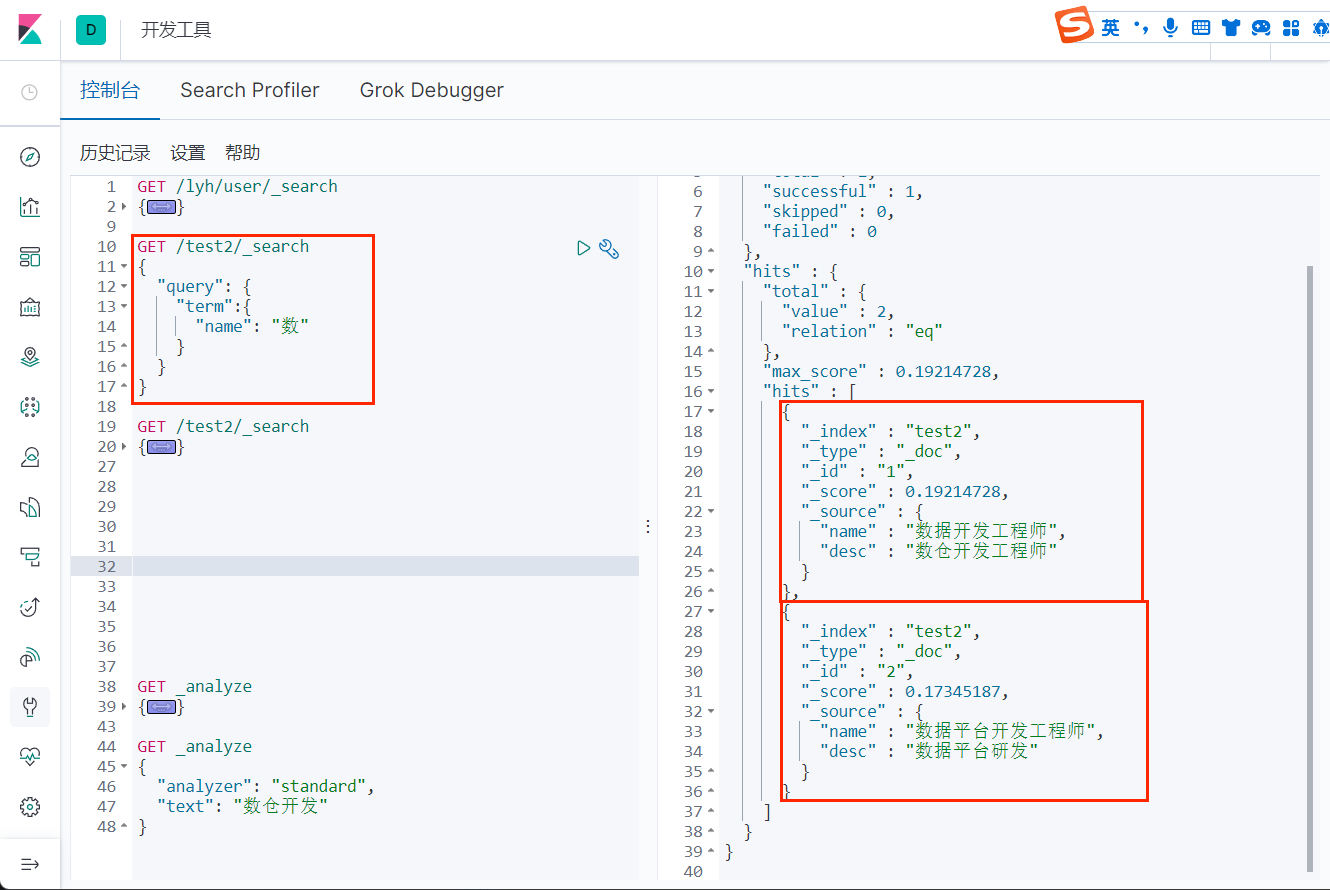
下面我们对比一下精确查询和普通查询的区别:
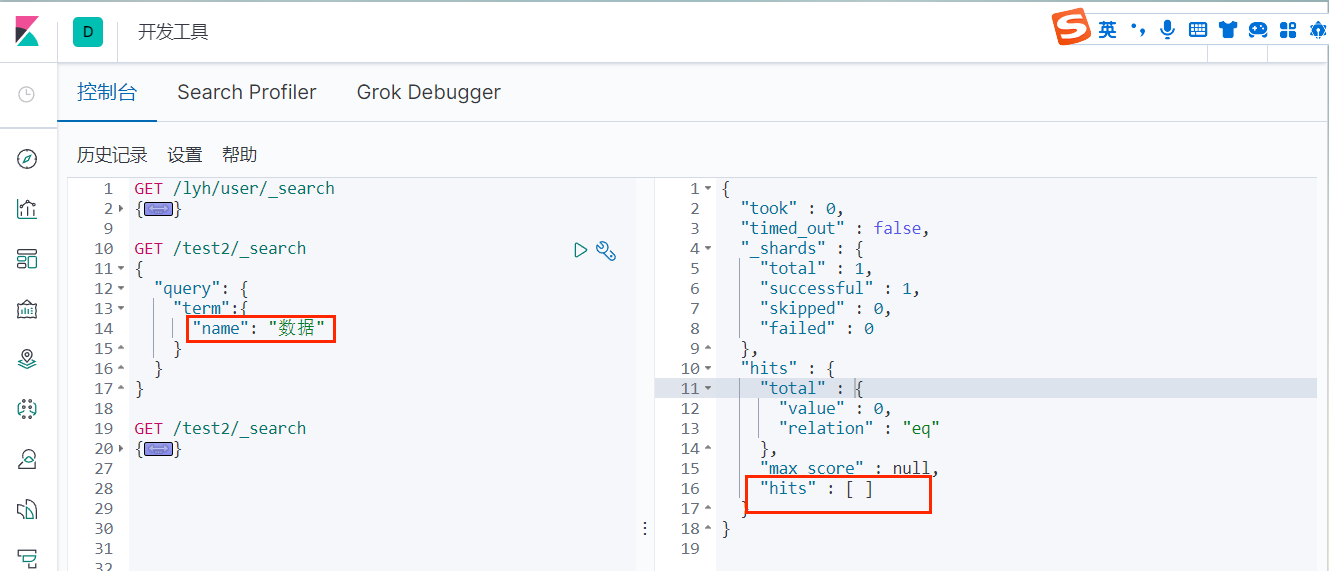
我们的 test2 索引中只有两条记录(name 分别为 "数据开发工程师" 和 "数据平台开发工程师")可以看到,当使用精确查询的时候,查询 "数据" 是查不出来的,这是因为精确查询默认会使用分词器,而标准的分词器是不支持中文的,它会把每一个中文都当做一个词,所以上面当查询 "数" 的时候才可以查出来。
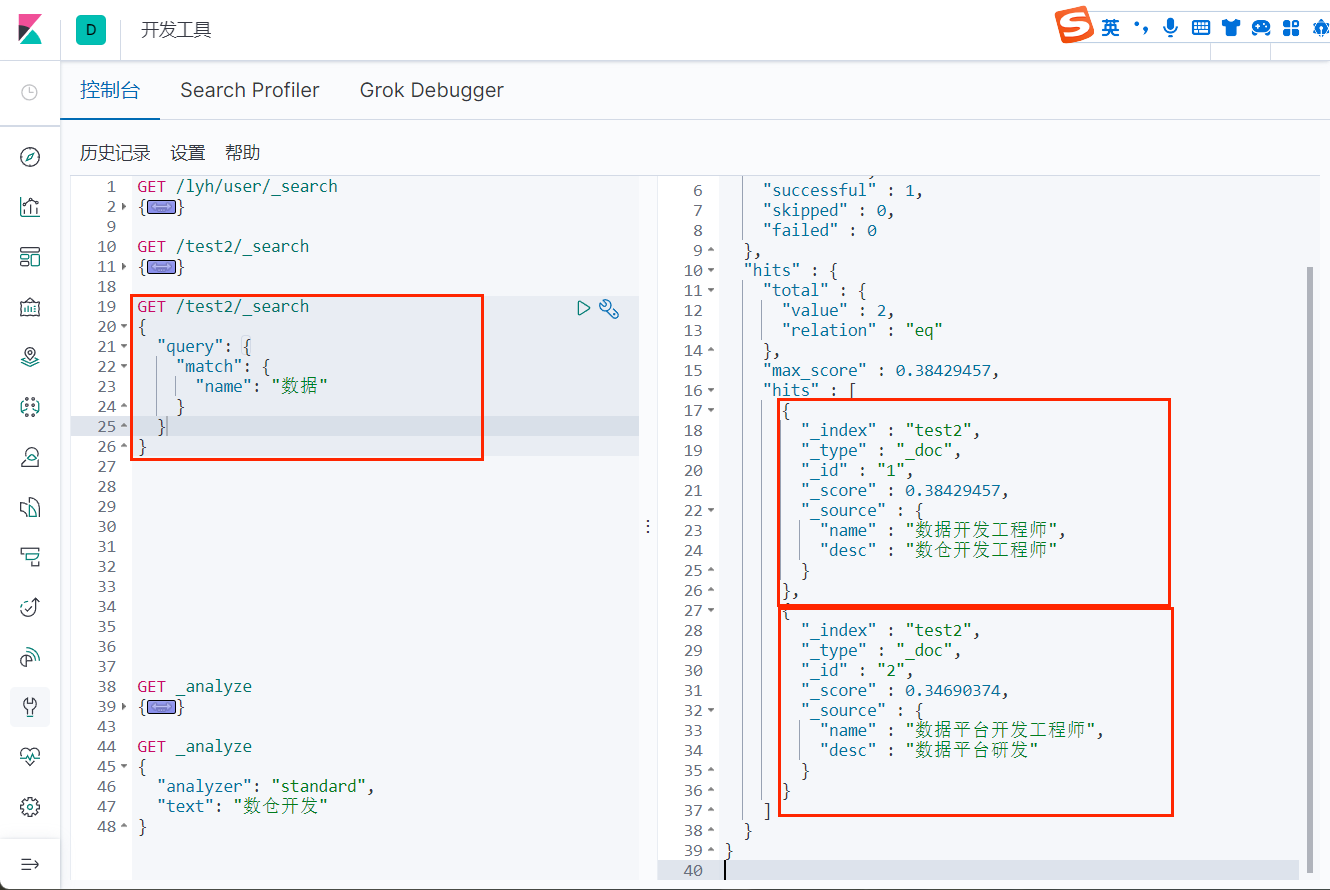
可以看到,当使用普通匹配查询时, 就可以查询出所有包含该词的所有记录;
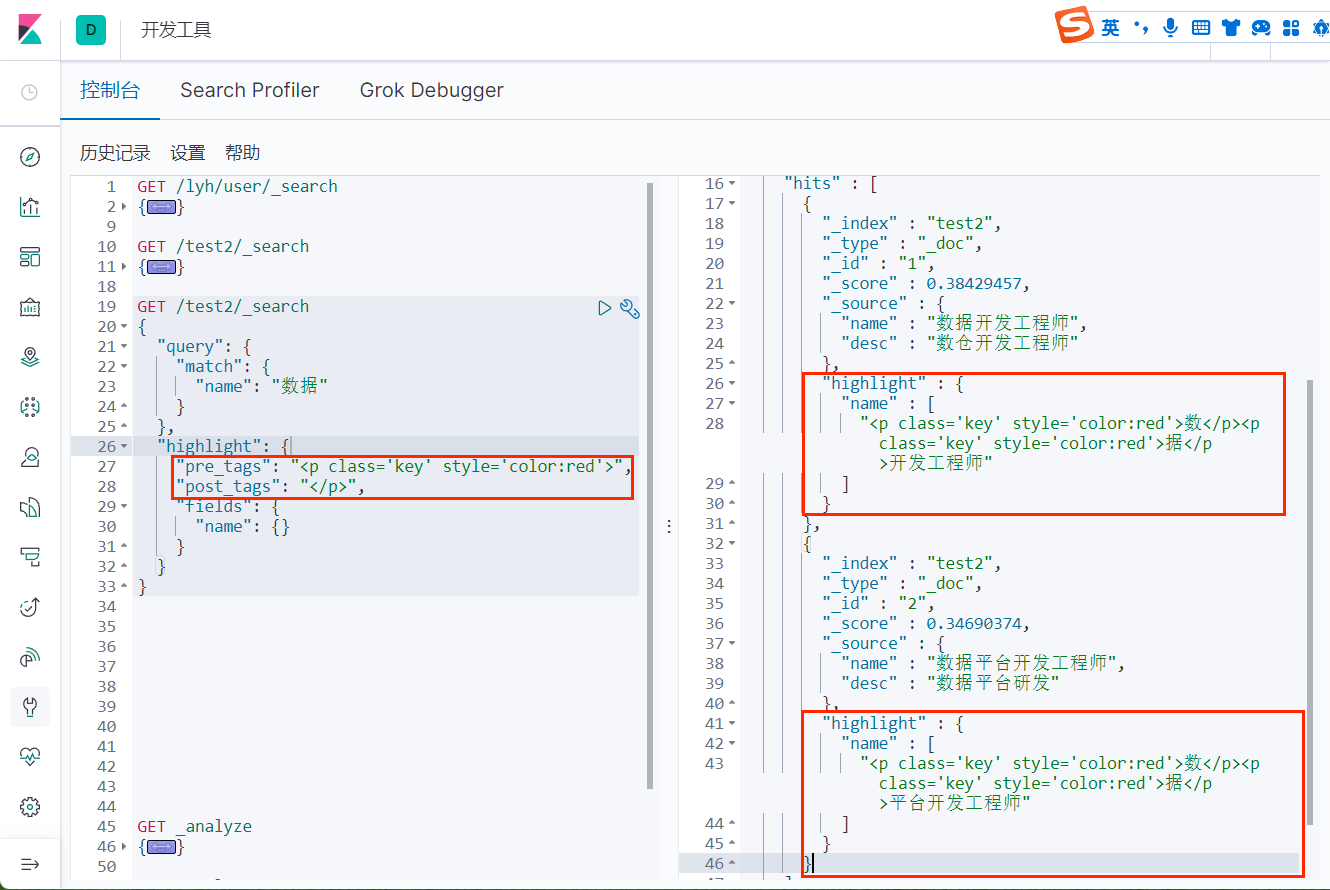
高亮查询
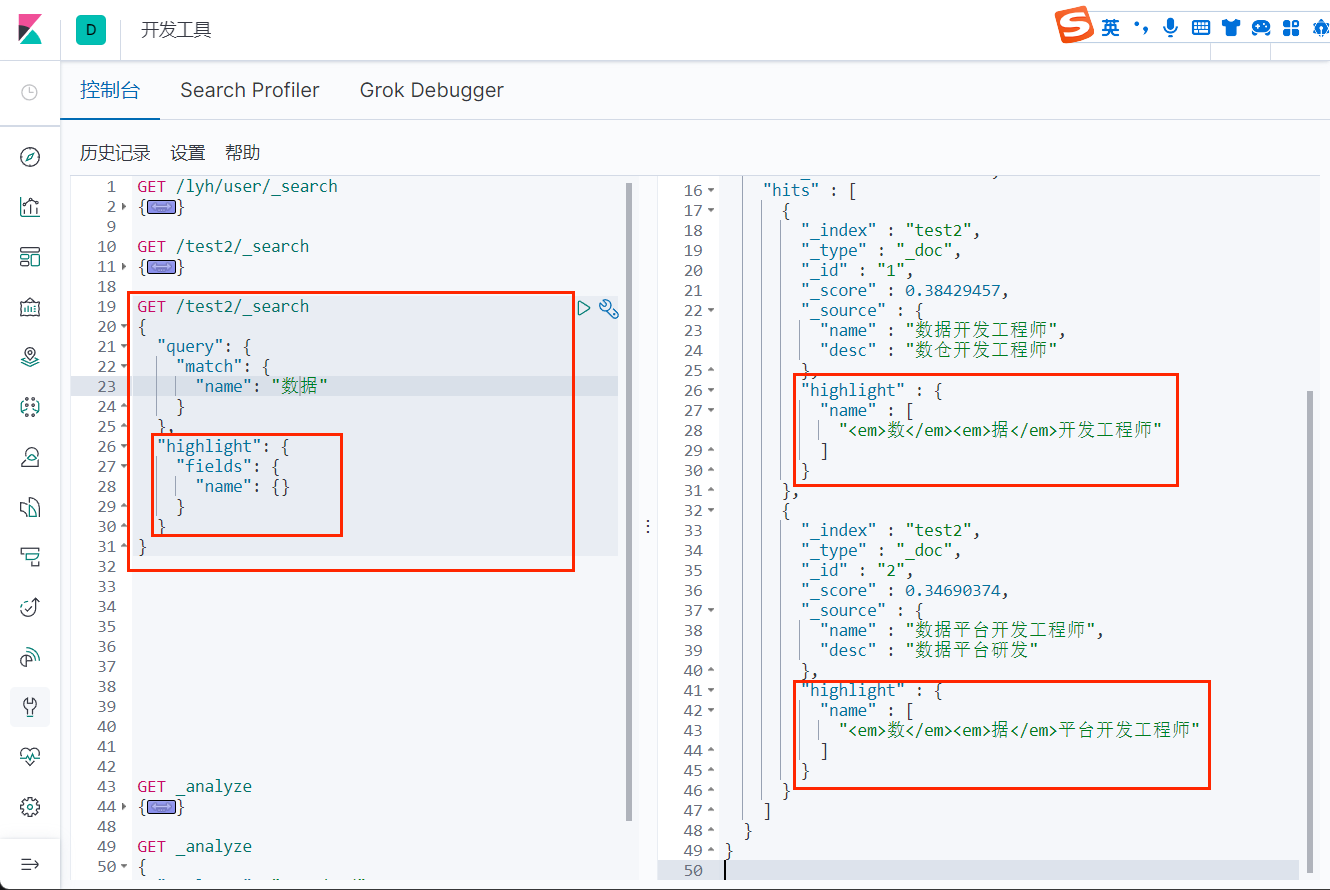
可以看到,查询出来的结果中的匹配字段被加上了 html 标签,我们也可以自定义这个标签:
1.3、ES 集成 SpringBoot
1.3.1、ES 配置类
@Configuration
public class ElasticSearchClientConfig {// <bean id="restHighLevelClient" class="org.elasticsearch.client.RestHighLevelClient">@Beanpublic