编者按: 如何更好地评估和比较不同版本的大语言模型?传统的学术基准测试固然重要,但往往难以全面反映模型在实际应用场景中的表现。在此背景下,本文作者别出心裁,通过让 Llama-2 和 Llama-3 模型进行井字游戏对决,为我们提供了一个新颖而有趣的模型评估视角。
此文不仅展示了一种创新的模型比较方法,更揭示了当前大语言模型在处理看似简单的空间逻辑任务时所面临的挑战。让我们得以一窥不同参数规模模型的表现差异,以及新一代模型相较前代的进步与不足。
尤为值得关注的是,即便是参数量达到 70B 的大模型,在面对井字游戏这样的基础任务时仍会出现一些令人意外的错误。这一发现不仅为大语言模型的能力边界划定提供了新的参考,也为未来模型的优化方向指明了道路。
我们希望这篇文章能够启发读者思考:在评估人工智能模型时,我们是否应该更多地关注那些看似简单却能深入考察模型认知能力的任务?同时,如何设计更多类似“井字游戏”的“微型基准测试“,以更加全面而直观地评估模型性能?
作者 | Dmitrii Eliuseev
编译 | 岳扬

Image by Solstice Hannan, Unsplash(https://unsplash.com/@darkersolstice)
就在我撰写这篇文章的大约一周前,Meta 推出了新的开源模型 Llama-3[1] 。他们宣称这是“当前在 8B 与 70B 参数量级下的最好模型”。通过 HuggingFace 平台的模型页面[2]可以看到,Llama-3 8B 在 MMLU(Massive Multitask Language Understanding) 基准测试上的表现,以 66.6 的得分超越了 Llama-2 7B 的 45.7 ;而在 CommonSense QA(dataset for commonsense question answering)上进行评估,Llama-3 同样领先,分别以 72.6 和 57.6 的得分战胜了对手。有一款经过特殊指令数据微调(instruction-tuned)的 Llama-3 8B 模型尤其值得一提,在数学基准测试中的表现得分从 3.8 跃升至 30.0,这一进步令人印象深刻。
通过学术基准测试(Academic benchmarks)进行大模型评估固然很重要,但亲眼见证它们的实际表现岂不更加直观且更有趣?答案是肯定的,而且这种体验往往妙趣横生。设想一下,如果让两个模型进行一场经典的井字棋对决(tic-tac-toe game),胜负究竟如何?在接下来的游戏环节中,我将全面测试 7B、8B以及70B 等参数规格的模型。与此同时,我还会记录下模型的性能指标及系统配置要求。
话不多说,让我们即刻启程,一探究竟!
01 加载模型
为了全面测试这些模型,我选择使用 Python 库Llama-cpp[3] 进行测试,该工具的一大优点在于其既能适应 CPU 环境,也能在 GPU 上高效运行。我们需要并行运行两个 LLM。好消息是,无论是 7B 还是 8B 的模型,都能在 Google Colab 的 16GB GPU 环境中顺畅运行。然而,当面对 70B 参数级别的庞大模型时,我们不得不退而求其次,转而使用 CPU 进行测试,因为即便是顶级的 NVIDIA A100 显卡,其内存容量也难以承担起同时运行两个此类巨无霸模型的重任。
首先需要我们先动手安装 Llama-cpp,紧接着下载 7B 与 8B 参数级别的这两个模型。至于 70B 参数级别的模型,其操作流程基本一致,唯一的区别仅在于替换其下载链接而已。
!CMAKE_ARGS="-DLLAMA_CUBLAS=on" FORCE_CMAKE=1 pip3 install llama-cpp-python -U
!pip3 install huggingface-hub hf-transfer sentence-transformers!export HF_HUB_ENABLE_HF_TRANSFER="1" && huggingface-cli download TheBloke/Llama-2-7B-Chat-GGUF llama-2-7b-chat.Q4_K_M.gguf --local-dir /content --local-dir-use-symlinks False
!export HF_HUB_ENABLE_HF_TRANSFER="1" && huggingface-cli download QuantFactory/Meta-Llama-3-8B-Instruct-GGUF Meta-Llama-3-8B-Instruct.Q4_K_M.gguf --local-dir /content --local-dir-use-symlinks False
模型下载完成后,接下来就需要正式启动这些模型了:
from llama_cpp import Llamallama2 = Llama(model_path="/content/llama-2-7b-chat.Q4_K_M.gguf",n_gpu_layers=-1,n_ctx=1024,echo=False
)
llama3 = Llama(model_path="/content/Meta-Llama-3-8B-Instruct.Q4_K_M.gguf",n_gpu_layers=-1,n_ctx=1024,echo=False
)
接下来,我们着手创建一个函数,用于处理和执行各种提示词信息:
