一、引言
论文: DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection
作者: IDEA
代码: DINO
注意: 该算法是在Deformable DETR、DAB-DETR、DN-DETR基础上的改进,在学习该算法前,建议先掌握相关知识。
特点: 提出对比去噪训练方法,相比原DN-DETR中的去噪训练方法引入了负查询来避免重复的和不期望的预测;提出混合查询选择方法,相比原Deformable DETR中的查询选择方法移除了由编码器输出初始化解码器内容查询的部分;提出向前看两层的锚框更新方法,相比原Deformable DETR中向前看一层的锚框更新方法将梯度更新扩展到了前一层。
二、详情
DINO与其他DETR系列方法一样,包括backbone、编码器、解码器、预测头。DINO融合了Deformable DETR、DAB-DETR、DN-DETR的各种策略,例如多尺度特征图输入、可变形注意力、解码器位置查询由4D锚框表达、使用编码器输出初始化解码器输入、去噪训练、逐层更新预测框等等。
针对后三个策略,DINO又做了简单的改进。
2.1 对比去噪训练(Contrastive DeNoising Training)
DN-DETR提出去噪训练来提升模型收敛速度。但是该方法有两个问题:
(1)可能产生重复的预测。 对于同一个目标可能产生多个十分接近的预测,由于DETR系列方法都不需要执行NMS,这些不必要的预测无法被滤除,最终会对性能会有一定的影响。
(2)无法拒绝距离真实目标较远的预测。 即使预测框内无任何目标,如果它的置信分数较大也可能被选中并留到最后,这种无效预测也会影响模型性能。
对比去噪训练引入了显式的难分负样本,在训练时将其分为“no object”,从而使模型具有拒绝无用锚框的能力来解决这两个问题。与难分负样本对应的带噪正样本。事实上,正负都是通过在真实锚框和标签上增加噪声产生的,只是正负样本的噪声等级不同。下图是一个二维数据的正负样本区别示意图:

可见,作者增加了两个超参数, λ 1 < λ 2 \lambda_1<\lambda_2 λ1<λ2。所有噪声等级小于 λ 1 \lambda_1 λ1的都视作正样本,所有等级大于 λ 1 \lambda_1 λ1但小于 λ 2 \lambda_2 λ2的都视作负样本。 当 λ 1 \lambda_1 λ1和 λ 2 \lambda_2 λ2差别不大时,负样本就可以视为难分负样本,因为它与正样本的区别不大,作者表示这样能提升性能。