RestHighLevelClient restHighLevelClient(){return new RestHighLevelClient(RestClient.builder(new HttpHost("localhost",9200,"http")));}}1.3.2、创建索引
@SpringBootTest
class EsApiApplicationTests {@Autowiredprivate RestHighLevelClient client;// 索引创建@Testvoid testCreateIndex() throws IOException {// 1. 创建索引请求CreateIndexRequest request = new CreateIndexRequest("lyh_index");// 2. 执行请求,返回响应CreateIndexResponse createIndexResponse = client.indices().create(request, RequestOptions.DEFAULT);System.out.println(createIndexResponse);}
}执行结果:
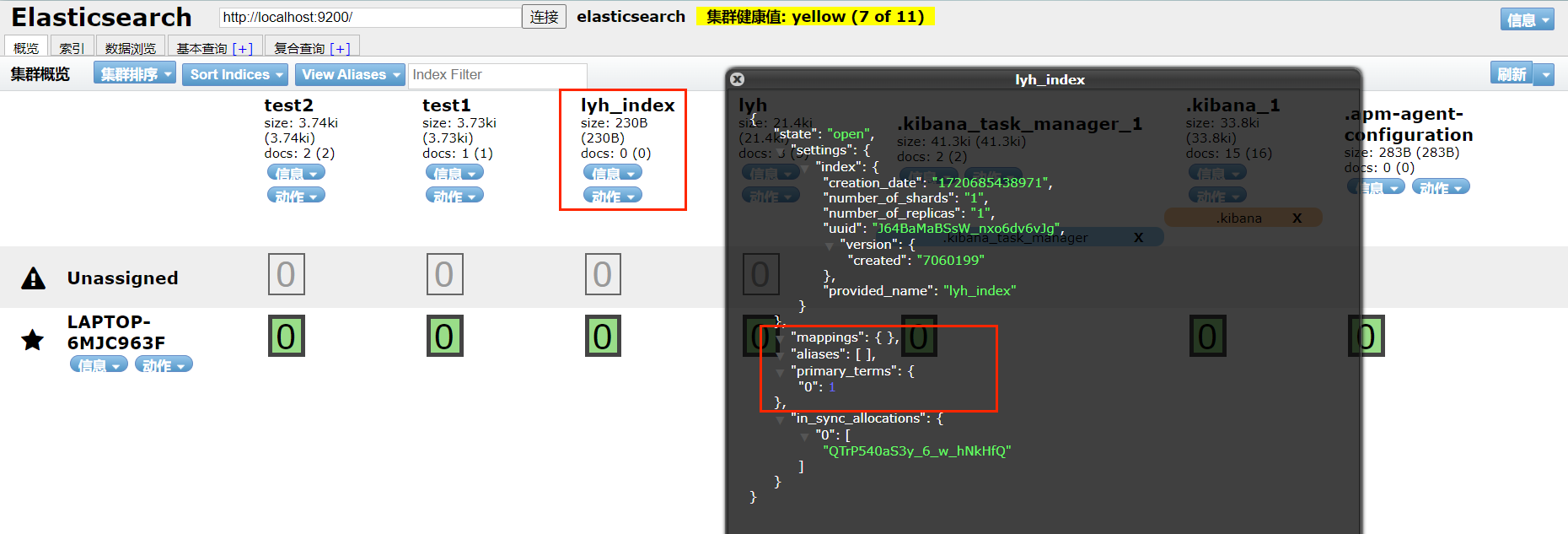
可以看到,成功创建了一个索引(没有任何字段)
1.3.3、判断索引是否存在