def llm_make_move(model: Llama, prompt: str) -> str:""" Call a model with a prompt """res = model(prompt, stream=False, max_tokens=1024, temperature=0.8)return res["choices"][0]["text"]
02 Prompts
现在,我们来编写代码实现井字游戏(Tic-Tac-Toe)。在棋盘上交替放置“X”和“O”,首位成功在任意一行、一列或对角线上连成一线的玩家即为胜者:
Image source Wikipedia(https://en.wikipedia.org/wiki/Tic-tac-toe)
正如我们所见,这个游戏对于人类来说非常简单,但对语言模型而言可能颇具挑战;要走出正确的一步棋,需要理解棋盘空间、物体之间的关系,甚至还会涉及一些简单的数学知识。
首先,我们将棋盘编码为一个二维数组。同时也会创建一个函数方法用于将棋盘转换成字符串形式:
board = [["E", "E", "E"],["E", "E", "E"],["E", "E", "E"]]def board_to_string(board_data: List) -> str:""" Convert board to the string representation """return "\n".join([" ".join(x) for x in board_data])
输出结果如下:
E E E
E E E
E E E
现在,我们可以创建模型提示词(model prompts)了:
sys_prompt1 = """You play a tic-tac-toe game. You make a move by placing X, your opponent plays by placing O. Empty cells are marked with E. You can place X only to the empty cell."""
sys_prompt2 = """You play a tic-tac-toe game. You make a move by placing O, your opponent plays by placing X. Empty cells are marked with E. You can place O only to the empty cell."""
game_prompt = """What is your next move? Think in steps. Each row and column should be in range 1..3. Writethe answer in JSON as {"ROW": ROW, "COLUMN": COLUMN}."""
在这里,我为模型 1 和模型 2 分别创建了两个提示词(prompt)。我们可以看到,这两个句子几乎是相同的。唯一不同的是,第一个模型在“棋盘”上放置“X”,而第二个模型则放置“O”。
Llama-2 和 Llama-3 的提示词格式有所不同:
template_llama2 = f"""<s>[INST]<<SYS>>{sys_prompt1}<</SYS>>
Here is the board image:
__BOARD__\n
{game_prompt}
[/INST]"""template_llama3 = f"""<|begin_of_text|>
<|start_header_id|>system<|end_header_id|>{sys_prompt2}<|eot_id|>
<|start_header_id|>user<|end_header_id|>
Here is the board image:
__BOARD__\n
{game_prompt}
<|eot_id|>
<|start_header_id|>assistant<|end_header_id|>"""
当然,我们可以创建两个函数方法来利用这些提示词(prompts),其中一个函数方法针对 Llama-2 ,另一个则针对 Llama-3 。
def make_prompt_llama2(board: List) -> str:""" Make Llama-2 prompt """return template_llama2.replace("__BOARD__", board_to_string(board))def make_prompt_llama3(board: List) -> str:""" Make Llama-3 prompt """return template_llama3.replace("__BOARD__", board_to_string(board))
03 Coding the Game
我们已经为构建该井字游戏(Tic-Tac-Toe)准备好了所有的提示词信息,接下来该进入此游戏的编码阶段了。在某一个提示词中,我要求模型以 JSON 格式提供模型响应。在实际操作中,模型可以回答这个问题:
My next move would be to place my X in the top-right corner, on cell (3, 1).