以真实目标框归一化后的宽 w = 0.26 w=0.26 w=0.26为例, λ 1 = 1 , λ 2 = 2 \lambda_1=1, \lambda_2=2 λ1=1,λ2=2,那么在 [ ( 1 − λ 1 ) w , ( 1 + λ 1 ) w ] = [ 0 , 0.52 ] [(1-\lambda_1)w,(1+\lambda_1)w]=[0,0.52] [(1−λ1)w,(1+λ1)w]=[0,0.52]范围内随机取一个值就形成了正样本的宽,在 [ ( 1 − λ 2 ) w , ( 1 − λ 1 ) w ] = [ − 0.26 , 0 ] [(1-\lambda_2)w,(1-\lambda_1)w]=[-0.26,0] [(1−λ2)w,(1−λ1)w]=[−0.26,0]或 [ ( 1 + λ 1 ) w , ( 1 + λ 2 ) w ] = [ 0.52 , 0.78 ] [(1+\lambda_1)w,(1+\lambda_2)w]=[0.52,0.78] [(1+λ1)w,(1+λ2)w]=[0.52,0.78]范围内取一个值就形成了负样本的宽。
有了正负样本之后,训练时,正样本仍然使用重构损失,即锚框回归使用 l 1 l_1 l1和GIOU损失,标签分类使用focal损失。负样本因为原本就远离真实目标框了,所以框不必优化,而是希望将负样本分类为“no object”,使用focal损失。
除正负样本的生成与损失外,DINO与DN-DETR的区别还有以下几点:
(1)DN-DETR将匹配部分的内容查询(解码器嵌入)改为了类别标签嵌入,所以设置了一个指示项来区分匹配部分和去噪部分,但是DINO没有改变匹配部分的解码器嵌入所以不需要指示项。DN-DETR使用nn.Embedding初始化一个尺寸为 ( n u m _ c l a s s e s + 1 , h i d d e n _ d i m − 1 ) (num\_classes+1,hidden\_dim-1) (num_classes+1,hidden_dim−1)的矩阵, − 1 -1 −1留给指示项;DINO中初始化一个尺寸为 ( n u m _ c l a s s e s + 1 , h i d d e n _ d i m ) (num\_classes+1,hidden\_dim) (num_classes+1,hidden_dim)的矩阵。
(2)上面DN-DETR初始化的矩阵 + 1 +1 +1留给了匹配部分的内容查询,DINO的 + 1 +1 +1则是留给负样本。
(3)与DN-DETR一样,DINO会施加不同版本的噪声到真实目标的框和标签上。每组中每个真实目标的框和标签都会产生一个正样本和一个负样本。不同的是,DN-DETR固定每次都分5组,DINO则采取了动态组数的策略,当前批次数据中目标多时就组数就少一些,反之就多一些。
2.2 混合查询选择(Mixed Query Selection)
该操作仅针对匹配部分,不影响去噪部分。
DETR、Deformable DETR、DINO的解码器查询初始化间的差异如下图所示:
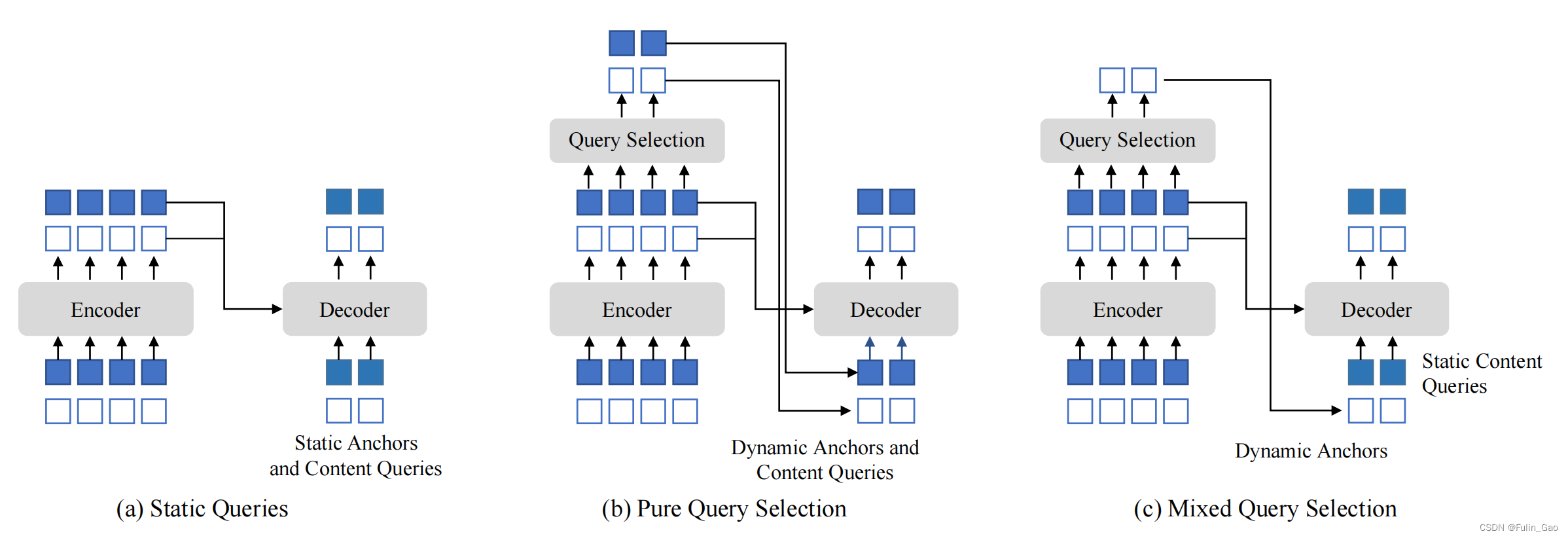