// 判断索引是否存在@Testvoid testGetIndex() throws IOException {GetIndexRequest request = new GetIndexRequest("lyh_index");boolean exists = client.indices().exists(request, RequestOptions.DEFAULT);System.out.println(exists);}1.3.4、删除索引
// 删除索引@Testvoid testDeleteIndex() throws IOException {DeleteIndexRequest request = new DeleteIndexRequest("lyh_index");AcknowledgedResponse delete = client.indices().delete(request, RequestOptions.DEFAULT);System.out.println(delete.isAcknowledged());}1.3.5、创建文档
创建 Student 类:
@Data
@AllArgsConstructor
@NoArgsConstructor
@Component
public class Student {private String name;private int age;
}导入 fastjson 并测试:
// 测试添加文档@Testvoid testAddDocument() throws IOException {Student student = new Student("李元芳",20);IndexRequest request = new IndexRequest("lyh_index");// 索引规则request.id("1");request.timeout("1s");// 放入请求request.source(JSONValue.toJSONString(student), XContentType.JSON);// 获取响应结果IndexResponse indexResponse = client.index(request, RequestOptions.DEFAULT);System.out.println(indexResponse.toString());System.out.println(indexResponse.status());}上面的代码相当于:
PUT /lyh_index/_doc/1
{"name": "李元芳","age": 20
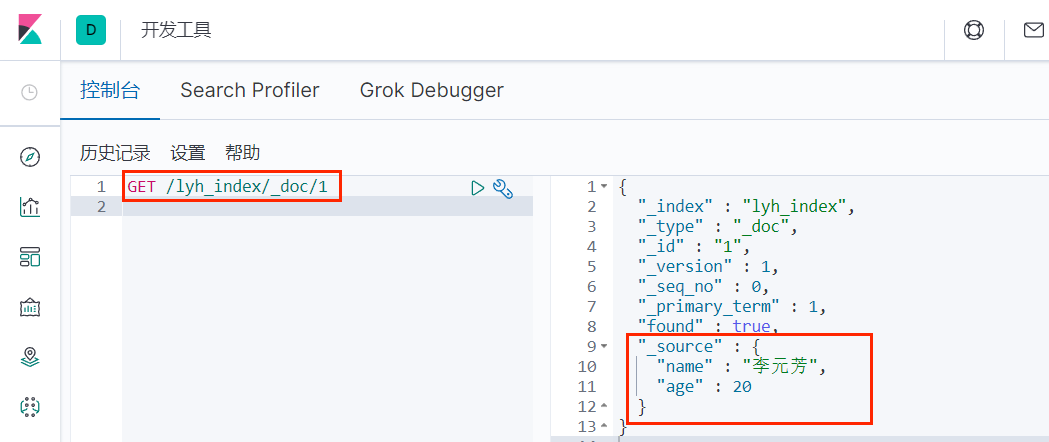
}执行结果:
1.3.5、判断文档是否存在
@Testvoid testExists() throws IOException {// 相当于 GET /lyh_index/_doc/1GetRequest getRequest = new