{
"ROW": 3,
"COLUMN": 1
}
现在,我们开始着手设计一个函数方法,用于从这类字符串中抽取出 JSON 数据:
def extract_json(response: str) -> Optional[dict]:""" Extract dictionary from a response string """try:# Models sometimes to a mistake, fix: {ROW: 1, COLUMN: 2} => {"ROW": 1, "COLUMN": 2}response = response.replace('ROW:', '"ROW":').replace('COLUMN:', '"COLUMN":')# Extract json from a responsepos_end = response.rfind("}")pos_start = response.rfind("{")return json.loads(response[pos_start:pos_end+1])except Exception as exp:print(f"extract_json::cannot parse output: {exp}")return None
结果发现,LLaMA-2 生成的模型响应并非总是有效的 JSON 格式;它经常会生成类似 “{ROW: 3, COLUMN: 3}” 这样的模型响应。如上述代码块所示,在这种情况下,我会补全字符串中的缺失的引号,确保其格式正确。
获得棋盘的行数和列数后,我们就能对该棋盘进行更新了:
def make_move(board_data: List, move: Optional[dict], symb: str):""" Update board with a new symbol """row, col = int(move["ROW"]), int(move["COLUMN"])if 1 <= row <= 3 and 1 <= col <= 3:if board_data[row - 1][col - 1] == "E":board_data[row - 1][col - 1] = symbelse:print(f"Wrong move: cell {row}:{col} is not empty")else:print("Wrong move: incorrect index")
在更新棋盘状态后,下一步应当判断游戏是否达到结束条件。
def check_for_end_game(board_data: List) -> bool:""" Check if there are no empty cells available """return board_to_string(board_data).find("E") == -1def check_for_win(board_data: List) -> bool:""" Check if the game is over """# Check Horizontal and Vertical linesfor ind in range(3):if board_data[ind][0] == board_data[ind][1] == board_data[ind][2] and board_data[ind][0] != "E":print(f"{board_data[ind][0]} win!")return Trueif board_data[0][ind] == board_data[1][ind] == board_data[2][ind] and board_data[0][ind] != "E":print(f"{board_data[0][ind]} win!")return True# Check Diagonalsif board_data[0][0] == board_data[1][1] == board_data[2][2] and board_data[1][1] != "E" or \board_data[2][0] == board_data[1][1] == board_data[0][2] and board_data[1][1] != "E":print(f"{board_data[1][1]} win!")return Truereturn False
在此代码逻辑中,会循环检查棋盘的水平线、垂直线和对角线,判断是否出现胜利的一方。也许可能存在更为简洁的解法,但当前这种方法足以应对目前的需求。
现在,所有必要组件都已准备完毕。接下来,我们将这些组件整合在一起:
num_wins1, num_wins2 = 0, 0
times_1, times_2 = [], []def run_game():""" Run a game between two models """board = [["E", "E", "E"],["E", "E", "E"],["E", "E", "E"]]moves_limit = 20for step in range(moves_limit):print(f"Step {step+1}")# Move: Model-1t_start = time.monotonic()prompt = make_prompt_llama2(board)result_str = llm_make_move(llama2, prompt)times_1.append(time.monotonic() - t_start)new_data = extract_json(result_str)if new_data is not None:make_move(board, new_data, symb="X")if check_for_win(board):print('**Model 1 Won**')num_wins1 += 1breakif check_for_end_game(board):break# Move: Model-2t_start = time.monotonic()prompt = make_prompt_llama3(board)result_str = llm_make_move(llama3, prompt)times_2.append(time.monotonic() - t_start)new_data = extract_json(result_str)if new_data is not None:make_move(board, new_data, symb="O")if check_for_win(board):print('**Model 2 Won**')num_wins2 += 1breakif check_for_end_game(board):breakprint()
同时,我还记录了每个步骤的执行耗时,以及各个模型在游戏中的获胜次数。
04 Results
说到实验结果,确实很有趣。
对于参数规模为 7B 和 8B 的模型,完成井字游戏似乎比较有挑战性。7B 的 Llama-2 模型虽然对游戏规则有所认知,但它却没能准确理解棋盘坐标的含义,导致常常将“X”标记置于不当之处。
下面是一些具体的 Prompt 与模型响应示例:
>>> Prompt:<s>[INST]<<SYS>>You play a tic-tac-toe game. You make a move by placing X,
your opponent plays by placing O. Empty cells are marked with E.