DETR的内容查询是初始化为0,位置查询是用nn.Embedding随机初始化成可学习的参数。
Deformable DETR的内容查询和位置查询均由编码器输出导出。 首先编码器输出memory经过一次不变维度的全连接映射,再经过预测头预测类别和框,取类别分数topk的框(k和解码查询数量300一致),之后将topk的框的4个值进行位置编码再经过一次不变维度的全连接映射,最后分割为两部分分别作为解码器的初始化内容和位置查询。
可以看出将框的值经过位置编码再做全连接和分割感觉并不是很合理,毕竟内容查询用位置编码的映射做初始化没什么道理。所以DINO直接把topk的4个值作为位置查询的初始化,而内容查询的初始化是用nn.Embedding随机初始化成可学习的参数。
2.3 向前看两层的锚框更新(Look Forward Twice)
每层解码器输出都参与损失计算时才有用。
Deformable DETR、DINO的锚框更新间的差异如下图所示:
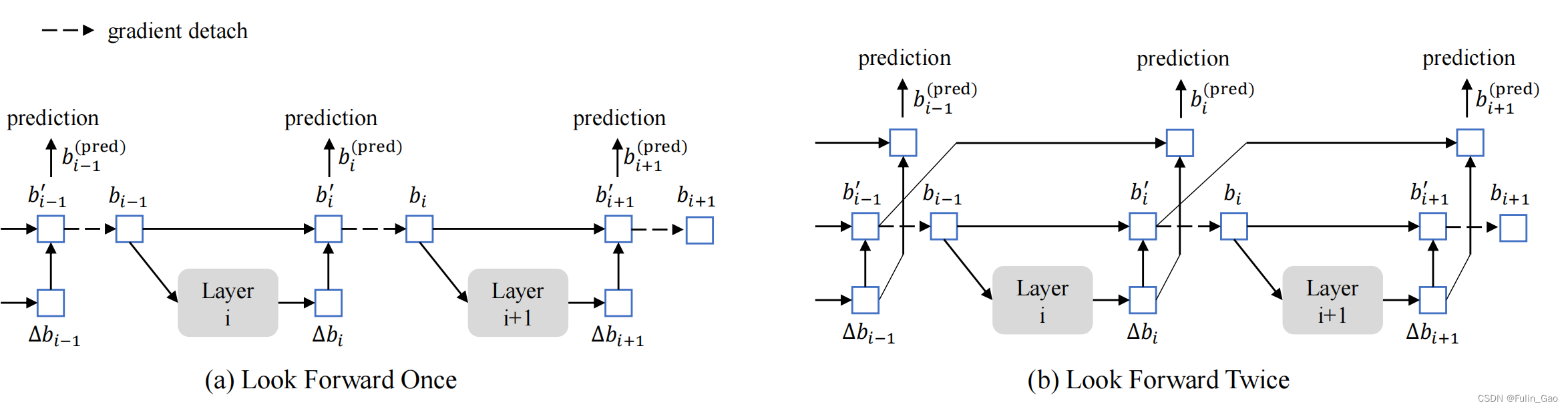
Deformable DETR的解码器层会预测锚框的偏移量从而逐层更新锚框。 例如上图(a)中 b i − 1 b_{i-1} bi−1是上一层的锚框预测,经 L a y e r i Layer_i Layeri后得出偏移量 Δ b i \Delta b_i Δbi,综合得出该层锚框预测 b i ′ b_i^{\prime} bi′。
但是每层的预测结果在进行损失计算时只会影响当前层的参数更新,例如 b i ′ b_i^{\prime} bi′作为第 i i i层的预测传入第 i + 1 i+1 i+1层前会被detach,即上图(a)中的虚线。detach后 b i ′ b_i^{\prime} bi′和 b i b_i bi值相同但与该项相关的损失梯度就无法从第 i + 1 i+1 i+1层传到第 i i i层。
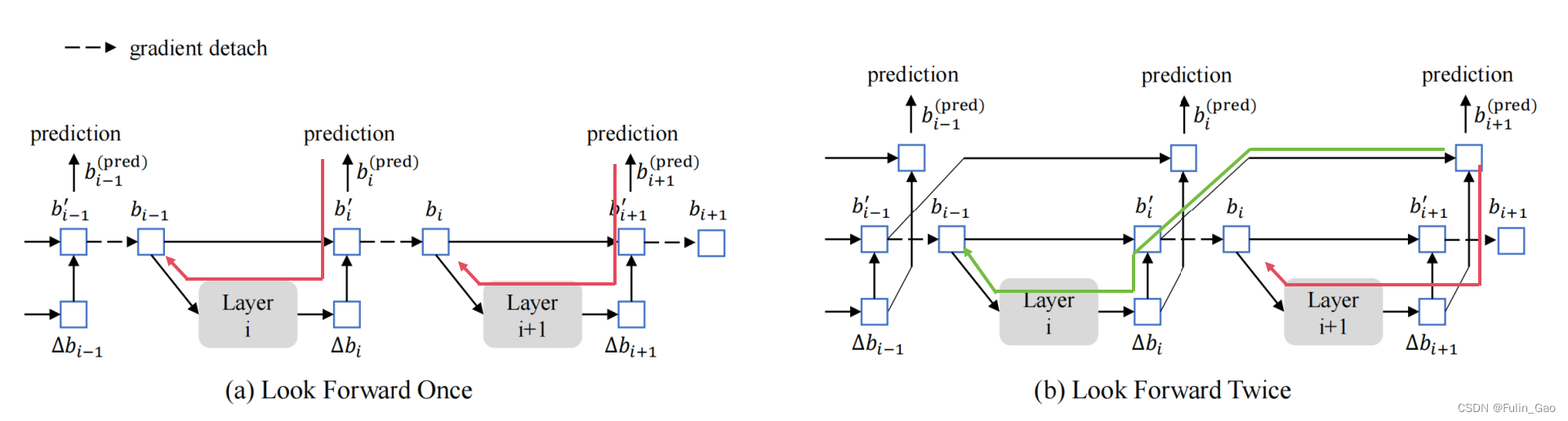
作者认为后一层的信息可能有助于修正前一层的锚框偏移量,所以把预测 b i p r e d b_i^{pred} bipred从 b i − 1 + Δ b i b_{i-1}+\Delta b_i bi−1+Δbi改为了 b i − 1 ′ + Δ b i b^{\prime}_{i-1}+\Delta b_i bi−1′+Δbi。 这样第 i + 1 i+1 i+1层的梯度可以传递到第 i + 1 i+1 i+1层和第 i i i层,同时指导 L a y e r i Layer_i Layeri和 L a y e r i + 1 Layer_{i+1} Layeri+1的更新,再往前就不行了,如下图所示:
致谢:
本博客仅做记录使用,无任何商业用途,参考内容如下:
DINO 论文简介
DINO 源码解析