GetRequest("lyh_index","1");boolean exists = client.exists(getRequest, RequestOptions.DEFAULT);System.out.println(exists); }1.3.6、获取文档内容
@Testvoid testGetDocument() throws IOException {// 相当于 GET /lyh_index/_doc/1GetRequest getRequest = new GetRequest("lyh_index","1");GetResponse getResponse = client.get(getRequest, RequestOptions.DEFAULT);System.out.println(getResponse.getSourceAsString());System.out.println(getResponse);}执行结果:
{"name":"李元芳","age":20}
{"_index":"lyh_index","_type":"_doc","_id":"1","_version":1,"_seq_no":0,"_primary_term":1,"found":true,"_source":{"name":"李元芳","age":20}}
1.3.7、更新文档内容
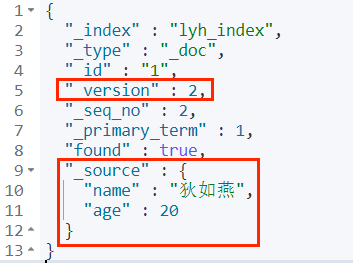
@Testvoid testUpdateDocument() throws IOException {UpdateRequest updateRequest = new UpdateRequest("lyh_index","1");updateRequest.timeout("1s");Student student = new Student("狄如燕", 20);updateRequest.doc(JSONValue.toJSONString(student),XContentType.JSON);client.update(updateRequest,RequestOptions.DEFAULT);}执行结果:
1.3.8、删除文档
@Testvoid testDeleteDocument() throws IOException {DeleteRequest deleteRequest = new DeleteRequest("lyh_index", "2");deleteRequest.timeout("1s");DeleteResponse deleteResponse = client.delete(deleteRequest, RequestOptions.DEFAULT);System.out.println(deleteResponse.status());}1.3.9、批量导入数据
@Testvoid testBulkRequest() throws IOException {BulkRequest bulkRequest = new BulkRequest();bulkRequest.timeout("10s");ArrayList<Student> students = new ArrayList<>();students.add(new Student("谢永强",20));students.add(new Student("谢小梅",25));students.add(new Student("谢广坤",50));students.add(new Student("刘能",51));students.add(new Student("赵四",48));students.add(new Student("王老七",52));students.add(new Student("刘英",21));for(int i=0;i<students.size();i++){bulkRequest.add(new IndexRequest("lyh_index").id(""+(i+1)).source(JSONValue.toJSONString(students.get(i)),XContentType.JSON));BulkResponse bulk = client.bulk(bulkRequest, RequestOptions.DEFAULT);System.out.println(bulk.status());}}