You can place X only to the empty cell.<</SYS>>
Here is the board image:
X X O
X O E
E E EWhat is your next move? Think in steps.
Each row and column should be in range 1..3.
Write the answer in JSON as {"ROW": ROW, "COLUMN": COLUMN}.
[/INST]>>> Response:Since there are no empty cells on the board, I will place my X in the
center cell: { "ROW": 2, "COLUMN": 1 }.
根据上文的响应内容,我们可以看到,这段模型响应中存在多个错误。首先,棋盘上还有许多空位可选;其次,坐标 (2,1) 并不是棋盘的中心;最后,给出的残局中,初始状态那个位置本身就有棋子,并非空缺。
相比之下,参数规模为 70B 的 LLaMA-2 模型整体表现更佳,然而它也并非完美无瑕,依旧存在不少错误。以下为一个极具代表性的 prompt 与模型响应案例:
>>> Prompt:<s>[INST]<<SYS>>You play a tic-tac-toe game. You make a move by placing X,
your opponent plays by placing O. Empty cells are marked with E.
You can place X only to the empty cell.<</SYS>>
Here is the board image:
O E E
E X E
E E E...>>> Response:My next move would be to place my X in the center cell, which is empty.
Here is the updated board:O E E
E X X
E E EJSON representation of my move: {"ROW": 2, "COLUMN": 2}
可以看到,参数规格为 70B 的模型确实找到了“中心”位置,但相关“棋子”♟的位置放置决策却是错的;该模型似乎并未“意识到”中间的格子其实已经被占用了。该模型甚至尝试重新“描绘”棋盘,但这番“修改”同样也是错误的。
令人啼笑皆非的是,ChatGPT 3.5 面对同一问题也给出了错误解答,同样得出了中心位置为 {“ROW”: 2, “COLUMN”: 2} 的结论。不过,LLaMA-3 70B 却成功避免了这个陷阱。即便如此,它还是会犯类似的错误,偶尔会在已经有“棋子”的格子里再次放置“棋子”。遗憾的是,我没有统计每款模型的具体错误次数,这是一个值得后续关注的改进点。
如果用柱状图来展示,7B 和 8B 模型的表现数据大致如下:
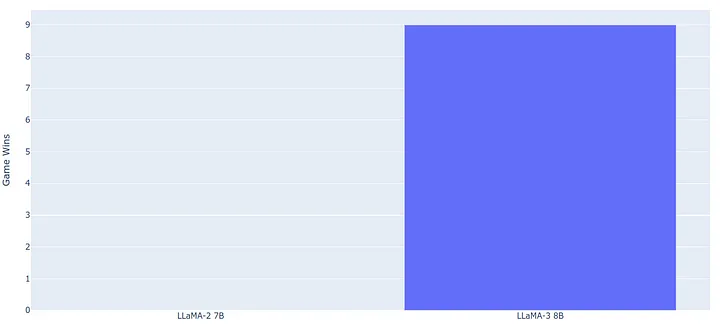
Game score for 7B and 8B models, Image by author
结果显而易见:Llama-3 以 10:0 的大比分获胜!
同时,我们可以观察到两组模型在搭载 16 GB NVIDIA T4 GPU 的设备上的推理耗时情况:


Inference time for 7B and 8B models, Image by author
略有不足的是,Llama-3 的运行速度相比前一代模型略慢(分别为 2.5 秒和 4.3 秒)。然而实际上,4.3 秒的响应时间已经足够优秀了,因为大多数情况下会采用流式处理(streaming),并且用户通常也不会期待立刻获得即时回答。
至于参数规格为 70B 的 Llama-2 模型,它的表现更佳,能够胜出两次,但即便如此,在绝大多数情况下,Llama-3 仍然占据了上风。最终,在推理速度这方面,Llama-3 以 8:2 的比分获胜!
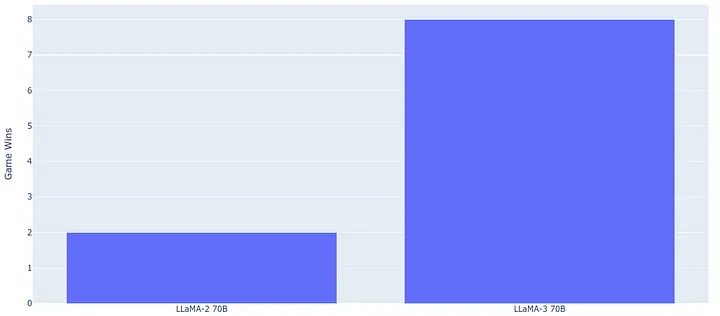
Game score for 70B models, Image by author
使用 CPU 进行大模型的推理运算时,由于 CPU 的计算能力和并行处理能力相对有限,其推理速度自然不会很快:
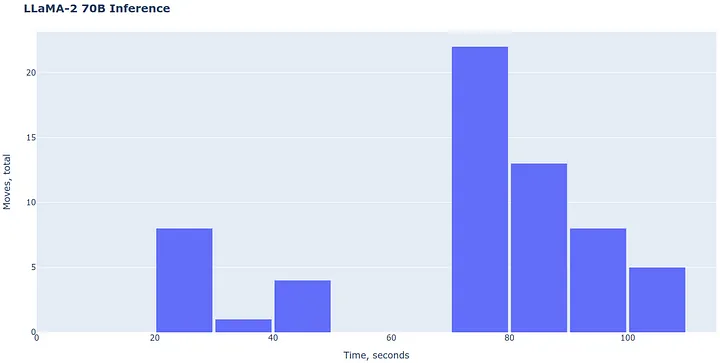
Inference time, Image by author
完成十局游戏大约会耗费一个小时。虽然这个速度对于生产环境来说并不理想,但在测试阶段还可以吧。有一点很有趣,Llama-cpp 采用了一种内存映射文件(memory-mapped file)的方式来加载模型,即便同时处理两个 70B 参数级别的模型,其内存占用也控制在了 12GB 以内。这就表明,在仅配备 16GB RAM 的个人电脑上,我们同样能够顺利地测试两个 70B 模型(可惜这一招在 GPU 上行不通)。
05 Conclusion
在本文中,我安排两组语言模型进行了一场别开生面的井字游戏对战。有趣的是,这个看似简单的“基准测试”实际上极具挑战性。其考验的不仅仅是模型对游戏规则的掌握,还涉及到了坐标系统以及使用字符串形式表达“空间”和“抽象思维”的能力,以此模拟二维棋盘。
从比赛结果来看,LLaMA-3 明显是赢家。显然,这款模型的表现更为出色,但我必须承认,两款模型都在游戏中犯了很多错误。这一现象引人深思,暗示着即便是当前的大语言模型,在面对这个小巧却非正式的“基准测试”时也会感到棘手,本文提出的 “Tic-Tac-Toe Battle” 基准测试无疑可为未来其他大模型的测试提供参考。
文中链接
[1]https://ai.meta.com/blog/meta-llama-3/
[2]https://huggingface.co/meta-llama/Meta-Llama-3-70B-Instruct
[3]GitHub - abetlen/llama-cpp-python: Python bindings for llama.cpp
Thanks for reading!
————
Dmitrii Eliuseev
Python/IoT developer and data engineer, data science and electronics enthusiast
https://www.linkedin.com/in/dmitrii-eliuseev/
原文链接:
https://towardsdatascience.com/llama-2-vs-llama-3-a-tic-tac-toe-battle-between-models-7301962ca65d